二阶段手写汉字骨架提取优化
2023-07-21陈泓汉熊显航
陈泓汉,王 涛,熊显航
(1.华南师范大学 人工智能学院,广东 佛山 528200;2.华南师范大学 计算机学院,广东 广州 510631)
0 引 言
图像细化是在保持原图像拓扑结构的情况下,抽出图像的单像素宽度过程[1]。目前细化算法已广泛应用于运动检测[2]、农作物[3]、裂缝检测[4-5]、工业仪表[6]和汉字研究[7]等场景。
文献[8]提出基于ZS算法的改进方法,通过删除保留模板得到单像素且毛刺更少骨架。针对骨架多分叉点未合并问题,文献[9]引入圆盘对其进行合并,继而修复。方法过程清晰,但分叉点会过度合并。通过骨架轮廓圆盘半径信息,文献[10]对畸变处进行修复,该方法过程耗时较多。文献[11]提出复杂区域检测法,并根据笔段方向及曲率进行修复。该方法只适用字体宽度较细情况。
文中算法借鉴文献[9-10]中的圆盘概念,考虑汉字方正特性使用矩形进行分叉检测。采用了二阶段聚类合并克服文献[9]以及文献[11]存在的问题。根据区域畸变程度采用不同范围修复,同时对畸变区域归类,采用相应修复策略。
1 算法描述
提出的改进算法核心优化思路可分为两个阶段。第一阶段是为了精准找到字体畸变待修复区域即笔画的交错处以及拐点处,通过引入字体宽度Wf概念进行的二阶段合并提高对不同字体交叉区域识别的准确率;第二阶段需要划分畸变区域类型并采取相应的策略进行修复。
文章在传统判断拐点的基础上,进行二次筛选合并得到符合分叉点特征的点。第二阶段是根据畸变区域信息,清空畸变区域重新连接分叉点,形成更符合该手写汉字风格的骨架连接图。
1.1 分叉点检测
目前分叉点检测方法常见的有角点检测法[12]和段化法,这两种方法都是在原始文字图像上进行处理,存在检测耗时长以及误判多等问题。
文章提出的分叉点检测处理是细化后骨架,分为两阶段,一阶段主要是筛选出分叉特征点,二阶段为对筛选的特征点簇群进行聚类合并,从而得到准确的单分叉点。
定义1 字体宽度Wf:未经细化字体二值图前景点数量与细化后的骨架全景点数量的比例,称为字体宽度Wf,计算过程如式(1)所示:
(1)
其中,N(S)为细化后骨架图前景点数,N(0)为原二值图前景点数
定义2 向量夹角:局部向量所形成的角度,如aij趋向于1时,表示两向量为平行关系,通过余弦相似度可以量化分支的方向关系,具体计算过程如式(2)所示:
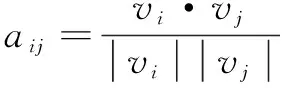
(2)
1.1.1 分叉特征点筛选
得到细化后的骨架与原图信息,通过计算得到该手写汉字字体宽度Wf,待筛选的特征点为Sd={P0|A(P0)≥3,P0=1},即该点满足的8-邻域存在三个以上的前景点数。筛选流程如下:
(1)以Wf为范围对Sd进行分类得到簇群;
(2)从单簇群任选三点形成向量vi、vj;
(3)如aij≠1,加入点集Sdf;
(4)重复遍历簇群,得到所有满足的点。
1.1.2 分叉特征点聚类合并
集合Sdf为特征点簇群,不能有效表示单个分叉区域,因此还需进行聚类合并[13]。为解决过度合并分叉点以及未能正确合并的问题,文中的聚类合并分两阶段进行,一阶段筛选区域畸变程度小的分叉点,二阶段合并区域程度畸变大的分叉点。
在进行聚类合并前,需要了解二阶段聚类合并得到的不仅是分叉点,考虑畸变程度不同,待修复面积也应有所区别,因此引入修复区域概念。
定义3 修复区域:动态矩形的中心为最优分叉点PL,动态边长为Ldy,未经过第二阶段聚类合并Ldy为Wf。
一阶段聚类合并是为了得到紧密的分叉点簇群。根据单簇群中坐标的x、y均值,得到修复区域的PL坐标,Ldy为字体宽度Wf。此时细化得到的骨架畸变较小区域已被正确识别,依然存在未能正确合并的情况,因此需要二阶段的聚类合并操作。同时为了防止合并错误,引入了定义4、5。
定义4 延展分支特征点:分叉特征点P0可以不经过任何其他分叉特征点到达端点。
定义5 标准T型分叉特征点:分叉特征点P0在矩形Ldy为字体宽度Wf局部范围内满足标准十字以及T型的骨架结构。
在第二阶段,距离min Pts为字体宽度Wf,得到待合并点簇Smerge。同时补充了3个限制条件防止过度合并,具体如下:
(1)如单簇待合并分叉点数超过3,任取三点形成aij,aij→1满足合并条件;
(2)单簇中存在两个以及以上延展分支特征点,则该簇不满足合并条件;
(3)单簇中存在一个或多个标准T型分叉特征点,则该簇不满足合并条件。
条件1、2主要是防止手写字体局部笔画过于密集导致分叉点的误合并;条件3主要是避免标准的细化骨架结构被过度合并。三个限制条件合理保留了传统细化算法可准确细化的区域,同时也避免了局部最优分叉点过于密集产生,以至于过度合并丢失了骨架应有的细节。结果如图1所示。

图1 合并局部最优分叉点结果
经过第二阶段合并后修复区域的边长Ldy以及中心坐标PL,分别为:
Ldy=max(xmax-xmin,ymax-ymin)
(3)
PL=(xmin+Ldy,ymin+Ldy)
(4)
其中,xmin、xmax、ymin、ymax为Smerge中待合并点的修复区域中x、y坐标的最小和最大值,经过二阶段得到的待修复分叉点(PL,Ldy)的集合用Sdy表示。
1.2 分叉点修复
根据二阶段聚类合并得到的待修复集合Sdy,分析集合Sdy中(PL,Ldy)形成动态矩形与骨架形成的交界点。同时依据汉字笔段形成规律[14-15],结合待修复区域与骨架相交点信息,将分叉点进行归纳分类。
为了更好地进行分析,归纳出定义6~11五种类型的畸变区域对应后续修复策略。
定义6 交界点可延展性:如延展Wf的距离,得不到骨架上的点则认为不可延展。
定义7 四通区域类型:交界点集数为4,各点满足交界点集四边界有且仅有一点。
定义8 三通区域类型:分叉点交界点集数为3,其中四边界各有且仅有一点,且各边界点都具有可延展性。
定义9 毛刺区域类型:分叉点交界点集数为3,其中四边界各有且仅有一点,同时仅存在一边界点具有不可延展性。
定义10 拐角区域类型:交界点集中个数为2,其中四边界各有且仅有一点,两边界为相邻关系。
定义11 多通区域类型:四边界存在任意一边界存在两个及以上的交界点。
待修复分叉点类型如图2所示。

图2 待修复分叉点类型
图3为交叉区域类型归类流程,具体描述如下:
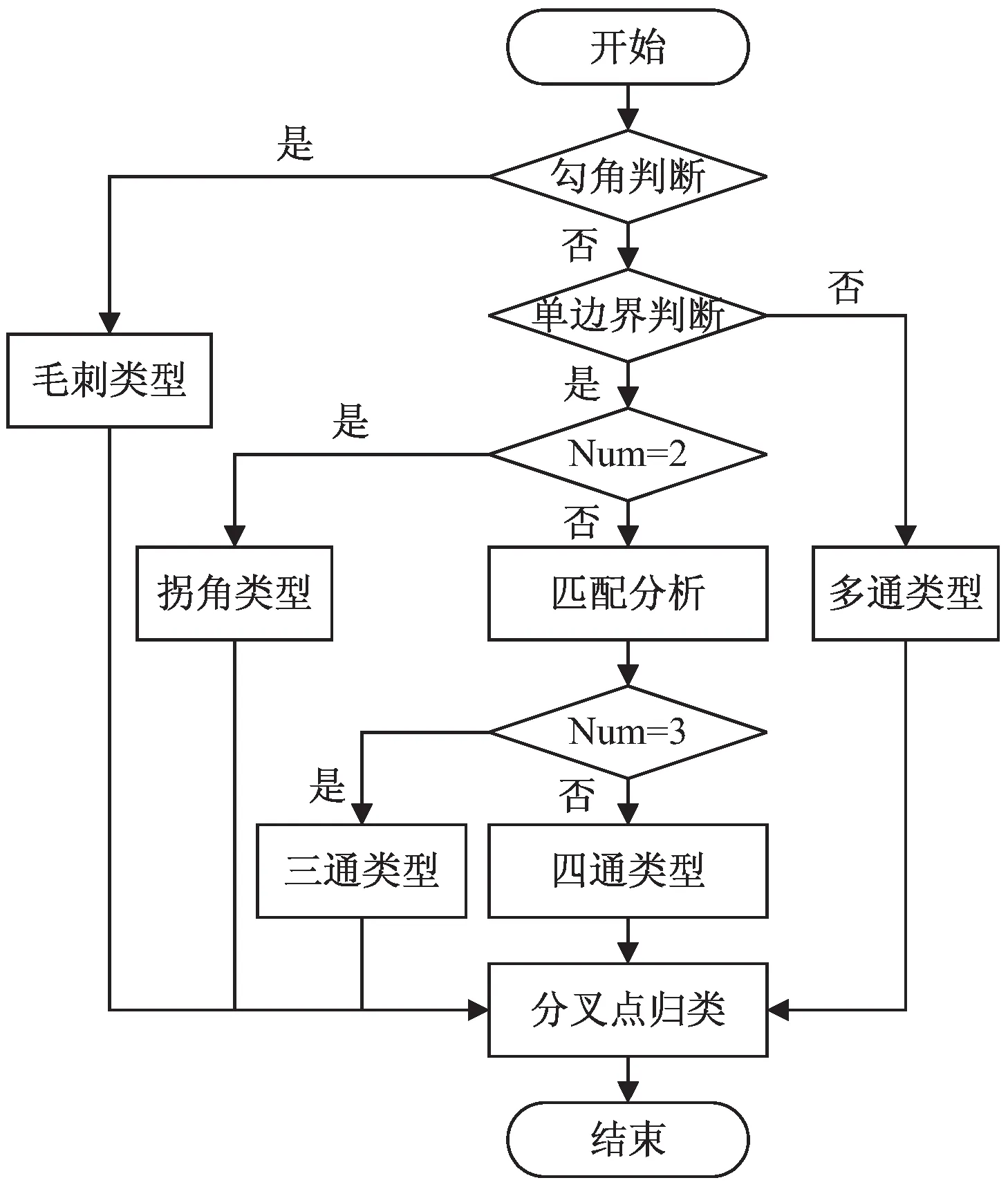
图3 交叉区域类型归类流程
(1)遍历集合Sfix中的元素点,如该区域满足毛刺区域类型定义,则可直接归类;
(2)单边界判断,如该点四边界点集存在任意边界,存在两个及以上的分支,归类为多通区域类型;
(3)根据交界点集Num进行分类,如Num为2,归类为拐角区域类型;
(4)匹配分析为根据分支局部斜率找到于与走势相近的分支,如图2中四通区域类型,南北分支的局部斜率aij→1,则可将南北分之判定为匹配关系;
(5)得到匹配关系后,根据当前交界点集Num为3归类为三通区域类型,否则为四通区域类型。
通过上述交叉区域类型归类流程,可得到相应区域类型,接下来需要根据相应的区域类型展开修复工作。
四通区域类型修复策略根据得到的匹配关系集合,处理流程如下:
(1)将两相匹配的边界点按照局部斜率进行延展;
(2)存在未处理的点,计算两点到PL与匹配点相交的直线距离,取最小距离方案将未处理点与之相连。
由图4可看出,常见的四通区域类型根据分支匹配进行准确修复,修复后区域走势自然,也很好地解决了笔画错误粘贴问题。
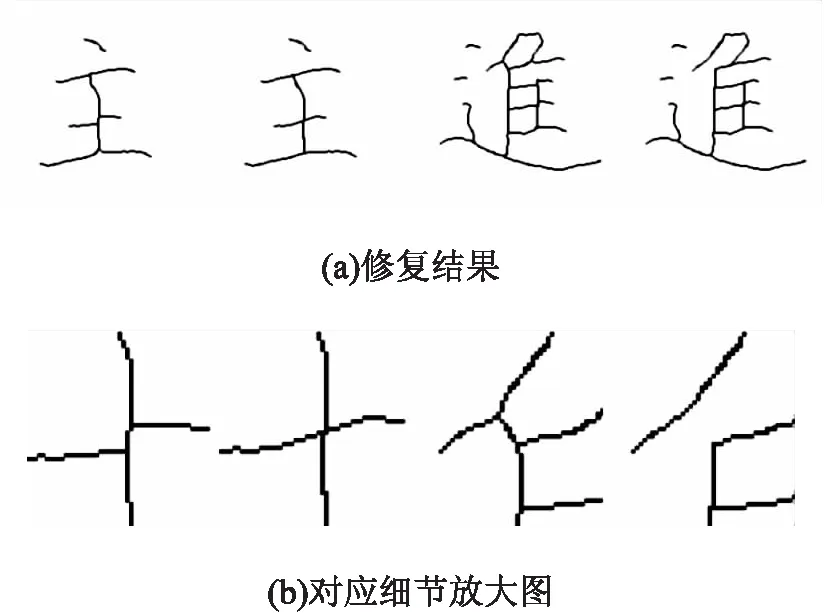
图4 四通区域类型修复
三通区域类型修复策略处理流程如下:
(1)如存在匹配关系集合,则将匹配的边界点按局部斜率延展相连;
(2)未处理的点按该点的局部斜率进行延展,连接到匹配分支形成的直线上;
(3)如不存在匹配关系,则将待修复点集都连接到PL上。
如图5所示,骨架交错区域发生畸变,此处的笔画走势显得抖动,不符合实际字体的特点。通过局部斜率将笔画延展相交在一起,正确还原了笔画趋势。

图5 三通区域类型修复
拐角区域类型处存在毛刺问题并没形成单独分支,产生的毛刺是因为细化发生轻量畸变。因此对该区域进行局部斜率重连,因此采取的拐点区域类型修复策略为:
(1)将各交界点按照局部斜率延展,得到相交点;
(2)交界点连接到相交点上。
经过拐点修复策略后的骨架效果如图6所示,其产生的毛刺都被有效处理,局部笔画抖动基本消失。

图6 拐角区域类型修复
毛刺区域类型因存在边界点具有不可延展性导致该区域存在较大的毛刺,相关结果如图7所示,毛刺区域类型修复策略的处理流程如下:
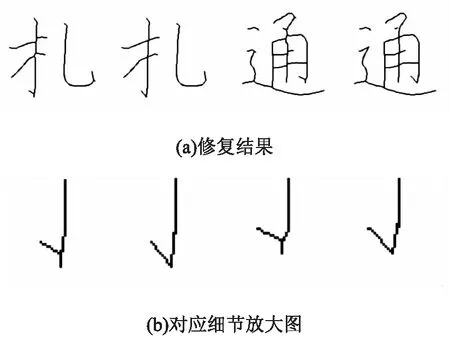
图7 毛刺区域类型修复
(1)得到未能延展的交界点Pex;
(2)清除Pex到端点间的前景点;
(3)将其余的交界点按局部斜率延展相交。
汉字结构产生多通区域类型都是多笔画的聚集点,对多通策略的处理流程如下:
(1)通过修复信息Sdy得到分叉点PL;
(2)将交界点连接到分叉点PL上。
由于不同笔画在这个分叉点汇集,笔画的斜率以及粗细导致细化算法在此处是必然发生畸变的,修复策略将不同的分支边界点连接到二阶段合并得到的最优分叉点上,效果如图8所示。
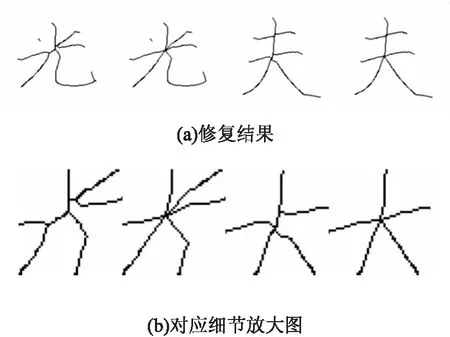
图8 多通区域类型修复
2 实验结果与分析
通过实验验证文中算法的有效性。实验环境如下:操作系统为windows10,处理器为英特尔7700k,16G运行内存,使用跨平台计算机视觉OpenCV。使用颜真卿的楷书作品《多宝塔碑》、田英章《弟子规》以及《九成宫醴泉铭》共967个楷书字体作为实验数据。
2.1 交叉点检测算法对比
在使用细化算法得到骨架后,首先通过计算原图像有效点与骨架有效点比例得到Wf后,根据提出的交叉点检测算法得到待修复集合Sdy,为更好量化不同分叉点检测算法的性能,提出相关定义12~16。
定义12 人工标注分叉点Pmark:对实验数据的原图进行人工处理,标记所有分叉区域的中心位置点作为Pmark。
定义13 分叉点检测准确率BRR:如单Pmark有且仅被Sdy集合中(PL,Ldy)形成的动态矩形覆盖,则认为该被正确识别。分叉点检测准确率BRR等于被正确识别的分叉点数占人工标注分叉点数的比率。
定义14 过度合并分叉点率ORR:Sdy集合中(PL,Ldy)形成的动态矩形覆盖两个及以上Pmark,则认为存在过度合并的情况。ORR等同于过度合并的Pmark与人工标注分叉点数的比率。
定义15 未合并分叉点率URR:Sdy集合中存在两个及以上(PL,Ldy)形成动态矩形覆盖单Pmark,则认为Sdy集合存在未能正确合并情况。URR等同于未合并的(PL,Ldy)数与人工标注分叉点数的比率。
定义16 错误检测率ER:Sdy集合中存在(PL,Ldy)形成动态矩形未能覆盖任何Pmark。ER等同于未能覆盖任何Pmark的(PL,Ldy)数与人工标注分叉点数的比率。
图9为文中交叉点检测算法与最大圆盘法[9]以及复杂区域检测算法[11]的对比实验结果。从左到右依次书写字体原图,最大圆盘法过程分析图,最大圆盘法结果,复杂区域检测算法结果以及文中算法得出的交叉点结果。
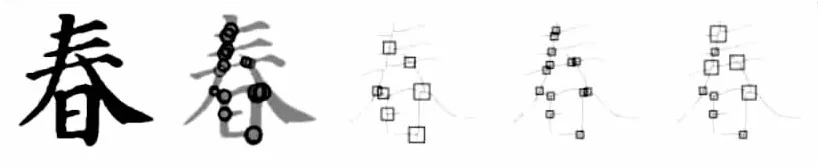
图9 不同交叉点检测算法结果对比
从对比结果可以看出,最大圆盘法[9]存在过度合并的问题,导致最终在分叉点密集区域,多分叉点被错误识别成单分叉点。复杂区域检测算法[11]对畸变程度较大的区域进行未正确识别合并,从而导致单分叉点检测成两个或以上的分叉点。文中提出的二阶段检测法正确识别到分叉点,同时对畸变区域范围也作出更准确动态调整。
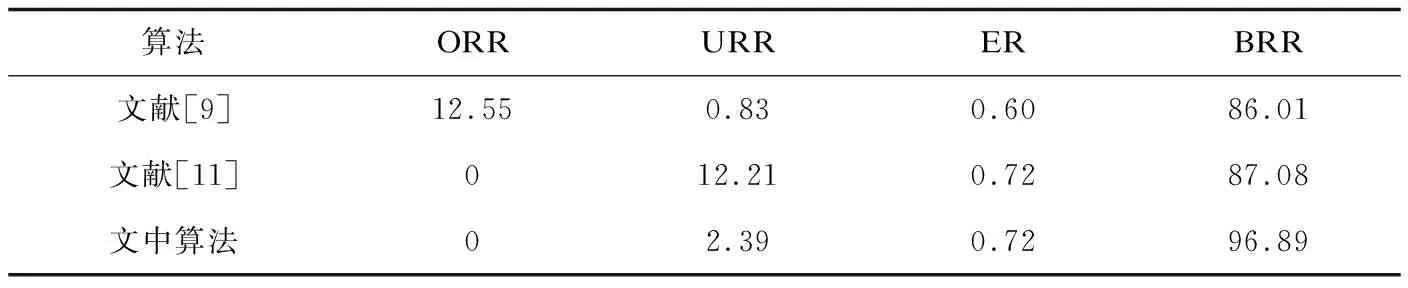
表1 分叉点检测算法准确率 %
2.2 骨架修复对比
实验中,绝大部分骨架畸变区域都被二阶段检测算法很好地识别检测到。受文献[16]中相似度计算方法以及文献[17]提出的骨架特征不变量描述接合点启发,此处将人工标注正确的骨架与经优化算法得到的骨架进行重合度比较,作为衡量不同细化算法的性能指标。表2中的数据是指识别到的分叉区域按照修复类型进行修复,未修复导致的原因是不满足文章提出的修复类型,导致不能找到相应的修复策略,可以看出通过二阶段检测出的分叉区域都能很好归类成修复类型,并采取了相应的修复。修复效果对比如图10所示。

表2 细化实验效果统计

图10 不同骨架提取算法结果
定义17 策略覆盖率SCR:待修复集合Sfix归类成区域类型的成功率,策略覆盖率SCR等同于归类区域类型个数占人工标注分叉区域数量的比率。
定义18 骨架提取准确率ERR[11]:对畸变区域进行人工标注骨架,ERR等同于重合骨架点数占标注骨架总点数比率,若所提骨架与标准骨架一致,则所有骨架点应重合。
根据表2数据可以得出,未能修复区域主要是因为分叉区域得不到归类的区域类型。从SCR可知,对于区域类型归类已经很好覆盖不同笔画交错形成的畸变区域,文献[11]提出的骨架提取准确率可以很好地作为修复效果量化指标。为进一步量化区域修复的效果,通过对比标注骨架与文中的修复策略得到的优化区域骨架重合比率,验证文中算法的有效性。提出的优化算法在二阶段聚类合并因为限制条件判断过程,导致算法的时间会增多,而文献[9]在计算最大圆盘方面消耗以及计算圆盘与骨架交点的计算时间花销占重较大。
文献[9]方法根据最大圆盘获取到中心点进行连接,对于拐角处的修复有着不错效果,由于没有三通以及四通分叉区域笔画走势延伸等分析,修复方面效果不足。因此可得出文章提出的优化算法更高效可行。
3 结束语
文章提出的交叉点检测算法更合理适用字体宽度Wf以及动态矩形概念识别分叉点,经实验验证可更准确识别分叉区域。通过提出的修复策略可覆盖绝大部分字体畸变的区域,修复后的骨架更能反映出手写汉字的特征,笔画会更为顺畅且交叉以及拐角区域的笔画走势更为自然。提出的优化算法是基于细化后骨架结果进行修复,不针对具体细化算法畸变问题,可适用范围更广。
二阶段优化算法适用于较为规则的手写汉字,对于笔画走势灵活或是笔画相对潦草的草书等风格字体,该算法修复效果不足。因此后续工作会针对走势更灵活、潦草的草书[18]进行相应研究以及骨架提取优化。
