科研大数据迷雾模型的建构与解构
2023-07-20丰佰恒杜宝贵
丰佰恒 杜宝贵


关键词:科研大数据;科研大数据迷雾;模型;生态系统;数据治理
DOI:10.3969/j.issn.1008-0821.2023.07.001
[中图分类号]G203 [文献标识码]A [文章编号]1008-0821(2023)07-0003-11
科研大数据是隶属于大数据,产生于科研,辅助于科研,具有规模性、高速性、价值性、多样性、高维性、错综性等特征,反映自然与社会现象的一种数据类型。在数据价比黄金的时代,科研大数据作为国家基础性战略资源引起多国(地区)关注。美国以《大数据研究发展倡议》等率先拉开科研数据治理的序幕,并在《大数据研究与发展计划》中提及医疗、航天等众多领域的科研数据管理,英国在《把握数据带来的机遇:英国数据能力战略》中警醒数据机遇,日本在《大数据时代的人才培养》中倡议培养专业化人才,中国亦在《科学数据管理办法》中制定科研大数据管理规范。各国(地区)均聚焦于科研大数据的发展,使得数据量激增的同时,也带来了科研大数据造假、科研大数据维度错乱、科研大数据冗余等一系列“迷雾”问题,影响数据质量,危害数据安全。现有研究多集中在科研大数据共享、科研大数据时效、科研大数据质量管控模型、科研大数据维度灾难、科研大数据安全等方面,对科研大数据迷雾的专项探析还存在些许不足。此外,在各国(地区)的科学数据交流愈加频繁、数据维度急剧攀升的今天,科研人员的迷雾甄别能力愈发关键。在构建科研大数据迷雾模型基础上,进一步了解科研大数据迷雾的类型、路径及机理有助于科研人员走出“迷雾丛林”,维护科研大数据生态系统的和谐稳定。因此,本文以识别迷雾数据、规避科研风险为主要研究目的,以科研大数据生态系统中不断演化的迷雾型科研大数据为主要研究对象,以科研大数据库建设、科研决策、科研大数据政策制定为主要应用场景,创造性地建构了科研大数据迷雾模型,以期在丰富科研大数据相关理论的同时,对解决科研大数据冗余、科研大数据造假、劣质科研大数据传播管控、科技政策制定等现实问题提供有益启示。
1科研大数据迷雾概念的提出
“迷雾”的概念缘起于气象学,后广泛运用于其他领域。在经济学领域,迷雾指干扰经济发展方向、阻碍经济发展的不稳定性因素;在政治学领域,迷雾指与本质相悖、掩盖目的、迷惑敌方决策的一种政治行为;在新闻学领域,迷雾指脱离事实真相甚至与事实相反的扭曲报道等;在情报学领域,信息迷雾是信息战的重要手段,指不真实、政治相关、隐藏目的、精心设计、以进攻为目标的虚假情报。数据迷雾是指用于诱骗、隐真的虚假、有毒、垃圾数据。与“信息迷雾”相比较,“科研大数据迷雾”是“信息迷雾”的重要核心内容;信息迷雾是数据迷雾的“外壳”,为“科研大数据迷雾”的产生提供了环境。信息迷雾越多,其产生科研大数据迷雾的可能性越大,反之,科研大数据迷雾越多,并经加工后产生信息迷雾的程度越大,故二者是相辅相成、相互促进的关系。“信息迷雾”与“科研大数据迷雾”两者之间又存在区别:首先是本质属性不同,科研大数据作为一种特殊的数据类型,本质上仍是具有即时高价值性的数据,而信息是对数据的反映,是对数据所记录事实的传递;其次是人为干预程度不同,单一数据诞生初期并不具有迷惑性,当人员将数据应用于某一目的时,多重属性的叠加,使其具有特殊含义,迷惑性逐渐显现,而信息迷雾的迷惑性从信息产生初期便有大量的人为干预;最后是应用领域不同,信息迷雾最早出现于军事领域,而科研大数据迷雾往往伴随科研活动产生。由于数据包含着科研大数据这一种特殊类型,因此,数据迷雾与科研大数据迷雾紧密相关,是科研大数据迷雾的外延和上位集;换言之,科研大数据迷雾包含于数据迷雾,是数据迷雾的子集。与数据迷雾相比,科研大数据迷雾服务于技术壁垒,专指在不同科研大数据机构数据交流过程中,导致科研大数据质量与安全性降低,以及干扰科研人员决策的各类数据,其更集中体现科研域尺度,是“迷雾”在科研域的“直接而具体”的表现形式。
从空间角度看,“迷雾”入侵至科研大数据链后,以链带状在科研大数据生态系统中传播,可新生、流通于科研大数据生态链的任意节点,由此可见其具有全链性;从时间角度看,其出现可大致划分为浓淡两期,随时间而波动,在一定趋势线上重复可预测,但迷雾数据的催生因素复杂,有时亦会出现突变情况,因此可认为其具有不严格波动性;从形态角度看,当出现相互引用错误、失效等数据时,迷惑性数据弥散形成迷雾,在科研大数据生态系统中久久不能消散,处于缥缈悬浮、动态演化的状态,因此其具有雾化性特征;从人员分布角度看,学者间相互的数据引用使其扩散,但学科间存在一定的壁垒,对数据的引用也存在强弱关系的差异,因此迷雾数据的出现往往聚焦于特定的学科,各学科或主题间存在派系的关联,可见其具有派系性特征;科研活动有着高精确度的要求,迷雾数据迷惑科研工作人员行为、加大实验误差、使指标失真、影响科研进程,甚至导致灾难性后果,因此其具有灾难性。
综合以上分析,本文认为科研大数据迷雾( Sci-entific Research Big Data Fog,SRBDF)是指衍生于数据迷雾,以科研域虚假、有毒、垃圾、冗余数据为基本组成,以全链性、不严格波动性、派系性、雾化性、灾难性为基本特征,在利益驱动下流转于科研大数据生命周期,降低科研大数据质量、干扰科研决策、引发数据灾难进而扰亂科研大数据生态稳定的一类数据的集合。2科研大数据迷雾模型的建构
科研大数据作为基础性科技资源,引起诸多学者关注,并从数据共享与数据治理等不同角度构建了科研大数据相关模型。例如聚焦于科研大数据再生、科研大数据共生、科研大数据变异的科研大数据生态模型,以生态学的视角介绍了科研大数据复杂的生命周期;基于尖点突变理论、病毒传播理论有科研大数据治理模型,侧重于对科研大数据的宏观治理;从数据伦理、科研诚信等不同视角出发的科研大数据共享模型,则致力于促进科研大数据的共享,以及关注科研大数据服务模式、服务系统的科研大数据服务模型等。综上可以看出,以往的模型较多关注科研大数据生态系统的宏观治理,鲜有迷雾型科研大数据的专项研究,针对“迷雾”问题的深度探索仍略显不足。
科研大数据迷雾在科研大数据生态系统中逐渐演化生成,从“科研大数据生态系统”对“科研大数据迷雾”的作用角度看:在科研大数据生态失调下(即发生异常时)产生科研大数据迷雾,科研大数据生态系统是科研大数据迷雾的客观环境,迷雾的生消都必须在系统内发生。科研大数据量激增使数据库得以丰富的同时,也为“科研大数据迷雾”的产生提供了“土壤”。从“科研大数据迷雾”对“科研大数据生态系统”的影响角度看:“科研大数据迷雾”作为一种独特的风险,是科研大数据生态系统的高危域。迷雾浓度影响系统稳定性,当迷雾浓度越大时生态系统越不稳定。科研大数据迷雾与科研大数据生态系统息息相关。
科研大数据迷雾作为干扰科研大数据生态稳定的一类数据的集合,本质依然是数据,仍具有数据的周期性生命特征,数据生命周期模型将数据管理划分为生产、传播、消费、分解等阶段,同样,科研大数据迷雾亦会经历初生、激增、消散等过程。由此可见,数据生命周期理论对科研大数据迷雾的阶段划分具有较强的适用性。
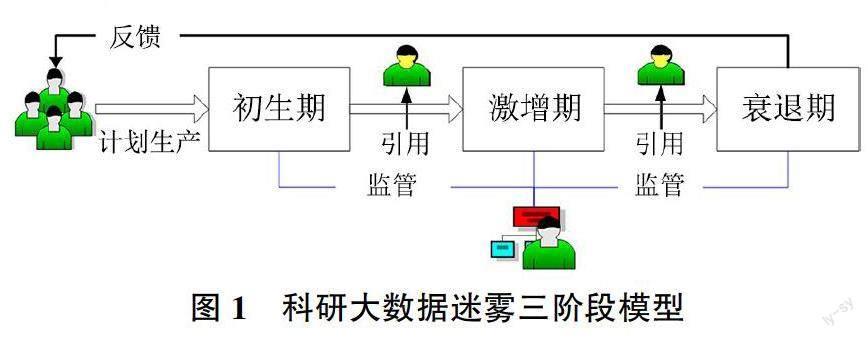
因此,本文基于科研大数据生态系统理论与数据生命周期理论,将科研大数据迷雾模型划分为初生期、激增期、衰退期,并将模型内相关人员划分为生产者、消费者、监管者、传递者,以建构科研大数据迷雾三阶段模型,如图1所示。
1)阶段一:SRBDF初生期
此阶段是科研大数据迷雾的计划阶段,迷雾生产者在利益驱动下生产迷雾数据,初生期科研大数据迷雾样本较少,“迷雾”还没有大范围传播,此时的科研大数据迷雾聚集现象较为明显,即在初生期科研大数据迷雾往往集中在单一学科领域,因此阶段一的迷雾较弱。
2)阶段二:SRBDF激增期
在激增期迷雾数据量急剧增加,已扩散至相关领域,影响范围逐渐增大,因此这一时期的科研大数据迷雾多呈弥散型状态。此时迷雾强度将会出现峰值且短期内迷雾型数据会有爆发式增长的可能,对科研人员与政府来说最难控制,危害性也最大。对于迷雾生产者而言此阶段获益颇丰。
3)阶段三:SRBDF衰退期
在第三阶段,科研大数据监管者严格监管,科研大数据迷雾强度逐渐降低。对科研大数据消费者来说,此阶段科研大数据迷雾灾害性逐渐减弱。对于迷雾生产者而言,科研大数据迷雾的得益将会反馈,为下一步的科研大数据迷雾计划提供参考。
科研大数据迷雾的存在给科研大数据生态系统带来极大的安全隐患,其不仅仅会影响科研结果,还会影响政府决策,导致科技政策的制定出现偏差,甚至影响公众对科研结果以及科技政策的认同感。与已有模型不同的是,科研大数据迷雾模型(Scientific Research Big Data Fog Model, SRBDF-M)以迷雾型科研大数据为主要研究对象,以帮助相关人员认识迷雾、了解迷雾、走出迷雾、科学决策进而维护科研大数据生态稳定为目的,以初生期、激增期、衰退期为主要划分阶段,专注于迷雾型数据的溯源与演化分析,侧重于深入剖析科研大数据迷雾的生成、类型、作用路径等,是科研大数据治理模型中对虚假、有毒、垃圾、冗余数据专项研究的子模型。
3科研大数据迷雾模型的解构
3.1科研大数据迷雾的组成类型分析
基于前文对SRBDF-M建构的基础,在时间、空间、强度、利益、繁育等维度,对科研大数据迷雾的组成类型进一步阐述分析。
3.1.1时间维
结合科研大数据迷雾的波动性特征,在时间维度上,可分为“初生型”“激增型”“衰退型”3种类型,如图2所示:
1)初生型(Primary Type)是指在初生期SRB-DF覆盖范围较小、影响力度较弱,此时其具有可辨、可减、可祛除的特点,科研大数据工作者可根据多年工作经验及积累的技术辨别SRBDF,并采用相应措施祛除迷雾,减少其危害,例如《数据管理能力成熟度评估模型》定义的8个能力域中就包含了“数据质量”,并明确指出通过数据质量检查来促进数据质量提升[38]。
2)激增型(Surge Type)是指在SRBDF初生期并未得到有效的控制,以致后续仍有大量相关的科研活动直接引用此部分数据,或是对此类数据次级引用,造成大范围高强度的影响,此时其有范围广、强度高、难控制的特点,相关科研工作者除了需要投入大量的時间与精力来辨别迷雾,还需要掌握专业的技术,例如《土壤水分自动站逐小时资料质量控制方案》为甄别疑误数据增加内部一致性检验。
3)衰退型(Recession Type)是指SRBDF在数据质量控制下其影响范围与影响力度逐渐减小,呈现衰败的特点,但仍具有死灰复燃的可能性,此类数据流转至科研大数据流中易成为新一轮迷雾的催生动力。从SRBDF的“初生”到“激增”再至“衰退”体现了其周期性与波动性特征。
3.1.2空间维
结合SRBDF的派系性与全链性特征,在空间维上,可分为焦聚型迷雾和弥散型迷雾,如图3所示:
1)焦聚型( Focus Type)是指SRBDF往往聚集于某一的领域,科研人员在自己所属学科领域进行数据引用,生成迷雾的现象,本属学科间的数据引用情况远高于跨学科引用,如图3(a)所示。焦聚型迷雾具有集中性(数据集中、领域集中、人员集中)的特征。例如,随生物学领域的“丁香实验”、医学领域的“梅斯医学”、经济管理领域的“经管之家”等交流平台的兴起,产生的迷雾更为聚集,这是其派系性的典型体现。随时间演化焦聚型迷雾在科研大数据生态系统中扩散开来,逐渐转变为另一种类型。
2)弥散型(Diffuse Type)是指SRBDF逐渐扩散影响相邻学科,造成跨学科影响的现象。如图3(b)所示,弥散性迷雾以现代信息技术与相关政策漏洞为滋生土壤,在多机构、多平台、多学科内传播,具有范围广、速度快、灾害性强的特点。在当今《科协系统深化改革实施方案》等鼓励跨学科合作相关文件颁布的背景下,跨学科合作迸发出前所未有的新活力,但与此同时,弥散型迷雾也广泛分散在了科研大数据生态链。其缥缈难以捕获,体现了SRBDF的全链性特性。
3.1.3强度维
结合SRBDF波动性特征,在强度维度其可分为强迷雾与弱迷雾,如图4所示:
1)弱迷雾(Infirm Fog)指“迷雾”影响范围相对较小,迷雾浓度较低,对数据接收者的危害程度较浅的一种数据形态。对于释放者来说,尽管其浓度及影响范围较小,但对于错误数据接收者而言,弱迷雾型数据與可用科研数据更相近,因此在面对弱迷雾时更容易受其迷惑。但是因其影响范围有限、危害程度较小,相对而言也较容易处理。
2)强迷雾(Strong Fog)指在科研大数据生态系统中影响范围大、作用时间持久、危害程度较深的一种数据形态,此形态多出于浓雾期。对于释放者来说,强“迷雾”的释放能够更加有效地干扰竞争对手,削减其实力。对于接收者来说,强迷雾难以防控,迷雾中处处存在风险,接收者长时间面对大量鱼龙混杂的科研数据,易造成学科发展停滞。
3.1.4利益维
结合SRBDF灾难性特征,在利益维度可分为趋利型和趋害型,如图5所示:
1)趋利型(Profit Type)是指在科研个体(微观)、科研机构或企业(中观)、国家或地区(宏观)等竞争的驱动下,以迷惑竞争对手提高自身竞争力为目的,以故意加大实验误差生产错误数据为手段,对于释放者来说,造成的最终结果是有利的一种数据形态。如图5(a)所示,迷雾释放者通过释放科研大数据迷雾干扰竞争对手,提高自身竞争力。趋利型迷雾对于释放者来说具有可见、可防、可控的特点。
2)趋害型(Hasten to Harm Type)是指同是在竞争驱动下产生的,与趋利型相对的,对数据接受者来说可造成伤害的一种数据形态。如图5(b)所示,趋害型相对于趋利型来说,只是接受主体不同,对于自身来说是趋害型的对于竞争对手来说有可能是趋利型的,但将会影响接收方自身决策分析,造成决策失误。趋害型迷雾对数据接收者来说具有难捕捉、难评估、难控制的特点,继而可造成灾难性后果。
3.1.5繁育维
结合SRBDF派系性特征,在繁育维度科研大数据“迷雾”现象可分为杂育型和寡育型,如图6所示:
1)寡育型( Oligonucleotides Type)是指只在特定的领域内出现的,易切断阻隔的SRBDF类型。如图6(a)所示,此类型具有学科单一(往往出现在高精尖领域亦或是冷门学科)、主体单一(在特定的科研人员范围间传播)、类型单一(数据类型单一,很少存在结构化、半结构化、非结构化数据混杂的情况)、数据一脉相承(科研大数据迷雾易溯源)、易控制的特点。
2)杂育型(Mixed Type)是指多学科、多领域、多人员、多地域的各类科研数据相互引用而出现的SRBDF。如图6(b)所示,跨学科、跨地域、跨时空的科研人员在方法论、知识论、价值判断等方面存在一定的差异,导致学科交流不通畅,从而产生SRBDF,此类迷雾更具有缥缈、悬浮的雾化性特征,且涵盖知识范围较广,因此往往较难控制,易引发数据灾难。
综合以上分析知SRBDF组成类型多样,在时间维可划分为初生型、激增型、衰退型,在空间维可划分为焦聚型、弥散型,在强度维可划分为强迷雾、弱迷雾,在利益维可划分为趋利型、趋害型,在繁育维可划分为杂育型、寡育型。
3.2科研大数据迷雾的演化路径分析
SRBDF在科研大数据生态系统中逐渐演化生成,如图7所示,基于数据生命周期理论,以A机构医疗科研数据造假事件为例,以时间维度为主路径综合考虑利益维度、空间维度、强度维度、繁育维度对SRBDF的演化路径进行分析。
3.2.1路径节点一
1)从空间维看初生期SRBDF,其多以焦聚型呈现。例如在A机构注册初期,科研数据样本较少,“迷雾”还没有大范围传播,此时的SRBDF焦聚现象较为明显,即在初生期SRBDF往往是集中在医疗健康学科领域。尽管弥散现象在这一时期也会出现,但仅限于大规模的急性突发事件,但是这类情况爆发速度较快,初生期转瞬即逝,将会很快步入下一时期——激增期。
2)从强度维看初生期SRBDF,因为其大部分处于萌芽时期,所以此时的迷雾较弱,如果短期内爆发高强度的迷雾,此时的迷雾数量定会发生激增,因此将此类型划分至激增期,即研究认为科研大数据迷雾初生期强度较弱。
3)从利益维看初生期SRBDF,此阶段是迷雾的计划阶段,A机构注册便以盈利为主要目的,利益维充满了人的主观能动色彩,在迷雾诞生初期早已被人为笼罩上了利益的面纱,即便是A机构最终受到了自己释放的迷雾的影响,但在迷雾释放初期对释放者来说是趋于有利的,并且在整个过程都是趋利向演化的。同理对科研人员及政府来说,在迷雾初生期便伴随着扰乱其决策的目的,在整个演化过程都是趋害的。
4)从繁育维看初生期SRBDF,A机构的虚假科研数据还并未进行大量的传播繁育,故很难直接判断出此时的迷雾究竟是杂育型还是寡育型,对于前期多类型、多机构、多学科交叉产生的SRBDF可以将其直接划分为杂育型,但现实情况中不乏在中期乃至后期才出现跨学科的科研数据,此时便需要将其重新分类。
3.2.2路径节点二
1)从空间维看激增期SRBDF,在激增期极易出现迷雾大规模扩散的情况,此时A机构已与“北京焕一医学检验实验室”“北京普通医学检验实验室”成为房山区三大机构,科研数据量急剧增加,影响范围逐渐增大,此时期的科研大数据迷雾多呈弥散型状态,已扩散至医疗健康相关领域,即在短期迷雾数据会有突然爆发式增长的可能。
2)从强度维看激增期SRBDF,随着该机构核酸检测数量增加,与之产生的科研大数据数量势必进一步增加,因此在激增期迷雾强度将会达到第一个峰值,此时的科研大数据迷雾最难控制,对科研人员与政府决策的危害性也最大。
3)从利益维看激增期SRBDF,此阶段是干扰对手的主要时期,在激增期SRBDF的意图已经基本暴露,对何种机构有利或是有害极易判断,此时的A机构获益颇丰,对于政府与科研机构而言,其决策判断已受影响。
4)从繁育维看激增期SRBDF,随A机构规模扩大,实验员等岗位大规模招聘,此时的科研大数据已影响至监管部门、药物生产商等,随之产生的迷雾以杂育型为主。迷雾的爆发式增长,大部分迷雾形态逐渐明确,此阶段的中后期迷雾是杂育型还是寡欲型已经基本确定。
3.2.3路径节点三
1)从空间维看衰退期SRBDF,随北京市公安局通报,卫健部门已吊销A机构《医疗机构执业许可证》,弥散在整个科研大数据生态系统的迷雾逐渐回笼,弥散在边缘学科或是弱相关学科的迷雾逐渐淡化直至消失,再次呈现焦聚的状态(可聚集特定的学科、机构、地区),因此从空间维度看衰退期的迷雾,此时期的迷雾以焦聚型为主。
2)从强度维看衰退期SRBDF,因市场监管部门已立案查处,在此时期非核心迷雾逐渐消散,此时的迷雾空间覆盖范围逐渐缩小,在数据治理的作用下迷雾的灾害性逐渐减弱,因此迷雾在衰退期强度逐渐降低。
3)从利益维看衰退期SRBDF,衰退期属最终时期,是否提高了自身的核心竞争力、干扰了对手的决策,或者是否受迷雾影响造成决策失误,从而影响了自己的竞争地位,其利益目的早已明确。科研大数据人员可准确判断此时的“迷雾”是趋利型的还是趋害型,但在竞争双方的僵持作用效果下,衰退期的迷雾尽管在逐渐变弱,但还未完全消失,因此在科研大数据迷雾衰退期仍是趋利型与趋害型两种“迷雾”混杂。
4)从繁育维看衰退期SRBDF,此时期迷雾繁育能力降低,很少出现大范围繁殖的情况,但前期因跨学科、跨机构、跨地域引用而产生了多种杂育型迷雾,并伴随多代寡育型迷雾,科研大数据生态系统中杂育型与寡育型迷雾并存,在短期内难以完全消除。
3.3科研大数据迷雾机理分析
3.3.1生成机理
由SRBDF-M知,“迷雾”的生成需经历初生期、激增期、衰退期3个阶段,迷雾的生成机理是一个整体化的机体,其过程是一个动态复杂的过程,在迷雾生命周期内,生产者、传播者、消费者、监管者等主体均有参与。对迷雾的生成机理进行阐述,有助于科研人员掌握其演化规律,走出“迷雾丛林”。因此,本文主要从利益机理(催生)、扩散机理(传播)、管控机理(阻隔)3个维度结合迷雾生命周期,对其内在逻辑进行剖析,如图8所示。
1)利益机理:科研大数据生态系统内部存在优质与劣质两种类型数据,优质科研大数据可信度高、生产成本高、可利用价值高;劣质科研大数据(迷雾数据)可信度低、生产成本低、可利用价值低。初生期迷雾生产者(以营利性企业或数据生产商为代表)受利益驱使计劃制造大量的迷雾数据,此时数据类型单一,呈现为焦聚型的弱迷雾,在迷雾型数据流出且获益后会进一步刺激迷雾的生产。监管者为保护消费者利益在迷雾出现后会介入进行监管。
2)扩散机理:激增期迷雾传播者(数据共享平台、数据中介组织、数据产商等)对迷雾进行扩散,消费者(高校、企业、科研机构等)对迷雾数据进行引用,此时的传播者一部分来自于先前趋利的生产者,另一部分则是受扩散机理影响自发地扩散迷雾的消费者,迷雾扩散机理指的是受大量的迷雾数据的反复刺激,消费者对迷雾数据的鉴别产生自我怀疑,开始引用高迷惑性迷雾数据,使得迷雾数据量激增,此阶段的科研大数据迷雾为数据类型复杂的弥散型强迷雾,随数据量的激增,生产者收益增加,进一步刺激劣质数据产出。
3)管控机理:大量的迷雾数据流入科研大数据生态系统中引起监管者(政府监管部门等)注意,开始干预生产者行为,对迷雾数据进行管控,随科研经历的增加,科研工作者数据鉴别能力逐步提升,开始对迷雾数据进行剔除与举报,生产者利益受阻,迷雾数据量逐渐减少,此时的迷雾呈现数据类型趋于单一的焦聚型弱迷雾特点。
3.3.2机理间的内在联系
科研大数据迷雾催生因素多样、生成过程复杂,但利益机理、扩散机理、管控机理并不是孤立存在的,内部具有一定的逻辑联系,如图9所示。
扩散机理与利益机理的关联关系。消费者的策略选择通常有消费与不消费两种。生产者对高品质科研大数据通常有保留和流出两种策略,对科研大数据迷雾通常有保留和流出两种策略。因此在科研大数据生态系统中存在的4种数据流转策略:第一种是高价优质科研大数据;第二种是低价优质科研大数据;第三种是高价迷雾数据;第四种是低价迷雾数据。在利益机理下,科研大数据生产者会向消费者索要高回报。当消费者选择消费时,可能高价买到优质数据或迷雾数据,也可能低价买到优质数据或迷雾数据,此时存在迷雾扩散的可能;消费者的收益为数据价值与获取数据成本的差值;当选择不消费时,消费者的得益为0,此时不存在迷雾扩散的可能。
管控机理与利益机理的关联关系。监管者对于生产者的各种行为存在监管与不监管两种策略。当监管者在利益机理作用下,为降低监管成本,即松懈检测时,存在优劣科研大数据混合。消费者在明确要付出较大成本获取数据时的得益应该不小于不获取数据的得益。由管控机理知,当监管者选择监管松懈时,生产者流出迷雾数据,但当流出迷雾数据加大时,监管者会再次选择监管严厉。当生产者提供优质数据时,监管者又会选择监管松懈以减低监管的成本支出。
扩散机理与管控机理的关联关系。监管者对数据质量严格监管时,生产者减少迷雾型数据的生产,消费者获取迷雾数据的可能性降低,迷雾扩散的概率随之降低。监管者对数据质量监管松懈时,生产者加大迷雾型数据的生产,更多的迷雾数据流转到消费者的手中,加大了迷雾的扩散。
利益机理、扩散机理与管控机理的关联关系。如果监管者严格监管科研大数据生态系统中数据流通行为,生产者会向消费者索要较低的报酬,消费者得益大于0时会选择接受科研大数据迷雾;否则生产者索要高报酬,生产者高低报酬比例使消费者接受的得益大于不接受得益。在管控机理作用下,生产者若仍选择流出迷雾数据,此时监管者将会实施系统内部混合策略。当监管者对于生产者所产数据检测不到位时,消费者无法根据生产者对所放出的报酬要求来判断科研大数据的优劣,此时迷雾扩散的概率加大。利益机理、扩散机理与管控机理分别发挥着催生、传播、阻隔的作用,维持着科研大数据生态系统内部的动态平衡。
3.4科研大数据迷雾模型的应用分析
1)应用过程。第一步,确定对象。确定科研大数据所属的领域及模型的运用者。不同领域甚至同一领域的科研决策者、一线人员以及科技政策制定者的关注侧重点各有不同。第二步,从科研大数据库中获取相关数据。此步骤应注意科研大数据迷雾发现机制的实现问题(是对已知数据的判断还是对未知数据的挖掘)。第三步,开展综合分析。对科研大数据迷雾的类型、路径、机理进行分析。从不同维度对科研大数据迷雾进行类型划分,并探索其作用路径及所处阶段,为后续数据治理提供启示。同时还应注意数据的格式问题以及人员间、人员与模型间的协同性问题。第四步,形成结论,即对科研大数据的评价结果。第五步,将结论反馈决策者,提交数据质量报告,为科研大数据治理提供合理化建议。
2)应用场景。SRBDF-M具有较强的实用性,在科研大数据库建设、科研决策、科研大数据政策制定等场景中均可使用,具体分析如下:①应用场景一:科研大数据库建设。随着科技发展,科研人员对科研大数据的需求日益增加,科研大数据库逐渐兴起。将SRBDF-M引入到科研大数据库建设,可起到优化数据存储(通过SRBDF-M进行数据筛选分类,剔除劣质数据、无效数据、冗余数据)、加强数据保护(通过SRBDF-M进行迷雾型数据生产者溯源,减少劣质数据的产出,如已有的科技资源标识符与数字对象唯一标识符)、促进数据共享(数据共享成为科研大数据治理的重要任务之一,SRBDF-M可控制劣质数据的流入,提高科研效率,加快科研大数据流转,同时保障数据权益使更多的科研成果参与共享)的作用;②应用场景二:科研決策。SRBDF-M有助于实时、全面、准确、专一的科研大数据清洗平台的建设,科研人员通过SRBDF-M获取高精度数据使科研决策更加科学。大数据时代背景下大量冗余数据使得科研决策环境发生变化,SRBDF-M可有效评价数据优劣、剔除冗余数据,更好满足管理者决策需求,为领导层的决策制定提供高价值、高精度的支撑数据;③应用场景三:科研大数据政策制定。从2008年的《中华人民共和国科技进步法》到2015年的《促进大数据发展的行动纲要》,再至2018年的《科学数据管理办法》,科研大数据的共享与利用不断推进,然而由前文机理分析知科研大数据政策的制定过程是一个博弈行为,SRBDF-M可帮助政府分析系统内部其他主体的选择行为,了解科研大数据发展态势,提高科研大数据政策科学性。
4结语
1)科研大数据迷雾模型较好地描述了科研域迷雾数据出现、聚集、消散的演化过程。本研究提出了“科研大数据迷雾”的概念,并在科研大数据迷雾模型的建构与解构的过程中,从时间、空间、强度、利益、繁育等维度对科研大数据迷雾的类型、路径与生成机理进行了详尽剖析。研究得出科研大数据迷雾是指衍生于数据迷雾、贯穿于科研大数据生命周期,以科研域虚假、有毒、垃圾数据为重要组成部分,以全链性、不严格波动性、派系性、雾化性、灾难性为基本特征,以初生型、激增型、衰退型、焦聚型、弥散型、强迷雾、弱迷雾、趋利型、趋害型、杂育型、寡育型为基本类型,降低科研大数据质量、干扰科研人员决策、引发数据灾难进而扰乱科研大数据生态稳定的一类数据的总称。
2)科研大数据迷雾模型的建构与解构对于科研大数据治理具有重要的理论价值与实践价值,主要体现在以下几个方面:
①对科研大数据治理目标的新安排。科研大数据迷雾概念的提出要求构建科研大数据治理优势互补新布局,发现新优势、发掘新动能、制定新规制、应对“迷雾”新问题,稳科技研究预期、利创新发展长远,坚持科研大数据良性转化,健全科研大数据治理体制,优化科研大数据资源配置,提升科研大数据创新效能,扩大国际科研大数据共享,以完成开放、共享、创新、多样、稳定、持续的科研大数据生态系统建设新目标。
②对科研大数据内涵的新丰富。科研大数据迷雾生成模型是对科研域虚假、有毒、垃圾数据运行机理的深度阐释。研究提出的“科研大数据迷雾”的概念具有整体性、原创性、前瞻性、引导性,以全局性的眼光看待整个科学研究过程中出现的迷雾数据,并第一次系统地对科研域虚假的、有毒的垃圾数据进行归纳与总结,丰富了科研大数据理论,可为后续相关研究提供理论依据。
③对科研大数据治理价值旨归的新构造。宏观层面:在科研大数据蓬勃发展的时代背景下,厘清“迷雾”生成机理,是大数据发展中至关重要的一环,有利于打破数据壁垒、加强科研数据共享、巩固科研大数据生态系统的和谐稳定,是对国家大数据战略的积极响应。中观层面:在科学发展过程中,“迷雾”的存在将会成为科研进步的绊脚石,揭露其存在是科学发展的“清朗”行动。微观层面:有助于帮助科研机构、科研人员、企业更好地了解科研大数据迷雾,有效规避风险,提高决策效率,从而增强自身核心竞争力。
④对科研大数据治理风险的新研判。以生态系统的眼光探究“迷雾”,具有系统性、整体性、协同性、时效性的特点。在当今安全赤字与治理赤字的大背景下,科研合作筑墙设垒、数据共享脱钩断链,是对治理体系、治理能力、治理水平的新挑战。科研大数据共享过程中应兼顾外部风险与内部风险、传统风险与非传统风险、自身风险与共同风险。多阶段、多主体、多维度分析迷雾类型及演化,为整体有序地开展科研大数据治理提供了新思路。
⑤对科研大数据治理举措的新阐述。科研大数据迷雾概念的提出不仅要求健全科研大数据治理体系、增强科研大数据治理能力、提高科研大数据治理水平,还要求革新科研大数据治理举措,夯实科研大数据生态稳定基础。主要包括治理框架的革新:构建科研大数据安全应急框架,实现全科研域数据、人才、环境联动,立体高效地应对科研大数据迷雾。治理体系的革新:对科研大数据生态进行一体化保护、系统化治理,构建面向“迷雾”特性的全局化、整体化的应对性的科研大数据治理体系。治理过程的革新:以科研大数据生态系统内外双循环为辅助,遵循“迷雾”生命周期规律,多阶段、多主体协同治理,注重迷雾治理过程的规范化、程序化,增强科研大数据生态链韧性。
3)尽管本文构建了科研大数据迷雾模型,提出了科研大数据迷雾的概念,并对其特性、类型、路径、机理进行了详尽的剖析,但如何应对科研大数据迷雾问题、维持科研大数据生态的和谐稳定,后续仍需深入讨论。
