我国房地产行业信用风险预测的实证研究
2023-06-30许婉,刘胜题
许婉,刘胜题

[摘要]为促进房地产行业平稳发展,本文以上市房地产企业数据为背景,融合ADASYN技术及Stacking算法构建性能表现优异、数据集适应度强的预测模型,旨在测度相关信用风险,为我国防范化解房地产重大金融风险尽绵薄之力。创新之处在于:一是从宏观角度引入与房地产业息息相关的经济增长风险(GDP同比-预期GDP同比)、利率风险(10年期国债收益率)、通胀风险(0.3*PPI+0.7*CPI)等指标;二是基于融合模型思想构建预测模型,从实践层面为解决传统信用风险预测模型单一问题提供新思路。实证结果表明:1、Stacking-BPNN均超越单一模型取得性能指标最优结果;2、结果依然存在较高风险值的原因在于房地产相关人口及购买力存在动力不足现象与企业自身“亚健康”现象,风险企业主要集中于财务风险型房企、战略错位型房企以及缺乏竞争力型房企。
[关键词] 房地产信用风险;Stacking融合算法;自适应综合过采样
[中图分类号] F293.3 [文献标识码]A [文章编号]1000-4211(2023)03-0050-18
一、引 言
2022年6月,自社交媒体曝光业主的《强制停贷告知书》后,全国多个省份200多个问题房地产项目的购房者加入集体停止还贷的行列。停贷事件是涉险房企原有项目风险的集中释放,其中以爆雷房企项目为主,相关涉及数量占比约58%。随后,国家金融与发展实验室在官网发布的2022年第二季度房地产金融研究报告显示称,房企爆雷势头未得到彻底遏制,购房者集体停贷事件是房企违约、停工等问题进一步发酵、扩散的结果。受“断供潮”影响,即使在中报业绩的加持下,银行板块在7月仍然持续走弱,整体42家上市银行全线飘绿,无一上涨。整个逻辑链条在于,房价负面波动引起违约增加,银行不可避免会蒙受巨额损失,体现了信用风险的传递效应。
据克而瑞地产研究中心数据显示,截至2022年11月末,百强房企累计实现销售金额57847.2亿元,相比去年同期减少了42.6%。数据及“停贷”风波事件说明房企存在早期激进拿地且高债务杠杆经营特征、居民个体购房信心整体偏悲观导致销售下滑引起的资金链断裂风险。
在融资受阻、销售疲软、偿债压力较大的环境下,具备慢回款特征的房企难以实现资金的快速回笼,内生现金流仍然紧张且未出现明显改善,债务危机持续蔓延。部分房企抗风险能力较弱,大而不倒信仰崩塌,开启危机爆发的前奏。根据人民法院公告网显示,2022年已有395家房地产相关企业相继申请破产或清算,其中多为二、三线城市的中小型房地产开发企业。但知名上市房企也难逃厄运,如龙头房企恒大于2021年9月正式宣告爆雷;融创于2022年3月美元债展期宣告爆雷;世茂于2022年3月公告60亿信托展期宣告爆雷;阳光城于2021年公司理财未兑付宣告爆雷,等等。房地产行业的现状说明其面临信用风险潜在危机的暴露及扩大化,风险的不确定性正在逐步上升。
经过2018年出台的资管新规导致前融受限、2020年的“三道红线”导致信贷受限、2021年下半年的预售资金监管收紧等多项政策的共同作用,房地产行业引来信用紧缩,爆雷现象频发,冲击了需求端的信心。因此2022年末,中央经济工作会议定调2023年房地产工作主旋律仍是“确保房地产市场平稳发展,扎实做好保交楼、保民生、保稳定各项工作”,从实际行动上保持房地产融资平稳有序、全力维护房地产市场稳健运行。
与信用深度绑定的房地产行业既是国民经济的支柱性产业,又是资金密集型行业。若其遭受重大损失,资产价格泡沫通过信贷渠道传递至金融机构,造成信贷资产质量下降,发生大概率违约事件,导致金融机构破产从而引发金融危机。房地产信用风险不仅会向金融部门传递,甚至会蔓延至公共部门,致使经济中的流动性与活跃度均大幅下降。严重的话会引起其他行业资金链断裂乃至破产,总需求下降,国民经济陷入衰退。由此可见,房地产信用危机对国家经济安全及金融稳定构成威胁。
随着房地产企业规模数量的扩大及其关联链条的复杂性,使得信用风险日趋复杂,加大了度量的困难程度。因此,如何有效识别和测度房地产信用风险成为风险控制的关键问题。基于上述背景,本文以上市房地产企业数据为背景融合机器学习模型反映测度我国房地产信用风险,进一步拓展风险量化思路,为我国防范化解房地产重大金融风险尽绵薄之力。
二、文献综述
房地产信用风险预测模型本质上隶属二分类模型,其构建流程核心点如下:一是非平衡数据集问题。鉴于房地产信用数据集中违约样本数量远大于非违约样本数量,存在类别不平衡现象。大多数分类算法在面对非平衡数据时往往倾向于拟合非违约样本,从而导致预测模型对关键的违约样本识别不足,现实应用性较差。基于上述问题,Chawla N. V.、Bowyer K. W.等(2002)发现对少数类进行SMOTE(Synthetic Minority Over-sampling Technique)过采样可以提升分类器性能。由于该方法常忽略临近样本的分布特征,从而生成少数类样本重叠信息。因此国外学者Tran K. D.、Thanh C. T.等(2021)与国内学者杨莲、石宝峰等(2022)等及柳培忠、洪铭等(2017)为了避免该缺陷,在研究中使用ADASYN采样提高少数类样本在边界区域的密度,避免小样本偏误,以此提高非平衡数据中违约样本的识别力;
二是模型选择问题。现有国内外研究均证实了机器学习领域模型的优越性,例如传统机器学习领域国外学者Li Z、Tian Y.等(2017)及Danenas P.、Garsva G.等(2015)與国内学者周颖与苏小婷(2021)为避免信用风险评估中的样本偏移,提出构建支持向量机模型,将预测违约样本推论结果纳入评分系统,结合外部评估和滑动窗口测试,以期提高预测的准确性。而霍源源、姚添译等(2019)与方匡南、逯宇铎等在信用评估领域发现Probit、Logistic模型更能抓住影响信用风险的关键因素;除传统方法外,Mushava J.、Murray M.等(2022)与Vassallo D.、Jha S. B.、Qin C.等(2020)提出构建集成学习XGBoost用于匹配具有高维和复杂相关性的信用数据,研究表明其可显著提高召回率及降低总体误差。考虑到XGBoost的优越性,周永圣、崔佳丽等(2020)提出了以XGBoost为基础,融合随机森林为代表的Bagging算法(XGBoost-RF)对个人信用风险评估领域进行预测,实验效果显示融合算法具有显著的优越性。同时,针对相同领域的预测,Zhou X.、Zhang W.等(2020)却选择构建卷积神经网络,并体现了99%AUC的超优性能。此外,王鑫与王莹(2022)采用LSTM-CNN融合模型的方法解决了传统领域中无法对时序数据进行动态预测的问题。
针对信用风险预测问题,国内外学者利用统计分析及机器学习技术构建了众多预测模型,涌现出大量优秀研究成果,其中SVM、Logistic、XGBoost、RF、CNN、BPNN具备显著的优越性。然而通过文献梳理,本文发现当前研究尚且存在以下几点不足:一是预测模型在非平衡数据集中易表现不佳。鉴于房地产信用数据集中违约样本数量远大于非违约样本数量,且存在较高的类别不平衡现象。大多数分类算法在面对非平衡数据时往往倾向于拟合非违约样本,从而导致预测模型对关键的违约样本识别不足,现实应用性较差。二是普遍倾向于单一模型且精度较低。目前大多数模型仍然依赖于单一的统计机器学习,无法多维度深刻把握指标与预测结果之间存在的复杂映射关系。而周永圣、崔佳丽等(2020)与王鑫与王莹(2022)提出融合模型可显著提高预测精度,降低误差,但其均运用同类融合。因此针对以往研究的不足,本文基于ADASYN过采样技术及Stacking融合算法,分别从数据层面把握不平衡特征及算法层面融合异类模型,构建性能表现优异、数据集适应度强的房地产信用风险预测模型。
本文的创新性在于:①针对现有信用风险指标体系进行多角度扩充。现有文献以生产者物价指数、人均GDP、利率、货币供给等宏观经济变量为解释变量,探讨中国宏观经济波动对房地产波动的影响。研究显示宏观经济变量与房价波动息息相关。因此除基本面财务数据及常用宏观经济指标以外,额外引入经济增长风险(GDP同比-预期GDP同比)、利率风险(10年期国债收益率)、通胀风险(0.3*PPI+0.7*CPI)等一系列指标。从数据层面扩展宽度,克服丢失有用信息。②本文基于融合模型思想构建信用风险预测模型,从实践层面为解决传统信用风险预测模型单一问题提供了新思路。融合模型解决了现有方法体系中单一模型较难充分提取原始数据中隐藏有效信息的困境,可以在主模型的基础上对基分类器进行扩充。
三、信用风险预测模型构建
(一)建立信用预测海选指标集
房地产行业信用风险预测的前提在于如何构建一组科学、完善的指标体系,从而全面把握整体信用违约风险。本文在结合券商行业研报以及国内外文献的基础上,综合考量各项因素,总结了适用于房地产行业的相关指标体系,主要海选指标如表1所示。
本文针对现有信用风险指标体系进行多角度扩充。除了基本面财务数据及常用指标以外,额外引入宏观风险指标旨在探索基本经济因素的不确定性,从而对系统风险作出识别判断。首先,在宏观形势中对房地产运行产生重大影响的是经济循环周期,本文采取GDP同比-预期GDP同比衡量经济增长风险,其差值大于0说明经济呈现超预期增长,经济处于正常上升通道,房价高概率稳步回升,房企现金流压力缓解,信用风险下降。反之,其差值小于0,说明经济增长不及预期,房企信用风险上升;其次,利率作为控制房产价格至稳定区间、维护市场稳定的重要工具。由图1所示,2017年以后,10年期国债收益率与房企融资规模增速走势基本一致,该现象的背后是房企融资通过改变金融机构资金流向影响了银行间市场流动性结构,进一步使债市产生被动调整。因此本文以10年期国债收益率度量利率风险,收益率水平高低与利率风险呈正比。利率波动显著影响房企的财务成本及盈利能力,财务成本增加进一步影响资金周转,从而诱发资金链风险;最后,基于理性预期与价格黏性假设,通过以产出类为指标的总量逻辑研判物价走势。本文采取网格优化算法对PPI与CPI之间的权重进行寻参,约束条件为二者权重之和为1。在其他条件不变的情况下,最优参数输出为0.3*PPI+0.7*CPI。而随着通货膨胀的持续,土拍价格、人力成本、施工成本的走高必然侵蚀价格的上升,而为避免经济过热所导致的信贷收紧、融资受阻对房地产而言无疑是重大利空,信用风险陡然上升。
(二)基于ADASYN的信用预测数据均衡化处理
ADASYN (adaptive synthetic sampling)自适应合成抽样,通过对不同的少数类样本赋予不同的权重,从而生成不同数量的样本。具体流程如下:
Step 1.计算不平衡度
(1)
记违约样本集为,非违约样本集为,为的第个违约样本,。
Step 2.计算需新生成的违约样本数
(2)
当时,即等于违约样本类和非违约样本类的差值,此时合成数据后的非违约样本类和违约样本类数据正好平衡。因此本文中取。
Step 3.计算每个违约样本的近邻中非违约样本占比
(3)
对每个属于违约样本类的用欧式距离计算个邻居,为个邻居中属于非违约样本类的数目,记比例为的近邻中非违约样本占比。
Step 4.对标准化,得到分布函数
(4)
用分布函数去计算每个违约类样本的周围非违约样本类的情况。
Step 5.根据分布函数,计算违约样本需要新生成的样本数
(5)
Step 6.根据计算每个违约样本需生成的数目,利用SMOTE算法生成样本
(6)
為新生成的违约样本,为的近邻中随机选取的一个违约样本,的随机数。
上述ADASYN过程既可以保证新生成的违约类样本蕴含原房地产信用预测数据的基本特征,也弥补了正负样本不均衡致使预测模型性能下降的不足。
(三)基于Stacking的信用风险预测模型
Stacking又称堆栈法,通过元分类器对多个异质基分类器的预测结果进行再度训练,从而提升模型能力。数学表达式如下所示:
(7)
其中表示k个基分类器所组成的向量,表示关于的估计值,,。
Stacking集成算法作为融合模型可分为两部分,首先是对异质基分类器进行训练,随后得到各组分类器的预测结果,将其作为新的特征传入元分类器从而得到最终预测结果。实际上若直接经过基学习器的结果输入进原学习器,极易造成过拟合现象,解决方法在于采用K-fold交叉验证,其考虑了样本集合的特点,因此模型的鲁棒性更强。将原始训练数据集设为,原始测试集数据设为,本文采用四种不同的基分类器()于第一层进行模型训练,以五折交叉验证为例其具体实现步骤如下:
Step 1.将原始训练集做五等均分,分别获得五个子集:
Step 2.依次将Step 1中的五个子集之一设为测试集,剩余四项子集仍然作为训练集用于四大基模型的训练,当模型训练完成后对测试集采取预测操作并获得相应结果,并将基分类器对的预测结果记作。
Step 3.将基分类器所得到的四项结果通过顺序拼接作为元分类器的新的训练集。因本文探讨问题本质上是分类问题,因此将预测结果求投票作为元分类器的测试集。
Step 4.新的数据集对原分类器进行训练,输出最终预测结果。
(四)对比模型精度检验标准
混淆矩阵是用来总结一个分类器结果的矩阵,本文用其作为信用违约判别模型分类效果的评价基础,其表现形式如表2所示:
准确度(Accuracy)表示为非违约客户被模型判为非违约的数量与违约客户被判定为违约的数量之和(判定准确的数目和)占总客户数的比,即
(8)
召回率(Recall)表示为正确预测为非违约客户的数量占实际非违约客户数量的比,即
(9)
第一类错误(TypeⅠ-Error)是指将非违约样本错判为违约样本的比,即
(10)
第二类错误(TypeⅡ-Error)是指将违约样本错判为非违约样本的比,即
(11)
几何平均值(G-Mean)因其同时考虑了非违约客户和违约客户的判对率,所以在信用风险领域常被用作判别模型好坏的标准。
(12)
AUC被定义为ROC曲线下的面积,其作为评价标准可以弥补ROC曲线不能明确说明哪个模型效果更好的缺陷,AUC越大说明模型鉴别房地产企业信用违约状态的性能越强。
四、实证分析
(一)数据来源与预处理
本文通过国泰安数据库(CSMAR)、同花顺iFinD选取2000年至2021年期间我国房地产行业137家上市企业作为研究样本,构建信用违约风险预测模型。ST(Special Treated)股是指企业经营连续两年亏损被中国证监会给予特别处理,* ST股则指企业经营连续三年亏损被中国证监会给予退市警告,这两类企业往往是因为经营不善出现违约状况的企业,因此本文以是否被标ST 或* ST将房地产企业的信用状态分为违约与非违约。
参照已有研究方法,剔除指标数据缺失严重或异常值较多的样本,最终选择10438个原始样本作为此次研究的实证对象,其中有信用风险类样本673个,编码为1;正常类样本9765个,编码为0。为避免财务报表时间点问题的发生,本文参考周颖与苏小婷(2021)的处理对样本企业的-2季度(以某年第季度为当前时间点,往前数2个季度间隔的时间点为-2)的指标数据与季度的违约状态进行建模,利用-2季度的数据来预测企业第季度是否存在信用违约风险。上述原因在于若企业发生信用风险时,其数据发布往往具有延迟性。
(二)统计分析与指标筛选
1.统计分析
由于部分统计方法只适用于正态分布或近似正态分布数据,因此在统计分析前期应先对指标数据进行K-S正态性检验,结果表明在给定显著性水平0.05条件下,房地产行业115个指标p值均小于0.05,全体指标数据特征分布不服从正态分布,无法满足使用t检验统计方法的条件,因此采取Mann-Whitney U秩和非参数检验对基分类器间以及特征选择间差异进行显著性检验,其原假设为特征指标分配在有信用违约风险和无信用违约风险的类别间具有一致性。显著性水平为0.05的情况下,应付账款周转率TTM、内部控制是否存在缺陷等13个指标未能通过显著性检验,予以剔除,据此减少类间重叠。考虑到指标之间可能存在潜在相关性,剔除Spearman相关系数绝对值大于0.8且p值小于0.05的冗余指标,优先祛除经济学含义较差的指标,若含义无法比较,则进行随机删除,避免自相关及多重共線性对后续预测产生干扰。最终形净值债务率等22个指标未能通过检验予以删除。
2.随机森林指标筛选
(1)短期指标重要性分析
近二十年来,中国房地产市场呈现出较为明显的短周期现象,基本每三年左右为一次短周期,主要驱动因素为房地产开发、投资驱动与政策影响。表3为随机森林以各年度指标为输入,每个特征对最终结果的预期贡献率为输出(即指标重要性)。由表可知,对应期间指标重要性排序凸显出异质特点,有必要结合房地产市场发展特点及周期背景进行相关分析。
2000—2002年小周期以母公司资本积累率及母公司资本保值增值率为代表的指标凸显该时期企业发展潜力的重要性。自1998年国务院发布公文做出了截断住房实物福利分配,实行住房分配货币化的决定,房地产行业呈现稳定发展的态势,房地产投资总量每年增幅已达20%以上(源自2002年8月13日《房地产时报》),诠释了发展潜力已成为该时期重点关注领域。
2003—2005年小周期以市盈率及Z值为代表,表明该时期不仅需关注收益情况,还应结合风险指标共同权衡房地产企业状况。原因在于2003年后,房价上升幅度过快,2004年与2005年商品房平均销售增长率为17.76%、14.03%,显著高于同年城镇居民家庭人均收入增长率。数据证明该时期的房地产市场含有适当的泡沫存在,因此国务院发布《关于切实稳定住房价格的通知》公文旨在抑制房价上涨过快,也从侧面提示应纳入收益风险指标防患于未然。
2006—2008小周期与2009—2011年小周期指标方面呈现相似特征,均以风险因子与相关系数所代表的贝塔系数同市场相关性为重点评释指标。2007年政府先后五次上调住房信贷利率以严厉打击房地产投机行为,由于加大宏观调控力度与次贷危机双重影响导致2008年房地产市场低迷甚至给部分地区带来些许金融冲击。因此2009年政府大幅度放宽了企业信贷政策,房市出现反弹,报复性上升的价格在该阶段创立新高。2010年与2011年出台的一系列调控政策遏制房价上涨幅度,局部地区出现降价趋势。由此可知,风险衡量指标一定程度上阐释了整个周期市场环境的动荡。
2012—2014年小周期并未有明显指标倾向。2012年虽承接2010—2011年所带来的强势压制,但房地产销售量仅略微下降且房价依旧处于高位,因此该年市场风险相关指标虽仍保持高位但重要性有所下降。2013年在政府调控弱化且相关政策趋于宽松、经济向好发展以及国内需求上升的背景下,许多地区楼王记录频繁刷新,说明房企逐渐回暖、现金周转加快、利润快速上涨。而2014年房地产市场库存量创新高,与其相关的销售管理费用率以及固定资产周转率重要性开始大幅提升,为解决库存问题,国家再度出台大量利好政策推动市场回暖。
与过去几轮短周期呈现的“快升快降”的态势相比,2015—2018年短周期的下行时间明显拉长且与资金密切相关,筹资活动及投资收益相关指标重要性也显著上升。上一轮周期结束,在稳增长与去库存的要求下,限购限贷等政策逐渐宽松,但市场复苏并未呈现理想态势,因此2015年证监会《公司债券发行与交易管理办法》的发布拓宽了房企境内融资渠道,使得房企公司债发行出现井喷态势。同时出台非限购城市首付比例进一步降低、二套房首付比例降低、全面推行异地贷等宽松政策,并且强调去库存,棚改货币化力度加大。2016年开始转向调控政策,由需求端向供给端发展,且规定发债募集资金不得购置土地。2017年国家外汇管理局允许内保外贷下资金调回境内使用,由于境内融资压力上涨 ,因此美元债市场引来高速发展,促使美元债作为房企融资渠道构成的重要性迅速上升。2018年政府层面实施窗口指导,规定发行新债募集资金仅限于借新还旧及长租公寓领域。虽受到相关限制措施,但与“三道红线”等政策相比,2015—2018年短周期融资环境还是相对宽松,对房地产市场形成了有力支撑。
而在2019—2021年短周期占据重要性比例最高的是现金及现金等价物周转率,说明在该时期流动性是影响房地产的核心因素。期间随着调控深化、融资收紧,资产端与负债端同时带来的压力外加公司债的集中到期,使得企业流动性不足,引发中小房企违约潮。2020年以来,新冠疫情爆发外加“三道红线”的限制,房地产融资端的债券额度及募集资金用途进一步收紧,降杠杆成为该短周期房地产调控重点。流动性问题导致高杠杆且经营回款较慢的房企出现大规模违约,爆发信用风险。房地产行业状态急转直下出现负向螺旋效应,引发大规模负反馈,无论内生还是融资现金流均遭受严重承压。
(2)长期指标重要性遴选
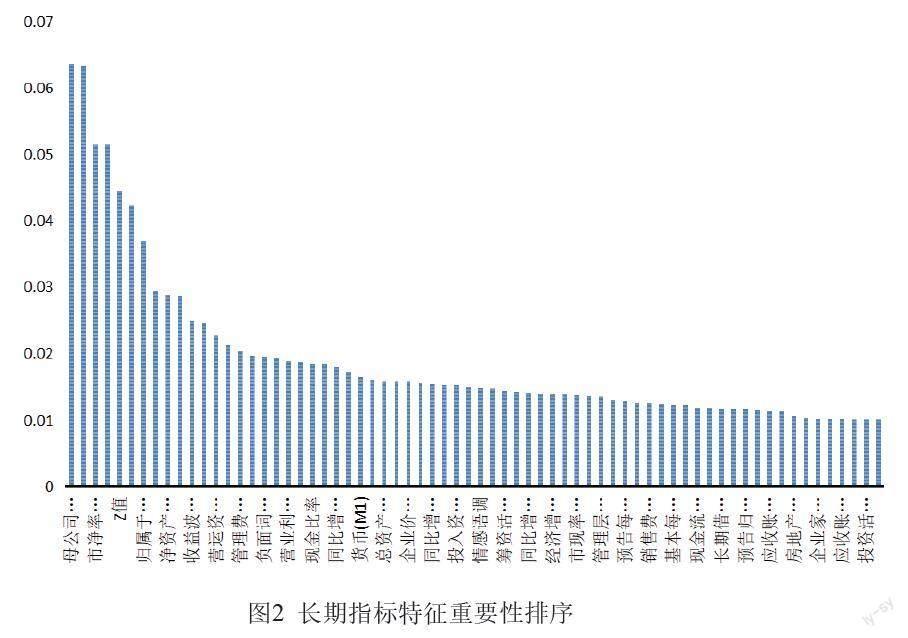
经过短期指标分析可知,随机森林重要性度量能够帮助筛选出符合实际情况且对房地产影响程度较大的指标。基于长期指标,本文倾向于剔除重要性小于0.01的指标变量,排序图如下所示。
研究发现:①重要性排名前五的指标分别为母公司资本保值增值率、母公司资本积累率、市净率(PB)、风险因子-流通市值加权、Z值,表明长期角度房企自身发展潜力以及收益风险状态是反映信用风险的重要因素。②滞后指数、业绩预告发布次数等12项指标重要性均小于0.01,予以剔除。
(一)模型预测与分析
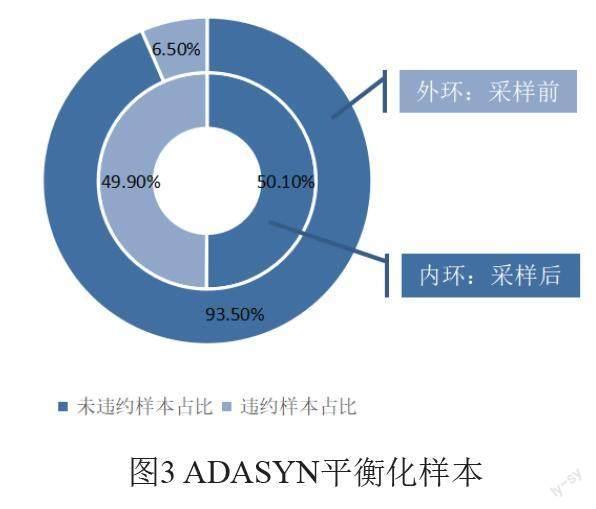
由于违约样本与正常样本二者之比约为1:14.5。明显存在极端不平衡现象,为避免后续建模偏向正常样本类数据,需对训练集进行ADASYN平衡化处理,结果如图3所示。
1.模型分析
(1)单一模型
将2000—2020年房地产信用风险数据集作为训练集样本、2021年数据作为测试集样本,分别使用逻辑回归(Logistic)、支持向量机(SVM)、极度梯度提升树(XGBoost)、随机森林(RF)、后向传播神经网络(BPNN)、卷积神经网络(CNN)进行训练。模型调参的目的在于寻找全局最优解或较好的局部最优解使得期望风险最小化,但源于该过程的复杂性,多数最优化算法较易陷入局部最小陷阱。而遗传算法(GA)以生物进化为原型,使用随机性的概率机制进行迭代,可较好避免陷入上述问题。本文各模型基于遗传算法的参数设置如下表所示。
对于分类问题,本论文在实证板块以AUC为主,Accuracy、Recall、G-mean、TypeⅠ-Error、TypeⅡ-Error為辅以判别模型表现效果,如表5所示,从Accuracy、Recall的角度出发,RF在有效识别非违约企业及分类正确覆盖率方面表现最为优异。但为了对不平衡样本的分类性能进行评估,应采用AUC、G-Mean两项指标综合考虑模型的判别能力,其值越大则说明模型表现效果越好。其中排名第一的均是BPNN,其在具有较好的分类性能的同时能进一步有效提升房地产行业信用违约风险样本的预测效果。从TypeⅠ-Error、TypeⅡ-Error角度出发,RF在将非违约企业判定为违约企业的错误率上最低,有利于非违约企业的识别预测。而在将违约企业判定为非违约企业的错误率上BPNN与CNN拥有更好的表现。实践中信用风险预测更倾向于识别违约企业,降低TypeⅡ-Error能避免给金融机构或企业政府带来巨额损失,因此单一预测模型更适宜于选择BPNN。
(2)融合模型
对比单一分类器的表现效果,以TypeⅡ-Error为信用风险重要指标的情况下,BPNN与CNN为Stacking元分类器的最佳选项。同时,Logistic、SVM、RF、XGBoost作为基分类器采用五折交叉验证构建两类融合模型。
表6为汇总的模型精度对比结果展示,经过Stacking融合后的模型与单一模型相比,在Accuracy、Recall、AUC、G-Mean四项评价标准下均有显著提升,Stacking-BPNN甚至均超越单一模型取得最优结果。其中,Accuracy、Recall比RF分别高了0.6与0.2个百分点,达到了95.82%与96.23%;AUC、G-Mean比BPNN分别上升了1与1.9个百分点,提升至96.84%与91.76%。由此可见,模型在有效识别与非平衡数据集分类方面综合取得了显著改善效果,初步验证了融合模型的有效性。而在TypeⅠ-Error、TypeⅡ-Error指标下,Stacking-BPNN比单一BPNN降低了15.47%的一类错误率,但在二类错误率上上涨了12.5%。这可能是因为基分类器对于TypeⅡ错误的识别不足所引起整体融合模型效果降低。
Stacking-CNN虽表現不足Stacking-BPNN,但对比CNN模型,其在Accuracy、Recall上分别上涨了16.93%与18.41%;在AUC、G-Mean上同样分别提高了0.6与3.6个百分点。而TypeⅠ-Error也降低了18.41%。结果证明Stacking融合模型相较于单一模型能显著提高模型性能,同时提升分类精度。
2.预测结果分析
(1)预测结果
在算法建模中一般会选取上述指标来衡量模型好坏,stacking融合模型在多项量化指标上均有其优越性,但模型评价指标只应作为决策的部分内容,结合分析其预测结果也同样重要,能为实际运用提供桥梁。因此,2021年房地产信用风险预测结果如表7所示。为便于展示,本文选择将季度数据转化为年度数据,规则如下:若四个季度中有一个季度被预测为1(有信用风险),则年度取值为1;若四个季度均被预测为0,则年度取值为0。
由结果可知,2021年共126家上市房企,其中违约房企为12家,占比近10%。而模型预测占比均高于真实值,其中Stacking-BPNN最接近真实情况,随机森林表现次优。结合历年来违约房企占比情况可以发现,2000后违约占比呈现上涨趋势,并于2007—2008次贷危机后以21%高值达到顶峰,随后经过国家宏观调控救市、放宽信贷政策,比值呈现好转信号逐步下跌,房企逐渐回暖、现金周转加快,2014年房地产市场库存量创新高。因此2015年以0%的违约占比达到低谷。此后随着调控深化、融资收紧、疫情影响等因素,违约房企占比再次呈现上升趋势,并于2021年涨至10%。
结合模型普遍偏高预测,从现实环境分析来看,依然存在较高信用风险的原因可能在于:一是房地产需求硬上限的人口及购买力存在动力不足现象。居民收入增速放缓引导堆积于房地产的大量资金回归其他领域;而人口周期断档及出生率断崖式下跌也将从中长期维度对房地产产生相关影响;二是企业自身“亚健康”现象。虽目前政策释放红利有力稳定房地产市场,促使供需结构改善,但基本面及政策仅仅是影响房企风险暴露的外在因素,主要源头还是在于房企近年来经营战略的失误及长期累积的杠杆风险,使其呈现“亚健康”经营模式。
(2)违约样本
分析违约房企样本发现,风险企业主要存在以下三种类型:
财务风险型
此类企业的现金流依赖于筹资维系资金链,易追随市场波动周期。以财务指标为例,部分房企的筹资性现金流入持续大于经营性现金流入,反映出其内生性经营能力不足,导致较难利用销售回款来实现本企健康稳定发展。若全面依赖筹资渠道便会导致其敏感性上涨,经济周期、政策变向便极易引致信用风险。
其次,违约房企“三道红线”踩线较多。某龙头房企甚至连续7年触及红档,2021年一季度剔除预收账款后的资产负债率达到80.99%,净负债率为117.99%。呈现出杠杆率高的共有特点,高杠杆高周转极易引发流动性危机。
最后,违约房企存货周转率持续偏低。当前在业绩增速放缓叠加偿债高峰,房企经营普遍遭受牵制的背景下,该财务指标说明违约房企存货变现困难,原因可能在于前期过度关注下沉三、四线城市的战略失误,致使财务雪上加霜。
战略布局错位型
此类主要集中于在经营战略错判的房地产企业。比如其集中布局文旅地产、以及如1)所说的布局三、四线城市等,该类项目难去化会使资金长期承压,过于消耗财务资源,伴随着行业下行的大环境便极难维持。此外,近一两年资本支出占比较高、新增土储规模较大的房地产企业说明其大量购买高价地,可预期后期偿债压力上涨,提前消耗流动性累积风险。
缺乏核心竞争力型
在房地产经历过寒冬时刻,市场容量大幅萎缩、需求持续支撑不足的环境下必然会导致市场竞争加剧,那么盈利能力较弱、缺乏核心竞争力的房企便会逐步暴露风险。即使其目前并未预测出信用风险,但其也会在行业趋势下面临淘汰。
总的来说,虽然目前行业风险程度依然偏高,但整体行业指标层面有好转现象。比如2020年A股房企经营性现金流入平均占比51.39%,筹资性平均占比41.22%。表明在杠杆时代的红利退散后众多房企开始倾向于精细经营以实现稳健增长。如某科、某地、某利等龙头企业在风险指标的表现下依然稳健优异,其长期来看具备更强周期驾驭能力及更强的市场竞争力。而对于风险暴露的违约房企也会逐步退场,优质资源更易向优良房企倾斜,信用格局重构,风险也较难蔓延至全市场。
五、结 论
通过统计检验剔除反映信息重复、统计与经济学意义均不显著的指标,经过随机森林重要性遴选对房企违约状态影响显著的指标,建立了房地产信用风险评估指标体系。在此基础上,利用ADASYN过采样技术消除不平衡样本影响,构建基于Stacking融合算法的预测模型,并对中国137家上市房地产企业样本进行实证,得出如下结论:
(一)Stacking-BPNN在模型设定合理、数据构造得当的前提下性能表现最优。相较于单一模型,其在Accuracy、Recall、AUC、G-Mean上均有显著提升,能够更加及时、准确地了解房企的违约概率,进而防范风险。
(二)违约房企仍处于上涨趋势,信用风险缓释未达预期。预测结果显示模型违约占比均高于真实值,除在模型设定时以降低第二类错误(将违约样本错判为非违约样本)为主的影响外,受制于疫情和地产行业景气下行、内生融资疲软等因素是结论的核心。但随着经济基本面整体改善,在宽财政基调下地产链条有望底部企稳,局面极可能扭转。
本文所采取的指标体系仅仅也是冰山一角,随着人工智能技术的应用逐渐成熟,未来数据维度也逐渐突破传统特征限制倾向于高维化,因此如何利用海量高维数据协助进行房地产信用风险预测分析应成为下一步研究目标。
参考文献:
[1]Maldonado, Sebastian, Bravo, et al. Integrated framework for profit-based feature selection and SVM classification in credit scoring[J]. Decision Support Systems, 2018. 104(Dec.):113-121.
[2]Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: synthetic minority over-sampling technique[J]. 2011.
[3]Tran K D, Thanh C T, Luc M T, et al. Machine learning based on resampling approaches and deep reinforcement learning for credit card fraud detection systems[J]. 2021.
[4]Li Z, Tian Y, Li K, et al. Reject inference in credit scoring using semi-supervised Support Vector Machines[J]. Expert Systems with Applications, 2017, 74:105-114.
[5]Danenas P, Garsva G. Selection of Support Vector Machines based classifiers for credit risk domain[J]. Expert Systems with Applications, 2015, 42(6):3194-3204.
[6]Golbayani P, Florescu I, Chatterjee R. A comparative study of forecasting Corporate Credit Ratings using Neural Networks, Support Vector Machines, and Decision Trees[J]. The North American Journal of Economics and Finance, 2020, 54(1):101251.
[7]Mushava J, Murray M. A novel XGBoost extension for credit scoring class-imbalanced data combining a generalized extreme value link and a modified focal loss function[J]. Expert Systems with Applications, 2022.
[8]Vassallo D, Vella V, Ellul J. Application of Gradient Boosting Algorithms for Anti-money Laundering in Cryptocurrencies[J]. SN Computer Science, 2021, 2(3).
[9]Bai M, Zheng Y, Shen Y. Gradient boosting survival tree with applications in credit scoring[J]. Journal of the Operational Research Society, 2021(1):1-17.
[10]Jha S B, Babiceanu R F, Pandey V, et al. Housing market prediction problem using different machine learning algorithms: A Case Study[J]. 2020.
[11]Qin C, Zhang Y, Bao F, et al. XGBoost optimized by adaptive particle swarm optimization for credit scoring[J]. Mathematical Problems in Engineering, 2021.
[12]Zhou X, Zhang W, Jiang Y. personal credit default prediction model based on convolution neural network[J]. Mathematical Problems in Engineering, 2020.
[13]Gao J, Sun W, Sui X. Research on default prediction for credit card users based on XGBoost-LSTM model[J]. Discrete Dynamics in Nature and Society, 2021.
[14]石寶峰, 王静. 基于ELECTRE III的农户小额贷款信用评级模型[J]. 系统管理学报, 2018, 27(05):854-862.
[15]杨莲, 石宝峰. 基于Focal Loss修正交叉熵损失函数的信用风险评价模型及实证[J]. 中国管理科学, 2022, 30(05):65-75.
[16]张雷, 王家琪, 费职友, 罗帅, 隋京岐. 基于RF-SMOTE-XGBoost下的银行用户个人信用风险评估模型[J]. 现代电子技术, 2020, 43(16):76-81.
[17]陳刚, 郭晓梅. 基于时间序列模型的非平衡数据的过采样算法[J]. 信息与控制, 2021, 50(05):522-530.
[18]柳培忠, 洪铭, 黄德天, 骆炎民, 王守觉. 基于ADASYN与AdaBoostSVM相结合的不平衡分类算法[J]. 北京工业大学学报, 2017, 43(03):368-375.
[19]周颖, 苏小婷. 基于最优指标组合的企业信用风险预测[J]. 系统管理学报, 2021, 30(05):817-838.
[20]霍源源, 姚添译, 李江. 基于Probit模型的中国制造业企业信贷风险测度研究[J]. 预测, 2019, 38(04):76-82.
[21]方匡南, 章贵军, 张惠颖. 基于Lasso-Logistic模型的个人信用风险预警方法[J]. 数量经济技术经济研究, 2014, 31(02):125-136.
[22]逯宇铎, 金艳玲. 基于Lasso-Logistic模型的供应链金融信用风险实证研究[J]. 管理现代化, 2016, 36(02):98-100.
[23]周永圣, 崔佳丽, 周琳云, 孙红霞, 刘淑芹. 基于改进的随机森林模型的个人信用风险评估研究[J]. 征信, 2020, 38(01):28-32.
[24]王鑫,王莹.基于LSTM-CNN的中小企业信用风险预测[J].系统科学与数学,2022,42(10):2698-2711.
[25]陈学彬, 武靖, 徐明东. 我国信用债个体违约风险测度与防范——基于LSTM深度学习模型[J]. 复旦学报(社会科学版), 2021, 63(03):159-173.
[26]李保林. 宏观经济波动对房价走势的影响——来自中国31个省市的经验证据[J].西南金融,2019,No.452(03):36-43.
An empirical study on credit risk prediction of China's real estate industry
—Based on Stacking Model
Xu Wan, Liu Shengti
(School of Management,University of Shanghai for Science and Technology,200093)
Abstract: In order to promote the steady development of the real estate industry, this paper combines ADASYN technology and Stacking algorithm to build a prediction model with excellent performance and strong fitness of the data set against the background of the data of the listed real estate enterprises, aiming to measure the relevant credit risks and make a modest contribution to China's prevention and resolution of major financial risks in real estate. The innovation lies in: firstly, from a macro perspective, the introduction of indicators closely related to the real estate industry, such as economic growth risk (GDP year-on-year - expected GDP year-on-year), interest rate risk (10-year treasury bond bond yield), inflation risk (0.3 * PPI+0.7 * CPI), etc; The second is to construct a prediction model based on the fusion model idea, providing new ideas from a practical perspective to solve the problem of single traditional credit risk prediction models. The empirical results show that: 1. Stacking BPNN outperforms the single model to obtain the optimal performance index; 2. The reason why there is still a high risk value is due to the lack of motivation in the real estate related population and purchasing power, as well as the phenomenon of "sub health" of the enterprise itself. Risk enterprises are mainly concentrated in financial risk oriented real estate enterprises, strategic dislocation oriented real estate enterprises, and lack of competitiveness oriented real estate enterprises.
Key words: Real Estate Credit Risk; Stacking; ADASYN
