Spark云平台电力负载预测系统的设计与实现
2023-08-22邓洪波梁志明
李 磊,王 云,邓洪波,梁志明
(华南理工大学电子与信息学院,广州 510641)
0 引 言
电力工业是关乎国家经济发展和人民生活质量的重要基础,如何能合理的规划和开展安全的电力传输成为提高电力服务质量的重要因素[1]。而电力负荷预测是电力系统有效规划和安远运行决策制度的重要数据依据之一。电网负荷预测不仅影响电网电力传输调度的决策,使得电力供给能够提前进行调度,提高电力传输的有效性和经济性,同时提高了对电力系统的装置的优化利用、减少发电备用、提高经济调度、确保系统可靠性和可维护性[2-3]。目前已有很多的预测方法,如杨中华[4]提出了—元线性回归模型在电力系统负荷预测中的应用,该方法证明了线性回归模型对于电力负载预测的有效性;张宗华等[5]提出了BP 神经网络的电力负载算法,该算法利用全连接神经网络获得比线性回归更加精确的预测结果;程子华[6]提出了一种基于支持向量机的电力负载预测算法,该算法利用支持向量预测方法对电力的负载数据进行处理,获得优于神经网络的处理效果。然而,传统的预测模型参数难以同时满足不同情况下复杂时变的电力负载预测,从而获得更高预测精度,其电力负载数据吞吐量极大,单台计算服务器的算力无法保证对电力负载数据的处理。因此,需要基于大数据云平台架构设计一种新的电力负载预测模型。
本文针对上述问题,提出了一种多模型的自适应神经网络预测算法,可根据不同电力负载的变化将数据调度到相对应的神经网络模型中进行处理,从而提高对复杂多变电力负载的预测精度;同时,基于Spark云计算架构对提出的模型算法进行实现,以证明云平台对电力负载处理性能的优势。
1 预测模型的设计
电力负载数据是一种典型的时序数据,即按照时间先后顺序记录的数据信息,因此,对于电力负载预测模型其本质是建立历史的数据之间的关系,利用这种关系估计未来的输出数值,即预测下一个时刻的数值,可表示为
式中:tn为时间t中第n个时刻,tn-m为时间t第n-m个时刻,即距第n个时刻tn过去的第m个时刻;g*(t)n+1)为时间t中第n+1 个时刻的负载预测数值;g(tn),g(tn-1),…,g(tn-m)为时间t中n到n-m个时刻的负载真实数值;f(·)为预测数值与历史数值之间的关系函数。
人工神经网络也已经被成功用于处理各类的数据处理。本文采用人工神经网络作为电力负荷的预测模型,其用于数据预测的人工神经网络结构模型(回归神经网络)如图1 所示。该神经网络分为3 层结构,输入层由归一化后前几个时刻的电力负荷数据构成;隐藏层由多个神经元通过权重值与输入层进行全连接,每个神经元的输出可表达为
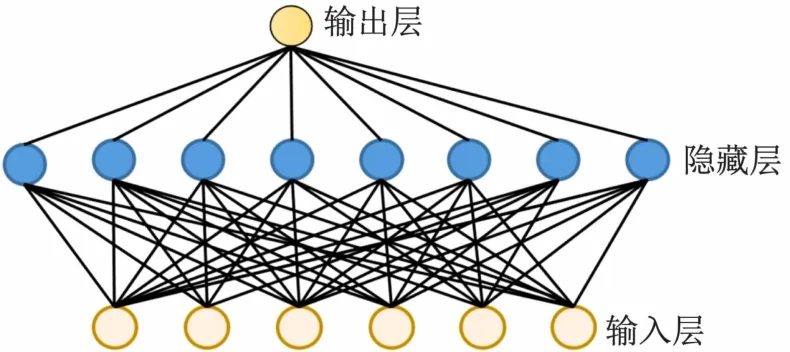
图1 回归神经网络结构示意
式中:j为输入层神经元总的个数;k代表隐藏层中第k个神经元为输入层神经元与隐藏层神经元对应的连接权重值;xi为输入层第i个神经元输入的数值;σ(·)为对应神经网络的激活函数,一般为Sigmoid或者ReLU函数。输出层为线性输出,可表示为
如图1 所示,本文采用的神经网络模型j=5,l=8。此外,输出层需进行输入反归一化运算后可得到实际电力负载预测数值。
电力负荷数据的变化的规律受多种因素影响,如作息时间、节假日、社会活动等,因此,电力负荷并不是恒定不变的,会呈现周期性,甚至是突变性的,如图2所示为0.5 h采集一次的电力负载变化示意图。
从图2 中可知,电力负荷数据具有明显周期性和突变型,而单一的人工神经网络难以处理如此复杂的数据。因此,为了提高电力负荷的预测精度,本文分析了电力负荷变化的特点,将电力负荷分为上升和下降2 种类型分别进行处理,如图3 所示。

图3 电力负荷变化分类示意
基于上述思路,本文提出了一种自适应分类电力负荷分类预测神经网络(Adaptive Classification Neural Network for Power Workload,ACNN-PW),其结构如图4所示,自适应的分类电力负荷分类预测神经网络工作流程:①电力负荷数据输入到分类神经网络中,由分类神经网络对数据的数据进行分类,判断该数据是爬升还是下降类型;②根据分类神经网络的输出结果触发对应类型的预测神经网络;③将电力负荷数据调度输入到触发的预测神经网络中进行预测处理。
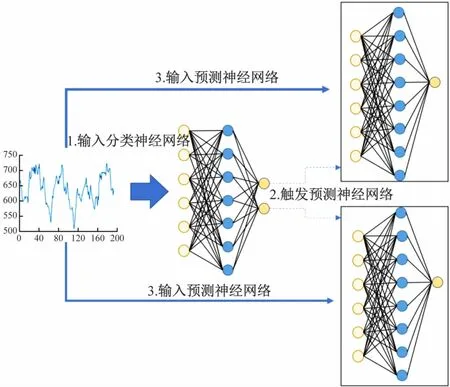
图4 自适应的分类电力负荷分类预测神经网络结构示意
2 非监督学习与模型的训练方法
在训练分类神经网络和预测神经网络时,电力负荷数据采集时间点和其自身的电力负荷值难以将电力负荷数据有效地分为爬升和下降2 种类型。为避免分类数据产生的人工成本问题,本文使用非监督机器学习算法(即K-Means算法[7]),并结合电力负荷变化特征,将电力负荷自适应划分至对应的类别中。其中一阶梯度特征能有效地表征电力负荷变化,如图5 所示其可表示电力如何变化趋势,其表达式为

图5 一阶梯度特征电力负荷变化表征示意
式中:∇为一阶梯度值;y(ti)为第ti时刻电力负载值。
图6 所示为基于一阶梯度特征的自适应分类电力负荷分类预测神经网络训练流程。
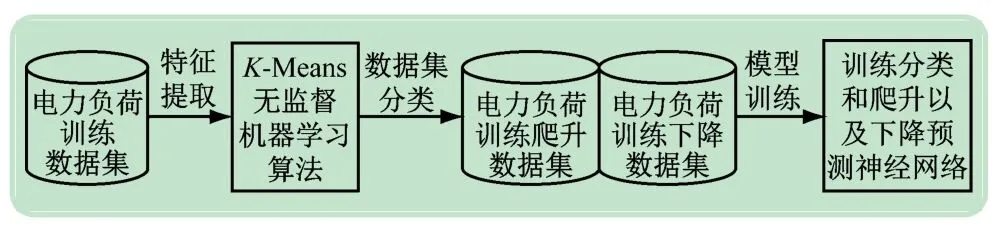
图6 自适应的分类电力负荷分类预测神经网络训练流程
由图6 可知,自适应的分类电力负荷分类预测神经网络训练流程:①从电力负荷训练数据集提取一阶梯度特征;②根据一阶梯度特征,K-Means 算法将电力负荷数据集分为爬升和下降训练数据集;③将爬升和下降数据集以及K-Means算法对2 个数据集进行标签训练分类神经网络以及爬升和下降预测神经网络模型。预测神经网络采用平方差损失函数,即:
式中,N为模型训练中采集数据时刻的总数。
3 Spark云平台的数据处理的实现
如图7 所示Sprak RDD 结构示意图,核心是建立在统一的抽象弹性分布式数据集(Resilient Distributed Datasets,RDD)之上,是基于RDD 进行内存算法的分布式和迭代实现[8]。其中,RDD包括了基本的数据分发和数据汇聚,其中每次运算都会转换为一个新的RDD对象,其速度明显快于传统的Hadoop 框架[9-10]。该结构可以同时启动多个RDD 对象对神经网络进行并行化训练,利用Spark 的Manager Node 结构实现类似Boosting 并行化训练方式,可加速神经网络的迭代训练速度,将每个Work Node 都运行一个独立ACCNPW,然后将数据分配到各个Work Node 进行独立训练,Manager Node负责将梯度进行收集并收集然后进行分发,以更新各个Work Node 节点模型的梯度。同时。在完成模型的训练后,可以利用Spark 的Streaming框架,即Spark的实时数据流处理模式,实现高吞吐量的电力负荷处理处理。
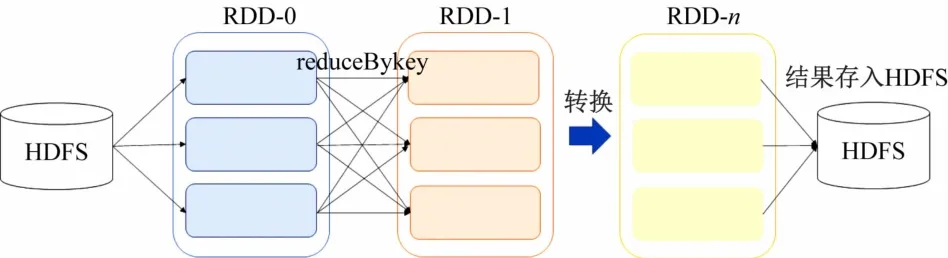
图7 Spark RDD结构示意
4 实验与结果分析
4.1 测试平台
本文采用6 台配置为2 个E5-2630CPU、96GB 内存的服务器进行Spark 集群的搭建,其中1 台作为Spark的管理节点Manager Node,5 台作为计算节点服务,每台服务器采用Docker 进行资源的整合和管理,Spark架构如图8 所示。

图8 Spark集群架构示意
4.2 测试评价指标
测试采用1997、1998 年度的电力负载测试数据,数据记录了0.5 h为周期的电力负荷数值。本文将该数据集70%用作训练,30%用作测试,同时与线性回归(Linear Regression,LR)、支持向量(Support Vector Regression,SVR)、人工神经网络(Artificial Neural Network,ANN)进行比较。采用方均根偏移(Root-Mean-Squra Deviation,RMSD)[11]、平均绝对百分比误差(Mean-Absolute-Percentage-Error,MAPE)[12]、R2[13]评测指标对预测模型的精度评价:
(1)RMSD指标
(2)MAPE指标
该指标数值越低,说明预测精度越高。
(3)R2指标
4.3 实验结果分析
(1)预测分析。本文随机选取了150 个电力负荷数据在不同模型下的预测结果和真实数据进行对比,结果如图9 所示,各模型的预测指标见表1 所列。

表1 不同预测模型的测评指标对比
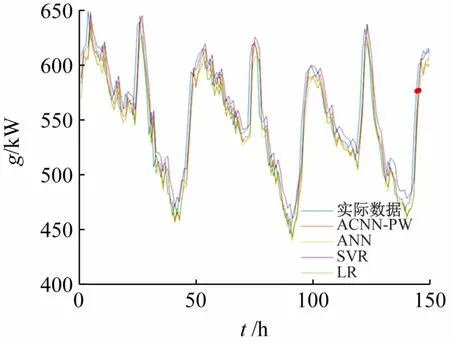
图9 不同模型的电力负荷预测结果对比
由图9 可知,各模型均能对电力负荷变化进行有效的预测;由表1可见,所提出的ACNN-PW预测模型在RMSD和MAPE指标上均低于其他模型的值,并且其R2=0.9582,相比与其他模型的指标值更加接近于1,说明本文提出的ACNN-PW 模型相比于ANN、SVR和LR 预测模型能获得更高的预测精度。本文将ACNN-PW模型自适应分类的数据进行可视化,如图10 所示。图中,ACNN-PW 模型对爬升和下降类型数据分类准确。因此模型在预测时能很好地将2 类数据调度到对应的预测神经网络中进行处理。

图10 ACNN-PW模型自适应分类的数据可视化示意
(2)有效性分析。为进一步验证一阶梯度特征的有效性,本文随机提取了ACNN-PW 模型在预测过程中分类神经网络的分类结果(见图10),Spark 并行处理(10 000 个数据点)的指标对比结果见表2 所列。由图10 可知,一阶梯度可以有效利用一阶梯度特征引导基于Spark的无监督机器学习K-Means算法[14]对训练数据集进行分类学和标注,表明对分类神经网络和预测神经进行训练的有效,因此,分类神经网络对输入的电力负荷数据能有效进行分类,验证了本文的理论的设计部分;由表2 可见,采用单一服务算力对于海量电力负载数据进行预测,处理时间为2 s,而采用Spark云平台进行处理,处理时间随着计算节点的增多而减少,即提高了数据数据处理的吞吐量。由此,当电力负载数据进一步增加时,单计算服务器难以保证对电力负载预测处理的算力要求,而Spark 云平台可灵活更加电力负载数据的容量进行弹性伸缩,从而保证算力的需求。

表2 Spark并行处理的指标对比(10 000 个数据点)
5 结 语
本文针对电力负荷,在Spark 云平台上提出了一种自适应分类电力负荷分类预测神经网络模型,该模型可以自适应的将电力负荷分为爬升和下降2 种类型,并将对应的类型的电力负荷数据送入到相应的人工神经网络预测模型进行预测以提高预测精度。同时,为了避免训练过程中对于训练数据人工按照爬升和下降类型分类造成成本问题,本文采用一阶梯度特征和无监督K-Means机器学习算法能自动地完成对训练数据的分类和标注。最后,实验结果表明,本文提出的电力负荷预测模型能相比于其他的预测,能进一步提高预测精度。
