基于集成学习的电影票房预测
2023-08-23张涛陈潇潇
张涛,陈潇潇
(北方工业大学, 北京,100144)
0 引言
随着社会经济的发展,社会生活水平提高,看电影已经成为一项主要的娱乐活动。据国家统计局统计,2021中国票房近470亿,几乎是2019年中国票房的5倍[1]。尽管大多数公司都想从这个巨大的市场中分一杯羹,但只有几部热门电影实现了盈利,其他电影则在亏损[2]。因此,如何准确地预测电影票房,降低投资风险,避免公司因投资失败而遭受巨大损失已成为亟需解决的问题。
随着人工智能技术的快速发展,越来越多的学者将机器学习等数据挖掘技术应用于电影票房预测中,郭萱[3]以2014年-2016年的173部影片为研究对象,引入了基于条件推断树的随机森林模型对电影票房进行预测,研究结果表明,基于条件推断树的随机森林预测模型比传统的随机森林预测模型准确度更高。杨朝强[4]分别训练了LSTM模型和BP神经网络模型,得出了LSTM模型的平均相对误差比BP神经网络模型的平均相对误差要低的结论。李振兴[5]的研究结果表明,演员是影响电影票房的关键因素。甘雨涵[6]爬取了2016年全年在国内上映的150部电影的豆瓣评论信息,通过分析评论中的情感倾向,证明了口碑对电影票房的重要性。
在前人研究的基础上,本文首先分别建立了XGBoost、LightGBM、CatBoost、随机森林(Random Forest)和支持向量回归(support vector Regression)票房预测模型,并通过optuna框架对五个票房预测模型的超参数进行优化,提高单个票房预测模型的预测精确度;然后,使用测试集,通过加权stacking算法进行了电影票房预测,并与传统的票房预测模型进行了对比,验证了模型的有效性。
1 相关工作
■1.1 评价指标
为了有效评估模型的预测效果,本文采用了平均绝对百分比误差(MAPE)、均方误差 (MSE)、均方根误差(RMSE)以及kaggle上的评分这四项指标作为模型评价指标。
平均绝对百分比误差(MAPE)表示的是真实值与预测值之差的绝对值占真实值之比。MAPE值越小,模型预测效果越好。具体公式如下:
式中:n为样本数,为预测值,yi为真实值。
均方误差(MSE)是指预测值与真实值的距离的平方和的平均数,MSE的值越小,模型预测效果越好,具体公式如下:
均方根误差(RMSE)是均方误差的算数平方根,RMSE的值越小,模型预测效果越好,具体公式如下:
Kaggle上的评分是指当用户提交对测试集的预测结果时,kaggle对测试集的预测结果的打分,kaggle上的评分越低,排名越靠前,模型预测效果越好。
■1.2 Optuna框架
Sklearn 的GridSearchCV函数可通过网格搜索与交叉验证的方式来进行超参数优化,但由于其会遍历给定范围内的所有超参数组合,所以非常耗时,特别是当超参数的数量增长时,网格搜索的时间复杂度将呈现指数增长。
Optuna 是一个完全用 Python 编写的自动超参数调整框架。专为机器学习而设计,可以与 PyTorch、TensorFlow、Keras、SKlearn 等其他框架一起使用。
Optuna 的优化程序中只有三个核心的概念,分别为目标函数(objective),单次试验(trial),和研究(study)。其中目标函数负责定义待优化函数并指定超参数范围,单词试验对应着目标函数的单次执行,而研究则负责管理优化,决定优化的方式,记录总试验的次数、试验结果等。
■1.3 传统stacking算法介绍
stacking 算法一般采用两层结构,第一层的学习器被称作初级学习器,也被称为基学习器,常用作对经过处理后的原始样本的训练和预测,第二层的学习器为次级学习器,也被称为元学习器,用于结合第一层的验证集与测试集的预测结果再次进行学习。
Stacking算法能够结合每个基学习器的优点,提高模型的整体预测精度。Stacking算法的流程图如图1所示,假设第一层有两个基学习器,每个基学习器分别对原始训练集进行训练, 得到验证集的预测结果v1 和v2。对整个测试集的进行五次预测,将结果进行相加取平均得到测试集结果T1和T2。水平连接V1和V2得到新训练集TrainNew,水平连接T1和T2得到新的测试集Testew,将新训练集Trainnew与原始训练集一同放入元学习器中进行训练,将最终所得的元学习器对TestNew进行测试后即可得到测试集的最终预测结果。

图1 stacking算法的流程图
■1.4 改进stacking算法介绍
在传统stacking算法中,在第二层进行集成时,仅仅是将测试集的预测结果进行的平均处理,这样会平均掉表现好的模型的训练结果。因此,可对次级学习器的每一折预测结果进行加权处理,从而提高模型在测试集上的表现,具体的示意图如图2所示,其中wi即为权值,权值为每一折验证集的预测值与真实值的误差,wi的计算方式如公式(4)所示,式中mape的定义如公式(1)所示。

图2 次学习器中精度加权的改进
2 数据预处理
本文选取的是Kaggle竞赛中的数据,数据来自于TMDB电影数据库,数据集共有9399条,其中有5001条训练集数据,4398条测试集数据。数据集共包括电影Id、系列电影名、电影预算、电影类型、电影官方主页、TMDB官网id、原始语言、电影原始名称、电影简介、流行程度、海报链接、出品公司、出品国家、发行日期、电影时长、电影语言、电影状态、宣传语、电影名称、电影关键词、演员、导演和电影总收入这二十三个特征。其中,电影总收入为预测目标变量。
由于Kaggle提供的数据为未经过处理的原始数据,其中包含有文本类型的数据,不能将其直接输入模型训练,需要进行数据预处理,数据预处理包括正态化处理、数值化处理以及标准化处理。
(1)正态化处理
正态化处理是指将不符合正态分布的特征数据转换成符合正态分布的特征数据。该数据集包含有电影预算和电影总收入这两个不符合正态分布的特征,正态化处理方式有指数变换、对数变换、Box-cox变换等,需要根据数据的不同情况进行选择,通常采用指数变换将左偏数据的数值较大的数据点间的距离增大,采用对数变换将右偏数据的数值较大的数据点间的距离缩小,而Box-cox变换既可以处理左偏数据,也可以处理右偏数据。本文使用的是对数变换对电影预算和电影总收入进行转换,使分布不均的数据服从正态分布。
(2)数值化处理
数值化处理是指将类别型特征和文本型特征转换成数值型特征,该数据集共包含有11个类别型特征,分别包括系列电影名、电影类型、电影官方主页、出品公司、出品国家、电影语言、电影状态、电影名称、电影关键词、演员、导演。该数据集有三个文本型特征,分别包括电影简介、发行日期和宣传语。
独热编码,又称一位有效编码,是使用M位状态寄存器对M个状态进行编码的方式,每个状态都有它独立的寄存器位,并且在任意时刻,这些寄存器位中只有其中一位有效。独热编码能将类别型特征的取值扩展到欧式空间,有效扩充了特征,使特征之间的距离计算更合理。经过独热编码,系列电影名、电影类型、电影官方主页等11个类别型特征一共转换成了113个数值型特征。
而对于电影简介和宣传语这两个特征来说,将对应文本的长度作为特征的量化值;对于发行日期这个特征来说,将具体的年、月、日作为其量化值。
(3)标准化处理
标准化处理是指通过一定的数据变换方式,将数据落入到特定区间内,使结果更具有可比性。标准化的处理方式有极差标准化法,即min-max标准化法、Z-score标准化法、归一化法、中心化法。本文采用的是min-max标准化法,该方法的具体转换公式如下。
式中x′为转换后的数据,min为原始数据的最小值,max为原始数据的最大值,x为原始数据。
删除了电影Id、TMDB官网Id、原始语言、原始名称、海报链接这五个无关特征后,最终形成了一共包含有9399条数据,143个特征的数据集。
3 实验
对于第一层的初级学习器来说,搭建模型的主要任务即是进行模型的超参数优化,常用的超参数的优化方法有网格搜索、随机搜索、贝叶斯优化等, Optuna优化框架支持以上所有优化方法,因此本文选用了Optuna框架对模型的超参数进行优化。
(1)基于XGBoost的票房预测模型
基于XGBoost的电影票房预测模型的主要超参数有max_depth, subsample, colsample_bytree和learning_rate,max_depth为XGBoost中树的最大深度,max_depth的值越大,树越复杂,模型学习的更加具体,系统默认值为6,一般设置在3~10之间。subsample为XGBoost中每棵树随机选择样本的比率,系统默认值为1,范围在 (0,1]之间。colsample_bytree是构建每棵树时随机选择特征的比例,系统默认值为1,范围在在(0,1]之间。learning_rate为每一步迭代的步长,默认值为0.3,一般设置为0.1。
根据Optuna优化框架得到的基于XGBoost的票房预测模型的主要超参数如表1所示。

表1 XGBoost模型的超参数表
(2)基于LightGBM的电影票房预测模型
基于LightGBM的电影票房预测模型的主要超参数有num_leaves, min_data_in_leaf, max_depth, learning_rate 。nums_leaves为LightGBM中每棵树上的叶子节点的个数,默认值为31,增大num_leaves的值能提高模型预测的准确率,但过高会导致模型过拟合。min_data_in_leaf为LightGBM中一个叶子节点上的最小样本数,默认值为20,增大min_data_in_leaf可以防止过拟合。与XGBoost类似,max_depth为树的最大深度,learning_rate为学习率。
根据Optuna优化框架得到的基于LightGBM的票房预测模型的主要超参数如表2所示。

表2 LightGBM模型的超参数表
(3)基于CatBoost的电影票房预测模型
基于CatBoost的电影票房预测模型的主要超参数有iterations, learning_rate, depth, bagging_temperature。与XGBoost类似,iterations为可以建立的树的数目,learning_rate为学习率,depth为树的深度,bagging_temperature为贝叶斯套袋控制强度,默认值为1。
根据Optuna优化框架得到的基于CatBoost的票房预测模型的主要超参数如表3所示。

表3 CatBoost4模型的超参数表
(4)基于支持向量回归的票房预测模型
在使用rbf作为核函数的情况下,基于支持向量回归的票房预测模型的主要超参数有gamma和C。其中,gamma决定了数据集映射到新的特征空间后的分布,gamma越大,支持向量越少。gamme越小,支持向量越多C是模型的正则化系数,默认值为1.0,主要用来防止模型过拟合,C值越大,对模型的惩罚越高,泛化能力越弱,即造成了过拟合。反之,C值越小,对模型的惩罚越低,泛化能力越强,即造成欠拟合。
根据Optuna优化框架得到的基于支持向量回归的票房预测模型的主要超参数如表4所示。

表4 基于支持向量回归的票房预测模型的超参数表
(5)基于随机森林的票房预测模型
基于随机森林的票房预测模型的主要超参数有n_estimators, max_depth, min_samples_leaf和max_features。与XGBoost类似,max_depth 为决策树的最大深度,n_estimators为决策树的个数, min_samples_leaf为叶子节点所需的最小样本数,默认值为1,若叶子节点样本数小于min_samples_leaf,则对该叶子节点和兄弟叶子节点进行减枝,只留下该叶子节点的父节点。max_feature为构建决策树最优模型时考虑的最大特征数。
根据Optuna优化框架得到的基于随机森林的票房预测模型的主要超参数如表5所示。
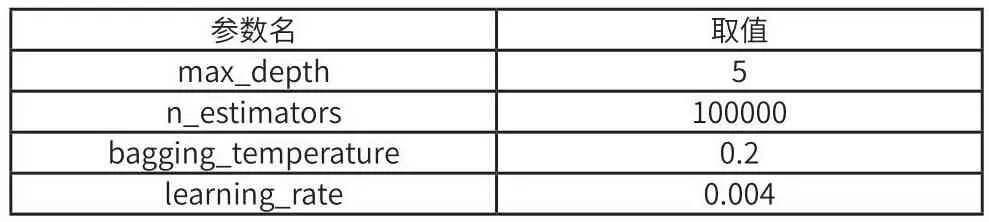
表5 基于随机森林的票房预测模型的超参数表
(6)基于改进stacking算法的票房预测模型
在对以上五个模型进行集成时,本文选用的是岭回归算法进行集成。分别记录下每折验证集真实值与预测值的差异,对对应测试集的结果进行加权,即得到最终预测结果。
将本文提出的基于改进stacking算法的票房预测模型与基于XGBoost、LightGBM、CatBoost 、随机森林、支持向量回归、传统stacking算法的票房预测模型的实验结果进行对比,最终结果如表6所示。

表6 不同算法的指标对比
从表6中可以看出,单个模型中,基于XGBoost的票房预测模型性能最好,而基于传统Stacking算法的票房预测模型的性能优于单个模型的性能,基于改进stacking算法的票房预测模型性能又优于基于传统stacking算法的票房预测模型,可见改进stacking算法能充分挖掘和利用数据信息,在模型之间取长补短,最终取得更好的效果。
4 总结与展望
针对电影票房预测模型精确度低的问题,本文提出了一种对测试集加权的stacking算法,对 kaggle提供的TMDB电影票房数据集进行了预测。首先,分别训练了第一层的XGBoost、LightGBM。CatBoost、支持向量回归和随机森林电影票房模型,并使用了Optuna参数优化框架找到了模型的最优超参数,优化了模型;然后,在对第一层的模型进行集成时,第二层使用了对测试集加权的岭回归算法。实验结果表明,与其他算法所搭建的电影票房预测模型相比,基于对测试集加权的改进stacking算法所搭建的模型对电影票房的预测更加准确,效果更好。因此,本文的方法可以对投资公司进行电影票房预测提供有效的参考。然而,本文中使用的电影票房数据有限,将来需要更多的数据来构建鲁棒性更强的票房收入预测模型。
