基于改进YOLOv5+Kalman的动态手势识别跟踪算法研究
2023-07-12张睿敏杜叔强周秀媛
张睿敏,杜叔强,周秀媛
(兰州工业学院计算机与人工智能学院,甘肃 兰州 730050)
0 引言(Introduction)
随着计算机视觉技术的发展,基于摄像头的手势识别研究受到了学习和业界的重视,手势识别在智能人机交互、智能驾驶系统等方面都有着广阔的应用前景[1]。高效的动态手势识别算法能让计算机准确地识别复杂的手部动作,张建荣[2]提出的动态时间规整(improve Dynamic Time Warping,i DTW)手势识别算法,采用点和线结合的方法约束搜索路径,提高了手势识别的精确度。KHARI等[3]使用微调后的VGG19(Visual Geometry Group)模型对RGB(Red Green Blue)和RGB-D(RGB+Depth)图像进行手势识别,识别准确率达到了94.8%,但只能对静态手势进行识别。王龙等[4]通过建立手势肤色模型,提取手势特征,能快速识别相关手势,但是容易受到光照等因素的影响。丁驰等[5]提出将神经网络和SSD(Single Shot Multibox Detector)结构结合起来提取手势特征,提高了在光线等因素影响下手势的识别效率,但模型较大、检测时间长。
从以上学者的研究可以看出,动态手势识别算法已经取得了不错的识别效果,但研究者很难设计出一种对所有手势都适用的识别方法。基于改进YOLOv5+Kalman的动态手势识别跟踪算法主要在YOLOv5网络的基础上添加了两个模块:自适应注意力模块(Adaptive Attention Module,AAM)和特征增强模块(Feature Enhancement Module,FEM)。增加这两个模块后,一方面减少了生成特征图时的信息丢失问题,另一方面增强了特征金字塔的表示能力,以便对不同手势进行实时准确的识别,然后应用Kalman滤波器进行预测跟踪。预测跟踪时,将短时内的手部运动看作恒定的运动,目标状态在设定的非常短的时间内是不变的,在跟踪时,因为相邻两帧图像差异不大,所以手势的运动模型采用的是等速度运动模型。
1 改进YOLOv5网络(Improved YOLOv5 network)
1.1 YOLOv5网络模型
YOLOv5模型是基于YOLOv3模型的基础上改进而来的,目前有YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个模型。YOLOv5的组成分为三个部分:Backbone(骨干网络)、Neck(颈部网络)、Output(头部网络),具体如图1所示。
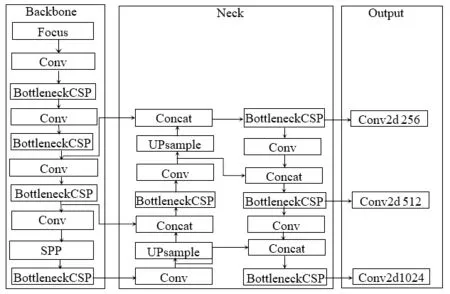
图1 YOLOv5网络模型Fig.1 YOLOv5 net work model
Focus、Conv、Bottleneck CSP 和SPP 等模块组成模型的Backbone网络,Backbone主要是在不同图像细粒度上聚合并提取图像特征。YOLOv5通过在骨干网络Backbone和Neck网络部分使用Bottleneck CSP模块,在保证语义提取准确的同时,提高网络速度[6]。Neck网络组合了一系列图像特征,并将图像特征传递到Output网络。Output网络对图像进行检测并生成边界框和预测类别。设置大小为80×80×512的图像,Neck网络进行上采样操作,上采样操作包含两个瓶颈层 Bottleneck CSP,两个标准卷积层Conv(大小步长为1),两个UPsample和Concat层;然后进行下采样操作,下采样操作包括两组Bottleneck CSP、Conv、Concat层和单独的Battleneck CSP,得到大小分别是80×80×256、40×40×512、20×20×1 024的特征图。
YOLOv5应用大小不同的特征图在头部进行检测,即应用大图像检测小目标,应用小图像检测大目标。对于颈部操作得到的结果,再经Conv2d卷积操作,便得到大小为80×80×256、40×40×512、20×20×1 024的特征图。
1.2 AF-YOLOv5网络
在YOLOv5原有特征金字塔的基础上,添加AAM 和FEM 两个模块,既减少了生成特征图时的信息丢失问题,也增强了特征金字塔的表示能力,如图2所示。这样在保证实时检测的前提下提高了YOLOv5网络对多尺度目标的检测性能,各组分别采取具有差异卷积核的大小卷积,从而获取不同尺度的感受野[7],得到不同尺度的目标信息。此外,增加了自动学习数据增强模块,在增强数据集的同时提高了模型的鲁棒性,使其更适用于实际场景。
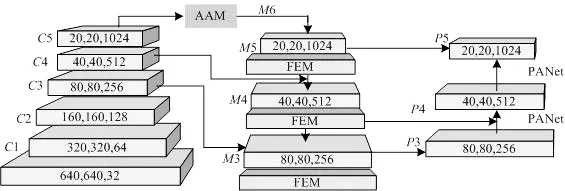
图2 AF-YOLOv5网络Fig.2 AF-YOLOv5 net work
输入图像经过多个卷积操作生成{C1,C2,C3,C4,C5}特征映射。C5通过AAM 生成特征映射{M6},映射{M6}与{M5}求和,然后传递给下一层与其他特征融合,通过有限元分析,路径聚合网络(Path Aggregation Net work,PANet)缩短了底层与顶层特征间的信息路径。首先,AAM 模块通过自适应池化层得到不同尺度的语义特征;然后,每个上、下文特征进行1×1卷积,以获得通道维数,利用双线性插值将其上采样,得到S尺度以便进行后续融合,空间注意力机制通过Concat层将三个上、下文特征的通道进行合并;特征图依次经过1×1卷积层、整流线性单元(Rectified Linear Unit,ReLU)激活层、3×3卷积层和Sigmoid激活层,为每个特征图生成相应的空间权值。
FEM 模块由多分支卷积层和分支池化层两个部分组成,多分支卷积层能为输入特征图提供不同大小的感受野,它通过扩张卷积、批归一化(Batch Nor malization,BN)层和ReLU 激活层。把三个平行分支中的扩张卷积核设定为相同大小,都为3×3,扩张速率设定为不同,分别为1、3、5。分支池化层用于融合来自不同并行分支的信息,避免引入额外参数[8-9]。在训练过程中,不同分支的平衡通过平均操作实现,使单个分支在测试过程中实现推理。
1.3 数据增强预处理
图像增强通过一定手段对原图像附加一些信息或变换数据,有选择地突出图像中感兴趣的特征或者抑制(掩盖)图像中某些不需要的特征,使图像与视觉响应特性相匹配[10-12]。图像数据增强就是对被训练的图像做随机改变(如旋转、缩放、变形等),目的是生成相似而又不同的训练样本,进而扩大训练数据集大小。模型通过多种类型数据集的训练,能够降低模型对有些特定属性的依赖,提高模型的泛化能力。同时,图像本身的变化能够增强模型对未见数据的泛化,从而避免了模型的过度拟合。
本文增强图像时使用的是ImageDataGenerator()类,ImageDataGenerator()类是图片生成器,它包含在keras.preprocessing.image包中;每次使用它对batch_size个样本图像进行增强,部分关键代码如下:
2 Kalman预测跟踪模型(Kalman predictive tracking model)
在跟踪算法上加一个预测机,本文使用Kalman滤波器预测机[13-14],形成有预测机制的跟踪算法。把短时的手部运动粗略地看成一种恒定的运动,在设定的非常短的时间内目标的状态是不变的,设计Kalman预测跟踪机对手势进行预测跟踪。通过遍历图像特征的所有通道,减去平均像素值,对于去均值后的特征图,再遍历所有特征[15-17],得到S,V,D(x i=VSD),取V矩阵前K列,即对应特征的压缩维度(预设值)。在预测跟踪中,手势运动模型采用的是等速度运动模型,状态向量定义为公式(1):
观测向量定义为公式(2):
预测向量定义为公式(3):
其中,colcenter'(t),rowcenter'(t)表示Kalman滤波器预测的搜索窗口的中心位置,v'x(t),v'y(t)表示搜索速度。
将Kalman滤波的状态方程定义为公式(4):
观测方程定义为公式(5):
以上方程中,参数w t是t时刻的动态噪声,v t是t时刻的观测噪声,其余参数都表示相关矩阵,x t表示状态,u t表示控制,Y t表示t时刻的观测,A t表示状态转移,B t表示状态控制,H表示观测。
将时间更新方程定义为公式(6):
将状态更新方程定义为公式(7):
以上方程中,P t是协方差矩阵,^x k是新的最优估计,K t是卡尔曼增益,它表明当前时刻新的最优估计是由上一时刻的最优估计加上外部控制量预测得到的。这样Kalman滤波器预测模型通过时间更新和状态更新保证跟踪的实时性和准确性。
3 实验过程与结果(Experimental process and results)
3.1 实验环境部署
实验硬件配置要求:CPU为AMD Ryzen 5 3600@4.2 GHz,GPU为NVIDIA GeForce RTX 3060,内存为32 GB,显卡为ASUS TUF-GeForce RTX3080TI-O12G-GAMING 12 GB 显存。软件开发工具:官网下载安装Python3;安装Python编辑器Py Charm;安装Anaconda;打开cmd 窗口输入命令pip install pandas,安装pandas库;打开cmd窗口输入命令pip install opencv,安装OpenCV库;官网下载安装CUDA;官网下载安装cuDNN;安装PyTorch。
3.2 训练集
利用大量样本训练模型,实验数据集采用动态手势图像,其来源主要包括向前、向后、向左、向右、点赞等共13种动态手势数据,包括600张正样本(手势)和600张负样本(不出现手势的背景),负样本在一定程度上增加了模型的鲁棒性和泛化功能。正负样本的比例为1∶1,用来进行模型训练,借助开源计算机视觉库(Open Source Computer Vision Library,OpenCV)进行对应的手势模型训练,然后进行手势识别跟踪训练。
3.3 实验结果
动态手势识别跟踪系统采用改进的YOLOv5卷积神经网络模型+Kalman预测跟踪模型进行动态手势的识别和跟踪,通过对算法的改进可以很好地提升手势识别精度,识别准确率达到了99.6%,而且不会占用太多资源。系统对部分手势识别跟踪的具体运行结果如图3所示。
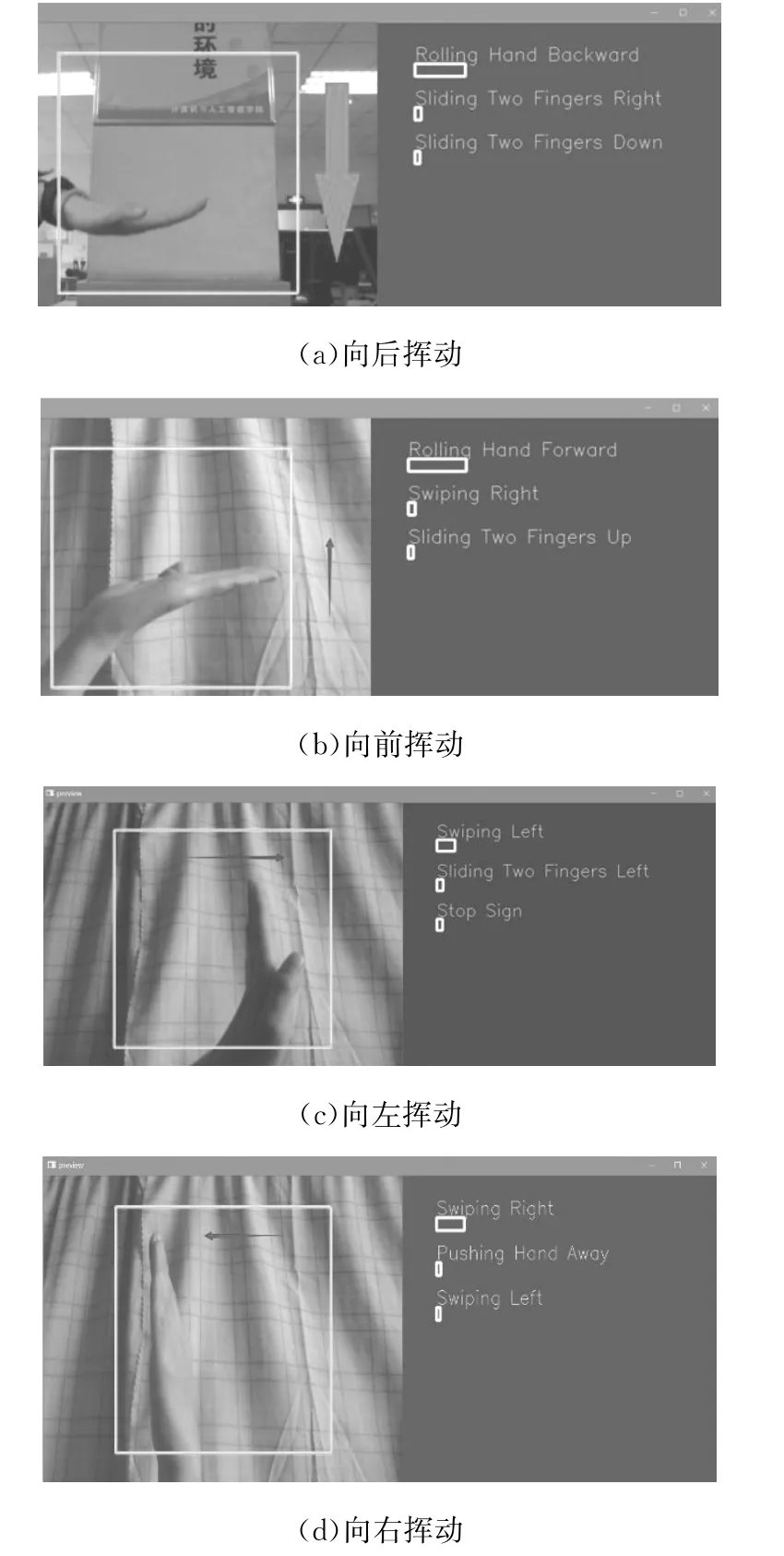
图3 运行结果Fig.3 Operation results
在项目运行结果窗口中,左侧窗口通过检测框和箭头的组合表示对手势的识别和手势的运动方向,右侧窗口通过文字和滚动状态框显示识别到的动态手势结果。其中,图3(a)的识别结果是“Rolling Hand Back ward”,图3(c)的识别结果是“Swiping Left”。
4 结论(Conclusion)
本文针对动态手势的识别跟踪问题,提出基于改进的YOLOv5卷积神经网络模型+Kalman预测跟踪模型进行动态手势的识别和跟踪算法。算法是在YOLOv5原有的特征金字塔网络基础上,增加了自适应注意力模块AAM 模块和特征增强FEM 模块,起到了减少特征图生成过程中信息丢失并增强表示能力的作用,设计Kalman跟踪器,通过时间更新和状态更新,能适时、准确地对动态手势进行跟踪。采用大量样本进行实验,实验证明算法能够对基本动态手势进行快速且准确的识别,并且Kalman滤波器预测模型保证了对动态手势跟踪的实时性和准确性。为了进一步提高算法对更多动态手势的识别和跟踪,后续将对算法进行持续的优化研究。
