基于改进YOLOv7 模型的复杂环境下鸭蛋识别定位
2023-08-15祝志慧何昱廷李沃霖蔡紫荆王巧华马美湖
祝志慧 ,何昱廷 ,李沃霖 ,蔡紫荆 ,王巧华 ,马美湖
(1. 华中农业大学工学院,武汉 430070;2. 农业部长江中下游农业装备重点实验室,武汉 430070;3. 华中农业大学食品科学技术学院,武汉 430070)
0 引 言
中国是世界上最大的水禽生产与消费国,其中,鸭的饲养量占中国水禽饲养量70%以上。2021 年中国蛋鸭存栏1.5 亿只,鸭蛋产量277.6 万t,总产值352.2 亿元,较2020 年上涨37.1%[1-3],然而,中国蛋鸭养殖总体呈“小规模、大群体”的特点[4],巡检和捡蛋均依赖人工,劳动强度大、人工成本高、工作环境差。故迫切需要一种可以代替人工,在鸭场进行鸭蛋拾取的机器人。开发鸭蛋拾取机器人的关键技术,是使其能够在不同干扰、遮挡覆盖等复杂环境下,对鸭蛋进行快速、准确检测和定位。
研究表明,对于目标重叠、遮挡等复杂环境导致的识别困难问题,深度学习因其较高的鲁棒性、普适性,能够很好地解决[5-9]。特别是YOLO(you only look once)模型,可根据待检测目标特征和应用场景做出改进,以提高模型性能[10-16]。
目前,尚未有对禽舍中鸭蛋自动识别的报道,但是针对番茄花果、芒果、火龙果、苹果、柑橘等类椭圆的农产品,已有学者提出在遮挡重叠等复杂环境的检测方法。吕志远等[17]采用组合增强的YOLOX-ViT 对番茄花果进行识别,引入图像组合增强与前端ViT 分类网络,得到平均识别率均值为92.3%的模型。ROY 等[18]在检测芒果时,将DenseNet 加入骨干网络,优化模型特征提取,使得检测平均精度达96.2%。龚惟新等[19]为实现对猕猴桃花朵的快速准确检测,提出基于改进YOLOv5s 的猕猴桃花朵检测模型,改进模型的检测精确率为85.21%。王金鹏等[20]为检测复杂自然环境下多种生长姿态的火龙果,基于YOLOv7 模型提出一种多姿态火龙果检测方法,其检测准确率达83.6%。周桂红等[21]为解决苹果果园密植栽培模式,果树之间相互遮挡导致苹果果实识别效果差的问题,提出一种基于改进YOLOv4 和基于阈值的边界框匹配合并算法的全景图像苹果识别方法,改进后的YOLOv4 网络模型识别精确率达到96.19%。刘洁等[22]提出一种便于迁移与部署的改进YOLOv4 模型,实现对橙果的检测,识别平均精度达97.24%,为橙果在复杂场景下采摘提供新的思路。杨坚等[23]提出基于改进YOLOv4-tiny 模型,将卷积注意力模块集成到网络中,以提高被遮挡番茄的识别准确率,平均精度值达97.9%。XU 等[24]提出一种改进的Mask R-CNN 模型,用于对番茄目标的检测,准确率达93.76%。这些方法为鸭蛋识别与定位提供了参考。
鸭场环境复杂恶劣,常有泥土、秸秆等遮挡鸭蛋,同时亦有大量颜色相近的鸭羽覆盖,易造成簇拥、重叠、遮挡等现象,目标检测难度大。因此在识别过程中需要考虑以下几个方面的问题:1)鸭蛋形态的差异性,鸭蛋的形状和大小变化较小,因此在目标重叠和遮挡的情况下,较难通过目标的外形信息来进行区分;2)鸭蛋表面的异质性,鸭蛋往往会因其表面纹理的差异,同时受到光照、阴影等因素的影响,导致图像中的鸭蛋出现亮度和颜色变化,进而影响识别结果;3)鸭蛋背景的复杂性,鸭蛋识别的背景往往比较复杂,存在秸秆和稻壳、分隔网栅、鸭子等干扰信息,使得背景中的纹理和颜色等信息与鸭蛋的信息混淆,干扰识别的准确性。由于上述差异,现有的目标识别策略难以直接应用于鸭蛋识别领域。为解决这些问题,本文拟采用YOLOv7 模型作为目标检测方法并针对鸭蛋识别场景进行专门研究和算法优化。
针对鸭蛋形状和大小变化较小,环境及背景复杂,存在较多干扰信息等问题,本文在主干网络加入卷积注意力模块(CBAM,convolutional block attention module),加强网络信息传递,提高模型对特征的敏感程度,减少复杂环境对鸭蛋识别干扰。同时,在特征提取网络之后引入优化的空间金字塔池化结构(SPP,spatial pyramid pooling),将原本分支并行的SPP 结构调整为串联传递,在实现鸭蛋目标特征增强的同时,降低一定运算成本。最后,为更好地将模型部署到机器人上构建鸭蛋识别系统,利用深度可分离卷积(DSC,depthwise separable convolution)降低模型参数数量和运算成本,以期实现在复杂环境下,鸭蛋的快速精准识别定位,为复杂环境中鸭蛋拾取机器人的智能化精准识别提供一定的技术指导。
1 材料与方法
1.1 数据材料
1.1.1 数据采集与预处理
试验材料为购自河南商丘的樱桃谷白壳鸭蛋。为搭建鸭蛋图像采集平台,使用羽毛、秸秆、泥沙等材料,模拟鸭舍的复杂环境。同时,于武汉余家湾种鸭养殖厂采集实际场景鸭蛋图像。模拟场景和实际场景的鸭蛋图像采集均使用荣耀HLK-AL10 型相机。为保证检测模型的鲁棒性和精确性,所得数据中包括多角度、多位置、不同距离、不同遮挡形式的鸭蛋图像,如图1 所示。共采集分辨率为4 000× 3 000 像素的JPG 格式图像2 600 张。

图1 鸭蛋数据图Fig.1 Duck-eggs data image
使用Make Sense 软件,对鸭蛋图像进行标注,得到包含鸭蛋中心点坐标(x,y),标注框宽度、高度(w,h)信息的txt 文件。本文在标注过程中,只将图像分为鸭蛋目标和背景两类。由于本文仅进行鸭蛋目标检测,故仅需标注鸭蛋,图像其他部分由Make Sense 自动标注为背景。
对原始图像采取数据增强的方法,增加模型训练的数据量,防止模型出现过拟合,泛化性差等问题[25-26]。常用数据增强方法包括:旋转、翻转、平移、裁剪、引入噪声、调节亮度等[27]。本文选择对原始图像添加12%的高斯噪声、2.5%的椒盐噪声,通过增加冗余信息,降低图像平滑性,加入噪声前后的对比图像如图2a、2b、2c 所示。同时,为模拟鸭场的昏暗环境,在RGB 通道利用转换公式:

图2 鸭蛋数据增强Fig.2 Duck-eggs data enhancement
式中g(i,j)为转换后图像像素灰度;f(i,j)为原始图像像素灰度;a为图像增益;b为图像偏置。
分别设置a=0.5,b=10;a=0.3,b=10;使得原始图像亮度降低,有利于提升检测模型的鲁棒性。转换前后图像对比分别如图2 d、2e、2f 所示。并且,在训练过程中,使用Mosaic 方法[28],将多张图像随机裁剪并拼接,丰富待检测物体的背景,该方法能有效提升模型抗扰动能力[29],其拼接结果如图2 g 所示。
1.1.2 数据集划分
对采集的原始图像数据(2 600 张)按照6:2:2 划分为训练集(1 560 张)、验证集(520 张)、测试集(520 张)。为丰富现有训练集数据信息,防止模型出现过拟合等问题,对训练集样本使用如下数据增强方法:1)添加12%的高斯噪声。2)添加2.5%的椒盐噪声。3)设置图像增益a=0.3 及a=0.5,改变图像亮度。经数据增强后,共得训练集数据7 800 张,同时为保证模型的准确性和环境适应性,训练集中包含各类影响识别的图像,具体分类见表1。图像中鸭蛋目标数量为1~5 个时属于稀疏分布,6~10 个时属于中等密集分布,10 个以上时属于簇拥分布。同时,表中每一类图像,都分别经过添加噪声(12%高斯噪声、2.5%椒盐噪声)、降低亮度处理(设置图像增益a=0.3、a=0.5)。

表1 训练集分类Table 1 Classification of train set
经过数据增强处理,结合所标注的原始样本数据,共得8 840 张图像。其中训练集为7 800 张,验证集为520 张,测试集为520 张。
1.1.3 试验平台
本文对鸭蛋检测模型的训练和测试,均在同一环境下运行。硬件配置及软件环境如表2 所示。
表2 试验平台环境Table 2 Experiment bed environment
1.2 检测方法
1.2.1 YOLOv7 目标检测模型
YOLOv7 模型框架主要由输入端、主干网络、特征融合、预测头4 个模块组成,是WANG 等[30]为更好实现实时目标检测,研究更适配边缘设备及云端的算法,在YOLOv4、YOLOv5 等的基础上于2022 年提出。YOLOv7 模型作为单阶段目标检测算法,可以通过直接回归的方式一次处理并获得对应物体的目标区域、位置及类别,相较于两阶段目标检测算法,有着检测速度快的优点,能较好地平衡速度和精度,为实现实时鸭场中复杂环境下鸭蛋识别定位奠定了基础[31]。
1.2.2 模型改进方法
为使模型学习到局部和全局信息,并在提高识别鸭蛋精度和速度的同时,减少漏检和错检,本文在YOLOv7模型的基础上,提出一种融合CBAM、DSC 及优化空间金字塔池化结构的改进YOLOv7 模型(YOLOv7_CDS),改进的模型结构如图3 所示。
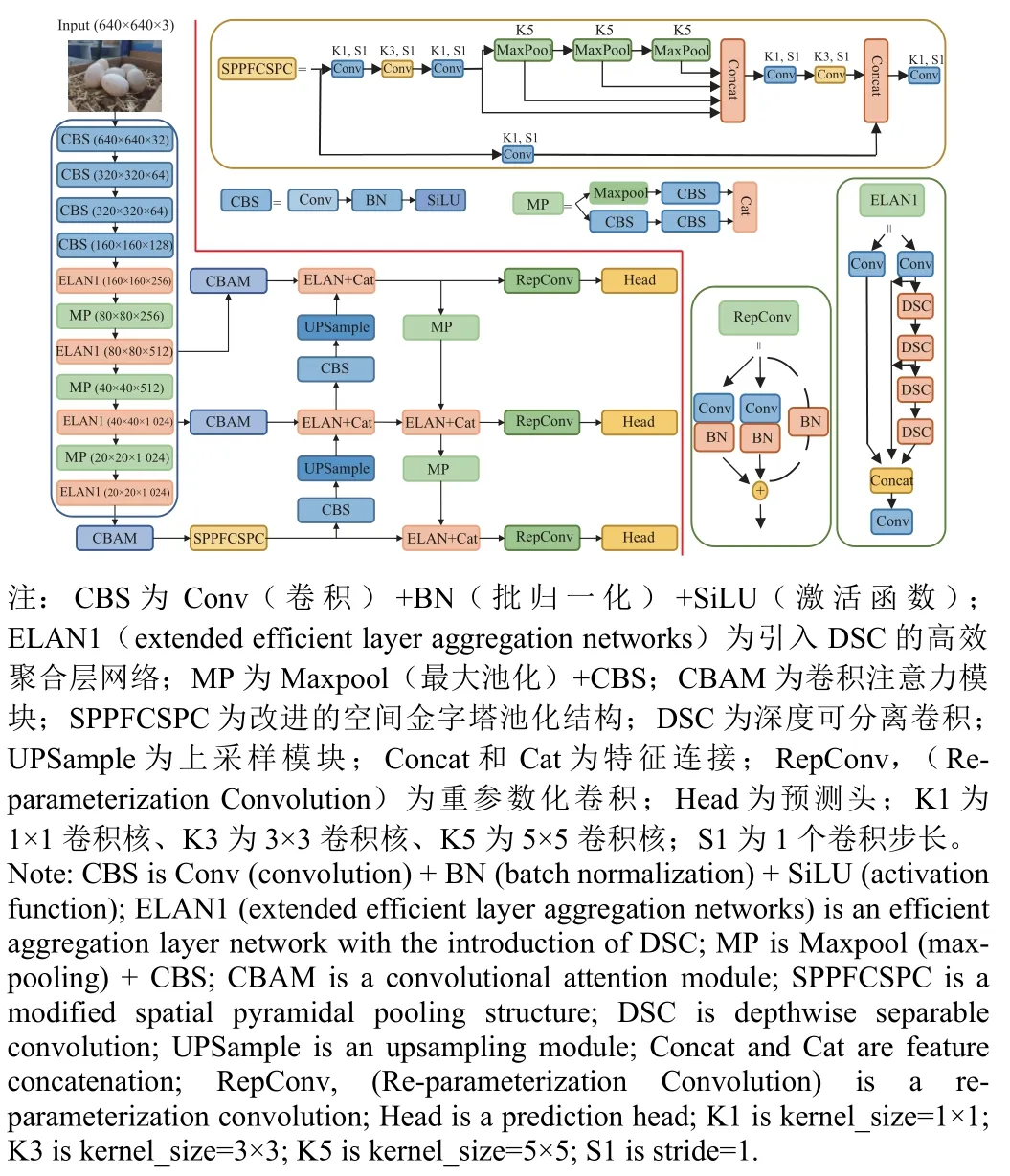
图3 改进模型整体结构Fig.3 Structure of improved model
从以下3 个方面进行改进:
1)卷积注意力模块
鸭场中,因为光照、遮挡以及背景(秸秆和稻壳、鸭子)等因素,导致图片中干扰信息与鸭蛋特征信息混淆,影响识别的准确性,出现漏检和错检,故为进一步解决复杂环境中环境信息对于鸭蛋特征提取的干扰问题,本文在YOLOv7 主干网络中引入CBAM 结构,包含通道注意力、空间注意力2 个模块[32]。在原网络提取特征后,利用CBAM 进行通道注意力和空间注意力模块的串联,对原有的鸭蛋特征图进行信息提炼,提升模型在主干网络中对特征提取的准确性[33-34]。
CBAM 的通道注意力模块,对输入的特征图(Feature map),分别进行全局平均池化和全局最大池化,得到新的特征图,接着通过σ函数得到权重系数,权重系数与新的特征图相乘,最终得到输出特征图,其计算方法如式(2)。
空间注意力模块,将通道注意力模块输出的特征图作为输入,进行最大池化和平均池化后在通道维度拼接,接着经过卷积降为一个通道,并通过σ函数生成空间权重系数,将输入特征图与权重相乘,即得到输出的特征图,其计算方法如式(3)所示。
式中Mc为通道注意力图,Ms为空间注意力图;Fm为输入特征图;σ为Sigmoid 函数;f7×7为7×7 卷积;MLP为Multilayer Perceptron 神经网络。
CBAM 中两个模块的串联较好地解决了SE(squeezeand-excitation)和ECA(efficient channel attention)仅关注通道信息的问题。如表3 为YOLOv7 模型分别引入CBAM、SE 和ECA 注意力机制后的检测性能对比,由表知,YOLOv7+CBAM 的F1 分数分别高出YOLOv7、YOLOv7+SE 和YOLOv7+ECA 模型5.1、3.3 和2.4 个百分点。CBAM 通过串联通道和空间模块给予鸭蛋特征更多的关注,使得模型提取的特征指向性更强,对鸭蛋识别任务更具优越性。图4 展示了模型引入CBAM 模块的位置。
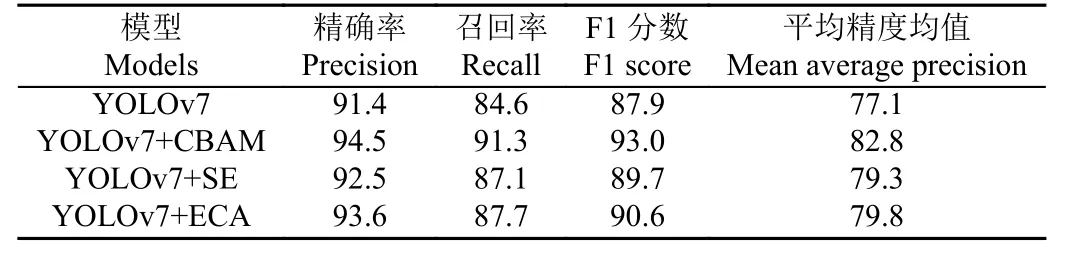
表3 模型引入不同注意力机制的检测性能Table 3 Detection performance of models introducing different attention mechanisms%
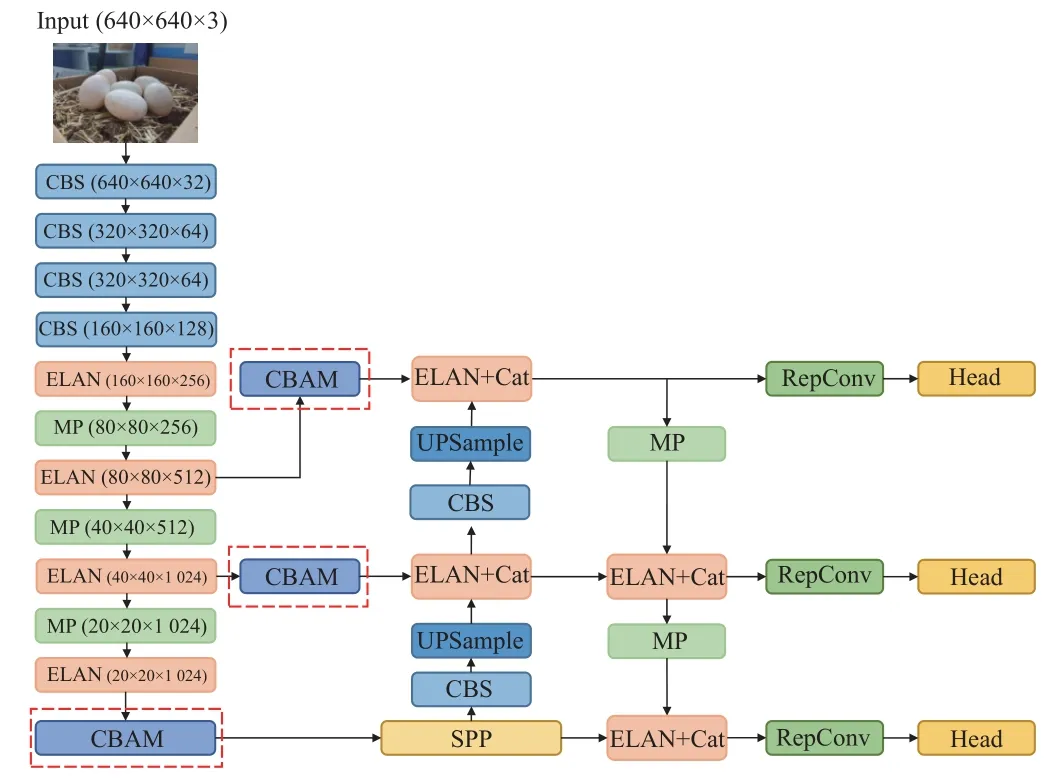
图4 CBAM 改进位置Fig.4 CBAM improves position
2)深度可分离卷积网络
实现鸭蛋的准确识别定位是鸭蛋拾取机器人的关键技术,需要考虑嵌入式设备的内存及算力限制。在保证良好检测精度的前提下,对模型运算量及大小进行一定压缩,提高其对嵌入式设备的适用性。本文在YOLOv7模型的ELAN 结构中将3×3 的卷积层替换为深度可分离卷积(DSC,depthwise separable convolution),使得网络在保证原有信息传递的情况下,减少一定的浮点运算量及模型大小。图5 和表4 为深度可分离卷积应用的具体位置。
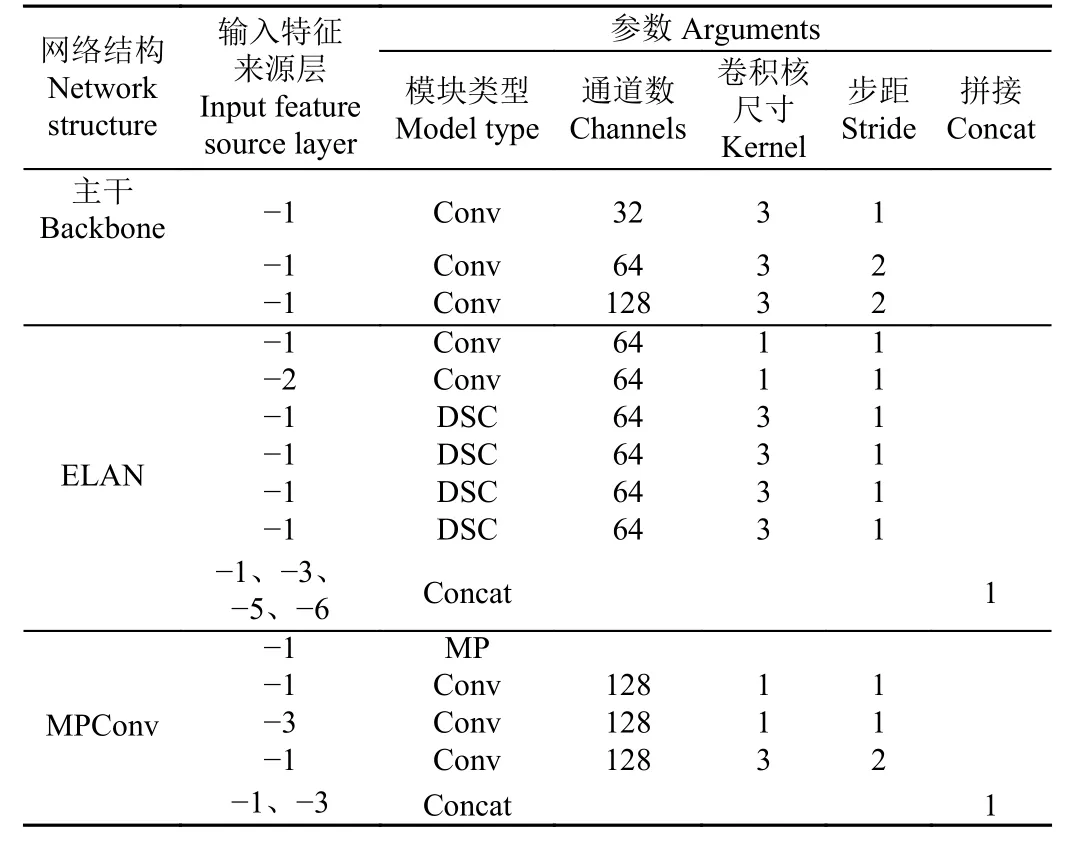
表4 主干网络中深度可分离卷积位置Table 4 Depthwise separable convolution positions in backbone
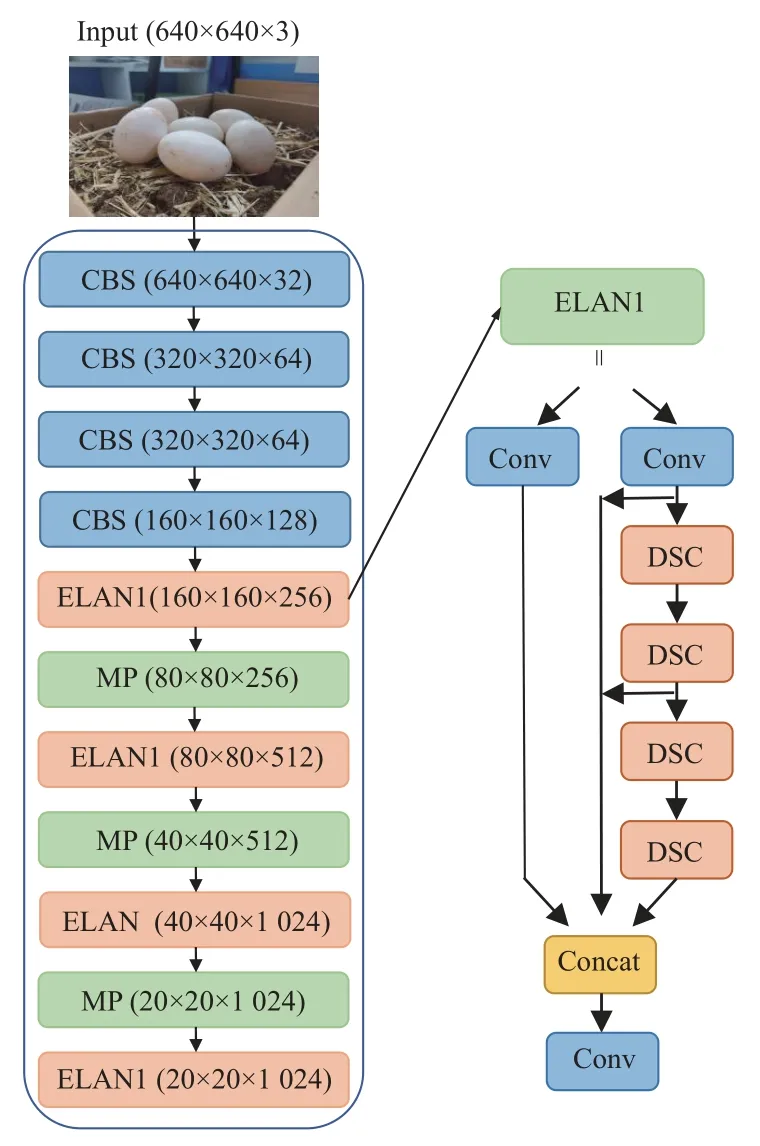
图5 深度可分离卷积改进位置Fig.5 Depthwise separable convolution improves position
DSC 于2018 年由SANDLER 等[35]提出,其浮点预算量(FLOPs,floating point operations per second)计算如式(4)。对比标准卷积浮点运算量[36],计算如式(5)。
式中Ci、Co分别为输入、输出通道数,K为卷积核大小,Ho、Wo分别为输出特征图高度、宽度。二者浮点运算量之比为:+,当Co为4,K为3时,深度可分离卷积浮点运算量减少约。
3)空间金字塔池化结构
空间金字塔池化结构(SPP,spatial pyramid pooling)由HE 等[37]提出。该结构能够提高全局感受野,减少对空间信息的依赖,帮助模型在复杂环境中分离出鸭蛋和背景,通过捕捉不同尺度的鸭蛋信息,较好地解决视场较大、遮挡较多时,鸭蛋远近不一、大小不一的问题,提升模型采集有效特征的能力,增强模型对小目标的检测能力。本文借鉴快速空间金字塔池化结构(SPPF,spatial pyramid pooling - fast)思想[38],在原YOLOv7 模型中引入改进的空间金字塔池化结构,改进前后的结构分别如图6a、6b 所示。
原空间金字塔池化结构采用分支并行的方式进行不同尺度(5×5、9×9、13×13)的最大池化,并Concat 堆叠通道。本文改进的结构采用串联3 个相同尺度(5×5)的最大池化的方法,将每一个最大池化的输出进行通道堆叠。若输入特征尺寸为16×16,串联的2 个5×5 的最大池化可以等效于1 个9×9 的最大池化,二者均输出尺寸为8×8 的特征。同理,串联的3 个5×5 的最大池化可以等效于1 个13×13 的最大池化。并且,池化尺度越大所需的计算成本越大[39],故对其采用统一尺度串联的方式,充分利用每个池化的输出,使得模型能在保持原有优点的基础上,提升检测效率。
1.2.3 模型评价指标
为检验训练好的模型,是否适用于复杂环境下鸭蛋的实时检测,本文将从检测精度和检测速度两方面的指标进行评价。
1)模型精度指标:精确度(Precision),评估模型预测是否准确,计算式如(6)所示;召回率(Recall),评估模型检测出目标数据的能力,计算式如(7)所示;F1 分数(F1 score)是精确度与召回率的调和平均,是避免精确度或召回率出现单一极大值,用于综合反映整体的指标,计算式如(8)所示;平均精度均值(mAP,mean average precision)是衡量预测目标位置及类别算法的指标,对目标检测模型评估有着一定意义。
式中TP为鸭蛋被正确识别的数量;FP为将其他物体识别为鸭蛋的数量,即错检;FN为没有正确识别出鸭蛋的数量,即漏检。
2)模型速度指标:将模型检测1 张图片的平均用时,作为衡量模型速度指标。同时,利用浮点运算量(FLOPs,floating point operations per second)、模型占内存空间大小两个指标,来衡量模型部署于嵌入式设备的能力。
本文需要在鸭场复杂环境中实现鸭蛋检测,为区别于其他目标检测任务,本文将对模型在检测中出现的结果进行定义与说明。1)漏检:鸭蛋存在,但模型将其识别为背景,未输出检测框。2)误检:①将背景识别为鸭蛋;②将n个粘连的鸭蛋识别为1 个鸭蛋,记为误检n个鸭蛋。另外,模型输出大小正确的单个检测框,且检测框内只存在被鸭羽覆盖的单个鸭蛋,该情况对鸭蛋拾取机器人的拾取过程影响较小,故不将该情况记为漏检或误检。
1.2.4 模型训练参数
输入图片尺寸640× 640 像素,迭代次数150 轮,训练批次(batch_size)设置为8。为使模型同时满足“快”和“优”,并且防止过拟合,设置初始学习率为0.01,学习退火参数为0.1,训练过程中,模型学习率从0.01呈余弦变化衰退至0.001。此外,模型训练过程中使用YOLOv7.pt 预训练权重文件。
2 结果与分析
2.1 消融试验结果
使用相同数据集进行训练和测试,利用各改进方法做消融试验,得到消融试验结果如表5 所示,其中使用CBAM 模块进行改进的模型记为YOLOv7_C,使用DSC 模块进行改进的模型记为YOLOv7_D,使用优化后的空间金字塔池化结构改进的记为YOLOv7_S,组合改进命名以此类推。从表5 可以看出,经过CBAM 模块对通道和空间两个维度的优化,模型提取待检测目标特征能力有所加强,如模型YOLOv7_C 相较YOLOv7 模型,F1分数提高5.1 个百分点;同时,在mAP 上,相较于YOLOv7模型,YOLOv7_C 提升了5.7 个百分点,YOLOv7_CD提升了6.2 个百分点,YOLOv7_CS 提升了7.3 个百分点,YOLOv7_CDS 提升了8.1 个百分点。由表5 可以看出,相比于YOLOv7 原始模型,单独采用深度可分离卷积、单独采用空间金字塔池化进行改进的方法,在F1 分数上提升分别为1.2 个百分点和2.5 个百分点,在mAP 上提升分别为1.8 个百分点和4 个百分点,说明单独应用一种优化方法对鸭蛋数据检测性能提升有限。

表5 消融试验结果Table 5 Ablation experiment results
图7 为改进模型的训练损失和验证损失曲线,由图7 可得,经过CBAM 模块的优化,模型的损失振荡减弱,并快速趋于稳定。当单独使用深度可分离卷积、空间金字塔池化进行优化时,仅较轻减弱损失振荡。当与CBAM 进行结合使用后,模型的各指标均得到较大提升。由其损失曲线能直观地反映出,YOLOv7_C、YOLOv7_CD、YOLOv7_CS、YOLOv7_CDS 在训练至50 轮后趋于稳定,且损失降低至一个较低值。说明CBAM 模块、深度可分离卷积和空间金字塔池化结构的结合对鸭蛋的识别定位具有较高效益。
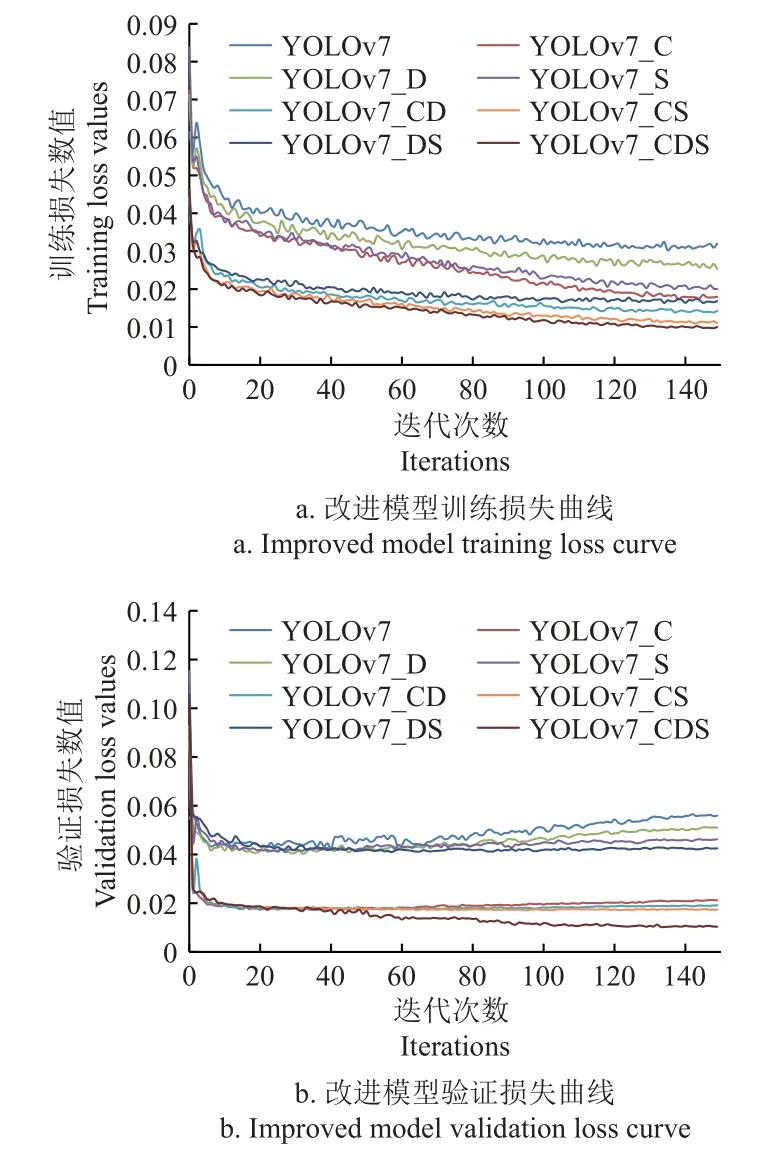
图7 改进模型损失曲线Fig.7 Improved model loss curve
此外,通过调整深度可分离卷积网络、空间金字塔池化结构,YOLOv7_CDS 相较于YOLOv7,模型浮点运算量(FLOPs)减少7.9 G,模型占内存空间大小减少6.1 M。记录各个模型在验证集上的检测时间,将每张图像平均耗时作为模型检测速度,试验结果如表5 所示。对于单张图像,YOLOv7_CDS 模型检测平均耗时0.022 s。试验表明YOLOv7_CDS 模型占空间内存较少,在精度和速度方面具有一定优越性,可部署于鸭蛋拾取机器人的嵌入式设备。
2.2 改进模型检测对比
利用处于不同情况的鸭蛋进一步对比改进模型的实际检测效果。图8 展示了YOLOv7 改进后实际检测效果对比。对于在蛋窝中的堆叠鸭蛋,各模型均无漏检错检,改进的YOLOv7_CDS 模型其平均置信度达95.0%,符合预期。同时,由图8 知,在视场较大、背景干扰较多、情况较复杂时,YOLOv7_CDS 模型检测效果较优。如图中鸭场无遮挡场景所示,YOLOv7_CDS 无错检漏检,平均置信度达83.3%。而YOLOv7 原始模型错将羽毛识别为1 个鸭蛋,并漏检1 个。如图中鸭场复杂环境所示,YOLOv7_CDS 漏检5 个,无错检。YOLOv7 原始模型仅检测出3 个鸭蛋。其余模型实际检测效果均差于YOLOv7_CDS 模型,如YOLOv7_CS 漏检11 个,无错检。试验结果表明,CBAM 较好地抑制干扰,优化模型性能,同时结合深度可分离卷积、空间金字塔池化的优化方法,可以更好地提升模型对鸭蛋的检测性能。

图8 YOLOv7 改进后检测效果对比Fig.8 Comparison of detection effects after improvement of YOLOv7
2.3 不同模型性能对比
将改进的YOLOv7 模型,与目前常用的目标检测模型:SSD、YOLOv4、YOLOv5 进行对比,结果如表6 所示。由表6 可知,YOLOv5_L、YOLOv7_CDS 具有一定优越性,F1 分数都达到95%以上。在F1 分数上,YOLOv7_CDS 高出SSD 模型8.3 个百分点、高出YOLOv4 模型10.1 个百分点、高出YOLOv5_M 模型8.7 个百分点、高出YOLOv7 模型7.6 个百分点,但是低于YOLOv5_L 模型0.4 个百分点。这是由于YOLOv5_L 模型的网络深度和宽度,分别在C3 模块和卷积核数量的影响下,不断加深、扩大,致使其牺牲速度而获得更高精度。由表6 可知,YOLOv5_L 模型平均精度均值(mAP)高出YOLOv7_CDS 模型1.1 个百分点,但YOLOv7_CDS 占空间大小比YOLOv5_L 减少24.1 M。同时,相较于YOLOv5_L,YOLOv7_CDS 单张图像检测平均用时减少0.011 s,在速度上具有一定优越性,更适于部署在鸭蛋拾取机器人的嵌入式设备上。
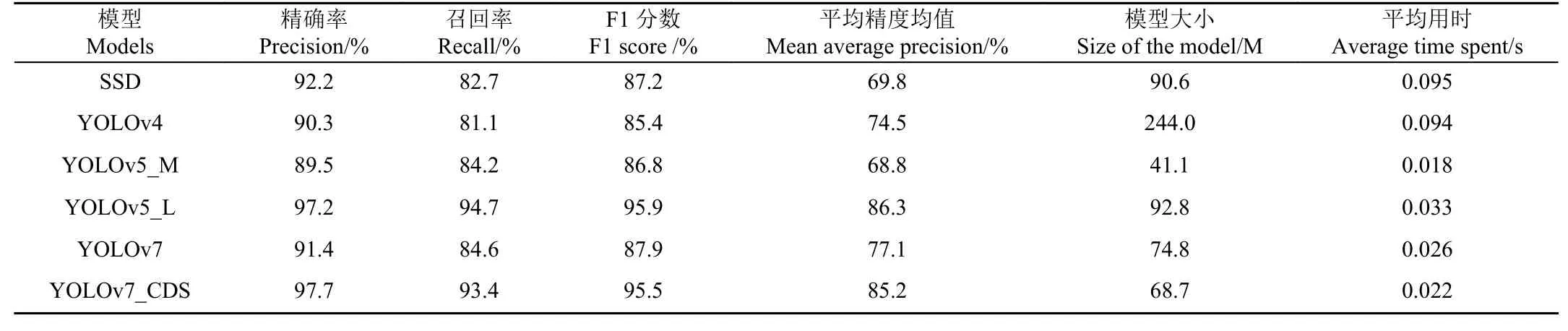
表6 不同模型的检测性能Table 6 Detection performance of different models
2.4 模型检测结果
2.4.1 遮挡目标检测对比
为进一步验证YOLOv7_CDS 模型对解决鸭蛋遮挡问题的能力,将无遮挡、相互遮挡、泥土遮挡、羽毛遮挡4 类图像输入模型。图9 展示了各模型对4 类情况的检测结果。由图9 知,在无遮挡的情况下,各模型均准确检测出6 个目标,并且平均置信度均达到90%及以上。当鸭蛋相互遮挡时,YOLOv4 出现了误检的情况,将背景错误识别为鸭蛋,而其他模型均准确无误地检测出目标。鸭蛋被泥土和粪便遮挡是鸭场中经常出现的情况,对于只有10%~20%可见面积的鸭蛋,由图9 可得,5个模型都准确地检测出被泥土遮挡的鸭蛋,并且平均置信度都达90%以上,较好地解决鸭蛋被遮挡覆盖的检测问题。

图9 不同遮挡情况下各模型检测对比Fig.9 Comparison of different model detection for each obscure situation
鸭子在鸭场中活动时会散落大量鸭羽,鸭羽覆盖在鸭蛋上时,因其颜色相近,造成目标检测困难。图9 展示了各模型在鸭蛋被鸭羽遮挡时的检测能力(为了更清晰地观察检测结果,隐藏图中的鸭蛋标签及置信度)。由图9 可知,SSD 模型漏检5 个鸭蛋,错检2 个;YOLOv4 模型漏检5 个鸭蛋,错检4 个;YOLOv5_M 模型漏检2 个鸭蛋,错检8 个;YOLOv7_CDS 无漏检、错检,以较高的准确率检测出被羽毛遮挡的鸭蛋。表7 为各模型在解决羽毛遮挡问题时,检测性能对比。由表7 可知,改进的模型在无漏检、错检的情况下,有着较高的平均置信度以及较小的空间大小,表明其可以很好地解决羽毛遮挡时鸭蛋检测问题。
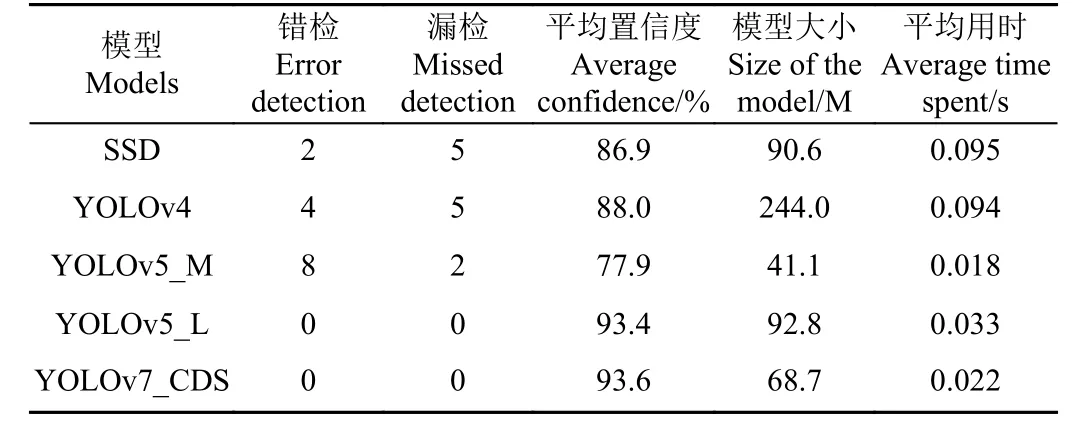
表7 羽毛遮挡情况不同模型检测对比Table 7 Comparison of different models for feather obscuring detection
2.4.2 密集目标检测对比
为检验模型是否可以解决鸭场中鸭蛋密集程度不同导致检测困难的问题,将稀疏、中等密集、簇拥3 类图像输入模型,检测结果如图10 所示。各模型在稀疏和中等密集情况下,对鸭蛋的检测具有很好的适用性。在簇拥情况下,YOLOv5_M、YOLOv4 以及SSD 模型均有较多漏检和误检,无法解决密集目标检测问题。YOLOv5_L与YOLOv7_CDS 检测性能的对比结果见表8。由表8 可知,2 个模型对于簇拥情况的鸭蛋,均无漏检、误检,有较好的适用性。YOLOv7_CDS 平均置信度较YOLOv5_L提高了2.4 个百分点,综合考虑2 个模型的模型大小、检测平均用时和平均置信度,本文提出的YOLOv7_CDS模型更适合部署在鸭蛋拾取机器人上,并为鸭蛋拾取机器人在鸭场中拾取密集分布的鸭蛋提供技术支持。
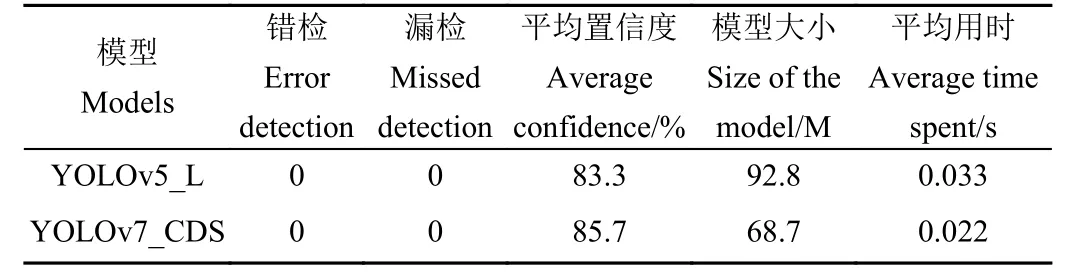
表8 簇拥情况不同模型检测对比Table 8 Comparison of different models for clustered detection

图10 不同密集程度下各模型检测对比Fig.10 Comparison of the detection of each model at different densities
2.4.3 鸭场实例检测结果
将从鸭场实地采集的未经训练图像输入改进模型,观察其在实际情况下对鸭蛋的检测能力。图11 为改进模型检测结果,对比左边原始图像可以看出,YOLOv7_CDS模型在实际场景下检测性能良好,对于昏暗、多目标、遮挡、大视场等场景,均无错检,可实现复杂环境中鸭蛋的准确检出。

图11 实例检测Fig.11 Instance detection
3 结 论
为实现在不同角度、不同干扰等复杂环境下,对鸭蛋的快速准确检测,本研究采集模拟环境和实际环境的鸭蛋图像,以YOLOv7 为基础算法,引入CBAM 机制加强模型对鸭蛋的关注度,改进空间金字塔池化结构,并添加DSC 结构提高模型效率。将改进的YOLOv7 模型与原模型,以及其他常用算法模型的检测结果进行对比,得出以下结论:
1)在本文采集的模拟和实际环境的鸭蛋数据集上,改进并训练YOLOv7 模型,得到较优检测模型YOLOv7_CDS,其F1 分数为95.5%,平均精度均值为85.2%。与原始模型YOLOv7 相比,精确率提高了6.3 个百分点,召回率提高了8.8 个百分点,F1 分数提高了7.6 个百分点,平均精度均值提高了8.1 个百分点。同时在实例检测中,无论是堆叠遮挡、还是多干扰等复杂情况,YOLOv7_CDS 模型均具有一定优势。
2)与常用目标检测模型SSD、YOLOv4 以及YOLOv5_M 相比,改进后模型YOLOv7_CDS 的F1 分数分别提高了8.3、10.1 和8.7 个百分点;平均精度均值分别提高了15.4、10.7 以及16.4 个百分点。结果表明在复杂环境中,YOLOv7_CDS 模型进行鸭蛋检测具有可行性。针对鸭蛋簇拥、光照昏暗、覆盖遮挡等复杂情况时YOLOv7_CDS 模型具有较高鲁棒性,都能达到较优的检测效果。
3)YOLOv7_CDS 模型检测速度快,对单张图片检测,平均耗时仅为0.022 s,相比SSD、YOLOv4 以及YOLOv5_L,耗时分别减少0.073、0.072 以及0.011 s。同时,改进的YOLOv7 模型占内存空间小,在部署于鸭蛋拾取机器人的嵌入式设备具有一定优越性,为鸭蛋拾取机器人在鸭场中拾取鸭蛋提供技术支持。
