基于残缺值的模糊偏好关系多属性大群体决策方法
2023-08-01冯晓静


摘 要: 在多属性大群体决策环境下,针对决策者给出关于决策方案两两比较且可能包含残缺值的模糊偏好关系的决策问题,提出了一种基于相似度聚类的残缺值模糊偏好关系大群体决策方法。此方法首先通过标准化残缺值矩阵,然后定义判断矩阵之间的相似度对大群体进行聚类,再对各个属性下的群体偏好进行集结,通过偏差熵模型确定各个决策属性的权重,集结所有决策属性下的群体偏好,最后得到决策方案的排序结果。文章最后给出了一个算例分析以验证此方法的有效性。
关键词: 残缺值;模糊偏好关系;聚类;多属性决策;大群体决策
中图分类号: C 934
文献标志码: A
Multi-Attribute Large Group Decision Making Method Basedon Incomplete Fuzzy Preference Relation
FENG Xiaojing
(Institute of Western China Economic Research, Southwestern Universityof Finance and Economics, Chengdu 611130, China)
Abstract: In the environment of multi-attribute large group decision-making, aiming at the decision-making problem that the decision-maker gives the fuzzy preference relation of pairwise comparison of decision-making schemes and may contain residual value, a large group decision-making method based on similarity clustering of fuzzy preference relation of residual value is proposed. This method firstly standardizes the incomplete value matrix, then defines the similarity between judgment matrices to cluster large groups, and then aggregates the group preferences under each attribute; Next, it determines the weight of each decision attribute through the deviation entropy model, and aggregates all decisions Group preferences under attributes, and finally get the ranking results of decision-making schemes. A numerical example analysis is given to illustrate the effectiveness of the method developed.
Key words: incomplete value; fuzzy preference relations; clustering; multi-attribute decision making; large group decision making
0 引言
近年来,决策这一研究领域得到了广泛关注和研究,众多学者在决策领域提出了多种决策方法,并将它们应用到管理科学的各个方面。现有的决策方法主要集中在多属性群决策、模糊数决策、语言信息决策、多阶段决策等领域。群体决策一直都是决策领域研究的重要范畴,然而现有的群体决策方法却局限在小群体范围内。随着现代网络信息的迅猛发展以及信息资源的暴增,决策问题变得越来越复杂,因此需要更多的不同领域的专家来参与决策。鉴于此,徐选华等学者对此类问题进行了研究并提出了一些大群体决策方法,但是这些大群体决策方法却局限在决策信息为实值的决策中。
由于人类认识事物的主观性以及客观事物的复杂性,决策者往往更喜欢用模糊偏好来表达自己的决策信息,而模糊偏好关系正是模糊偏好的一种,由此徐选华进一步提出了基于模糊偏好关系的大群体决策方法。但是,由于人类认识事物的不确定性和局限性,决策者往往不可能对所有的决策方案都给出自己确切的决策偏好,鉴于此,徐泽水进行了深入研究并提出了一些基于残缺值的决策方法,但是这些基于残缺值的决策方法却没有应用到大群体决策上。同时,决策者在做决策时往往要考虑决策方案的多个属性,从而做出准确的决策。徐选华提出的模糊偏好关系大群体决策方法没有考虑到决策问题的多属性。本文将基于残缺值的决策以及模糊偏好关系决策综合考虑,放在多属性大群体决策环境下进行研究。先将各个属性下的基于模糊偏好关系的残缺值矩阵转化为一般形式的模糊关系矩阵,再通过定义模糊偏好关系之间的相似度,构造基于相似度的聚类算法对各个属性下的大群体进行聚类,通过聚集之间的权重对各个属性下的聚集进行集结,再通过偏差熵模型求出属性的权重对多属性进行集结,最后通过一个算子得到决策方案的排序。
1 问题描述
本文研究的是模糊偏好关系决策,在这里先给出其定义如下:若矩阵A为模糊偏好关系对应的判断矩阵,则矩阵中元素aij表示决策方案i优于决策方案j的程度。当0.5
假设一个决策问题有P个决策方案,N个决策属性,并且是一个有M(当M≥20时,我们称之为大群体)个决策者的大群体决策问题,在决策过程中,在每一个属性下,每一个决策者都有一个关于决策方案两两比较的模糊偏好关系判断矩阵,则在第n个决策属性下第m个决策者关于决策方案的模糊偏好关系判断矩阵如下:
Amn=(amij)P×P=amn11amn12…amn1P
amn21amn22…amn2P
…………
amnP1amnP2…amnPPP×P
其中,amij表示在第n个决策属性下第m个决策者的决策方案i优于决策方案j的程度。
同时,由于决策者自身关于决策问题的局限性以及不确定性,决策者无法判断某两个方案的优劣程度,在这种情况下,决策者则不给出这两个方案的比较值,即让aij和aji为空。
现要由N个属性下M个决策者做决策时得到的N×M个P维的模糊偏好关系判断矩阵,而这些判断矩阵中的某些元素可能为空值,得到一个最后的决策排序结果。
2 方法原理
考虑到模糊偏好关系判断矩阵中的某些元素为残缺值(空值),将这些空值转化为群体偏好从而使原判断矩阵转化为标准的模糊偏好关系判断矩阵;考虑到大群体决策环境下决策群体的复杂性,通过判断矩阵相似度的定义,对各个属性下的大群体偏好进行聚类,形成各个决策属性下的模糊偏好关系群体偏好;再通过偏差熵模型对各个决策属性下的权重进行求解,从而对群体偏好进行集结,最后通过一个算子得到决策方案的排序结果。
2.1 判断矩阵标准化
在决策过程中,如果决策者无法判断某两个决策方案的优劣程度,则该决策者不给出这两个方案的比较值,即让aij和aji都为残缺值,即空值。在这种情况下,我们就认为该决策者关于这两个决策方案的偏好程度和整个群体的偏好程度一致,则用群体的平均偏好替换空值。若anmij=anmji=Φ,则用a*nmji和a*nmij代替:
a*mnij 1Mnij∑Mm=1amnij,amnij≠Φ
a*mnji 1Mnji∑Mm=1amnji,amnji≠Φ(1)
其中,Mnij=Mnji为第n个属性下各个决策者关于方案i和方案j的模糊偏好值,anmij≠Φ(anmji≠Φ)的个数。
将所有的残缺值用群体平均偏好替代后,得到新的N×M个P维标准化的模糊偏好关系判断矩阵:
Bmn=(bmij)P×P=bmn11bmn12…bmn1P
bmn21bmn22…bmn2P
…………
bmnP1bmnP2…bmnPPP×P
其中,bmij表示替代残缺值后第n个决策属性下第m个决策者的决策方案i优于决策方案j的程度。
2.2 基于相似度聚类的大群体偏好集结
由于大群体决策环境下各个决策成员之间的差异较大,为此考虑各个决策属性下各个决策者关于方案偏好之间的相似度,基于相似度对决策成员进行聚类从而对群体偏好进行集结。有学者从范数的角度定义了两个模糊偏好关系矩阵之间的相聚度没有满足自反性,即相同的两个判断矩阵之间的相聚度应该为1。为了弥补这一缺陷,本文定义了如下的相似度:
定义1 两个决策者m1和m2的模糊偏好关系判断矩阵之间的相似度定义如下:
rm1m2(Bm1,Bm2)=1-1P(P-1)∑Pi=1∑Pj=1|bm1ij-bm2ij|(2)
定义1定义的两个模糊偏好关系判断矩阵之间的冲突度满足下列三个性质:
(1)有界性:0≤rm1m2(Bm1,Bm2)≤1。
(2)对称性:rm1m2(Bm1,Bm2)=rm2m1(Bm2,Bm1)。
(3)自反性:rmimi(Bmi,Bmi)=1。
证明:性质(1)∵0≤|bm1ij-bm2ij|≤1,aii = 0.5;
∴0≤1P(P-1)∑Pi=1∑Pj=1|bm1ij-bm2ij|≤1;
∴0≤rm1m2(Bm1,Bm2)≤1。
性质(2)、(3)显然成立。
基于式(2)定义的相似度,借鉴的聚类方法,在每一个决策属性下对每一个成员偏好都进行聚类,对决策成员形成不超过M个聚集(M是决策成员的总数)。在聚类算法中引入阈值γ用来判断两个方案偏好关系判断矩阵之间的相聚度,即判断该成员是否归类为其中某一个聚集,在本文中,取阈值γ=0.75。对一个已经形成的初始聚集,从未被聚类的群体中选择一个方案偏好关系判断矩阵,如果这个矩阵与所有被选入该聚集的方案偏好关系判断矩阵的集结矩阵间的相聚度大于或等于阈值γ,则将这个矩阵分配给该聚集。否则,这个方案偏好判断矩阵将不分配給这个聚集,而把它分配给一个临时集合。当所有成员的方案偏好判断矩阵都被分配到相应的聚集中时,成员偏好聚类完毕。
对各个决策属性下的标准化后的模糊偏好关系判断矩阵聚类后,形成K个聚集(每一个属性下的K可能不同),nk为聚集Ck的成员个数,接下来需要对各个聚集内的各个决策者的偏好进行集结,借鉴文献[17]聚集内决策成员偏好的集结方法,认为能够聚类在同一个聚集内,则这个聚集内决策成员之间的差异不大,故赋予他们相同的权重。对于聚集Ck,利用加权几何平均算子(WGAO: Weighted Geometric Averaging Operator)进行集结得:
BnCK=bnCKijP×P,bnckij=1nk∑nmm=1,i,j=1,2,…,P; k=1,2,…,K(3)
对各个聚集内的偏好进行集结后,就需要对各个聚集的模糊偏好关系进行集结。在这里,考虑各个聚集内的决策成员个数,聚集内决策成员个数越多,则认为该聚集内的成员能够代表大多数决策者的意见,对达成最终的决策结果贡献更大,因此应该赋予更大的权重;反之,聚集内决策成员个数越少,则赋予更小的权重。根据这一原则,第n个决策属性下聚集k的权重wnk定义为:
wnk=nnkM,n=1,2,…,N; k=1,2,…,K(4)
其中,M为决策成员总个数,nnk为第n个属性下的第k个聚集的决策成员个数。
用求出各个聚集权重,分别对n个属性下的所有的聚集的偏好关系判断矩阵BnCK利用WGAO进行集结,得到第n个决策属性下的群体模糊偏好关系判断矩阵
BnG=bnGijP×P,
bnGij=∑Kk=1wnk·nCKij,i,j=1,2,…,P(5)
得到每一个决策属性下的群体模糊偏好关系判断矩阵后,为了得到各个决策属性的权重,采用文献[13]的方法,通过偏差熵模型进行求解。熵原是热力学中的一个概念,它是信息的一个度量指标,可以用来度量获取的数据所提供的有用信息量。熵权法也广泛应用于决策过程中,属性的熵权越大,则对决策最终结果的贡献就越大。构建多属性偏差熵模型如下:
max T=-∑Nn=1∑Pi=1∑Pj=1|bnGij-∑Nn=1ωn·bnGij|∑Nn=1∑Pi=1∑Pj=1|bnGij-∑Nn=1ωn·bnGij|×ln∑Pi=1∑Pj=1|bnGij-∑Nn=1ωn·bnGij|∑Nn=1∑Pi=1∑Pj=1|bnGij-∑Nn=1ωn·bnGij|
s.t. ∑Nn=1ωn=1,0≤ωn≤1(6)
用求出的决策属性熵权值,对所有决策属性下的群体方案模糊偏好关系判断矩阵BnG利用WGAO进行集结得到所有决策属性下的群体方案模糊偏好关系判断矩阵
BG=(bGij)P×P,
bGij=∑Nn=1ωn·bnGij,i,j=1,2,…,P(7)
对求得的所有决策属性下的群体方案模糊偏好关系判断矩阵B通过式(8)可以求得决策方案的排序向量:
Oi=1P(P-1)∑Pj=111+bij+P2-1(8)
求得方案排序向量O=(o1,o2,…,oP),即可获得最终的方案排序结果。
2.3 基于相似度聚类的残缺值多属性大群体决策方案排序
基于上述讨论结果,给出一种基于相似度的残缺值多属性模糊偏好关系大群体决策方法,步骤如下:
Step1:首先通过式(1)将各个决策属性下的包含残缺值的模糊偏好关系判断矩阵转化为标准模糊关系判断矩阵。
Step2:通过式(2)定义的相似度,对每个属性下的模糊偏好关系进行聚类,形成K个聚集。
Step3:利用式(3)集结每个属性下各个聚集的方案模糊偏好关系。
Step4:利用式(4)求出各个决策属性下每个聚集的权重,并利用式(5)集结每一个属性下的群体方案模糊偏好关系。
Step5:利用式(6)的偏差熵模型求出各个决策属性的熵权值,并利用式(7)集结所有决策属性下的群体方案模糊偏好关系。
Step6:利用式(8)即可求得最终的方案排序。
3 算例分析
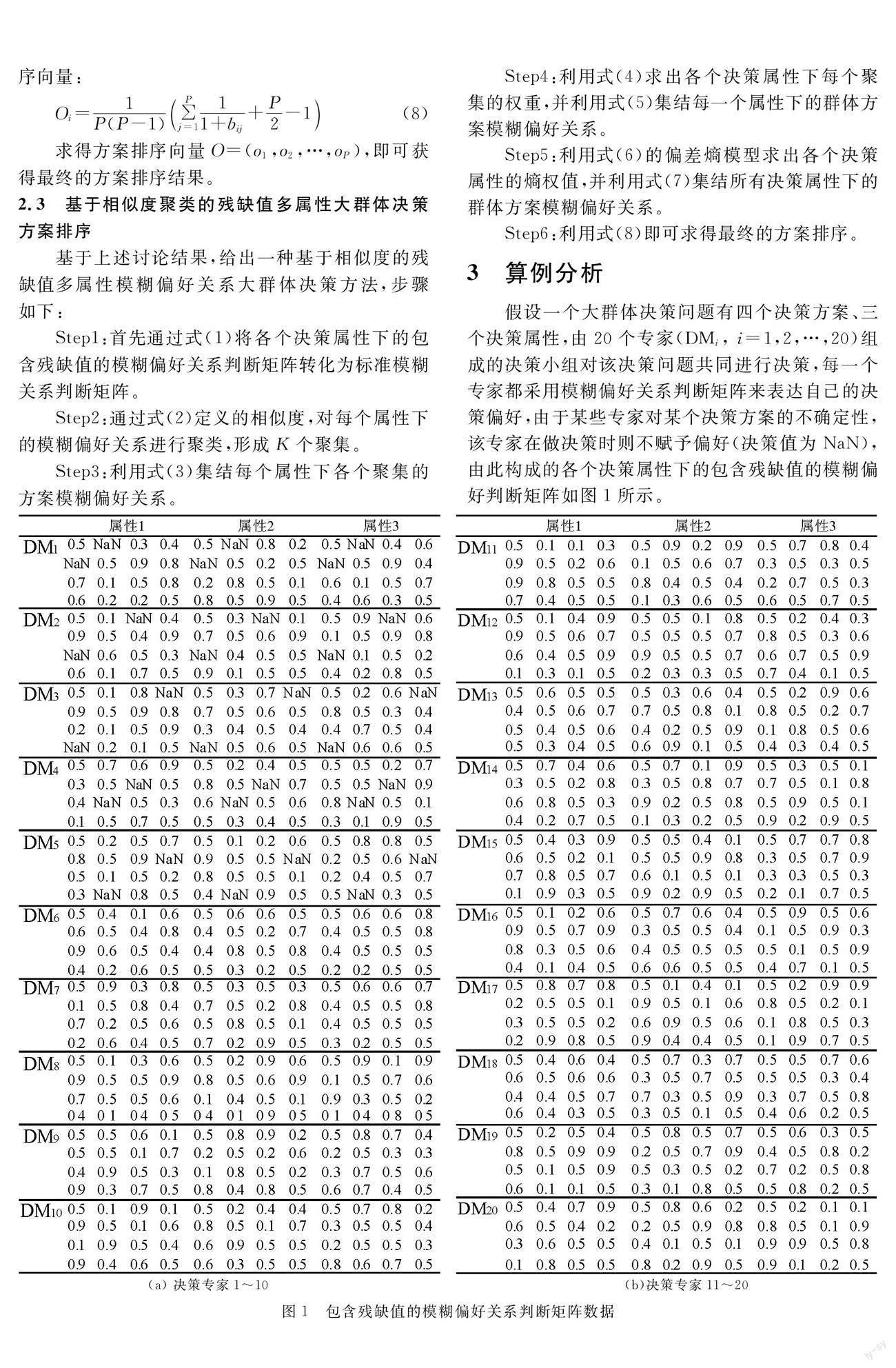
假设一个大群体决策问题有四个决策方案、三个决策属性,由20个专家(DMi , i=1,2,…,20)组成的决策小组对该决策问题共同进行决策,每一个专家都采用模糊偏好关系判断矩阵来表达自己的决策偏好,由于某些专家对某个决策方案的不确定性,该专家在做决策时则不赋予偏好(决策值为NaN),由此构成的各个决策属性下的包含残缺值的模糊偏好判断矩阵如图1所示。
然后,通过式(1)对决策者1到决策者5的残缺值进行标准化,得到其标准化模糊偏好关系判断矩阵,如表1所示。
将标准化后的模糊偏好关系判断矩阵替代原残缺值矩阵后,对每个决策属性下的决策者偏好进行聚类,得到各个决策属性下聚集如表2~4所示。
集结后得到三个决策属性下的群体模糊偏好关系判断矩阵如表5所示。
再利用偏差熵模型求得各个决策属性的权重为ω=(0.4390,0.2147,0.3464)。利用属性权重集结各个决策属性下的群体模糊偏好关系判断矩阵得
BG=0.50.45250.50050.5368
0.54750.50.50420.6154
0.49960.49620.50.5003
0.46690.41110.49970.5
最后利用式(8)求得决策方案的排序向量为O=(0.3060,0.2997,0.3057,0.3103),所以决策方案四为最优方案。
4 结束语
本文针对在多属性大群体决策环境下,由于决策者自身的局限性和不确定性而给出关于决策方案的殘缺值的模糊偏好关系的决策问题,提出了一种基于残缺值的模糊偏好关系的多属性大群体决策方法。此方法考虑了大群体决策环境下的残缺值决策以及多属性决策问题,进一步完善了大群体决策方法。然而,大群体决策问题本身就是一个复杂的问题,它涉及的决策群体规模庞大且复杂,因此决策群体成员之间必然存在冲突,而本文未考虑到大群体决策成员之间的冲突与协同。另外,大群体决策问题由于决策成员众多,更加需要通过多阶段交互式协商才能取得更加准确的决策结果。在本文基础之上,未来的多属性大群体决策研究可以考虑决策群体成员之间的冲突消解,放在多阶段交互式决策下进行研究,也可考虑将该方法应用在多样的多属性评价与决策环境之中。
参考文献:
[1] WU Z, XU J. A consistency and consensus based decision support model for group decision making with multiplicative preference relations[J]. Decision Support Systems, 2012,52(3):757-767.
[2] XU J, WU Z. A discrete consensus support model for multiple attribute group decision making[J]. Knowledge-Based Systems, 2011,24(8):1196-1202.
[3] RODRGUEZ R M, MARTNEZ L, HERRERA F. A group decision making model dealing with comparative linguistic expressions based on hesitant fuzzy linguistic term sets[J]. Information Sciences, 2013,241:28-42.
[4] XU Z. A method based on linguistic aggregation operators for group decision making with linguistic preference relations[J]. Information Sciences, 2004,166(1-4):19-30.
[5] XU Z, CHEN J. An interactive method for fuzzy multiple attribute group decision making[J]. Information Sciences, 2007,177(1):248-263.
[6] KACPRZYK J, ZADRO Z NY S. Collective choice rules in group decision making under fuzzy preferences and fuzzy majority: a unified OWA operator based approach[J]. Control and Cybernetics, 2002,31:937-948.
[7] SZMIDT E, KACPRZYK J. Concept of distances and entropy for intuitionistic fuzzy sets and their applications in group decision making[J]. Notes on Intuitionistic Fuzzy Sets, 2002,8(3):11-25.
[8] DONG Y, ZHANG G, HONG W, et al. Consensus models for AHP group decision making under row geometric mean prioritization method[J]. Decision Support Systems, 2010,49(3):281-289.
[9] KACPRZYK J, ROMERO R A, GOMIDE F A. Involving objective and subjective aspects in multistage decision making and control under fuzziness: dynamic programming and neural networks[J]. International Journal of Intelligent Systems, 1999,14(1):79-104.
[10] FU C, YANG S. The group consensus based evidential reasoning approach for multiple attributive group decision analysis[J]. European Journal of Operational Research, 2010,206(3):601-608.
[11] TAMOˇSAITIEN J, ZAVADSKAS E K. The multi-stage decision making system for complicated problems[J]. Procedia - Social and Behavioral Sciences, 2013,82:215-219.
[12] SZMIDT E, KACPRZYK J. Using intuitionistic fuzzy sets in group decision making[J]. Control and Cybernetics, 2002,31:1055-1057.
[13] 徐選华, 周声海, 周艳菊, 等. 基于乘法偏好关系的群一致性偏差熵多属性群决策方法[J]. 控制与决策, 2014(2):257-262.
[14] 陈晓红, 徐选华, 曾江洪. 基于熵权的多属性大群体决策方法[J]. 系统工程与电子技术, 2007(7):1086-1089.
[15] 徐选华, 陈晓红. 一种多属性多方案大群体决策方法研究[J]. 系统工程学报, 2008(2):137-141.
[16] 徐选华, 陈晓红, 王红伟. 一种面向效用值偏好信息的大群体决策方法[J]. 控制与决策, 2009(3):440-445.
[17] 唐明,廖虎昌,徐泽水.基于最大共识序列的子群关联型大群体决策方法[J]. 系统工程理论与实践, 2021,41(11):3043-3054.
[18] 缑迅杰,邓富民,徐泽水.基于自信双层语言偏好关系的大规模群体共识决策方法及其应用研究[J/OL]. 中国管理科学:1-12[2023-05-29]. https://doi.org/10.16381/j.cnki.issn1003-207x.2021.0927.
[19] 徐泽水,任珮嘉.犹豫模糊偏好决策研究进展与前景[J].系统工程理论与实践, 2020,40(8):2193-2202.
[20] 徐选华, 周声海, 周艳菊, 等. 基于群体冲突的模糊偏好关系大群体决策方法[J]. 运筹与管理, 2014(3):91-96.
[21] 徐泽水. 基于不同类型残缺判断矩阵的群决策方法[J]. 控制与决策, 2006(1):28-33.
[22] 徐泽水. 基于残缺互补判断矩阵的交互式群决策方法[J]. 控制与决策, 2005(8):913-916.
[23] 徐选华, 陈晓红. 基于矢量空间的群体聚类方法研究[J]. 系统工程与电子技术, 2005,27(6):1034-1037.
[24] 徐泽水, 顾红芳. 混合判断矩阵的两种排序方法[J]. 系统工程与电子技术, 2002,24(5):1-3.
[25] 刘晓慧,沈惠璋.基于协同度的网络舆情突发事件模糊多属性应急决策方法[J].上海管理科学,2021,43(6):103-109.
[26] 谢丽敏,张旭亮,周思敏.民营企业对政府扶持性政策效果评价:基于模糊综合评价方法[J].上海管理科学,2022,44(1):84-90.
收稿日期:2023-05-15
基金项目:中央高校基本科研业务费专项资金资助(JBK22YJ11,JBK2304149)
作者简介:冯晓静(1989—),女,河南新郑人,博士,副教授,研究方向:行为运营管理。
