概念漂移复杂数据流分类方法综述
2023-07-03穆栋梁刘淑娟高智慧
穆栋梁,韩 萌,李 昂,刘淑娟,高智慧
(北方民族大学 计算机科学与工程学院,银川 750021)
0 引言
在信息时代,数据不断高速产生且随时间的推移不断变化、增长,量是无限的,含有这些特征的数据被称为数据流,如网络数据、金融数据、传感数据和电网数据等。研究发现,在真实的数据流环境中,还存在着多种复杂数据流类型,如不平衡、多标签、概念演化和含噪声的数据流。随着时间的推移,流数据的数据分布发生了不可预见的变化,这些变化被认为是概念漂移[1]。概念漂移指目标类的底层分布的变化,具体地,概念漂移就是在一组有序实例到达后,之前的目标概念发生了改变。概念漂移使前后数据的分布发生变化,影响了数据流的稳定性,使得之前的分类模型不再适用于漂移后的数据,导致传统的机器学习模型在发生了概念漂移时分类性能显著下降。含有漂移特征的数据流,称为可变数据流或概念漂移数据流[1]。当概念漂移问题出现在复杂类型数据流中,这一问题就会随着底层数据的演变更加难以处理。例如:顾客的网上购物偏好,由于内部或外部原因,不常购买物品转变成了常购买物品;某地天气预报由于特殊原因出现了极端天气的情况;网络攻击检测中,首次出现新类型的攻击方式等。
目前多种数据流分类方法大多都仅处理复杂类型数据流的分类问题,没有考虑复杂数据流类型和概念漂移联合条件下的数据流分类问题。Wu 等[2]提出基于不平衡数据集重采样的集成学习模型。Tao 等[3]提出基于自适应代价权重的支持向量机代价敏感集成方法用于不平衡数据流分类。Nguyen 等[4]介绍了一种可扩展的基于在线可变推理的多标签数据分类集成方法,其中使用随机投影创建集成系统。Xia 等[5]利用标签相关性和集成成员的权值学习过程解决分类器选择的问题,并处理成对标签相关性与多标签分类性能之间的关系。以上方法是高效的数据流分类方法,然而这些方法的分类器在概念漂移复杂数据流中受到概念漂移的干扰,从而出现类不平衡、标签转换、新类出现以及噪声干扰的问题,使得性能严重下降,因此这些方法并不适应于概念漂移复杂数据流分类。
在现有的数据流分类综述中,杜诗语等[6]对突变、渐变、重复和增量四种类型的漂移数据流的分类方法进行综述,主要从集成学习的策略角度进行了分析;Hu 等[7]仅从概念漂移的类型方面进行了综述,对漂移检测方法进行了分类,没有将漂移处理方法与集成方法联合进行阐述;Zhang 等[8]对不平衡数据流、非标准数据流等复杂数据流集成分类进行了综述,但未对含概念漂移的复杂数据流分类进行介绍。以上研究没有专门从概念漂移复杂数据流分类的角度展开阐述。本文根据不同的数据流特征,在包含概念漂移的情况下,将其划分为4 类最常见的类型:不平衡概念漂移数据流、概念演化概念漂移数据流、多标签概念漂移数据流和含噪声概念漂移数据流,并对相应的分类方法进行了分类。本文框架如图1 所示。

图1 本文框架Fig.1 Framework of this paper
本文的主要工作有:
1)对不平衡概念漂移、概念演化概念漂移、多标签概念漂移和含噪声概念漂移这4 个方面数据流分类方法进行介绍,并从学习方式的角度对分类方法进行了分析总结。
2)从基于块和基于在线学习方式的角度对不平衡概念漂移数据流分类算法进行分析;从基于聚类和基于模型学习方式的角度对概念演化概念漂移数据流分类算法进行分析;从基于问题转换和算法适应的角度对多标签漂移数据流分类算法进行分析,对使用同一数据集的算法,在实验结果方面进行了详细的分析对比。
3)对目前存在于概念漂移复杂数据流中所面临的挑战,如在复杂数据流类型中的概念漂移类型检测及方法、多类不平衡概念漂移数据流的分类问题和在特征演化数据流中的新颖类检测问题,进行了总结并提出下一步研究方向。
1 不平衡概念漂移数据流分类
在数据流环境下,数据流样本中存在类失衡情况,出现了多数类和少数类的区别,在此过程中同时受到概念漂移的影响,多数类和少数类之间发生转变,从而大幅降低了分类器的分类效果,需要动态化的学习框架以适应不稳定类概念的演化(概念漂移)是不平衡概念漂移数据流中面临的一个重要难题。基于块和基于在线的学习方式是数据流分类中有效的方法,在概念漂移和类不平衡同时存在的条件下,将现有处理不平衡概念漂移数据流方法从学习方式的角度进行划分。
1.1 基于块的学习方式
基于块的学习方式,实例以数据块的形式连续出现,数据块的大小通常相等,基于数据块完成对分类器的构造、评估和更新,基于块的方法是数据流分类常用的训练方式。
UCB(UnCorrelated Bagging)[9]是解决概念漂移和类失衡最早的算法之一,它基于一个Bagging 框架,通过重采样平衡数据集,基于平衡的数据集训练分类器,并根据基分类器的鉴别能力对其进行加权,被动克服概念漂移。Chen 等[10]提出了一种选择性递归算法SERA(SElectively Recursive Approach),通过引入马氏距离衡量少数类概念漂移的严重程度,增加少数类数据的采样权重来解决少数类漂移的问题,对发生概念漂移的少数类给予更多的关注,及时修正分类器。之后,Chen 等[11]又提出了一个递归集成算法REA(REcursive Approach),以动态加权的方式结合所有随时间建立的假设,对测试数据集进行预测,在时间上解决概念漂移。
基于旧实例和新的少数类是同一分布概率的实例选择策 略,Hoens 等[12]提出了HUWRS.IP(Heuristic Updatable Weighted Random Subspaces IP),从类不平衡中获得鲁棒性,使用海林格距离(式(1))作为概念漂移检测的加权测度,漂移检测的海林格权重计算为两个特征分布之间的少数类和多数类海林格距离的平均值(式(2))。
其中:P1和P2是概率测度;p(P1,P2)是P1和P2之间的距离系数;D1和D2是独立的概率分布集;f表示特征;n表示特征数;dH表示海林格距离。
为从批量可用的新数据中学习,且不必访问以前批量中的数据,Ditzler 等[13-14]基于Learn++学习框架提出了集成的增量学习法Learn++.CDS(incremental Learning for Concept Drift from Streaming imbalance data)和Learn++.NIE(incremental Learning for Nonstationary and Imbalanced Environments)。Learn++.CDS 使用合成少数类采样技术(Synthetic Minority class Over-sampling TEchnique,SMOTE)减小数据的不平衡比例,然后使用Learn++.NSE(incremental Learning for NonStationary Environments)在重新平衡的数据集中学习概念漂移。Learn++.NIE 使用加权召回或几何平均单个类的表现,对概念漂移进行有效的跟踪识别,提高少数类上的分类性能,避免多数类分类性能下降。
在DWSE(Dynamic Weighted Selective Ensemble)算法[15]中,对之前数据块中的少数样本进行重采样,并吸收之前数据块中的信息构建分类器,减少概念漂移的影响。DWSE 算法中定义了基分类器动态衰减因子计算方法,根据衰减情况选择子分类器进行消除,使算法更好地处理概念漂移问题。
基于学习机的方法为解决不平衡和概念漂移的联合问题提供了很好的思路,MOS-ELM(Meta-cognitive Online Sequential Extreme Learning Machine)[16]利用一种基于变化检测器的自适应窗口方法和基于OS-ELM(Online Sequential Extreme Learning Machine)的输出更新方程同时针对类不平衡和概念漂移,通过减小数据块大小提高处理概念漂移的能力。ESOS-ELM(Ensemble of Subset Online Sequential Extreme Learning Machine)[17]使用重采样方法进行类的平衡。根据基分类器在与当前训练数据验证数据集上的性能均值更新基分类器的投票权重解决概念漂移问题。利用独立仓库模块处理重复出现的概念漂移,维护一个加权极端学习机器池以保留旧的信息,采用基于阈值技术和假设检验主动检测突然和逐渐的概念漂移。
基于块的集成会消耗大量的内存,DUE(Dynamic Updated Ensemble)[18]采用基于块的增量动态更新集成方法解决内存消耗问题。DUE 使用了一个基于Bagging 的框架获得相对平衡的数据块,通过分量加权机制和分量更新机制对概念漂移作出快速反应,使用最新的实例周期性地更新先前的分类器以应对多种概念漂移。
ECISD(Ensemble Classifier for mining Imbalanced Streaming Data)[19]利用过采样技术平衡各类样本,并周期更新分类器权重以应对概念漂移在分类器的淘汰过程中考虑了各个分类器对集成分类的影响,从而达到提高分类效果的目的。CIDD-ADODNN(Class Imbalance with concept Drift Detection-ADadelta Optimizer-based Deep Neural Network)[20]采用自适应合成技术处理类不平衡数据,此外,应用自适应滑动窗口技术对应用流数据中的概念漂移进行识别,通过应用堆叠自动编码器进行概念漂移分类以增强估计措施。最后,利用ADODNN 算法进行分类。图2 展示了ADODNN 算法框架。
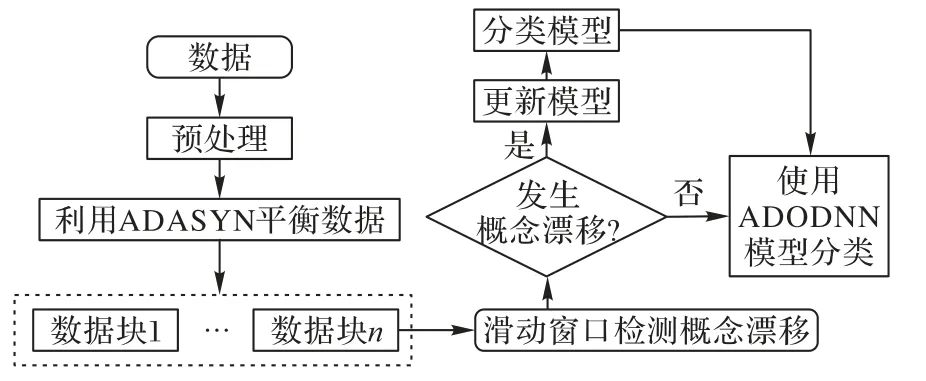
图2 ADODNN算法框架Fig.2 ADODNN algorithm framework
1.2 基于在线的学习方式
在线学习方法可以应用于数据以块形式到达的问题,在线学习中,实例不断从数据流中获得并且只能被处理一次,不需要再次存储和再处理。在数据连续到达的情况下,在线算法比典型的批处理算法运行更快、精度更高,因此在线技术被广泛地应用在数据流分类中。基于在线学习方式的代表 是Wang 等[21]提出的OOB(Oversampling-based Online Bagging)和UOB(Under-sampling-based Online Bagging)。
Somasundaram 等[22]提出了事务窗口打包(Transaction Window Bagging,TWB)模型,即并行增量学习集成。TWB 使用了一种增量学习模型,使用事务窗口在流事务数据上创建包,处理逐渐的概念漂移;采用贝叶斯基础学习器处理噪声和边界数据。HIDC(Handling Imbalanced Data with Concept drift)[23]利用差异因子估计多数类和少数类的分类精度之间的差异,对过采样和欠采样过程进行动态决策,解决了类分布不平衡的问题。通过对候选分类器的效率进行评估,从而替换集合分类器中最差的分类器成员,以此解决概念漂移问题。
梁斌等[24]结合重采样和自适应滑动窗口技术,提出了一种基于G 均值加权的不平衡数据流在线分类方法OGUEIL(Online G-mean Update Ensemble for Imbalance Learning),根据当前数据分布及时调整每个成员分类器的权重,解决不平衡数据流中的概念漂移问题。Sun 等[25]提出的TSCS(Two-Stage Cost-Sensitive)是一种两阶段代价敏感的数据流分类框架。在特征选择阶段,利用成本敏感主成分分析进行特征选择,提高算法的泛化能力,从而适应各种概念漂移;在分类阶段,建立代价敏感加权模型,将代价信息引入学习框架。TSCS 框架如图3所示。
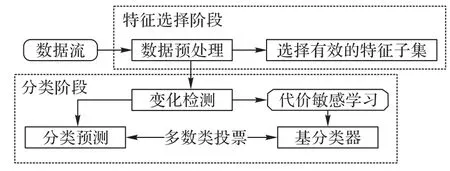
图3 TSCS框架Fig.3 TSCS framework
CSDS(Cost-Sensitive based Data Stream)[26]同样是基于代价敏感的算法。该算法在数据预处理过程中引入了成本信息,以解决数据级的类不平衡问题;在分类过程中,设计了一种对成本敏感的加权模式,以提高集成的整体性能。
2 概念演化的概念漂移数据流分类
在数据流的分类过程中,随着时间的推移出现了离群点和新颖类,这种情况被称为概念演化。新颖类的出现使原有的分类器分类效果降低,因此在数据流中对新颖类的检测并与原有已知类进行区分非常有必要。本章针对数据流受概念漂移影响的情况,从基于聚类和基于模型两种传统高效方法的角度对新颖类检测的分类算法进行介绍。图4 表示初始数据分布发生演变,最终出现了概念漂移、噪声和新颖类的情况。
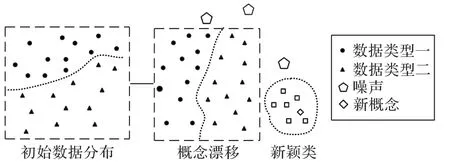
图4 初始数据分布演变Fig.4 Evolution of initial data distribution
2.1 基于聚类的学习算法
基于聚类的学习算法是一种新颖类别识别方法。基于聚类算法的主要思想是通过应用一些聚类算法表示正常或已知的概念(类),为学习模型创建决策边界以区分正常概念和异常值(可能是新的类实例)。
Spinosa 等[27]提出一种基于k-means 聚类方法的在线新颖性和漂移检测算法(OnLIne Novelty and Drift Detection Algorithm,OLINDDA),首次基于单一学习策略解决了数据流上的概念漂移和新颖类别探测问题。De Faria 等[28]提出了MINAS(MultIclass learning algorithm for Novelty detection in dAta Streams)技术,用于对多个类别进行分类。Masud 等[29]提出了数据流分类框架MineClass(Mining novel Classes),该框架基于集成分类技术,并用k-means 算法作为探测新颖类别的聚类算法,解决了数据流中包含多个已知类别的新颖类别探测问题。Masud 等[30]针对概念演变问题,提出了MCM(stands for MultiClass Miner)集成分类框架,利用离散基尼系数筛选过滤点。其中每个分类器配备了一个新的类检测器,以解决概念漂移和概念演化问题。
采用分类误差率检测重复出现的概念漂移是常用的方法。Zheng 等[31]采用了基于Jensen-Shannon 散度的分类器置信度变化检测技术,提出了一个带有重复概念漂移的半监督框架和一种新的类检测方法ESCR(sEmi-Supervised framework with recurring concept drift and novel Class detection),利用递归函数和动态规划策略,有选择地执行漂移检测模块;同时,通过监测有强内聚性的离群值,将概念演化考虑在内。
根据动态学习微观数据流的变化研究概念漂移和演化是非常高效的一种方法。Din 等[32]基于此提出了新的数据流分类方法EMC(Evolving Micro-Clusters)。EMC 动态地维护了一组在线微簇,通过演化微簇探索数据流分类中的概念漂移和演化,并且在线微簇对概念漂移和演化进行动态建模。基于衍生演化的微簇,从局部密度的角度直观地检测概念演化(即新的类识别)。由于微簇建模的不断发展,EMC分别提供了更好的概念漂移适应和新的类检测。
Mustafa 等[33]提出了一种结合深度学习、异常值检测和基于集成的分类技术的新类检测方法NovelDetectorDAE(Novel class Detector with Denoising AutoEncoder)。该方法将特征学习、去噪自编码与新类检测相结合,通过一个新的类检测器丰富集成中的每个分类器,如果所有的分类器都发现了一个新类,那么就声明一个新类的发现,并且潜在的新类实例被分离并分类为新类的成员。该方法使用一种非参数多维变化点检测方法检测概念漂移(数据特征值随时间的变化),并且使用无监督学习方法丰富传统的分类模型。
Haque 等[34]提出了 一个半 监督框 架SAND(Semisupervised Adaptive Novel class Detection),该框架使用变化检测技术检测概念漂移和块边界,通过检测具有强内聚性的离群值解决概念演化问题。为解决SAND 时间开销大的问题,基于SAND 利用动态规划有选择地执行变更检测模块。Haque 等[35]又提出了一种半监督分类框架ECHO(Efficient Concept drift and concept evolution Handling Over stream data),通过发现分类器置信度的任何显著变化检测概念漂移和动态确定块边界;此外,还使用置信度分数智能地从最新的块中选择有限数量的数据实例进行标记,然后使用这些数据实例更新分类器。
为了缓解概念漂移和概念演化对新类检测和分类的影响,Li 等[36]提出了基于马氏距离内聚性和分离指数的新类检测分类算法(Classification and Novel Class detection algorithm Based on Mahalanobis distance,C&NCBM)。该算法将数据流划分为大小相同的数据块,对数据块中的实例进行分类,确定是否为异常值,对异常值集合进行聚类,从而确定新类,通过随时维护当前最新概念的分类模型解决概念漂移问题。基于马氏距离的方法更注重实例之间的相似性,能敏感地检测离群点之间的微小变化,对于判断新颖类更具优势。
AnyNovel(An application for activity recognition,detection of Novel concepts in evolving data streams)[37]是一种基于类(如图5 所示)的集成方法,将训练数据分成不同的类,然后为每个类创建集群,在每个集群周围创建一个弹性间隙,以区分一个全新的概念和一个现有概念的扩展或漂移。AnyNovel应用持续学习方法监控流中的进化,从而检测正常和异常的概念的出现和消失;通过合并检测到的新概念或删除过时的概念动态调整学习模型,经过调整的学习模型能够识别新概念重复出现。

图5 基于类的集成分类器的训练和更新过程Fig.5 Training and updating process of class-based ensemble classifiers
2.2 基于模型的学习算法
与基于聚类的技术不同,基于模型的学习算法的目的是找到可以用于分类和检测新类的模型。
Masud 等[38]通过引入延迟数据标记和分类决策的时间约束提出了一种数据流分类技术ECSMiner(Enhanced Classifier for data Streams with novel class Miner)。该技术将一种新的类检测机制集成到传统的分类器中,使之能够在新类实例的真实标签到达之前自动检测新类,在分类时考虑了时间限制。Masud 等[39]根据循环类这一概念演化的特殊情况,提出了一个解决存在概念漂移的循环类问题的方法SCANR(Stream Classifier And Novel and Recurring class detector)。该方法用来作为概念漂移数据流的多类分类器,检测新的类,并区分重复类和新的类。
基于决策树模型是检测新颖类最常用到的方法之一。Farid 等[40]提出基于决策树分类器的技术NCDC(Novel Class Detection in Concept-drifting data stream),从概念漂移数据流中发现新颖类并进行分类,计算树中每个叶节点的数据点相对于训练数据集中总数据点的百分比,从而判断新类的出现。SENCForest(classification under Streaming Emerging New Class Forest)[41]是一种随机决策树集合的方法,它基于无监督异常检测器,在构建检测器后,使用称为路径长度的阈值将数据空间划分为正常和异常区域,根据实例位置确定新类。AhtNODE(Adaptive hoeffding tree based NOvel class DEtection)[42]使用自适应Hoeffding 树(Adaptive Hoeffding Tree,AHT)分类器检测概念漂移和数据流中存在概念漂移时的新类,用规划的方法求解无限长度、概念漂移和概念演化问题。
Gao 等[43]提出了一个半监督流分类框架SACCOS(Semisupervised Adaptive ClassifiCation Over data Stream),使用基于相互图模型的聚类技术解决概念漂移和概念演化的问题。Bouguelia 等[44]提出的GNG(Growing Neural Gas algorithm)是一种基于图模型的算法,以实例作为节点进行图拓扑,边作为不同节点之间的连接构建图。当新数据到达时,通过创建新节点和节点之间的连接定期更新此图。GNG 在静态环境中学习数据的拓扑结构如图6 所示,GNG 通过遗忘机制以自适应的方式消除独立无关的神经元处理概念漂移数据,根据引入的局部变量公式(3)计算神经元相关性。
其中:Cn是局部变量,每个神经元用n表示,x表示实例,t是当前的时间步长(即流中的第t个实例),n*和n**表示最近的两个神经元。1(Cond)是条件Cond的0-1 指示器功能。
3 多标签概念漂移数据流分类
多标签数据流是随着时间的推移到达多标签分类器的多标签实例的序列,在多标签数据流中数据的底层分布可能还会随着时间而改变,即概念漂移。因为多标签数据流中的每个实例含有多个标签,所以处理概念漂移会更加有难度。问题转换方法和算法适应方法是处理多标签问题的有效途径,本章将结合概念漂移问题的处理对相关算法进行介绍。
3.1 基于问题转换方法
问题转换方法是处理多标签数据的经典方法,该方法的主要思想就是将多标签的分类问题转化成一个或多个单标签的分类或回归问题,即将每个标签视为一个独立的二元问题。
Qu 等[45]提出了一种加权投票集成算法DCEBR(Dynamic Classifier Ensemble with Binary Relevance-based algorithm),将数据流划分为连续的数据块,使用二进制关联方法将每个数据块转换为一组单标签数据块,对每个单独数据块构建分类器;通过在最新模块上建立模型取代实例中最老的模型从而处理概念漂移;使用堆叠二进制相关性从每个块中学习,利用类标签之间的依赖信息;通过改进的BR(Binary Relevance-based)分类器进行动态分类集成,实现概念漂移的多标签分类。MINAS-BR(MultIlabel learNing Algorithm for data Streams with Binary Relevance transformation)[46]同样利用二元关联问题变换策略为每个类建立一个决策模型,使用新颖性检测程序检测概念演化和概念漂移,以无监督的方式更新。MINAS-PS(MINAS-Pruned Sets)[47]应用了新的剪枝方法,该算法可以在没有样本真实标签和任何外部反馈的情况下更新模型。在训练阶段,使用基于PS 的策略对多标签数据进行转换,然后利用标签集对样本进行分离,利用聚类算法对微簇进行聚类,并建立决策模型。在分类阶段,使用决策模型分类新的例子或标记为未知。为更新决策模型,在未知的例子中应用了聚类算法,能够适应不同类型的概念漂移。
Spyromitros-Xioufis 等[48]提出了一种多窗口方法处理多标签数据流方法MW(Multiple Windows),MW 为每个标签设置了基于正面实例和负面实例双窗口,从而处理每个标签正负样本分布中的概念漂移和偏斜的类分布。另外,该方法使用KNN(KNearest Neighbors)作为基分类器,使用批量增量阈值技术进一步解决类不平衡问题,使用BR 进行独立建模,从而有效地处理标签之间频率和概念漂移的预期差异。
Wang 等[49]提出了一种基于集成的主动学习框架(Ensemble-based Active Learning Framework,EALF)处理数据量巨大、标签成本高以及多标签数据流中的概念漂移问题。采用主动学习方法降低多标签流上的标签成本,应用最大后验权模式不断更新集合模型的权值和在多标签数据流上增加加权模式处理概念漂移问题。
标签对之间的相关性以及标签和特征之间的关系是多标签数据流分类中的重要问题。Nguyen 等[50]提出了BBML(Bayesian-Based Method for Learning from multi-label data streams),将更多注意力放在了新样本上以适应概念漂 移 。MLAW(Multi-Label ensemble with Adaptive Window)[51]采用了周期性加权机制应对概念的逐渐漂移,选择Jensen-Shannon 散度作为度量两个连续窗口之间分布的指标,通过维护一个分类器池处理循环概念漂移问题。通过删除一些不常见的标签组合考虑标签依赖,更高效地处理多标签数据,提高分类器的性能。
3.2 基于算法适应方法
算法适应方法就是通过扩展特定的学习算法来直接处理多标 签数据。如ML-KNN(Multi-Label lazy learning approach withKNearest Neighbors)[52]适应性懒惰学习方法就是一个经典算法适应方法。
分类器必须能够处理大量的示例,并在任何时候进行预测的同时,使用有限的时间和内存适应变化。Read 等[53]提出了一种基于多标签剪枝集分类器的Hoeffding 树分类方法。这种方法继承了增量决策树的高性能,以及高效的多标签方法的预测能力。该方法实时学习和预测,并在每个示例中更新模型——在检测到漂移时重新启动模型。
Roseberry 等[54]提出了一种用于漂移数据流的多标签分类器 MLSAMkNN(Multi-Label kNN with Self Adjusting Memory),使用自调整存储器来处理漂移数据流,并将这种存储结构与简单的多标签KNN 分类器相结合,用于处理混合概念漂移的多标签数据流。随后,Roseberry 等[55]又提出MLSAMPkNN(Multi-Label Punitive kNN with Self-Adjusting Memory),在自调整内存中只包含当前的概念,惩罚系统会从窗口中删除错误示例,MLSAMPkNN 使用多数投票KNN,作用于最新数据示例的一个小窗口,该窗口根据数据流中的概念漂移进行自我调整。一个健壮有效的算法必须不断适应新的数据分布,AESAKNNS(Adaptive Ensemble of Self-Adjusting Nearest Neighbor Subspaces)[56]利用自调整KNN 作为基分类器,每个基分类器被赋予一个独特的特征子集和样本进行训练,利用漂移探测器的集合监测子空间上的概念漂移,在新的可变大小特征子空间上建立一个背景集合。
4 含噪声概念漂移数据流分类
数据污染是一个严重的问题,因为噪声会严重损害学习的质量和速度。在许多源数据可能不可靠的应用程序中都会遇到这个问题,并且在数据传输过程中也可能注入错误。对于数据流,这个问题更具有挑战性,因为在数据流中很难区分噪声和概念漂移引起的数据。如果一种算法过于急于适应概念的变化,它可能就会过拟合噪声。
袁泉等[57]提出了一种新型的增量式学习的数据流集成分类算法(Ensemble Classification Algorithm for data streams with Noise and Concept Drifts,ECANCD)。引入噪声过滤机制过滤噪声,引入假设检验方法对概念漂移进行检测。Myint 等[58]提出了一种基于自适应窗口的精度更新集成方法A-AUE2(AccurAcy Updated Ensemble-2),采用基于KNN 的噪声滤波方法去除每个自适应窗口中的噪声样本。
Luo 等[59]提出了基于块动态加权的方法GBDT(Gradient Boosting Decision Tree framework)处理含噪声的漂移数据流。在分类过程中去除不能适应当前概念分布的弱分类器,创建新的弱分类器以应对发生的概念漂移。将逐块处理样本的块动态加权多数模块与在线梯度推进决策树框架相结合,以应对含有噪声的漂移数据流,并开发了一个稳健的损失函数,避免了噪声样本的过拟合。SPL(Selective Prototypebased Learning)[60]通过动态选择最重要的实例捕捉当前的概念。SPL 进一步检查存储的错误分类的实例,从而检测突然的概念漂移。由于SPL 可以检测所有错误分类的例子,因此可以有效地识别代表新概念的例子,并通过错误驱动的代表性学习进一步去除噪声。
Li 等[61]提出了一种基于集成决策树的概念漂移(Ensemble Decision Trees for Concept-drifting,EDTC)数据流增量算法,引入3 种随机特征选择变量实现分裂测试,并利用Hoeffding 边界不等式区分概念漂移和噪声数据,有效提高了分类器的性能。Krawczyk 等[62]提出了一种新的在线集成动态轻量级的方法,通过弃权修改提高在线集成系统对噪声的鲁棒性,为每个实例有效地选择最不可能受到噪声分布影响的分类器,这允许利用基础学习器的潜在多样性,并大幅减小了漂移恢复期间的误差。
5 算法分析对比及性能总结
本章对不平衡和概念演化概念漂移数据流的分类方法性能进行分析,介绍了所使用的相同数据集,并在使用同一数据集的情况下对实验结果进行了详细的对比分析。对多标签和含噪声概念漂移数据流的分类方法进行了性能总结。
5.1 不平衡概念漂移数据流分类方法对比
从基于块和基于在线的学习方式对不平衡概念漂移数据流的处理方法进行了介绍。将根据在相同条件下进行实验的算法进行对比,进行算法性能小结。对所使用相同数据集进行了介绍,表1 是在相同数据集下进行实验的算法,表2是对所用算法在所用技术、数据集、对比算法和优缺点方面的总结。

表1 使用相同数据集的不平衡分类算法Tab.1 Unbalanced classification algorithms using same dataset

表2 不平衡概念漂移数据流分类方法Tab.2 Classification methods for imbalanced concept drift data streams
5.1.1 数据集介绍
HyperPlane 数据集 漂移超平面问题是由Sea 数据集引入的,数据集的特点是周期延长,类边界偶尔会出现急剧变化,即突然漂移或概念变化。数据集包括2 个类和3 个特征,其中只有2 个是相关的,第3 个是噪声。该数据集生成器有10 个属性,通过连续旋转决策超平面产生漂移。
Sea 数据集 该数据集是经典的突变式概念漂移数据集,基本结构是a,b,c,C,其中a、b和c是条件属性,C是类属性。a、b和C有关,a和b两个特征的总和是否超过了定义的阈值决定了类标签,c可被视为噪声用于测试算法的鲁棒性。概念漂移被设计成周期性调整阈值。
Electricity 数据集 该数据集是真实数据集,收集了澳大利亚新南威尔士州电力市场的45 312 个电价数据,该数据集包含8 个属性和2 个类别。
5.1.2 算法性能对比小结
1)HeperPlane数据集中算法性能对比小结。
相较于SERA 和UCB,Learn++.CDS 在ROC(Receiver Operating Characteristic)曲线中平均值高,平均在0.95,Learn++.CDS受到漂移影响最小。在AUC(Area Under Curve)中Learn++.NIE 的值最高。Learn++.CDS 的F-measure 值最高。召回率(Recall)曲线上表现最好的分别是UCB 和Learn++.NIE。UCB在召回率上也表现出较好的性能,但这种好的召回率是以非常差的ROC 为代价的。在比较运行速度时,UCB 是最快的。DUE 的AUC 值随着块大小的增加而增加,在不平衡比率为3∶17 时AUC 值达到最高为0.85;与UCB、CDS、OOB 和UOB 等算法相比,Accuracy、F-measure、G-mean、Recall、AUC 值分别达到0.92、0.50、0.80、0.75 和0.84,均为第一名。TSCS的G-maen值为0.84、F-measure值为0.22、运行时间为156.41 s(此时NIE 对应的值分别为0.89、0.35、51.23),TSCS 优于对比算法,并在常用的度量指标评估中获得了较好性能,特别是在类别不平衡环境下的演化数据流。CSDS 的G-mean 值为0.97,运行时间为18.10 s,在时间复杂度方面略高,但总体性能方面较好,CSDS 在大多数情况下能够较好地兼顾G-mean 和运行时间,且比AUE2 等集成方法更能适应漂移。OGUEIL 在不同参数P(基分类器更新周期)下对G-mean 性能进行了实验,在P=500 时G-mean 值最高为0.87。Accuracy 为0.92、Recall 值为0.81,ROC 值分别为0.80、0.61和0.46。
2)Sea数据集上算法性能对比小结。
对于UCB、SERA、CDS、NIE 这4 个算法,在ROC 和F-measure 中CDS 平均表现最好,在AUC 和Recall 中NIE 平均表现最 好。DWSE 的Accuracy、AUC、F-measure、G-mean、Recall 平均值分别为0.90、0.88、0.48、0.80、0.75,整体性能最 好。MOS-ELM 的G-mean 值为0.84(NIE 和ESOS-ELM 的G-mean 值分别为0.82、0.84)。DUE 在与UB、SERA、CDS、OOB、UOB 的对比 实验中,DUE 的Precision、F-measure、G-mean、Recall、AUC 值均为最高,分别为0.48、0.60、0.85、0.82、0.88。ECISD 的平均G-mean 值为0.82,NIE 为0.84。TSCS 在与NIE 的对比实验中,TSCS 的G-mean、F-measure、运行时间分别为0.79 s、0.26 s、67.45 s,NIE 分别为0.64、0.02、55.47。CSDS 在实验 中G-mean 值达到 了0.88、运行时 间10.60 s 为最短。OGUEIL 在 与OOB、REA 的对比 实验中,Accuracy、G-mean、Recall 分别平均为0.94、0.89、0.84,OOB分别为0.90、0.86、0.82,REA 分别为0.72、0.82、0.84,相较于实验中对比算法取得了最佳性能。
3)Electricity数据集中算法性能对比小结。
在NIE、CDS、SERA、UCB的对比实验中,CDS在ROC达到了最高值为0.88,NIE 在F-measure 和AUC 中达到了最高,分别为0.21、0.70,UCB 在Recall 达到了最高,UCB 在召回率上表现出较好的性能但是以非常差的ROC 为代价的。在NIE、ESOS-ELM 和MOS-ELM 的对比 实验中,G-mean 值分别 为0.58、0.62、0.63。在DUE与UCB、SERA、CDS的对比实验中,DUE 的F-measure、G-mean 和AUC 值均为最高,分别为0.54、0.75 和0.88,UCB 在Accuracy 和Precision 取得了最高值分别为0.92 和0.64,CDS 在Recall 取得了最高值0.63。TSCS 与NIE 对比,TCSC 的G-mean 值为0.76、F-measure 值为0.07、运行时间为35.02 s,NIE 分别为0.80、0.10 和25.33。CSDS 在其实验中,CSDS 的G-mean 值为0.73、运行时间为31.63 s。OGUEIL 与OOB 和REA 的对比实验中,Accuracy、G-mean 和Recall 值分别为0.91、0.91 和0.91,OOB 的值分别为0.77、0.76和0.71,ROC的值分别为0.73、0.65和0.45。
5.2 概念演化概念漂移数据流分类方法的对比
从基于聚类和基于模型的学习方法的角度对概念演化概念漂移数据流的处理方法进行了介绍。为进一步探讨各种方法的性能,本节对使用相同数据集且实验环境相同条件下的算法进行了对比分析,对使用相同数据集进行了介绍,表3 是使用相同数据集的算法,表4 对所用算法的详细分析汇总。

表3 使用相同数据集的概念演化分类算法Tab.3 Conceptual evolution classification algorithms using same dataset

表4 概念演化和多标签概念漂移数据流分类方法Tab.4 Classification methods for concept evolution and multi-label concept drift data streams
5.2.1 数据集介绍
KddCup 包含麻省理工学院林肯实验室两周的局域网流量中提取的TCP连接记录,每条记录指向正常连接或攻击。有22 种类型的攻击,在该数据集里不同的类频繁出现和消失。
Pamap UCI 数据集。在这组数据中,有9 个人配备了传感器,当他们执行活动时,这些传感器收集了52 个流数据。
Forest Cover 植被覆盖类型数据集,所有观测均为30 m×30 m 森林区域采样。样本总数581 012,每个样本有54个特征,且有7 种类型。
5.2.2 算法性能对比小结
1)KddCup 数据集上算法对比分析。
MINAS 比OLINDDA 具有更高的新颖类识别率,且获得更低的时间消耗。对比W-OP(WCE-OLINDDA PARALLEL)和W-OS(WCE-OLINDDA SINGLE),MineClass 以决策树为基分类器获得了最低的误分类(ERR)值为1.7,而W-OP 和W-OS 分别为11.6 和8.7,在KddCup 数据集上运行速度比W-OP 快2 095 倍,比W-OS 快246 倍。ECSMiner 以决策树为基分类器的最低ERR 值为1.0,在运行速度上ECSMiner 比W-OP快26.9倍。EMC与ECSMiner、SENCForest、MINAS相比获得了最低的ERR 值为0.53,SENCForest 整体错误率最高。C&NCBM 在整个数据流分类过程中与MineClass 和KNN 两种算法对比,C&NCBM 的准确性非常稳定,显著高于其他两种,C&NCBM 算法的运行时间明显长于其他两种算法,C&NCBM比MineClass 具有更高的准确性,但它也需要更多的评估时间。SCANR 与OLINDDA-WCE、ECSMiner 相比获得最低的ERR 值为0.107,此时OLINDDA-WCE、ECSMiner 的ERR 值分别为0.307 和0.130。NCDC 与传统的决策树分类器和KNN分类器进行对比,在ERR值方面分别下降了1.3和2.3。在新的类检测方面,SENCForest 与表3 所提对比算法相比产生了最高的F-measure,Accuracy 方面SENCForest 性能最高,SENCForest 作为分类器具有较强竞争优势。AhtNODE 与W-OP 和W-OS 进行了错误率的对比分析,AhtNODE 的ERR、F_new(已存在类实例最终确定为新类的百分比)、M_new(错误分类为现有类的新类实例的百分比)值分别为7.2、11 和5.3,此时W-OP 的值分别为11.6、26.7 和7.5,W-OS 的值分别为8.7、99.4 和0。由此可见,AhtNODE 的整体性能最好。SACCOS拥有较高的检测精度,但也有较高的开销。
2)Forest Cover数据集上算法对比分析。
相较于W-OP 和W-OS,MineClass 的ERR 值均为最低为5.4,W-OP 和W-OS分别为19.2和8.9。在ECSMiner与W-OP和W-OS 对比中,ECSMiner 的ERR 值最低为3.6,W-OP 和W-OS 分别为7.9 和8.5,此时W-OS 有最低的F_new 值。MCM 与MineClass 相比,ERR、M_new、F_new 和AUC 值分别为3.1、4.0、0.68 和0.99,MineClass 的值分别为3.6、8.4、1.30和0.97,MCM 具有更好的性能,此时MCM 具有更少的时间消耗为0.9 s。ESCR 与SAND 和ECSMiner 相比,置信阈值τ 为0.9时ERR 最低为0.04。ECSR还具有检测重复漂移的能力,在误报的性能方面表现最好。DAE 与ECSMiner 和ECHO 相比,ERR 值为最低为0.02,ECSMiner 和ECHO 分别为0.05 和0.03。SAND 在分类结果和使用有限数量的标记数据进行分类结果中,都展示出了比ECSMiner 更低的错误率。在新类探测的结果中ECSMiner具有比SAND更低的M_new值。
3)Pamap数据集中算法对比分析。
EMC 与其他8 种数据流分类算法(AWE、OAUE、DWM、LNSE、AHT、OBA、NBDM、HOT)在18个数据集上的误分类错误性能对比,除在Sea和HyperPlane数据集上均展示了最好的效果,与ECSMiner、SENForest、SENCForest和MINAS算法对比具有最低的ERR值。DAE与ECSMiner和ECHO相比具有最低的ERR 值 为2.46,此 时,ECSMiner 和ECHO 分别为17.38 和2.37。SAND 在Pamap 数据集 中,虽 然M_new 值不如ECSMiner,但通过使用有限数量的标记数据和有选择地执行变更检测,SAND还可以在不牺牲准确性的情况下节省时间和资源。ECHO与ECSMiner、AHT和OBA相比,在使用有限数量的标记数据进行分类性能的性能比较和整体分类效果中都获得了最好的效果。对于Pamap 数据集,ECHO-D 的所有M_new、F_new和F-Score(α=2)性能都优于ECSMiner。在SACCOS与其对比算法实验中,SACCOS具有最好的分类性能,要求较少的标签同时解决了概念漂移检测和新出现的类检测问题。
5.3 多标签概念漂移数据流分类方法总结
本节对基于问题转换和算法扩展的算法进行分析总结,其中问题转换方法就是将多标签分类问题转换成单一标签问题进行处理;算法适应方法是扩展特定的学习算法直接处理多标签数据。表4是对相应算法特点的总结。DCEBR算法在大数据块的情况下汉明损失更小,且具有很强的利用不同标签之间相关性的能力。EALF更好地解决了概念漂移问题、过拟合问题、标签不平衡问题和标签成本问题,独立更新每个类的集合可以为每个标签保留最佳分类器。MW 提出的阈值技术能够有效地调整决策阈值,在AUC 值上优于对比方法;但这种方法与主动学习方法不兼容。MLAW 在预测性能的大多数度量下优于所有其他对比算法,该算法能够根据概念的变化及时检测到概念漂移,并及时构建分类器,实现对这类概念漂移的快速处理。MINAS-BR 在所有数据集上都优于下界方法,并且在某些情况下优于上界方法,在更新时不需要示例的真正标签,也不需要任何外部反馈。MINAS-PS离线阶段的剪枝过程有时会丢失重要的信息,在F-measure、Accuracy 方面优于基准方法。BBML 通过以样本的时间为中心的衰减机制处理概念漂移,对于处理缺失值也有良好的效果,在分类精确度等性能上优于基准方法,但运行时间开销较大,时间复杂度在相当大程度上依赖于数据的维度。
MLSAMkNN 在测试的23 个数据集上获得了最佳的子集精度和F-measure 值,并在准确度和召回率方面同样表现良好。MLSAMPkNN 是适用于各种学习场景(包括概念漂移、不平衡数据和噪声)的通用分类器,它是一种易于使用的现成分类器,因为不需要任何繁琐的模型选择和参数调优。AESAKNNS在12项实验指标中,有9项达到最佳性能,对概念漂移具有高度适应性,并克服了其他各种多标签数据困难,是一个全面的分类器。
5.4 含噪声概念漂移数据流分类方法总结
本节对处理含噪声的概念漂移数据流分类方法进行了性能分析汇总,表5 是对相关算法的汇总。

表5 含噪声概念漂移数据流分类方法Tab.5 Classification methods for data streams with noisy concept drift
ECANCD 与其对比算法相比,以C4.5 作为基分类器在真实动态数据中的分类时间、分类精度、Kappa 统计量、均方根误差和相对均方根误差均比支持向量机分类器优越。A-AUE2 在每个窗口上使用了噪声滤波方法(KNN)和自适应加窗方法(BSS)。在F1(即F-Measure)、Precision、Recall、MCC(Matthews Correlation Coefficient)和AUC 这5 个预测指标上进行了验证,在与8 种最先进的概念漂移检测和处理方法对比中,A-AUE2 在两种基础学习器中都表现出色。GBDT 能够在有噪声的数据流中准确地识别出真实模式,在6 种在线集成学习方法的15 个实验中,GBDT 表现最好,在15 个实验中有12 个实验排名第一。结果表明,与其他在线集成学习方法相比,GBDT 对噪声的敏感性较低,在训练集包含噪声时具有较好的鲁棒性。SPL 使用自适应窗口来关注最近的数据,因此比传统的单模型算法要慢。与其他基于实例的算法相比,SPL 显示了它的优势,它只需要动态地维护一小组实例。DyAbst 能够提高在线集成对数据流中噪声的鲁棒性,引入了一个动态的、自适应的阈值,它能够通过监控集合的输出来适应数据流中的变化,有效地预测漂移。
6 下一步工作
虽然目前已经提出了许多算法处理相应的概念漂移复杂数据流,但现有的算法仍存在一些问题,限制了它们在许多实际应用中的适用性。许多问题仍然是有待解决的研究问题,下面将探讨现有困难和挑战,并提出下一步研究方向。
1)复杂数据流中的概念漂移检测。
概念漂移的检测在复杂类型数据流中是一个急切需要解决的难题。在数据流中,分类器性能除受概念漂移问题影响外,还受数据复杂性的影响,如类不平衡、多标签、噪声等,这些问题导致现有漂移检测器在检测精度和时空复杂度上面临巨大的挑战。我们下一步拟提出一个基于半监督的多尺度窗口漂移检测器,大尺度窗口用来进行数据与标记样本的对比检测,小窗口用于检测概念漂移。将该检测器应用在概念漂移复杂数据流中,旨在更精确检测概念漂移的同时能识别漂移类型。
2)含概念漂移的多类不平衡数据流分类。
截至目前,相当多的研究仅处理二类不平衡数据流的情况,但二类问题的解决方案不能直接适用于多类问题。在多类不平衡数据流的情况下,处理概念漂移问题就不得不考虑多个类概念的变化。分类器精确度受多类和概念漂移的影响较大,我们将提出新的动态集成方法检测多类不平衡数据流中多种类型的概念漂移,并加以处理,以此提高分类精确度。
3)多标签中类不平衡数据流分类。
在多标签数据流分类中,类不平衡问题仍然是一个具有挑战性和重要性的问题。有些标签有更多的少数实例,而有些标签具有更多的多数实例。现有的研究只考虑了不平衡类中最简单的条件,并假设不平衡比例随着时间的推移是静态的;但在现实世界中并非如此,研究多标签中少数类的变化有助于提高分类性能。未来将采用半监督增量的方法结合采样方法来解决这一问题。
4)在特征演化数据流中的新类探测。
目前大多数的算法都使用固定的特征集,只有少数的算法考虑了特征演化的问题。然而,现实世界中,数据流是动态的,因此数据的特征也会随着时间进行演化,新的特征可能会增强,旧的特征可能会消失,特征演化可能会导致不相关的分类器预测未来的实例时性能下降。在多个特征的空间中,一些关键特征可能丢失,同样会导致分类器性能下降。因此,如何在特征演化的数据流中检测出新出现的模式并加以处理也是一个重要的问题。
7 结语
本文首次从不平衡概念漂移数据流、概念演化概念漂移数据流、多标签概念漂移数据流和含噪声漂移数据流这4 个方面对概念漂移复杂数据流分类方法进行了介绍。从不同学习方式的角度对算法进行了分析,对不平衡概念漂移数据流和概念演化概念漂移数据流的分类方法进行了详细的实验结果对比,对多标签概念漂移数据流和含噪声概念漂移数据流的分类方法进行了性能总结,并对所用方法的技术、数据集、对比算法,以及优缺点方面进行了列表汇总。
最后,针对目前现实世界中复杂数据流所面临的挑战和问题,对复杂数据流的漂移检测、多类不平衡概念漂移数据流分类、多标签数据流中类不平衡,以及特征演化数据流中的新类探测等问题进行了总结,并且提出下一步的研究方向。
