基于U型残差编解码网络的带钢缺陷检测算法
2023-08-05郭华平毛海涛詹尚桂孙艳歌
郭华平,毛海涛, 詹尚桂,孙艳歌,李 萌,张 莉
(信阳师范大学 计算机与信息技术学院, 河南 信阳 464000)
0 引言
带钢是工业生产中一种不可或缺的原材料,在航空航天、船舶、汽车等制造领域有着广泛的应用。然而,在制造过程中受制造工艺和生产环境等复杂因素的影响,带钢表面可能会出现各种类型的缺陷,如划痕、裂纹、斑块等。这些缺陷不仅会对产品的外观造成影响,还会影响其使用寿命。因此,带钢表面缺陷检测是现代工业生产中极其重要的一步。由于传统的人工检测方式受视觉疲劳、注意力分散等因素的影响,很难达到现代工业生产中高效性和实时性的要求,所以建立带钢表面缺陷自动检测系统对带钢质量控制具有极其重要的意义。人类视觉系统具有有效的注意力机制,受人类视觉注意机制的启发,显著性目标检测技术被用来快速检测缺陷对象。显著性目标检测可以快速捕捉图像中最重要视觉信息,并过滤大量背景干扰,所以其作为一种快速的预处理操作被广泛应用于各种计算机视觉任务,如图像分割[1]、缺陷分类[2]、缺陷检测[3]、目标跟踪[4]等。
目前,根据特征提取策略的不同,显著性目标检测方法主要分为基于传统模型的方法和基于深度学习的方法。前者先是手工制作视觉特征,然后根据先验知识和假设开发各种模型,例如稀疏编码、流形排序等。如BOLUKI等[5]提出了一种基于最优Gabor滤波的纺织面料实时检测自动算法。由于该算法对噪声很敏感,只能适用于特定的情况。为了解决上述问题,基于深度学习的显著性检测方法被提了出来。在真实值的监督下,深度学习方法可以自动学习丰富的图像表示,显著提高了缺陷检测的性能。尽管基于深度学习的显著性检测方法已取得了瞩目的结果,但它们在目标完整性和边界保留方面仍有一些不足。具体而言,现有基于深度学习的缺陷检测方法在分割缺陷对象方面仍具有以下缺点:1)在检测具有小目标的图像时,很难从紧凑的背景中分割出完整的缺陷对象;2)在处理杂乱背景或低对比度时,往往会引入背景噪声,无法清晰地检测出整个缺陷区域。
针对以上问题,本文提出了U型残差编解码网络(U-Residual Encod-Decoder Network,UDRNet),具体如下:
(1)提出一种基于编解码残差网络的显著性检测方法,该方法具有较小的模型规模且具有较高的检测精度和鲁棒性;
(2)在编码器阶段,利用全卷积神经网络(Fully Convolutional Network,FCN)[6]的优势,提取丰富的多尺度特征;同时,引入轻量级注意力机制,使模型更加关注重要的缺陷区域;
(3)在解码器阶段,使用所提出的U型残差解码块(U-shaped Residual Decoding Block,URB),以恢复在FCN的多个层中编码的显著性信息;同时,解码网络后添加了一个细化网络,以优化显著图中缺陷对象的边界细节。
为了使模型更好地定位缺陷区域,本文采用深度监督机制,6个监督信号分别被施加到解码器网络中的5个U型解码块和细化网络上,用于监督U型解码块和细化网络的预测。
1 提出方法
先详细介绍UDRNet的3个子模块,然后进一步阐述融合损失对网络输出完整结构和详细边界的重要性。
1.1 编码器网络
采用编码器-解码器结构的显著性检测方法,这种网络结构可以有效地融合低层丰富的纹理信息和高层详细的上下文语义信息,有助于精准预测缺陷对象的位置。与以往的编解码网络不同,本文使用ResNet-34作为特征提取的主干,采用残差网络作为主干,一方面,其不是简单地堆叠在一起,而是使用跳越连接;另一方面,残差网络实现较深层次的网络时,受梯度消失影响小,并且具有较低复杂性。
编码器部分具有1个输入卷积层和4个残差块(conv2-3、conv3-4、conv4-6和conv5-3)。输入卷积层和4个残差块都来自ResNet-34,不同之处在于,本文所提出模型输入层通道数为64,卷积核大小为3×3、步长为1,而不是7×7、步长为2的卷积核。为了进一步扩大感受野的大小,本文在输入层之后添加了一个步长为2的最大池化操作。最后,每个卷积的输出被送到BN层,随后使用ReLU激活函数来增强非线性表示能力。
近年来,注意力机制因其可移植性和高效性而被广泛用于各种计算机视觉任务中。因此,在ResNet-34[7]的每个残差基本块中嵌入了一个轻量级的卷积注意力机制模块,表示为RM-i(i=1,2,3,4)。RM的详细结构如图1所示。
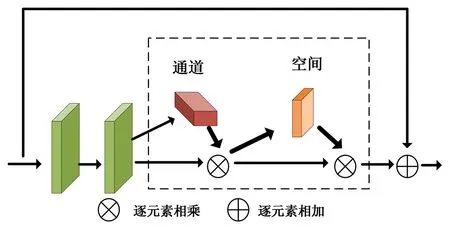
图1 RM的详细网络结构图Fig. 1 Detailed network structure diagram of RM
为了进一步捕捉全局信息,在编码器跟解码器之间添加一个空洞卷积模块,它是由3个512通道(扩张率为2)且卷积核大小为3×3的卷积层组成。为了与原始ResNet-34保持相同的分辨率,第一个卷积层以2的步幅进行下采样。然后,这些卷积层中的每一层之后是BN和ReLU激活函数。
1.2 URB解码网络
在显著目标检测与其他分割任务中,局部和全局信息都非常重要。但现有的大部分卷积神经网络,为了节省空间和提高计算效率,通常使用尺寸为1×1或者3×3的卷积核进行特征提取如VGG[8]、DenseNet[9]等。受尺寸限制,卷积核感受野较小,浅层的输出特征仅包含局部特征。为了获得更多的全局信息,最直接的方法是扩大感受野。传统的卷积神经网络是对图像先做卷积再进行池化操作,降低图像尺寸的同时增大感受野。但是由于图像分割预测的输出是逐像素的,所以只有将池化后的图像上采样到原始的图像尺寸再进行预测,才能使得每个像素都能看到较大感受野信息。
因此使用FCN图像分割中有两个关键点:一个是池化操作减小图像尺寸的同时增大感受野;另一个是上采样扩大图像尺寸。然而在尺寸变化的过程中,会造成一些空间信息的丢失。空洞卷积的提出解决了上述问题。空洞卷积的引入能扩大感受野和捕获多尺度上下文信息。另外空洞卷积还可以通过调整扩张率,从而获得不同的感受野。
综上所述,为了捕获多尺度特征,提出了一个U型的残差解码网络URB。URB-L(Cin,M,Cout)的结构如图2所示,其中L是解码器中的层数,Cin、Cout表示输入和输出信道,M表示URB内部层中的信道数。

图2 URB的整体结构Fig. 2 Overall structure of URB
URB主要由3部分组成:
(1)先是一个输入卷积层,把输入Cin通道的图像x转换为Cout通道的中间映射F1(x),这层是用来提取局部特征。
(2)高度为L的U型对称编解码结构,以中间特征映射F1(x)为输入,学习提取和编码多尺度上下文信息U(F1(x))。L越大,意味着URB就需要更多的池化、更大的感受野和更丰富的局部和全局特征。通过调整此参数,可以从任意空间分辨率的输入特征映射中提取多尺度特征。该方法先从下采样的特征映射中提取多尺度特征,然后通过逐步上采样、连接和卷积将其编码成高分辨率特征映射。这个过程减轻了大尺度直接上采样造成的细节损失。
(3)受ResNet的启发,一个跳越连接通过相加的方式融合局部特征和多尺度特征F1(x)+U(F1(x))。
残差块中的运算可以总结为
H(x)=F1(x)+U(F1(x)),
式中:H(x)表示输入特征x的期望映射,F1代表权重层。URB与残差块的主要区别在于URB将平面的卷积替换为U型结构,并用权重层转换的局部特征替换原特征。这种结构设计使得网络能够直接从每个残差块中提取多个尺度的特征。更重要的是,因为大多数操作都应用在下采样特征映射上,所以U结构的计算开销很小。
1.3 细化网络
在训练过程中,采用深度监督机制,以利于有用信息向缺陷对象区域传播。但输出显著图仍有部分细节丢失,因此本文提出了一个具有1D滤波器的残差细化结构(RRS_1D),如图3所示该结构遵循编码器-解码器风格。

图3 UDRNet网络结构图Fig. 3 Network structure diagram of UDRNet
细化模块的编码器和解码器都由4个级组成,每级由两个卷积层组成,后面是一个最大池化或双线性上采样单元。而桥接部分是具有64通道且卷积核大小为3×3的卷积层,随后是BN和ReLU激活函数。为了实现更深的网络层数,使用最大池化操作进行下采样。用于上采样的双线性插值的引入,是为了更好地匹配特征尺寸。另外,为了避免占据大部分计算复杂度的卷积,采用了两个专门的1D滤波器(即3×1和1×3卷积),有效地平衡了细化性能和计算效率。最后将Sigmoid映射后的细化图作为UDRNet的最终显著图。
1.4 损失函数
由于显著对象检测本质上也可以看作是一个密集二分类问题,因此它的输出是每个像素成为前景对象的概率分数,所以大多数以前的方法总是使用交叉熵作为训练损失。然而,这种简单的策略使网络很难捕捉显著对象的全局信息,从而产生了模糊的边界或不完整的检测结果。为了在边界定位和结构捕捉方面学习更详细的信息,在QIN等[10]工作的影响下,构造了一个融合损失来监督网络的训练过程。融合损失分别由BCE(Binary Cross Entropy)、IOU(Intersection Over Union)和SSIM(Structural Similarity Index)3种损失组成。因此UDRNet的总损失被定义为:
(1)
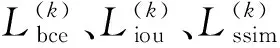
2 实验
2.1 实验配置
为了验证所提出的模型的有效性,在一个具有挑战性的公共带钢基准数据集SD-saliency-90[11]上进行了各种实验。该数据集总共包含900幅带有3种缺陷类型(夹杂物、斑块和划痕)的裁剪图像,每幅图像的分辨率为200×200像素。除此之外,SD-saliency-900也有SONG等[11]贡献的像素级注释。
2.2 评价指标
使用几个普遍认可的评价指标,评估了各种显著目标检测方法,包括MAE(mean absolute error)、WF(weightedF-measure)、SM(structure-measure)等。
MAE被用来测量预测的显著性图与真实值之间的差异,定义为
(2)
式中:N为测试图像的个数,ygt为真实图像,ypred为预测图像。
WF是F-measure的加权版本,用于克服插值缺陷、依赖性缺陷和同等重要性缺陷可能导致的不公平比较。定义为:
(3)
式中:Precison为准确率,Recall为召回率,w为权重系数,β为平衡系数(设置为1)。
SM用于评估预测的非二值显著性图和真值的结构相似性,定义为:
SM=αso+(1-α)sr,
(4)
式中:so为对象感知相似性,sr为区域感知相似性,α为平衡因子(通常设置为0.5)。
PFOM用于评估图像分割的边界质量,定义为:
(5)
式中:Ne和Nd分别是理想边缘点和真实边缘点的数量,dk是第k个理想边缘点与检测的边缘点之间的像素误差距离,β是缩放系数(实验中设置β=1/9)。
2.3 参数设置
使用NVIDIA TITAN Xp 图形处理器加速实现了基于Pytorch框架的模型。为了训练并比较其他深度模型,构建了一个标准的包含810个图像的训练集。该训练集随机从SD-saliency900数据集中选择的540幅原图像(每种缺陷类型180幅图像)和受噪声(ρ=20%)干扰的270幅图像(每种缺陷类型90幅图像)组成。这些噪声图像的原图像是从之前的540幅图像中随机采集的,有助于增强网络的鲁棒性。
在训练过程中,首先将每个图像I的大小调整为256×256,并随机裁剪为224×224,然后通过(1-μ)/σ进行归一化。均值μ和标准差σ分别设为0.466 9和0.243 7。此外,不使用任何验证集,而是训练模型直到训练损失收敛。训练时,采用初始化策略来初始化特征,网络的参数不是使用预先训练好的ResNet-34模型,而是通过初始化提取。其他层的参数通过使用Pytorch的默认设置来初始化。整个网络以端到端的方式进行训练。利用RMSprop优化器来训练所提出的网络,其超参数设置如下:学习率为(1e-3),而其他参数固定为默认值。训练过程大约需要7 h,在大约50 K次迭代后收敛,批量为8。测试时,将每幅图像简单地调整到256×256,并反馈到网络以获得其显著图。
2.4 消融实验
为了验证所提出的UDRNet模型中使用的每个关键组件的有效性,进行了消融实验。该消融研究包括结构分析和损失分析。所有的实验都是在SD-saliency-900数据集上进行的。
(1)结构分析
为了证明所提出网络模型中关键组件的有效性,使用MAE、WF和SM指标对模型进行了相关结构的定量评估。如表1所示,每次增加一个关键组件,模型的性能也会相应提高,所以包含组件CBAM、URB和RRS_1D的模型实现了最佳性能。其中“*”表示去除相关子模块,例如UDRNet-URB*表示不包含子模块URB的UDRNet模型。与基准模型相比,UDRNet在MAE上实现了26%的大幅降低,在WF和SM指标上分别贡献了3.0%和1.4%的收益。客观地证明了所提出的模型中的所有关键组件对于获得最佳的缺陷对象检测结果都是有用和必要的。
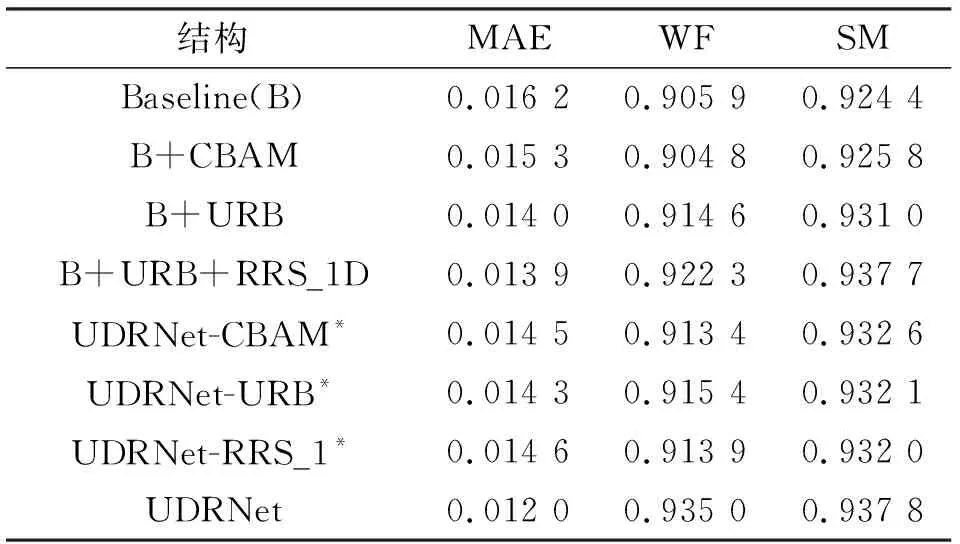
表1 结构分析Tab. 1 Structural Analysis
(2)损失分析
为了验证所构建的融合损耗的合理性,对UDRNet结构进行了一组不同损失的实验。如表2最后一行所示,配备融合损失Lall的UDRNet实现了优越的性能。与采用广泛使用的交叉熵损失Lbce的对应方法相比,WF和SM分别增长了2.50%和0.56%,而MAE则下降了14.00%。结果发现,使用Lall可以很好地保留缺陷对象的边界,并有效地抑制背景噪声的干扰。因此,这些结果说明融合损失能让本文提出的模型在边界定位中学习更详细和准确的信息。
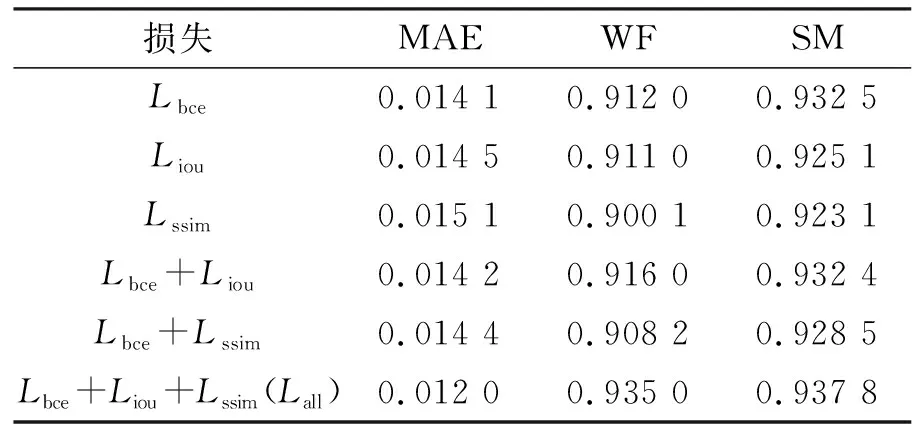
表2 损失分析Tab. 2 Loss analysis
2.5 结果对比
将提出的UDRNet模型与基于传统模型或深度学习的8种最新的显著性检测方法进行了比较,包括RCRR[12]、2LSG[13]、BC、SMD、PoolNet[14]、PiCANet[15]、CPD[16]和BASNet[10],如表3。为了公平比较,使用默认参数运行作者发布的源代码或可执行文件。值得注意的是,所有比较的深度学习模型都在所提出的标准训练集上重新训练。
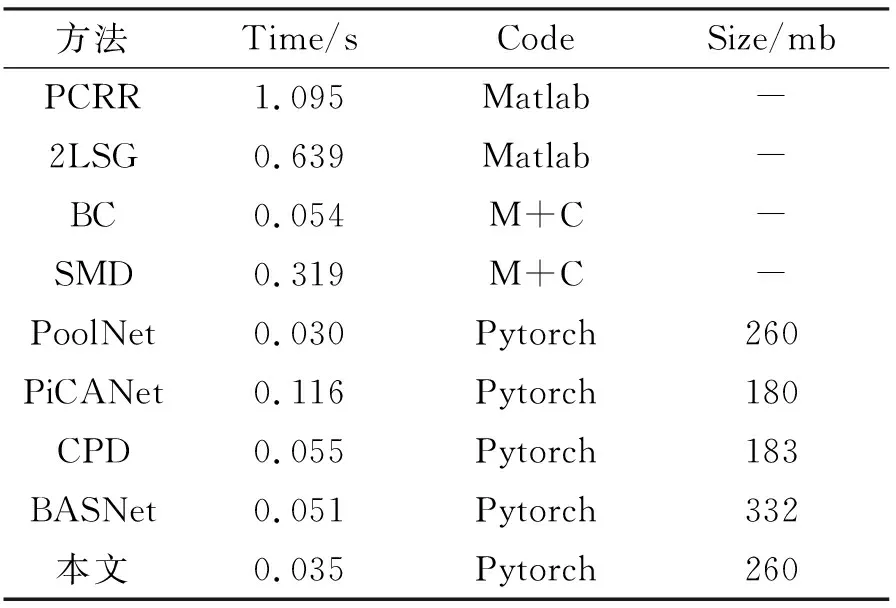
表3 运行速率比较Tab. 3 Running rate comparison
为了定量评估分割缺陷对象的质量,设置ρ=10%,表4中展示了所提出模型相对于8种最先进方法的性能。从表4可以看出,与现有的CPD[16]方法相比,在WF、SM和PFOM度量上分别实现了12.6%、8.6%和3.1%的提升。此外,与BASNet方法相比,所提出的模型在MAE上也实现了14.5%的大幅降低。而对于边界质量,UDRNet在PFOM度量方面比BASNet方法提高了1.9%。事实证明,所提出的模型性能更好。
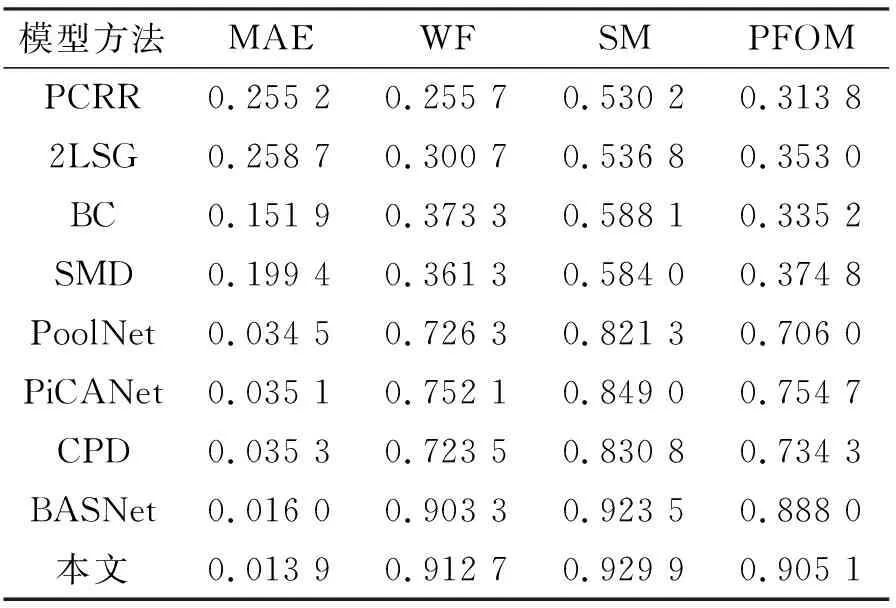
表4 与8种最新模型的性能比较Tab. 4 Performance comparison with eight state-of-the-art models
2.6 运行效率
在NVIDIA TITAN Xp的GPU上对比了8种显著性检测方法在SD-saliency-900数据集上平均运行时间和模型大小。对于一幅200×200的测试图像,本文方法在不进行任何其他的后处理情况下,只需要0.035 s就可以产生最终的显著图,除了PoolNet,比其他大多数竞争方法都快得多。虽然BASNet和本文的模型一样都获得了出色的检测结果,但BASNet的模型规模最大。相比之下,所提出的UDRNet尺寸还不到它的1/2。上述结果表明,UDRNet能够更好地满足当前工业缺陷检测的要求,但仍有不足,对于未来的工作仍有进一步提高其效率的空间。
3 结论
提出了一种新的端到端的编解码残差网络UDRNet来有效地检测带钢表面缺陷。通过结合深度监督和融合损失的方式,使模型能够捕捉更精细的细节,并且更容易优化。大量的实验表明,该模型在生成边界清晰的缺陷对象的同时,能有效地滤除背景噪声,最终生成几乎接近真实值的显著图。与其他8种最新的方法相比,UDRNet模型在4个评价指标上取得了最好的性能,并且具有很强的鲁棒性。此外,UDRNet不需要任何后处理,并且在单个GPU上以实时速度运行。
