基于样式生成对抗网络的风景园林方案生成及设计特征识别
2023-08-01陈然赵晶
陈然 赵晶*
人工智能如何理解设计特征?这是一个关键而亟待解决的新问题。近年来,人工智能技术在图像处理、语音处理、自然语言处理(natural language progressing, NLP)等领域取得了突破,为风景园林设计领域提供了新的可能性。尤其是一些基于深度学习技术的图像生成模型(如Midjourney、Dall-E、Stable Diffusion 等新应用工具),可以根据用户简单输入生成具有创造力的图像,似乎能产出令人满意的设计结果。然而它们能否捕捉到设计作品的本质、规律和逻辑?还是仅能基于图形生成图形?这些问题具有重要的理论和实践意义,也面临着巨大的挑战,涉及诸多方面问题。
1)“AI 算法驱动的设计循证”——当今技术背景下产生的新问题。大多数传统数字景观技术是用人工逻辑进行正向推导,从而产生可“循证”的设计结果。深度学习与传统方法不同,它不是用人工逻辑进行正向推导,而是利用海量数据训练,从中发现隐式规律,并用它们进行再创造。但由于“黑盒”效应,神经网络所习得的“隐式规律”可解释性较低,也难以循证,这是关乎技术落地的重要问题。
2)“AI 算法驱动的人机协同方式”——敏感且尖锐的行业问题。神经网络在生成设计方案时,本质上是通过海量数据训练,拟合从条件到设计结果之间的“映射关系”。这个“映射关系”就是设计师最核心的工作——生成方案。探究算法理解并生成方案的逻辑是重要的科学问题,这关系到算法可以从什么方面、什么角度辅助设计师工作。
3)“算法可解释性”——富有挑战性的高难度技术问题。从设计师的角度,风景园林设计本身就是一项难以量化的工作,设计工作往往依赖于直觉、经验、情感等难以表达和传递的因素,其思维过程也不一定是线性和逻辑性的,很难用量化和标准化的方式来定义和评价;从算法的角度,算法可解释性研究是目前学界无法完全解决的问题,也是持续的研究热点。
1 相关研究
1.1 从深度学习到AI 生成设计
人工智能技术的快速发展对设计领域产生极大冲击,得益于深度学习技术特殊的学习能力。深度学习是人工智能的关键技术,可以通过大量数据训练拟合事物间的映射关系,挖掘事物规律。
深度学习于20 世纪60 年代被提出,但近10 年来才开始迅速发展,逐渐被社会各界所认识。2012 年,AlexNet 由Alex Krizhevsky[1]提出,在ImageNet 视觉识别比赛中获得第一名,自此深度学习开启了新的纪元。2015 年,微软ResNet 系统在ImageNet 图像分类竞赛中刷新了纪录,实现3.6%的错误率,首度超过人类表现[2]。2016 年,AlphaGo 算法以深度学习和强化学习为核心,击败了围棋世界冠军,人工智能开始走进公众视野[3]。仅隔一年,AlphaZero 在2017 年被提出。它无需人类的数据和指导,用自我博弈强化学习的方式,在40 天内打败AlphaGo,证明了强化学习的特殊能力[4]。同年,Pytorch[5]、Tensorflow[6]等框架相继发布,方便了更多的研究者快速调用成熟的深度学习算法。自此,深度学习在各个领域百花齐放。
深度学习主要应用领域包括NLP、计算机视觉(computer vision, CV)。在NLP 领域中:2017 年,Vaswani、Ashish 等提出了框架Transformer[7],2018 年,openAI 公司在其基础上提出了GPT 系列模型,从此GPT 系列每年一更新,从GPT-3、Embeddings、GPT-3.5,到现在的ChatGPT[8]。在CV 领域中:2017 年,循环生成对抗网络(CycleGAN)[9]、图到图翻译的条件生成对抗网络(Pix2Pix)[10]等算法开始进入设计领域,奠定了AI 生成内容(artificial intelligence generated content, AIGC)[11]的基础,随后,在2018 年,英伟达公司提出了样式生成对抗网络(StyleGAN)[12],又于2019 年 提 出 了GauGAN[13],直 到2021 年,openAI 公司提出CLIP 多模态图文处理模型[14]、DALLE 图像生成工具[15],2022 年Midjourney公司、Stability AI 公司、Adobe 公司等相继推出Midjourney、Stable Diffusion、Adobe Firefly等商用级产品,AIGC 开始进入高速发展期,与设计领域产生越来越多的交互。
也正是在近几年,风景园林智能化革命逐步从参数化时代走向人工智能时代,AI 技术与设计行业走向交汇处[16-17]。人工智能算法类型众多,分类方法众多,在风景园林中的应用可以分为人工生命类、智能随机优化类和机器学习类[18]。其中机器学习是最为关键的分支之一,它具有强大的学习能力,可以通过大量数据训练拟合事物间的映射关系。机器学习在风景园林中的应用又包括景观评价[19]、景观格局模拟预测、生成设计(generative design)[20]。其中深度学习比其他机器学习算法的学习能力更强,神经网络的深度更深,有更强的拟合能力,更加适配生成设计问题。
1.2 深度学习在生成设计中的应用
生成设计是一种由设计师和计算机协同工作的设计流程[21],即在设计师给定设计空间的基础上,借助计算机的数据计算高效生成大量设计方案,其次基于用户限定筛选出符合要求的高质量方案。生成设计的发展大致经历了参数化、智能化、深度学习3 个阶段[16-17]。参数化设计方法扩展了传统设计方法的可能性,推动了计算机辅助设计在设计过程中的位置[22];智能化时代,生成设计领域产生了元胞自动机应用、遗传算法应用、多智能体系统应用等多种技术手段[23]。近年来,深度学习的快速发展为生成设计优化和广泛应用提供了可能性,也成为当前风景园林智能化改革的主要技术路线之一。
生成设计主要应用深度学习中的生成算法,包括生成对抗网络(generative adversarial network, GAN)系列、扩散模型(diffusion models)系列、流形模型(flow models)系列、自编码器(auto encoder, AE)系列。GAN 系列通过多个神经网络之间相互对抗约束,而不是单纯逼近最优解,生成结果既能约束,也富有多样性,在生成设计中应用较多[16,24]。
基于GAN 的场景效果图生成领域的研究涉及的专业较多。由于效果图与自然场景图像较为相似,数据量较大,主要研究问题不仅是规划设计的专业问题,更多集中于基于GAN 的城市场景及城市要素分析,比如城市建筑足迹提取及变化检测[25-29]、城市建筑细部分析[30-32]、城市车辆轨迹预测[30,33-37]、城市扩张分析[34,38]、城市遥感影像分析[39-45]等。
基于GAN 的平面图生成包括了大量空间规划的设计专业性问题,相关研究主要集中于规划设计行业。该领域从建筑室内方案生成开始[46-54],逐渐拓展到规律性较强的室外空间生成,如住区、校园等[24,55-60],近年开始往风景园林等复杂空间对象发展[61-65]。该领域研究问题主要集中于如何约束算法进行空间规划和优化。
可见,基于深度学习的平面图生成相关研究更加契合规划设计本质,是“人工智能理解设计”的核心部分。
1.3 从设计理解到高维特征识别
如前文所述,平面图生成的研究是“人工智能理解设计”的核心部分,但目前还较少有“人工智能理解设计”相关的探索,主要研究问题集中于如何构建生成设计技术流程,以及如何将该流程迁移到更复杂的空间规划工作。
在基于深度学习的生成设计技术中,设计条件和结果间的映射关系由算法训练习得,可解释性较低,“人工智能理解设计”的研究就集中在如何构建、提取、分析这个映射关系。目前已有研究主要集中在基于图(graph)的建筑室内生成设计,图是一种可以凝练大量实体和实体间关系的数据结构,该细分方向主要的技术方法是将设计要素(如建筑室内的功能布局、建筑室内设计要素)凝练于图中,用于约束算法进行可解释的生成任务[47,49]。
但由于风景园林设计工作过于复杂,包含了大量非线性逻辑的推理过程,以及大量难以界定的模糊边界、多种复合功能的空间,甚至难以确定设计要素、要素关系分类(例如,拓宽的园路属于广场还是园路?应该以实体要素还是以视觉感知为分割界限限定围合空间?)这种难以量化的评价逻辑限制了图神经网络(graph neural network, GNN)在风景园林生成设计中的应用。
从算法的角度,该问题本质上是因为风景园林方案包含大量难以解释的抽象特征,而且特征之间存在大量的特征耦合性(feature coupling,是Tero Karras 在StyleGAN 算法原文中提出的概念,指不同数据特征之间的影响程度)[12],因此“如何解开风景园林特征耦合性、探究高维抽象设计特征”是在研究“人工智能理解设计”之前的必要步骤,也是笔者研究的关键科学问题。
因此本研究拟借助StyleGAN 技术,通过大量的设计方案训练算法,抓取算法内部隐空间特征,分析算法能否识别风景园林方案抽象设计特征,可以识别哪些特征,以及能否解开特征耦合性。
2 研究方法
本研究首先运用设计方案数据集进行StyleGAN 的算法训练,令算法生成多样化的设计方案;然后利用主成分分析(principal component analysis, PCA)降维方法可视化算法内部隐空间,分析算法以何种特征指引多样化的设计方案生成,以探究神经网络如何理解设计特征。
2.1 StyleGAN 原理
StyleGAN 可以通过控制不同层次的风格特征实现对生成图像的细粒度编辑。该算法主要由映射网络(mapping network)、生成网络(synthesis network)2 个部分组成。整个正向传播过程如下。
1)随机噪声向量z(一种服从标准正态分布的随机向量,无规律的随机噪声可以增加生成图像的多样性)通过8 个全连接网络层得到w 向量。w 向量是一种经过特征解耦的隐空间向量,难以直接可视化,其中包含了不同层次的风格特征,这也是本研究关键的研究内容。
2)w 向量再控制生成网络进行多样化图像生成。在生成网络中,常数向量(一种服从标准正态分布的固定向量,无规律的固定噪声可以作为生成图像的初始状态)通过类似于渐进式增长生成对抗网络(progressive growing of GANs, ProGAN)的架构,从4×4到8×8 逐步生成高分辨率图像,生成内容从低分辨率逐渐到高分辨率。在这个过程中,不同深度层(风格特征层)上的w 向量分别控制生成方案的不同尺度信息。w 向量就在这个过程中,传到与每个层次相对应的部分,通过自适应实例归一化(adaptive instance normalization, AdaIN)操作控制不同尺度的特征,不同深度层(风格特征层)上的w 向量分别控制生成的设计方案的不同尺度信息,如从空间布局,到路网结构,再到细部纹理、树种等。这种架构使得StyleGAN 能够实现风格特征和生成网络之间的解耦,即不同风格特征层上的w 向量可以独立地影响生成方案的不同尺度信息,而不会相互干扰。此外,为增加图像多样化,w 向量与随机噪声通过加法操作同时控制每个层次的细节信息(此处的随机噪声与向量z 不同,是另一个服从标准正态分布的随机向量,目的是增加生成图像的细节变化)。
2.2 StyleGAN 应用方法
该算法通过大量数据训练习得不同的设计特征,生成不同的方案。其中,w 向量包含了每个生成方案的特征。因此本研究的关键部分是探究w 向量,包括“w 向量数据特征分析”“w 向量语义信息分析”。
2.2.1 w 向量数据特征分析方法
在本研究中,我们使用了2 个概念来描述和分析StyleGAN 生成的图像:风格特征和设计特征。风格特征是指w 向量在不同深度层(风格特征层)上控制图像生成的不同尺度信息,是算法的概念,包含了部分设计特征,也包含了其他图像特征。它反映了StyleGAN 如何将随机噪声向量z 映射到具有不同风格特征的向量w,并且如何将w 注入合成网络中生成高质量的图像。设计特征是我们对图像进行研究和分析所使用的概念,它反映了我们如何从图像中识别或提取具有语义的特征,如风景园林方案抽象设计特征。w 向量包含了风格特征(算法概念);风格特征中既包含了设计方案中的设计特征,也包含了非设计特征的其他特征。本研究目标是研究w 向量中能提取什么设计特征。
w 向量存在于高维空间,难以可视化,因此笔者通过降维、聚类与图像嵌入2 个步骤完成w 向量的分析。
1)降维:由于w 向量(设计特征)由z向量(随机噪声)经过映射网络得来。因此将w 向量与z 向量同时降维并可视化,通过数据分布初步分析算法能否提取有规律的特征信息。
2)聚类与图像嵌入:仅根据数据分布难以分析算法习得的特征是否为设计特征,因此进一步将多个w 向量进行聚类,并将每个对应的生成方案嵌入w 向量的数据分布中,通过生成方案的设计特征差异进一步分析算法能否有效提取设计特征。
2.2.2 w 向量语义信息分析方法
在本研究中,我们假设存在一个所有方案的“平均方案”(即抹除了特定设计特征的方案),来分析每一个生成方案与“平均方案”的差异,从而得到该生成方案对应的w 向量包含的最重要的设计特征信息。
为了实现这一目标,我们需要借鉴StyleGAN 框架中的截断(truncation)技巧。这种技巧可以通过调节不同层次的特征影响强度,观察在同一w 向量影响下,生成结果的连续变化。这与本研究的假设有相似之处,即不同层次的特征对风格迁移的影响程度不同。截断后的特征向量 的计算式如下:
式中,w 为每个生成方案对应的原始特征w向量;为平均特征w 向量,是W 空间中分布的所有特征点的平均点;φ为截断系数,是可人为调整的超参数,一般情况下0 ≤φ≤1(但实际操作中φ也可以在这个范围之外)。该方法通过计算到所有点的距离,再进行统一压缩,将所有数据点聚拢。
因此,当φ为1 时,截断后的特征向量为原始特征,对应的生成方案保留特定设计特征:
当φ为0 时,截断后的特征向量为平均特征,对应的生成方案即“平均方案”:
因此,通过截断技巧,调节φ从0 到1,可以分析方案在同一w 向量不同强度影响下,从抹除所有特征信息的“平均方案”,到包含该w 向量完整特征的“特定生成方案”的连续变化。以此回应前述假设,分析每一个w 向量所内含的设计特征语义。
2.3 数据来源
本研究数据来源包括2 个部分:4 047 个多样化设计方案(下称通用数据集)、105 个针对同一场地的“一题多解”方案(下称定向数据集)。其中通用数据集来源于公开资料,由27 个风景园林专业本科生、研究生在设计网站上搜集、处理,包含了多种类型绿地空间设计方案;定向数据集来源于北京林业大学园林专业学生作业,包括针对同一场地(北京市海淀区西北旺一处10 hm2绿地空间)的105 种不同风格的设计方案。
这2 套数据集分别用于探究不同内容。数据集的选择会影响StyleGAN 拟合映射关系和提炼通用设计特征的难度和效果。如果数据集风格过少,即数据集中包含的设计特征过于单一或相似,那么StyleGAN 可能无法学习到足够多样或丰富的设计特征,也无法反映出不同设计特征之间的差异或联系。如果数据集风格过多,即数据集中包含的设计特征过于多样或复杂,那么StyleGAN 可能难以拟合映射关系,也难以提炼出通用的设计特征,因为不同设计特征之间可能存在冲突或干扰。
2.4 算法训练
StyleGAN3 多用于多角度动图的训练生成,而风景园林设计方案是静态的平面图图像数据,因此StyleGAN3 不适用于本研究。本研究采用StyleGAN2 模型,训练采用512×512 分辨率,在双卡NVIDIA 3090 GPU上运行,显存为64 GB。其中,为更好习得设计规律,针对通用数据集的训练开启数据镜像增强功能;而针对定向数据集的训练中,为保持场地红线不变,不开启数据镜像增强功能。
3 结果分析
本研究针对2 个数据集训练了2 个生成器(下称通用生成器和定向生成器),通用生成器生成的方案风格多样,包括了多尺度、多类型方案,其生成结果多样性高,但由于数据风格差距过大,方案局部细节效果较差(图1)。定向生成器生成了同一场地的不同风格设计方案,整体设计内容稳定,细节丰富,但多样性较差(图2)。

1 通用生成器生成方案结果Results of scheme generation by universal generator
生成结果并不是本研究的主要目的,拆解算法并理解算法才是关键问题,因此下一步进行算法内部的向量推理,以理解算法如何习得设计特征。
3.1 w 向量数据特征分析结果
设计方案由w 向量控制,w 向量中包含了设计方案的所有特征,每一个w 向量控制一张图像。下面将从“w 向量降维分析”和“w 向量聚类和图像嵌入”2 个方面进行分析。
3.1.1 w 向量降维分析
w 向量的降维分析包括2 个步骤:1)单w 向量分析:将单个生成方案的w 向量拆解分析,初步分析w 向量是否有习得特征;2)多w 向量分析:将多个生成方案的w 向量展平到二维空间,从整体分布上验证是否有习得特征。
w 向量(设计特征)由z 向量(随机噪声)经过映射网络得来。在同一个生成器中,所有的生成结果都来自同一分布,但不同的z 向量会对应不同的w 向量,w 向量决定了图像的风格特征。因此笔者采用PCA 将2 种向量分别降到二维,并可视化,以分析z 向量和w 向量之间的变换关系。
在单w 向量分析中,我们选取最有代表性的平均特征w 向量()进行分析。该特征向量为16×512 的数据矩阵,即16 行,每行512 个数据。由于w 向量进入生成网络前未逐层经过AdalN,所以16 层信息是均布的,即16 行数据是相同的。因此只取w 向量中的第一行进行数据分布统计,并与输入的z 向量对比,可见w 向量经过映射网络之后已经将趋近于标准正态分布的z 向量转换为带有特征的w 向量(图3)。这证明了映射网络可以将随机噪声z 向量转换为带有特征的新的向量,初步证明了映射网络已经习得某种特征。

3 z 向量和w 向量数据特征对比Comparison between the data features of z vectors and those of w vectors
平均特征只证明了算法可以习得特征,而多样化的特征需要随机输入大量z 向量测试。因此进一步输入多个随机z 向量,通过映射网络转换为多个w 向量,对比多个z 向量分布和多个w 向量的分布,分析算法能否生成不同的设计方案特征。
w 向量与z 向量都是高维数据,无法直接可视化。因此将所有向量展平、合并、降维到二维平面。这些z 向量代表了多个抹除所有信息的随机噪声,w 向量代表了生成器生成的多个多样化设计方案的特征信息。
对比多个z 向量和多个w 向量分布结果(图4),发现输入的多个z 随机向量是完全随机分布的,而输出的w 向量带有明显的特征,初步证明映射网络可以习得多样化设计方案特征,且可以猜测特征中心即设计方案中的特征均值。

4 多个z 向量和w 向量分布的对比Comparison between the distribution of multiple z vectors and that of multiple w vectors
3.1.2 w 向量聚类和图像嵌入
经过分析,发现w 向量带有一定的特征信息,而这些信息能否反映设计方案信息,则需要进一步进行聚类和图像嵌入可视化。
1)采用K 均值聚类方法,根据特征相似度对w 向量进行聚类。对通用生成器和定向生成器的100 个生成方案进行测试,不同分类用坐标点颜色表示,包含3 个要素以上的类别用连线框选。
2)将图像嵌入不同的w 向量,分析算法习得的设计方案特征。每张图像对应一个w向量(图5)。生成结果显示,通用生成器所生成的w 向量中,算法可以大致提炼并归类特征,但分类逻辑不同,有根据形态、根据水体面积、根据软硬质比例、根据路网结构、根据公园类型等多种分类逻辑,甚至有的类别是根据同一设计节点出现的频率分类。

5 通用生成器w 向量聚类与图像嵌入w vector clustering and image embedding of universal generator
算法根据w 向量特征相似度分类,因此聚为一类的图像中,w 向量特征是较为相似的。而w 向量代表了方案的特征,因而可以推断算法将聚为一类的图纸视为同一类型设计特征。通用生成器的生成结果表明,该生成器难以提炼出准确的分类逻辑。在分类结果中,同一类别设计方案差距较大,可以初步推断是数据集风格差异过大导致的。该数据集包含的数据内容涵盖了风景园林大多数设计风格,差异极大,相对于如此复杂的设计特征,数据集样本数据量小、网络体量参数量少、训练时间短,因此难以拟合如此复杂的设计规律。
定向生成器的生成结果表明,当数据集里的图像相似度较高时,分类逻辑更清晰,特征解耦程度较高。从整体上分析,类别间差异较大,多样性高,可以生成不同类型的设计方案。从聚类图像局部分析,每个类别中的设计方案较为相似,但设计细节存在差异(图6)。
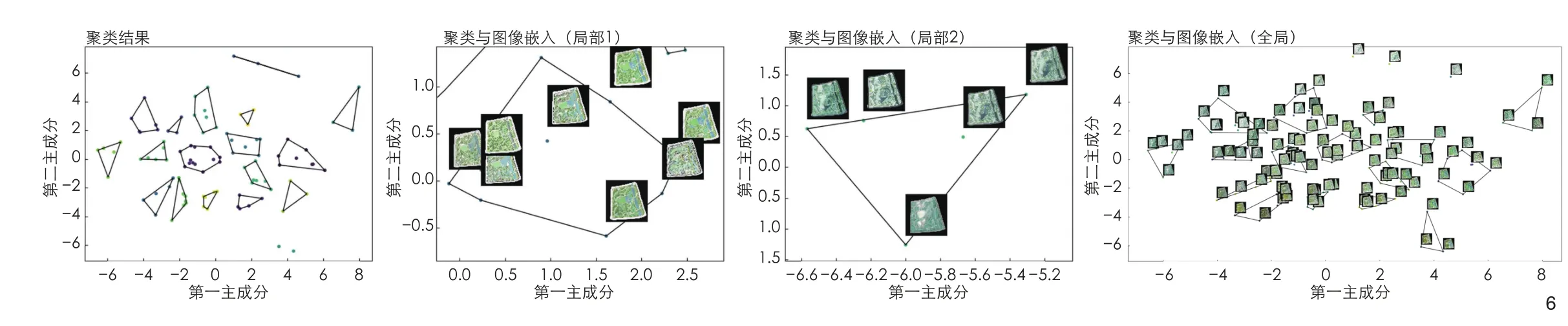
6 定向生成器w 向量聚类与图像嵌入w vector clustering and image embedding of directional generator
3.2 w 向量语义信息分析结果
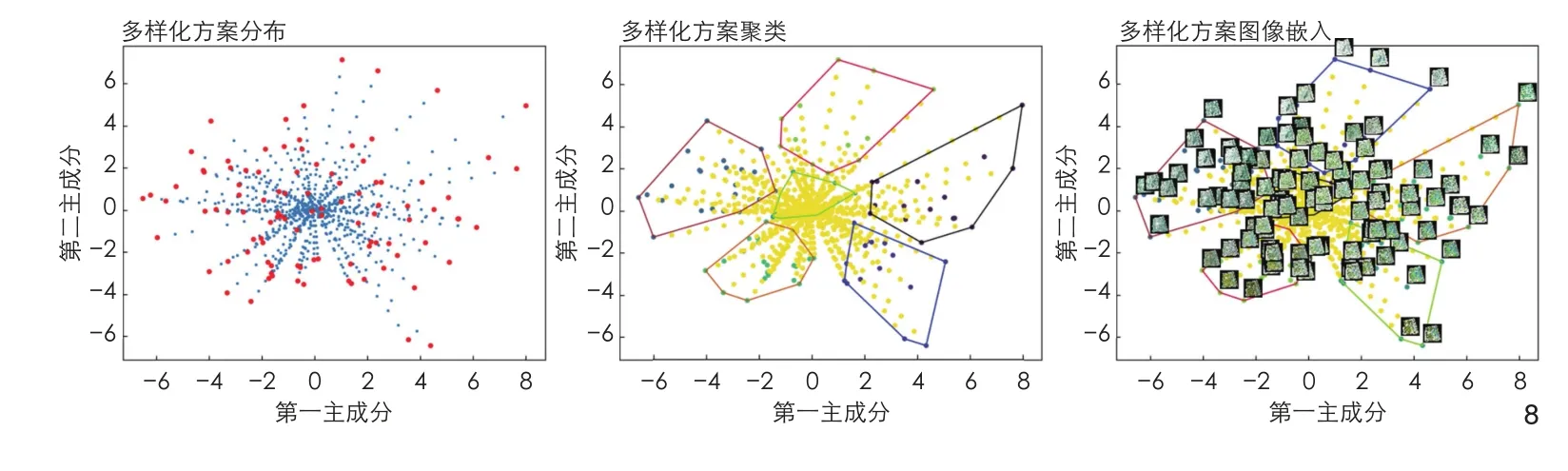
本节采用截断技巧截断w 向量:设置截断系数 为0~0.9 的10 个连续浮点数(步长为0.1),基于前文100 个随机z 向量,共同约束算法生成1 000 个w 向量。
进一步嵌入图像分析,可以可视化生成器生成的平均方案。定向生成器可以从多种方案中总结通用的设计框架,该设计方案可以代表最适宜该场地的设计方案,其他的多样性方案都是基于此框架进行设计内容上的微调(图7)。

7 平均w 向量及平均方案Average w vector and the average scheme
将定向生成器的完整w 向量(为1)标红、聚类、嵌入生成结果,得到100 个带有完整设计特征的多样化设计方案(图8),从中选取5 个方案(图9~13)深入分析。从0 到0.9 调节 ,分析w 向量在不同的截断系数影响下的变化。受到截断系数的影响,方案特征向特定方向变化,可基于方案特征变化的方向分析该w 向量所包含的语义特征。

8 多样化设计方案聚类及图像嵌入Clustering and image embedding of diversified design schemes

9 案例一:特征连续变化影响下的植被郁闭度变化Case 1: Change in vegetation depression under the influence of continuous change in features
10 案例二:特征连续变化影响下的水体面积连续变化Case 2: Continuous change in water body area underthe influence of continuous change in features

11 案例三:特征连续变化影响下的硬质铺装面积与分布连续变化Case 3: Continuous change in area and distribution of hard paving under the influence of continuous change in features

12 案例四:特征连续变化影响下的活动广场分布、植被连续变化Case 4: Continuous change in the distribution of active squares and vegetation under the influence of continuous change in features

13 案例五:特征连续变化影响下的水体形态变化Case 5: Changes in water body morphology under the influence of continuous changes in features
在案例一、案例二中,w 向量代表的意义分别是植物郁闭度、水体面积。从结果可见,算法可以在完全没有其他信息的情况下,仅通过大量设计方案习得植物郁闭度与水体面积等抽象指标含义。在截断系数的影响下,案例一的方案基本结构保持不变,植物郁闭度整体增加,植物围合的草坪空间减少。算法能考虑植物群落边缘丰富灵活的点状种植,创造多样植物空间。案例二在截断系数的影响下,方案基本结构保持不变,水体面积整体减少。算法能灵活地降低水域深度,从湖面逐渐变为湿地最后再变为草地,将整个河道变为小溪。
案例三、案例四都是针对铺装广场相关指标的变化,但由于铺装广场分布变化会影响整个方案结构布局,因此在案例三中硬质铺装面积与分布持续变化,与此同时,整体的植物、水体都有细微的变化。同样问题出现在案例四中,方案在保持硬质广场总体面积基本不变的情况下,硬质铺装位置分布连续变化,也会影响部分植物种植的布局。这种问题是特征缠绕引起的,说明算法无法完全解耦特征,但由于设计工作的特殊性,这种特征缠绕一定会出现。例如铺装广场的布局变化会导致空间视域方向的变化,必然会导致植物种植群落的改变。
案例五则出现了更严重的特征缠绕,算法在修改水体布局的时候,整个方案的多种特征同时变化。甚至在方案变化过程中,不同阶段的截断系数变化主要影响的特征不同,如 取值0~0.4 的时候主要修改方案铺装广场分布和路网结构,取值0.5~0.9 的时候主要修改水体形态和种植群落分布。可见,如果再对w 向量进行微调,可以挖掘同一个w 向量中的不同设计特征。基于此,本研究最后进行了4 个w 向量的截断系数微调测试。结果表明:通过微调截断系数,算法可以区分出植物郁闭度、路网密度、驳岸硬化程度、路网结构4 种高级设计属性(图14)。

14 w 向量截断系数微调Fine-tuning of vector w truncation coefficients
4 结论与展望
本研究应用StyleGAN2 算法挖掘风景园林设计方案设计特征,通过数据分布可视化、聚类、图像嵌入等技术方法探究神经网络中人类不可解的部分,以探究人工智能算法如何理解风景园林设计特征,推进智能设计循证研究。笔者发现,人工智能算法可以识别、提取设计方案中部分高维设计特征。算法识别的特征中,不仅包含了图像形态特征,也包含了富含设计语义的高维设计特征。
但目前算法识别的大部分特征还是难以解耦:一方面是因为风景园林设计工作的复杂性,评价指标难以量化;另一方面是因为算法本身的不可解释性,从神经网络黑盒中提取出有效信息难度较大。但即便难度大,算法驱动下的设计循证依然是一个非常重要的研究问题,因为算法正在逐步介入真实设计工作,可解释性研究与算法开发研究是同等重要的。可解释性研究有助于约束算法以满足设计师需求,目前本研究暂未涉及该问题,这也是未来可以继续深入的研究方向。
图片来源(Sources of Figures):
图1~14 由作者绘制。
