基于主题相关性和深度学习的文本情感分析
2023-08-05吉秉彧
闵 洁,吉秉彧
(信阳农林学院 信息工程学院, 河南 信阳 464000)
0 引言
互联网时代背景下,各种电子商务平台的评论文本数据巨量增长,其中蕴含的情感信息对商家用户有着非凡的意义和实用价值,如何快速精准地从其中提取有情感的信息,已经成为该领域科学家和学者的研究方向,发展行之有效的理论方法是当下亟待解决的问题,因此,文本情感分析研究具有广阔的前景和重大意义。
目前,文本情感分析已经广泛应用于新闻传媒、文化娱乐、电子商务、语义相似计算等领域[1]。早期的研究中,主要采用聚类算法对文本进行处理来实现特征提取,主题概率统计模型是常用理论方法,其良好的可移植性和优良的性能受到广大研究者的青睐,所采用的概率统计理论可以挖掘文本中隐含的主题特征,进而将具有相似语义的关键词进行特征归类。
文献[2]提出了潜在评级回归模型(Latent Rating Regression,LRR),使用基于自举的文本分割算法对文本进行主题特征分割,并构建主题概率统计模型进行情感信息处理,但该方法没有考虑到文本语义的连贯性。
文献[3-4]基于 LDA模型(Latent Dirichlet Allocation,LDA)对微博文档进行建模和主题提取,在此基础上实现微博用户划分和聚类。文献[5]采用LDA模型对电影评论文本进行情感分析和分类,在得到电影评论主题分布的基础上,结合TF-IDF方法获取文本相似度矩阵和评分,进而实现电影聚类和推荐。
主题概率统计模型的应用取得了一定的效果,然而,其所涉及的研究是在主题之间相互独立的假设下实现的,忽略了文本主题的相关关系,不符合文本表述中主题相互关联的现实情况,进而使得词表示存在缺陷,同时也存在数据维度过高、计算复杂等问题。
针对以上问题,相关主题模型(Correlated Topic Model,CTM)[6]实现了对主题特征潜在相关性地挖掘,因此得到了广为使用。基于该模型,文献[7]提出相关主题模型-概率矩阵分解(Correlated Topic Model and Probabilistic Matrix Factorization,CTM-PMF)模型,在挖掘出没有评分新物品主题归类和隐含相关关系基础上,实现了相关的推荐功能;文献[8]进行了文本情感分析研究,提出基于主题情感混合的CTM模型(Sentiment and Topic hybrid Correlated Topic Model,STCTM),其实验结果也验证了CTM模型在相关性表示方面具有良好的性能。在实际文本表述中,评论内容中所蕴含的主题是相互关联的,因此基于CTM模型的信息处理和情感分析研究具有一定的应用价值和意义,但以上研究均采用机器学习的方法进行知识表示,无法解决词表示粒度稀疏的问题。
近年来,深度学习技术取得突破性进展,大量研究基于该技术使用神经网络构建情感分析模型,解决了传统机器学习中词表示粒度稀疏的问题,取得了一些建设性成果。目前,深度学习已经成为文本情感分析的主流研究方法和技术。
文献[9]中提出了长短期记忆(Long Short-Term Memory,LSTM)神经网络模型进行情感分析研究,在词嵌入层使用固定的词向量进行表示,忽略了词与词之间的先后顺序,导致情感监测结果存在偏差。而双向长短期记忆 (Bidirectional Long Short-Term Memory,BiLSTM) 网络[10]在文本句子表示时,结合当前词语的前后信息进行建模,更好地捕捉句子的位置信息和语境资源。文献[11]利用多层感知机抽取情感特征,但该方法在进行特征分割时,忽略了主题相关性对文本词句的影响,在句子表示中采用的组合矢量模型不能很好地捕获句子的位置信息,导致无法抽取到更深层次的情感信息。
综合考虑以上优缺点,本文将基于主题相关性和深度学习理论进行文本情感分析研究,在采用CTM模型获取文本相关主题信息的基础上进行文本词表示,并融合word2vec和BiLSTM模型,来提取文本情感分类信息。
1 基于主题相关性的特征分割算法
综合考虑以上优缺点,LRR模型[2]是一个半监督主题概率统计模型,采用基于自举的文本分割算法对在线评论文本进行特征分割,对每个特征首先人工给定一组种子关键词,基于这组初始特征通过卡方统计进行迭代,最后得到评论数据集的特征分割结果。该模型需要人工标注数据集,其精确度过度依赖于相关领域的专业水平,迭代过程中也没有考虑文本主题特征的相关性。
CTM模型在主题相关性表示方面具有良好的性能,本文采用该模型来获取文本主题相关信息,提出基于主题相关性的特征分割ASTC(Aspect Segmentation based on Topic Correlation)算法,将主题特征相关性量化后融入深度神经网络结构中,实现基于主题相关性的文本特征分割。
ASTC算法主要分为两个步骤:1、使用CTM模型获取主题相关信息;2、文本特征分割。下面对该算法的处理过程进行详细描述。
设D={d1,d2, …,dM} 是包含M篇文本的数据集,所涵盖的k个特征为A={A1,A2, …,Ak},所包含的词汇集为V={w1,w2, …,wN},V中包括N个互不相同的单词。
首先,调用R语言中CTM模型的相关工具包对D进行聚类处理,得到主题与单词之间的相关关系矩阵Q,Q∈Rk×N(k为主题特征个数,N为语料库词汇集V中单词个数);qij∈Q(i=1,…,k;j=1,…,N)表示第j个单词属于主题Ai的相关程度。
其次,对D中每篇评论做文本分割:对任意的dm∈D(m=1,…,M),将dm中包含的句子按序排列成句子集
S(dm)={sm1, …,smi, …,sml},
对∀smi∈dm(i=1,…,l),对照矩阵Q为smi中单词匹配相关程度最大值的主题,将匹配到主题Aj(j=1,…,k)下所有单词对应的相关关系值相加,进而得到smi属于主题Aj的相关概率值Pij(i=1,…,l;j=1,…,k),取max{Pij}对应的主题为句子smi所属主题,得到smi对应的主题特征向量
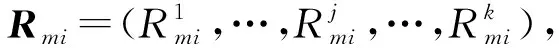
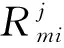
对D中所有文本完成特征分割后,可以得到评论集D中每篇评论di(i=1,…,M)关于特征集A的k个特征的M×k维分割矩阵T:
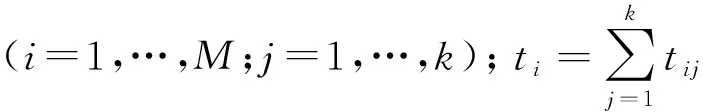
令wij=tij/ti,则wi=(wi1,…,wij,…,wik)即为评论di的预测特征权重向量,
为整个评论集的预测特征权重向量,αj=(w1j,…,wij,…,wMj)为整个评论集D关于Aj的预测特征权重向量。
2 情感分析神经网络模型
常用的传统情感分类存在诸多局限性,具备自动学习特征能力的深度学习在情感分析研究领域中得到越来越多的关注。
情感分析任务中常用的深度神经网络主要包括多层感知机[12]、卷积神经网络(Convolutional Neural Network,CNN)[13]和循环神经网络(Recurrent Neural Network,RNN)[14], 其中RNN因其对文本上下文信息的捕获能力而成为情感分析的常见研究工具,但RNN在训练过程中存在梯度爆炸和消失的问题,研究人员提出了LSTM[15],其每个单元使用3个门调节允许进入每个节点状态的信息量,从而更有效地保持长期依赖,克服了RNN梯度爆炸和消失的问题,BiLSTM是LSTM的进一步延展,可以从文本序列的前后双向获取上下文特征[16]。
在基于主题相关性的特征分割基础上,结合BiLSTM模型,提出基于主题相关性的BiLSTM情感分析模型(BiLSTM-based on Topic Correlation,BiLSTM-TC)。本文的情感分类问题为二元分类,BiLSTM-TC模型主要思想如下:
首先,采用word2vec模型进行文本词表示,将得到的主题特征向量与目标词的word2vec词向量进行交叉拼接,得到预训练词向量;接着,使用BiLSTM模型进行句子表示;最后,使用全连接层对语义信息进行提取,实现文本情感分类。情感分析模型如图1所示,共分为4层:输入层、句子表示层、全连接层和输出层。

图1 情感分析神经网络模型图Fig. 1 Sentiment analysis neural network model diagram
在输入层中,输入样本数据,用word2vec模型进行文本词表示,并将文本句子与主题-词相关关系融入词表示中,充分考虑文本所蕴含主题信息的影响,对情感分析结果起到优化作用。具体处理方法如下:
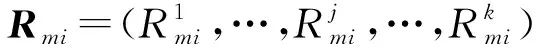
G=Rmi×Q,
(1)
式中:Rmi∈R1×k,Q∈Rk×N,G∈R1×N(k为主题特征个数,N为语料库词汇集V中单词个数),将该向量与word2vec词向量进行交叉拼接,得到词嵌入向量。
句子表示层中,采用BiLSTM进行句子表示,将输入层词嵌入的输出作为BiLSTM的输入来学习文本的语义信息,BiLSTM模型充分考虑文本词序列的先后顺序,从前后双向获取上下文特征,这更好地获取句子位置信息和上下文语境资源。
在全连接层,对句子表示层学习到的信息进行提取,使用公式(2)中ReLU函数进行激活:
g(x)=max{0,x}。
(2)
在输出层,针对二元情感分类,该层对应采用的激活函数为sigmoid函数,如公式(3)所示,所得到的输出向量为。中每个元素对应一个训练批次中的每个样本,其值介于0和1之间,越接近1,对应样本的情感倾向为积极的可能性越大; 反之,元素的值越接近0。计算样本标签y与的交叉熵得到损失值loss。
(3)
3 仿真实验
实验数据来自Yelp,它是最常用于情感分析的公开英文数据集之一,包括旅游、酒店、购物等领域的评论,包含560 000条验证集和38 000条测试集。考虑到总的数据集太大,本实验从Yelp验证集中抽取了200 000条作为训练集、10 000条作为验证集,从Yelp测试集中抽取了20 000条作为测试集。
实验采用的神经网络框架为tensorflow,它是目前最流行的深度学习框架之一。对于Yelp数据集,使用每个样本的前200个词作为词嵌入层的输入,该数量在情感分析实验中使用较为普遍,对于数量不足的进行随机填充达到200个。
将本文BiLSTM-TC模型与LRR模型、STCTM模型和使用word2vec的 BiLSTM模型进行实验对比,其中LRR和STCTM是基于机器学习的模型,BiLSTM和BiLSTM-TC是基于深度学习的神经网络模型。实验中使用准确率和F值作为评价指标,F值是精确率和召回率的调和平均值,用于综合反映模型性能的整体指标,其值越高说明实验方法越有效。实验结果如表1所示。
由表1中数据可以得出, STCTM的实验性能指标高于LRR,其中分类准确率高出2.28个百分点,F值高出2.28个百分点,说明主题相关性地加入对情感分析结果有提升作用;BiLSTM与BiLSTM-TC的准确率和F值均高于LRR和STCTM,其中分类准确率比LRR模型高出6.39和8.46个百分点,比STCTM模型高出4.11和6.18个百分点,F值比LRR模型高出6.05和8.9个百分点,比STCTM模型高出3.77和6.62个百分点,这说明基于深度学习的方法明显优于机器学习方法。另外,BiLSTM-TC的实验性能指标超过BiLSTM,其中分类准确率高出2.07个百分点,F值高出2.85个百分点,这证明了神经网络模型输入中融入主题相关信息,能帮助模型获得更好的分类性能。
为了考评本文模型在预测主题特征情感方面的精确程度,实验采用类似文献[2]中评价方法,用皮尔逊相关系数计算得到评论集D中每篇评论di(i=1,…,M)的真实特征权重向量和预测权重向量之间的相关关系,取均值后用σ1表示,以及整个评论集D关于Aj的真实特征权重向量和预测特征权重向量之间的相关关系σ2。
(4)
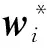
(5)
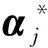
实验结果的对比结果如表2所示。
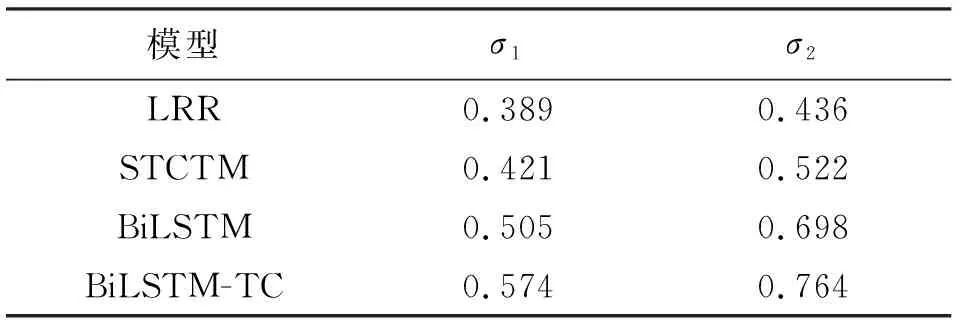
表2 几种模型相关关系性能指标对比Tab. 2 Comparison of performance indicators of several model correlations
从表2的数据可以得出,对于基于机器学习的LRR和STCTM模型,STCTM的σ1和σ2值高于LRR,说明主题相关性的融入能提高模型特征权重预测值的准确性;基于深度学习的模型BiLSTM与BiLSTM-TC的σ1和σ2值均高于LRR和STCTM,这说明基于深度学习的方法所预测特征权重和真实特征权重相关性更高,更接近真实值;本文BiLSTM-TC模型的σ1和σ2值高于BiLSTM模型,验证了神经网络模型输入中融入主题相关信息,能帮助模型得到与真实情况最为吻合的特征权重值。
4 结论
本文的情感分析模型结合相关性理论和深度学习技术,将文本隐含的相关关系融入神经网络模型中,在采用CTM模型实现文本特征分割的基础上,构造蕴含相关性信息的词向量,将其作为BiLSTM模型的输入,实现文本句子表示和情感特征提取。所采用的深度学习技术解决了机器学习中特征依赖和词表示粒度稀疏的问题,BiLSTM模型从文本序列的前后双向获取上下文特征,可以更好地捕获句子的位置信息。主题相关性理论的引入,能帮助模型抽取到更深层次的情感信息,实现网络海量评论的情感分析,可以推广到相关领域,有广阔的应用前景和理论意义。
