基于数据挖掘的课程推荐系统设计研究
2023-07-10王仡捷
王仡捷
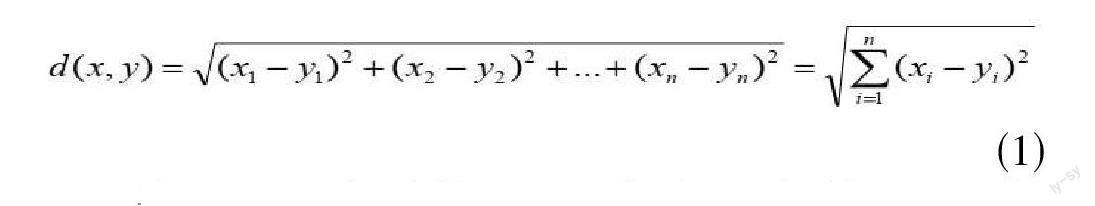
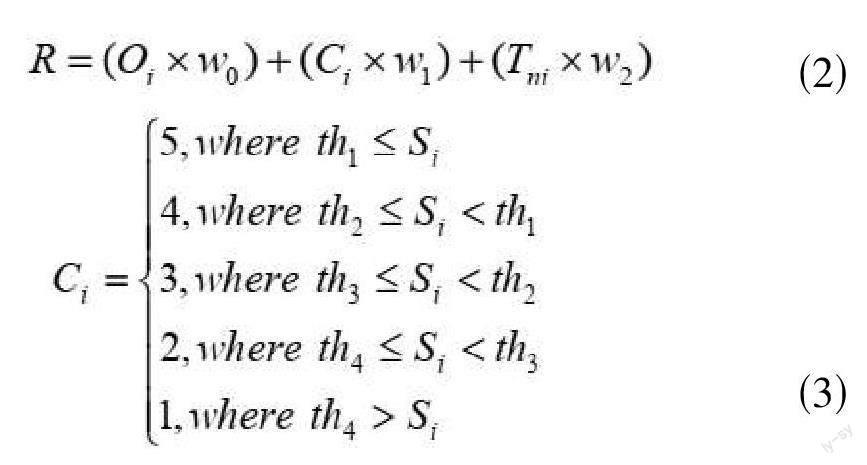
关键词:数据挖掘;课程推荐;协同过滤算法
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)14-0054-03
1概论
1.1 研究背景和意義
随着在线学习的逐渐兴起和规模的扩大,各种在线学习平台和相关资讯也在不断增多,各种类型课程也在快速增多,类型越来越丰富,用户学习课程类型选择的余地也逐渐增加,但是顾客往往要花费大量的时间才能找到自己喜欢的类型的课程,并且缺少与用户交流的功能,多以用户为主导,由用户主动去直接搜索,很少有对用户进行个性化推荐的功能,这些存在一定的局限性,从而可能造成课程平台的用户流失问题。为了解决这个问题,个性化推荐系统应运而生[1]。个性化推荐系统基于特定的算法向用户推荐他们感兴趣的课程,实现了系统与用户之间的互动,根据用户的学习记录和学习习惯或者用户对课程的评分,向用户推荐用户喜欢的具有相同标签的课程或者相同类型的课程内容。
1.2 国内外研究现状
网络学习推荐技术是指通过对用户历史行为数据和课程资源属性等信息的分析,利用机器学习、深度学习等技术为用户推荐合适的课程,以提高学习效果和用户满意度。Natarajan S等人[2]根据网民的网页操作行为推荐课程资源。在课程推荐系统中,除了明确的评分之外,还有各种类型的隐性评分数据,如赞、评论等。在许多混合系统中,这些功能被视为要包含在评级矩阵基础上的模型中的侧信息(评级可以是数字或二进制)。国内在推荐领域的研究虽然起步较晚,但也产生了一批具有代表性的推荐算法,如古险峰等人[3]针对项目评分的稀疏性,提出一种基于项目的协同过滤推荐算法;刘锦涛等人[4]提出一种适应用户兴趣变化的协同过滤推荐算法,以此来解决传统协同过滤不能反映用户兴趣变化的问题;潘毓昉等人[5]针对传统概率矩阵分解算法容易忽略用户和产品之间的关系,提出一种基于时序行为的推荐算法。针对课程推荐的准确性问题,魏江南[6]认为可以从用户的学习行为中获取用户评分,从而解决评分矩阵稀疏的问题,进而提高推荐的准确率。
2 推荐系统推荐系统
主要分为用户(User)、项目(Item)及评价(Review)三个不同的数据,用户数据是用来描述用户的特征,例如用户的性别、年龄、零售产品、居住地等信息。但这些特征与项目之间难以建立彼此的关系,因此在推荐系统中虽然有被使用,但很少与算法进行结合,通常都是对推荐的结果进行过滤排序。推荐系统在不同领域的应用上,鉴于产生推荐的方式不同,文献[7]将推荐系统共分为内容导向(Content-Based)、协同过滤(Collaborative Filtering)、混合过滤(Hybrid Fil?tering)以及人口统计推荐(Demographic Recommenda?tion)四类。
1)基于内容导向的推荐:它是基于项目的内容信息上做推荐,不需要利用用户对项目的评价意见,例如根据音乐的类型、电影的风格等固有或内在品质的属性进行推荐,以项目内容的相似性作为依据来做推荐。
2)协同过滤的推荐:利用用户过往的行为记录分析偏好并提供个人化的推荐,也是电子商务中最常使用的推荐方法。根据用户历史购买记录,并从具有相似购买行为的用户群中的购买行为来推荐目标用户可能感兴趣或喜欢的商品。
3)混合过滤的推荐:它组合了2种以上的推荐系统方法,希望能避免自己本身的缺点,同时融合彼此的优点。而Burke整理了混合过滤的推荐系统的方法以及其介绍,主要分为权重(Weighted)、交换(Switch?ing)、混合(Mixed)、特征组合(Feature combination)、瀑布型(Cascade)、特征递增(Feature augmentation)及元层级(Meta-level)7种。
4)人口统计的推荐:它依据用户的个人属性作为分类的指标,包含性别、年龄、居住地区、薪资、零售产品等个人属性。用户的个人属性与相似的个人属性彼此间都可能会拥有共同的喜好,因此可以利用这些属性对每个用户建立一个用户剖面(User Profile)进行聚类,并且通过计算分析用户之间的相似度,最后将评分较高的项目推荐给当前的用户。
这四种方法中,依据学者的研究发现协同过滤法较常被推荐系统所使用。协同过滤推荐算法拥有简单高效的特点,也是比较受欢迎的个人化(Personal?ized)推荐方法,因此在实践中受到许多研究者的关注。在协同过滤的推荐中又可分为基于记忆体(Memory-based)的协同过滤和基于模型(Modelbased)的协同过滤。
3 课程推荐设计
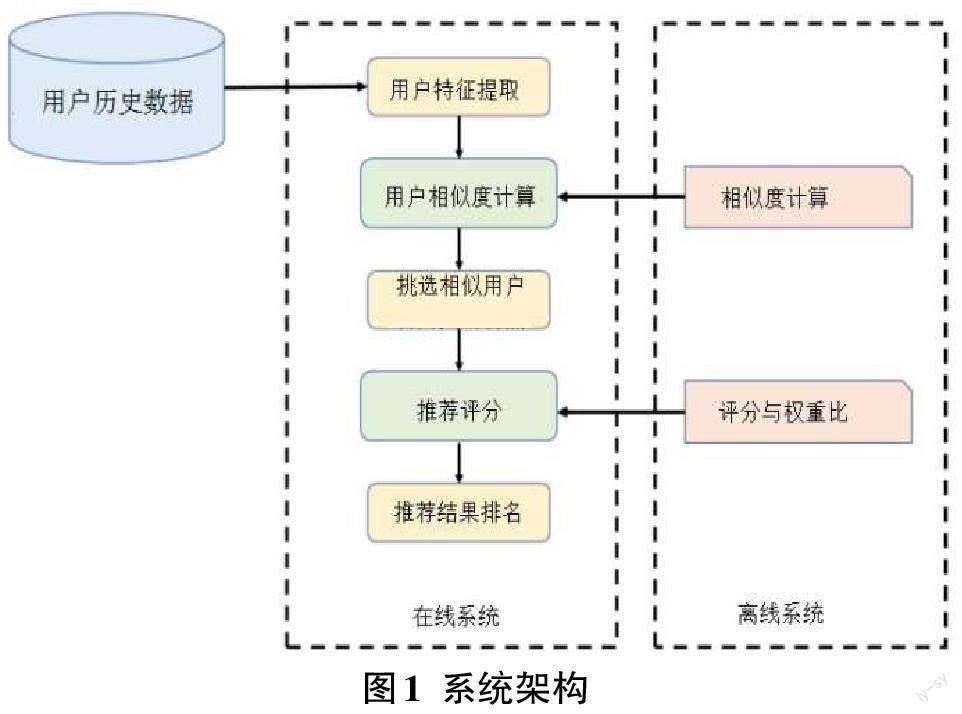
本研究的推荐系统整体的流程如图1所示,先利用人口统计的过滤法,经由用户的年龄和性别的特征,先计算进门用户与历史数据里用户彼此间的相似度,借此得到初步的推荐结果。接着针对相似的用户所适合的课程,根据设计的权重替课程产生各自的评分,并进行排名,取得最终TOP-N的推荐结果。因此该系统可以提供个性化推荐服务,依据不同的用户提供不同的推荐服务。
当面对大量数据时,首先需要进行数据清理,剔除不需要的数据,过滤错误的信息,提取自己需要的有用信息等前置作业。我们将各种不同来源的相关数据集合起来进行分析,包含数据库、数据仓储以及网络流等。接着根据不同情况,不同目标进行数据过滤处理,找出有价值或者所需要的数据。然后将过滤后的数据放进模块里进行评估确认和调整,确保评估出的结果是所期望的结果。最后再将数据进行分析,确认模型所评估出来的结果是正确的,若是错误则回到模型进行调整。
对于用户情况以及历史学习记录的搭配,我们对用户做出推荐,以下为推荐生成的步骤流程:
步骤一:首先进行用户特征提取,这边选择了几个属性作为描述用户的特征,分别为年龄、性别和疾病。
步骤二:接着进行用户相似度计算,度量或相似度量(SM)用来确定用户对用户或项目对项目之间的相似度,取得用户或项目之间的相似度也是很重要的一环。KNN算法基本上基于使用统计起源的传统相似度量,其中最常用的传统指标有Pearson correlation、Cosine以及Euclidean等。本文所选择的是欧几里得距离公式,如公式(1),计算空间向量中两点的距离,距离越近,代表相似度越高。利用距离公式,计算出A 用户与其他用户数据之间的相似度。
步骤三:根据计算出的相似度,选择前N个相似度最高的用户,并将前N个用户曾学习的课程挑选出来,为其课程产生评分以及推荐结果。
步骤四:在推荐评分的部分,考虑到由于系统中没有用户对课程的评价记录,因此我们设计了一套评分机制,利用过往用户的学习记录,将课程的类型和学习数量作为推荐依据,同时加入了时间的考虑。因为季节的不同会影响用户学习课程的行为,因此把每一季课程的学习频率也考虑在评分机制里,并生成最后的评分。公式(2)中,评价分数分为三个部分:课程点击数量、类型和该季课程的学习频率。Oi为会员学习课程i的数量,Ci为课程i的类型系数,Tni为课程i在每月里第n天的学习频率系数。
在这些历史学习数据中,我们必须先对数据预先处理过。根据分析系统的学习情况,扣除批量学习,或者一些特殊情况发生,将学习数量超过5都视为离群值过滤掉。Ci的计算中,如公式(3),Oi为该会员学习课程i的总数量,Tni的学习率则是计算在第n天中,所有学习过的课程总数量里课程i所被学习过的数量占的百分比,而w0、w1与w2则是课程数量、课程类型和该季课程学习频率之间的权重设置,三者相加总和为1。
步骤五:最后依据关联规则产生的权重所生成的课程评分产生最后的推荐结果排名,根据推荐排名顺序,将课程推荐给A用户。
关联法则也被称作购物车分析,经典的案例是美国零售业者沃尔玛从结账订单中发现每当星期五晚上啤酒与尿布的销量有正向关联,因此在每周五都会将这两样商品放在同一区让销售量增加30%。在本研究中尝试将每位用户每天评价的课程数据视为一笔数据,计算课程间同时发生的概率。该概率值作为权重可以输入用户偏好预测的权重,从而更好地完成混合推荐算法。
4 结果分析
4.1 实验数据
此系统研发者进行实验的数据来源是使用爬虫软件进行采集的某教学系统中的真实用户数据以及课程数据。在进行数据采集时,先以某一组用户选取为种子节点,选取之后,使用滚雪球抽样的方式来抽取其他用户并采集这些用户的信息,从而得到实验需要的数据。此次为完成实验进行采集的数据中,包含100位用户的具体信息,如背景信息、行为信息以及社会信息等,同时还包含相关的2000 位课程的具体信息。
4.2 评价标准
本系统能够度量预测用户评分的准确率,当平均绝对误差(MAE)较大时,系统预测准确率低,系统推荐准确度低,反之亦然。
4.3 實验
本文使用传统的基于用户的协同过滤推荐算法作为基准算法进行对比实验,具体的实验结果如图2 所示。
通过图2的算法比较可以发现,本文的算法MAE 值一直都比传统的算法低,说明本文的系统具有很好的精确度。本文还测试了不同n值对系统的推荐结果的影响,具体的实验结果如图3所示。
如图3所示,从算法验证的结果不难发现:无论n 的取值为多少,改进后的算法都要比传统算法的MAE 值低。这是因为在进行协同过滤算法的改进时,充分将用户评分的时间衰减和用户信任度考虑了进去,使得改进后的算法在准确度方面有所提升。
5 结束语
随着大数据时代的来临,数据的增加速度比以往更加迅速,因此如何从这庞大的数据中提取所需要的数据,如何从中获得重要信息并做出正确的决策判断,是一个重要的议题。因此本文所提出方法,除了改善传统的协同过滤方式,与人口统计推荐进行结合,还改进了该算法的准确性。课程的排名推荐是利用我们所研究出的评分机制以及权重调整,最终产生更符合实际情况的推荐结果,这样可以让用户除了更有目标性地快速找到所想要的课程外,还能大幅增加用户体验的满意度,让更多用户愿意学习该课程。未来我们希望能朝两个方向更进一步地研究,完善模型,配合学习记录的数据,加入更多不同的属性,增强用户彼此间的相似度。同时配合权重更多比例的分配,让推荐系统所推荐的课程更贴近用户所期望的结果。
