学术论文研究亮点的语言特征与主题识别*
2023-08-08杨思洛莫莹莹
杨思洛,程 濛,莫莹莹
0 引言
在学术成果海量增长和网络知识加速流动背景下,一篇学术论文受到读者发现与认可的成本越来越高。为了更加精确地匹配读者和论文,同时吸引受众的阅读兴趣,爱思唯尔出版集团ScienceDirect数据库推出了研究亮点(Research Highlight),并对其全部投稿论文提供研究亮点做出了强制性要求。根据作者指南的说明,在形式和内容上,亮点由3-5个要点构成,篇幅限制在85个字符以内,凸显研究的新颖结果和创新方法,最终逐条展示于论文网页版本的标题之下;在作用价值上,经由数据库的机器阅读匹配,亮点被证明有助于提高论文在搜索引擎中的曝光度,扩大学术成果的传播范围,引发科学工作者的关注[1]。当用户使用ScienceDirect 数据库进行检索时,可以发现在返还页面中,每一条结果与检索词匹配的突出黄色标记有两处,一是标题,二是“Extracts”栏目下的亮点文本,充分表明了亮点对于提升文章可发现性的重要作用。一方面,亮点语言简明通俗,能够更加精确地匹配论文与读者,扩大论文的传播范围。对亮点的语言特征进行研究,在当前亮点写作规范下,探究作者对这一体裁的具体呈现形式,以及受到更多读者利用的论文如何撰写亮点,有利于深度发挥亮点的宣传作用,帮助作者提升文章潜在利用的可能性,促进学术交流与合作。另一方面,亮点作为独立的组成部分,浓缩了一篇论文最重要且最具特色的新方法和新结论,能够帮助学者快速获取论文核心观点[2],降低文献阅读和筛选的成本。对亮点的内容主题进行识别,有利于发现一门学科领域最具突破性的创新贡献,明确研究重点和发展方向,进一步推动知识流动与科研创新。
目前专门对于学术论文亮点的关注少,研究主题分散,主要在于亮点的概念特征和自动抽取两方面。在亮点的概念特征上,Yang W以亮点的评价性语言和交互性语篇为研究对象,探究240篇期刊论文亮点的语言学特征,并利用问卷调查总结了编辑和作者对亮点的看法,认为亮点能够支持论文的学术立场和塑造可靠的学术形象[3];索传军等借助关键词分析法和自然语言处理算法,探索了亮点的语言学特征及其在论文中的位置分布规律,归纳出亮点具有新颖性、简明性、易读性、宣传性等特点[2]。在亮点的自动抽取上,Wang W等对多种无监督自动抽取文本方法进行评估,研究了亮点的提取特征[4];Cagliero L等通过预测文章句子和亮点的相似度,提出了基于回归模型的有监督的亮点自动抽取方法[5]。
已有研究成果对亮点的特征和价值做了总结,探索了亮点的自动抽取方法,然而整体数量少,对这一具有独特价值的文本的探索尚处于初步阶段,认识有待深入,其中关于亮点语言特征的研究限于部分语法统计和关键词频数统计,没有进行语言写作风格的深入分析,且尚未有研究探讨亮点的内容主题构成。为了丰富亮点相关研究,提升学术界和出版界的认识,引发对于亮点应用和普及的思考,本文参考现有其他类型学术文本的相关研究,从外部特征和内部特征两个方向对亮点展开探索性研究:结合亮点的宣传性功能和创新性特点,用语言特征反映外部特征,用主题识别反映内部特征,借助自然语言标注处理工具、主题模型以及科学知识图谱聚类方法,建立较为系统的研究框架对亮点文本进行实证探索。
1 研究思路与数据
针对亮点内外部特征的研究思路从语言特征和主题识别两个方面展开,见图1。具体步骤为:(1)获取学科领域的研究亮点和摘要数据集,分别导入自然语言标注处理工具MAT,获取表示语言特征频率的标准化数据;(2)将亮点和摘要语言特征的频率标准化数据进行独立样本T检验,分析亮点的语言特征;(3)依据论文的被引次数,将亮点的语言特征频率标准化数据划分为高被引、中被引和低被引3 个层次,通过Kruskal-Wallis检验探究论文被引次数与亮点语言特征的关系;(4)对研究亮点数据集进行数据预处理、特征提取、文本向量化,通过构建LDA主题模型进行亮点的整体主题识别;(5)通过人工标注对亮点进行分类,采用VOSviewer 文本主题挖掘工具识别亮点不同类型的主题。
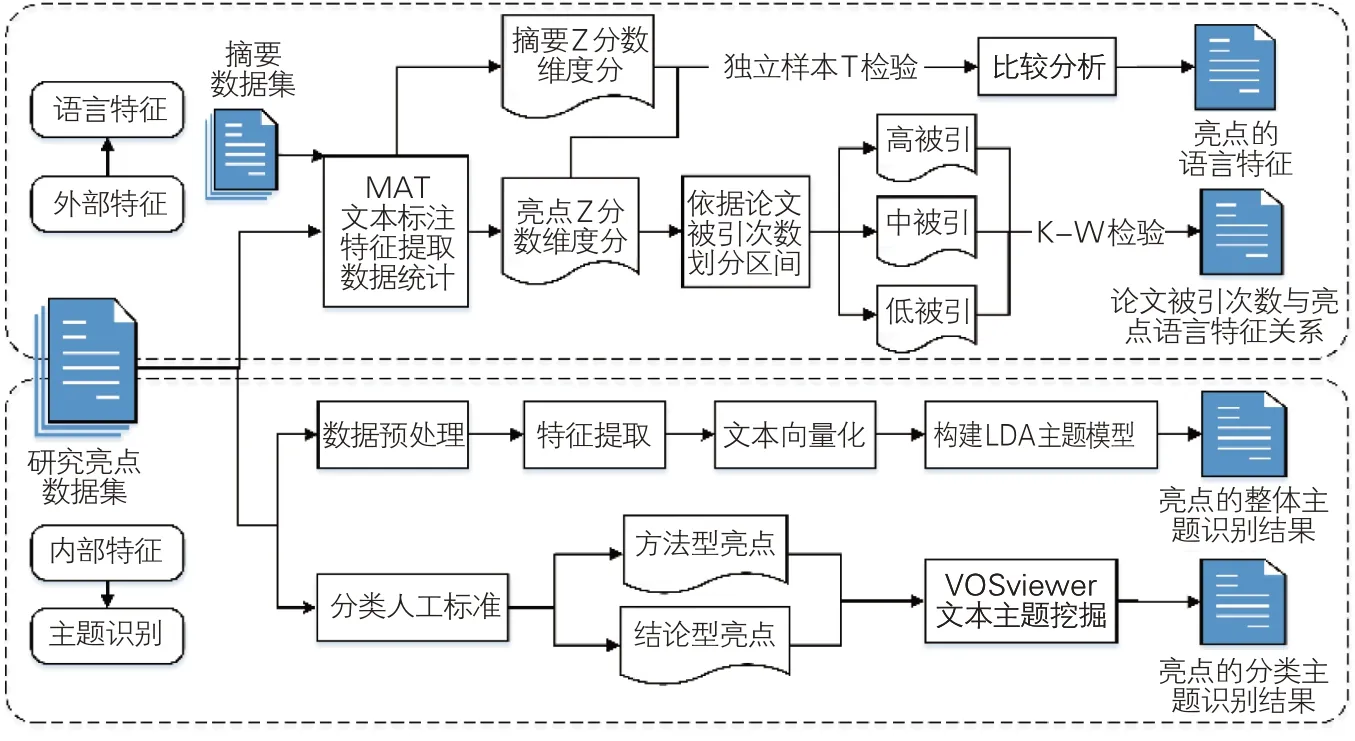
图1 亮点的语言特征与主题识别研究思路
在研究数据上,本文从爱思唯尔数据库Science Direct 选择期刊Journal of Informetrics(JOI)2013-2020 年发表的论文,获取其每篇论文的亮点、摘要和被引次数等信息,经过整理剔除缺失的数据后,得到亮点文本564篇。JOI创刊于2007年,2021年JCR分区位于Q2,期刊影响因子为4.373,是信息计量学领域权威期刊。国内外许多研究者以JOI 为数据分析信息计量学领域的研究趋势,如Halevi G 等通过JOI期刊论文的引文语境分析,揭示其跨学科领域的主题演变[6],刘丽敏等以JOI 为样本分析国际信息计量学研究足迹与知识结构[7]。JOI自2013年起实行ScienceDirect对出版论文亮点提出的要求,即规定亮点由3-5个独立句子构成,每一句的长度限定为包括空格在内的85 个字符,内容上主要介绍研究中新颖的成果和新方法。一篇论文的亮点如下例所示[8]:
·Exploring knowledge communication and scientific structure by author direct-citation.
·Author direct-citation analysis among prolific,highly cited,and core authors.
· Research subjects on information science around the world be divided into 10 clusters.
·Author direct-citation analysis is different from author co-citation analysis.
通过对亮点语料库进行统计,564篇亮点文本主要由3-5个语句构成,其中有3篇包含6条语句,罗列要点的语句总数量为2,341条,单词总数为32,875 个,平均每篇亮点长度为58.29个单词,每条要点平均长度为14.04 个单词。表1描述不同语句长度亮点的基本统计概况。
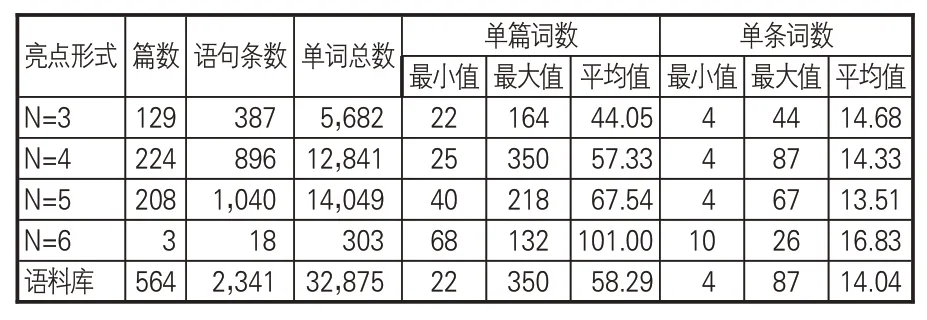
表1 亮点语料库统计描述
2 亮点的语言特征多维度分析
亮点位于论文摘要之前的重要位置,要求以简短的篇幅和通俗的语言展示最重要的方法或结论,对学术论文进行宣传推广,能引起读者的阅览兴趣,扩大文章的传播范围,提升文章潜在利用的可能性。作者进行亮点编写时需要关注语言特征,在观点表达以及读者互动上使用一定的策略,才能达到更好的宣传效果。本文使用多维度分析法,结合论文摘要进行比较研究,考察亮点语言特征的使用情况,并探究论文被引次数与亮点语言特征的关系,分析高被引论文的亮点在语言风格上的倾向性,为作者撰写亮点的语言表述提供参考。
2.1 多维度分析法
多维度分析法(Multidimensional Analysis,MDA)是由Douglas Biber提出的语言特征量化研究方法,其基本思想是文本的语言表达形式反映了文本的交际、认知和语境等功能,而文本的某一功能对应一组具有相关性的词汇语法特征。Biber利用LLC英语口语语料库和LOB英语书面语语料库,选取且确定了67个语言特征,并统计它们在每个语篇中的分布频率,采用因子分析法将语篇中共现的语言特征归结为7个因子,代表7个语言功能分析维度,每一维度的语言特征又根据因子载荷的正负值分为功能相反的两类。不同语域的文本使用的语言特征在各维度上的分布不同,从而体现出文本语言功能的差异。7 个维度具体包括:维度1,交互性/信息性表达(Involved vs.Informational production);维度2,叙述性/非叙述性关切(Narrative vs. Nonnarrative concerns);维度3,明确指称/情景依赖型指称(Explicit vs. Situation- dependent Reference);维度4,显性劝说型表述(Overt Expression of Persuasion);维度5,抽象信息/非抽象信息(Abstract vs.Non-abstract Information)维度6,即席信息组织精细度(Online Information Elaboration);维度7,学术性模糊表达(Academic Hedging),维度7由于数据量的单薄在实际研究中通常被省略。每个维度上分布有数量不同的语言特征,同一维度上可能存在性质相对、功能相反的两组特征,如维度1中代表文本强交互性的特征(如第一人称代词和现在时态)为正特征,代表文本强信息性的特征(如名词和形容词)为负特征。多维度分析法广泛应用于语域差异研究,如高校学生学术英语写作水平在培训前后的纵向对比[9],博士论文摘要的历时对比[10],英语学习者和母语者论文的写作风格对比[11],以及著作不同翻译版本的特征对比[12]。该方法从不同功能维度考察亮点的语言特征使用情况,与多元统计分析结合可以针对不同的文本进行量化比较分析。
本文使用多维度标注与分析工具MAT(Multidimensional Analysis Tagger),该软件整合Biber的8种语域类别、67个语言特征和前6个功能维度,借助斯坦福词性赋码器(Stanford Tagger)对词性和语言功能特征进行标注,实现多维度分析过程中文本标注、特征提取和数据统计等一系列工作的自动化操作,并输出文本最接近类型、每个语言特征的出现频率、频率标准化后的得分(Z-scores,Z分数)、每个维度的维度分(Dimension Scores)。维度分的计算规则是,因子载荷为正值和负值的两类语言特征Z分数之和相减,如维度1:D1=(ZPRIV+ZTHATD+ZVPRT+……)-(ZNN+ZAWL+ZJJ+……)。将564篇亮点文本分别以txt文件保存并导入MAT进行全部语言特征标签的标记与分析,获取每篇亮点文本的维度分和Z分数,以及该篇亮点文本最接近的文本类型,将以上数据导入Excel和SPSS以备分析和检验。
2.2 亮点的文本类型和维度特征
根据MAT标注分析结果得到亮点文本564篇,学术论文亮点整体语料库“最接近文本类型”为学术说明型(Learned Exposition)。学术说明型文本是典型的正式的信息说明文本,注重传递信息[13],表现在维度1得分较低,维度3和维度5得分较高。从单篇亮点的标注结果来看,所有文本归类共呈现4种形式,学术说明型(481篇,85.3%)占据主体,另有少量文本最接近科学说明型(Scientific Exposition)(41篇,7.3%)、一般叙述型(General Narrative Exposition)(29 篇,5.1%)和交互劝说型(Involved Persuasion)(13篇,2.3%)。语料库整体的维度分以及各类型亮点文本6个维度分平均值如图2所示。维度1分数越低,表明文本的语言中偏向信息性的特征(负特征)越多,反之则倾向于情感交互性的表达,一般分别对应书面语和口语对话,亮点文本在维度1的负值低分呈现出其较强的信息性。维度2的分值从正到负意味着文本语言特征由叙述性到非叙述性的转换,亮点的负分值表明文本的非叙述性特征密集出现。维度3的高分表明亮点文本指称明确且不依赖于时间地点等情境。维度4上,大量文本的负分值显示其呈现较弱的劝说性。维度5的高分表明信息抽象程度较高,文本词汇的技术性较强。维度6的负值表示文本以将信息囊括在较少的词汇和句子中这样完整的方式来详述,并不是有限时间内的即兴语言组织[14]。总体上,亮点的语言表达呈现信息性、技术性和精确性较强,互动性、叙述性和劝说性较弱的特点。
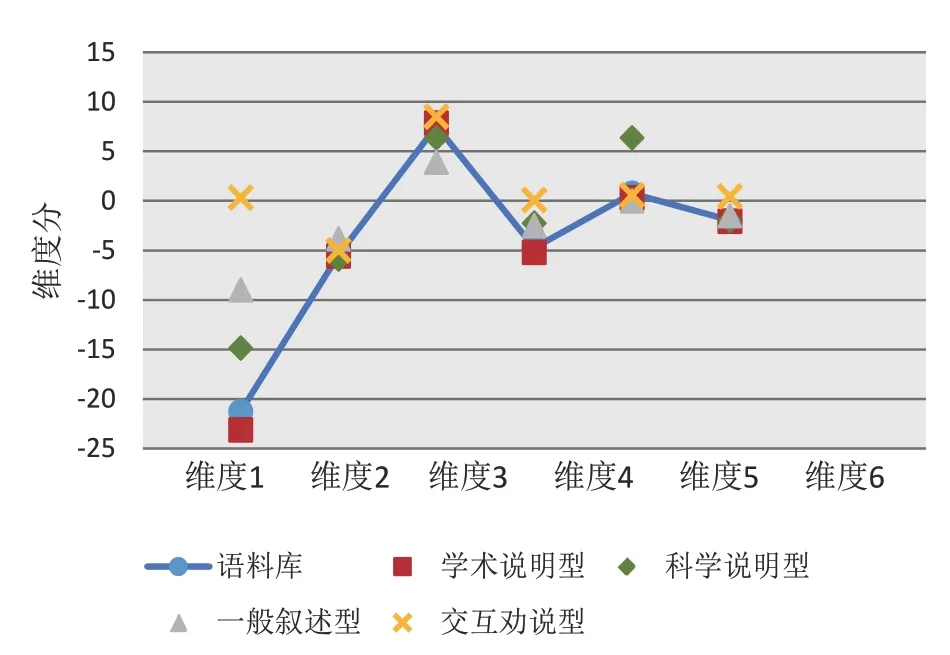
图2 各类型亮点维度分平均值
2.3 亮点与摘要的语言特征多维度对比分析
亮点与摘要在内容上有说明研究方法和结果结论的相似之处,但前者在语言上更为简洁凝练,并要求面向一般受众,不使用专业性强的文字表述。为了对比分析二者在语言风格上的差异,将获取的摘要数据利用MAT以同样的方式完成标注分析,借助SPSS对两类文本的6个维度分和全部语言特征Z 分数进行独立样本T 检验。检验结果显示,在维度2、维度3、维度5、维度6上,亮点与摘要文本存在显著差异,而维度1和维度4的差异不显著,两类文本均值差异如图3所示。
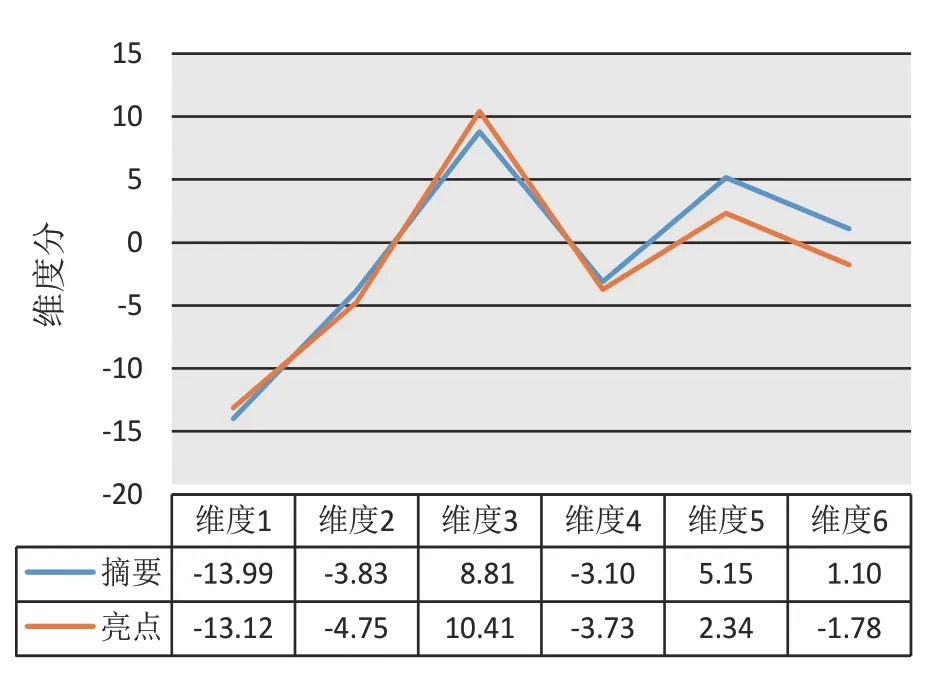
图3 亮点与摘要维度分均值差异
在语言特征上,由于文本长度和内容撰写重点的不同,摘要运用的语言特征种类和频次明显多于亮点。为了排除几乎未被使用的语言特征的干扰,确定亮点文本中实际影响各维度的具体语言特征,先对亮点和摘要每个维度分及其对应的语言特征Z分数进行逐步回归,从而得到每个维度真实使用的语言特征变量,然后在回归结果的基础之上进行比较,表2展示了独立样本T检验结果中,亮点和摘要各维度存在明显差异的具体语言特征。
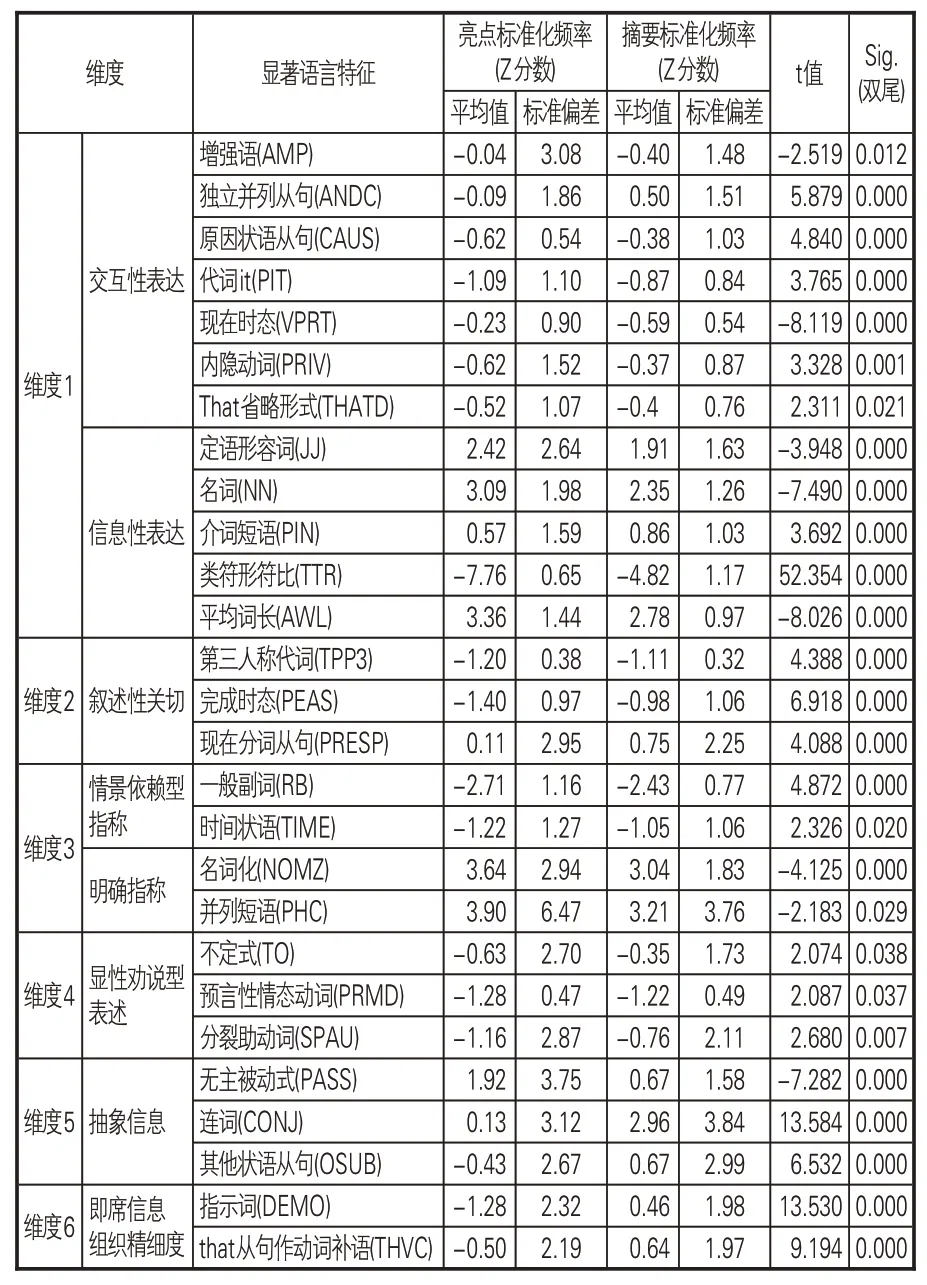
表2 亮点与摘要的各维度语言特征差异
根据回归分析结果,维度1“交互性/信息性表达”中,进入方程的语言特征变量有可能意义情态动词(POMD)、定语形容词(JJ)、名词(NN)等。在偏向信息性表达的语言特征中,亮点的平均词长(AWL)、名词(NN)和定语形容词(JJ)出现频率均高于摘要,它们都用于确定具体的信息以增加文本的信息密度。交互性表达中,亮点中出现highly、strongly、very、completely、greatly等增强语(AMP)的相对频率更高,体现在程度、数量关系、作用强度的表述上,用以强化观点、表明文章立场,提升对论文的宣传作用。整体而言维度1 差异不显著,摘要的维度分平均值更高,因而两类文本均偏向信息性表达,但摘要与读者的情感互动性相对更强。
维度2“叙述性关切”中,回归分析显示,主要影响因素包括公动词(PUBV)、现在分词从句(PRESP)、完成时态(PEAS)等语言特征。存在显著差异的第三人称代词(TPP3)、完成时态、现在分词从句等3个语言特征在摘要的出现频率均大于亮点,摘要的维度分均值更高,具有更强的叙述性。例如,文献[15]的亮点指出研究方法:“An Index of National Orientation (INO) is used,based on the geographical distribution of a journals’publishing and citing authors.”在摘要中的对应论述“It calculates for journals covered in Scopus an Index of National Orientation(INO),and analyses the distribution of INO values across disciplines and countries,and the correlation between INO values and journal impact factors”则展开说明了该方法的应用场景和对象,使用到更多的分句和代词。同时,亮点论述的研究结论并不涵盖全部,而是在有限的篇幅内选择最重要的加以展示,相比摘要会省略“It is found that”“The main findings are”“Our analysis shows that”等引导性用语,显示更弱的叙述性。
维度3“明确指称/情景依赖型指称”所识别的预测变量有并列短语(PHC)、地点状语(PLACE)、名词化(NOMZ)、时间状语(TIME)等7个。呈现显著差异的语言特征中,亮点的名词化和并列短语的频率高于摘要,偏向情景依赖的一般副词和时间状语的使用少于摘要;由于其逐条罗列的形式特点,不依赖上下文的程度明显强于摘要。
维度4“显性劝说型表述”,经过6次逐步回归分析,得到不定式(TO)、分裂助动词(SPAU)、劝说性动词(SUAV)等6个最佳预测变量。维度4的t检验结果差异不显著,数值上摘要的得分平均值略高于亮点,有显著差异的不定式、预期情态动词和分裂助动词等3 个语言特征均略高于亮点。
维度5“抽象信息”纳入的预测变量包含4个:无主被动式(PASS)、过去分词省略WH 式(WZPAST)、 连词(CONJ)、 其他状语从句(OSUB)。亮点得分均值显著低于摘要,摘要中更多使用连词和其他状语从句,增加了信息的抽象程度和技术性,原因是摘要中阐述研究问题和研究背景的语句更多。但在有限的文本篇幅中,亮点不带施动者的被动语态应用的频率更高,主因是“is proposed”“is compared”“is analyzed”“is constructed”“is used”“is introduced”等表示研究方法的被动形式的普遍应用。
维度6“即席信息组织精细度”的最佳预测变量有2个:指示词(DEMO)和that从句作动词补语(THVC)。同样地,摘要得分的平均值更高。that等指示词及其引导从句作补语的情况出现较多,因而信息组织更为精细严密,是亮点相较于摘要语言篇幅更短的体现。
综上所述,亮点与摘要整体维度趋势具有相似性。在信息密集的同时,亮点相对不注重与读者的互动,更加强调语言的描述性和说明性,比起摘要显示出相对更弱的叙事性和劝说性,以及更强的内容独立性和指向明确性。另外,数据表明,摘要平均词数(176.9)是亮点平均词数(58.3)的3倍以上。摘要中研究背景和过程的叙述,增加了读者获取文章创新内容的阅读成本,而亮点用于增强语气、增强信息密度的语法表达以及被动语态明显多于摘要,且语言组织不求复杂精细,内容表述不依赖上下文,对作者立场观点的传递更为简洁、明确有力。
2.4 论文被引次数与亮点语言特征关系分析
为探究论文被引次数与亮点语言特征的关系,借鉴文献[16]引文预测模型的四分位数分类法,将564篇亮点文本依据论文被引次数划分为4个区间,分别为Q1:被引次数0~5;Q2:被引次数6~10;Q3:被引次数11~20;Q4:被引次数21 及以上,使得每一区间亮点的篇数相当。由于数据样本不完全满足方差齐性,采用Kruskal-Wallis单因素ANOVA分析,对不同引文区间的亮点的维度分以及语言特征Z分数的差异进行检验,P<0.05认为有显著差异。结果显示,不同引文区间的亮点文本在6个维度上无明显差异,在具体语言特征上差异达到显著水平的有:独立并列从句(ANDC)、劝说性动词(SUAV)、强调语(EMPH)、基数词(CD)和数量词(QUAN)。
独立并列从句主要指逗号后接and连词引导的句式,如“Technical details on the construction,visualization,and analysis of citation networks are discussed.”。劝说性动词主要指propose、suggest、allow、determine、recommend、intend、prefer 等带有观点性的动词。强调语主要指more、most、really、so、do等表示强调副词的应用,在研究结果中突出比较关系。基数词指文本中出现的所有数值,包括年份、比例、个数、版本等各种数字表示。数量词指some、all、many、any、few、several等表示数量的修饰语。
根据表3的成对比较结果,除劝说性动词在被引次数更高论文的亮点中使用较少(Q4>Q1)外,其余4 种语言特征在Q4 的使用频率均更高。即,被引次数更高的论文,其亮点通常会更多使用独立并列从句、强调语、基数词、数量词,更少使用的劝说性动词。这可能是由于独立并列从句比长句更容易阅读,强调语、基数词和数量词以比较和量化的方式,直观展示论文的重点信息,更容易被浏览发现,吸引阅读兴趣。通过对语料库标注信息的检索,劝说性动词在亮点中的使用以“propose”及其改变形式为主,而新提出的理论、方法、模型、技术可能需要历经更长时期的检验,才得到广泛利用。
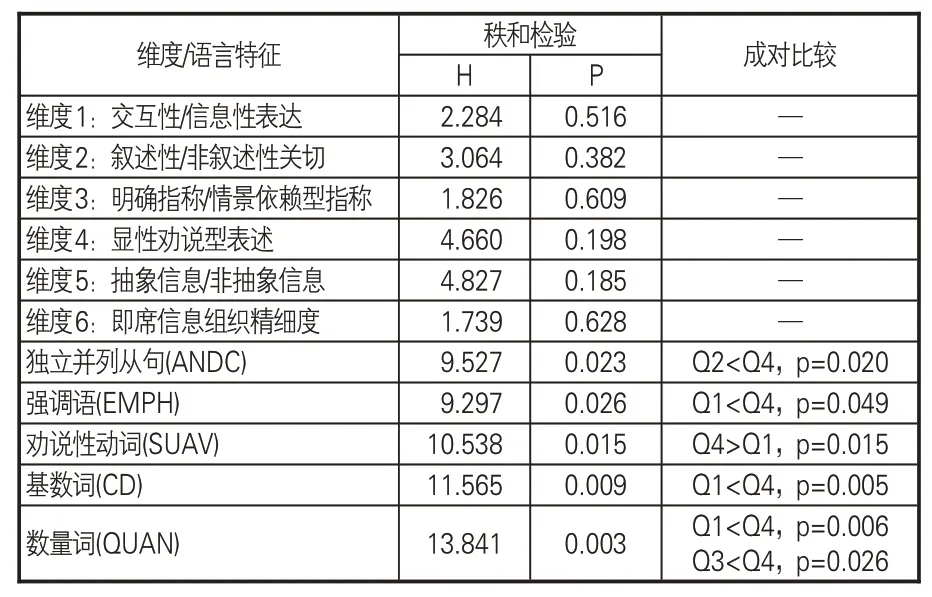
表3 不同引文区间亮点各维度和语言特征对比
3 亮点的内容主题识别分析
在反映科技创新主题和研究热点上,相比于广泛应用的文献摘要等题录信息,亮点经由作者遴选,精练了论文中最具特色的方法和最重要的发现,其独立成句的形式排除了大量语义信息,为识别创新的研究方法和结论提供了更为便捷的条件。本文首先采用LDA主题建模方法从整体上识别亮点语篇,其次对亮点语句逐条进行人工分类标注,并根据分类结果使用VOSviewer进行文本挖掘,从而梳理亮点在表达论文创新主题上的内部特征,以及不同类型亮点的分布特征。
3.1 亮点整体主题识别
LDA主题模型的应用能增强学科领域研究热点的语义信息解释性[17]。针对亮点文本的总体内容特征,利用Python对数据预处理,清洗不必要的符号并将亮点文本进行分词和词形还原,使用nltk 停用词表对分词结果进行停用词过滤处理,调用WordNet内置函数实现词形还原,并自行设置同义词和停用词读取替换,计算并保存文本词频结果。经过统计和分类后,出现频率较高的名词和形容词关键词见表4。
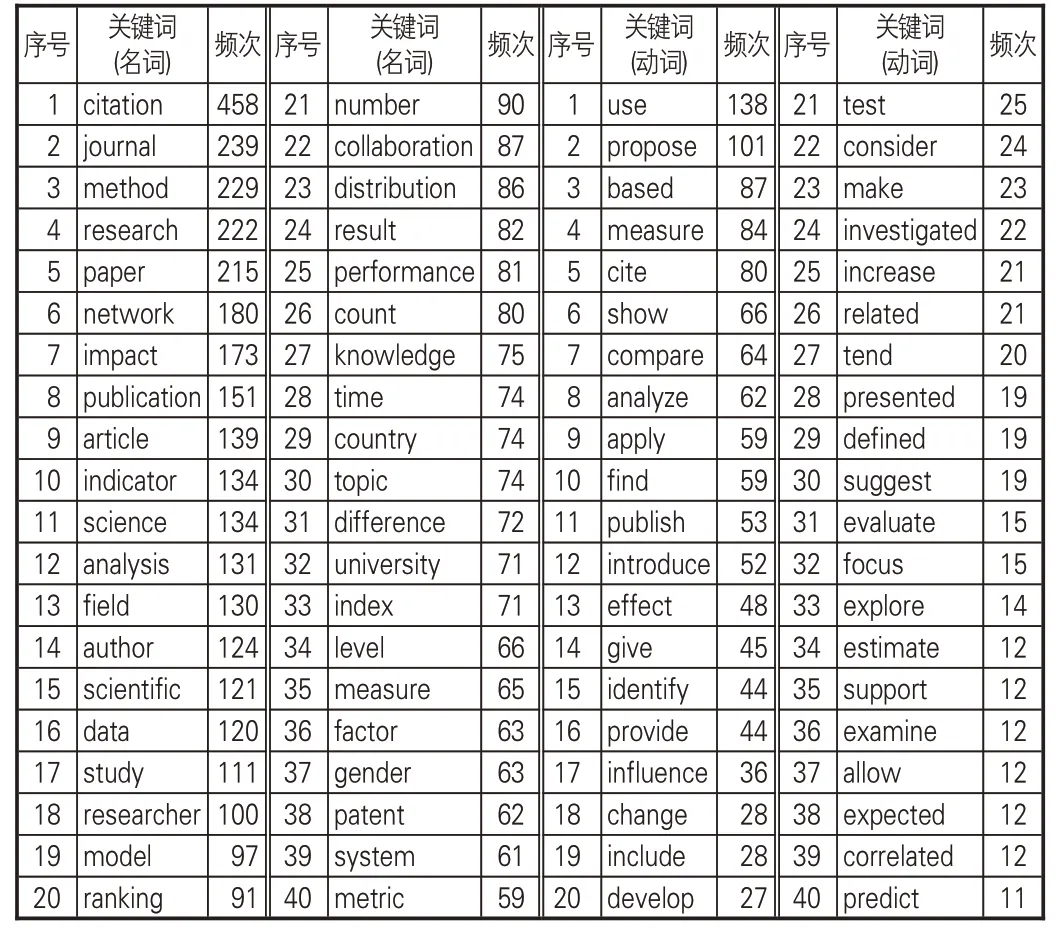
表4 亮点高频关键词统计
在主题建模阶段,通过工具包Gensim 中LdaModel 函数结合TF-IDF 加权处理方法对经过清洗后的亮点文本进行迭代训练,在困惑度随主题数目增加而上升的情况下,选用一致性检验方法确定最优主题数目,形成主题-特征词分布。不断调整各项参数以提升主题结果的可解释性,最终设置主题数为10,迭代次数为600,每组特征词个数为100。形成主题特征词分布后,分别依据主题词内容进行命名,选取每个主题前20个关键词,如表5所示。引文分析主题趋向引文预测模型、网络数据库的比较评估、引文与其他因素的影响作用关系等研究。科研主题类涉及学术研究和社交网络中的热点主题挖掘以及学科领域的主题演化。期刊与出版物主题关注出版物的分类、影响力、书目特征和开放获取。影响因子主题主要研究JIF为主的期刊影响力指数,涉及计算方式的优化比较以及标准化方法的应用,如文献[18]指出对于JIF计算,几何平均值比算术平均值给出更稳定的结果。绩效评价主题关注学者、高校等科研机构绩效的影响因素和评价方法。专利计量主题主要探讨专利引用的方法和科学技术的联系、发展与融合,如文献[19]利用文本相似性论证专利引用可以表示知识链接。合作主题涉及研究人员、科研机构、国家层面跨领域合作的动态网络、合作模式、作用效果以及性别差异等。科技指标主要研究h 指数、g指数基础上新指标的构建和应用,同时关注基于社交网络的替代计量指标。方法和技术主题指面向解决领域问题所提出的方法模型和软件工具,如引文网络分析与可视化工具CitNetExplorer[20]和科学地图分析工具bibliometrix[21]。网络分析主题主要包括社会网络、复杂网络等分析方法在信息计量学中的应用。对比目前已有利用题录数据分析信息计量学知识结构的研究,田沛霖等通过分析Journal of Informetrics的文献题录数据,总结评价指标的理论与实践、网络指标对绩效的影响、高校科研绩效评价、期刊影响力与跨学科性测度、基于网络数据库的引文分析、研究的社会影响测度6个主题社区[22],其归纳的知识来源与上述部分识别结果基本对应,另有科研主题、专利计量、合作、方法和技术等主题与该研究总结的高频关键词大致契合,表明亮点在内容特征上具有表达论文核心主题的功能,可用于揭示特定学科领域的研究结构。
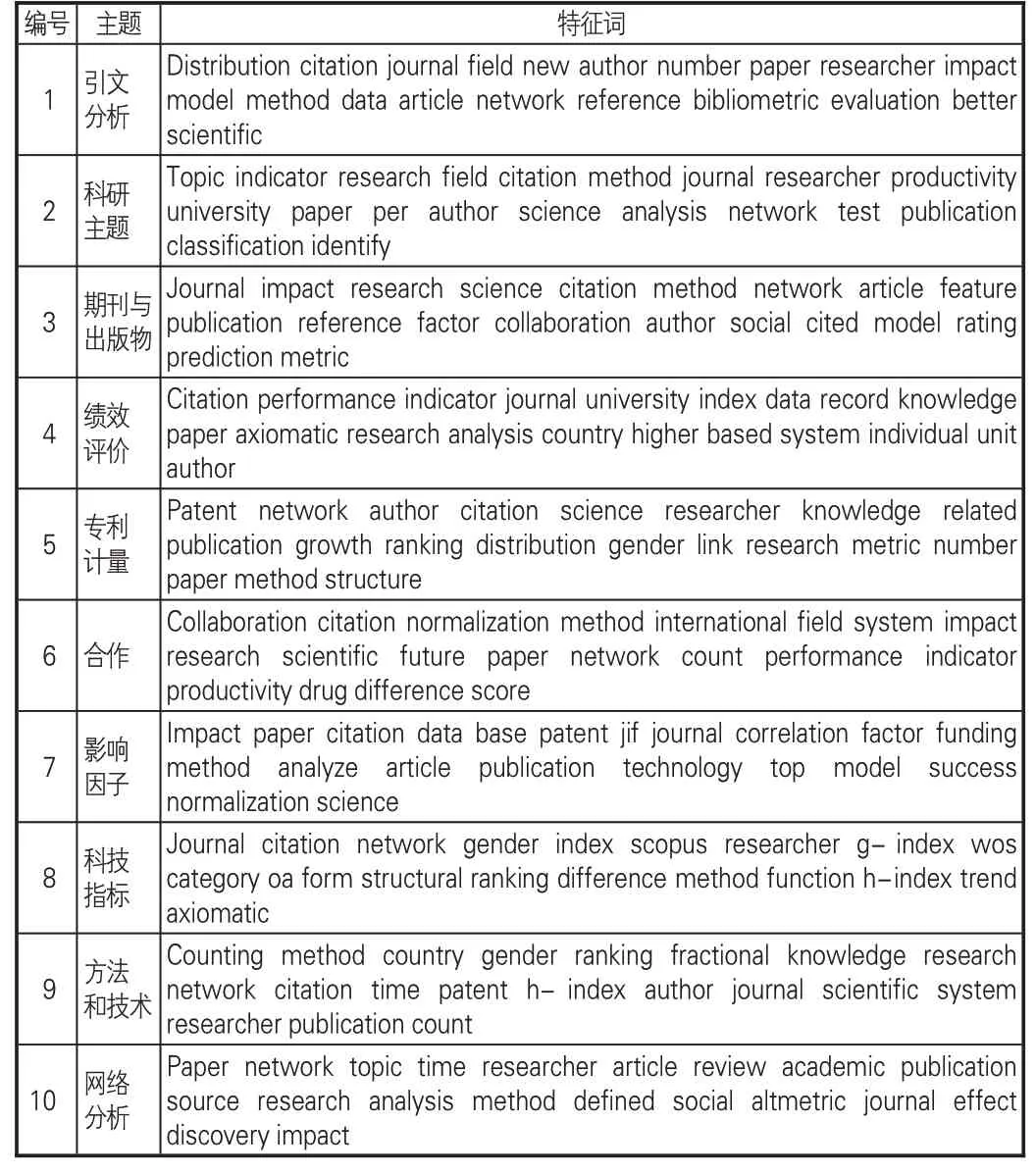
表5 亮点主题-特征词分布
3.2 亮点分类主题识别
3.2.1 亮点类型分布特征
ScienceDirect作者指南要求,亮点应突出创新的研究成果或研究方法。结合对亮点文本内容的判读,本文将亮点划分为方法型亮点、结论型亮点和其他型亮点。方法型亮点描述了研究采用的具体研究方法、数据来源、研究设计流程,介绍提出的新方法、新方法的功能效果、新技术工具等,对应“提出、测量、分析、使用、比较”等动词关键词。结论型亮点总结了研究结果或结论,以及结果相关讨论,对应了发现、确定、展现、揭示、建议等动词关键词。除此之外,部分亮点还会涉及研究目的和意义、研究背景和问题,归属于其他型亮点。人工分类标注由两位成员共同进行,首先通过阅读梳理就分类标准达成一致,然后相互独立初步标注50篇作为试验样本,对存在分歧之处通过讨论进一步调整和完善类型的定义,确定更加明确的区分细并完成全部文本的标注。最终分类结果Kappa 系数达到了0.8以上,具有较高的信度。
在单条语句层面,数据集共有2,341 条亮点,涵盖方法型亮点1,053条,分布于428篇文献;结论型亮点1,133条,分布于433篇文献;其他型亮点155条,分布于132篇文献,见表6。在语篇层面,亮点语篇包含6种结构:(1)全部为方法型,共96 篇;(2)全部为结论型,共106 篇;(3)方法型和结论型,共230篇;(4)方法型和其他型,共34 篇;(5)结论型和其他型,共29 篇;(6)方法型、结论型和其他型,共29 篇。另有1 篇只提出研究问题,为其他型亮点。图4 展示了亮点语篇结构,蓝色、红色、黄色依次代表方法型、结论型和其他型的3 类亮点成分,交叉重叠后形成6 个系列色块,分别代表了上述6 种结构。由统计结果发现,方法型亮点和结论型亮点总体数量接近,结构(1)和结构(2)的占比相当,约有一半的亮点语篇同时论述了方法和结论,通篇仅阐述方法或仅说明结论的分别约占四分之一,显示了研究方法和研究结论在亮点中具有同等重要性。
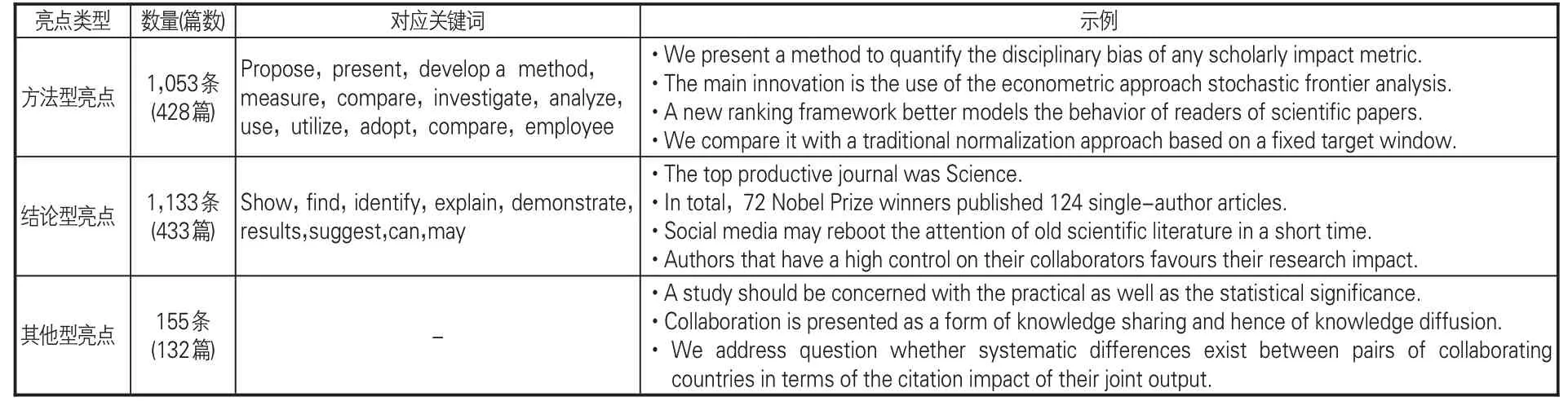
表6 亮点语句类型分布
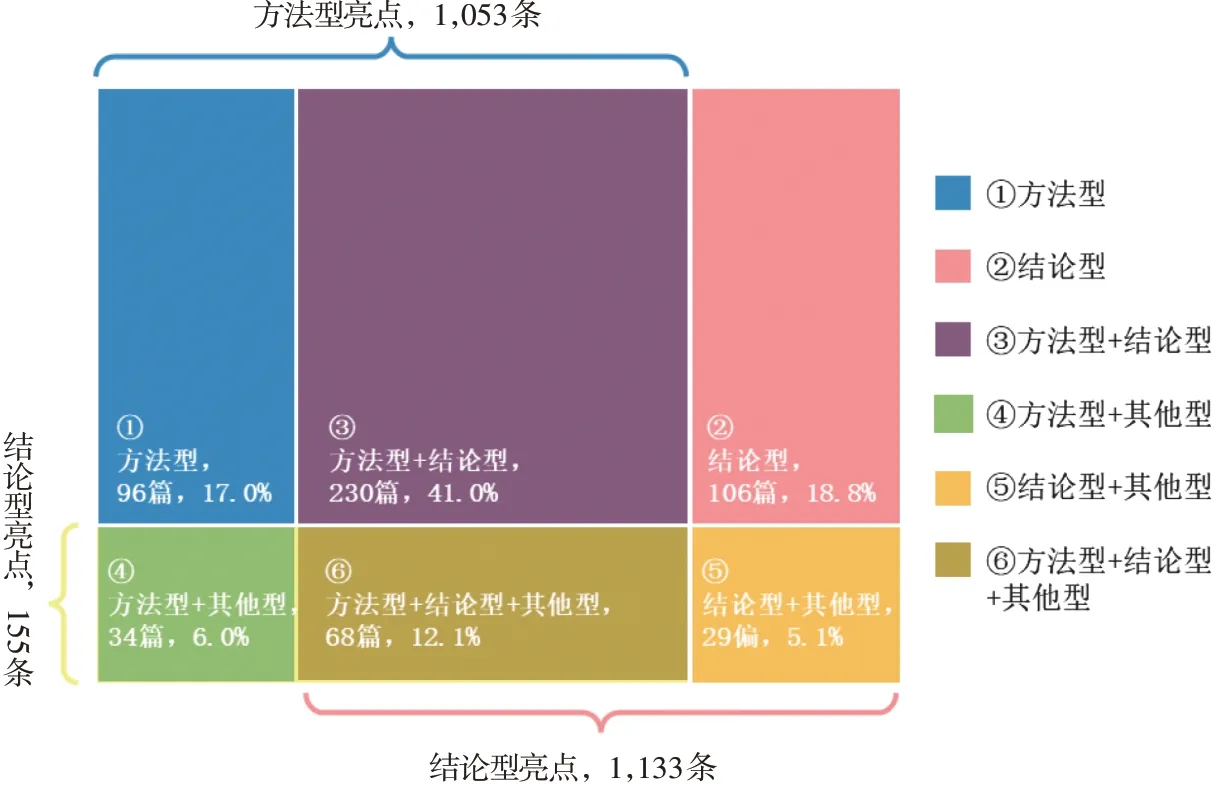
图4 亮点语篇结构
3.2.2 分类主题挖掘
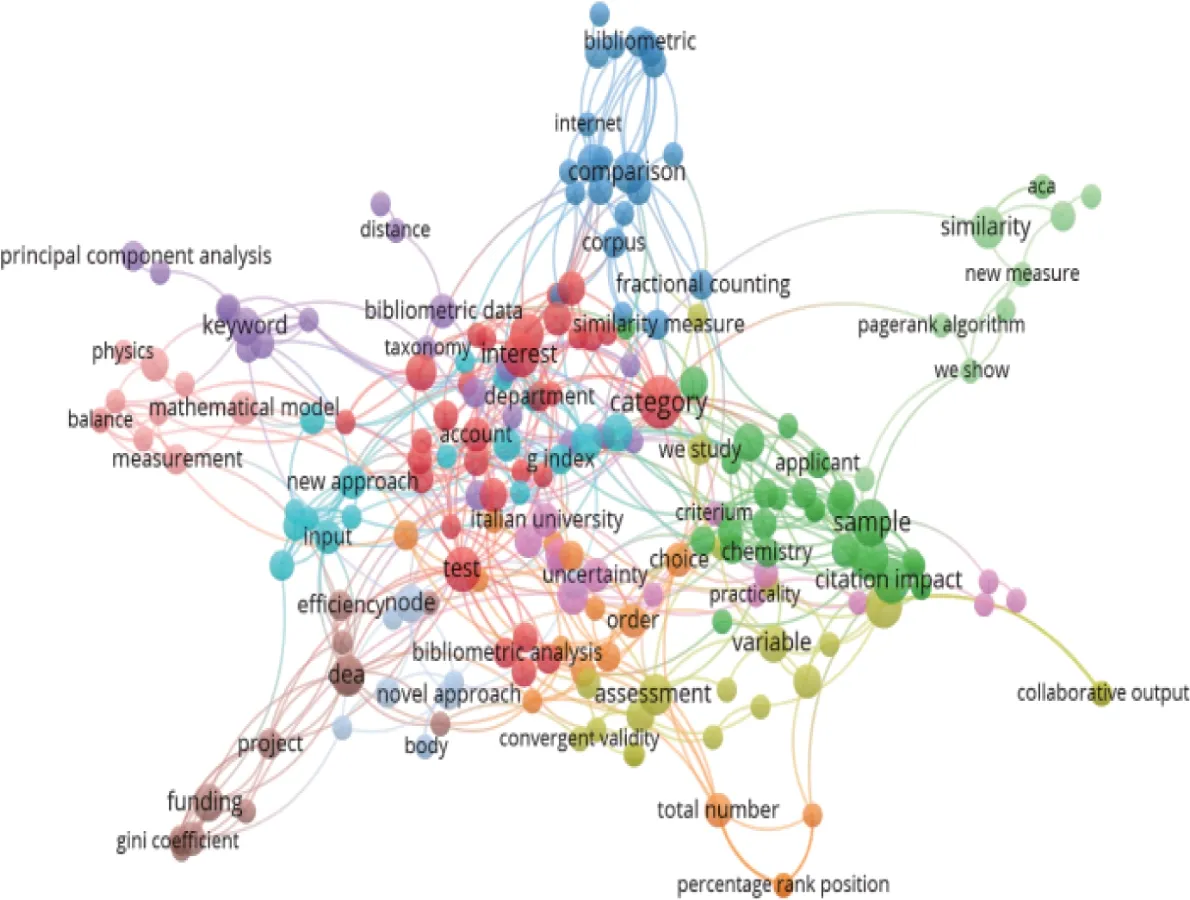
图5 方法型亮点主题共现
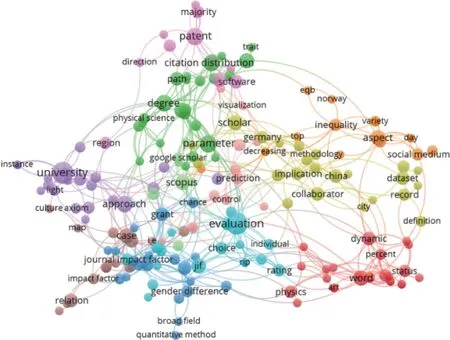
图6 结论型亮点主题共现
在分类标注的基础上,利用VOSviewer文本主题挖掘功能,将摘要字段替换为亮点文本,设置同义词替换和不同词性词合并,如h-index 与hirsch index、h index,normalize 和normalization,对方法型亮点和结论创新型亮点分别进行主题可视化分析,见图5-6。方法型亮点描述具体方法创新和特色,包括其他领域方法的引入或已有方法的创新,也包括新方法的提出或原有方法基础上的有效改进。JOI鼓励投稿使用其他定量领域的方法研究信息问题[23],如数学、统计学、计算机科学、经济学和计量经济学以及网络科学。由于样本限制以及新颖方法的独特性,聚类结果较为分散,参考输出的分词结果列表将方法进行归类,主要有6 种。(1)信息计量指标。传统引文分析指标中影响因子、h指数、g指数指标依旧出现频率较高,Almetric指标及Mendeley、Twitter等社交媒体新型评价工具也受到学术界关注,还有如百分位数排序位置指标(percentage rank position,PRP)、引文时间窗(citation time window)和作者共引统计等指标。(2)科研绩效评价方法。数据包络分析方法(data envelopment analysis,DEA)在期刊、机构、国家和地区绩效评价中广泛应用创新。此外,统计标准化方法探索较多,如分数计数法(fractional counting)、被引端标准化(cited-side normalization)和施引端标准化(citingside normalization),以及具体的来源标准化方法(source normalization approach)和平均标准化读者得分(mean normalized reader score,MNRS)。(3)数据统计方法,包括主成分分析法(principal component analysis)、回归模型(regression model)、TF-IDF 算法、相似度计算(similarity)、 聚类(cluster)、时间序列分析(time series)、可视化方法(visualization)、鲁棒性测试(robustness)。(4)网络分析方法,如引文网络、社会网络、共词网络、作者共现网络、合作网络、异构网络、二部网络、度分布(degree distribution)。(5)数据挖掘方法,如机器学习(machine learning)、主题模型(topic model)、PageRank 算法、优先连接算法(preferential attachment)。(6)跨学科方法,如以数学为基础的公理化方法(axiom)、经济学的基尼系数(Gini coefficient)以及合作博弈与收益分配的沙普利值方法(shapley value)。除具体方法之外,部分文献主要提出新理论和概念框架,通常伴随案例研究的实证,WoS、Google Scholar、Scopus、国家自然科学基金委员会等平台机构,以及意大利等国家地区大量出现于数据源中,医药学、物理学、3D打印领域是主要的热点分析领域。
结论型亮点通常展示基于研究对象的数据结果、被确定的关系以及得到的效果或性能。从聚类结果来看,相较于方法型亮点,结论型亮点更难从语词层面识别出解释性较强的信息,更多涉及模式、参数、程度、表现、相关关系、强度、领域、结构、重要性等表示领域重要内容的词汇。与亮点整体主题识别结果相似,引文、期刊影响因子、论文、专利、作者、国家、合作、出版物、绩效评价、网络分析等主题依旧是信息计量的重点研究方向。其次,更多主题和研究对象受到关注,如性别差异、开放获取、生产力、信息政策、同行评议、主题挖掘,以及各个国家地区、学科领域、社交媒体平台和学术平台。另外,有一定数量的文献针对不同的数据库、计数方法或评价指标进行比较研究,在结论型亮点中直接指出各自的差异与优势。例如,有研究认为,在专家判断一致的情况下,期刊质量评价指数中,篇均来源期刊标准影响(source normalized impact per paper,SNIP)比粗计量篇均影响(row impact per paper,RIP)或期刊影响因子有着更好的效能[24]。
4 结语
学术论文亮点的提出旨在用简明扼要的文字,介绍论文的研究要点,在搜索引擎中增强与用户信息检索的匹配程度,帮助读者迅速筛选文献,吸引不同学科领域研究者的关注和理解,起到宣传推广论文的效果,以提升其利用率,促进科研创新和知识流动。然而,这一学术体裁鲜少得到关注,本文对其外部特征和内部特征进行了探索性研究。
在外部特征上,亮点的语言呈现较强的信息性和非叙述性,指称明确不依赖语境,情感交互性和显性劝说性较弱,信息表达倾向于抽象和技术性,即席信息组织较为精细。与摘要文本对比,亮点文本的主要功能在于展示最重要的研究方法和研究结论,既不包含摘要中的研究问题和研究过程,也不囊括摘要中的具体方法和全部结论。独立语句的形式使其指示词和各类型从句的应用频率较低,但词汇密度较高,因而能更直观地表达核心结论。被引次数较高的论文,其亮点更倾向于使用较多的基数词、数量词、强调语和独立并列从句。在论文亮点撰写的过程中,建议作者可以更多展示具体数据和数量关系,用数字和程度副词说明研究所用的材料、得到的效能、确定的关系、对比的结果等,避免过于追求精炼而缺失实质信息;必要时可以使用并列从句,避免长难句带来的阅读阻力,从而展现论文的核心价值和竞争力,提升编辑审稿和读者阅读的效率。
在内部特征上,通过亮点主题识别结果与现有题录信息相关研究的对比,发现亮点具有表达论文核心主题的功能,可以用于揭示特定学科领域的研究重点。亮点依据内容可分为方法型亮点、结论型亮点和其他型亮点。单篇亮点基于文章属性对研究方法和研究结论的侧重有所不同,但整体结构分布上数量相当;方法型亮点的文本比结论型更具可解释性,能够反映相关领域的前沿方法。亮点中对未来应用进行展望,可以作为创新点事实单元[25],相比文摘更易于分解为问题、方法、结果的实体和语义关系,便于机器处理和阅读,可应用到学术资源检索系统中助力知识问答功能的智能化。
本研究的不足体现在:(1)采用的数据仅限于JOI期刊的564篇亮点文本,样本数量存在局限性,在语言特征与被引数量关系以及内容挖掘可解释性上需要谨慎考虑;(2)亮点人工标注分类标准上,没有将理论创新单独考虑,不同类型的亮点统计结果精确程度有待提升;(3)研究领域相对单一,而不同学科领域的论文亮点在方法和结论上的创新侧重点不同,语言风格倾向也不同,需要进行更多的实证对比。后续将针对以上问题,完善对学术论文亮点的认知和实践探索,为亮点在知识交流和科研创新中的应用提供参考。
