融合特征筛选策略的双塔网络鞋印检索算法
2023-08-23韩雨彤郭威唐云祁
韩雨彤, 郭威, 唐云祁
(中国人民公安大学侦查学院, 北京 100032)
鞋底花纹特征是犯罪侦查过程中极具价值的证据之一,但鞋印痕迹检索在实践应用中发挥的作用大小受到图像特质、设备引擎、算法技术以及专业职业素养等因素的影响,尚未满足公安实战的需求。根据Alexandre[1]的报道显示,在犯罪现场中,大概有30%的现场鞋印可以被提取,但这些被提取的鞋印不一定都能成为侦查破案的线索。 在现场勘验中,通过摄影或者静电吸附的方式将灰尘鞋印从地面提取,然后通过扫描来实现数字化。给定一个犯罪现场提取的嫌疑鞋印,检验人员在数据库中搜索出与之较为相似的清晰的样本鞋印。在公安工作中,这一检索过程需要调查人员在一个大型的图像数据库中手动搜索,会造成巨大的人工成本和时间成本浪费。因此,将基于计算机视觉的图像自动检索技术引入鞋印检索领域,并在公安实践工作中发挥作用是非常重要的一项工作。
传统的鞋印检索工作从基于人工文本的特征提取到使用尺度不变特征变换、Gabor等传统特征,再到如今以卷积神经网络(convolutional neural network,CNN)作为基础,提取鞋印图像的深度特征进行检索识别。基于深度学习的方法相比较传统算法更加自动化也有更好的识别结果。但是目前已知的研究工作中有以下两个问题:一是鞋印质量参差不齐,存在很多低质量的现场鞋印图像,使得鞋印检索的准确率大打折扣;二是由于卷积神经网络对鞋印特征的关注不够精细,提取的鞋印特征较少,不能够有效代表整个鞋印的特征。
针对以上问题,现对convNeXt网络进行改进,并将鞋印图片分区提取特征,使用两个convNeXt网络分别对各个区域进行学习训练,再将筛选后的分区特征融合,得到最终的鞋印图像特征。
1 鞋印检索技术概述
在多年的鞋印自动化检索研究过程中,鞋印检索算法提取不同鞋印图像特征,如形状特征,纹理特征、尺度不变特征变换(scale-invariant feature transform,SIFT)特征等经典图像特征,将其作为特征描述符进行鞋印图像检索,并都取得了较好的识别效果。
近年来,随着卷积神经网络在各个领域的广泛应用,鞋印检索算法的研究方向也逐渐发生转变,很多研究人员以卷积神经网络为基础模型,训练大量鞋印图像数据,以期让计算机自动提取鞋印图像特征,并根据提取到的特征描述符计算特征距离进行排序。史文韬等[2]将预训练的VGG-16网络在鞋印数据集上进行了微调并直接展开卷积层特征进行检索实验,该实验证明微调的VGG-16网络对残缺的鞋印图像检索效果并不理想。之后,史文韬等[3]又提出了基于选择卷积描述子的鞋印检索算法,并将完整鞋印和残缺鞋印分开检索,提取不同的卷积特征进行检索,其在CSS-200数据集上top1%的识别率达到了92.5%。赵梦影[4]对原始鞋印图像进行分割,构建了基于VGG19的Siamese网络融合并且用三元组损失训练模型,对提取的特征进行特征融合以及相似性度量。Kong等[5]将ResNet50网络提取到图像的深度特征采用多通道归一化互相关的方法进行鞋印图像的匹配。该算法在公开数据集[6]上取得了较好的检索效果。但是该方法由于通过滑动窗和一定角度之间的旋转获得了多个局部区域,在检索过程中耗费了大量时间,并不适用于实际应用中。Cui等[7]采用深度信念网络(deep belief networks,DBN)提取局部特征,并通过空间金字塔匹配得到从局部到全局的匹配分数。在该实验中,前10名的累计匹配得分为65.67%。Cui等[8]对鞋印图像进行预处理,旋转补偿之后划分图像为顶部和底部两区域,计算两个区域神经编码的余弦相似度的加权和,得到两张比对图像的匹配分数。经过实验,top10%的累计匹配分数为88.7%。该法经过主成分分析(principal component analysis,PCA)降维后发现,当降低至原图像特征的95%时检索精度最高。Ma等[9]使用分区策略融合多部分加权卷积神经网络(multi-part weighted convolutional neural network,MP-CNN)提取鞋印特征,在公开数据集上进行实验,top10%的识别率达到了89.83%。周思越[10]提出了一种局部语义滤波器组的鞋印检索算法,该算法在MUES-SR10KS2S、FID-300和CS-Database数据集上的检索实验都取得了优秀的检索结果。但由于数据依赖大量人工预处理,因此检索结果并不稳定。彭飞[11]结合局部语义块和流行排序,在低质量鞋印图像数据集上的top1%的识别率达到了90.3%。焦扬等[12]利用鞋印图片的SIFT特征,使用K均值进行聚类构造视觉词典,提出基于支持向量机(support vector machine,SVM)反馈的二次检索,对初次检索结果中前2%的图片再次分类,再利用二次分类得到的超平面计算图片与超平面之间的距离,以距离为依据进行二次检索。焦扬等[13]提取鞋印图像的SIFT图像并用K-means聚类方法对提取到的特征矩阵进行分类,建立图像特征包,在依据余弦距离进行紧缩排序。实验证明,该算法可以有效提高残缺鞋印的检索精度。吴艳军[14]针对低质量鞋印图像提出一种融合多粒度的图像表征信息,优化了鞋印花纹特征提取方法,是当下鞋印检索的最佳结果。辛一冉等[15]将全局特征和分块的局部特征进行融合,选取EfficientNet网络作为骨干网络,降低了计算成本,在CSS-200数据集上的检索实验也取得了当下最好的检索结果。韩雨彤等[16]将混合域注意力机制融入ResNet34网络中,证明了混合域注意力可以有效提升鞋印检索的准确率,但是由于ResNet34网络学习能力有限的,对于残缺鞋印的检索效果并不理想。
由上述研究可以看出,卷积神经网络在鞋印检索领域的应用范围不断扩展,并且都在改进后取得了较好的检索效果。但是仅仅依靠卷积神经网络并不能有效解决残缺鞋印检索精度低的问题,而现有研究已经开始从鞋印的全局特征转向局部特征,局部语义等方法因为需要人工处理导致实验结果并不稳定。因此,现提出一种融合分区策略和特征筛选的双塔网络模型,希望能提取到更多鞋印图像的有效信息,并进一步提高卷积神经网络对鞋印图像特征的提取能力。
2 融合特征筛选策略的双塔网络鞋印检索算法
卷积神经网络经过多年发展,近些年,计算机视觉应用研究逐渐被Transformer网络[17]取代。Transformer网络引入自注意力模块,这是一种避免循环的模型结构,完全依赖注意力机制对输入输出的全局依赖关系进行建模。Transformer网络突破了循环神经网络(recurrent neural network, RNN)模型不能并行计算的限制,相比较CNN来说,计算两个位置之间的关联所需的操作次数不随距离增长,而网络结构中的自注意力模块使得模型更具有可解释性。Liu等[18]提出了纯粹的“卷积神经网络”,实现了标准的ResNet网络向 “Vision Transformer”(VIT)[19]网络的转变。Liu等[17]经过实验对比发现,在相同的FLOPs下,convNeXt_xlarge网络在ImageNet22K数据集上达到了目前为止最好的准确率87.8%,且网络中具有更快的推理速度以及更高的准确率。但是由于本文使用的训练数据集较小,因此选取convNeXt_tiny网络作为本文算法的骨干网络。
本文研究中的鞋印检索算法结构如图1所示。通过鞋印分区策略将一张鞋印分成足掌区和足跟区分别输入两条卷积网络提取图像特征,在两条支路网络中分别采取两种特征筛选方法进行特征融合,将提取到的网络特征拼接融合后展开作为特征描述符,依据特征描述符计算样本鞋印与嫌疑鞋印之间的相似度,依据距离大小对样本鞋印进行排序输出。
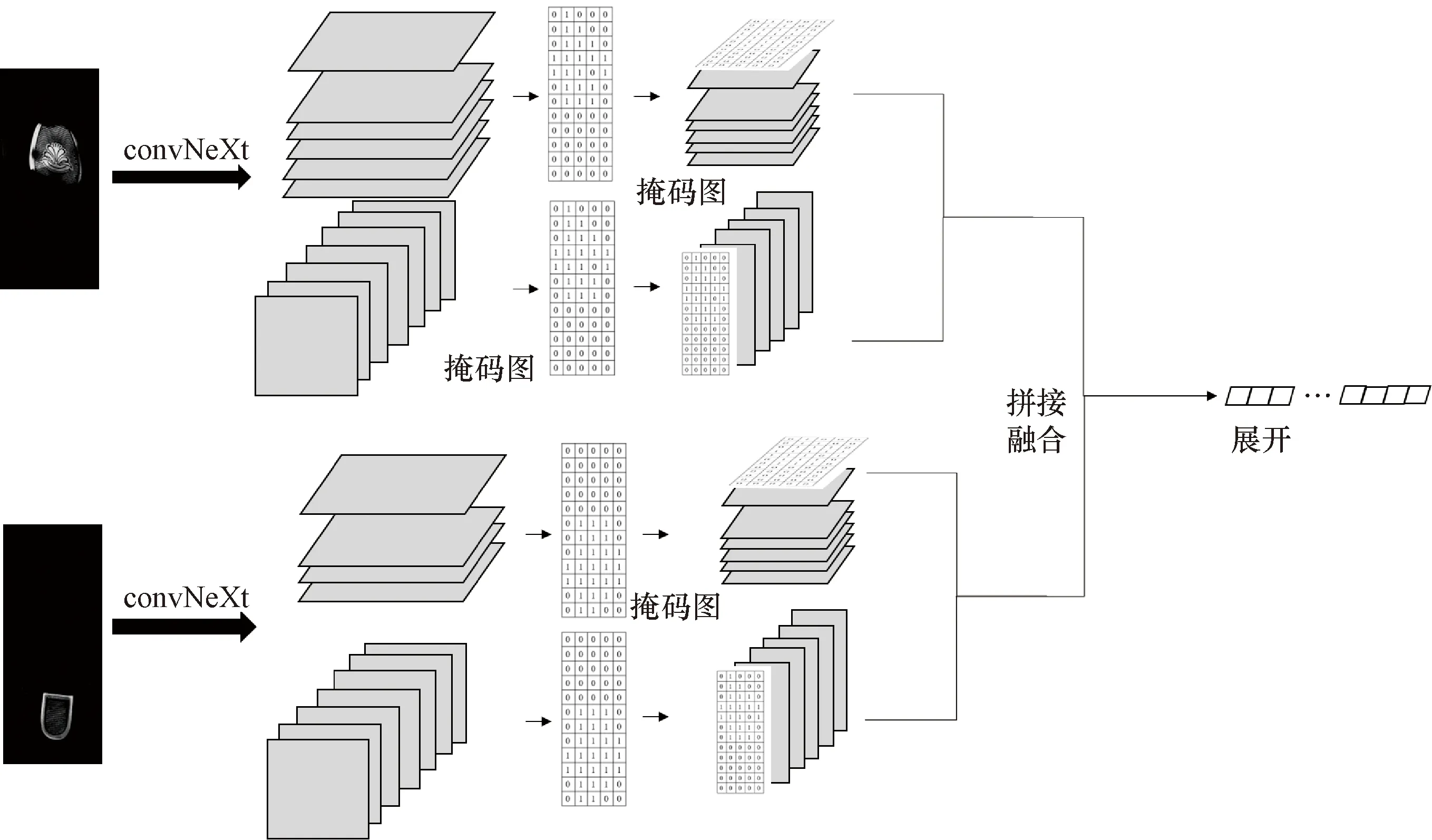
图1 鞋印图像检索算法结构Fig.1 Shoe printing image retrieval algorithm structure
2.1 分区策略
因为鞋印在足掌区和足跟区的花纹样式并不相同,所以将鞋印进行分区成为一种有效的方法,这种方法更加关注鞋印图像的局部特征。Tang等[20]将鞋印图像进行分区,在区分足掌和足跟的基础上,每个部分分别划分成9个更小的区域提取特征,检索时,分别对每个小区域的特征计算相似度,在依据部分相似度来确定整体的相似度。刘家浩[21]在足掌和足跟区划分6个区域,评价每个分区的有效性,只提取有效区的图像特征计算相似度。文献[7]将鞋印图片分为Top块与Bottom块,Top块与Bottom块的比例为3∶2,在各区域提取特征,将特征按照权重加权求和得到图像整体的相似度。专家经验认为为了获得更多的花纹信息,Top块的特征权重应大于Bottom块的权重。但是当应用该方法时,某一区块的鞋印花纹大面积缺失,两张图片相同区域之间的相似度会呈断崖式下降,影响鞋印图像识别的结果。分区求相似度时,两张图片Top块相似度很高,但是由于足跟区鞋印缺失,Bottom块相似度基本为0。所以文献[8]中给两区块简单赋以固定权重再融合的方法实际效果不好。文献[22]中通过计算两区块的有效信息量和置信度,再通过设置阈值、预设相似度等一系列方法解决这一问题,效果理想但是方法复杂。基于以上原因,为了简化方法,本文研究并未将鞋印进行裁剪,而是将其通过掩码图变为留有半张鞋印的残缺图像(图2),以此提高模型对鞋印图像的特征提取能力,进一步提升残缺鞋印的检索结果。不计算部分相似度,直接融合两个网络提取到的鞋印特征作为到特征描述符,即最终用于检索的特征向量,含有每个区域的特征信息,因此在计算相似度时这样当有鞋印缺失时,相似度不会出现突然下降的情况。

图2 分区鞋印 Fig.2 Partition shoe print
2.2 convNeXt骨干网络
参考文献[18]中叙述的convNeXt网络相比于其他的卷积神经网络,主要改进的方面如下。
2.2.1 结构设计
以ResNet50网络为例,ResNet50结构分为5个部分(stage),除第一层外,后4个stage都有残差模块堆叠而来,4个stage的残差模块的堆叠比例是3∶4∶6∶3,文章将Swin transformer网络[23]block模块中的比例引入ResNet50网络,变为1∶1∶3∶1,即将ResNet50中每个部分残差模块的数量从(3,4,6,3)调整为(3,3,9,3)。
在ResNet50网络中,鞋印图像在进入残差模块前会经过一个卷积核为7×7,步长为2的卷积层,再接入一个最大池化下采样层,而convNeXt网络选择引入“patchify”层,使用一个卷积核大小为4×4,步长为4的卷积层将图像进行分块,然后在通道方向展平。
2.2.2 深度可分离卷积
借鉴ResNeXt网络[24]的思想,将卷积核分成不同的组,使用深度可分离卷积结构,与传统卷积不同,在深度可分离卷积中由深度卷积和逐点卷积两部分组成。深度卷积模块中,如图3(a)所示,每个卷积核的深度都为1,每个通道都通过深度为1的卷积核进行卷积。因此,经过深度卷积后,特征矩阵的深度并不会发生变化。深度卷积相较于传统卷积核大大减少了运算量和参数数量,使得网络变得更为简单。逐点卷积模块将不同组经过深度卷积后的特征图用1×1的卷积并拼接起来得到输出的卷积特征图,如图3(b)所示。在深度卷积的过程中,将3×3的卷积核变为和Swin transformer中相同的7×7的卷积核。

图3 深度可分离卷积 Fig.3 Depthwise separatable convolution
2.2.3 Layer Normalization(LN)
Batch Normalization(BN)在卷积神经网络中是常用的操作,它可以加速网络的收敛并减少过拟合,但是BN层在训练过程中的效果需受到batch大小的限制,且计算复杂,因此本文研究选用LN层。LN是针对时序网络提出的。由于在时序网络中,文本的长短并非定值,所以针对时序网络提出的LN层并不受样本的限制。当LN应用于图像处理时,也不受batch大小的限制。LN层公式为

(1)

(2)

LN层只对单个样本进行计算,而且在计算过程中,不保存最小batch的均值和方差,节省了存储空间。
2.3 嵌入混合域注意力机制的convNeXt网络结构
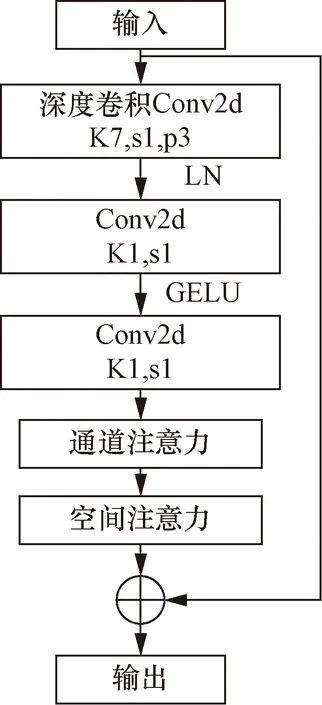
K为卷积核尺寸大小;s为卷积步长;p为图像边缘增加的边界像素层数;LN为层归一化;GELU为激活函数图4 加入注意机制的Block结构 Fig.4 Block structure
由于更改后的网络模型层数更多,而本文的数据集较小,因此选择以convNeXt_tiny网络作为骨干网络,独立的convNeXt网络模型如图5所示。

图5 convNeXt网络结构图Fig.5 ConvNeXt network structure diagram
2.4 特征筛选策略
选择性卷积特征卷积描述子[26](selective convolutional descriptor aggregation,SCDA)是2017年提出的专门针对细粒度图像的检索方法。在细粒度图像检索方法中,SCDA提取了VGG-16网络中relu5-2和最后一层卷积层特征,将两者的特征级联拼接成用于相似度计算的特征向量。但是SCDA方法对两个卷积层的特征进行计算,且中间层relu5-2的卷积特征是最后一层卷积特征大小的4倍,带来了计算内存的提高。史文韬等[3]将SCDA方法应用于鞋印检索领域,提取VGG-16网络最后一层卷特征进行筛选,将鞋印分为完整鞋印和残缺鞋印使用不同方法进行特征检索。Wang等[27]改进了特征筛选方法,依据最大响应频次进行特征筛选,节省了计算机的运算内存。本文研究选取convNeXt网络作为骨干网络,提取最后一层卷积特征进行筛选。每一层的卷积特征都是由前一层的卷积计算得来的,而每一个卷积层在特征图上滑动窗口时计算得到下一层的特征图,相当于组合了多个滤波器。经过大规模数据的学习训练,调整滤波器的参数,可以得到鞋印图像的特征图。因此,输出的二维特征图中(i,j)处是该张特征图的最大响应值,说明此处为滤波器对原始鞋印图像中最感兴趣的区域,可能包含重要的特征信息。每一层卷积特征沿深度方向会有多个二维特征图,当该区域多次出现最大响应值,那么说明该位置的特征在鞋印图像中较为重要。假设该图像不存在特征信息时,通过滤波器后特征响应会均匀分布在二维特征图上,因此出现最大响应次数多的位置即重点位置,而有些位置从未出现最大响应,该位置则被通过设定的阈值筛选掉。
最大响应频次的筛选规则为:提取convNeXt网络最后一层卷积特征,沿深度方向将其分为若干个二维特征图,标记每一个出现最大响应的位置,在深度方向将所有的特征图累加得到二维频次特征图,该特征图上记录了每个位置出现最大响应值的次数。再选取合适的阈值,将大于该阈值(Threshold)的特征保留下来,得到经过筛选的特征图。
前文假设了经过卷积计算的特征在没有被区别对待时,最大响应值的次数会均匀分布在特征频次图中,每个位置出现最大响应次数为
Threshold=D/WH
(3)
式(3)中:W为特征图的长度;H为特征图的宽度;D为特征矩阵的深度。
以convNeXt网络为例,最后一层特征深度D为768,以400×150的原始鞋印图像输入特征网络,得到12×4的卷积特征图,将Threshold作为筛选局部特征的阈值。但是该阈值只是一个参考标准,具体的Threshold需要通过后续的实验确定适当的数值以达到最佳的检索精度。
将二维频次图通过阈值进行筛选得到二维掩码图Maski,j为
近年来,我国公路桥梁施工技术发展迅速,如在高等级公路建设中,在线型设计布局方面的要求也在逐年提升,特别是对高墩桥梁建设中的加固技术更有了新的要求标准,在一定程度上增加了施工难度。我国高速公路桥梁的基本特点包括:(1)跨度大,对承载力要求高。公路桥梁工程是跨越水域、山谷等地势的构造物,因此,其跨度通常较大,相应地对其结构的承载力要求也高。(2)耐久性强。桥梁工程的设计年限一般为100~120年,并且在运营过程中,会受到环境、有害化学物质的侵蚀以及车辆荷载、风荷载、超载及人为等因素的影响,因此,为了保证桥梁的正常通行,要求桥梁工程的耐久性较强。
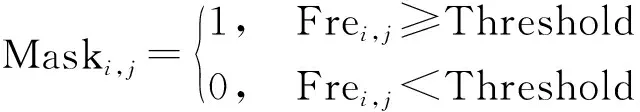
(4)
式(4)中:(i,j)为二维坐标;Frei,j为每个位置出现最大响应的次数;Threshold为当前阈值。
图6是特征筛选的流程图。从图6中可以看出,经过特征选择后,第24维特征图最大响应位置位于残缺鞋印的中间部位,第138维特征图的最大响应出现在残缺鞋印的底部,第566维特征图的最大响应位置出现在残缺鞋印的顶部,说明最大响应出现的位置都是含有图像特征的位置,保留下的二维频次图覆盖整个鞋印所在的区域,增强了特征区分度。

图6 最大响应频次特征选择流程图Fig.6 Flow chart of feature selection for maximum response frequency
3 实验结果及分析
3.1 数据集
3.1.1 训练集
所用训练集为文献[16]中重新处理的CSS-200数据集,加入了201类人为模仿的残缺鞋印。训练集中共有634类,131 105张鞋印图片。
3.1.2 测试集
选取CSS-200数据集[2]和公开数据集FID-300作为测试集。CSS-200数据集是公安机关标准采集的样本数据,与训练集中的部分数据属于同源数据但鞋印花纹种类并不重复。该数据集共有200张嫌疑鞋印以及5 000张样本鞋印比对数据。FID-300数据集是公开数据集,包含从现场采集的300张嫌疑鞋印和1 175张样本鞋印比对库。
3.2 实验配置
训练及检索实验都是在NVDIA Digits深度学习平台上完成,操作系统为Windows10(64位),CPU为英特尔Core i7-10700,内存64 GB,GPU为 GTX2080Ti,显存11 GB。实验所用的深度学习框架为Pytorch1.9。
在训练神经网络的过程中,选择AadmW优化器以及Warm up训练策略。AdamW优化器在Adam优化器的基础上将参数在更新时引入参数自身,解决了Adam函数中易出现的参数过拟合的问题。Warm up训练策略是指在神经网络的训练过程中,神经网络的学习率在开始训练时十分不稳定,设置很低的初始学习率,促进网络更好的收敛。Warm up策略使得学习率逐渐增大直至较高的学习率,当以较高的学习率完成训练后,再降至初始学习率进行训练,实现神经网络的快速收敛。
3.3 评价指标
本文算法主要应用于案件侦破过程中对现场鞋印的线索提取,检索返回的正确结果排名靠前可以为办案人员节省更多的时间和人工成本。因此采用累计匹配曲线(cumulative match characteristic,CMC)作为算法的评价指标。CMC曲线的横轴表示返回的所有候选图片的前k位,下文用topk表示,纵轴代表鞋印检索实验的准确率。针对公安侦查的需要,侦查人员需要在返回的结果图像中更靠前的位置找到相同种类的鞋印花纹,因此将top1和top1%作为主要的评价指标。
3.4 实验结果分析
为了证明本特征提取网络的有效性,对不同网络模型的实验结果和不同网络数量下的鞋印检索实验结果进行了比对。
3.4.1 消融实验
为了确定合适的Threshold,在不同的数据集上进行了消融实验。由表1可知,Threshold数值从0开始递增,可以看出在不同的数据集上检索精度随着阈值的变化趋势一致,在达到最佳阈值前,检索精度随着Threshold的增大而提高,当Threshold不断变大时,特征图中将保留下较少的鞋印特征信息,破坏鞋印的主体特征,鞋印图像的检索精度开始下降。为了更直观地看出实验结果的变化趋势,给出了不同数据集在不同阈值情况下实验结果的折线图。由图7可以看出,在Threshold=3时,检索精度最高。

表1 不同Threshold在CSS-200数据集上的实验结果比较Table 1 Comparison of experimental results of different thresholds on CSS-200 data sets
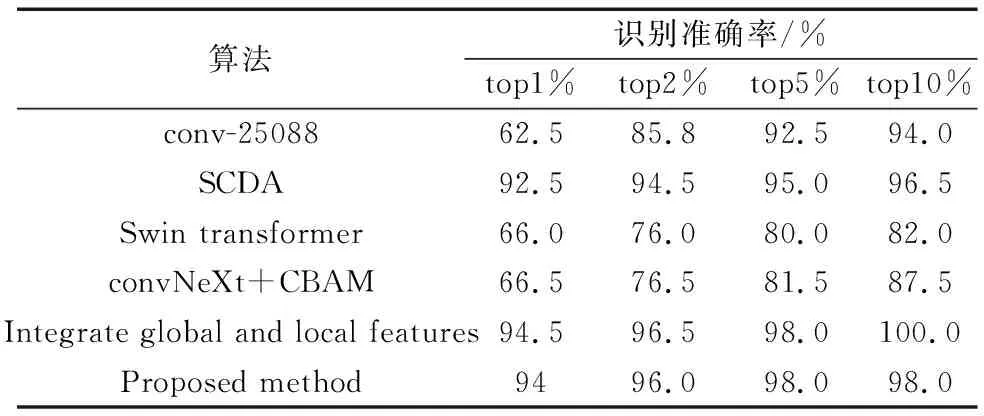
表2 不同网络模型在CSS-200上的实验结果Table 2 Different network models on the experimental results on CSS-200

图7 CMC曲线Fig.7 CMC curve
3.4.2 不同网络模型在CSS-200上的实验结果
选取微调VGG-16网络(conv-25088),选择性特征筛选方法,Swin-transformer网络,以及融合全局特征与局部特征等方法进行比对。同时,将独立convNeXt网络在鞋印检索实验中的数据一同进行比对。实验结果表明,虽然本文算法没有达到目前最好的结果,位列第二,但是与最好结果相差较小,相比较其他方法相比,仍然有很大提高,在top1%位置达到了94%的准确率。
3.4.3 基于公开鞋印数据集FID-300中不同方法的实验结果比较
通过对公开数据集的比较,可以直观地看出本文研究中特征提取网络在鞋印图像检索领域的实验效果。如表3所示,在FID-300数据集上,分区双塔网络提取的特征检索实验前1%的识别率为69.40%,top10%的识别率为90.75%。由于文献[10-11,28]采用频谱特征进行图像特征的相似度衡量,所以不将这两种算法的特征维度与其他方法进行比较。可以看出,本文提取的特征描述符维度过高,相比较其他特征维度较低的算法,特征描述符维度过高的算法对于残缺鞋印的识别准确率都有所欠缺。因为在进行特征检索时会将与图像无关的信息如噪声等一起与样本图像进行对比,无关信息会对鞋印图像特征之间的相似度计算造成不利影响。然而,本文算法在top1%的准确率大幅提高,算法在公安工作中依旧有其优势。相关方法在全部FID-300数据集上的识别率最高为93.7%。虽然本文算法没有超越当下的最好结果,但是通过CSS-200和FID-300两个数据集的实验结果可以看出,使用本文算法能够明显提高残缺鞋印图像的检索精度。

表3 本文算法与先进方法在FID-300数据集上的结果比较Table 3 Compare the results of the algorithm and advanced method on the FID-300 data set
4 结论
本文算法在CSS-200和FID-300数据集上均取得了较高的准确率,但是与当前最好的检索精度相比仍有较小差距,一方面是由于在训练阶段就使用了双塔网络结构,虽然convNeXt网络经过改进之后在训练时减少了参数,但是网络结构仍然较为复杂,且直接展开卷积特征的特征描述符维度过高制约了图像识别准确率的提高,这也为下一步的研究指明了方向;另一方面,FID-300数据集在预处理方面仍然有待提高,并没有达到公安机关采集鞋印的标准,导致鞋印图像出现变形,对图像识别造成困难。综上所述,通过融合分区策略以及特征筛选策略有效地加强了鞋印局部特征关注度,且嵌入注意力机制的新型卷积神经网络进一步提高了对鞋印图像的识别精度。
