基于Python的电子元件信息爬取与数据可视化系统设计
2023-07-20余丽红杨董涛李弋峰柳贵东
余丽红 杨董涛 李弋峰 柳贵东

摘要:电子元器件公司在日常的工作中,需要对市场上的电子物料信息做信息爬取,了解这些物料的基本信息,方便采购部门有关人员去选择采购。文章设计了一个能够自动在网上爬取电子元件信息并且进行数据可视化的爬虫系统。该设计是基于Python语言开发的爬虫系统,能够节约更多的人力物力,对于从事电子元器件行业的工作人员高效获取电子元件信息有很大的帮助。
关键词:网络爬虫;Python;数据可视化;反爬
中图分类号:F426.63
文献标志码:A
0 引言
网络爬虫又被称为网络机器人。它的工作就是在网页上搜索所需要的信息,是搜索引擎的重要组成部分[1]。它的工作原理是先确定所需要爬取的主页面的URL,然后通过此URL对目标服务器发出请求,在发出请求的同时还需要携带一些参数,避免反爬。服务器收到请求后给出响应,爬虫程序就获得了此URL的页面源代码。通过解析源代码获得所需要的数据。
本文设计的爬虫系统,能够爬取互联网指定网站上的电子元件信息,实现从购买电子物料的网页上将所需要的电子物料信息具体详细获取下来,进行存储,清洗再可视化,便于用户对这些信息的观察与选择。该系统做出可视化图形便于用户根据需求选择所需的电子物料,能够节省大量的人力物力,节省产品元器件采购设计的时长,降低生产成本。
1 系统设计方案
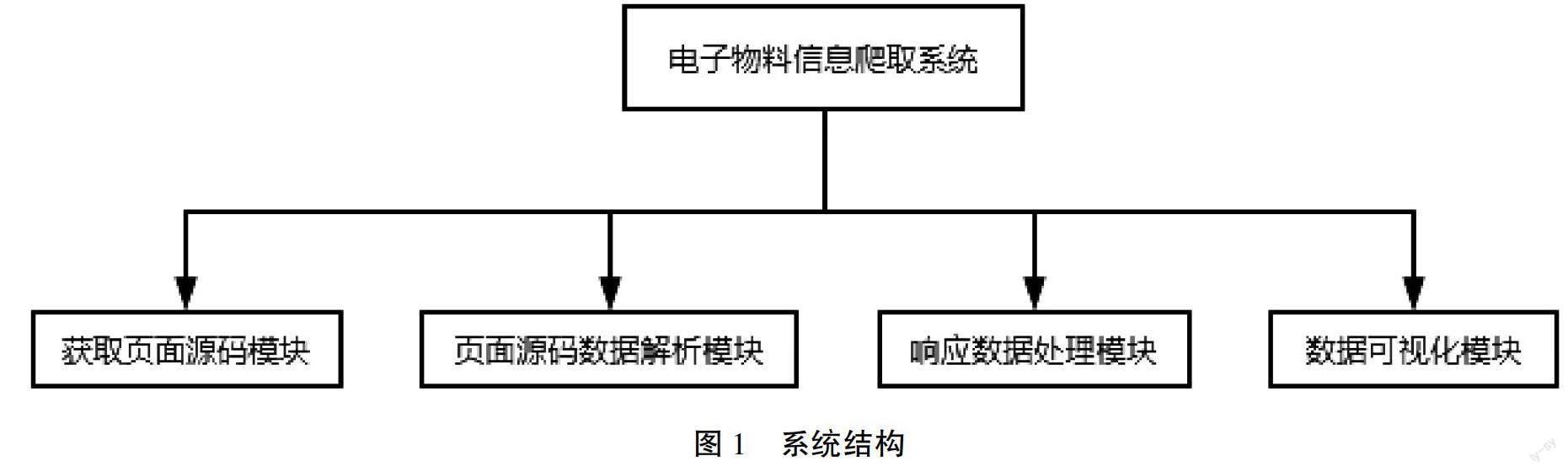
根据要完成的功能(数据爬取、数据清洗和数据可视化),系统主要包括四大模块,分别是:获取页面源码模块、页面源码数据解析模块、响应数据处理模块和数据可视化模块。系统的结构如图1所示。
图1中获取页面源码模块主要是通过requests库对目标URL发起请求获得目标URL的页面源码[2]。页面源码数据解析模块主要负责对获取到的页面源码进行分析从而获取所需要的数据;响应数据处理模块主要负责对最终所得到的响应数据进行处理,得到最终想要获取的详细数据后再对其进行本地存储;数据可视化模块就是负责对本地所存储的数据进行可视化处理,便于用户更加直观地了解产品信息。
2 系统的实现方法
2.1 利用反爬机制获取页面源码方法
获取页面源码最大的阻碍就是在访问目标URL时,会遇见一些常见和特殊的反爬措施。最常见的反爬机制有UA反爬、基于Cookie的反爬和Ajax动态加载。针对UA反爬,通过在浏览器中打开目标网页,启动开发者工具,在数据包中找到请求头。在请求头中将“User-Agent”的参数复制到脚本中,放入header里面,在发起请求的时候携带此header,就可以成功获取数据。对于Cookie反爬,只需要在发起请求时使用session方法,就能够保存在发起请求的時候产生的Cookie值,下次再次发出请求时就会携带此Cookie。对于Ajax动态加载的数据,先在网页中找到动态加载出来的数据包,然后在此数据包中找到关于页面数的参数,并将表单数据中的参数都复制下来,在系统源代码中做一个字典来存储此数据。之后再发出申请时会携带此字典,就能够成功获取到动态加载的数据。
2.2 页面源码数据解析方法
页面源码数据解析模块是对获取到的页面源码进行处理,找出需要的数据,并根据数据所在的位置使用xpath或正则表达式来获取相关的数据[3]。在此模块中,对于一般返回的页面源码数据解析会比较简单。但是对于动态加载的数据解析,就需要先到动态加载的数据所在的位置,并且将此数据格式化,格式化后的数据有利于观察。之后根据观察到的数据所在位置,编写代码获取数据,并按需要输出特定格式的数据。
2.3 响应数据处理方法
响应数据处理模块主要的工作内容就是对获取得到的数据进行处理,处理的内容包括对数据的清洗、存储。数据的清洗是将不符合要求的数据进行过滤,过滤后的数据才是有价值的数据。而数据存储就是将清洗后的数据进行本地保存或者保存在数据库中。
2.4 数据可视化方法
数据可视化模块主要就是对保存的数据进行绘制可视化图形处理,方便更加直观地观察数据的信息,而在此模块中负责绘制图形的库为Matpoltlib库。Matplotlib是Python中最受欢迎的数据可视化软件包之一,支持跨平台运行。
本模块主要绘制柱状图和饼状图,在Matpoltlib中就需要是用bar()函数来绘制柱状图,还需要使用pie()函数来绘制饼状图。而在这些函数中还需要定义一些参数来定义绘制的图形的大小、位置和样式。
3 系统的函数实现
3.1 系统的流程设计
系统主要处理流程如图2所示。开始对目标URL发起请求,获得目标URL的页面源码,再对其分析,列出所有初级的电子元件类型选择,用户选择自己所需求的类型。对用户所选择的类型所对应的URL发起请求,通过其页面源码解析获得初级电子元件类型并列出来。用户选择具体类型,对最终的URL发起请求获得最终响应。获取到元件的所有页面数,再利用循环对所有页面进行爬取,得到所有的数据,在爬取数据的过程中若没有对应的参数则用“-”表示。之后对所获取到的所有数据进行本地存储,最后对存储的数据进行可视化处理生成柱形图、词云或饼状图,列出最优选择。
3.2 获取页面源码的实现
获取页面源码模块程序主要使用session来实现。主要实现方法是先定义一个session对象:
session = requests.session(),
再根据提供的url进行页面爬取:
page_text = session.get(url = url,headers = headers).content.decode(‘utf-6)。
其中headers在文件開头已经定义,后面携带的content.decode(‘utf-8)是解决爬取到的中文数据乱码的问题。将爬取到的数据字符类型都定义为utf-8。最后返回page_text。对于电子元件信息的多页爬取,可以通过一个循环来实现。当要爬取所有页面的数据时,首先要知道总页数(pageCount),还要得到需要爬取的电子料的代号(NodeID),最后将表单数据构建为data参数。
3.3 数据清洗与本地存储的实现
当数据的爬取完成后,接下来还要对爬取下来的数据进行清洗,将没有意义的干扰数据信息去除掉[4]。本文使用text = text(~((text.电子元器件 == 0) )代码,将无意义元器件的信息值设为0来实现清洗。当数据清洗完毕后,接下来需要做的操作就是对数据进行本地存储,本文使用csv表格来存储爬取到的电子元件信息数据。首先需要为存储的表格构造一个列名,就是每一列存放数据的名称,将这些列名放入一个列表中lable = [列名1,列名2,…列名n],之后将爬取到的数据和列名构造成pandas中的DataFrame对象,对象名为text。实现语句为text = pandas.DataFrame(爬取到的数据列表名,columns = lable)。之后再通过爬取的电子物料名称作为存储的csv文件的文件名。创建csv文件并将DataFrame对象text写入该文件,完成数据的本地存储。
3.4 数据可视化的实现
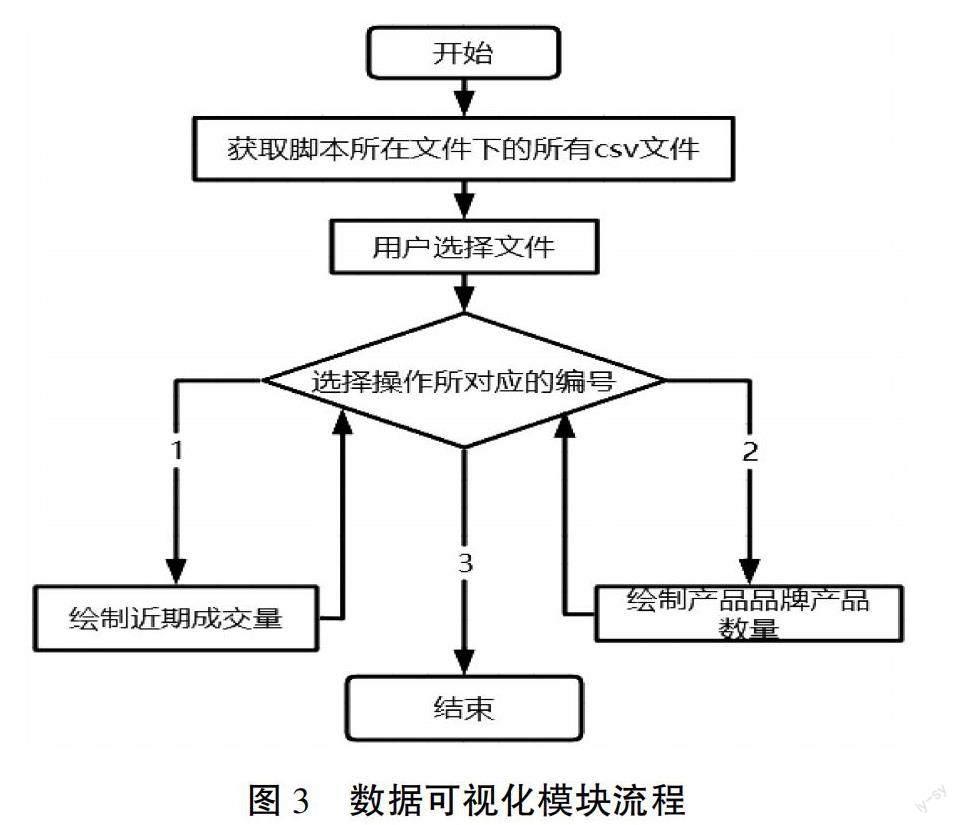
数据可视化用到的库有pandas、matplotlib和os。首先,需要用os库将脚本所在的文件下所有csv文件列出来供用户选择。当用户选择了一个csv文件后,程序会提示用户选择所需要的操作。数据可视化模块流程如图3所示。
4 系统测试
系统测试主要包括页面爬取测试和次级分类爬取测试。首页爬取测试是对初始URL发出请求,获取初始URL的首页页面源码,再通过数据解析,将首页的页面源码当中所有电子物料的大分类名称全部获取到,并且显示在终端。次级分类爬取测试是在获取到首页电子物料大分类的情况下,对单个大分类的电子物料下的具体分类信息进行获取并显示在终端窗口。测试表明,该系统实现了相应的功能。
5 结语
本文以电子产品贸易公司的电子元器件信息搜集工作为出发点,为提升电子元器件信息搜集的效率,设计基于Python语言的爬虫系统。该系统主要分为四大模块,分别是数据获取模块、数据清洗模块、数据存储模块和数据可视化模块。数据爬取模块将用户所需要的数据从互联网上获取下来,并且在此过程中应对一些反爬技术。数据清洗模块将获取到的数据进行清洗,将不符合要求的数据去掉,保留有价值的数据。数据存储模块将清洗过后的数据存储到本地或数据库中。数据可视化模块将存储的数据做成可以更直观地查看数据信息的可视化图形。该系统实现了电子元器件信息的批量下载及可视化操作,方便工作人员根据需求选择所需的电子物料。
参考文献
[1]卢花,冯新.网络爬虫在批量获取教学资源中的应用[J].福建电脑,2022(7):103-105.
[2]孟宪颖,毛应爽.基于Python爬虫技术的商品信息采集与分析[J].软件,2021(11):128-130.
[3]于淑云.基于校园BBS的舆情系统爬虫应用研究[J].长春工程学院学报,2016(2):95-98.
[4]杨丕仁.基于Python语言的网络日志处理系统设计[J].电脑知识与技术,2016(15):117-119.
(编辑 李春燕)
Design of electronic component information crawling and data visualization system based on Python
Yu Lihong, Yang Dongtao, Li Yifeng, Liu Guidong*
(School of Electronic and Information Engineering,Guangdong Baiyun University, Guangzhou 510450, China)
Abstract: In daily work, electronic component companies need to crawl the information of electronic materials in the market to understand the basic information of these materials, so that relevant personnel of the purchasing department can choose to purchase. This paper designs a crawler system that can automatically crawl the information of electronic components on the Internet and visualize the data. This design is a crawler system developed based on Python language. This system can save more manpower and material resources, and it is very helpful for the staff engaged in electronic component industry to obtain electronic component information efficiently.
Key words: web crawler; Python; data visualization; reverse crawl
