一种改进的轻量级人体姿态估计算法
2023-07-17王名赫徐望明蒋昊坤
王名赫,徐望明,2*,蒋昊坤
(1. 武汉科技大学 信息科学与工程学院,湖北 武汉 430081;2. 武汉科技大学 教育部冶金自动化与检测技术工程研究中心,湖北 武汉 430081)
1 引 言
人体姿态估计(Human Pose Estimation)是计算机视觉中的重要任务之一,是计算机理解人类动作、行为必不可少的一步。人体姿态所包含的信息具有非常广泛的应用价值,如在医疗救助领域可通过人体姿态估计获得病人骨骼状态[1],在日常健身和体育训练中可通过人体姿态估计帮助运动员更科学地训练,在人机交互和自动驾驶领域[2]可通过获取人体姿态信息实现对人体行为的理解并完成正确的决策判断,在虚拟现实、电影和动漫等领域也多见其用武之地。相比于其他穿戴式传感器[3],人体姿态估计算法从采集到的图像中获得人体姿态信息,是一种高效、经济且灵活的人体姿态获取方式。
学术界通常将人体姿态估计问题的求解方法转化为预测人体关键点位置并确定其空间关系从而得到人体骨架。近年来,使用深度学习估计人体姿态的方法被陆续提出且性能远超传统方法。人体姿态估计方法可分为自顶向下和自底向上两种[4]。自顶向下的方法分为两阶段,第一阶段使用人体目标检测器获得人体目标框,第二阶段利用单人体姿态估计方法在每个人体框中定位人体关键点。该方法在人体背景复杂时需要更复杂的模型实现单人关键点的定位,受人体目标检测器精度影响且计算复杂度随检测人数线性增加,难以满足实时需求。自底向上的方法先检测所有人体关键点,再通过不同的聚类和分组策略确定关键点与人体的所属关系。OpenPose[5]算法利用预测的部位亲和力场连接躯干上的关键点,从而实现人体关键点的分组。Associative embedding[6]和HigherHRNet[7]算 法通过为每个人体关键点分配不同的标签值,使同一人体关键点的所有标签值相互聚拢而不同人体关键点的标签值相互远离,从而实现同一人体关键点的组合。DEKR[8]算法对每类人体关键点采用独立的分支回归热力图(heatmap)并回归每个关键点相对人体中心的二维偏移图,利用关键点热力图和偏移图对关键点进行分组。自底向上的方法检测速度较为恒定,不受人体数量变化影响,但其检测到的人体关键点需分组处理,未实现端到端的人体姿态检测,而且大多采用低分辨率概率热力图回归人体关键点坐标,存在量化误差。
针对以上不足,YOLO-Pose[9]算法放弃热力图回归方式,采用和目标检测类似的方式回归人体关键点坐标,并采取分而治之的策略,将不同大小的人体姿态分配到不同尺度特征图上进行回归,实现了端到端的人体姿态估计,但人体姿态的非刚性特点和人体关键点分布的多样性特点导致该方法仍然存在错误估计的问题,其所用深度网络的特征提取能力还有待提升。计算机视觉中提升模型特征提取能力的方法有多种[10-11],其中注意力机制是一种简单且有效的方法,已广泛应用于图像分类、目标检测、语义分割、行为识别和姿态估计[12]等任务中。具有代表性的注意力机制包括RNNs[13]实现前景目标选择、SENet[14]动态调整特征通道注意力权重、CBAM[15]方法实现通道注意力权重和空间注意力权重的动态分配等。
针对人体姿态的非刚性特点及人体关键点特征在空间分布上的多样性,本文对YOLOS-Pose算法进一步改进,提出一种轻量级通道和空间注意力网络(LCSA-Net,Light-weight Channel and Spatial Attention),使网络学习到更丰富的空间信息,提升网络对高自由度人体姿态的估计能力。同时,提出一种基于距离自适应的加权(Distancebased Adaptive Weighting,DAW)策略在模型训练阶段计算人体关键点的回归损失,增强网络对不同位置人体关键点的回归能力。
2 YOLO-Pose 算法原理
YOLO-Pose 是以YOLO[16]目标检测网络模型为基础实现的端到端人体姿态估计算法。YOLO 是一类端到端目标检测模型,基本原理是通过回归待检测目标的位置和分类概率实现对图像目标的定位与识别。YOLO-Pose 在YOLO目标检测模型的基础上添加了新的人体关键点检测头用于回归。
YOLO-Pose 的输出层存在两类独立的检测头:一类是人体目标检测头,输出Box-Out 特征图,实现人体目标检测与定位;另一类是人体关键点检测头,输出Kpt-Out 特征图,实现人体关键点坐标回归。输出特征图Kpt-Out 与Box-Out 在每个特征点处回归的人体姿态和人体目标框是一一对应的,因此,损失函数包括人体目标检测损失和人体关键点回归损失。其中,采用CIoULoss (Complete IoU Loss)计算人体目标框回归损失Lbox,采用关键点相似度损失(OKS-Loss,Object Keypoint Similarity Loss)函数计算人体关键点坐标回归的损失Lkpts,其定义如式(1)所示:
其中:dn表示第n个关键点预测位置与标签坐标位置之间的欧式距离,s2表示人体框的面积,kn表示数据集中该类关键点的权重,vn>0 表示该人体关键点存在于图像中。
人体目标检测的分类损失Lcls和人体关键点置信度损失Lkpts_conf则采用BCE-Loss(Binary Cross Entropy Loss)作为损失函数。
模型的总损失函数如式(2)所示:
其中,参数λbox、λcls、λkpts、λkpts_conf是平衡每类损失的权重。
YOLO-Pose 算法相比于基于热力图回归的模型具有精度和速度上的双重优势,但通过对该算法原理分析可知,算法优先对人体目标检测结果进行处理,只有检测到人体目标,才会在对应位置回归与之匹配的人体关键点。人体目标检测精度直接影响人体姿态估计精度。误检的人体目标框必然会产生错误的人体姿态,漏检的人体目标框也同样造成人体姿态的漏检。如图1 所示,在日常生活中,人体目标出现时极可能呈现出不同的姿态,人体目标的这种非刚性特点加大了视觉算法检测的难度,同时这些人体姿态下的人体关键点在空间上也具有变化多样的分布,对关键点的预测定位也带来了挑战。因此,针对人体的非刚性及其关键点在空间分布上的多样性等特点,进一步提升模型对特征的空间分布的敏感性是非常必要的。

图1 变化多样的人体姿态Fig.1 Various human postures
本文从轻量级通道和空间注意力网络设计和模型训练时人体关键点回归损失自适应加权策略两个方面对YOLO-Pose 算法进行改进,提升模型的人体目标检测和人体关键点回归精度。
3 本文方法
3.1 轻量通道及空间注意力网络LCSA-Net
相对于刚体目标,人体目标的外观具有更高的变化自由度。为了提升模型对变化多样的人体目标及其关键点的检测及回归精度,受经典的CBAM 注意力网络的启发,本文提出一种轻量级通道和空间注意力网络(LCSA-Net)。与CBAM 相比,LCSA-Net 减小了参数量和计算复杂度,同时分别提取每个通道的注意力分布,获取更丰富的空间分布特征,其整体结构如图2所示。
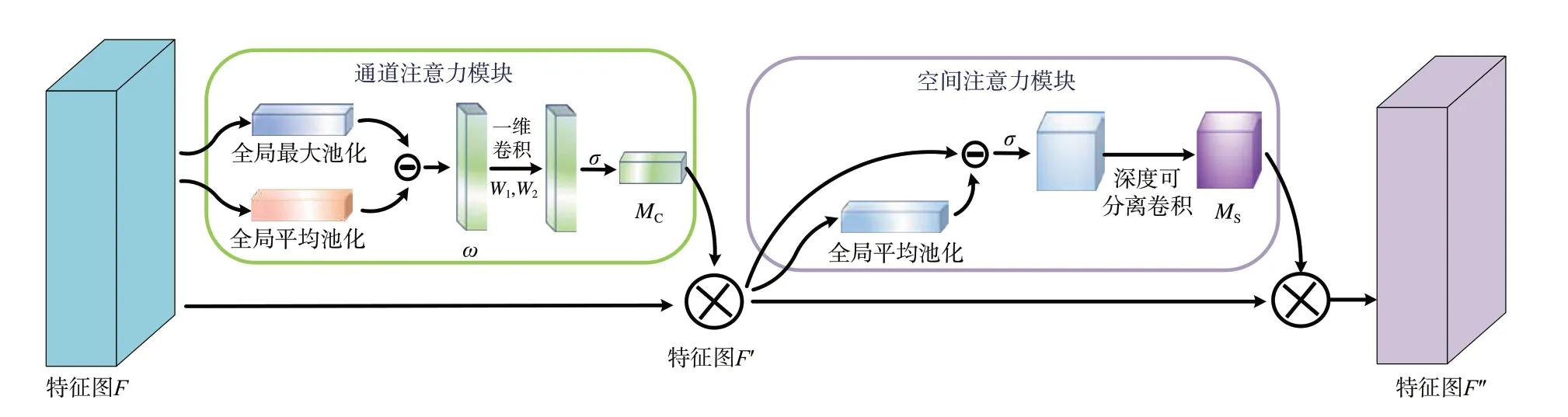
图2 LCSA-Net 网络结构Fig.2 Network structure of LCSA-Net
LCSA-Net 由通道注意力模块和空间注意力模块组成,输入特征图F∈RC×H×W通过通道注意力模块得到权重MC∈RC×1×1,通过空间注意力模块得到权重MS∈RC×H×W。其处理过程可表示为:
其中,⊗是基于元素的乘法,通过乘法操作使一维通道注意权重MC在空间维度上实现广播,加权计算后的特征图F'通过空间注意力权重对特征图F'的每个元素加权得到最终的特征图F″。
通道注意力模块通过全局最大池化(Max-Pool)和全局平均池化(AvgPool)获得每个通道上特征的最大值与平均值,并将两者的差异作为该通道的整体响应程度且不使用CBAM 中的1×1 二维卷积操作,而是采用计算量和参数量更小的一维卷积操作,使用两个核大小为3 的一维卷积来捕获局部跨通道交互信息,最后使用Sigmoid 函数得到归一化的通道注意力权重。这一过程可用公式表示为:
其 中:σ代 表Sigmoid 函 数,ReLU 表示修正线性单元,W1和W2表示k=3 的 一维卷积 核。
空间注意力模块将其输入特征图F'上的每个特征值与其所在通道的特征均值之间的差值作为各个通道中各自的特征强度分布,通过sigmoid 函数后,对每个通道进行深度可分离卷积[17]进一步提取空间特征,从而得到各个通道上不同的空间注意力权重。这一过程可用公式表示为:
3.2 基于距离自适应的加权策略
Luo[18]等人的研究发现,输出特征图上的每个位置在输入图像上存在有效感受野,有效感受野内不同位置的像素对输出特征图上的响应强度呈高斯分布,距离中心位置更近的像素对输出特征有更强的影响。
基于以上研究,考虑到人体关键点具有空间分布多样性的特点,其与特征图上对应像素点之间距离的不同,关键点坐标的回归难度也不同。因此,为了提升特征图上的像素对远离它的人体关键点的回归质量,在计算人体关键点回归损失时,本文提出一种基于距离自适应的加权策略,可表示为:
其中:distsoft(n)代表第n个人体关键点与特征图上对应的a点间的欧式距离,distsoft(n)代表归一化后的欧氏距离。
在计算人体关键点的回归损失和概率损失时,对远离当前像素点的人体关键点分配更高权重,提高其对输出特征的响应程度。模型训练过程中的关键点回归损失函数和概率损失函数计算公式如式(11)和式(12)所示:
其中,每个待回归人体关键点都对应一个权重,其他参数含义与公式(1)相同,并且总损失的类别与公式(2)相同,分为人体目标检测损失和人体关键点回归损失。
3.3 人体姿态估计算法LCSA-YOLO-Pose
本文基于上述两种策略改进YOLO-Pose 算法,将LCSA-Net 插入到YOLO-Pose 主干网络的浅层特征提取层以及特征金字塔之间,提升主干网络对人体目标的特征提取能力,使特征提取网络更加专注于人体姿态的变化,可称之为LCSAYOLO-Pose 人体姿态估计算法,其网络结构如图3 所示。
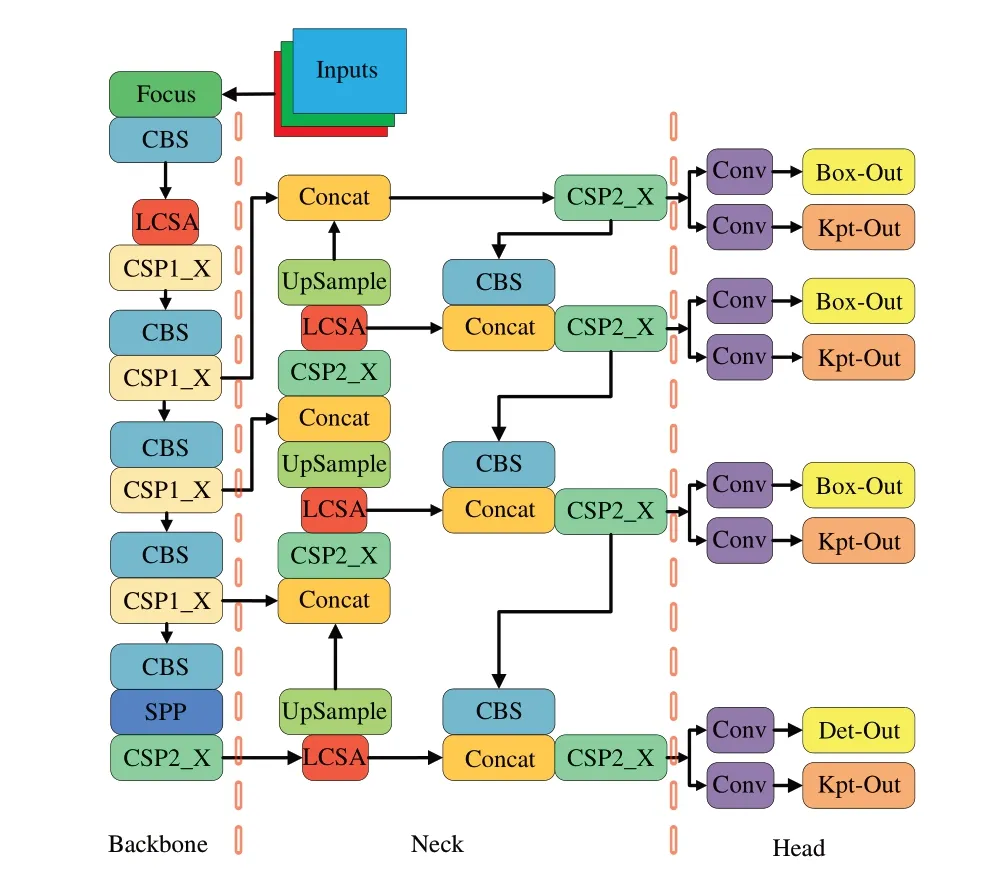
图3 LCSA-YOLO-Pose 网络结构Fig. 3 Network structure of LCSA-YOLO-Pose
LCSA-YOLO-Pose 分 为Backbone、Neck 和Head 3 个部分。Backbone 即主干网络部分,使用Focus、LCSA-Net、SPP 等模块提升主干网络的特征提取性能;Neck 即特征增强部分,采用PAN 结构实现自顶向下和自底向上双向多尺度特征融合,通过融合较低层特征信息和较高层特征信息,获得更丰富的语义信息;Head 即预测部分,由目标检测头和人体关键点检测头组成,两检测头具有相同的分辨率。在目标检测头输出的特征图上,每个位置预测的人体目标与人体关键点检测头每个位置预测的人体姿态一一对应。在算法的后处理部分,先对目标检测头输出的特征图进行处理,采用非极大值抑制(NMS)的方式得到最终检测到的人体目标。获取人体目标在特征图上的位置后,在人体关键点特征图中的相同位置获取对应人体目标的人体关键点。
在训练LCSA-YOLO-Pose 模型的过程中,采用DAW 策略对关键点回归损失和概率损失函数进行加权。
4 实验结果及分析
本文实验平台处理器为Intel(R) Xeon(R)Gold 5218 CPU @ 2.30 GHz,RAM 容量为64 GB;GPU 使用GeForce RTX 3090,显存容量为24 GB;操作系统为Ubuntu20.4,Python 版本为3.8.12并使用Pytorch 1.10.0 机器学习架构。
实验训练集和验证集都使用MS COCO2017人体姿态数据集,其中训练集图像数目为56 599张,验证集图像数目为2 346 张。
4.1 LCSA-Net 对人体目标检测的有效性
由于本文算法中人体目标框和人体关键点是分别预测的,但人体关键点的筛选却是由检测到的人体目标框决定的,因此,只有先准确检测出人体目标框才能通过Kpt-Out 和Box-Out 两种特征图的位置对应关系确定对应人体的关键点。
为了验证LCSA-Net 对人体目标检测的有效性,将LCSA-Net和对比方法CBAM 分别添加于轻量级模型YOLOv3-tiny 和YOLOv5s 中的相同位置,并比较添加前后对人体目标检测的效果。选择COCO2017人体姿态数据集中的人体目标数据作为训练数据和验证数据。模型使用RTX3090推理,batch size 设置为32,推理速度用每张图像的平均推理时间表示。实验结果如表1 所示。
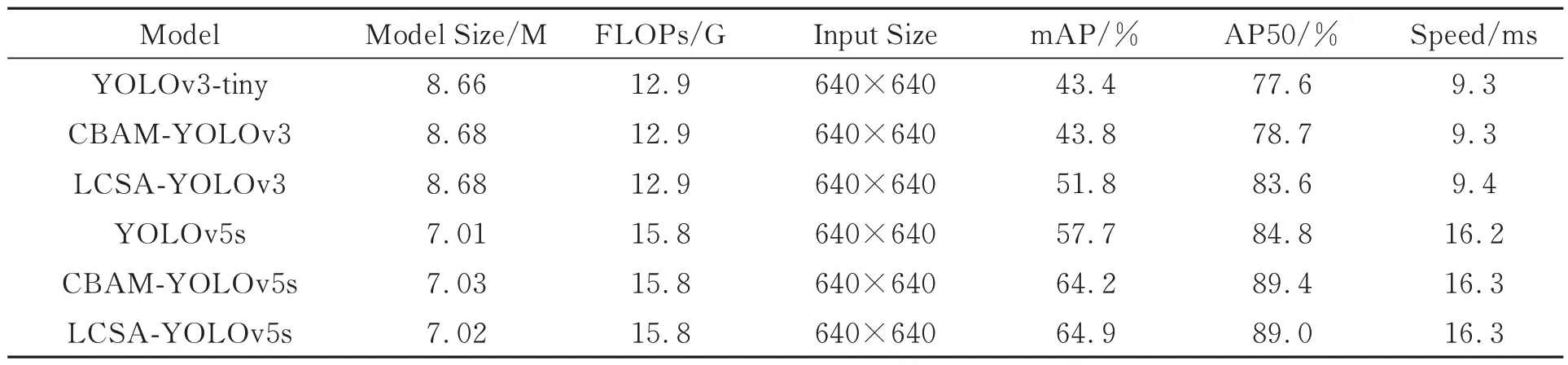
表1 轻量级人体目标检测算法性能对比Tab.1 Performance comparison of lightweight human object detection algorithms
结果表明,LCSA-Net 和CBAM 能在几乎保持模型参数量(Model Size)、计算量(FLOPs)和推理时间(Speed)不变的情况下,提升YOLOv3-tiny 和YOLOv5s 模型的人体目标检测性能。相比于CBAM,LCSA-Net 整体上实现了更大的性能提升,从而验证了LCSA-Net 对人体目标检测的有效性。
4.2 LCSA-Net 对基于热力图回归的人体姿态估计方法的性能提升
为了验证LCSA-Net 在基于热力图回归的人体姿态估计方法中的有效性,本文选择了自底向上方法中具有性能优势的HigherHRNet 高分辨率人体姿态估计网络作为对比模型。Higher HRNet 模 型 的Backbone 选 用HRNet-w32,模 型输入尺寸为512×512,通过冻结stage4 之前的网络并加载该冻结部分的预训练权重,重新训练stage4 以及之后的模型权重。作为对比,使用LCSA-Net 替换stage4 的部分卷积模块。在训练过程中,batch size 设为24,epoch 设 为200,实验结果如表2 所示。

表2 LCSA-Net 用于HigherHRNet 模型的性能对比Tab.2 Performance comparison of LCSA-Net used for HigherHRNet model
可见,使用LCSA-Net改进后的HigherHRNet模 型 的mAP 提 升0.4%,mAP50 和mAP75 也 分别提升0.1%和0.2%,中等尺度的人体姿态估计的APM提升0.7%,大尺度的人体姿态估计的APL提升0.3%。由于HigherHRNet 本身即是具有性能优势的人体姿态估计算法,LCSA-Net 的加入能进一步提升其性能,进一步验证了该注意力网络有助于增强对人体特征的提取能力,对人体关键点回归任务具有促进作用。
4.3 本文算法对YOLO-Pose 的改进效果
为验证本文算法对当前流行的YOLO-Pose算法的改进效果,以YOLOv5s6-Pose 中最轻量的ti-lite 模型为基准进行比较。输入图像尺寸为640×640,非极大值抑制阈值设置为0.6,所有模型运用相同的训练策略和数据增强方法。具体设置为:采用MS COCO2017 数据集,模型训练过程优化器使用SGD(Stochastic Gradient Descent)算法,初始学习率为0.01,动量为0.937。epoch设置为300,在warm-up 阶段每次采用一维线性插值方法更新学习率,采用周期为600 的余弦退火算法更新学习率;batch size 设置为64,使用了Mosaic、随机水平翻转、HSV 色域增强、随机旋转和平移变换等数据增强方法。
通过在MS COCO2017 验证集上进行消融实验,验证本文提出的改进策略的有效性。实验结果数据如表3 所示。
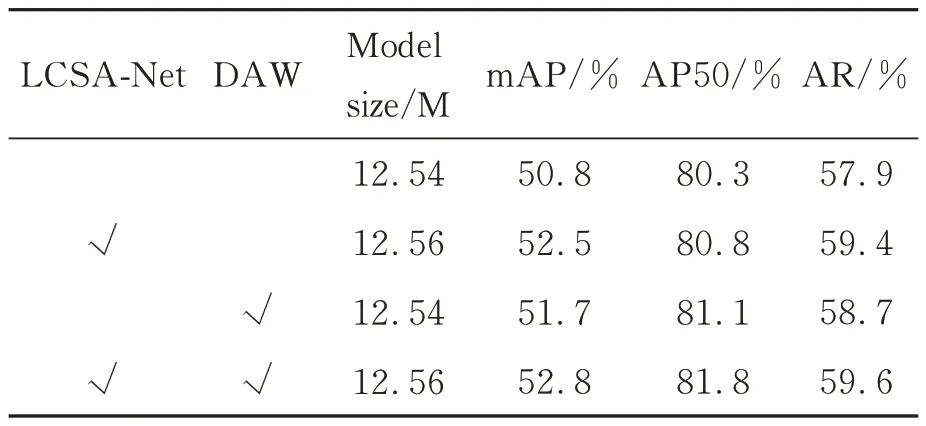
表3 不同改进策略下的YOLO-Pose 模型性能对比Tab.3 Performance comparison of YOLO-Pose models under different improved strategies
由表3 可见,本文提出的注意力网络LCSANet 和基于距离的自适应加权策略都对模型性能提升具有积极作用。相比于基准模型,使用LCSA-Net 改 进后的mAP 提升1.7%,AP50 提 升0.5%,AR 提升1.5%,进一步验证了这种改进策略的有效性。在人体关键点回归网络的中间特征图上,每个通道特征的分布是不同且多样的,插入LCSA-Net 模块加强了各个通道的特征分布,进而提升了人体目标和人体关键点检测的性能。在模型训练阶段使用DAW 策略对损失函数进行自适应加权,相比于基准模型,mAP 提升0.9%,AP50 提升0.7%,AR 提升0.8%,说明通过对远离当前位置的关键点赋以更高的权重有效改善了模型对这类关键点的回归质量。最终,同时使用LCSA-Net 和DAW 两种策略,在基准模型的基础上实现了2%的mAP 提升,1.5%的AP50提升和1.7%的AR 提升,显著提升了人体姿态估计性能。
YOLO-Pose 算法出现的误检和漏检结果以及改进后的算法对应的检测结果如图4 所示。

图4 原YOLO-Pose 算法与本文算法的人体姿态估计效果对比Fig.4 Effect comparison of the original YOLO-Pose algorithm and the proposed algorithm for human pose estimation
图4(a)中 第1 行的3 幅 图 像 展示了原YOLO-Pose 算法存在的误检问题,如将马腿或车体部位错误地检测为人体;第2 行的3 幅图像展示了原YOLO-Pose 算法存在的漏检问题,如没有检测到小尺度人体目标和被遮挡的人体目标。
与图4(a)中相对应,图4(b)展示了改进后的算法LCSA-YOLO-Pose 进行人体姿态估计的结果。可见,改进后的算法未将马腿和车体部位误判,并且在小目标人体及出现相互遮挡的情况下,模型同样得到了正确的结果,有效缓解了原模型出现的误检和漏检问题,提升了原模型的性能。
5 结 论
人体姿态非刚性和人体关键点分布多样性的特点给人体姿态估计算法带来了挑战。YOLOPose 算法吸收了先进目标检测算法的优点并获得了较高的精度和速度,然而仍然存在漏检和误检现象。其不足之处主要表现在:一是轻量级模型对人体目标的检测精度相对较低,漏检和误检的人体目标框将导致与之匹配的人体关键点发生漏检与误检;二是模型对人体关键点的坐标回归精度较低,这可能导致预测错误的人体姿态信息。针对第一点不足,本文提出了一种轻量级通道和空间注意力网络LCSA-Net 进行改进,通过提高轻量模型对人体特征的提取能力使模型尽可能提取更多的空间特征,提升模型对人体目标的检测精度,降低人体目标的误检和漏检概率,并且该注意力网络同样提升了人体关键点的回归质量。针对第二点不足,在模型的训练过程中,考虑到不同位置的特征点存在有效的感受野,为了提升模型对远离回归中心位置的关键点坐标的回归能力,本文又提出了一种基于距离自适应的加权策略,用于计算人体关键点的坐标回归损失,有效增强了模型对关键点坐标的回归能力。结合这两种改进策略,改进后的算法显著提升了基准模型的人体姿态估计性能。在计算机视觉任务中,将物理模型和深度相结合[19]是一种新的研究趋势,下一步可考虑将人体生理结构的相关先验知识引入到深度学习算法中,进一步提升人体姿态估计算法的性能。
