基于联邦学习的无线通信流量预测
2023-07-03林尚静李月颖李子怡
林尚静,马 冀,庄 琲,李月颖,李子怡,李 铁,田 锦
(1.安全生产智能监控北京市重点实验室(北京邮电大学),北京 100876;2.金陵科技学院 网络与通信工程学院,南京 211169)
0 引言
随着移动通信技术的高度发展,大众对于互联网的应用越来越广泛,智能手机、智能应用等电子产品需求量呈爆发式增长,同时网络直播、短视频也广受欢迎,导致用户对数据流量的需求越来越大,并且通信网络的负载量高速增长,因此,合理的流量预测可以有效地指导运营商建设和调整网络,同时提升用户体验,提高企业效益。
当前的流量预测方法普遍存在复杂性、时效性和准确性的问题。复杂性问题指由于数据体量不大,现有单个或局部范围的流量预测模型通常是集中式算法模型,如果直接扩展到城市全域范围,必然导致在模型训练过程中的复杂度急剧增加;时效性问题指在模型持续运行过程中,分散在城市全域范围的各个基站的实时流量数据需要全部汇聚到部署了预测模型的中心节点上进行推算,导致预测模型的时效性较低;准确性问题指城市尺度的流量特征是高度差异化的,与城市的规划、城市居民生活习惯、通信设施部署息息相关。城市尺度的流量预测模型需要准确地刻画本城市的流量特征。
针对以上问题,本文提出一种基于联邦学习的无线通信流量预测模型。本文的主要工作如下。
1)提出了云边协同下城市全域通信流量预测框架,如图1 所示。城市全域被分割成若干个子区域。一个移动边缘计算服务器负责一个或多个子区域的流量预测。若干移动边缘计算服务器和一个中心云服务器组成整个云边协同流量预测框架。预测模型训练和模型运行均在移动边缘计算服务器实现,中心云服务器仅负责协调多个移动边缘计算服务器进行协同训练,并将多个移动边缘计算服务器预测的区域级流量汇总形成全域流量预测结果。本文所提的云边协同的城市流量预测框架能够以较低的复杂度、较高的实时性实现城市全域流量预测。

图1 云边协同下的城市全域通信流量预测框架Fig.1 Framework of citywide communication traffic prediction under cloud-edge collaboration
2)本文提出基于合作博弈的联邦训练模型,并针对非独立同分 布(Non-Independent and Identically Distributed,Non-IID)的通信流量数据提出模型优化方法,有效提高通信流量预测的精确性,以及解决复杂度高、实时性低的问题。具体包含3 个步骤:首先构建初始联邦,利用JS(Jensen-Shannon)散度挑选出流量分布相似的栅格组成初始联邦;其次选择联邦成员,边缘计算服务器在执行联邦训练过程中,中心云服务器将栅格作为合作博弈的参与者,利用合作博弈中的超可加性准则在初始联邦成员中筛选栅格;最后分配合作后的收益,采用基于夏普利(Shapley)值的收益分配方法在合作产生收益盈余的情况下对栅格进行收益的合理分配,保证了栅格间联盟的稳定性,从而解决了流量预测模型的准确性问题。联盟的形成过程如图2 所示。
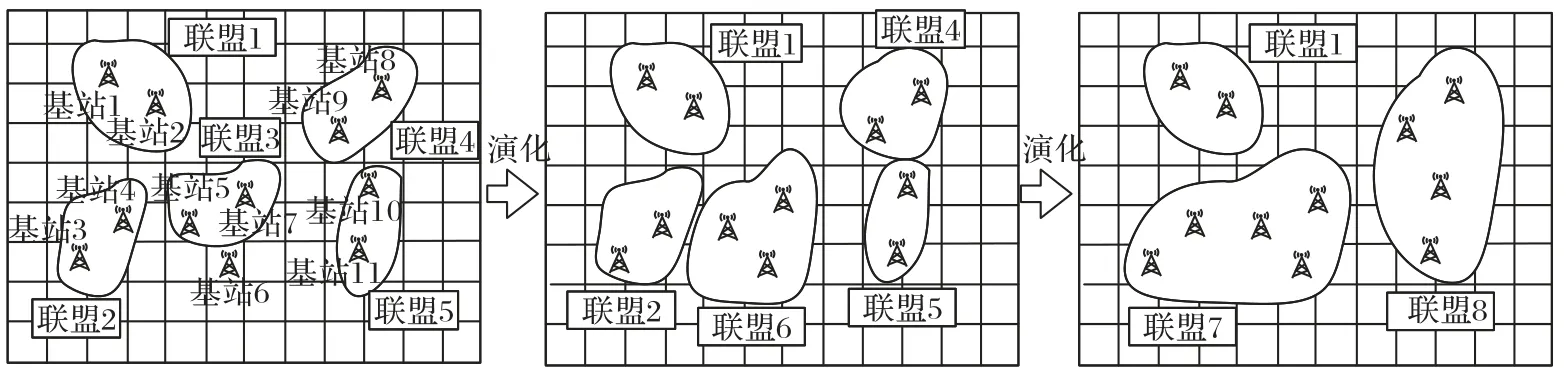
图2 联盟形成过程Fig.2 Formation process of alliance
3)仿真结果表明,本文提出的基于联邦学习的无线通信流量预测模型,各个栅格流量预测模型同步训练,预测效果优于栅格独立式训练。本文提出的基于合作博弈的联邦训练模型保证栅格间可以组成稳定的联盟。与栅格独立式训练以及集中式训练相比,模型预测误差在市区、市中心、郊区均有下降。
1 相关研究
针对蜂窝流量预测问题,传统算法[1-4]普遍采用统计概率模型或者时间序列预测模型预测流量。传统流量预测算法都是针对每个小区单独建模,然而针对单个小区的流量预测模型无法直接适用于所有小区。在实际应用中,需要对千万数量级别小区流量进行并行化建模,这无疑非常困难。
随着深度学习算法在各领域取得突破进展,能够捕获空间相关性的卷积神经网络(Convolutional Neural Network,CNN)和能够捕获时间相关性的长短时记忆(Long Short-Term Memory,LSTM)网络被逐步应用到通信流量预测领域[5-8]。深度学习模型由于具有拟合复杂非线性的特点,通常将多个小区的流量数据整体作为训练集进行训练,并产生统一模型用于多个小区的预测;然而,随着流量预测范围扩大到城市全域尺度,导致预测模型的复杂度提高,实际预测效果不理想。
为了解决以上问题,本文在模型中引入联邦学习的思想。联邦学习是一种能够具有隐私保护的分布式机器学习训练框架,多个客户端在一个中心服务器的协同之下共同训练一个模型[9-11]。分布式算法模型可以大范围地预测流量,数据集增多可以提高模型预测精度,同时也不会出现复杂度高、实时性低的问题。
然而,联邦学习的研究过程中面临一个问题,集中式算法中多个小区流量数据为独立同分布(Independent and Identically Distributed,IID),采用分布式算法时,每个边缘计算服务器的数据都包含多个小区,服务器的数据之间是非独立同分布(Non-IID)的,而Non-IID 数据往往比IID 数据在模型训练时表现差。为了提高联邦学习中Non-IID 数据模型性能,有研究提出不同的方法[12-14]。这些方法大多用于监督学习中的分类场景,预测通信流量属于回归问题且流量数据为带有空间特征的时间序列数据,所以并不适用。
本文提出的基于联邦学习的无线通信流量预测模型,在云边协同城市全域流量预测框架下采用基于合作博弈的联邦训练方法,通过筛选栅格流量预测模型参与训练,并搜索稳定联盟,解决了边缘服务器上流量数据Non-IID 的问题。现有方法模型与本文模型的具体对比见表1。

表1 现有方法模型与本文模型的对比Tab.1 Comparison between models of existing methods and the proposed model
2 蜂窝流量特征分析
本章结合“意大利电信大数据挑战赛”中所提供的开源数据集(https://dataverse.harvard.edu/dataverse/bigdatachallenge),分析蜂窝流量在时空范围的相关性和分布特性。该数据集将整个米兰市以235 m×235 m 的地理粒度划分为100×100 个栅格(栅格标号依次从1~10 000),并且统计了栅格内用户的上网(Internet)、短消息和语音(Voice)。
2.1 蜂窝流量相关性分析
图3 表示了米兰市3 个典型的功能区域:位于米兰市郊区的博科尼大学(Bocconi)、位于市中心的米兰大教堂(Duomo)和市区的纳维利(Navigli)这3 种业务流量日均流量的波动情况。

图3 米兰市不同区域日平均业务流量特性Fig.3 Characteristics of daily average business traffic in different regions of Milan
在图3 中,对于同一种业务流量类型,3 个典型区域在时间上流量波动具有周期性,周期大致为24 h,业务流量均在同一时间段(中午12:00 左右)达到峰值,表明不同区域的流量在时间维度上具有相似的相关性。然而,对于短消息服务(Short Message Service,SMS)或语音服务,市区纳维利和远离市中心的博科尼大学的流量远低于位于市中心的米兰大教堂。米兰大教堂的流量值保持在1 000 上下浮动,而纳维利和博科尼大学的流量值分别在500 和500 以下。可以看出,不同区域的流量差异映射出人群在不同区域的聚集度差异。再如,纳维利互联网服务流量峰值明显滞后于其他两个区,这与纳维利人群活动集中在夜间有关。
2.2 蜂窝流量的分布特性
大量个体的社会化活动聚集形成群体的社会化活动,导致地理空间上形成功能区域(商业区、大学、办公区、公交枢纽)。功能区域反向影响了人群的活动特性,导致不同功能区域的蜂窝流量又呈现差异性。
如图4 所示,本文统计了全域(共10 000 个栅格)每小时短消息业务的分布情况,从宏观上可以看出,中心区域栅格流量分布较高,边缘区域栅格流量分布较低,不同区域的流量分布具有差异性。在图4 的基础上,本文进一步挑选并统计了市中心栅格(ID=5051)、市区栅格(ID=3439)和郊区栅格(ID=444)每小时SMS 的分布,如图5 所示。图5 给出了值频率的离散显示。SMS 流量数据点被分成离散的、均匀间隔的柱状箱子,并绘制出每个柱状箱子中的数据点的出现频率。可以看出,中心栅格业务量最大,市区栅格业务量次之且拖尾较长,郊区栅格业务量最小。由此可见,不同栅格的SMS的分布也不尽相同。

图5 SMS在不同栅格上的分布Fig.5 Distribution of SMS on different grids
一方面,从2.1 节分析的结果可以发现,不同地理区域的蜂窝流量都具有相似的时间维度相关性,因此各个移动边缘计算服务器上运行的流量预测模型可以基于联邦训练框架进行协同训练以提升各自的性能;另一方面,从2.2 节分析可知,不同栅格的蜂窝流量的分布又不尽相同,即Non-IID,然而云服务中心将流量分布差异性较大的边缘服务器上的预测模型直接融合会导致融合后的模型性能较差,因此,云服务中心上需要解决边缘服务器上流量数据Non-IID 问题,以确保融合后的模型性能。
3 基于联邦学习的流量预测模型
本章详细介绍了基于联邦学习的通信流量预测模型中部署在边缘计算服务器端的流量预测模型、云服务器端上基于合作博弈的联邦平均(Federated Averaging,FedAvg)算法和云端与边缘端的联邦训练过程。在本文基于联邦学习的通信流量预测模型中,分布在边缘计算服务器端的流量预测模型采用LSTM 网络模型。流量预测模型的训练采用基于合作博弈的联邦训练过程,利用JS 散度筛选得到流量分布相似的栅格,并在此基础上引入合作博弈的超可加性准则判断联盟能否形成;为了确保联盟的稳定性,引入合作博弈的核(Core)以及Shapley 值将收益(整体预测误差的下降值)公平地分配给各个栅格成员。
3.1 流量预测模型
由第2 章可知,不同地理区域的蜂窝流量的分布具有差异性,因此,为解决边缘服务器上流量数据Non-IID 问题,本文初步对米兰市进行栅格划分。首先,将城市划分成h×w个栅格,城市全域在第t个时刻的流量可以表示为一个流量时空矩阵,定义为Dt,如式(1)所示:
对Dt进行数据归一化处理,处理后的数据定义为如式(2)所示:
3.2 基于合作博弈的联邦训练过程
不同栅格的蜂窝流量的分布不尽相同,即Non-IID。直接将流量分布差异性较大的预测模型融合,融合后的预测模型性能不佳。为了解决边缘服务器上流量数据Non-IID 的问题,本节提出了基于合作博弈的联邦训练模型。
首先,引用JS 散度的概念分析栅格间分布的相似性,挑选流量分布相似的栅格,形成初始联邦,初步解决流量数据Non-IID 的问题。
然后,考虑到分布相似的栅格共同训练不一定会带来增益,参与共同训练的栅格数目也并不是越多即增益越高,本文引入合作博弈中的超可加性定理以证明构建联邦的必要性。在JS 散度构建出的初始联邦中,进一步挑选联邦中的栅格成员,使得最终形成的联邦中成员的合作收益高于各自收益之和(即联邦的训练效果优于各个栅格独立训练的效果之和)。在此过程中,超可加性要求联邦中每加入一个新的栅格,形成的新联邦都比旧联邦的训练效果更好,即为联邦带来增益。部分成员的流量数据由于存在Non-IID 的问题,加入某联邦中会导致联邦收益变差,因此不满足超可加性,不能参与构建该联邦。
最后,由于形成的联邦带来了合作剩余(即合作增益),本文引入合作博弈中核以及夏普利值的概念对联邦成员进行公平的收益分配,使得成员无动机离开联邦,从而巩固了联邦的稳定性。
详细过程如下。
1)初始联邦构建。
首先,引用JS 散度衡量栅格间流量分布的差异性,以栅格k和栅格l为例,将两个栅格间的JS 散度定义为dJS(k‖l),如式(3)所示:
其中:N=h×w为城市栅格总数,k和l分别表示栅格标号,xn表示栅格中的流量统计值,Pk(xn)与Pl(xn)分别表示栅格k与栅格l的流量概率分布,Pm(xn)表示栅格与栅格流量概率分布的均值。散度越小,代表两个分布的相似性越高。
其次,通过计算JS 散度,利用谱聚类算法对栅格聚类,找到流量分布相似性较高的栅格,形成初始联邦。将栅格视为图节点,将节点流量分布的相似性作为节点之间边的权重,以此构建栅格的网络图,如图6 所示。

图6 栅格网络谱聚类图Fig.6 Network spectral clustering diagram of grids
具体地,针对栅格k,计算栅格k与同一区域中其他任意栅格流量的JS 散度,设定JS 散度阈值为dthreshold,其他栅格以栅格l为例,若栅格k与栅格l的散度服从约束条件:
2)联邦成员选择。
经过上述初始联邦的构建,可以初步筛选出流量分布相似的栅格。为保证各个栅格在之后的联邦训练中的融合效果,对栅格进一步筛选,从而提高流量预测精度,联邦成员选择过程如下。
首先,引入合作博弈的概念,将参与联邦训练的栅格作为合作博弈中的参与者,收益由预测评价指标均方根误差(Root Mean Squared Error,RMSE)和均方误差(Mean Squared Error,MSE)评判。本文将联邦训练中栅格间的合作博弈表示如下:定义G=(F,V)为一个N个栅格参与的合作博弈,其中,F表示参与合作博弈的栅格集合,V表示所有可能组合的收益函数,V:2N→R。收益函数V由预测模型的RMSE 和MSE 共同决定。
对筛选出的参与合作博弈的栅格集合F={k,l,…}中所有的栅格初始化,在中心服务器端,随机生成一个初始化全局模型参数ω,并将该全局模型推送至各个参与联邦训练的栅格流量模型,将栅格k的初始化模型参数定义为ωk,如式(7)所示:
其次,栅格流量模型进行本地训练,栅格k接收到ω后,根据本地流量数据训练全局模型并更新参数,得到更新后的本地模型参数。将本地模型的一次参数更新称为一次迭代,设定联邦训练迭代次数,达到次数后停止参数更新。从训练样本中选取一个批量,批量大小用b表示,本地模型根据梯度下降法更新参数,使得损失函数最小化,更新过程如式(8)所示:
其中η表示学习率,η∈[0,1]。损失函数利用L2 范数表示,具体见式(9):
其中Yt表示t时刻流量真实值。
然后,本文中N个参与合作的栅格同步训练,将训练后的模型参数上传至中心云服务器,中心云服务器根据FedAvg 算法对全局模型进行一次融合更新,更新后的全局模型参数表示为ωt,模型参数更新过程见式(10):
最后,所有栅格完成联邦训练后,中心云服务器需要根据参与联邦训练的栅格得到的收益决定栅格是否能够组成联盟。因此,本文引入了合作博弈中超可加性的概念以解决栅格间组成联盟的问题。
超可加性指对于任意由栅格组成的联盟S和联盟T,S,T⊆F且S∩T=∅,V(S∪T) ≥V(S) +V(T)。
简单地,由栅格组成的互不相交的联盟形成的大联盟至少保证了两个互不相交的联盟分别获得的收益,则博弈是超可加的。在本文中超可加性指由栅格组成的互不相交的联盟形成的大联盟的整体预测误差小于两个互不相交的联盟分别训练的预测误差之和,则栅格间有形成新联盟的必要性。
结合合作博弈的超可加性,中心云服务器根据训练得到的RMSE 判断联盟是否成立,若验证结果满足式(11),则保留联盟内的栅格;若不满足,联盟无法成立,中心云服务器继续筛选其他栅格参与上述联邦训练,直到中心云服务器遍历完毕F中所有的栅格,并采用贪心算法搜索联盟组合,最终得到新的联盟H。式(11)中的MSE 由式(12)表示:
筛选栅格组成稳定联盟的伪代码如算法1 所示。
算法1 栅格结成联盟的稳定性判断过程。
联邦成员选择过程算法流程如图7 所示。
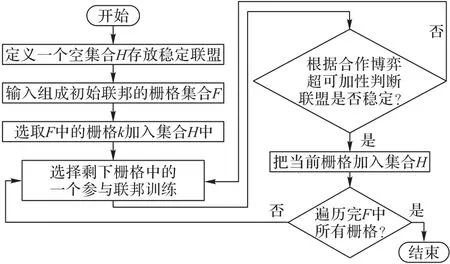
图7 联邦成员选择过程的流程Fig.7 Flow of alliance member selection process
3)收益分配机制。
由于超可加性,参与合作博弈的栅格有形成大联盟的动机,联盟整体获得预测误差下降的收益。然而,在联邦训练过程中,有个别栅格对收益作出了牺牲,即个别栅格的预测误差上升,导致对合作产生不满意,因此合作后的收益分配问题至关重要,这也确保了大联盟的稳定性。针对联盟稳定性问题,本文引入了Core 以及Shapley 值的概念进行探讨。
在本文中,一个合作博弈的核是一组收益分配,它保证没有一个参与者有动机离开该联盟,从而确保联盟的稳定性,定义如式(13)[15]所示:
其中:x表示分配给参与者的收益,i表示合作博弈的参与者,即栅格,H为稳定联盟集合。
然而,在解集中选择一个合适的核分配较难,且核有可能是空集;另外,收益分配也可能产生分配不公平的问题。Shapley 值是必然存在且唯一存在的博弈稳定点,能够提供一种相对公平的收益分配结果,从而确保联盟的稳定性,因此本文采用基于Shapley 值的价值分配方法以解决分配公平性问题。
对于博弈联盟H,它的Shapley 值表示为:
其中:S={S:∀S⊆H}为隶属于H的所有子集的集合,则集合S的基数为|S|=2|H|,|S|表示联盟S中栅格数。
3.3 联盟稳定性证明
3.2节中提到的以合作博弈中的核以及Shapley 值能够确保联盟参与者得到公平的收益分配,从而无动机离开联盟,保证了联盟的稳定性。本节进一步从理论上证明了Core与Shapley 值的稳定性。
1)合作博弈中的Core。
式(13)表示,对于大联盟H,如果那么划分V(H)的收益变量是群体理性的。如果参与者都能获得不少于单独行动的收益,即xi≥V({i}),∀i,那么收益变量xi就是个体理性的。本文根据这两个条件,可以在寻找稳定联盟的栅格筛选过程中求解,确定联盟的稳定性。
示例1 给定3个栅格参与的合作博弈(H,V),H={1,2,3},已知该合作博弈的收益函数满足超可加性,V({1,2,3})=4,V({1,2})=1.4,V({1,3})=2.1,V({2,3})=2.9,通过式(13),求解以下不等式产生核,并产生了如何分配可以稳定该大联盟。
通过求解这些不等式,本文得到一组收益分配解集,即P={x1,x2,x3|0 ≤x1≤1.1,0 ≤x2≤1.9,0 ≤x3≤2.6}。
2)合作博弈中的Shapley 值。
式(14)中,栅格i获取的合作收益分配xi应满足有效性公理、对称性公理和可加性公理。
有效性指联盟中各个栅格的收益总和等于合作收益:
对称性指收益分配不随联盟成员在合作中的次序变化而变化。如果两个栅格i和j对联盟的边际贡献相等,则满足:
可加性指联盟中栅格存在多种合作情况时,每种合作的收益分配与其他合作结果无关,每个成员的总分配是集中合作的分配之和:
其中S1和S2为隶属于H的子集。
对于博弈联盟H,存在唯一稳定的向量函数X,满足以上公理,它的第i个分量即为式(14)中的xi。
依据Shapley 值方法计算示例1 中合作博弈分配的唯一解为(1.1,1.075,1.825)。
为了直观地解释Shapley 方法分配解的稳定性,引入三角形重心坐标。由顶点ν1、ν2、ν3定义三角形T,其中,ν1=(1,0,0),ν2=(0,1,0),ν3=(0,0,1)。这样,合作博弈(H,V)的任意一个分配结果p=(x1,x2,x3)可以通过重心坐标顶点的加权和p=x1ν1+x2ν2+x3ν3表示。
图8中,位于三角形T阴影区域的合作收益分配是不稳定的,而位于三角形T非阴影区的合作收益分配结果是稳定的。例如,位于图8中右下角的三角形阴影区,由于栅格2分配了过多的收益,导致栅格1和栅格3对分配结果不满意,所以位于该区域的分配结果是不稳定的,则联盟是不稳定的。
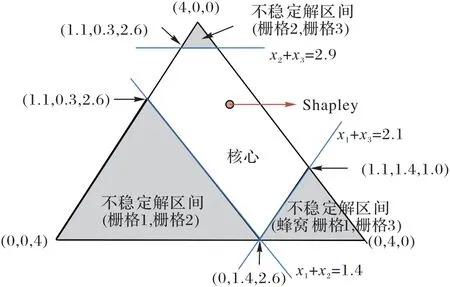
图8 重心坐标系中合作博弈的核以及分配Fig.8 Core and distribution of coalitional game in barycentric coordinate system
在各个联盟有收益盈余(整体预测误差下降)的情况下,本文对挑选的联盟进行合理收益分配,如表2 所示,保证了联盟的稳定性与公平性。

表2 联盟内部栅格的收益分配Tab.2 Profit distribution of grids within alliance
3.4 模型复杂度与时效性分析
本节将对所提出的基于联邦学习的流量预测模型的复杂度与时效性进行分析,主要体现在计算复杂度以及通信开销两个方面,并与集中式算法模型作对比。
3.4.1 计算复杂度
在模型离线训练阶段,本文模型主要包括4 个阶段的算法:第1 个阶段边缘服务器在各区域针对栅格应用谱聚类算法,从而构建初始联邦。第2 个阶段利用合作博弈的超可加性应用贪心算法搜索稳定联盟。第3 阶段与第2 阶段交替进行,贪心算法计算过程中得到的联盟组合中的栅格成员进行联邦训练。第4 个阶段边缘服务器计算Shapley 值进行收益分配,激励联邦成员参与训练。
第1 阶段的谱聚类算法用于构建初始联邦,谱聚类算法复杂度为O(d2)[16],d为训练样本数据维度,本文流量数据为一维数据,因此时间复杂度较低。第2 阶段的贪心算法用于搜索稳定联盟,贪心算法是一种近似算法,时间复杂度为O(N2),N为初始联邦成员数。由于采用了谱聚类算法后获得初始联邦规模较小,贪心算法的复杂度较低,在允许的范围之内。第3 阶段,各区域栅格配合贪心算法进行联邦训练。在本文模型中采用的基模型为LSTM,与相同基模型的集中式算法作相比,用网络参数量4(nm+n2+n)衡量模型复杂度[17],其中n为隐藏层单元数,m为输入数据维度。可以看出,模型复杂度与n呈指数相关,与m呈线性相关。由于本文对单栅格流量进行训练,因此本文模型输入数据维度为1,又设定隐藏层单元数为32,则网络参数量为1 088。而集中式算法模型的输入数据维度为400(一个区域包含400个栅格),为了提高模型精度,隐藏层单元数必然需要增加,本文设定集中式算法模型的隐藏层单元数为64,则网络参数量为29 760,约为本文模型参数量的27 倍。第4 阶段计算Shapley 值的算法时间复杂度为O(2M)[18],M为联邦成员数,但可以通过采样等方法优化算法减少计算量,降低时间复杂度。
其中,第1、2、4 阶段的算法只需执行一次,且贪心算法与计算Shapley 值的算法都可通过优化降低时间复杂度,而第3 阶段的联邦训练需要重复进行。相较于集中式模型,本文模型包含多种算法,整体复杂度较高,但综合分析各部分算法的复杂度,都在可接受的范围之内。
3.4.2 通信开销
在模型离线训练前的数据准备阶段,本文模型要求将本文所使用数据集中两个月的流量数据都上传至边缘服务器。集中式模型也要求将同样的数据上传至中心云服务器,因此,在这一阶段两者具有相同的通信开销。
在模型在线预测阶段,本文模型与集中式模型的时序对比如图9 所示。t1到t2时刻,各栅格使用训练阶段得到的模型直接在本地逐小时预测流量,在训练阶段得到的联盟稳定不变的情况下,通信开销为零。集中式模型需要实时将全市流量数据上传至中心云服务器,再在中心云服务器进行流量预测,通信开销为12.5 Mb/h。总而言之,相较于集中式模型,本文模型在预测阶段通信开销更低,实时性更强。

图9 云边协同框架与集中式算法的预测阶段时序对比Fig.9 Comparison of prediction phase time sequence between cloud-edge collaboration framework and centralized algorithm
本文挑选市中心的栅格进行了不同学习算法的预测误差对比,见图10 所示。其中,非联邦学习即栅格进行独立式训练,集中式学习即一个区域中所有栅格共同训练,集中式学习1 的隐藏层个数设为32,集中式学习2 的隐藏层个数设为64。从图10 中可以看出,首先,联邦学习的预测误差低于非联邦学习和集中式学习;其次,从集中式学习1 到集中式学习2,虽然预测误差有所下降,但是隐藏层个数增大,复杂度大幅提高,且预测误差高于联邦学习,因此,验证了3.3 节得出的结论(即在合作后具有收益盈余的情况下,可通过对栅格进行收益的合理分配,保证栅格间联盟的稳定性,从而提高流量预测模型的准确性)。

图10 不同复杂度的学习算法性能对比Fig.10 Performance comparison of learning algorithms with different complexity
4 模型性能分析
将模型在“意大利电信大数据挑战赛”中所提供的开源数据集上进行验证,共进行了4 组对比实验。1)将本文所提出的模型训练结果与去掉联邦学习的模型训练结果对比,前者的预测误差低于后者,验证了联邦学习能有效提取各区域流量共有特征,从而提高模型精度。2)将联邦训练结果与集中式训练作对比,前者的预测性能优于后者,验证了联邦学习能够提升预测性能。3)针对不同区域栅格的联邦学习性能对比,相较于市区、市中心,郊区的预测效果更优。4)针对不同业务类型的联邦学习性能对比,短消息流量与语音呼叫流量的预测误差低于互联网流量。
4.1 数据集描述
采用“意大利电信大数据挑战赛”中所提供的开源数据集,将20×20 的栅格设定为一个区域,则米兰市被划分为5×5的区域,将25 个区域进一步划分为市中心、市区和郊区,如图11 所示。

图11 米兰市栅格分布Fig.11 Distribution of grids in Milan
4.2 参数设置和实验环境
在模型训练过程中,本文从全部数据集中取出10%作为验证集,剩下的90%作为训练集。LSTM 网络模型参数中seq设为3,hidden_size 设为32,num_layers 设为1。在训练过程中,逐步调整参数达到最优模型,训练过程中学习率取0.001,Batch size设为32,Epoch size设为300。实验采用RMSE 作为衡量模型性能的指标。
实验环境的硬件配置为:Intel Core i5-8250U CPU @1.60 GHz(8 CPUs)~1.8 GHz,128 GB 内 存,Intel UHD Graphics 620,GPU 数量为2。软件配置为:Python 3.7.1,PyTorch 1.8.1,CUDA11.3,cuDNN8.1.1。
4.3 不同区域栅格联邦学习性能
为验证本文模型引入联邦学习的有效性,本文在市区、市中心和郊区中分别随机选取3 个栅格,并分别进行非联邦学习、集中式学习与联邦学习的训练。非联邦学习指栅格进行独立式学习,集中式学习指一个区域的栅格共同训练一个模型。对比这3 个栅格训练得到的预测误差,如表3 所示。

表3 不同区域预测效果对比Tab.3 Comparison of prediction effect of different regions
从表3 可以看出,市区内经过联邦学习训练过的栅格1较非联邦学习的RMSE 下降了0.7%,栅格2 下降了1.7%,栅格3 下降了3.4%。R2越大,表明真实值与预测值的相关性越强。在栅格1 上,相较于集中式学习,联邦学习的R2下降了42.1%,但栅格2 和栅格3 的R2有所上升,原因可能是联邦学习时栅格之间互相影响,导致栅格2 和栅格3 的训练效果提升,栅格1 的训练效果下降。
对于市中心的预测误差,联邦学习相较于非联邦学习和集中式学习均有所下降。其中,相较于非联邦学习栅格1 下降了4.7%,栅格2 下降了3.7%,栅格3 下降了0.8%;相较于集中式学习栅格1 下降了43.8%,栅格2 下降了57.6%,栅格3 下降了52.7%。
对于郊区,预测误差呈下降趋势。相较于非联邦学习栅格1,联邦学习下降了26.1%,栅格2 下降了28.7%,栅格3 下降了28.5%;相较于集中式学习栅格1 下降了49.8%,栅格2下降了49.1%,栅格3 下降了79.1%。
另外,对比3 个区域,市中心栅格流量的预测误差较大,其次是市区,郊区的误差最小,原因可能是市中心人流密度较大,导致流量密度较大,而郊区的流量密度小。
整体上,从非联邦学习、集中式学习到联邦学习,市区、市中心以及郊区栅格的RMSE 和MSE 呈下降趋势。通过R2可以看出,联邦学习的预测值与真实值相关性最强,经过联邦学习训练过的模型预测效果更好。原因是多栅格基站联邦学习,训练样本数据量增加,能够更准确地捕获各栅格共有的流量特性。其次,本节证明了3.3 节2)中所筛选得到的联盟的稳定性,通过结合合作博弈论,各个栅格的预测效果均有所提升。
由图12 进一步可以看出,3 个区域栅格流量的累积分布函数均呈正态分布。郊区曲线相较于其他曲线在最左端,则郊区栅格流量的预测误差均值最小,即预测误差最小;而市中心误差最大,市区居中。郊区曲线呈瘦高形状,表明它的栅格流量预测误差标准差最小,误差值相对集中;而市中心曲线呈矮胖形状,则它的栅格流量预测误差标准差最大,误差值相对分散。图12 进一步证明了针对不同区域栅格的联邦学习性能对比,性能由优到差依次为郊区、市区、市中心。
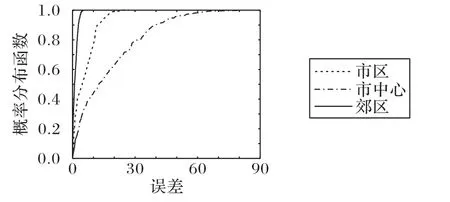
图12 不同区域累计误差对比Fig.12 Comparison of accumulative errors in different regions
4.4 不同业务类型联邦学习性能
针对不同业务类型的流量数据,联邦学习的预测性能存在差异性。对此,本文在3 个区域中分别随机选取栅格进行不同学习算法的训练,对比3 种业务流量的预测性能,验证联邦学习的性能差异性,如表4 所示。

表4 不同业务类型预测效果对比Tab.4 Comparison of prediction effect of different business types
从表4 可以看出,对于短消息流量,联邦学习下,市区、市中心和郊区的预测误差均为最小误差,其相关性最强。以RMSE 为例,与非联邦学习相比,市区下降了0.7%,市中心下降了4.7%,郊区下降了26.1%。与集中式学习相比,3 个区域的RMSE 也均有所下降。其中,市中心的RMSE 较大,原因可能是受到基站密度的影响。
对于语音流量,3 个区域经过联邦训练后的预测误差与相关性变化趋势与短消息业务量相同。其中,与非联邦学习相比,联邦学习市区的RMSE 下降了1.8%,市中心下降了8.1%,郊区下降了0.5%。与集中式学习相比,3 个区域的误差下降幅度更大。
对于上网流量,经过联邦训练后,与非联邦学习相比,联邦学习市区的RMSE 下降了51.6%,市中心下降了68.2%,郊区下降了35.1%。与集中式学习相比,市区、市中心以及郊区的预测误差均有不同程度的下降,分别是74.4%、9.6%和37.9%。市中心误差较大,原因可能是互联网流量较高。
可以看出,基于上网流量的模型预测误差较大,即分别基于短消息流量和语音流量的模型预测效果比上网流量的预测结果更好,原因可能是上网流量较大。
5 结语
本文提出了基于联邦学习的无线通信流量预测模型和基于合作博弈的联邦训练方法。前者的边缘服务器的栅格流量预测模型在中心云服务器协调下进行协同训练,训练结果优于栅格独立训练的结果;后者基于合作博弈对边缘服务器的栅格流量模型进行筛选,确保栅格间组成稳定联盟,提高了模型预测的精确性,解决了流量预测模型的复杂性和时效性问题。下一步工作将针对具体的流量预测模型进行改进,通过考虑天气、电力等外界因素对流量的影响或改变模型的结构来提高流量预测的精度,进一步实现城市全域流量的精准预测。
