汽车行业用户APP 精细化运营体系设计与实现
2023-08-05李思江吴文会方方梁宁陈娜程炎
李思江、吴文会、方方、梁宁、陈娜、程炎
(上汽通用五菱汽车股份有限公司,柳州 545007)
0 引言
随着智能化不断推进,汽车行业飞速发展,加之汽车消费需求也日趋放缓,我国乘用车市场模式从增量切换到存量模式[1]。汽车企业获得用户线索的方式,也逐渐从通过垂媒采买转变为从私域入手打造直面用户的平台,充分挖掘用户价值。而且,私域平台挖掘线索的成本也远远低于公域平台。
不过调研发现,虽然很多车企打造了私域平台,但大部分没有在用户购车、用车的全生命周期中做好用户运营,使得用户价值无法充分被挖掘,难以转化,投放效果与线索转化率普遍仍然偏低[2]。
1 私域提升变现效率解决方案
研究分析发现,私域平台之所以变现能力低,很大原因是运营模式没有站在用户购车用车的需求场景出发,没有挖掘出用户愿意为之买单的动机。企业要提升私域转化效率,可以搭建私域分层运营体系,根据用户标签将用户划分层级,针对不同级别人群的需求点,进行全生命周期培育和精准促进。
2 私域分层运营体系整体设计
私域分层运营体系主要由行为数据采集处理、用户分级和培育转化三大模块构成(图1)。其中,行为收集模块主要是对用户在客户端产生的行为动作进行采集、数据清洗和实时入库,是后续工作开展的基础。用户分级模块主要针对入库后的数据进行特征提炼,形成数据标签,再利用意向算法对用户进行意向分级评分,完成用户意向分级。培育转化模块主要负责对不同用户所处的不同意向级别进行精细化的运营,从而提升私域转化效率,最终完成私域变现。

图1 私域分层运营体系整体设计
2.1 行为收集分析
该模块主要负责收集和清洗用户在私域空间内产生的行为数据,主要在Hadoop 平台上实现。Hadoop 是一个开源分布式计算平台,以Hadoop 分布式文件系统(Hadoop Distributed File System,HDFS)和MapReduce 分布式计算框架为核心,为用户提供了底层细节透明的分布式基础设施以及极其可靠的共享分析和存储系统[3]。HDFS 的高容错性和高伸缩性等优点,允许用户将Hadoop 部署在廉价的硬件上,构建分布式系统。MapReduce 分布式计算框架则允许用户在不了解分布式系统底层细节的情况下开发并行和分布的应用程序,解决传统高性能单机无法解决的大数据处理问题[4]。用户在客户端上产生行为后,数据被实时采集。系统对某些特殊数据进行清洗,完成后实时入库,作为后续用户分级的基础输入。
2.2 用户分级
用户数据被系统采集入库后,是庞大而没有明显规律的。为了令数据具有识别性,需要引入用户标签体系。标签体系可以从基础标签、兴趣标签、行为标签和价值标签几个维度入手进行设计,标签设计的精细化程度会直接影响到用户运营的效果(图2)。

图2 标签样例
2.2.1 标签变量选取
用户标签数据是隐含的、事先未知且具备潜在商业价值的信息[5]。如今用户行为方式各种各样,庞大的用户标签数据中,该选择哪些行为标签表示为用户的意向级别。为此,首先要找到目标用户的共性行为。项目团队从购车前就在线上平台注册的用户中选取成功购车的案例进行行为分析,挖掘其中有共性的行为特点及规律,确定了主要标签变量。
项目团队将2 万个购车前注册的用户案例放入样本池,统计这些用户在购车前行为标签以及频率(图3)。行为特征出现频率高的,表示用户在购车前在私域内产生的共性行为,出现频率低的表示没有形成共性规律的行为标签,选取其中形成共性的行为标签确定具体变量。从2万个样本的行为标签中,可以识别出如“浏览时长、优惠政策和购车直播”等在成功购车用户群体中存在较明显的共性(图4)。那么,后续存在这些相似行为标签的用户,可以识别为具备潜在购车意向的线索进行培育。

图3 购车前用户共性行为示例

图4 选取模型变量示例
2.2.2 数据所处范围定位
虽然确认模型变量,但由于不同变量各自维度不同,有不同的计量标准,无法直接用于意向浓度的比较,所以需要进一步将各自变量值转化到同一计量标准开展使用。对此,项目团队采取变量映射到具体范围进行分级评分的思路转化变量。但是,范围边界如何定义,这可以使用聚类算法推出,并通过实践数据不断验证调整。聚类算法是将特定对象的集合有效地划分为多个组的一种方法。通过将抽象的或物理的对象有效地分为几个大类,并且每个独立的类中,对象都有相似的特性。而各组之间的对象不具备相似性。
将变量值对应的分数分为3 个分值等级(3 分、2 分和1 分),3 个等级的范围边界依据企业自身域平台的运营情况聚类分析之后定义,以近7 天的浏览次数pv_m 为例。
当一个用户近7 天活跃频率pv_m=15 次,该变量获得分值index_pv=3。当用户pv_m=3 次,则index_pv=1。
同理,近7 天浏览时长timespan 依据平台运营情况区分3个分值等级。
当用户7 天浏览时长timespan=10 min,该变量对应到特定范围区间时获得特定分值index_timespan=2。
需要特别注意的是,变量对应的分值范围并不是一成不变的,需要根据业务变化及时更新调整才能保证评分的合理准确。
2.2.3 变量加权系数
变量值对于意向浓度的贡献不一定是等同的。同样的分数,可能变量的组成不同,这会直接影响挖掘线索的有效率。此时就需要对变量进行加权处理。mn表示变量加权系数,其中n 表示变量,如浏览时长、优惠政策和车型评价等。通过样本抽样,计算变量点的有效率占比,根据变量点中有效率排名进行加权系数配置(表1)。
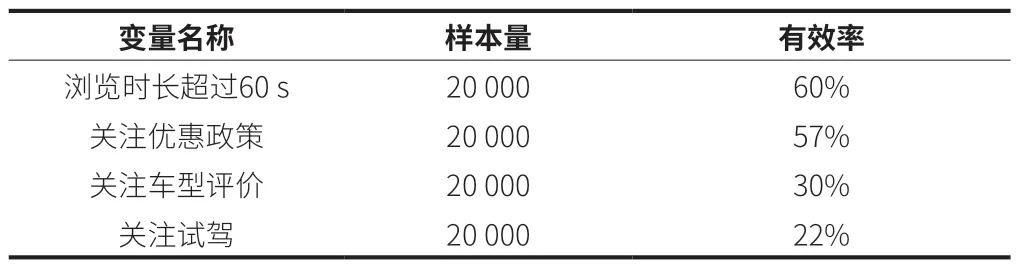
表1 各变量有效性分析示例
根据变量对线索有效率的影响,可以设计加权系数如下:m浏览时长>m优惠>m评价>m试驾。
2.2.4 意向综合得分
当确认好变量以及各变量的加权系数后,可以将其相加进行综合评分。
式中:user_score 为用户行为综合得分;index_n 为单个变量得分;mn为变量的加权系数。
综合得分可以反映用户购买意向以及用户价值,算出综合得分后,可以按需结合注册周期和会员等级等辅助标签将用户所在阶段对应为圈粉期、成长期、成熟期、衰退期和脱粉期。
2.3 培育转化
2.3.1 培育转化思路
根据数据挖掘和洞察分析完成潜客分层,基于用户场景的全周期运营才是精准运营的发力点。用户在购车前进入平台的契机通常是在线下或其他平台种草后,希望获得更详细的品牌资讯、优惠信息、车友生活和平台服务。从用户需求场景出发,线上私域平台可以在每个阶段进行针对性的促进动作,不断增强意向等级。并且,培育转化需线上线下双管齐下,同步促进,提高产品转化效率。
2.3.2 培育转化方法
面对不同层级的用户,需进行针对性的培育转化(图5)。

图5 面对不同层级用户的针对性培育转化
(1)圈粉期。此时用户刚接触产品,通过各种拉新方式引流进入私域平台,处在新手阶段,不知道该做什么或者可以做什么。这时需要降低用户的门槛,用直接、傻瓜的方式进行动线设计,引导用户对品牌形成认知,体验核心功能,加深品牌与用户之间互相的了解,比如新人专属限时礼包、内容种草等。该阶段运营指标可以重点关注用户活跃时长、交互步骤和互动频次。
(2)成长期。用户对品牌或某个车型有了初步了解与兴趣,此时需要加强用户的互动频次以唤起他们的兴趣,加深连接和引导高价值动作。这个时期的用户在内容上也需要有更多深层次的车辆细节和种草内容来辅助了解兴趣车型。此时可以给用户推送连续签到、试驾礼包、车友活动和车友生活等内容。该阶段的运营指标可以重点关注用户访问频次、互动频次、兴趣偏好和活动参与数。
(3)成熟期。用户深入了解产品并对产品产生下单的想法,此时的用户更关注优惠信息,开始比较择优,是促进成交的关键阶段。该阶段适合进行临门一脚的促进,例如限时直播优惠、限时下定礼包、限时定向优惠券以及专属顾问促进等。该阶段的运营指标可以重点关注留资数和成交数。
(4)衰退期。这个时期用户活跃度开始下降,此时可以参考RFM 模型和会员等级,区分识别出高价值用户。针对这部分活跃度下降的用户可以进行针对性的用户召回,例如对价格敏感用户推送限时优惠,组建会员福利群,增加1 对1 服务频次以了解活跃度下降原因等。该阶段的运营指标可以重点关注召回情况。
(5)脱粉期。该阶段用户活跃度持续下降,如果是高价值值得维护的用户,可以增加电话回访了解用户需求,针对用户痛点进行调整。
3 实施验证
为验证模型有效率,项目团队用连续3 个月时间观察验证,期间使用控制变量验证并逐次调整模型变量及评分标准。
该项目自2023 年3 月、开始通过上述方案对用户行为进行评分,完成用户分层,针对每个层级的用户进行精细化的运营促进。截止至2023 年6 月,私域平台通过算法挖掘到的线索量较3 个月前提升1 倍,线索有效率提升5%,挖掘的线索成交量提升2.6 倍,提升效果明显。
实践表明,相较传统的运营方案,汽车行业私域平台使用精细化培育促进方案能够更大限度地挖掘用户需求,创造更大的用户价值,帮助汽车企业提升私域转化效率。
4 结束语
本文基于汽车行业对于私域平台运营的需求分析,发现当前行业私域转化困难的问题现状并提出解决方案。通过私域精细化运营平台的设计与实现,并且在品牌私域APP 进行为期3 个月的实践验证,可以看出基于用户全生命周期的精细化运营模式对线索的挖掘和促进起到有效的提升作用。下一步项目团队将持续优化用户综合评分的评分标准,以及各生命阶段运营的动线设计,帮助企业更进一步提升业务转化效率。