基于YOLO 的多类别多目标检测算法改进
2023-07-13马帅田国富张文鹏周淑文
马帅,田国富,张文鹏,周淑文
(1.沈阳工业大学,辽宁沈阳,110027;2.东北大学,辽宁沈阳,110167)
0 引言
智能车辆的技术可分为四个层面:环境感知、行为决策、路径规划和运动控制,环境感知是获取外部信息的唯一渠道。随着计算机硬件资源和卷积算法的不断突破,基于CNN(卷积神经网络)的目标检测算法也得到质的提升,并且在精度和性能方面取得了显著成果[1]。基于CNN 的目标检测算法目前主要分为Two-Stages(二阶段)和One-Stage(一阶段)两种[2],两阶段目标检测算法主要有R-CNN、SPP-Net、Fast R-CNN 系列和Mask R-CNN 等;单阶段目标检测算法主要有SDD 算法和YOLO 系列算法。智能驾驶感知应达到实时识别的要求,所以只能采用一阶段算法。智能驾驶环境感知现如今分为两个派别:多传感器信息数据融合和视觉感知,基于视觉的环境感知成本相对来说要低得多。本文的自动驾驶目标检测仍选用YOLO V3 作为视觉感知算法基础框架,针对YOLO V3 检测器识别精度不高,且检测速度和模型大小均有一定的提升空间的问题,提出了一些可行方案。
1 YOLO V3 网络结构
YOLO V3 的检测过程细分可以分两步:首先确定检测目标的位置,再对被检测目标进行分类。网络接收到图像数据先将其宽高尺寸变为416×416,经过一系列的卷积操作、残差结构及上采样处理,最后输出目标物体位置、类别以及置信度。不同于YOLO V2 的检测策略,YOLO V3 具有三个不同尺度上的检测,而YOLO V2 只有一个检测头(Detection Head),不同的尺度特征包含丰富的语义信息。YOLO V3网络结构图如图1 所示。
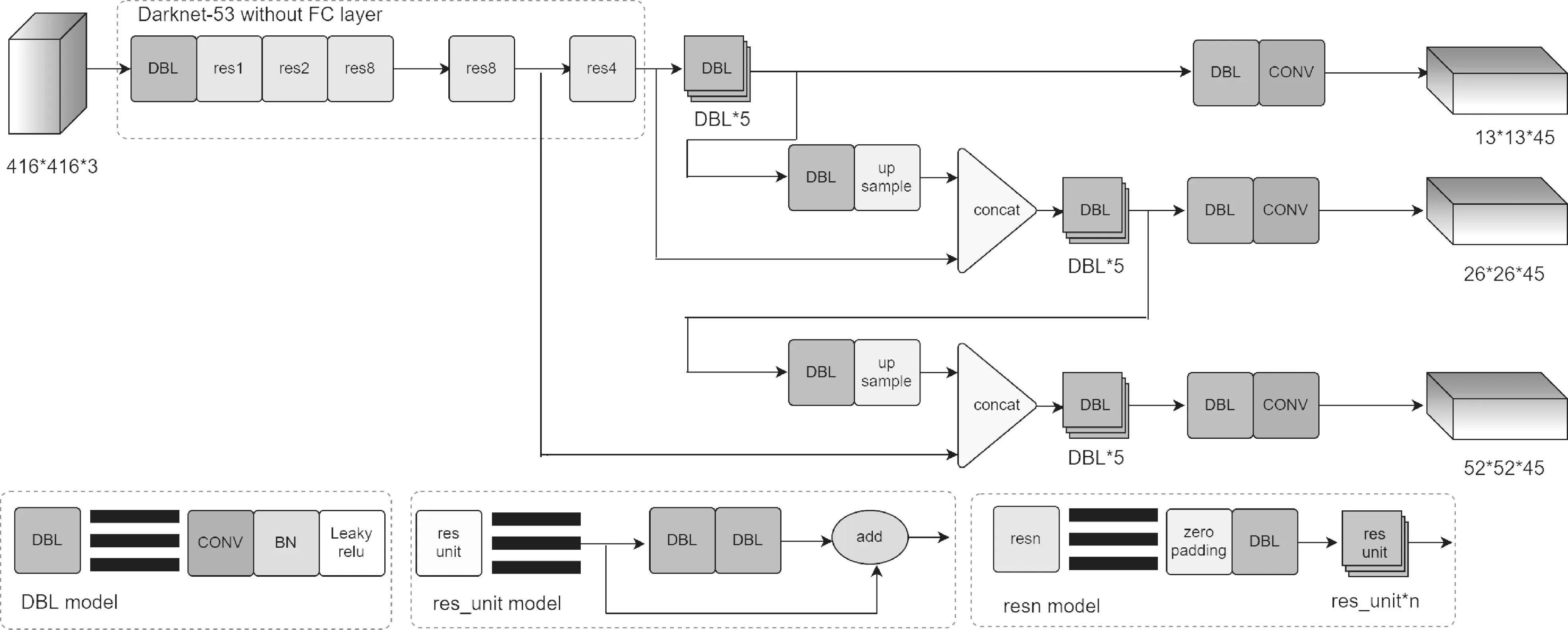
图1 YOLO V3 网络结构图
当输入尺寸为416×416 时,32 倍/16 倍/8 倍下采样后三个检测头的大小分别为13×13、26×26 和52×52。YOLO V3 仍使用K-Means 聚类法生成Anchor Box(先验框)。简单来说,Anchor Boxes 就是对预测的对象范围进行约束,对于每一个网格都生设置3 个Anchor Boxes,由于在三个不同尺度Feature Map 上做预测,所以一个位置共有9 个Anchor Boxes。该算法的缺点是对于小而密集目标检测效果不佳,且检测速度和模型大小均有进一步的优化空间。
2 YOLO V3-S 网络结构
■2.1 GELU 激活函数
神经网络中包含丰富的非线性因素,如:SMU、Relu、Maxout 和SLU 等激活函数,激活函数可以加强网络的非线性能力。在YOLO V3 网络中采用的Leaky Relu 激活函数避免了死亡Relu 问题,因为即使在负区间也有一定的数值允许较小的梯度传递,缺点是无法避免梯度爆炸问题且对负值处理不当,在微分时左右两部分都是线性的。如果想要网络模型具有很好的泛化能力,可用的方法有扩大数据集、设置更大的Batch Size、采用数据增强手段和随机失活(Dropout),增加数据集容量增加了成本,更大的Batch Size 对硬件提出了更高的挑战,所以数据增强和随机失活变成了常用的去拟合手段。随机失活遍历网络中的每层节点通过预先设定的概率保证每层节点的成活性,来减轻神经网络的过拟合。GELU 作为一种符合预期的随机正则变化方式的高性能激活函数,在Relu 的基础上加入了统计的特性,即增加了网络的非线性能力又抑制了网络的过拟合倾向,如图2 所示函数曲线。

图2 GELU 和Leaky ReLU 激活函数
YOLO V3 网络模型中包含很多的DBL 模块,鉴于上述所述的Leaky Relu 的缺点和GELU 激活函数的优点,构建DBG 模块替换原网络中的DBL 模块,如图3 所示。

图3 DBG 模块
■2.2 定位信息和语义信息融合
顶层语义信息虽然丰富,但网络层数越多会导致位置信息变得更加模糊,这就造成了顶层特征的目标类别预测可能会很准确,但目标的位置预测信息可能会很差;如果选择一个浅层网络作为目标检测的卷积神经网络,目标的位置预测信息可能很准确,但是目标类别预测可能会差很多。YOLO V3 中的FPN 结构融合了底层的位置信息和顶层的语义信息,扩大了底层的感受野,使得底层位置获得了更多的上下文信息,提高了目标检测算法的性能表现。一方面FPN 增加了算法的检测能力。另一方面由于经历连续的上采样操作(Up Sample),使得上采样后的特征信息形成了一定程度的损坏,为了恢复每一个候选区域和特征层之间的信息和路径,参考PANet 网络结构,增加下采样操作(Down Sample)构成‘双塔’结构,与相邻特征图进行信息融合。为了防止连续下采样操作对图像数据位置信息以及语义信息造成损失,在26*26*45 支路增加一次卷积操作做进一步的特征提取。
■2.3 模型简化
网络轻量化的方法有很多种,主要包括采用轻量化主干网络、知识蒸馏和模型剪枝。随着对算法的性能要求越来越高,虽然Alexnet 网络很大程度上地提升了算法的检测精度,但是也增大了计算量和模型大小,目前工业界除了对检测精度有要求,对于检测速度和模型大小也有很大的要求,想要算法走出实验室,必须要综合考虑上述问题作为自动驾驶视觉感知的目标检测算法除了要满足精度上的要求外,对网络模型大小以及检测速度也有一定的要求,车载平台系统内存有限,优秀的目标检测算法在保证精度的同时占用越小的内存越好。模型剪枝是通过一定手段删除网络中的冗余参数,从而起到降低网络模型大小,提高检测速度的目的。模型剪枝按照剪枝粒度可分为细粒度剪枝、向量剪枝、核剪枝和滤波器剪枝。前三种在网络的推理过程中每个卷积层的输出通道数不会发生改变,属于非结构化剪枝;滤波器剪枝会影响网络中卷积层的输出通道数,属于结构化剪枝。在图像经过主干网络特征提取后几乎都会经过DBL*5 的卷积操作,这种运行成本是巨大的,虽然进一步加强了网络的特征提取能力,但是也使得网络变得更深从而导致目标物体位置信息变得更加模糊,且加大了模型的计算量和大小。本文将DBL*5的卷积组替换为DBG*3,一方面使得目标物体位置信息更加清晰,另一方面降低了网络的运算量并缩减了模型,最终YOLO V3-S 网络结构如图4 所示。
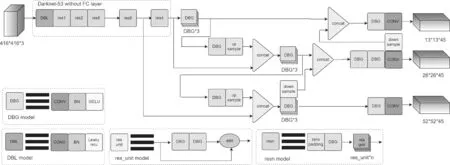
图4 YOLO V3-S 结构图
3 性能评价指标
衡量一个视觉识别器的好坏有很多种指标:如精确率(Precision),平均精度(mAP)等。Precision 表示检测正样本中正确的比例,召回率(Recall)表示正确检测正样本占所有正样本的比例,AP 值为两者曲线下的面积[3],表示每个类别在所有测试图像上的平均值,AP 值越高,表明识别器的识别性能越好;所有类别的平均精度mAP 是评价识别器的综合性能指标,计算的是全部类别的平均精度;检测速度FPS 是指画面每秒传输的帧数[4]。大而复杂的模型在实际应用中难以落地,且网络模型庞大存储起来不便。综上所述,本文选取AP、mAP、检测速度以及模型大小作为综合评价指标。
4 数据集—BDD100K 数据集
2018 年伯克利AI 实验室公布了一个丰富的智能驾驶数据集—BDD100K[5]。该数据集对真实场景中每个视频的第十秒进行截取得到10 万张图像,图像尺寸为1280×720。数据集中的视频来自美国人口众多的城市,在各种天气条件、时间和场景类型下进行采集,几乎覆盖了所有的驾驶场景。类别方面:在BDD100K 数据集中共有10 类别,分别为汽车、路灯、交通标志、行人等等,数据集中的汽车的数量最多,火车的数量最少,与现实驾驶相符。所有类别都遵循“长尾”分布,大约一半的图像目标被遮挡,约7%的图像目标被截断。天气、场景和时段方面:BDD100K 的十万高清视频是在不同天气条件下采集的,覆盖了大部分的天气情况,如晴天、雨天、雾天等等;采集场景包括城市街道、高速公路和住宅区等等;白天和黑天的图片数量比例达到了5:4。由于数据集中Motor 和Train 图像数据量过少,所以只选取前8 个类别作为研究对象。
5 实验平台及训练策略
为了测试YOLO V3 在BDD100K 数据集上的识别性能,实验环境在个人笔记本电脑上进行搭建,电脑配置及软件如表1 所示。在之前的数据集格式转换过程中,训练集共有69888 个Json 文件转换成功,为了进一步加快训练,在这69888 个文件中进一步划分训练集、验证集,划分后的测试集56608 张,验证集6288 张,测试集6288 张。训练过程共50 轮,后30 轮进行全参数更新。初始学习率为0.001,衰减率设置为0.0005;因冻结阶段占用显存较小,所以Batch-Size 设置为8;相反解冻阶段占用显存较大,Batch-Size 设置为4,输入图片尺寸宽高均Resize 为416×416,迭代次数为566080。
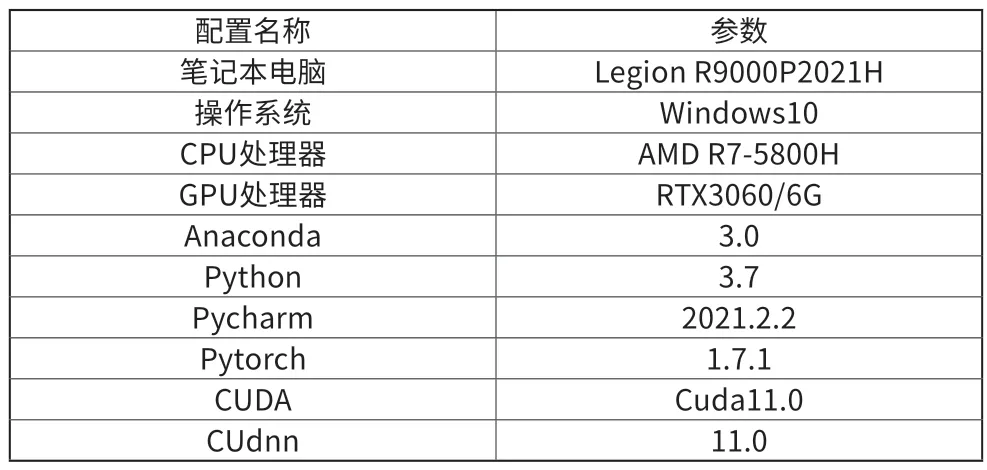
表1 电脑配置及软件汇总表
对于目前的单阶段目标检测算法而言,准确度高的先验框可以很大程度上的提高算法精度。为了提高先验框的准确度,重新在BDD100K 数据集进行K-Means 聚类分析。最终确定的Anchor Boxes 尺寸从小到大为(12,12)、(15,21)、(22,47)、(23,14)、(27,24)、(45,33)、(66,58)、(130,96)和(277,219),Avg-IOU 的值为68.67%。
6 实验结果分析
为了验证改进前后的算法优劣性,四次实验均在同一台设备上运行。从表2 可以看出,高性能GELU 激活函数的采用等顶底双层信息融合等操作均使得算法性能稳步提升,采用GELU 函数后的Bike 和Rider 提升较大,上升3%,特征融合后精度虽无明显提升,但是在测试过程中对于小目标的物体识别率比较高。YOLO V3-S 对于YOLO V3 而言,每一个类别都有提升,其中Bus 提升了5%,Bike和Rider 提 升 了3%;改进前后mAP 提高了2.375%;FPS 提升7%;模型大小由240882KB 减少到234134KB。综上所述,YOLO V3-S 算法对比YOLO V3 算法在检测精度AP、检测速度FPS 和模型大小上均有不同程度的提高,各个方面明显优于YOLO V3 算法。同时选取BDD100K 数据集中测试集中部分图片进行检测对比,图5为YOLO V3网络检测效果,图6 为YOLO V3-S 网络检测效果图,YOLO V3-S 在正常的天气下对于远处的车辆等目标具有明显优秀的检测效果,而且对于重叠物体的识别也具有很好地识别效果。如图5(a)和图6(a)所示,在路边各种障碍物的遮挡下,YOLO V3-S也能很好地识别转弯处的车辆,在阳光明媚的行驶情况下,视觉识别器可以检测到更远的目标,图6(b)所示;在大雾天气下,车辆行驶缓慢,近处的目标比远处的目标检测更重要,对比图5(c)和图6(c)可得,对于车辆正前方的车辆YOLO V3-S 可以很好地识别,并未把树错误地识别为人。综上所述,所提出的YOLO V3-S 网络在多种情况下能够保证更好的检测效果。

表2 数据集中各类别平均精度及FPS和模型大小对比

图5 YOLO V3 检测效果对比图

图6 YOLO V3-S 检测效果对比图
7 结论
本文主要对YOLO V3 网络进行改进,主要用于自动驾驶过程中实时目标检测。现有的YOLO V3 网络在对于尺度小或者密集的物体上检测效果并不友好,为了进一步提高智能驾驶视觉识别器的检测精度,对激活函数进行改进,选择了一种更加符合实际需求的激活函数,同时将深浅层的语义位置信息进行特征融合,提高自动驾驶过程中行驶周围环境的检测精度。同时考虑到训练后的网络模型要部署到自动驾驶车载平台,对网络结构进行部分轻量化处理,以保证训练后的YOLO V3-S 网络模型消耗更低的内存存储。后续将进一步对模型进行剪枝压缩,并部署在实际车载平台中进行性能测试。
