基于BTM和长文本语义增强的用户评论分类
2023-07-21宗福焱
关 慧,宗福焱,曲 盼
(1.沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110142;2.辽宁省化工过程工业智能化技术重点实验室,辽宁 沈阳 110142)
0 引 言
随着互联网时代的到来,智能移动终端和各类电子商务平台也得到了飞速的发展。微博、通讯信息、用户评论等以短文本形式呈现的信息正在以飞快的速度增长[1]。各类短文本涵盖了人们对各种社会现象的立场与观点,在舆情调查、热点话题的识别发现、问题反馈、需求挖掘等领域有着重要的应用前景[2-5]。因此,如何在大量且复杂的文本中获取最有效的信息是信息处理目标之一。短文本分类可以帮助用户快速定位需求信息和进行信息分流[6],同时分类也是对短文本中大量有价值信息进一步挖掘的重要步骤[7],因此,短文本分类越来越受到人们的关注。
从当前实际来看,西方哲学和马克思主义哲学早已深入中国人的现实生活和精神系统,是构建当代中国形而上学新形态中不可分割的有机组成部分。虽然上述两者还未真正实现与中国传统哲学的融会贯通,但三种思想资源的融合是有着深刻的历史和现实基础的。
短文本分类与长文本分类不同。长文本蕴含较为完备的语义信息和规范的表达模式,对长文本进行分类时传统的自然语言处理技术和分类方法可以达到很好的效果[8]。而短文本分类所面临的挑战在于短文本具有本身长度比较短、表达形式不规范、实时性强和海量性等特点[9],使得对短文本进处理时会产生特征异常稀疏、数据噪声大、上下文信息量少等问题。因此,传统的自然语言处理中的文本分类方法直接运用到短文本分类时分类效果不佳[10]。
针对上述问题,近年来对短文本分类方法的研究主要分为基于语义和基于规则两种方法。基于语义的方法一般是借助外部语料库或搜索引擎来扩充短文本中的语义信息。外部语料库通常是指维基百科、百度百科或知网等含有大量文本内容及语言素材的大型语料库。这些外部的语料库能给予短文本充分的信息补充与信息扩展从而增加文本内容。王海燕等人[11]通过Wikipedia知识库挖掘出单词、句子之间的语义关系、语序关系和词语的同义词信息进行辅助分类来提高分类效果。康卫等人[12]在综合考虑文本数据集规模、文档长度、类别数量分布情况下对朴素贝叶斯算法进行改进,提出了一种基于搜索的NaiveBayes短文本分类方法。丁连红等人[13]等通过构建知识图谱来推理短文本信息并将其运用于短文本特征上。彭晨淼等人[14]通过外部信息构建了短文本的领域本体,并结合BTM主题模型进行特征扩展来改善短文本分类。Gu Y等人[15]针对短文本语义缺失对分类性能的制约,利用外部语料库训练Word2Vec模型,对传统关键词提取算法基于外部语义信息提取的关键词进行扩展,研究了基于外部语义信息的短文本关键词根据不同扩展方式进行扩展的可行性。
基于规则的方法一般是分析短文本内容、挖掘短文本潜在的语义关系来构建基于文本的特征集。李昌兵等人[16]基于卡方统计来选取特征词,改善权重计算方法TF-IWF来提高短文本的分类。黄贤英等人[17]将Word2Vec训练的词向量与BTM主题模型训练的主题向量拼接作为特征向量进行特征扩展,结果表明分类效果有所提高。Lei Shi等人[18]提出一种自聚集的方法将短文本聚合为聚集文档捕获短文本的动态变化并解决短文本的稀疏性问题。王云云等人[19]针对短文本中的一词多义问题,提出了融合词向量与BTM的Multi-TWE多维词向量模型进行短文本分类,分类效果有所提高。郑腾等人[20]针对短文本信息量少、特征稀疏等特点,在短文本的基础上利用LDA主题模型得到文档主题分布并将主题词扩充到原短文本中。
综上,基于语义的方法对引入外部语料库质量依赖性较高,在增加语义信息的同时也会引入泛化能力不强的样本;而基于规则的方法则依赖于文本本身内容和潜在的语义关系来构建特征集,但是在构建这种特征集合的精确度上有一定的局限性。
考虑到以上两种方面的特点,该文将上述两种方法相结合,提出了融合词向量[21]及BTM主题模型[22]并辅以长文本扩充语义的用户需求分类方法,通过引用长文本作为外部语料库对短文本信息内容进行扩充,来解决短文本的信息量少和缺少上下文的问题。通过运用BTM主题模型在文本中的主题概率特征,词向量在LSTM中的编码特征作为分类的特征扩展,用以解决特征的稀疏问题。
1 基于BTM和长文本语义增强的分类方法
1.1 方法流程
对于用户评论来说,由于其文本较短,所以其包含的信息量较少、特征稀疏、缺少上下文信息。传统的LDA主题模型对于长文本具有很好的分类效果,但对于用户评论这类短文本的分类效果不佳。主要原因是其无法计算出各个词在主题中的重要性。该文提出了基于BTM和长文本语义增强的用户评论分类方法,结合LDA模型在长文本中的优势,用长文本来弥补短文本语义信息缺乏的问题。首先,选取特定的长文本作为外部语料库进行短文本扩展;然后,运用Word2vec和LSTM(Long Short Term Memory)训练得到的短文本的编码特征与BTM主题模型训练下得到的主题概率特征拼接得到扩展后的短文本特征;最后,使用SVM进行用户评论短文本的分类检验,并与传统分类及单一模型进行对比。其用户评论分类流程框架如图1所示。
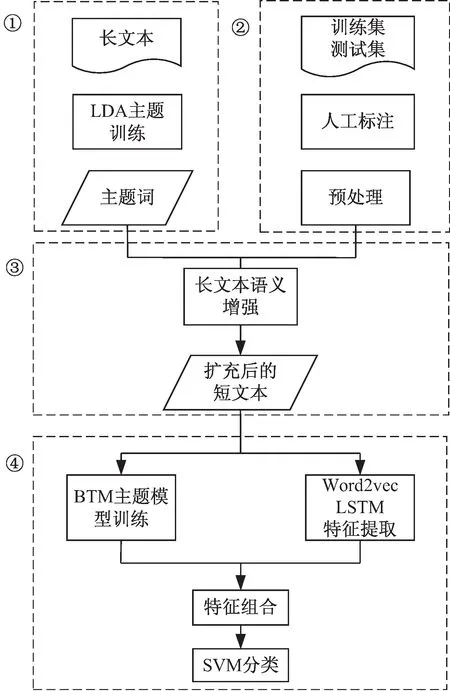
图1 分类流程框架
①长文本主题训练:外部语料库得到的与类别相关的长文本预处理后运用LDA主题模型训练并进行最大主题概率主题下词项的提取。
工程水土保持监测区划分为路基工程区、桥涵隧道工程区、取土场与临时堆土及弃渣场区、沿线附属设施区和施工场地及便道区。监测的重点区域为取土场、弃渣场、临时堆土场、大型开挖边坡及路基边坡、施工场地及收费管理所等服务设施。
③长文本语义增强:将长文本中提取到的词项基于匹配规则对预处理后的文本样本进行短文本扩充,增强短文本的语义信息。
②训练文本样本预处理:将用户评论分为测试集和训练集后进行人工标注、分词、去除停止词、词性标注等预处理。
④特征扩展与分类预测:基于BTM主题模型选取文本概率特征;基于Word2vec和LSTM提取文本的编码特征并进行特征组合实现特征扩展,并将其作为分类文本样本的总体特征。利用支持向量机的方法进行文本样本分类预测,检验该方法的分类效果。
1.2 长文本对短文本基于匹配的扩充方法
该文研究的中文用户评论属于短文本中的一类,其文本长度最长不超过一百个字符。可以通过引入外部语料库来扩充该类短文本的信息。但引入外部语料库内容的质量会直接影响短文本扩充的效果,因为引入扩充信息的同时也会引入大量的噪音数据,而且这些引入的外部文本数据缺少与原文所对应的上下文信息,引入之后会造成短文本原文语义内容和含义上的变化。因此,该文引入的外部预料信息与主题模型相结合,将其作为长文本放到主题模型中,长文本中最符合短文本语句内容的词项作为短文本信息内容的扩展。该文以小米手机的用户评论为研究案例,将在网络上爬取的用户评论分为三大类别,分别是:功能赞扬、功能改进和其他。
(1)功能赞扬:对小米手机内在功能、性能、系统、运行等正面的评价,是用户对手机各方面高满意度的认可。
(2)功能改进:对小米手机存在的一些缺陷,需要改善的方面的中性的或是负面的评价。是用户对手机各方面潜在的需求。
Step 3 Build the mapping form ujto pj,and complete the establishment of the DWWIKPof the manipulator.
首先,引入长文本,运用LDA主题模型挖掘最大概率下主题下的词汇进行短文本的扩充。对于LDA主题模型来说其主题数是不确定的,该文使用困惑度参数来确定长文本的最佳主题数。困惑度是度量概率分布或概率模型预测结果与样本的契合程度,即:对于一个文档D,所训练出来的模型对于文档D属于哪个主题的确定程度。困惑度越小,说明模型的效果越好,困惑度计算公式如下所示:
以上获取到的这三类用户评论都是短文本类型。由于短文本本身篇幅较短,导致本身特征偏少、信息量少。经过去除停止词、特征选择之后,去掉了一部分特征词,使得特征词更少,有些短文本中甚至就只剩下一两个特征词。特征词数量少虽然可以降低计算的复杂度,但是容易在分类中造成特征稀疏的严重后果,影响分类效率。为了降低文本特征稀疏对分类带来的影响,更好的进行分类操作需要在其他语料库中获取与之相匹配的长文本,将其放到LDA主题模型中进行训练。LDA主题模型以单个词的多项式分布对应主题分布,对短文本进行主题建模的效果不佳,但适合于长文本的主题建模。因此,该文设计了基于匹配规则的短文本扩充方法,既在外部扩充了短文本的文本信息又兼顾了短文本的上下文信息,对后面分类也起到了良好的效果。当分类文本样本的分词与长文本LDA模型训练后得出的最大概率主题下n个词项的任意一个词项重合时,将最大概率主题下全部的前n个词项都分配给分类文本样本,其基于匹配的短文本扩充方法具体流程如下所示:
输入:长文本在LDA主题模型下最大主题概率下的词项C{c1,c2,…,cm},需要扩充的短文本文档Ti{d1,d2,…,dn}
算法1:
输出:长文本扩充后的用户评论短文本
步骤:
常用的磨损颗粒检测法有铁谱分析法、磁塞检测法、红外光谱法、颗粒消光计数法[6].颗粒消光法利用含有颗粒的介质对激光的反射和吸收特征判断颗粒的大小和数量[7-10],该方法测量精度高,可同时获得颗粒的尺寸和数量信息,且实现方法简单,便于便携设计,达到“在线”测试目的.
②将Ti中的dj送入词汇集合C{c1,c2,…,cm}中;
③if短文本dj满足集合C{c1,c2,…,cm}中某个词项,则将集合C{c1,c2,…,cm}中的全部词项添加到Ti{d1,d2,…,dn}中
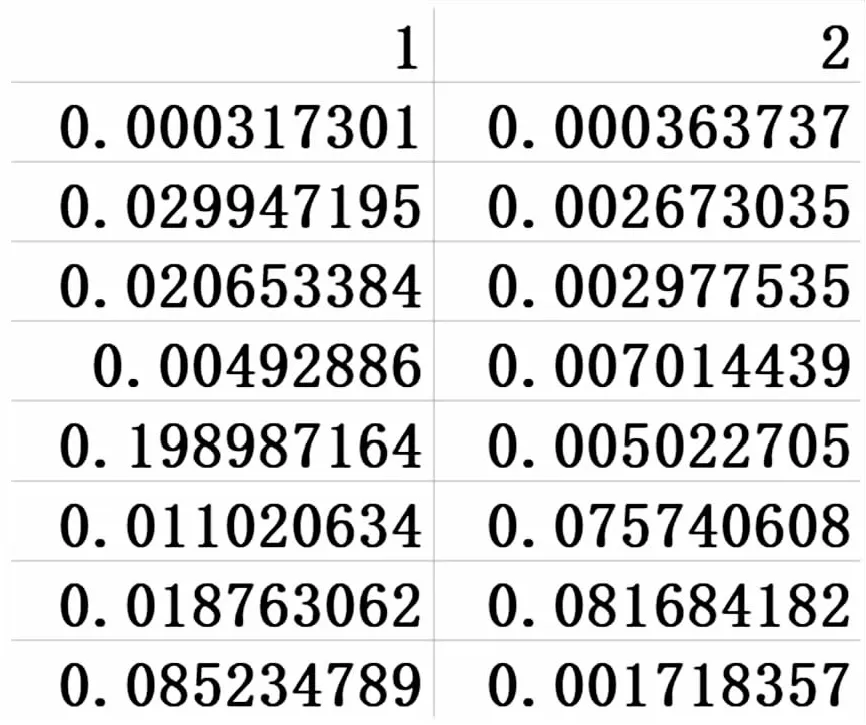
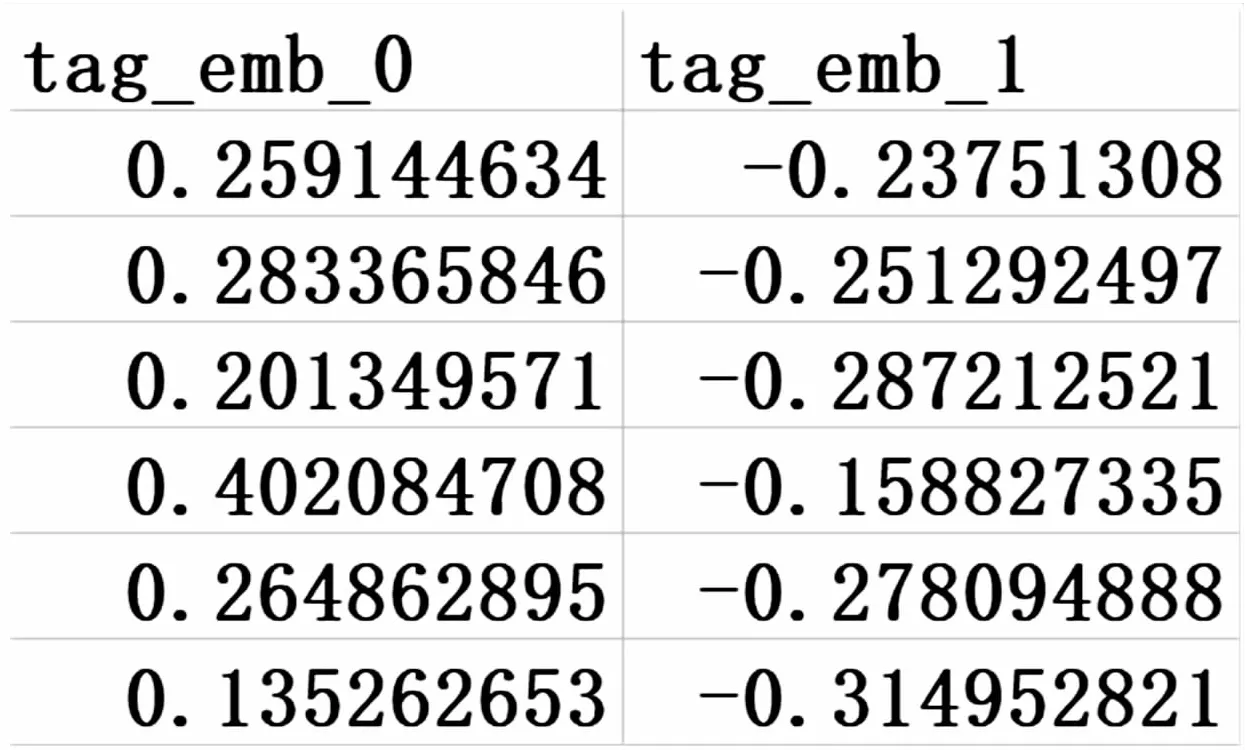
ifi 令i=i+1,重复②③步骤; else 21世纪,农业的可持续发展和保障粮食安全是全球的主要关注点。2010年,全球饥饿总人数增长到了10亿,随后联合国、G20和APEC都把农业发展作为了重要讨论议题。在国际方面,对农业的国际合作也展开讨论,将农业发展作为主要发展目标。农业发展速度较快时,农业合作便成为了当前国家和国家外交的重要主题[1]。 自从易非买了房后,他们的关系就不知不觉地进了一大步,有一天陈留送易非回来,老妈正好在家,他们就这样见面了,陈留表现得大方得体,母亲似乎也很喜欢。再后来,易非过生日,陈留带了蛋糕和鲜花来,就算是正式见面了。 令j=j+1,i=1,重复②③步骤; else 11月30日,国家统计局服务业调查中心和中国物流与采购联合会发布了中国采购经理指数,11月份,制造业PMI为50.0%,环比小幅回落0.2个百分点,处于临界点。对此,国家统计局服务业调查中心高级统计师赵庆河表示,11月中国制造业采购经理指数小幅回落,制造业景气度虽回落,但结构持续改善。 令j=j+1 ,i=1,重复②③步骤 对测试集、训练集进行去除停止词、分词、词性标注等预处理,在人工标注的处理下分为三大类:功能赞扬、功能改进和其他。预处理结束前后训练文本如表1所示。 表1 预处理前后训练文本 通过计算机课程实践教学内容、教学方式、教学评价贴近实际,研究增强学生主体意识能力,优化学习方式和策略,养成良好的习惯等,激发学生学习兴趣,提高学生的课程实践素养,促进学生发展计算机实践技能以及综合分析、发现和解决问题的能力,让学生创新精神和实践能力。 实验数据包括来自京东APP的小米11型号手机的真实用户评论和从百度百科、维基百科、小米官网、知乎等平台获取的小米11型号手机测评介绍相关的长文本。其中长文本共计11 551个字符。真实用户评论6 016条,其评论时间在2021年6月到10月之间。将用户评论分割为句子,进行人工标记(笔者及两名计算机专业硕士生共同参与用户评论句子标记)标记完成后总共得到三类用户评论(功能赞扬,功能改进和其他)用户评论为4 490条。其各类用户评论的数量和示例描述如表2所示。 表2 用户评论数量及示例 问题的分类结果及评价标准在文中采用3项指标来衡量,即:准确率(Precision)、召回率(Recall)及F-measure(F1或F-score),如下所示: (1) (2) (3) 其中,TPi为用户评论分类模型分类为类别i的用户评论中实际属于类别i的用户评论数;FPi为用户评论分类模型分类为类别i的用户评论中实际不属于类别i的用户评论数;FNi为用户评论分类模型没有分类为i的用户评论但实际属于i的用户评论数。类型i的准确率是指分类得到的类型i的用户评论中真正属于类别i的比例;类型i的召回率是指分类得到的真正类型i的用户评论占数据集中类型i的用户评论的比例。召回率和准确率两者是相互制约的。F-measure是评估准确率和召回率的调和平均值,提供了两者结合的精确度量。 其中,M为文档集合中文档的总数目,Nd为第d篇文档中词项的数目,p(wd)为第d篇文档的概率,也即这篇文档中每个词项概率的乘积,而对于任意一个单词w,单词概率p(w)=∑p(z|d)×p(w|z),z代表主题,p(z|d)为各个主题下该词所在文档的概率,p(w|z)为该词在各个主题下的概率。图2表示长文本在LDA主题模型中各个主题数下困惑度的折线图。由图2可知,在主题数为30时,困惑度最小。因此,选取主题数为30为最佳主题数,并选取其中最大概率主题下的词项作为短文本的扩充。 (3)其他:不包括前两方面,一些其他的评价,例如物流、客服、价格等。 ①令i=1,j=1; (4) 2.3.1 长文本主题确定 图2 长文本在各个主题下的困惑度 2.3.2 长文本语义增强 对预处理后外部语料库中的长文本运用LDA主题模型进行文档-主题概率,主题-词矩阵的共现。首先,选取所有主题中概率最大的主题;之后,选取最大主题下概率最大的词项,选取的最大概率主题下的前30个词项按概率排序依次为“支持,屏幕,视频,电影,提升,拍照,性能,模式,素皮,镜头,高清,像素,蓝牙,功能,采用,玻璃,智能,曲面,机身,旗舰,全新,切换,影像,系统,无线,夜景,搭载,美颜,专业,充电”。分别选取不同数量的主题词基于匹配规则进行短文本的扩充,其扩充示例如表3所示(选取最大概率主题下的前5个词项扩充)。扩充后的短文本语义信息与上下文关系更加完备,于是将其作为下一步特征扩展和分类的文本数据集。至此完成了分类流程中的第三部分。 顾实《汉书艺文志讲疏》云:“此《屈原赋》之属,盖主抒情者也。”〔4〕179“此《陆贾赋》之属,盖主说辞者也。”〔4〕183“此《荀卿赋》之属,盖主效物者也。”〔4〕188 表3 词项扩充示例 2.3.3 特征扩展与分类 将长文本中获取的词项扩充到用户评论中,使短文本获得了较为完备的语义信息,下一步是进行分类流程中的第四部分:即短文本特征扩展。首先,将词项扩充后的短文本作为本文的分类样本数据集。运用BTM主题模型进行训练得到文本样本的概率特征数据集,如图3所示,其中行数代表需要进行分类的文本样本数据数量,列数代表BTM主题模型提取的主题数量;运用Word2vec进行训练构建文本样本的词向量编码特征数据集,如图4所示,其中行数代表需要进行分类的文本样本数据数量,列数代表词嵌入矩阵的维度;运用LSTM长短时神经网络其特征是进入模型后的中间编码特征数据集,如图5所示,其中行数代表需要进行分类的文本样本数据数量,列数代表中间编码特征的维度。将上述得到的三类特征结合作为文本特征,完成了对短文本特征扩展。最后放到SVM分类器中进行分类训练,检验文中方法的分类效果。 图3 BTM主题概率特征集(部分) 图4 词向量编码特征集(部分) 图5 LSTM神经网络编码特征集(部分) 2.4.1 实验对比 在Anaconda的tensorflow虚拟环境下,使用Pycharm作为开发平台进行文本预处理、LDA主题模型进行主题概率的训练和预测(alpha=50/T,beta=0.005,获取前30个主题的概率特征,迭代300次)、BTM主题模型进行主题概率的训练和预测(alpha=50/T,beta=0.005,获取前100个主题的概率特征,迭代500次)、构建LSTM神经网络。为测试文中方法在用户评论短文本分类上的效果,选择基于向量空间模型的分类方法,基于词向量和LSTM模型分类方法,基于LDA主题概率、词向量和LSTM模型分类方法,基于BTM主题概率、词向量和LSTM模型分类方法与文中方法进行对比实验。其具体内容和实验结果如表4所示。 自2011年3月任职黑龙江省食品药品检验检测所所长以来,短短5年时间,安宏就先后获得省科技进步二等奖两次,三等奖两次;省科技发明三等奖一次;省医药行业科技进步一等奖一次,二等奖一次;省高校科技二等奖一次。同时,他还担任着省科学技术奖励委员会“医药制药与生物医学工程”行业评审组评审委员,省科学技术奖“医药行业”评审组评审委员,省科技经济顾问委员会“食品药品”专家组副组长。2012年,他获得全国医药卫生系统争先创优先进个人称号;2014年被评为省直机关“十佳公仆”;2015年被评为全省“优秀公仆”。 表4 对比实验的方法和数据 表4中,方法一采用的是传统的VSM向量空间模型,引入TF-IDF表示文本特征,虽然可以完成短文本分类但是由于短文本蕴含的信息量少、语句短小,因此这类传统方法会造成特征矩阵的稀疏性,从而导致分类效果不佳;方法二引入了词向量和深度学习模型,虽然可以解决方法一中特征矩阵稀疏造成的分类效果不佳的问题,但是仅仅引入了词向量一个特征维度并没有与主题模型相结合;方法三在方法二的基础上引入了LDA主题模型的文本主题概率特征的维度,对分类效果有一定的提升。但是LDA主题模型主要针对的是长文本文档下各个主题概率的共现,对短文本训练效果不佳;方法四是针对短文本的特征使用基于词对共现的BTM主题概率特征,虽然提高了分类效果,但是并没有与长文本结合解决短文本语义缺失的本质。文中所提出的结合长文本的分类方法在准确率、召回率、F-measure上明显好于前四种分类方法,既引入了结合LDA主题模型的长文本最大概率主题的主题词,对用户评论进行语义增强解决了短文本信息缺乏、上下文语义不足的问题,又引入了词向量、神经网络编码特征和BTM主题概率特征,解决了特征稀疏的问题,增强了分类效果。 2.4.2 长文本主题词数对短文本分类效果的影响 2.2.3 对铁磁性材质类植入物,或说明书未标明材质性质并且未说明若行MRI检查的条件或注意事项的植入物,归于MRI禁忌类。 一是加大涉农案件执行力度,加强失信联合惩戒,强化执行强制措施,切实维护乡村当事人的胜诉权益。二是积极开展国家司法救助,对权利受到侵害但无法获得有效赔偿的涉农案件当事人,给予适当经济资助,帮助他们摆脱困境。三是对经济确有困难的当事人,依法缓减免交诉讼费,确保困难乡村群众能够打得起官司。四是大力开展巡回审判,让法官多跑路、让群众少跑腿,降低群众诉讼成本,减少群众诉累,让乡村群众切实享受到便捷高效优质的诉讼服务。 表5表示文中方法结合长文本不同主题词数下对分类效果的影响。由表5分析得出,当引入长文本最大概率主题下的词数为30、25时,F-measure分别为0.930 6和0.942 2;引入词数为10、5和0时,F-measure分别为0.937 6、0.936 4和0.892 9;当引入的长文本最大概率主题下的词数为20和15时,F-measure分别为0.944 8和0.957 2;引入15个主题词时的分类效果最好,F-measure能达到0.957 2。这说明当引入长文本主题词的数量太多或太少都会影响分类效果。这是因为当引入的主题词数较多时会将泛化能力不强的噪声词扩充到短文本中,使得分类的噪声增多降低分类的效果;而引入的主题词数较少时,并不能扩充足够与样本相关的文本信息,造成上下文信息缺乏同样影响分类的结果。引入适当数量的主题词是提高分类效果的关键。 表5 文中方法结合长文本不同主题词数下的分类效果 该文提出了基于BTM主题模型和长文本语义增强的用户评论分类方法。从基于语义的层面上提出运用相关长文本在LDA主题模型上对短文本进行扩充,解决了短文本信息量少、缺乏上下文信息的问题;从基于规则的层面上提出用BTM文本主题概率和词向量作为特征进行特征扩展,解决了特征稀疏的问题。从京东APP获取的小米手机真实的用户评论和从百度百科、维基百科、小米官网、知乎等平台获取的小米11型号手机相关的长文本进行实验研究,利用支持向量机的分类方法多次与其他方法进行对比实验,结果表明提出的方法在选取适合数量的长文本主题词时其预测准确率、召回率、F-measure均有良好的表现。但是,该方法仍然有一定的不足,例如对用户评论进行人工标注时具有一定的主观性,会造成标注误差;在运用主题模型进行概率特征预测时最佳参数的选取等。在下一阶段的研究中可以挖掘更具有代表性的特征进行特征扩展来解决特征稀疏的问题;进一步尝试不同主题概率特征的数量对分类效果的影响;进一步验证该方法在不同数据集上的分类效果。这些是未来需要研究和解决的问题。1.3 训练集、测试集预处理及人工标注

1.4 短文本BTM主题训练、词向量训练及SVM分类
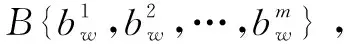
2 实验及结果分析
2.1 实验数据

2.2 评价标准
2.3 实验过程



2.4 文中方法及对比方法结果分析


3 结束语
