基于注意力机制的多模态图像语义分割
2023-07-17张吉友张荣芬刘宇红袁文昊
张吉友,张荣芬,刘宇红,袁文昊
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
1 引 言
夜间场景语义分割作为计算机视觉的一项基本任务,在自动驾驶方面有着广泛的应用[1]。由于天气、光照等原因,自动驾驶面临的比较严峻的问题是环境的多样性。现有的大多数基于深度学习的语义分割网络处理的都是RGB 图像。在光照正常的情况下,RGB 图像分辨率高,其颜色、纹理和细节信息丰富[2],图像成像清晰且图像内的各个物体边缘分明,这有利于语义分割网络学习图像的颜色、纹理和细节等特征[3]。但是RGB 图像容易受光照影响,在夜间场景下由于可见度和强曝光等问题,导致RGB 图像提供的信息不能很好地被计算机利用[4]。因此,利用RGB 图像训练的语义分割网络在夜间场景的极端环境下会产生分割不准确的问题[5]。
为了解决只利用RGB 图像对某些极端环境下进行语义分割效果不好的问题,需要采用多模态图像来进行图像信息的融合从而利于网络获得更多的特征信息[6]。热(Thermal)红外图像存在边缘模糊、无颜色纹理信息等缺点,但是其成像原理是基于热辐射,几乎不受光照影响,即使在烟雾、强光等能见度较低等极端环境下也能获得热红外图像。这对于极端环境下的语义分割网络显得尤为重要。研究表明,RGB-Thermal(RGB-T)多模态图像将RGB 图像和热红外图像组合,无论光照条件如何,其含有两种模态图像的特征信息,有利于语义分割模型从两种模态中提取特征信息并进行特征级信息融合从而提升极端环境下的语义分割性能[7]。此外,随着热成像技术的发展和成熟,热红外图像采集越来越容易。将热成像相机生成的热红外图像作为RGB图像的信息补充,即使在极端天气下,热成像相机也能获得热红外图像作为RGB 图像的补充信息源[7]。因此,结合热红外图像特征训练更加稳定的RGB-T 多模态语义分割网络成为应对夜间场景下精准语义分割问题的主流方法。
近年来,语义分割算法备受研究者青睐。在单模态图像分割领域,杨云等人将循环分割对抗网络算法运用到医疗图像分割领域对视网膜血管进行分割,获得了很好的分割效果[8]。赵战民等人在模糊C 均值框架基础上设计新算法,即使图像呈现出灰度分布不均衡的状况,该算法模型也能快速有效地分割无损检测图像[9]。赵为平等人通过在DeepLabv3+编码器中加入深度可分离卷积后融入改进的池化模块同时改进其解码器,有效降低了模型复杂度并提升了分割精度[10]。任莎莎等人在DeepLabv3+的编码器和解码器中增加了多级像素空间注意模块、边缘提取模块和小目标提取模块对热红外图像进行语义分割,提高了边缘相交区域像素和小目标物体的预测精度[11]。熊海涛等人[7]设计了一种包含多级上下文特征修正模块和多级边缘特征增强模块的算法对热红外图像进行分割,使得分割边缘更清晰。在RGB-T 多模态语义分割领域,受到FuseNet[12]的两个对称编码器和语义分割解码器[13]的启发,MFNet[14]运 用 两 个 对 称 编 码 器 同 时 对RGB 和 热红外图像做特征提取,再进行上采样后进行语义分 割。RTFNet[15]运 用ResNet[16]提 取RGB 和 热红外图像两种模态的特征并进行融合,最后通过不同的两种上采样模块不断恢复分辨率和重构其特征。FuseSeg[17]利用DenseNet[18]作为编码器的特征提取网络,分别对RGB 图像和热红外图像两种模态图像进行特征提取后通过相加进行融合,而且在解码器阶段通过上采样后将其与编码器下采样得到的相同大小的特征图进行拼接。FEANet[19]在RTFNet[15]的 基 础 上 加 入了FEAM注意力模块,以互补的方式融合RGB 和热红外图像信息。
虽然各种RGB-T 语义分割网络在不同程度上都对夜间语义分割场景做出了一定贡献,但也存在以下问题:(1)由于多层次特征提取和合并策略不考虑层次之间的差异,导致模态特征进行融合时会产生模态冲突;(2)如何同时利用好高级的语义信息和低级的细节信息是语义分割的一大难题。为了更好地提取两种模态图像的特征和充分利用好高级的语义信息和低级的细节信息,本文主要贡献如下:
(1) 利用RGB 图像和热红外图像搭建了一种稳定的多模态双编码器-解码器语义分割网络,将RESNet-152 作为特征提取网络,经过5 层提取后得到的特征图包含高级的语义信息,分阶段上采样并拼接不同阶段的语义特征图可以兼顾细节信息和语义信息。
(2) 提出了一种轻量化的注意力模块并将该注意力模块添加到编码器的各层中,将热红外编码器提取到的特征图和RGB 编码器提取到的特征图通过相加进行融合从而实现多模态信息的特征融合和互补特征提取。
(3) 在解码器阶段,在相应的每层解码器中,通过上采样从上一层解码器中对特征图进行上采样,将得到的特征图和编码器提取到的相同大小的特征图进行拼接融合,再通过两层卷积对融合的特征图进行特征提取,然后继续进行上采样,通过5 次上采样后还原成为原图像大小相同的特征图。通过融合编码器阶段的特征图和上采样的特征图,解码层能利用多尺度信息更好地进行语义分割。
2 网络架构
本文的总体架构包含两个编码器流和一个输出解码器流。编码器流和解码器流都包含5 个层(Layer 0-Layer 4)和(Upsampling1-Upsampling5)。为了从RGB 图像和热红外图像中充分挖掘信息线索,本文提出了一种轻量化注意力模块,并将其有效添加至编码器中,从而增强多层次特征以获得更好的分割性能。
2.1 总体架构
如图1 所示,本文所提出的架构主要包括两个结构一致的编码器流和一个解码器流,编码器流用于从RGB 图像和热红外图像中进行特征提取和融合,解码器流用于进行特征提取和逐渐恢复分辨率。
编码器流的特征提取框架是ResNet-152,其结构可以大致分为5 个提取层(Layer 0-Layer 4),在每一层之后都加入了轻量化注意力模块。在特征提取阶段,热红外图像编码器流从单通道热红外图像中提取相关特征,RGB 图像编码器流从三通道的RGB 图像中进行特征提取。两个编码器流的各特征提取层将提取到的特征图通过轻量化注意力模块细化细节特征。在特征融合阶段,各特征提取层中对应的RGB 特征图和热红外特征图通过元素求和聚合到RGB 编码器流中。
解码器流中主要包括3 个模块:一个上采样模块,主要用于逐步还原图像的分辨率;一个特征图拼接模块,主要用于拼接上采样过后的特征图和相应的编码器层产生的特征图;一个特征提取模块,主要用于提取拼接后的特征图的特征信息,将得到的特征图用于上采样。
随着编码器流的深度不断加深,所提取到的特征为高级的语义特征,高级语义特征对于捕获全局上下文起着重要作用,但也会丢失图像细节特征。解码器的上采样运算是对高级语义特征图进行上采样,而其缺乏细节信息,输出的预测边界将会变得很模糊。所以为了提高输出预测边界图的清晰度,引入轻量化的注意力模块,使编码器在下采样时注重两种模态的细节信息,在最终的输出层输出相对密集的输出预测。此外,为了能同时兼顾高级的语义信息和低级的细节信息,通过拼接模块将上采样的特征图和相应大小的编码器阶段的特征图进行拼接后通过两个卷积层进行特征提取,通过拼接的方式使得解码器在不断恢复分辨率时能兼顾语义信息和细节信息[2],有利于最后预测边界图的输出,从而优化语义分割的分割结果。
2.2 编码器
在编码器中,热红外图像编码器和RGB 编码器结构几乎相同,然而ResNet-152 是为了三通道的图像而设计的,不适用于单通道的热红外图像,于是将Layer 0 中的第一个卷积层中的通道数改为单通道以便适用于热红外图像,该编码器的其余结构与三通道的RGB 编码器具有相同的结构。
在编码器中热红外图像编码器只从热红外图像中提取特征信息,而RGB 编码器还需要提取将RGB 特征图和热红外特征图通过元素求和聚合到RGB 编码器的相关特征。为了更有效地提取两种不同模态的特征信息和减少参数,源于文献[19]和文献[20]的启发,引入了轻量化注意力模块并将其添加到两个模态编码器的Layer 0-Layer 4 的每个卷积层之后。
轻量化注意力模块包括通道注意力和空间注意力运算,其运算过程如图2 所示。通道注意力实现了一种不降维的局部跨通道交互策略,避免因通道维度减少而影响特征提取,而其中的局部跨通道交互的覆盖范围k由通道数C决定,两者之间的关系可表达为[20]:
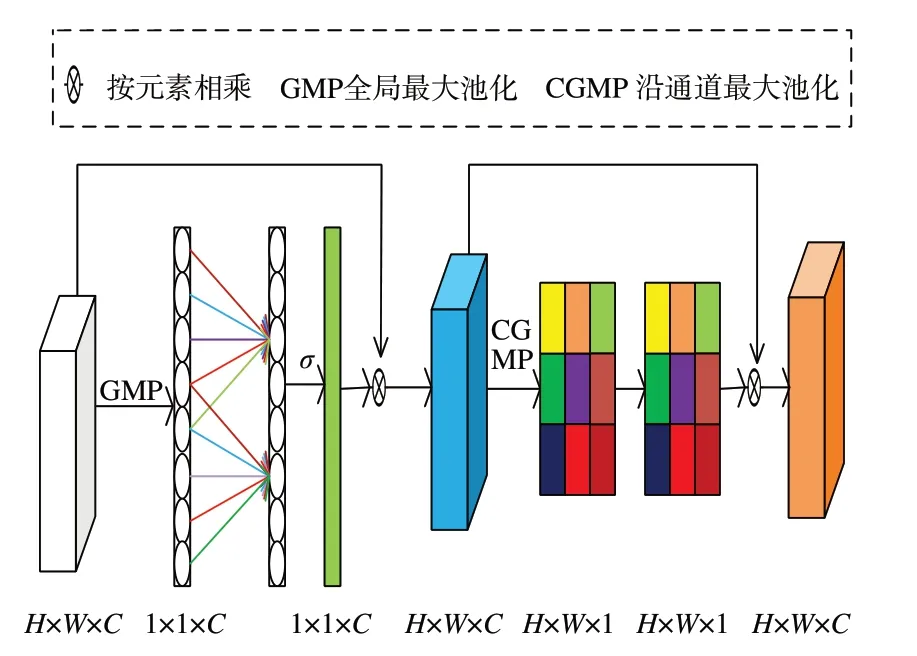
图2 注意力模块运算示意图Fig.2 Schematic diagram of attention module operation
其中:|t|odd表示离t最近的偶数;γ和b为超参数,分别设为2 和1[20]。通道注意力通过局部跨通道关注卷积层提取到的特征,更加注重全局特征,而空间注意力则关注全局区域,注重细小的物体。两种注意力结合在一起既能够把握全局特征又能够注意细节信息。
2.3 解码器
解码器流中主要包括3个模块:一个上采样模块、一个特征图拼接模块和一个特征提取模块。上采样模块有两个卷积块,其运算示意图如图3所示,特征图通过第一个卷积块后,其分辨率和通道均无变化。在第二个卷积块中,CONV1 将保持特征图的分辨率不变但是通道数变为原来的1/2,TRANSCONV1 将特征图的分辨率变为原来的2 倍但是保持通道数不变,TRANSCONV2将特征图通道数减半且分辨率变为原来的2 倍。拼接模块通过编程实现按通道进行拼接。特征提取模块依次包含两个卷积层、正则化层、激活层。解码器中各模块的详细配置如表1 所示。

表1 解码器中各模块配置Tab.1 Each module configuration in the decoder
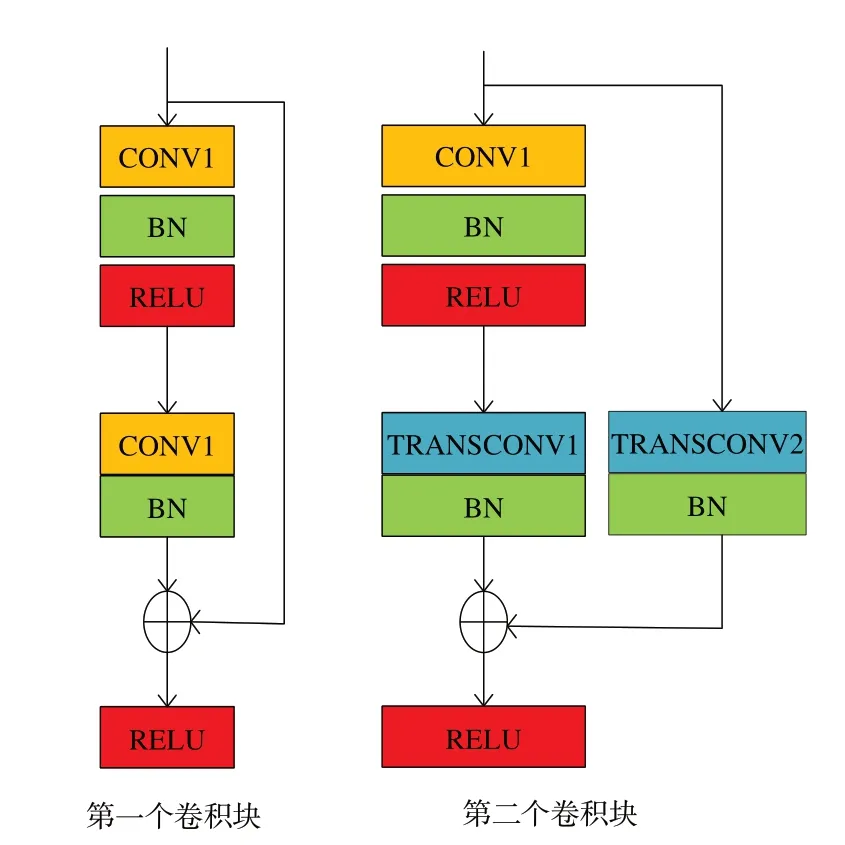
图3 上采样模块中的两个卷积块运算示意图Fig.3 Schematic diagram of two convolution block operations in the upsampling module
通过两个编码器的5 层提取后得到了RGB和热红外图像进行相加融合后的最终特征图S0,此时特征图的大小为2 048×15×20。在解码器中,Upsampling1 部分首先对S0通过上采样模块进行2 倍上采样得到上采样的特征图S1,其通道数和分辨率与Layer 3 输出的特征图S2相同,大小为1 024×30×40。然后通过特征图拼接模块将S1和S2进行拼接融合。融合后的特征图S3相比于S1和S2分辨率不变,但是通道数变为2 倍。随后通过特征提取模块对S3进行特征提取得到相应特征图S4,其大小和通道数与S1和S2相同。通过Upsampling1 部分后,特征图的大小为1 024×30×40,Upsampling 2~Upsampling 4 也 是 同 样的运算方式。经过3 次相同的运算后,得到的特征图的大小变为64×240×320,最后输出层进行2 倍上采样,同时将输出通道变为9,随后添加了一个softmax 层,得到分割结果的概率图。通过不断地拼接具有高级语义信息和低级细节信息的特征图进行特征提取后,利用多尺度特征进行上采样可以使最终的语义分割边界图更清晰,分割效果更好。
3 实验环境和实验设置
3.1 数据集
本文中所运用的数据集是MFNet[14]所发布的数据集,其使用INFEREC R500 摄像机拍摄城市街道场景,该数据集不仅包括RGB 图像,还包括热红外图像,比较适用于夜间场景下的语义分割,主要包含了8 个手动标记类别(汽车、行人、自行车、车道线、停车位、护栏、色锥、地面凸起物)和一个背景类共计9 类,其中820 幅拍摄于白天,749 幅拍摄于夜间,其RGB 图像和热红外图像的分辨率都是480×640。为了更好地训练语义分割模型,训练集由50%的白天图像和夜间图像组成,验证集由25%的白天和夜间图像组成,剩余的所有图像用作测试集。
3.2 实验环境和训练参数
本文基于pytorch1.10.2 架构开展了所有的实验,利用Python3.8 进行编程,所有程序在Ubuntu16.04 LTS 64-bit 系 统 上 运 行,CPU 为Intel(R) Core(TM) i7-7800X CPU@ 3.50 GHz,GPU 为单卡NVIDIA GeForce 3090Ti。Cuda版本为11.4,cuDNN 版本为8.2,显卡内存为24 GB。
为了加快训练速度,在实验时使用了pytorch提供的ResNet-152 的预训练权重来训练本文所提出的模型。由于ResNet-152 的预训练权重适用于三通道图像,而热红外图像是单通道数据,所以热红外编码器的第一个卷积层没有使用预训练权重。编码器的第一卷积层以及解码器中的卷积层和转置卷积层使用Xavier 方案初始化。在训练中,选择随机梯度相加优化器(SGD)进行优化,动量和权重衰减分别设置为0.9 和0.005,初始学习率设为0.05,且采用指数衰减的方案来逐渐降低学习率,训练epoch 设置为100。为了更好地训练模型,利用翻转操作进行了数据增强,同时在每一个epoch 开始之前将所有数据集随机打乱。
3.3 损失函数
训练模型时,损失函数选用Diceloss[21]和Soft-CrossEntropyloss[22]进行加权作为损失函数[19],其损失函数可表示为:
Diceloss 损失函数可表示为:
其中:N表示图片总像素点个数,pi表示像素点的预测值,gi表示像素点的真实标签值。
SoftCrossEntropyloss 损失函数可表示为:
其中:n表示batchsize 的大小,在实验中该数值为5;c表示分类的类别数;若像素点i被正确分类,则表示为1,否则其为0;表示像素点i的归一化概率。
3.4 评价指标
为了评价本文模型的好坏,引入了准确率(Accuracy,Acc)和交并比(Intersection over Union,IoU)两个评价指标,其中Acc表示预测正确的像素点占总像素点的比例,IoU 表示每个类别的真实标签与预测结果的交集。为了更直观地反映模型的效果,通常会计算平均准确率(mean Accuracy,mAcc)和平均交并比(mean Intersection over Union,mIoU),其计算公式如式(5)、式(6)所示:
其中:nii表示预测正确的像素点个数,nij表示真实类别为i但是预测为j类的像素点,nji表示真实类别为j但是预测为i类的像素点,N表示类别数。
4 实验结果分析
4.1 实验结果对比
为了更直观地反映出该模型的实验结果,将本 文 提 出 的 网 络 和FuseSeg[17]复现的MFNet[14]、FuseNet[12]、DepthAwareCNN[23]、RTFNet[15]进行了 对 比,同 时 对 比 了FuseSeg[17]和FEANet[19]等相对前沿模型的实验结果,表2 是系列网络在MFNet 测试集上的mAcc 和mIoU 的结果对比。由表2 可知,本文所提出的分割网络在mAcc 和mIoU 两个指标都取得了最好值,该网络模型在停车位和地面凸起物检测上的效果有一定的提升。对于色锥类别,其分割结果虽然略逊色于FEANet[19]网络,但是效果也很好,其主要得益于注意力机制比较关注图像中远景的细小物体,证明了在特征提取网络融入注意力机制的有效性。对于近景中汽车、行人两类大尺度目标,得益于RGB 图像和热红外图像的融合,实验中所有模型均取得了较好的分割效果。虽然注意力机制对于远景的小物体效果比较好,但其也有局限性,对于近景的自行车类别,其外观类似于聚簇结合体,分割效果相对于其他两类大尺度物体略差。而FuseSeg[17]使 用 稠 密 连 接 的DenseNet161[18]作为特征提取网络,对于自行车的分割效果相对于其他网络模型比较好。对于车道线类别,由于其通常呈现白色,而热红外相机在夜晚对于白色物体成像略差,所以其总体分割结果相比其他类别物体相对较差。而对于护栏类别,各个网络模型的分割效果都不是很好,其原因应该是测试集中缺少样本所导致,因为在测试集的393 对图像中,只有4 对图片图像出现了护栏这个类别。而且训练集中该类物体在总的像素点中占比也很小,在特征提取过程中,经过多次卷积层提取导致了特征丢失从而影响分割结果。
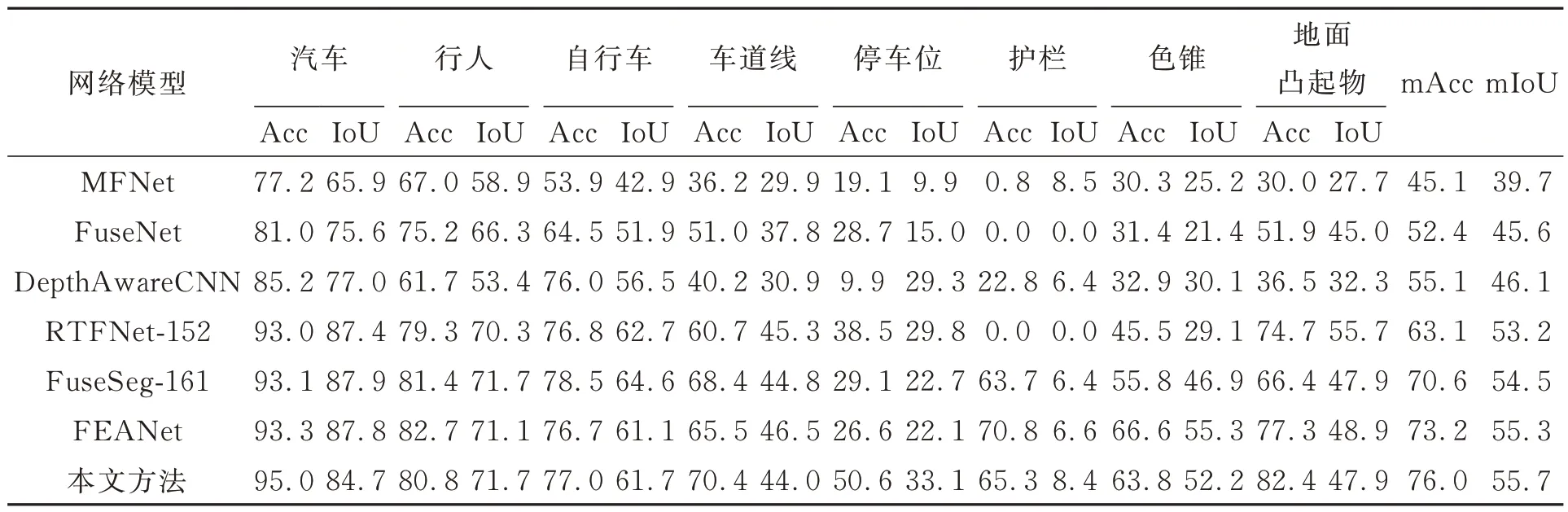
表2 系列网络模型在MFNet 测试集上的结果对比Tab.2 Comparison of results of serial network models on MFNet test set
为了进一步研究网络模型对于不同场景下的分割效果,将MFNet 测试集的图像拆分为白天图像测试集和夜间图像测试集,对比了几种网络模型分别在白天和夜间测试集上的实验结果。由表3 可知,所有的网络模型在夜间取得了相对好的分割结果,其原因是RGB 和热红外图像之间存在模态冲突,白天场景的RGB 编码器和热红外图像编码器都能从相应模态的图像中提取到很好的特征,将其融合时,两种模态数据之间会产生时间或空间的信息偏差。但是在夜间场景下,由于没有丰富的RGB 信息,所提取到的特征图没有太多的颜色、纹理和细节信息,引入热红外图像在很大程度上补充了RGB 图像信息,进行信息融合时模态之间的偏差大幅减小,所以在夜间场景的语义分割效果更好[17,19]。
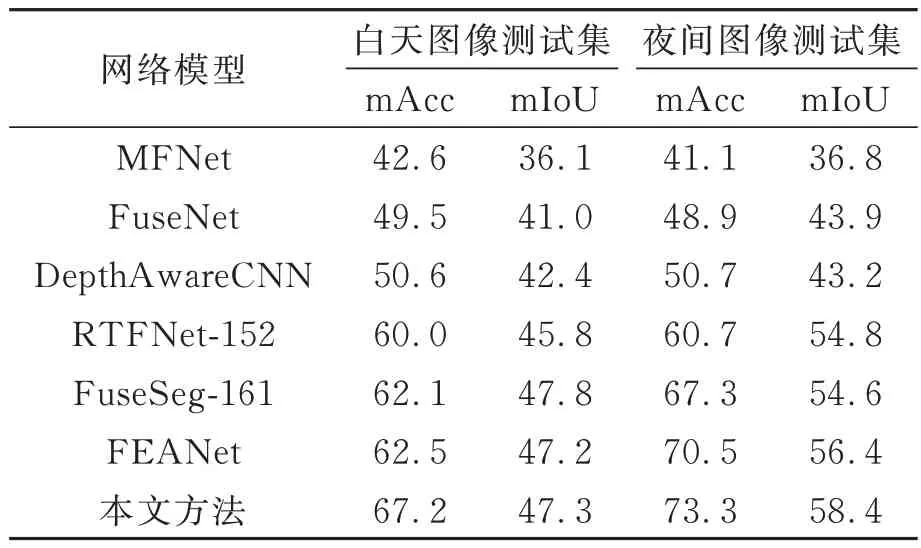
表3 系列模型昼夜测试集上的性能对比Tab.3 Performance comparison of a series of models on a day-night test set
分析图4 可知,对于白天的图像(前三列),无论任何一个网络模型其分割效果都比较好。后四列的夜间图像的分割效果得益于热红外图像对于RGB 图像的信息补充[24]。本文所提出的网络对于近景的行人和远景的行人,其分割结果和真实的标签都非常接近,分割边界比较清晰。并且,在第六列中只有本文提出的网络对于行人背后的护栏进行了精准的分割,其余网络都未对护栏进行分割。这主要是因为在语义分割特征提取网络中引入注意力机制,使得网络注重远景细小物体。其次,拼接高维语义特征图和低维细节特征图利用多尺度特征信息进行特征提取,利于分割网络输出分割边界图。

图4 部分网络模型的分割结果可视化对比Fig.4 Visual comparison of segmentation results of some network models
4.2 消融实验
为了验证所提出的注意力模块在编码器中的作用,将注意力模块从RGB 编码器流和热红外编码器中都移除,称其为对照组A;将注意力模块从热红外编码器中移除,称其为对照组B;将将注意力模块从RGB 编码器中移除,称其为对照组C;同时设置了将解码器中的拼接融合变为相加融合,称其为对照组D;将编码器中的相加融合用拼接融合取代,并通过一个1×1 卷积来改变通道数,称其为对照组E。各个对照组的模块设置以及实验结果如表4 所示。
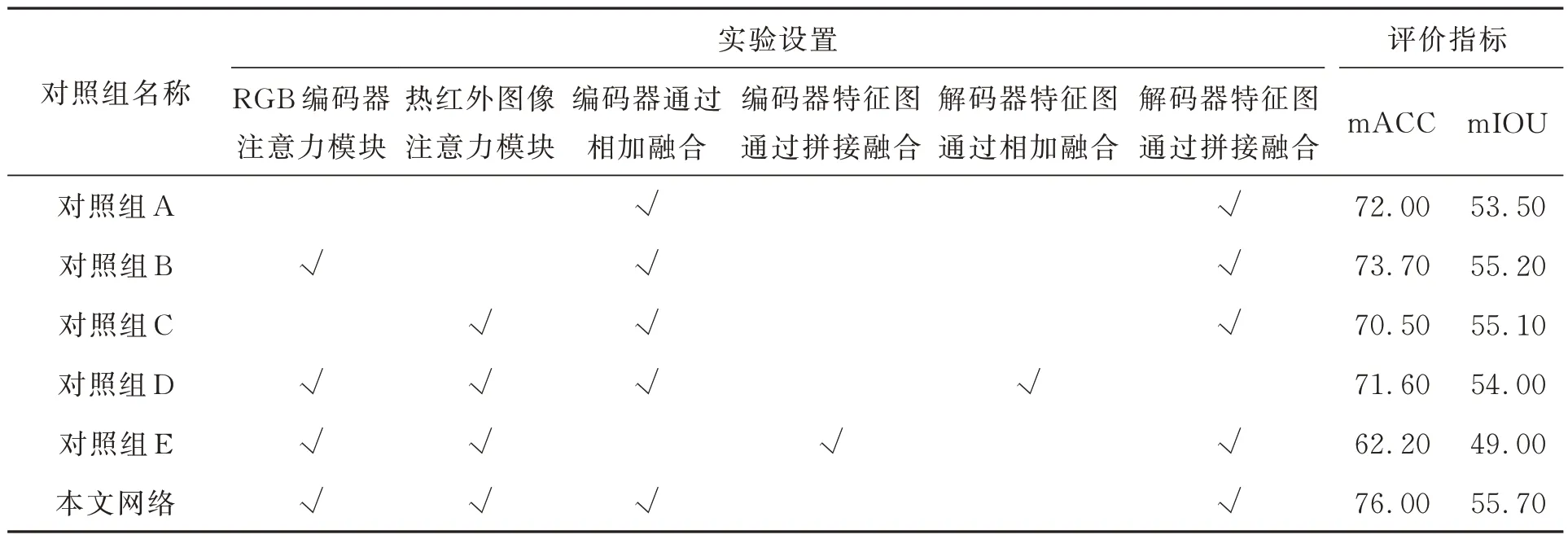
表4 对照组实验配置详情及结果Tab.4 Control group experimental configuration details and results
分析消融实验结果可知,如果从编码器中移除注意力机制,其mACC 和mIOU 都呈现了下降趋势。对比对照组B 和对照组C 发现,在RGB 编码器和热红外编码器中分别移除注意力模块,其mACC 和mIoU 都会呈现一定程度的下降,说明在该语义分割架构中,热红外图像的特征和RGB图像的特征确实对语义分割结果起到了至关重要的作用。而相比于对照组A,只要编码器中任何一个模态有注意力机制存在,相对于编码器中两种模态都没有注意力机制的对照组,其mIoU 都会有很大提升,说明注意力机制对语义分割的某些物体定位有着重要的作用。对比对照组D 和本文提出的网络,说明将各层编码器提取出具有细节信息的特征图和具有高级语义信息的特征图进行拼接后再进行多尺度特征提取能有效兼顾图像的细节信息和语义信息。对比对照组E 和本文提出的网络可知,通过相加融合更能够整合两种模态图片的特征信息,所以其分割效果也会更好,选择相加融合来整合两种模态的特征信息相比于使用拼接融合更有效。
5 结 论
本文利用ResNet-152 作为编码器的特征提取网络分别对RGB 和热红外两种模态的数据进行特征提取,旨在实现白天和夜间场景下的语义分割,以应对极端环境下语义分割的基本要求。通过在两种模态中的各个特征提取层中添加本文提出的注意力机制后,通过相加将两种模态数据的特征进行融合能有效融合多模态特征信息。在解码器部分,一般的语义分割网络通过不断采用上采样来恢复分辨率,而本文提出的模型试图兼顾高维的语义特征和低维的细节特征,将两种特征图先进行拼接后进行特征提取再进行上采样来还原分辨率。实验结果表明,本文提出的网络在相应的测试集上获得了平均准确率为76.0%,平均交并比为55.7%,获得了较好的语义分割性能。
本文提出的网络针对语义分割的编码器加入了注意力机制并对解码器结构进行了优化。虽然取得了不错的效果,但是如何进一步提升多模态RBG-T 图像语义分割的效果还需要更深入的研究,如在语义分割网络中融入边缘检测算法提取两种模态的边缘细节特征从而进一步优化分割边界,以及结合多标签监督对损失函数进行优化加速网络训练收敛等。
