一种基于FAS-Transformer的人脸防伪方法
2023-07-21马宏斌王英丽
魏 鑫, 马宏斌, 王英丽
(黑龙江大学 电子工程学院, 哈尔滨150080)
0 引 言
人脸识别系统具备判别性高、非接触和响应时间短等特点,可为用户提供良好的体验,成为众多场景下身份认证的选择。然而,未受保护的人脸识别系统很难应对表征攻击。针对人脸识别系统的安全性问题,研究人员开始对人脸防伪方法进行研究。目前,人脸防伪方法大体上可以分为两种类型:传统方法和基于深度学习的方法。传统的人脸防伪方法采用手工提取特征,从图片中提取具有针对性的特征进行检测。虽然针对性强,但当环境中出现变化因素时稳定性就会变差,在面对重放攻击时性能会急剧下降。2014年,Yang等首次将深度学习引入了人脸防伪领域,使用卷积神经网络(Convolutional neural networks, CNN)代替手工提取特征[1]。Liu等在用CNN和循环神经网络(Recurrent neural network, RNN)获取深度的同时,引入远程光电容积脉搏波信号作为辅助手段,让网络学习更具针对性[2]。这些基于CNN的研究方法,在应对如照片打印和视频重放等2D攻击时表现尚佳,但面对3D面具攻击时稳定性会急剧下降,说明了此类方法泛化性能不足。应对防伪方法泛化性差的缺点,研究人员提出了基于多通道的人脸防伪方法[3]。这类方法的主要思想是通过融合多个通道的补充信息增加泛化性,但从系统设计的角度出发,此类方法对硬件设备要求严格。表征攻击手段在不断地更新,会影响系统的构建和实际部署。
以上研究发现,近年来人脸防伪方法的研究思路大体可以概括为:添加辅助信号、融合多通道信息、将人脸防伪问题与其他问题相结合等,以此提升模型的有效性及泛化性。这些方法确实在一定程度上提升了模型分类的精确度以及面对不同表征攻击的泛化性,但随之而来的高硬件成本、高计算复杂度和低解释性等问题仍待解决。
2017年,谷歌提出Transformer模型,成功应用于机器翻译任务[4]。2020年,Dosovitskiy等将Transformer模型应用于图像分类任务[5],提出Vision Transformer模型,同样取得了成功。相比于传统的神经网络,注意力机制的优势主要体现在以下几个方面: (1) 每层的计算复杂度更低; (2) 可以并行地进行计算; (3) 可以有效地解决长输入序列的依赖问题; (4) 可解释性强。这些优势为将Vision Transformer模型应用于人脸防伪任务提供了可能,因为人脸防伪任务本质上是二分类任务。
结合人脸防伪任务存在的问题以及注意力机制的优势,本研究进行基于注意力机制的人脸防伪方法研究。通过对Vision Transformer模型进行改进,构建了FAS-Transformer模型,将输入的人脸图像经过线性映射嵌入位置信息和判别信息,借助多头注意力获取特征向量之间的关系。针对人脸防伪模型训练普遍存在的数据量不足问题,采用迁移学习的思想,为实验引入预训练模型。同时,为增强模型的可解释性,对注意力进行可视化处理。
1 基本理论
1.1 Transformer模型
Transformer模型的提出是为了解决传统神经网络在处理序列模型时存在的长期依赖和计算效率低的问题,在结构上首次引入全注意力机制代替传统的循环卷积神经网络。Transformer模型结构如图1所示,主要由编码器和解码器两部分构成,其中编码器用于将输入序列映射为符号表征,而解码器则会依据编码器的输出生成最终的预测。
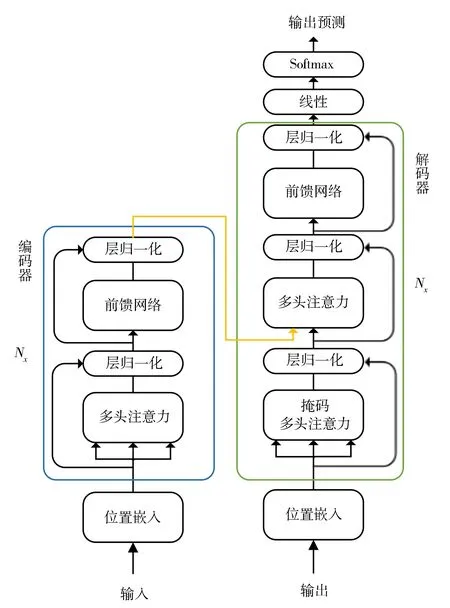
图1 Transformer模型结构
由于注意力机制中每个元素都要和其他元素进行交互,故它是一种位置无关的方法,需要嵌入位置编码。编码后的序列会通过多头注意力机制进行打分,比较输入序列元素之间的成对相似性关系,获取注意权重,进而对输出结果进行预测。多头注意力使得模型可以并行地进行计算,再将单个输出联合到一起作为输出。注意力的计算过程描述公式为:
(1)
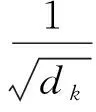
MultiHead(q,k,v)=Concat(head1,…,headn)W
(2)
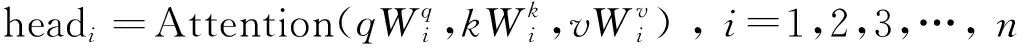
Transformer模型一经提出就引起了研究人员的广泛关注,这种不同于过去CNN和RNN的简单网络结构,使用全注意力机制避免了循环和卷积。得益于自身可并行计算的优势,所需的网络训练时间也更短。起初Transformer模型被用于处理Seq2seq问题,广泛用于机器翻译任务。由于模型的结构设计仅适用于一维序列输入,因此,一直无法在计算机视觉领域得到重用。
1.2 Vision Transformer (ViT)模型
为使Transformer模型适应计算机视觉任务,Dosovitskiy等提出了ViT模型。将输入图片格式由x∈H×W×C进行线性映射,转换为平铺的成块序列xp∈N×(p2·C),满足Transformer结构的一维输入,其中,(H,W)为原始图片分辨率,C为通道数,(P,P)为分块图片的大小,N=HW/P2为图片分块总数。ViT模型结构如图2所示。

图2 Vision Transformer模型结构
ViT模型改进了Transformer中的编码器结构获取图像像素间的相关性,为便于处理,在所有层使用D维的恒定向量,将所有块映射成相同维数。经过位置信息嵌入的块会经过层归一化处理,使用多头注意力机制计算注意力权重,并最终使用多层感知器进行分类,得到图片表征y。该过程如式(3)~式(5)所示:
z′l=MSA(LN(zl-1))+zl-1,l=1,…,L
(3)
zl=MLP(LN(z′l))+z′l,l=1,…,L
(4)
(5)

ViT模型将图片视为输入序列,通过线性映射使其适用于Transformer结构的一维输入,并利用注意力打分机制很好地实现了图像分类任务。
2 适用于人脸防伪任务的FAS-Transformer模型
为使注意力机制成功应用于人脸防伪任务,提出了基于ViT模型改进的FAS-Transformer模型。为使模型对人脸真伪特征进行学习并作出区分,在输入人脸图像序列化后嵌入位置信息,并嵌入真伪判别信息。同时,对分类网络结构进行改进,采用全连接层配合Softmax函数进行最终的结果分类。FAS-Transformer模型结构如图3所示。

图3 FAS-Transformer模型结构
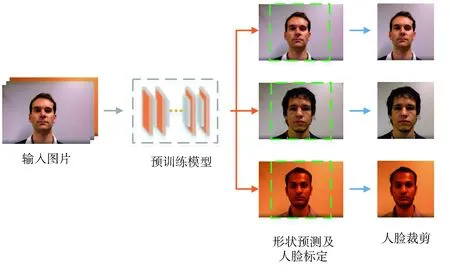
图4 数据预处理流程
在对输入的人脸图像进行和ViT模型相同的分块操作后经过线性映射,使用正余弦函数作为学习的位置编码函数,保证每个位置编码的唯一性。偶数位置采用正弦函数编码,奇数位置采用余弦函数编码,通过这种方式使模型能够学习到输入图像小块的相对位置信息。
PE(pos,2i)=sin(pos/10 0002i/dmodel)
(6)
PE(pos,2i+1)=cos(pos/10 0002i/dmodel)
(7)
式中:pos表示位置;i表示特征维度;dmodel表示模型维度。
为了使模型对人脸真伪特征进行学习,采用有监督训练,在嵌入位置信息的同时,嵌入真伪判别标识(其中,0表示伪造特征,1表示真实特征)。
模型结构中使用多头注意力将输入映射到不同的特征子空间。此后,计算每个头的注意力,再将计算得到的多个头的输出进行拼接,经过再次投影构成多头注意力的整体输出。使用多头注意力的优势在于,可以同时关注来自不同位置的不同表示子空间的信息,如果使用单一注意力在计算时就会使用平均去抑制这些信息。
在模型训练的过程中,随着每一层参数的更新会导致上层输入数据分布的变化,堆叠的层数越多,这种分布变化越剧烈,这使得高层需要不断地适应底层数据的更新。为了加快模型的收敛,保证数据特征分布的稳定性,在训练单个样本时采用了层归一化。
(8)
式中:x为样本;μ为均值;σ为方差;α和β为可学习参数。
损失函数:为获取更好的实验结果,在训练过程中采用二值交叉熵(Binary cross-entropy, BCE)损失函数对网络进行监督,对参数进行微调。
(9)
式中:N表示样本个数;yi表示样本标签;ai表示样本权重值。
测试策略:在测试阶段为了评估特征的真伪,需要将经注意力机制处理的特征与真实特征的权重均值做出比较,通过计算两者之间的距离获取最终分类打分,打分公式为:
Score(xi)=‖φ(xi;ai)-c‖
(10)
式中:xi表示人脸特征;ai表示特征所对应的权重;c表示真实特征的权重均值。
3 测试与结果分析
3.1 测试环境及实验参数
硬件平台采用32GB运行内存,11th Gen Intel(R) Core(TM) i7-11800H @ 2.30GHz处理器,NVIDIA GeForce RTX 3060 GPU。软件平台采用基于Windows 11搭建的Pytorch深度学习框架。实验采用的基本网络结构的实践方法已在Github上开源。实验参数设置如表1所示,其中训练Batch-size可以根据自身设备性能好坏适当提高,选择标准Adam作为优化器。将验证集上损失最少的模型作为最终的模型选择,模型的训练流程如算法1所示。

表1 实验参数设置
3.2 数据预处理
为避免不同数据集中的背景环境对实验造成的影响,预先对数据集中的人脸进行剪裁。裁剪过程采用Dlib作为人脸检测器并使用开源计算机视觉库OpenCV,首先获取人脸矩形坐标信息,再通过加载68点预训练模型(Shape_predictor_68_face_landmarks)进行关键点预测,并使用自带函数实现人脸对齐操作。在对坐标、角度进行一系列计算后定位图片中的人脸,将提取到的关键区域保存。通过加载预训练模型,整个剪裁过程速度很快,对于数据集中存在视频的情况,设定帧数进行视频抽帧,再进行裁剪。为满足后续实验安排,图片裁剪大小统一设置为224×224,分块大小为16×16,并对经过预处理的图片采用垂直镜像对称的方式以0.5的概率进行数据扩充。
3.3 权重
集内测试实验中使用表征攻击分类错误率(Attack presentation classification error rate, APCER)、真实呈现分类错误率(Based presentation classification error rate, BPCER)以及平均分类错误率(Attuck classification error rate, ACER)进行评估。ACER是APCER和BPCER总和的一半,其中APCER表示所有表征攻击中最高的假阳性率,其公式为:
(11)
对于CASIA-MFSD和Replay-Attack之间的集间测试实验,使用半总错误率(Half total error rate, HTER)、错误接受率(False accept rate, FAR)和错误拒绝率(False rejection rate, FRR)进行评估,其公式为:
(12)
3.4 集内测试实验
为了验证所提出方法的有效性,设计了两组集内测试实验,分别在SiW和WMCA数据集上进行。
3.4.1 SiW集内测试实验
SiW: 数据集提供165个对象的活体和伪造视频[6]。其中为每个对象录制8个真实视频和20个伪造视频,共有4 478个视频。视频的帧数为30 fps,时长为15 s,清晰度为1 080P HD。活体视频的收集分为4种类型:距离、姿态、光照和表情。伪造视频的攻击手段如打印照片和视频重放。为方便未来研究,数据集制作团队定义了子协议方便研究人员对人脸表征攻击方法的泛化性和模型在不同媒介上的表现能力及应对未知攻击时的表现进行评估。
参考文献[7]中的方法对评估集应用固定的预训练阈值0.3,应用到3种子协议中,使用ACER、APCER和BPCER进行评估。实验结果如图5所示,选取了4种主流方法与本方法进行对比,分别是:Auxiliary[6]、ResNet[8]、DenseNet[9]和Meta-FAS-DR[10],可以看出,在3种协议的对比实验中,所提出的方法性能最佳。
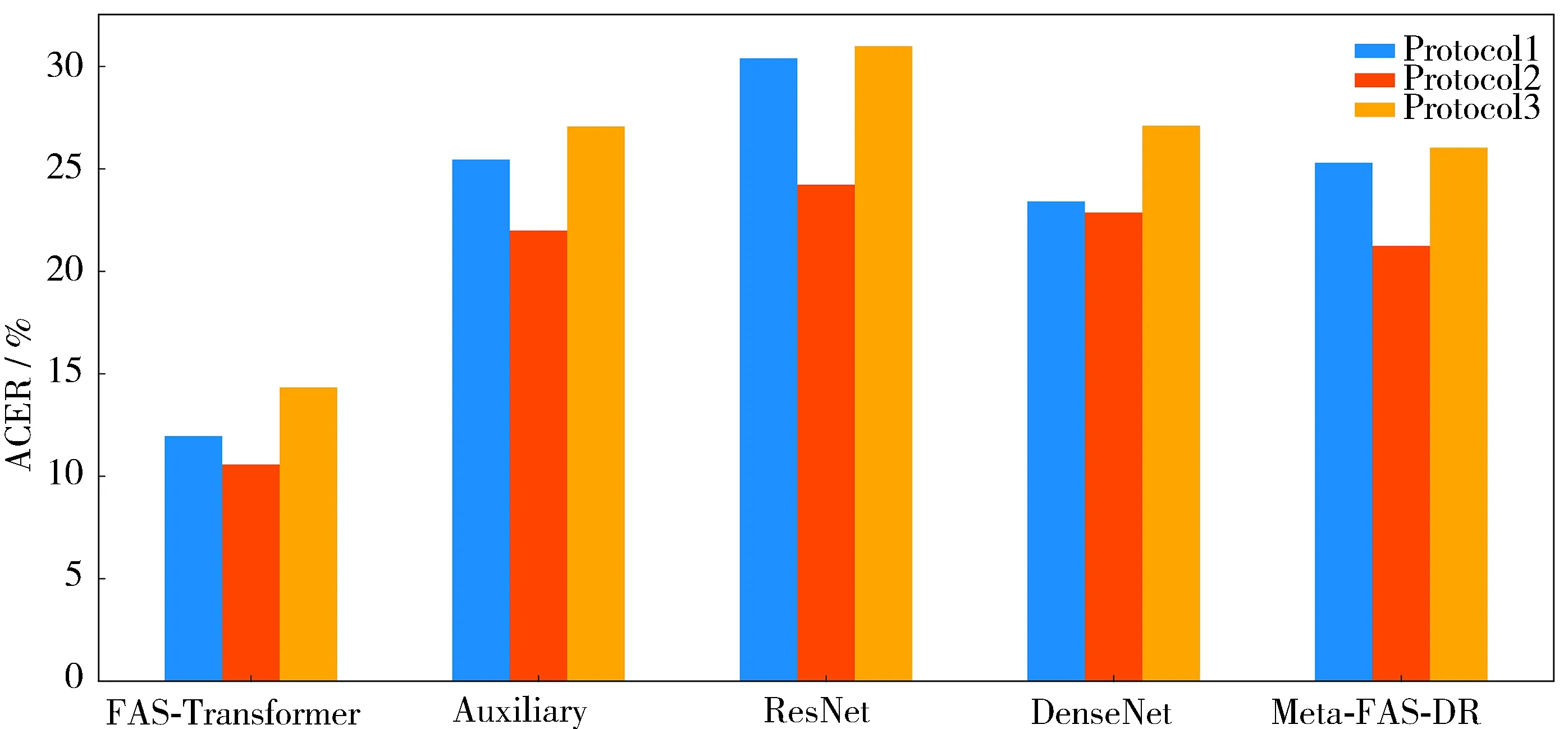
图5 SiW数据集上3种协议下的集内测试结果
3.4.2 WMCA集内测试实验
WMCA数据集记录了72位不同身份对象的1 941个短视频,包括真实的和伪造的[11]。数据的记录通过渠道为:色彩、深度、红外线和热温度计。该数据集依赖强大的拍摄设备模仿3D表征攻击。不同通道的数据依靠不同类别的传感器进行采集。所用的数据集源自2个传感器的采集,在信息采集时对背景进行改变。
实验使用留一法,单独留出一种攻击类型放在训练集中,将其他的攻击类型用于评估集,这样就构成了一个简单的留一协议。测试所提出方法在不同攻击类型下的表现,并与基线方法进行比较,在实验过程中对标准的网络结构进行微调,将最后一层改为全连接层适应二分类任务,实验结果如表2所示。由实验结果可知,在与ResNet50和DenseNet169两种方法比较后,所提出方法的性能更好,平均值达到了(14.4±8.2)%,远优于基线方法。

表2 不同攻击类型下基线方法和所提出方法在WMCA数据集上的性能对比
3.5 集间测试实验
为了验证本方法具备一定的泛化性,设置了集间测试实验,并选用CASIA-FASD[12]及Replay-Attack[13]两个数据集进行实验,整个实验过程可以简单概括为在一个数据集上训练模型,在另一个数据集上验证模型的性能。
CASIA-FASD: 该数据集包含来自50个对象的真实和伪造人脸的录像。数据集中设计了3种伪造攻击:扭曲照片攻击、剪切照片攻击及视频攻击。
Replay-Attack: 该数据集包含在不同的光照条件下,来自50名对象的共计1 300个视频片段,由图片和视频攻击共同组成,是一个2D人脸防伪攻击数据集。数据集中的数据被划分为4个子集:(1) 训练数据用于训练防伪分类器;(2) 开发集用于阈值的估计;(3) 测试数据用于报告错误数;(4) 注册数据用于验证人脸检测算法的敏感性。出现在一个数据集中的对象不会在其他数据集中再次出现。如表3所示,模型在HTER权重下获得了较好的性能,并且性能优于主流研究方法,这也验证了所提出方法具备一定的泛化性。同时,实验结果显示出了一种规律,在图片分辨率较高的数据集上训练出的模型,在分辨率低的数据集上测试会显示出更好的精度。

表3 集间测试实验结果
3.6 注意力的优化
为了更直观地展示注意力机制在人脸防伪任务中的工作原理,使用注意力图可视化的方法,直观地展现了注意力机制在处理人脸防伪任务时关注的位置。在实验过程中对底层注意力进行移除操作,因为已有实验证明底层注意力效果不佳,对其进行移除操作可以实现去噪,保证注意力更集中。同时,对注意力头打分取平均值用于设置丢弃率,去除低分的输出。通过调整让注意力更加集中,优化实验效果。如图6所示,经过优化后的注意力集中出现在人脸五官和面部与背景区域的边界处。

图6 注意力图
3.7 特征可视化
为了以更直观的方式显示模型在处理人脸特征过程中对不同类型特征所做出的区分,利用t-SNE可视化方法,对数据集中的部分特征进行可视化显示。t-SNE技术通过在二维或三维地图中给每个数据提供一点进行标识来可视化高维数据,该技术是随机邻域嵌入的一种变体,通过减少中心聚点的趋势提供更直观的可视化效果,也更易优化。Replay-Attack数据集集内测试过程中的真伪分类数据可视化处理的结果如图7所示,可以看出,所提出的模型对真伪特征进行了有效区分,特征会向自身类别聚拢,这为后续分类提供了依据。WMCA数据集不同攻击类型特征可视化的结果如图8所示,实验选用了真实,眼镜、打印及重放攻击特征进行可视化,由结果图可知,不同攻击类型的特征在分类测试过程中同样提供了类别区分,但仍有少量特征会与其他类别特征出现重叠情况。
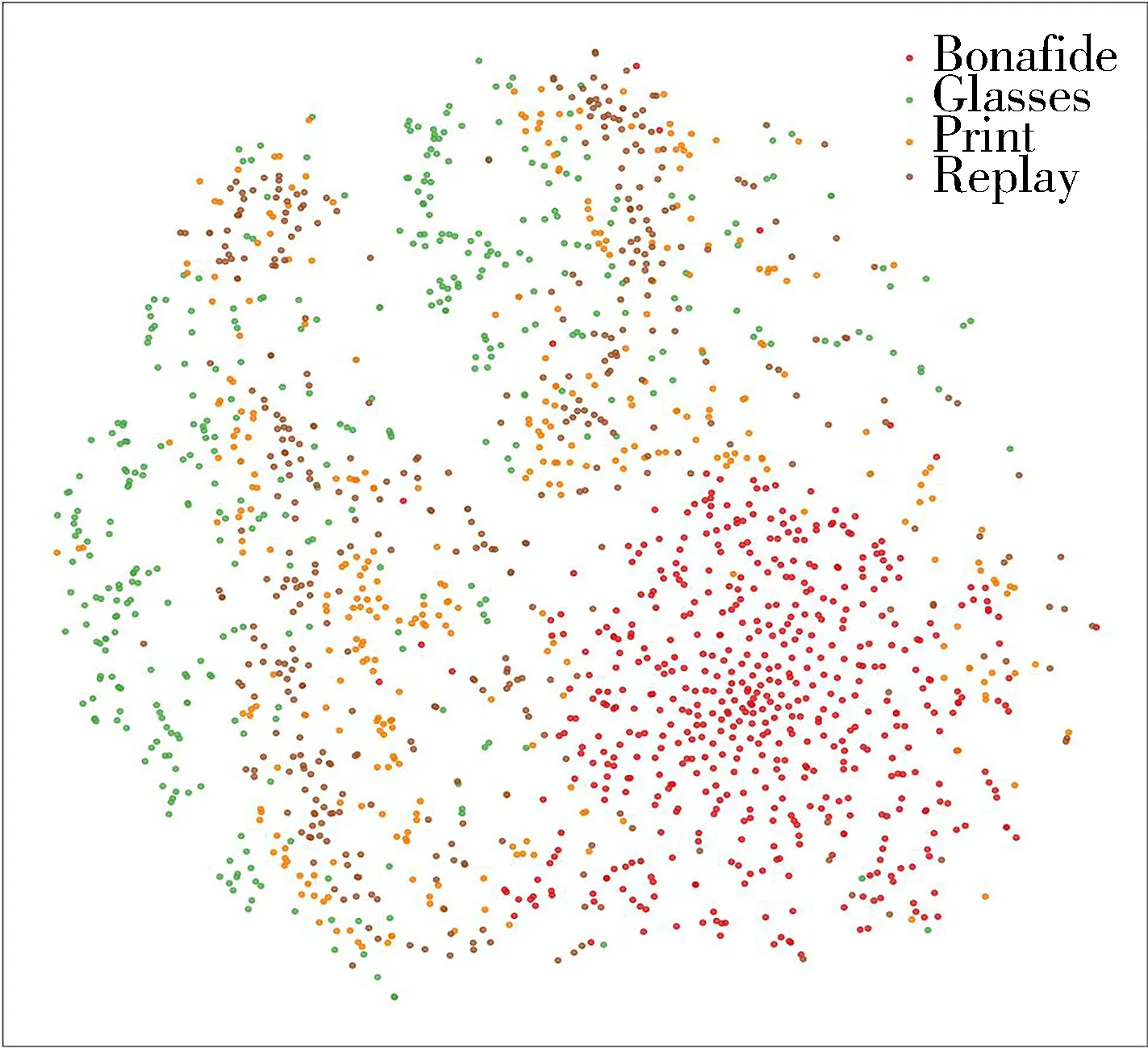
图8 WMCA数据集4种特征可视化结果
3.8 模型复杂度分析
模型的复杂度可由两个指标进行描述:时间复杂度和空间复杂度。其中,时间复杂度通过模型计算量衡量,空间复杂度则是通过模型参数量衡量。为了对模型复杂度进行分析,通过实验对比了基线方法及本方法的计算复杂度及参数总量。本方法与基线方法模型计算复杂度的对比结果如图9所示,本方法与基线方法各自参数总量的对比结果如图10所示。可以看到,模型的计算复杂度及参数总量随着训练轮次的增加而增加,大幅度的超过了对比的基线方法,这为模型的进一步优化提供了方向。

图9 模型计算复杂度折线图

图10 模型参数总量折线图
4 结 论
将注意力机制应用到人脸防伪任务中,通过对ViT模型进行改进,将模型的分类层替换为全连接层,并添加真伪判别信息,提出一种基于FAS-Transformer的人脸防伪方法。为验证本方法的性能,设计集内和集间测试实验与主流方法进行对比。通过实验验证,本方法在同一数据集的不同协议类型、不同攻击类型及跨数据集测试结果中的有效性和泛化性均优于主流方法,较好地解决了人脸防伪方法在应对不同表征攻击类型时,普遍存在的泛化性差的问题,具备一定的实用价值。同时,为体现注意力机制可解释性强的优点,对注意力做可视化处理,方便对其工作原理进行理解。当然,仍有一些问题需要进一步研究,如不同数据集背景环境对实验结果的影响。本实验操作中对输入的图像进行了统一的剪裁,这是为了消除不同人脸防伪数据集间的背景差异,但也在一定程度上损失了背景环境信息。此外,FAS-Transformer模型虽然在性能上更优于主流方法,但也存在一定的局限性,如模型训练数据量大和计算复杂度较高等特点,这些问题值得进一步研究。
