基于文本挖掘的软件漏洞信息知识图谱构建方法
2023-08-21行久红牛保民
行久红 牛保民


摘要:针对现阶段互联网软件中存在的漏洞问题,文章提出了基于文本挖掘的软件漏洞信息知识图谱构建方法。先确定软件漏洞信息知识图谱构建的基本架构,应用文本挖掘技术,完成软件漏洞信息的采集、预处理与特征提取,然后设计本体模型,完成软件漏洞信息的抽取与融合,最后设计存储机制,构建软件漏洞信息知识图谱。实验结果表明,文章所构建知识图谱的软件漏洞信息完整度均值为93.6%,构建所需时间均值为1.52 s,均优于对比方法,具有较好的应用价值。
关键词:文本挖掘技术;互联网技术;软件漏洞信息;构建知识图谱
中图分类号:TP751 文献标志码:A
0 引言
随着科技的发展,互联网技术、通信技术等广泛应用,给人民生活、生产带来了便利[1],但也带来了一定危机。目前,网络安全问题已经成为人民最为重视的问题,信息安全漏洞严重威胁个人隐私和财产安全,如不及时处理将会给人民造成经济财产损失[2]。因此,如何高效地排查软件漏洞成为互联网技术领域重点研究的课题之一[3]。知识图谱可以通过抽取知识融合与分析计算,得到整体描述并挖掘隐藏内涵[4],可将其应用其中,提升软件漏洞的排查效果。基于此,本文研究了基于文本挖掘技术的软件漏洞信息知识图谱构建方法,旨在提高网络安全管理工作的可靠性,维护网络信息安全。
1 确定软件漏洞信息知识图谱构建的基本架构
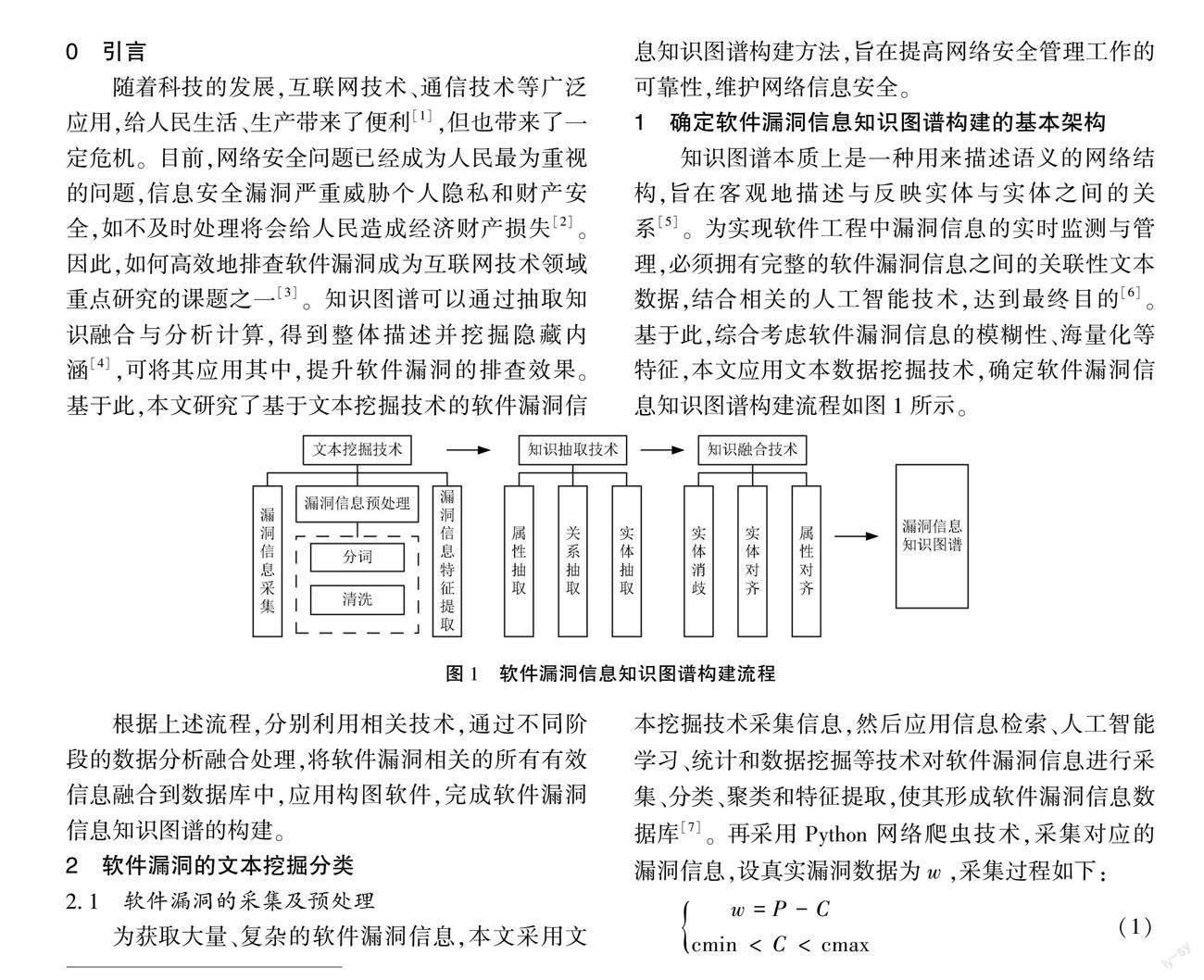
知识图谱本质上是一种用来描述语义的网络结构,旨在客观地描述与反映实体与实体之间的关系[5]。为实现软件工程中漏洞信息的实时监测与管理,必须拥有完整的软件漏洞信息之间的关联性文本数据,结合相关的人工智能技术,达到最终目的[6]。基于此,综合考虑软件漏洞信息的模糊性、海量化等特征,本文应用文本数据挖掘技术,确定软件漏洞信息知识图谱构建流程如图1所示。
图1 软件漏洞信息知识图谱构建流程
根据上述流程,分别利用相关技术,通过不同阶段的数据分析融合处理,将软件漏洞相关的所有有效信息融合到数据库中,应用构图软件,完成软件漏洞信息知识图谱的构建。
2 软件漏洞的文本挖掘分类
2.1 软件漏洞的采集及预处理
为获取大量、复杂的软件漏洞信息,本文采用文本挖掘技术采集信息,然后应用信息检索、人工智能学习、统计和数据挖掘等技术对软件漏洞信息进行采集、分类、聚类和特征提取,使其形成软件漏洞信息数据库[7]。再采用Python网络爬虫技术,采集对应的漏洞信息,设真实漏洞数据为w,采集过程如下:
w=P-C
cmin 式(1)中,C为爬虫检索出的非有效信息,cmin为漏洞最小信息数据载量,cmax为漏洞最大信息数据载量,P为全部采集信息数据。得到的真实漏洞数据在于中国国家漏洞数据库中相关的安全漏洞信息核实,并存储備用。软件漏洞信息知识图谱包括软件信息、漏洞信息、PoC信息以及补丁信息等,需要进行预处理,如分词和清洗等提高数据信息的有效性,以此来提高构建知识图谱的准确率和效率。 2.2 软件漏洞的特征提取 为统一软件漏洞向量映射的维度,使不同长度大小、不同文本数量、不同计量单位的软件漏洞信息具有相同维度的向量表示,提高软件漏洞信息分类的准确性,本文应用文本挖掘技术中的信息增益算法,对软件漏洞信息的特征信号进行分类与提取[8]。根据自然语义的漏洞信息转化为数学向量形式的公式为 U=∑wi=1(ψi/σ)(2) 式(2)中,U表示转化后的自然语义下的漏洞信息,i表示漏洞信息的特征提取条件,ψ表示特征提取条件下的总数据,σ表示特征提取条件外的非定于数据。以此为基础,将其转化后,根据每段漏洞信息数学向量的出现次数确定该漏洞在整体信息集合中的权重值,提取出软件漏洞信息的特征信号,便于后续知识图谱的构建。 3 构建软件漏洞信息知识图谱 3.1 设计软件漏洞的本体模型 为表述与反映不同软件漏洞信息之间的关联性,结合文本挖掘技术设计软件漏洞的本体模型ω,模型的目标函数表示为: ω={A,E,G,F,H,T,W,Y}(3) 式(3)中,A表示软件漏洞名称;E表示软件属性;G表示情报信息;F表示评价标准;H表示PoC;T表示补丁;W表示数据当量值;Y表示模型承载量。将上述本体模型中的信息抽取出来,并建立关联性,以此来实现软件信息知识图谱的构建。 3.2 抽取软件漏洞信息 为提高软件漏洞信息知识图谱构建的可靠程度和效率[9],需要进行实体识别和抽取,过程如下: F1(α)=∑ni∈n,j∈n,i≠j(αi-αj)2(4) 式(4)中,α表示抽取中限制参数,F1表示识别出的抽取数据,i,j表示漏洞信息知识图谱对应的漏洞信息起始数据和终止数据,n表示实际抽取数量。实体抽取技术使用基于规则和词典的方法,可识别并抽取出软件漏洞信息中的七大类实体数据;关系抽取技术可通过使用统计、规则和分类器等方法从软件漏洞信息中提取实体之间的内在关系。针对软件漏洞的本体模型实体属性的抽取,需要应用卷积神经网络算法进行分类和训练[10]。 3.3 软件漏洞信息的数据融合 在软件漏洞信息的处理中,可能存在错误、冗余信息和逻辑模糊等问题,这会影响软件漏洞信息知识图谱构建的准确性和可靠性。为解决以上问题,本文采用实体消歧技术,将具有歧义命名的实体映射到具体的概念,然后进行数据融合,过程如下: I=θ{(β+ε+η)λ}(5) 式(5)中,I表示融合后软件漏洞数据,θ表示融合指标,β表示融合数据模式,ε表示融合工具,λ表示融合参量的权值,η表示现有的漏洞信息数据。这种融合方式可有效降低信息中的逻辑模糊和层次不匹配现象,并实现数据融合。通过概率统计和图像排序方法,实现软件漏洞信息实体链接的消歧与对齐,使漏洞信息更具体化,同时筛除冗余信息以提高准确度。该步骤能够有效提高软件漏洞信息知识图谱构建的准确性和可靠性。 3.4 数据的存储与知识图谱的构建 为使海量化的软件漏洞信息全面地、动态化地展示在同一图谱中,本文应用Neo4j图数据库存储软件漏洞信息,结合可视化技术,完成基于文本挖掘技术的软件漏洞信息知识图谱的构建,过程如下: B=(1-y)×L×R(6) 式(6)中,B表示信息知识图谱表示当量(CVE-2022-N),y表示数据挖掘方向,表示重叠度,L表示知识图谱像元,R表示知识图谱内存量。其中信息知识图谱表示当量CVE-2022-N表示中国国家漏洞数据库中的软件漏洞信息及其编号。根据上述软件漏洞信息的本体模型,并通过相关的处理操作,构成对应的软件漏洞知识图谱,充分地为后续相关的软件漏洞安全管理工作奠定良好的数据基础。 4 测试与分析 4.1 试验准备 为检测本文设计的基于文本挖掘的软件漏洞信息知识图谱构建方法的可行性与应用效果,结合其它方法,本文设计了仿真模拟对比试验。试验在JAVA语言编程环境下搭建,搭建参数如表1所示。 将中国国家漏洞数据库中的软件漏洞信息作为测试样本数据,存储在数字数据库与图像数据库中。 4.2 漏洞信息知识图谱的完整度检测 记录不同方法构建知识图谱中收录漏洞数量的大小,与实际有效漏洞数量进行对比分析,计算完整度,结果如图2所示。 由图2可知,对于随机选取10组大小、漏洞种类均不同的数据组,试验组方法融合并构建的知识图谱软件漏洞信息的完整度高于对照组1、对照组2。试验组方法构建的知识图谱信息完整度均值为93.6%,分别比对照组1、对照组2高28.4%、13.8%,有效提高了对软件漏洞有效信息采集与存储的覆盖范围。 4.4 漏洞信息处理效率检测 记录不同方法从采集漏洞信息到完成知识图谱构建所用时间,对比结果如图3所示。 由图3可知,通过对10组随机选取的不同大小和漏洞种类的数据组进行试验组方法的数据处理,发现试验组知识图谱构建时间均低于对照组1和对照组2。试验组方法平均构建时间为1.52 s,比对照组1和2分别快6.02 s和4.11 s。这说明本文设计的软件漏洞信息知识图谱构建方法具有高效和实时的特点,能够准确而快速地完成漏洞信息的采集和预处理,为软件工程项目的安全管理提供可靠的数据基础和依据。 5 结语 随着科学技术与互联网技术的大范围应用,相关的软件漏洞也层出不穷,对用户的信息安全与个人财产造成了较为严重影响。在此背景下,本文通过应用文本挖掘技术,充分结合现代化技术手段,构建完整、精准的软件漏洞信息知识图谱,为软件工程安全管理与防御系统的智能化运行提供数据基础。本文所提方法构建时间较短、信息完整度更强,可有效保证软件工程项目运营过程中的安全性与可靠性,为我国网络科技市场结构的长久稳定发展,奠定良好基础。 参考文献 [1]郭军军,王乐,王正源,等.软件安全漏洞知识图谱构建方法[J].计算机工程与设计,2022(8):2137-2145. [2]张瑞,王晓菲.基于混合深度学习模型的软件漏洞检测方法[J].电脑知识与技术,2021(18):72-73. [3]彭佳玲,周茂林,杨青.公众对上门护理服务的态度和关注点:基于网络爬虫的文本挖掘[J].护理学杂志,2023(5):110-113,116. [4]周洁,夏换.基于文本挖掘的微博用户健康信息关注热点研究[J].新媒体研究,2023(2):102-106. [5]孙宝生,敖长林,王菁霞,等.基于网络文本挖掘的生态旅游满意度评价研究[J].运筹与管理,2022(12):165-172. [6]梁俊毅,陈静.基于双向LSTM的软件漏洞自动识别方法研究[J].信息与电脑(理论版),2021(8):174-176. [7]蔡敏.基于混合深度学习模型的网络服务软件漏洞挖掘方法[J].宁夏师范学院学报,2020(7):73-79. [8]王晓辉,宋学坤.基于知识图谱的网络安全漏洞类型关联分析系统设计[J].电子设计工程,2021(17):85-89. [9]刘存,李晋.安卓平台软件漏洞挖掘与分析技术浅析[J].保密科学技术,2020(2):33-38. [10]陶耀东,贾新桐,吴云坤.一种基于知识图谱的工业互联网安全漏洞研究方法[J].信息技术与网络安全,2020(1):6-13,18. (編辑 李春燕) Construction method of knowledge graph of software vulnerability information based on text mining Xing Jiuhong, Niu Baomin (School of Big Data and Artificial Intelligence, Zhengzhou University of Science and Technology, Zhengzhou 450064, China) Abstract: A method for constructing a knowledge graph of software vulnerability information based on text mining is proposed to address the vulnerability issues in current internet software. Firstly, the basic architecture for constructing a knowledge graph of software vulnerability information is determined, and text mining technology is applied to complete the collection, preprocessing, and feature extraction of software vulnerability information. Then, an ontology model is designed to complete the extraction and fusion of software vulnerability information. Finally, a storage mechanism is designed to construct a knowledge graph of software vulnerability information. The experimental results show that the average integrity of software vulnerability information in the constructed knowledge graph is 93.6%, and the average construction time is 1.52 seconds, both of which are superior to the comparison method and have good application value. Key words: text mining technology; Internet technology; software vulnerability information; construction of knowledge graph
