基于多分类器集成的沅陵县天然林类型信息提取研究
2023-06-30鲁宏旺龙江平
张 颖 ,肖 越,鲁宏旺,龙江平,林 辉
(1.中南林业科技大学林业遥感信息工程研究中心,湖南 长沙 410004; 2.林业遥感大数据与生态安全湖南省重点实验室,湖南 长沙 410004; 3.南方森林资源经营与监测国家林业与草原局重点实验室,湖南 长沙 410004;4.长沙市长长林业技术咨询有限责任公司,湖南 长沙 410004)
天然林是我国森林资源的重要组成部分,约占我国森林总面积的三分之二,在水源涵养和水土保持等方面具有不可替代的作用。准确地获取天然林林分类型能够因地制宜、适地适树地保护天然林资源,为形成稳定的森林生态系统和实现林业可持续发展提供依据。我国1998年特大水灾发生后国家正式启动了“全国重点地区天然林资源保护工程”,以彻底扭转生态环境不断恶化的局面,实现国家中长远计划的核心目标之一 ——促进社会与经济的可持续发展[1]。传统的天然林调查主要靠实地调查,然而这种实地调查的方法费时费力,效率也较低[2]。近年来,遥感技术的飞速发展大大提高了森林资源调查的效率及精确度[3-6]。
目前,森林分类主要集中在针叶林、阔叶林和混交林等林地信息提取方面,并逐步开始尝试主要人工林树种的精细分类[7]。然而,面对南方复杂环境下的天然林,基于遥感技术的天然林分类具有较大的挑战。为了更好地评价天然林的生长过程和生态价值,基于遥感技术建立天然林的分类模型与算法具有重要意义。近几年来,随着遥感技术的迅速发展,遥感卫星层出不穷,各学者进行了大量的研究与分析。Sentinel-2相较于其他遥感卫星影像而言具有重访周期短、空间分辨率高以及波段信息丰富等优势,尤其是它拥有较多的红边波段,对于植被的区分具有较大的作用。
随着国内外学者对于分类精度的要求不断提高,传统的单一机器学习分类算法已经不能满足要求,因此,通过对多分类器进行组合的集成学习算法应运而生,其能更好地将各分类器的优缺点进行互补,从而避免某一分类器所具有的偶然性与不确定性,提高整体的分类精度。Wang等[8]对祁连山的森林分布进行了制图研究,对比了自动集成学习方法、LightGBM、随机森林、CatBoost、XGBoost和神经网络等多种基分类器,发现集成学习方法区分森林覆盖和制图的结果最优,更能够充分地展示高质量和丰富的空间细节。
本研究以怀化市沅陵县的天然林为研究对象,以Sentinel-2影像为数据源进行天然林分类实验。首先,基于Sentinel-2数据提取光谱特征、植被指数以及纹理特征等31个分类特征。然后,采用先分层后分类的方法,遵循“从上到下、从简单到复杂”的原则,使用最大似然算法(Maximum Likelihood,ML)、神经网络算法(Artificial Neural Net,ANN)、支持向量机算法(Support Vector Machine,SVM)、随机森林算法(Random Forests,RF)以及集成学习算法(Ensemble Learning,EL)对研究区进行分类,建立符合天然林的遥感特征筛选的准则,实现天然林分类。
1 研究区概况
研究区位于湖南省怀化市沅陵县,地理位置为110°05′31″—111°06′27″E,28°04′48″—29°02′26″N,总面积5852km2。全县有林地面积3848.8km2,占沅陵县国土面积的66.07%,森林覆盖率达76.19%。本研究选取沅陵县东北部火场乡、大合坪乡、七甲坪镇、清浪乡、五强溪镇、陈家滩乡、官庄镇共7个乡镇的天然林为研究对象,研究区的总面积为1959.64km2,其中天然林面积为1141.21km2,占研究区国土总面积的58.24%。根据地面调查数据可知,研究区的天然林主要树种为马尾松(Pinusmassoniana)、杉木(Cunninghamialanceolata)、樟树(Cinnamomumcamphora)、枫香(Liquidambarformosana)等。
2 材料与方法
2.1 数据来源与预处理
2.1.1 Sentinel-2数据下载与预处理
本研究使用的Sentinel-2数据来自欧洲航天局(https://scihub.copernicus.eu)。本研究选取了2019年9月28日的Level 1C的研究区Sentinel-2影像作为本次分类实验的遥感数据源。由于研究区覆盖范围较大,因此需要下载2景影像进行镶嵌,以获取覆盖整个研究区范围的影像。欧洲航天局发布的Sentinel-2数据为已经过辐射定标与几何校正操作处理后的Level 1C级多光谱数据。本研究只需进行大气校正、重采样(空间分辨率10 m)以及图像镶嵌和裁剪的预处理。
2.1.2 样本数据选取
本研究根据地面采集辅助数据建立了沅陵县天然林分类体系,通过地面调查数据计算出各类别所占比例,结合目视解译判读选取了3000个分类样本,并将训练样本和验证样本数量的比例设置为7∶3(见表1)。为保证实验的客观性,保证样本点分布均匀,剔除了部分质量较差的样本,最终选择2163个样本,其分布如图1所示。从影像上来看,阔叶林的纹理最为粗糙,地类内部呈块状差异分布,表观不均匀;针叶林分布较均匀,呈颗粒状;竹林呈点状,分布最为均匀。
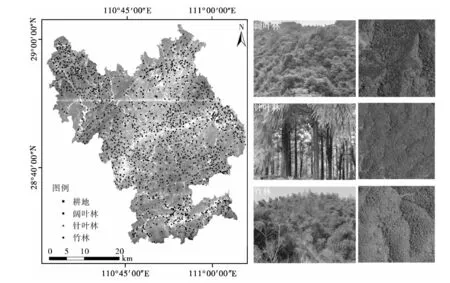
图1 研究区样本点分布Fig.1 Distribution of samples in the study area
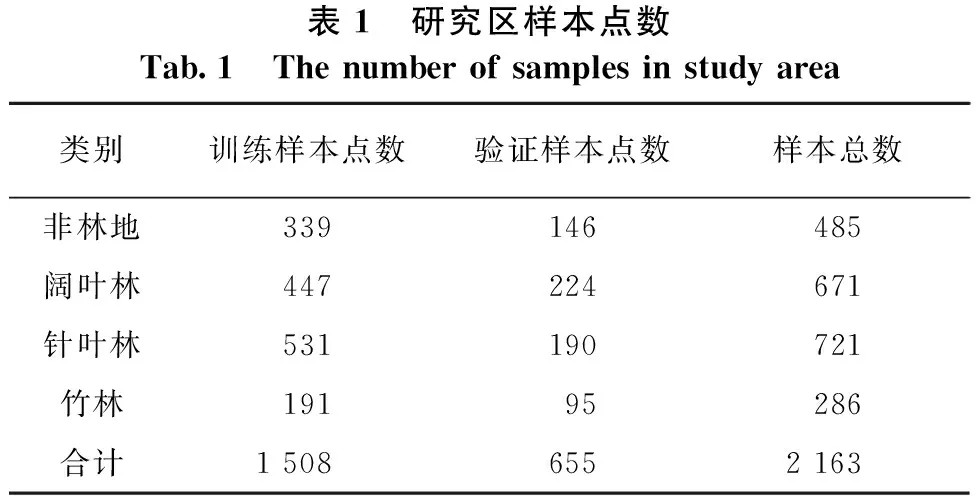
表1 研究区样本点数Tab.1 The number of samples in study area类别训练样本点数验证样本点数样本总数非林地339146485阔叶林447224671针叶林531190721竹林19195286合计1 5086552 163
2.2 研究方法
本研究以Sentinel-2为主要数据源,分别提取光谱特征、植被特征以及纹理特征,并结合地面样本数据,将研究区人工林部分进行掩膜,对剩余的非林地及天然林的部分以分层分类的思想采用ML、ANN、SVM、RF以及EL共5种分类算法提取天然林类型信息,构建基于集成学习模型的沅陵县天然林分类的模型。本实验总体的技术路线如图2所示。
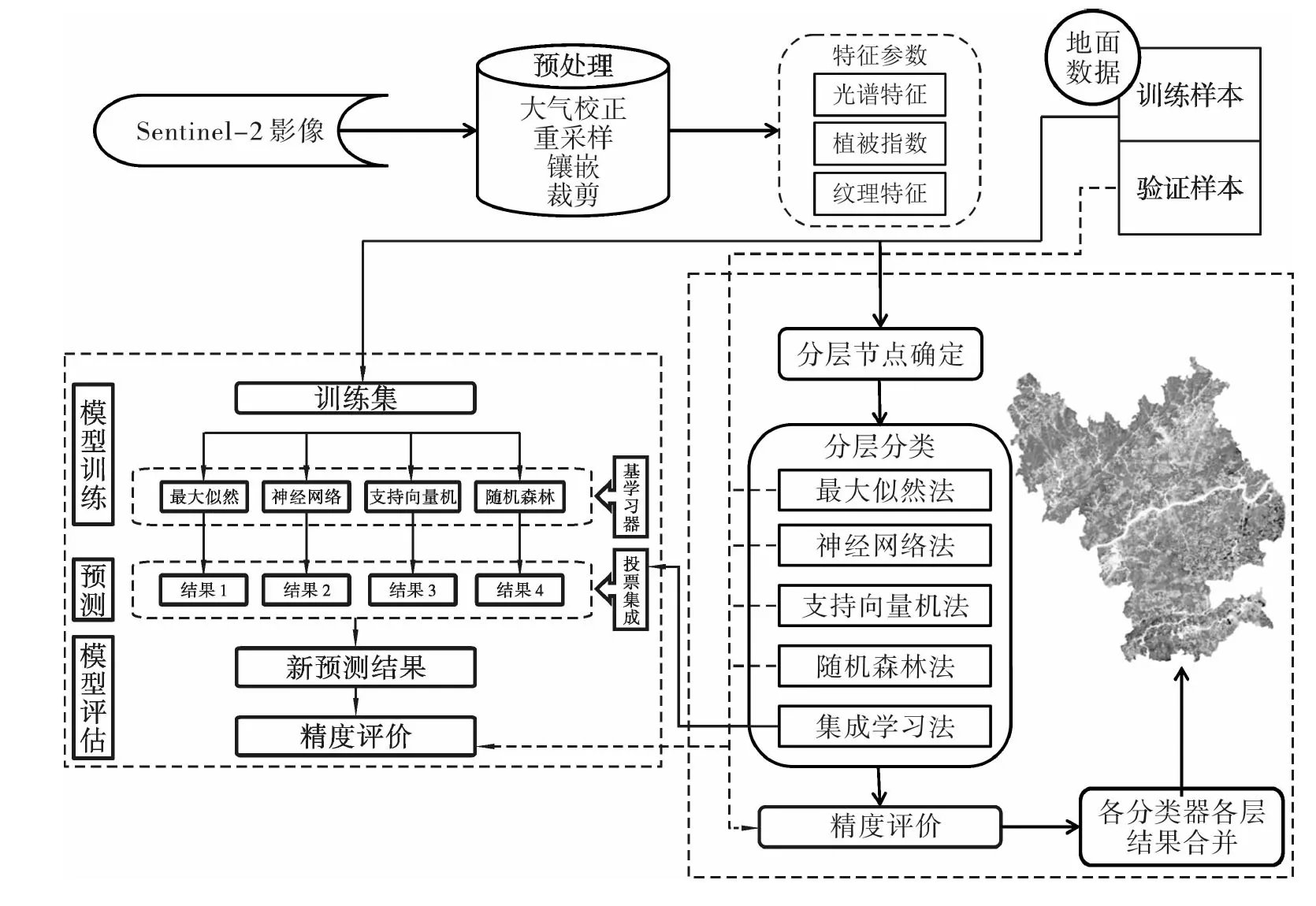
图2 技术路线图Fig.2 Technical route
2.3 分类特征构建
分别提取Sentinel-2影像的光谱特征、植被指数和纹理特征作为分类特征进行后续的实验。由于Sentinel-2影像具有12个波段,若对每个波段都进行纹理特征的提取,将会造成巨大的数据冗余,从而增大计算难度。因此,需要先对Sentinel-2影像波段数据进行主成分分析,并提取包含了最多信息数据的第一主成分波段,再对其进行纹理特征的提取和后续的分类研究。本实验提取的31个特征详见表2。
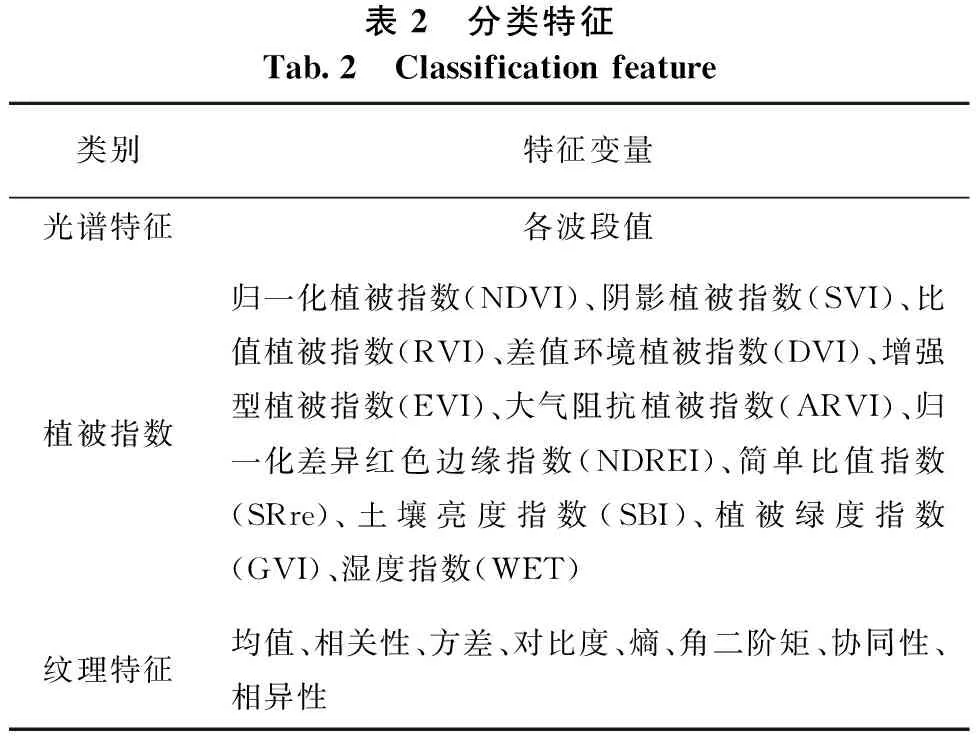
表2 分类特征Tab.2 Classification feature类别特征变量光谱特征各波段值植被指数归一化植被指数(NDVI)、阴影植被指数(SVI)、比值植被指数(RVI)、差值环境植被指数(DVI)、增强型植被指数(EVI)、大气阻抗植被指数(ARVI)、归一化差异红色边缘指数(NDREI)、简单比值指数(SRre)、土壤亮度指数(SBI)、植被绿度指数(GVI)、湿度指数(WET)纹理特征均值、相关性、方差、对比度、熵、角二阶矩、协同性、相异性
2.4 特征筛选
在以往使用多光谱数据进行分类的遥感研究中,常会出现休斯现象,即对于同一分类数据集,在最初逐步添加特征参数时,分类精度成正比趋势逐渐提高,但到达某一临界值时,随着特征参数的继续添加,分类结果的精度会开始下降[9]。而随机森林算法可以通过筛选并剔除无关或者重要性较低的特征,降低信息冗余而保留对实验各分类数据贡献度较大的特征,以避免休斯现象的发生,从而提高分类精度。因此,本研究采用随机森林算法,利用基尼指数(Gini index)对特征的重要性进行评估[10],其公式如下:
(1)
式中:n为随机森林中决策树的数目,Ginii(M)为第i棵决策树划分前集合M的基尼指数,Ginii(M,A)为第i棵决策树通过特征A划分后集合M的基尼指数。
2.5 分层分类体系
本实验采用ML、ANN、SVM、RF与EL共5种分类算法,基于分层分类的思路实现天然林的分类(见图3)。第一层分类分别使用各分类算法将研究区识别为林地和非林地,并用于后续实验;第二层分类将林地区分为竹林和其他林地两部分;第三层将阔叶林与针叶林进行区分;最后将非林地、阔叶林、针叶林、竹林以及人工林合并为研究区整体分类结果图。
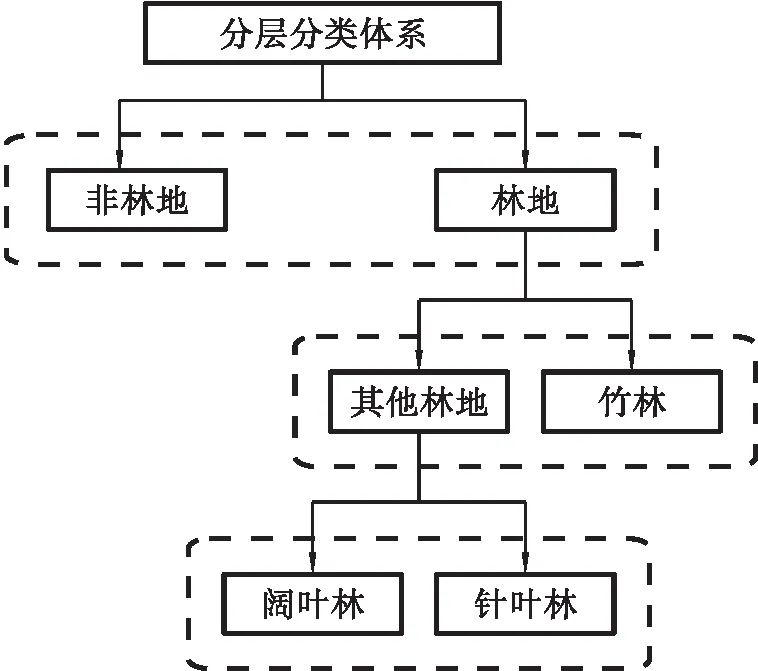
图3 分类体系Fig.3 The hierarchical classification system
2.6 分类算法
2.6.1 单分类算法
机器学习是进行遥感影像分类最常见的方法。ML具有分类速度快、操作简单、结果准确直观等特点,因此得到了广泛使用[11]。ANN使用的是反向传播学习算法,是研究最为广泛的神经网络训练方法之一[12]。SVM能够在决策过程中对样本进行筛选优化,剔除具有冗余信息的样本,保留具有关键作用信息的样本,降低了分类模型的求解难度,从而提高分类的准确性,具有较高的实用价值[13]。RF能够处理更多高维海量的数据,并且由于其随机输入的方式和随机特征不同,所以在分类中展现出了良好的效果,且近年来被广泛应用于遥感影像分类领域[14]。
2.6.2 集成学习算法
EL本身并不是一种单独的机器学习算法,而是将多个机器学习分类器按照一定的规则与策略组合起来而得到的算法。多分类器组合的方式包括串联式、并联式以及嵌入式三种。并联式是将多个分类器以并联的方式组合起来,各分类器单独运行,相互独立,互不影响[15]。本实验利用并联式结构对四种基分类器进行集成。最常见的集成学习的组合策略为投票法。投票法的使用原则是少数服从多数,从而降低分类误差,提高精度。投票法包括硬投票和软投票两种,硬投票是直接通过少数服从多数的方式输出结果,即多数投票法。而软投票则是考虑了概率,分析各分类器结果的权重,将概率最大的类别输出为结果。本实验投票集成流程图如图4所示。加权投票法相较于多数投票法而言能够更好地降低弱分类器对投票结果带来的影响,从而更准确地预测分类结果[16],其公式如下:
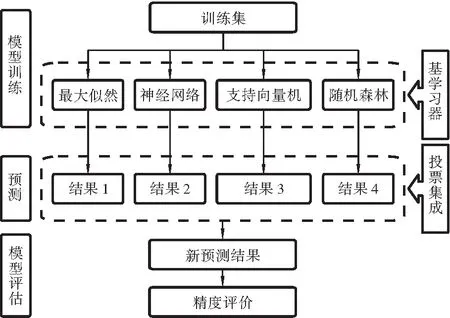
图4 实验投票集成流程图Fig.4 Experimental voting integration flow chart
(2)
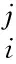
2.7 精度评价指标
本研究为每个分类结果创建混淆矩阵,并分别计算用户精度(User’s Accuracy,UA)、生产精度(Producer’s Accuracy,PA)、总体精度(Overall Accuracy,OA)和Kappa系数对分类结果进行精度验证与评价,公式如表3所示。

表3 精度评价指标计算公式Tab.3 Calculation formula accuracy evaluation index指标名称计算公式注解 序号生产精度PA=NiiN+i用户精度UA=NiiNi+总体精度OA=∑ni=1NiiNKappa系数Kappa=N ∑ni=1Nii -∑ni=1 Ni+ N+i N2-∑ni=1 Ni+ N+i N为总样本数;Nii为矩阵中第i行、第i列上像元的数量一类所在行总数;Ni+为某一类所在第i行像元总数;N+i为某一类所在第i列像元总数(3)(4)(5)(6)
3 结果与分析
3.1 特征筛选结果
利用随机森林算法对12个波段光谱特征、11个植被指数特征、8个纹理特征共31个特征波段进行排序。由图5可知,对于不同地类,各个特征的重要性是不同的,在林地与非林地的提取中,最佳分类特征为B2;在竹林与其他林地的提取中,最佳分类特征为B12;在阔叶林与针叶林的提取中,最佳分类特征则为B1。由于各层次所需要区分的类别不同,因此,分类特征的重要性也不相同。我们通过遍历的方式筛选出各层次最优的分类特征进行后续的分类实验。

图5 各层次特征重要性排序 Fig.5 The characteristics of each level ranked in importance
3.2 各层次分类结果及精度评价
3.2.1 非林地与林地
第一层次为非林地与林地的区分,其分类精度如表4所示。结果表明:集成学习算法(EL)的结果最佳,总体精度达到了98.63%,Kappa系数达到了0.96,均优于其他4种分类算法。集成学习算法在非林地的提取上展现出了极强的优势。
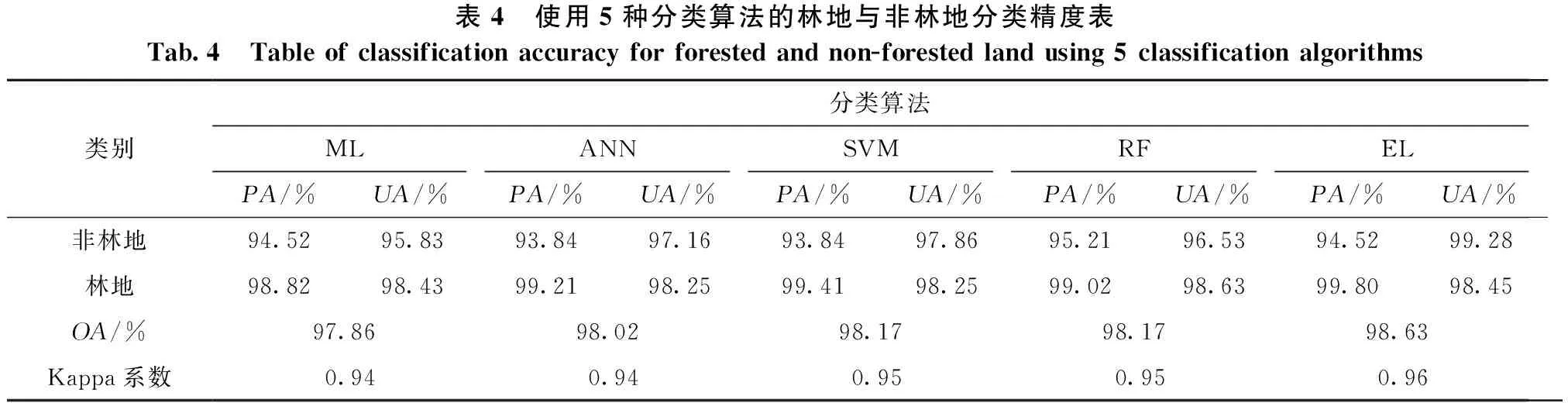
表4 使用5种分类算法的林地与非林地分类精度表Tab.4 Table of classification accuracy for forested and non-forested land using 5 classification algorithms类别分类算法MLANNSVMRFELPA/%UA/%PA/%UA/%PA/%UA/%PA/%UA/%PA/%UA/%非林地94.5295.8393.8497.1693.8497.8695.2196.5394.5299.28林地98.8298.4399.2198.2599.4198.2599.0298.6399.8098.45OA/%97.8698.0298.1798.1798.63Kappa系数0.940.940.950.950.96
3.2.2 竹林与其他林地
第二层次为竹林与其他林地的区分,其中其他林地包括阔叶林与针叶林两大类,其分类精度如表5所示。结果表明:集成学习算法(EL)依然为最优算法,其总体精度和Kappa系数分别为96.70%和0.86,均高于其他4种算法。
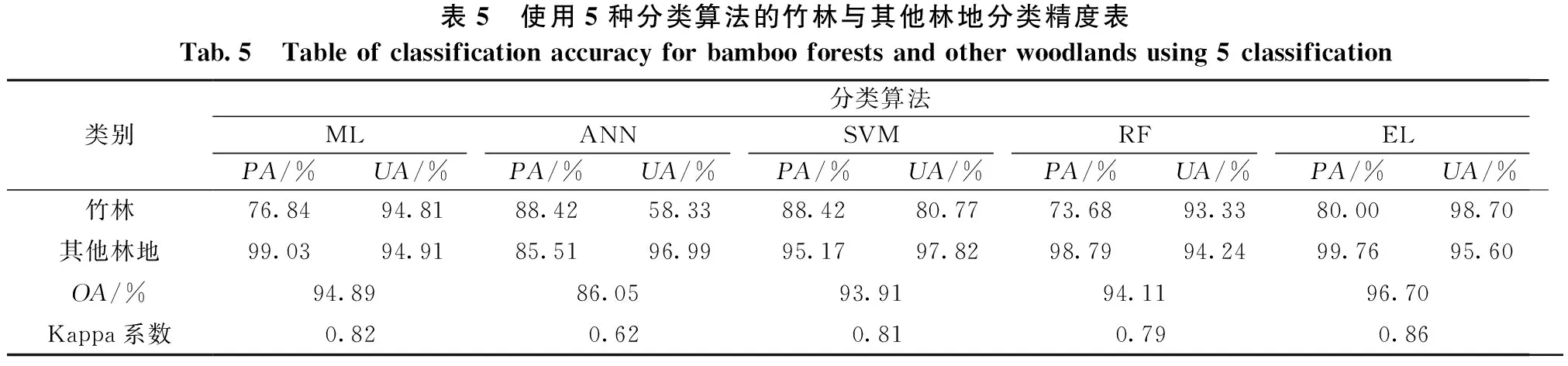
表5 使用5种分类算法的竹林与其他林地分类精度表Tab.5 Table of classification accuracy for bamboo forests and other woodlands using 5 classification类别分类算法MLANNSVMRFELPA/%UA/%PA/%UA/%PA/%UA/%PA/%UA/%PA/%UA/%竹林76.8494.8188.4258.3388.4280.7773.6893.3380.0098.70其他林地99.0394.9185.5196.9995.1797.8298.7994.2499.7695.60OA/%94.8986.0593.9194.1196.70Kappa系数0.820.620.810.790.86
3.2.3 阔叶林与针叶林
第三层次为阔叶林与针叶林的提取,其分类精度如表6所示。结果表明:集成学习算法(EL)为最佳的分类器,其总体系数和Kappa系数分别为86.71%和0.74;其次为支持向量机算法(SVM)与神经网络算法(ANN)。

表6 使用5种分类算法的阔叶林与针叶林分类精度表Tab.6 Table of classification accuracy for broadleaf and coniferous forests using 5 classification 类别分类算法MLANNSVMRFELPA/%UA/%PA/%UA/%PA/%UA/%PA/%UA/%PA/%UA/%阔叶林65.1877.2572.7796.4580.8093.3066.5282.7879.0295.68针叶林77.3765.3396.8475.1093.1680.4583.6867.9595.7979.48OA/%70.7783.8286.4774.4086.71Kappa系数0.420.680.730.490.74
3.3 总体分类结果及精度评价
在分类实验前对人工林进行了掩膜,最后将其与实验分类结果进行合并,形成研究区整体地类分布图。整体的分类精度如表7所示。结果表明:最优分类算法为集成学习算法(EL),其次分别为随机森林算法(RF)、支持向量机算法(SVM)、神经网络算法(ANN)、最大似然算法(ML)。EL的总体分类精度达到了87.18%,分别比其他4种算法提高了4.13、7.94、8.86、9.01个百分点,Kappa系数达到了0.82,展现出了极佳的分类性能。图6为分别使用ML、ANN、SVM、RF及EL的研究区整体分类结果图。
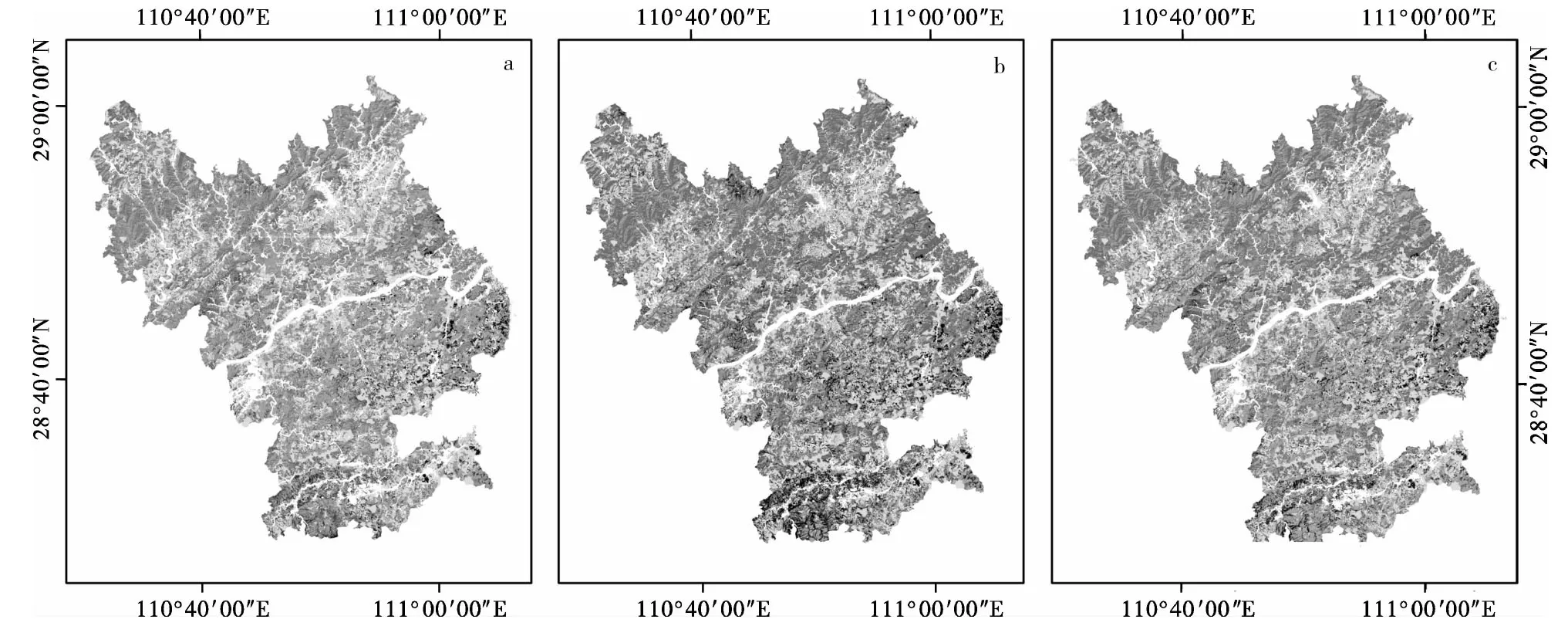
图6 研究区整体分类结果图Fig.6 Plot of overall classification results for the study area
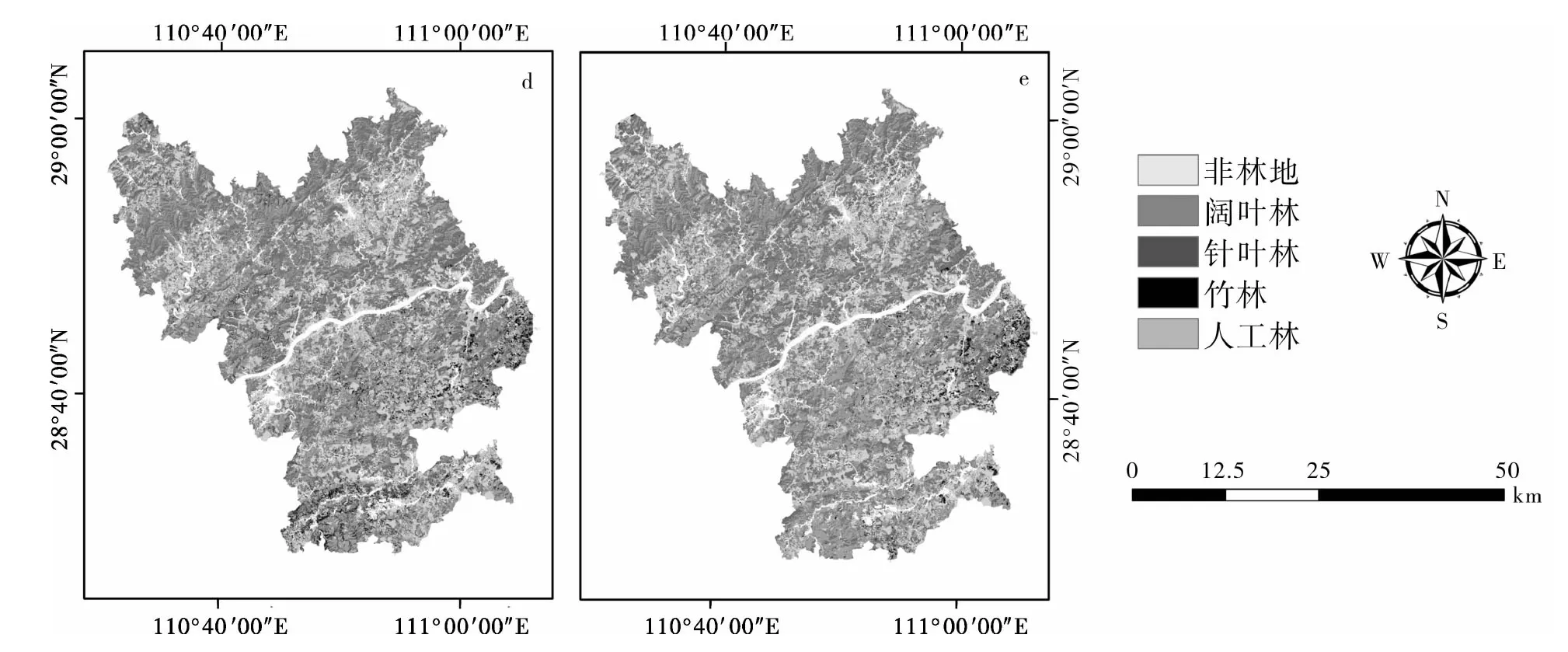
续图6 研究区整体分类结果图Continued Fig.6 Plot of overall classification results for the study area
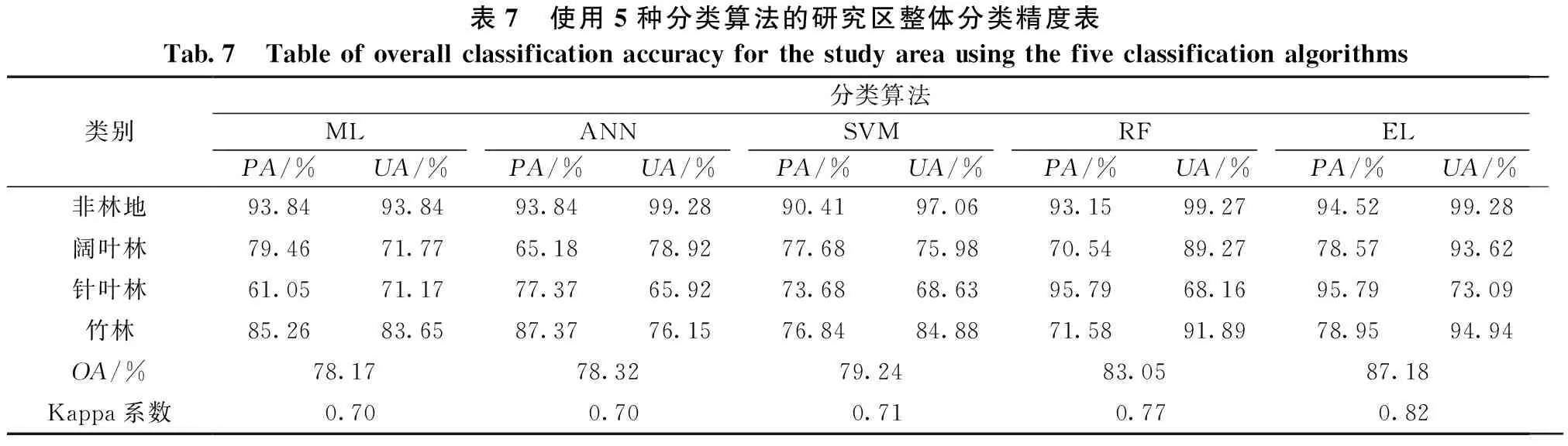
表7 使用5种分类算法的研究区整体分类精度表Tab.7 Table of overall classification accuracy for the study area using the five classification algorithms类别分类算法MLANNSVMRFELPA/%UA/%PA/%UA/%PA/%UA/%PA/%UA/%PA/%UA/%非林地93.8493.8493.8499.2890.4197.0693.1599.2794.5299.28阔叶林79.4671.7765.1878.9277.6875.9870.5489.2778.5793.62针叶林61.0571.1777.3765.9273.6868.6395.7968.1695.7973.09竹林85.2683.6587.3776.1576.8484.8871.5891.8978.9594.94OA/%78.1778.3279.2483.0587.18Kappa系数0.700.700.710.770.82
4 结论与讨论
4.1 结论
本研究基于Sentinel-2影像,提取光谱特征、植被指数以及纹理特征共31个分类特征参与实验,并通过随机森林算法对特征进行筛选,以求快速且高效地进行分类实验。以分层分类的思想分别使用ML、ANN、SVM、RF以及EL共5种机器学习分类算法进行分类并比较各分类结果和精度,从而获取研究区天然林最优的分类结果,主要结论如下:
(1)在对南方复杂环境下的天然林进行信息提取时,采用分层分类法逐级进行特征筛选,可以有效减少光谱等特征相似而导致的错分现象,从而提高各类别的分类精度。
(2)本研究分别使用ML、ANN、SVM、RF以及EL共 5种机器学习分类算法对三个层次下的分类结果进行比较可知,EL均为最佳算法。研究区整体的分类结果显示,EL的总体精度达到了87.18%,比RF、SVM、ANN以及ML的精度分别提高了4.13、7.94、8.86、9.01个百分点,Kappa系数达到了0.82,展现出了极佳的分类性能,表明EL能够有效提高天然林分类的精度。
4.2 讨论
本研究的出发点是为了使用遥感技术有效地提取复杂地形中的天然林信息。经过大量的实验与验证,总体达到了研究目的,但在实验过程中还有一些问题和方法需要进一步的完善与实验。
在选择影像时,需要考虑不同年份和不同时期的天气对影像质量的影响,因此每年可获得的达到标准要求的影像数量不同。而本实验需要对多时相的影像数据进行筛选,所以存在遥感影像的获取时间与地面数据采集的时间不完全一致的问题,实验的结果也可能会因此存在一定的局限性[17]。在样本的选择过程中,使用了随机抽样的方式进行样本点的选取,然而在确定样本数量和剔除质量较差样本等方面,仍存在一定程度的主观性。因此,实验结果可能存在一定的不确定性和偏差。
