基于改进YOLOv5的无人机实时密集小目标检测算法
2023-06-28奉志强谢志军包正伟陈科伟
奉志强,谢志军,*,包正伟,陈科伟
1.宁波大学 信息科学与工程学院,宁波 315211
2.宁波极望信息科技有限公司,宁波 315000
3.宁波大学 机械工程与力学学院,宁波 315211
随着无人机成本的下降,民用无人机市场进入快速发展时期。同时,基于深度学习的目标检测技术在近年来也取得了瞩目进步,这使得无人机与目标检测技术更加紧密,两者的结合可以在诸多领域如智能安防、智慧交通、智慧工地等发挥重要作用。在深度学习时代,基于卷积神经网络(CNN)的目标检测技术显著提高了目标检测的性能。然而,大多数目标检测模型都是基于自然场景图像数据集进行设计,自然场景图像与无人机航拍图像之间存在显著差异,这使得设计一种专门适用于无人机航拍视角的目标检测模型成为一项具有意义和挑战性的课题。首先,在实际应用场景中,对无人机航拍视频流进行实时目标检测,对算法模型的检测速度有较高要求;其次,与自然场景图像不同,由于无人机飞行高度高,航拍图像中存在大量小目标,其可提取特征少,且由于无人机飞行高度变化大,物体比例变化剧烈,导致检测精度低;最后,在实际飞行拍摄中存在复杂场景,密集小目标之间会存在大量遮挡,且易被其他目标或背景遮挡[1]。综上所述,需要设计一种适用于密集小目标场景下的无人机航拍实时目标检测模型,以满足实际应用场景需求。
在Faster RCNN[2]之后,对目标检测速度慢、实时性低的问题,提出了基于单阶段检测器(One-stage Detector)的YOLO(You Only Look Once)算法[3]和SSD(Single Shot MultiBox Detector)算法[4],及后续基于YOLO改进的YOLOv2[5]、YOLOv3[6]、YOLOv4[7]、YOLOv5。与Faster RCNN不同,YOLO系列算法直接对目标的坐标和类别进行回归,这种端到端的检测方式使得检测精度高且检测速度FPS达到了45,满足无人机实时视频检测的基本要求[8]。文献[9]在SSD的基础上提出了一种轻量、高效的特征融合模块,更充分利用特征,在损失较少检测速度的情况下精度有较大提升,且对小目标检测效果更佳。同时为了降低计算成本和存储空间,进行剪枝以实现模型压缩,但检测速度较慢,实时性不足以满足实际需求;文献[10]从特征金字塔网络(Feature Pyramid Network,FPN)[11]上出发,在FPN上添加一个融合因子描述相邻层的耦合度,来控制深层传递浅层的信息,使得FPN更加适应小目标,提高了小目标检测性能。但不同层的特征融合依旧是简单的线性操作(串联或求和),不能根据特征所在场景不同,进行自适应特征权重分配;文献[12]引入多尺度卷积模块,自适应优化特征权重,并根据小目标特点构建多尺度特征融合预测网络,选取多层级特征映射融合成高分辨率特征图,提升了无人机图像的目标检测精度。但没有很好解决在复杂背景下密集小目标存在大量遮挡,导致小目标大量漏检的问题。
针对上述问题,本文选取Ultralytics 5.0版本的YOLOv5算法模型作为实时目标检测算法。其中,Conv模块由一个二维卷积层、BN(Batch Normalization)层以及SiLU激活函数组成,将输入特征经过卷积层、激活函数、归一化层,得到输出层。C3模块是基于BottleneckCSP模块,去掉了残差输出后的Conv模块,Concat(通道维度拼接)后的卷积模块中的激活函数也由LeakyRelu变为了SiLU。SPP模块先通过一个标准卷积模块将输入通道减半,然后分别做卷积核大小为5、9、13的最大池化操作,再对这3次最大池化的结果与未进行池化操作的数据进行Concat操作。
本文在YOLOv5的基础上进行改进,改进后的结构如图1所示。首先,为了提高对小目标区域的关注程度,将空间注意力与通道注意力结合,提出一种轻量级的空间-通道注意力模块(Spatial Channel Attention Module,SCAM),得到基于空间和通道2个维度的注意力权重,可以增强小目标特征,减少复杂背景对小目标的干扰。其次,将SCAM运用到多尺度特征融合中,提出一种新的多尺度注意力特征融合模块(Spatial Channel Attention Feature Fusion,SC-AFF),改变原有基于固定权重分配的特征融合方式,利用SCAM动态获取不同尺度特征图的注意力权重,使每次特征融合过程都能更关注小目标区域的特征,提高多尺度特征融合效率。最后,用SCAFF替换原有Transformer Encoder结构中残差连接处的特征融合模块,提出一种新的基于空间和通道注意力的SC-Transformer模块,替换主干网络末端的卷积模块。通过自注意力(Self-Attention)机制,提高模型捕获特征图全局信息和丰富上下文信息的能力,优化复杂背景下密集小目标特征提取难的问题。
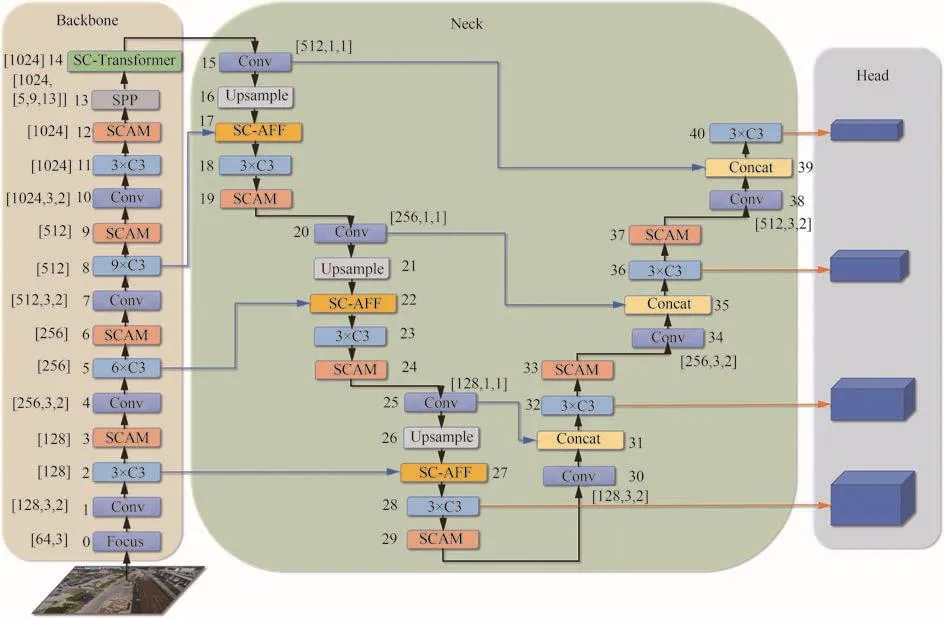
图1 改进YOLOv5s后的网络结构图Fig.1 Improved YOLOv5s network structure diagram
1 无人机航拍图像实时密集小目标检测
在满足实时性和提高检测精度的前提下,提出一种基于改进YOLOv5算法的无人机航拍图像密集小目标检测模型。改进算法的核心思想是利用注意力机制和自注意力机制,在保证模型实时性的前提下,通过修改YOLOv5网络结构,尽可能挖掘小目标密集区域的特征信息,减少背景噪声干扰,提高检测精度。主要创新点如下:首先,本文针对性地改进了CBAM注意力模块,提出空间-通道注意力模块SCAM,它更轻量化且更关注小目标空间维度特征。然后,提出一种新的注意力特征融合方式SC-AFF,能根据不同尺度特征图的特点,计算并动态分配基于SCAM的注意力权重。最后,在自注意力机制中加入注意力机制,用SC-AFF模块替换Transformer Encoder中残差连接处的特征融合模块。综上对YOLOv5网络结构进行以下2部分的改进:① 特征融合网络:在特征金字塔结构中,将Concat特征融合模块替换为基于SCAM的SC-AFF模块,并在特征金字塔网络中嵌入SCAM模块;② 主干网络:在YOLOv5主干网络末端插入SC-Transformer,并在每次卷积提取特征后嵌入SCAM模块。
1.1 空间-通道注意力模块
SCAM的关键思想是将输入的特征图Y分别沿空间和通道2个维度得到注意力权重矩阵Zc、Zs,来为输入特征图中的区域特征分配权重,对于密集小目标来说,单个特征区域会分配到更大的权重,权重越大表明该区域蕴含更多的有效目标,模型会将更多的注意力用来学习该区域特征,以便在有限的计算资源下更好地提取特征。
本文参考卷积注意力模块CBAM[13]中的2个注意力模块:通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spatial Attention Module,SAM)。CAM聚焦特征图中的有效特征是什么,即更关注特征的语义特征。通道注意力模块对输入大小为H×W×C的特征图Y在空间维度上使用平均池化来聚合空间信息、最大池化来收集更细的目标特征。同时使用这2种池化操作可以在减少特征图大小和计算量的同时,提高网络的表达能力。将池化后的2个一维向量送入全连接层运算,这里使用1×1卷积核实现特征向量间的权值共享。最后,经加和操作和sigmoid激活操作生成通道注意力Zc为
SAM则更关注特征的位置信息,聚焦于特征图中有效特征多的区域,是对通道注意力的补充。使用平均池化和最大池化对特征图Yc在通道维度上做压缩操作,得到2个二维特征图,将其基于通道Concat在一起得到一个通道数为2的特征图。为了保证最后得到的特征在空间维度上与输入的Yc一致,使用一个包含单个卷积核的隐藏层对拼接后的特征图进行卷积操作,最后经sigmoid操作生成空间注意力权重Zs为
由于CBAM在计算通道注意力时使用了全连接层对特征进行映射,全连接层的计算量较大,即使对通道特征压缩r倍,参数量仍然与输入特征图通道数的平方成正比。因此,当在网络中插入多个CBAM模块时,网络参数和计算量会大量增长。鉴于在中间特征图的相邻通道间的相关性更大,使用全连接层对通道特征进行映射会产生许多冗余计算[14]。因此,本文针对参数量大导致计算量大的问题,对CAM进行改进。选择使用卷积核长度为k的一维卷积对通道邻域内的k个通道进行特征聚合。
对改进后的CAM模块加入YOLOv5中的参数量对比如表1所示。CAM表示通道特征压缩率r=16下的通道注意力模块,CAM-表示用一维卷积轻量化后的CAM。可以发现,CAM-不仅参数量和计算量减少,且mAP50提高了0.09%,分析认为CAM在全连接层中引入了特征压缩来减少运算量,但也造成了特征信息丢失,这使得CAM的特征表达能力下降。
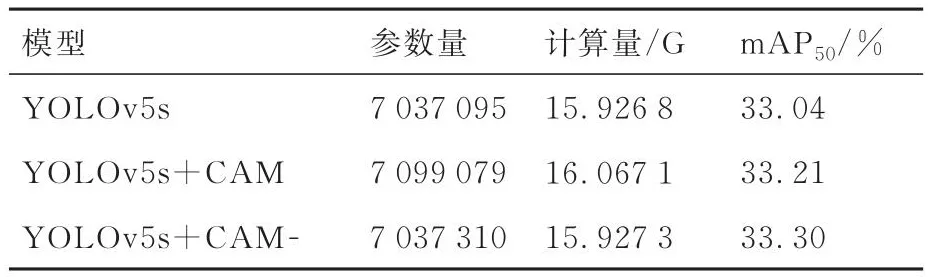
表1 改进CAM模块后参数量和计算量对比Table 1 Comparison of number of parameters and calculation volume after improvement of CAM module
另外,本文利用改进后的CAM和SAM模块提出一种新的SCAM结构,如图2所示。首先利用CAM得到通道注意力权重Zc,将其与输入的特征图Y相乘得到基于通道注意力权重的特征

图2 空间-通道注意力模块Fig.2 spatial-channel attention module
Yc经过SAM得到空间注意力权重Zs,其融合了通道和空间注意力。与CBAM不同的是,本文并未将Yc作为与Zs相乘的特征图,这是考虑到在无人机视角下,密集小目标众多,模型能否准确聚焦密集目标区域对检测精度会产生更大影响。然而Yc与Y相比具有更多的语义信息,这使得模型对同一类别目标变得更敏感,这可能会导致注意力区域更加聚集且感受野变小,处在聚集区域边缘的有效目标被识别为背景的概率变大。如图3所示,处在注意力边缘的特征丢失。

图3 注意力区域分布对比图Fig.3 Diagram of attention area distribution comparison
因此,想规避语义信息可能带来的影响,本文选择在更干净的原始输入特征图Y中聚焦目标位置区域,即用Y与Zs相乘得到特征图Ys。计算公式为
式中:Zs为Yc经过SAM获取得到,本身已经包含了一定通道注意力机制的先验知识,因此权重Zs与Zc相比,能更好地聚焦Y的有效特征。另外,将Yc与Ys进行加和操作是为了进一步综合空间图Yc,计算公式为
和通道2个维度上的特征,互补地应用于输入特征图。最后,sigmoid归一化,得到基于空间和通道注意力权重矩阵Zcs,权重的大小可以反映特征图中注意力分布情况,使得模型可以在更准确的注意力区域获取更多的有效特征。计算公式为
1.2 注意力特征融合模块
主干网络在对输入图像不断卷积提取特征的过程中,图像分辨率不断降低,这导致分辨率较小的小目标特征信息丢失。FPN通过简单的网络结构改变,在计算量增加较少的情况下,采用多尺度特征融合方式,大幅提升了小目标的检测性能。YOLOv5采用PANet[15]结构的多尺度特征融合方法,与FPN相比增加了自底向上的特征融合层,同时考虑浅层的高分辨率表征信息和深层的语义信息,以获得分辨率高、语义特征强的特征信息。这种多尺度特征融合方式有利于提取小目标特征。然而,特征融合会将不同层或分支的特征进行组合,通常操作为特征的简单求和或拼接。这使得模型默认对不同尺度特征图以固定的权重分配特征,而忽视了不同尺度特征图之间的差异[16]。与浅层大尺度特征图相比,深层小尺度特征图分辨率较低,小目标的有效特征信息更少,更容易被模型识别为背景噪声[17]。因此,在存在大量密集小目标的无人机目标检测任务中,不同尺度特征图的简单求和或拼接已经不能有效地提取并融合小目标的特征。
本文从特征融合角度出发,设计了一种基于SCAM的空间-通道注意力特征融合(SC-AFF)模块。核心思路是在特征融合过程中加入注意力机制,在通道和空间维度上对不同尺度特征图分配注意力权重,来动态地改变原有固定特征权重分配方式,提高模型对小目标特征提取能力提升。SC-AFF模块对不同尺度特征图的特征融合过程可以表示为
式中:Z代表经过特征融合后的特征图;X为特征金字塔中的低层高分辨率特征图;Y为高层高语义特征图经过上采样后的特征图;SCAM(X⊕Y)表示X与Yelement-wise sum后,经SCAM模块后得到的注意力权重矩阵,记为η。
图4为SC-AFF模块的结构示意图,虚线框中内容为原始特征融合结构。本文认为将更多有效权重分配给浅层高分辨率特征图X,可以融合更多小目标特征。同时,将高权重分配给具有更多深层高语义信息的特征图Y能减少浅层特征图中语言歧义的问题,提高模型的泛化能力。为了更加合理地分配权重,本文通过一种基于注意力机制的动态权重分配方法来分配2种尺度下的特征图权重。本文没有分别计算X与Y的注意力权重,而是将X与Y融合后的特征图,经SCAM模块计算注意力权重矩阵η。sigmoid后的η中权重范围为0~1,因此可用式(4)中的权重分配方法[16],使得网络能够在X与Y之间进行soft selection或weighted averaging。图中虚线表示用元素全为1的系数矩阵减X的权重矩阵得到Y的权重矩阵。与原始特征融合相比,SCAFF能利用更加灵活和准确的动态注意力权重来融合更多小目标特征,提高了最终的检测精度。
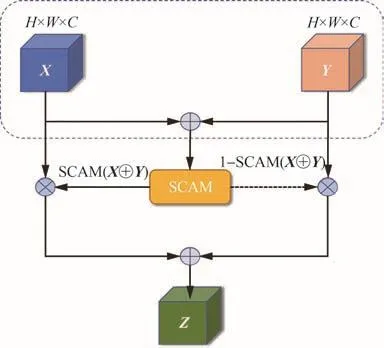
图4 SA-AFF模块结构示意图Fig.4 Structure diagram of SC-AFF module
本文采用SC-AFF模块替换YOLOv5特征金字塔网络中的Concat模块,替换后的结构图如图5所示。从输入图像开始,主干网络中的下采样操作会使得特征图分辨率不断减小,导致小目标特征大量丢失。上采样的目的是将较小特征图放大到与较大特征图相同尺寸,满足特征融合的前提条件,这并没有带来更多的特征信息,但会对特征图的质量造成影响。修改后的特征融合网络与原本直接由Concat操作进行特征融合不同,SC-AFF利用SCAM模块计算得到对应特征图的注意力权重,动态分配权重到不同尺度特征图,更好地融合上、下采样后特征图中的小目标特征,缓解特征融合过程中小目标特征丢失的问题。
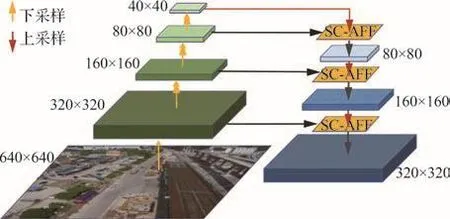
图5 替换SC-AFF后的FPN结构Fig.5 FPN structure after replacing SC-AFF
1.3 自注意力主干网络
在无人机小目标检测中,复杂背景更容易遮挡小目标,不利于小目标的特征提取。在主干网络中,提取特征图中的上下文信息,可以加强模型对有效目标与背景噪声的理解。但对复杂背景下的小目标来说,提取到的上下文信息会存在大量无效信息,因此需要过滤掉这些噪声,将更多注意力放到有效目标上[18]。
近年来,CNN和Self-Attention在计算机领域上都取得了长足的发展。随着Vision Transformer(ViT)[19]的出现,基于Self-Attention结构的模型在许多视觉领域中取得了优异的表现。传统卷积操作把局部感受野上得到的权值利用一个聚合函数在整个特征图中共享,固有的特征为图像处理带来了至关重要的归纳偏置。Self-Attention则采用基于输入特征上下文的加权平均操作,通过相似性函数动态计算相关像素对之间的注意力权重,使得注意力模块能够自适应地关注全局感受野下的不同区域,捕捉更多有效特征。卷积的局部性和Self-Attention的全局性存在互补的潜在性,因此将Self-Attention用于增强CNN的全局性成为了一种新的研究方向[20]。另一方面,注意力机制从本质上来讲是指从大量信息中筛选出重要信息,并让模型聚焦到这些重要的信息上。注意力权重的大小表示模型对某一信息的聚焦程度,也代表了信息的重要性。Self-Attention机制属于注意力机制的一种,减少了对外部信息的依赖,更擅长捕捉特征图内部的相关性,解决像素间的长距离依赖问题[21]。因此在Self-Attention网络结构中加入传统的注意力机制,在不同维度上增强模型的特征提取能力也是本文的一个研究点。
在计算机视觉领域,图像的每一个像素特征点都可以当做是一个RGB三通道组成的1×1×3三维向量。一张图像上有H×W个像素特征点,输入CNN模型的过程可以看做是将多个像素特征点组合输入到模型,模型不仅仅考虑某一个像素,而是考虑由多个像素组成的方形感受野。类似的,ViT将一张图像切分为多个图像块,并嵌入位置编码,得到输入序列X。利用Self-Attention机制计算出X上每一图像块与其他图像块之间的相关性,得到注意力权重。这种相关性权重分配让模型更多地集中在有效目标而不是无关背景上。与CNN相比更利于捕获在复杂背景干扰下密集小目标的特征。利用Self-Attention机制计算自注意力全权重Z的过程为
十月的阳光暖洋洋的,就像新麦面做的馒头,又松软又暄腾。莲米问我儿子取号冇,我说他父取了,叫桂生,说是桂子飘香时节生的。莲米说,这两个伢儿啊有福气,都赶着节气出生。我笑着说,我桂生中秋生的,有月饼吃;你二丫生在重阳,么事吃的都冇得,那福气可就差远啰!莲米说,那叫你桂生匀点儿福气给二丫唦。我停下脚步,拉了莲米一把,一本正经地说,唉,莲米呀,给这两个伢儿结个亲吧?莲米哈哈笑着说,那要看你桂生将后有冇得好造化。我说,中秋生的,么会冇得好造化呢?你将后看吧。
式中:X为输入序列;QKT用于计算每一个图像块对其他图像块(包括该图像块本身)的相关程度,通过softmax归一化得到权重系数,除以缩放因子来避免dK过大导致归一化后产生的梯度过小的问题。最后将权重系数和V进行加权求和,得到每个图像块的自注意力权重矩阵Z。另外,Q、K、V分别是维度为dQ、dK、dV的3个矩阵(一般设置dQ=dK=dV),由输入序列X分别乘以3个随机初始化矩阵WQ、WK、WV计算得到:
因此,通过Self-Attention机制,只需要对输入序列X进行几次矩阵变换就可得到不同图像块之间的注意力权重。然而,当模型对当前位置的图像块进行注意力权重计算时,Self-Attention会使得模型过度集中于自身位置而忽略其他位置的图像块特征,如图6所示,Q与KT进行矩阵相乘后,会导致对角线上的权重值较大。
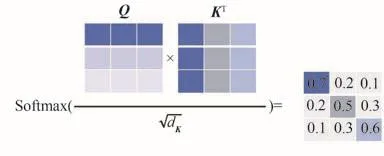
图6 注意力权重计算Fig.6 Attention weight calculation
基于以上需求和问题,本文在YOLOv5主干网络中引入基于Self-Attention的Transformer Encoder,可以在避免图6中的特征权重过度集中在对角线问题的同时,进一步加强主干网络对特征图中有效的上下文信息的提取能力。
另外,提出SC-Transformer结构,如图7所示,该模块包含2个子层,第1层为多头注意力模块(Multi-Head Attention Module);第2层为前馈神经网络,主要由一个多层感知机(MLP)组成。每一子层前应用LayerNorm,每一子层后应用DropPath。在样本数小的情况下,前者对隐含层做层归一化,能加速模型收敛,后者在训练过程中随机丢弃子图层,防止模型过拟合。每一子层之间用残差连接,避免由于网络深度的增加,导致梯度消失问题和权重矩阵退化,使得训练更加容易。最后将残差连接处的特征融合模块替换为SC-AFF模块,引入注意力机制,将输入的特征图作为SC-AFF模块的X,将DropPath的输出特征图作为Y。从通道和空间维度进一步聚焦有效特征区域。
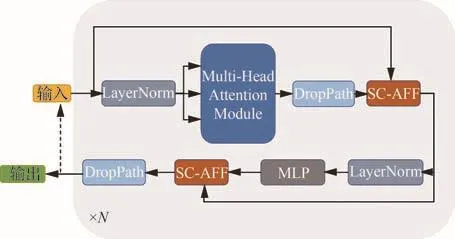
图7 SC-Transformer Encoder结构图Fig.7 Structure diagram SC-Transformer Encoder
Multi-Head Attention Module可以理解为多个带有Self-Attention机制的模块组成的Multi-Head Attention。将输入序列X分为多个子空间进行多组Self-Attention处理,将每一子空间得到的结果拼接起来进行一次线性变换得到最终的输出,如图8所示。这使得模型能够综合利用各子空间中的特征信息,缓解图6中过度集中自身位置信息的问题,有助于模型捕捉更丰富的特征信息。该过程可表示为
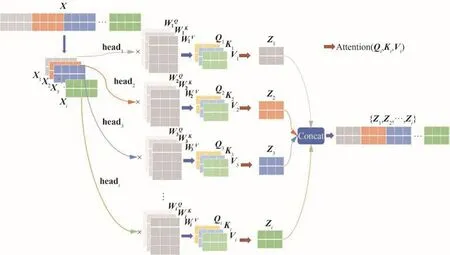
图8 多头注意力模块计算流程Fig.8 Multi-head attention model calculation process
式中:i为头的个数,一个头对应一个子空间。将输入序列X先经过式(8)得到Q、K、V,再分别输入到i个不同的子空间中,利用式(10)计算得到i个head,即i个自注意力权重矩阵Z1,Z2,…,Zi,再用Concat模块拼接在一起,最终点乘权重矩阵WO,得到最终的自注意力权重矩阵Z。
本文在YOLOv5主干网络中使用提出的SC-Transformer,首先需要生成一个(N,D)的二维序列X满足输入条件,如图8中的序列X。其中N是序列的长度,D是序列中每个向量的大小。然而,原始YOLOv5主干网络中都是H×W×C的三维特征图,因此需要将三维特征图转化为二维序列输入。以维度为224×224×3的特征图和P=16为例。首先,将224×224大小的特征图划分为N个16×16的图像块,其中N=HW/P2,共196个图像块。以取左上角这一图像块为例,在C个通道上展开得到1×(P2×C)维度的特征向量,作为X′的第1行向量。其他图像块操作相同,拼接得到一个196×768的二维矩阵X′,最后对X′进行线性变换,得到最终满足条件的输入序列X。序列化示意图如图9所示。
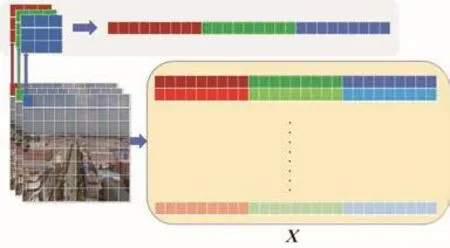
图9 特征图序列化Fig.9 Feature map serialization
多头注意力模块中的Self-Attention机制作为SC-Transformer中的核心模块,使得当前特征图中每个像素更关注其他像素特征,建立各个像素间的相关性权重,根据权重大小分析出不同目标之间存在的某种联系,从全局提取出更多的有效特征,获得更丰富的上下文信息。另外,用SCAFF模块替换残差连接处的特征融合模块,引入动态注意力权重,从通道和空间维度进一步提高特征融合能力。因此,在主干网络在中添加SCTransformer模块,可以增强主干网络在复杂背景下对小目标的特征提取能力。
2 实验与分析
本文使用VisDrone2021数据集来训练和评估模型,该数据集由天津大学机器学习与数据挖掘实验室AISKYEYE团队负责,全部基准数据集由无人机拍摄,包括288个视频片段,总共包括261 908帧和10 209个静态图像,其中选取了6 471张作为训练集,3 190张测试集和548张验证集。图像种类包括汽车、行人、公交车、自行车、三轮车、带篷三轮车、卡车、面包车、人以及摩托车10类,共260万个标注。图10是训练集中所有标签大小的分布图可以发现左下角聚集了更多的点,说明VisDrone2021数据集中存在更多的小目标,反映了无人机在实际应用场景的一般情况,与本文的研究背景和问题契合。

图10 训练集中所有标签的大小分布Fig.10 Size distribution of all labels in training set
本文使用Ubuntu20.04系统,实验环境为python3.6.13,pytorch1.8.0,cuda11.1。所有的模型都在NVIDIA RTX 3080Ti GPU运行,在相同超参数下(不一定最优)进行训练、验证和测试。其中,训练epochs设置为300,warmup epochs为3,初始学习率为0.01。采取mAP50、mAP75、mAP50:95、Params(参数量,Parameters)、Pre(精确率,Precision)、GFLOPs、FPS等指标作为模型性能的评价指标。mAP50、mAP75分别表示IoU阈值为0.5、0.75时所有目标类别的平均检测精度,其中mAP50反映算法对不同类别目标的综合分类能力,mAP75更能反映算法对目标边界框的回归能力。mAP50:95代表以步长为0.05,计算IoU阈值从0.5~0.95的所有10个IoU阈值下的检测精度的平均值。一般来说,IoU阈值越高对模型的回归能力要求越高,在高阈值下的检测指标越高,模型的检测结果更贴合实际目标。GFLOPs为每秒10亿次的浮点运算,用于衡量训练模型时的计算复杂度。Params值模型的参数量,用于衡量计算内存资源的消耗。FPS是指模型每秒能检测多少张图像,用于衡量模型的实时性。由于无人机航拍图像分辨率较高,且FPS与检测图像分辨率有直接的关系。一般来说,相同模型和运行环境下,检测时输入图像的分辨率越高,FPS越低。因此本文的FPS都是在检测1 504×1 504的高分辨率图像下测得,记FPS1504。
2.1 消融实验
为验证提出的空间-通道注意力模块SCAM和基于注意力特征融合模块SC-AFF,以及引入Self-Attention机制的自注意力主干网络的有效性,本文进行消融实验评估不同模块在相同实验条件下对目标检测算法性能的影响。消融实验中选择Ultralytics 5.0版本的YOLOv5s作为基准模型,设输入图像分辨率为640×640,训练300个epoch后的结果见表2和图11所示。
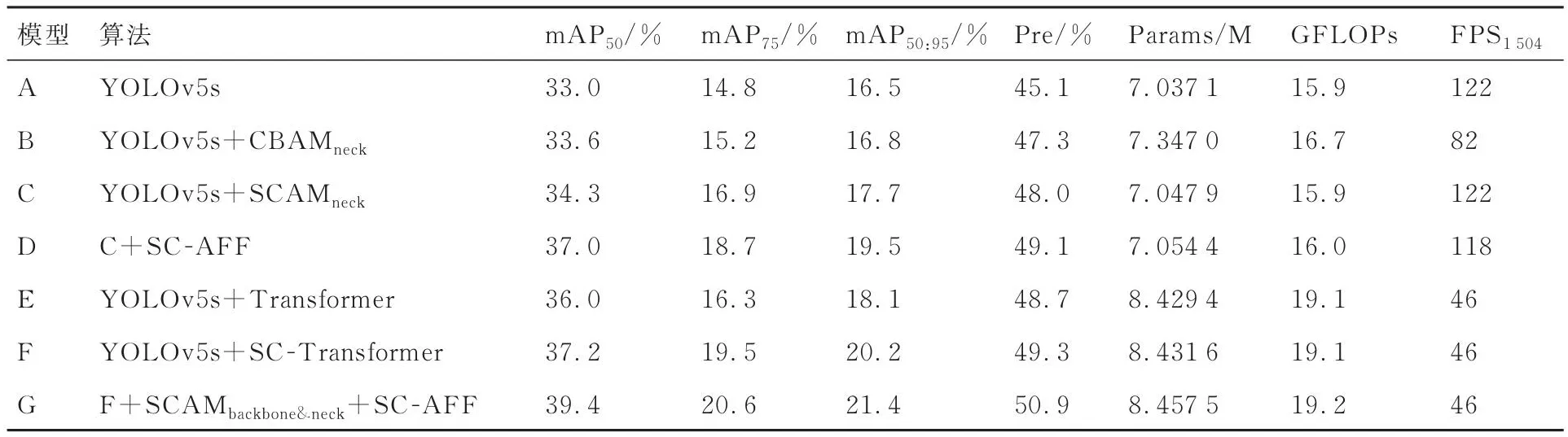
表2 消融实验Table 2 Ablation experiment
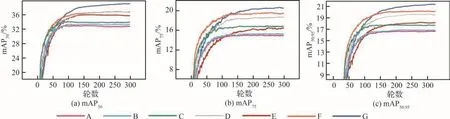
图11 消融实验的mAP50、mAP75、mAP50:95Fig.11 Ablation experiments of mAP50, mAP75, and mAP50:95
消融实验结果B和C表明SCAM具有更好的性能,mAP50比CBAM提高了0.7%,且网络参数量减少了0.299 1 M,FLOPs减少了0.8 G,FPS1504提高了40。模型D在替换SC-AFF注意力特征融合模块后与模型C相比,mAP50提升了2.7%,这说明将注意力机制与特征融合模块本身相结合比简单地将注意力模块嵌入到FPN中效果更好。即为不同尺度的特征图,根据注意力权重合理分配计算资源,能够在不增加过多计算量的情况下有效提高模型的检测精度。模型E在backbone引入Transformer模块后检测精度提升明显,在YOLOv5s的基础上提升了3.0%,证明了Self-Attention的有效性。但参数量增加了1.392 3M,GFLOPs增加了3.2,导致检测速度大幅降低。分析认为Self-Attention机制本身需要消耗较大的计算资源计算每张特征图中各像素之间的相关性权重,且检测速度与参数量和计算复杂度呈明显的负相关性。因此,考虑实际应用情况,为减少计算开销、提高训练效率、提高模型检测精度和速度,本文只在主干网络末端插入Transformer结构。模型F用SC-AFF模块替换Transformer残差连连接处的特征融合模块后,mAP50进一步提升1.2%,且模型收敛速度变快,如图11所示。这说明SC-AFF在Transformer中不仅能提高检测精度,还可以提高收敛速度。分析认为将残差连接处的特征融合方式改为了SC-AFF,为skip connection来的特征图计算注意力权重,将特征学习范围缩小到注意力区域,让网络朝着梯度更快更准的方向下降,因此提高了精度和加速了收敛。模型G在F的基础上在backbone和neck中添加SCAM,以及在FPN中替换SC-AFF模块,验证最终改进模型在网络规模为s下的性能。最终的mAP50比模型F提高了2.2%,比YOLOv5 baseline提高了6.4%,进一步说明了这2个模块的有效性,证明本文改进方法在YOLOv5的基础上大幅提高了检测精度,且保证了实时性。
2.2 模型选择实验
为了适用与不同的应用场景,YOLOv5通过调节网络深度(depth_multiple)和网络宽度(width_multiple)参数,来改变网络整体规模大小。在本文实验中,YOLOv5n是YOLOv5 6.0版本提出的新模型,网络规模最小,具有最小的参数量和计算复杂度,且检测速度更快,但检测精度不如网络规模更大的YOLOv5s、m、l 和x。因此,需要在不同大小的网络规模中选择一个最适合无人机小目标实时目标检测的模型,其应具备基本的检测速度和较高的检测精度。
本文在VisDrone2021数据集上,根据不同网络规模参数(n、s、m)和输入图像分辨率参数(640、1 024、1 504)进行改进前后的对比实验,实验结果如表3所示,其中YOLOv5n是6.0版本的网络结构。
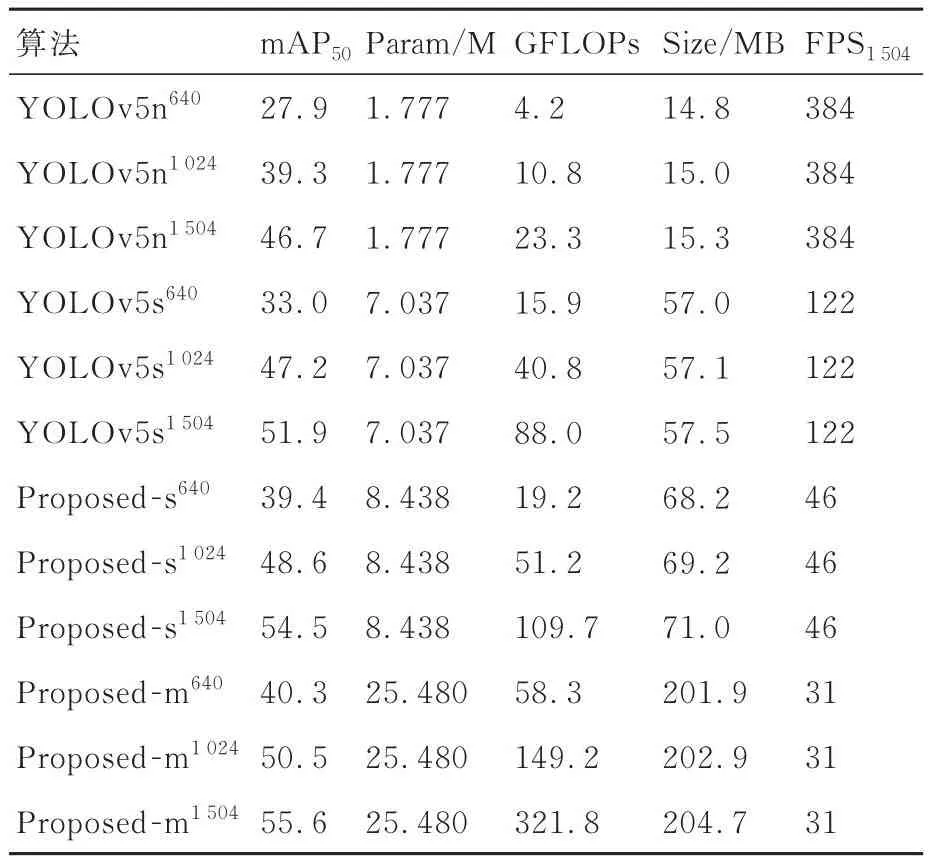
表3 训练时不同输入图像分辨率和网络规模的影响Table 3 Effect of different input image resolutions and network size during training
无人机航拍图像往往分辨率高,由于小目标分辨率低,高分辨率图像可以保留更多的细节特征,最终的检测性能也更好。如表3所示,在训练阶段,YOLOv5s输入图像分辨率参数为1 504时,mAP50比640提高了18.9%,且FPS保持不变。分析认为,由于网络结构和规模并未改变,训练时输入图像分辨率的增大对模型的参数量和实时性都没有影响。因此,可以提高模型训练时输入图像的分辨率,实现在不损失检测实时性的前提下,大幅提高检测精度。然而,高分辨率的输入图像使得计算量显著增长,训练时间成倍增长。以Proposed-s模型为例,对于分辨率参数为1 504的图像,在本文实验环境下训练1 epoch需要15 min 32 s左右,且GFLOPs达到了109.7,是Proposed-s640的5倍。对于网络规模更大的模型,由于其参数量和计算量更大,训练时间将更长,且模型权重文件大小过大导致部署难度上升,如Proposed-m模型的文件大小超过200 MB,这些因素可能无法满足实际应用场景需求。另外需要注意输入图像分辨率过高会导致模型计算过于复杂,出现过拟合现象,导致检测精度降低。因此不能一味地提高输入图像分辨率。
对于实时性,如表3所示,YOLOv5s640比YOLOv5n640参数量增加5.26 M,计算量增加11.7 GFLOPs,FPS降低了262。说明随着网络规模的增大,计算量和参数量都显著增大,检测实时性下降明显。另外,如图12所示,检测阶段输入图像的分辨率不仅对检测速度产生影响,还会影响检测精度。随着检测时输入图像分辨率的增大,FPS整体呈下降趋势。当分辨率参数由320增加到1 024和由1 920增加到2 048时,对FPS的影响较小,由1 024增加到1920时,影响较大。当分辨率参数达到4 096时,FPS最低。说明检测时图像分辨率的大小会对检测的实时性产生一定影响,且无人机航拍图像分辨率较高,因此对模型实时性的要求更高。另外,随着检测时输入图像分辨率的增大,mAP50呈现快速上升后缓慢下降的趋势。说明检测图像分辨率大小会影响检测精度,分析认为在检测阶段,分辨率越高意味着目标的特征信息更丰富,特别对于密集小目标来说,分辨率的高低直接影响小目标细节特征是否得到保留。然而,从图中发现分辨率参数由1 504增大到4 096的过程中,mAP50开始下降。分析认为过高的检测分辨率导致检测模型与训练时的输入图像分辨率相差过大,出现模型学习到的特征参数与检测图像不匹配的问题,导致检测精度不升反降。因此,在训练阶段的图像分辨率应与检测时的分辨率相差不大,避免过拟合现象的发生。在VisDrone2021数据集中,大多数图像分辨率为1 360×765与1 920×1 080,因此本文折中采用1 504分辨率参数作为训练和检测时的图像分辨率,实验表明在保证足够的实时性的前提下,检精度更高。
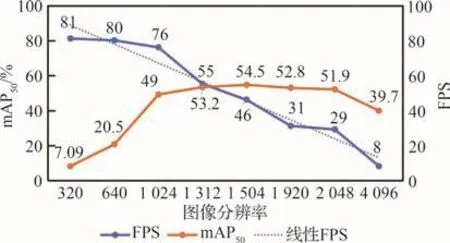
图12 Proposed-s模型在不同检测图像分辨率下的FPS及mAP50变化图Fig.12 Variation of FPS and mAP50 of Proposed-s model at different detection image resolutions
综上实验结论,本文以检测精度和速度为侧重点,同时考虑模型实际部署难度,考虑到l和x规模下的模型实时性会因为网络规模的增大而大大降低,且n规模下模型的检测速度性能过剩、检测精度较低。因此本文认为Proposed-s模型参数量和计算量较低,具有更好的实时性和检测精度,能更好地满足实际项目需求。
2.3 对比实验分析
为验证本文改进后的目标检测算法相比与其他算法的优越性,本文与各种先进的目标检测算法进行对比实验,主要测试算法的检测精度和检测速度,结果如表4所示。首先与一些经典的目标检测算法做对比实验,再与Ultralytics 9.6.0版本的YOLOv3算法、YOLOv4以及YOLOv5-v6.0版本模型进行对比。其中,YOLOv3-SPP使用SPPNet[27]中的空间金字塔池化(Spatial Pyramid Pooling,SPP),在主干网络中实现多尺度的特征融合,其mAP50较YOLOv3提高了0.2%,说明添加该模块后检测精度有所提升,且YOLOv4、YOLOv5中也使用了SPP模块。
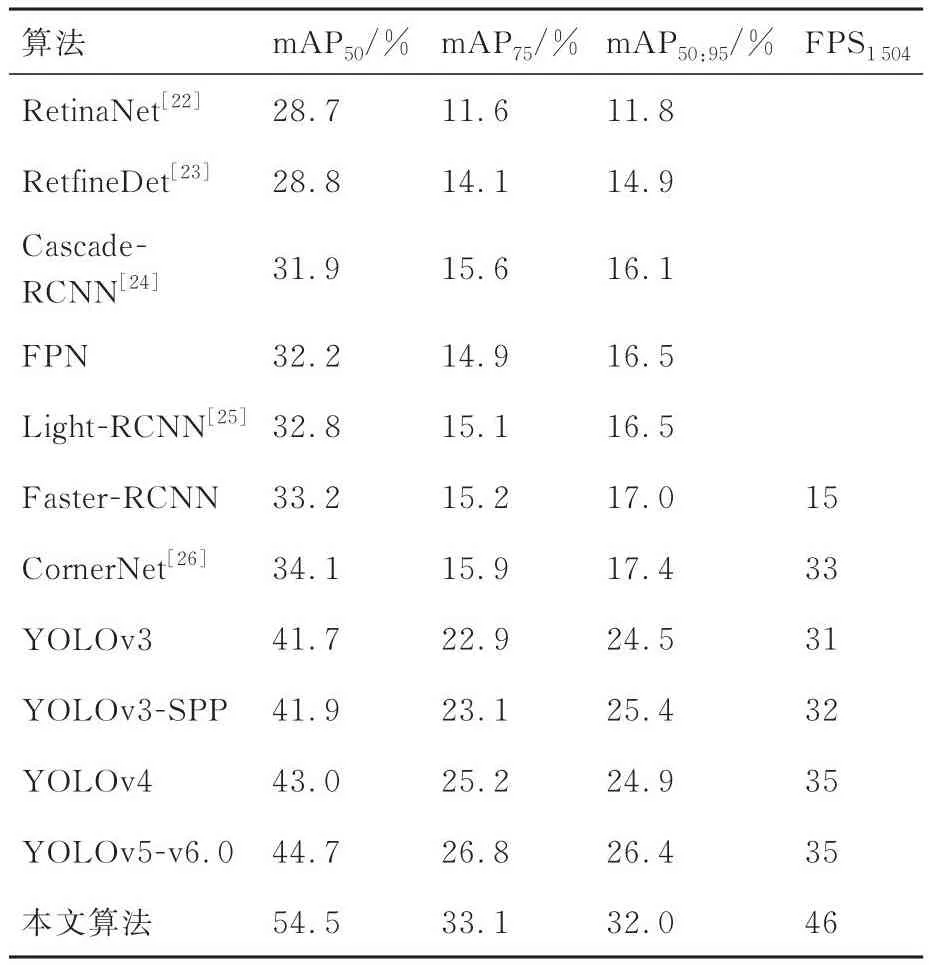
表4 不同目标检测算法的对比实验Table 4 Comparison experiments of different object detection algorithms
由表4可得结论,本文所提出的改进算法在保证基本的实时检测的前提下,检测精度也优于其他算法,mAP50比YOLOv4提高了11.5%,达到54.5%,比YOLOv5 6.0提高了9.8%,且FPS可达到46。综合来看,本文提出的算法在backbone引入注意力机制和自注意力机制,将更多注意力聚集到密集小目标区域,提高小目标特征提取能力;同时在neck的特征融合网络中引入了注意力机制,动态分配不同尺度特征图的权重,提高小目标特征图融合能力。本文改进算法在保证一定的实时性的前提下,有效地提高了小目标的特征提取能力,使得模型在处理无人机航拍图像目标检测任务时具有更大优势。
2.4 算法有效性分析
为验证改进算法在实际场景中的目标检测效果,本文使用VisDrone2021测试集中的具有代表性并且检测较为困难的图像进行测试,评估算法对所有类别目标的实际结果并可视化分析。检测效果如图13所示。

图13 不同困难条件下的检测效果图Fig.13 Diagram of detection effect under different difficult conditions
图13(a)为街道实际拍摄场景检测效果,该场景下存在大量遮挡的小目标。改进后的算法可以很好检测出被树遮挡的不同种类车辆,且远处骑车的人和自行车也可以区分开来,说明模型能够检测出受遮挡和重叠度高的小目标。图13(b)为检验光线变化大情况下对检测效果的影响,图中存在昏暗场景下的密集人群以及光线充足场景下的行人,可以发现模型受光线变换影响较小,在昏暗场景依旧具有较好的检测能力。图13(c)为高空拍摄下的检测效果图,路上的行人目标极小,但都能被准确地检测出来,说明模型对小目标的检测能力突出。图13(d)为实际拍摄场景中可能由于无人机或摄像头云台转动过快导致的拍摄图像模糊失真的情况。可以发现模型依旧可以检测出模糊场景下的目标,说明算法具有较好的鲁棒性,以应对实际情况。
为验证本文改进算法在密集小目标场景下的检测优化效果,选取VisDrone2021测试集中不同环境背景条件下的密集小目标场景图像作为测试对象,做可视化对比。如图14所示,图14(a)为改进后的算法,图14(b)为YO-LOv5s baseline。选取街道、市场、白天与夜晚路口等场景作为检测对象。改进后算法通过注意力机制,强化了网络对密集小目标区域的特征提取能力。在不同尺度特征图融合中引入注意力机制动态分配权重,使得模型可以更好地结合不同尺度下的小目标特征,保留更多特征融合后的小目标特征信息。在主干网络中引入自注意力机制,通过弱化背景噪声干扰、提高全局特征提取能力,来强化小目标区域特征。如图14所示,在处理密集小目标时具有更好的性能,不仅能减少漏检和误检,且受环境光照变化的影响也更小。总的来说,改进后的YOLOv5算法检测精度有一定提升,且对于密集小目标区域检测效果提升明显。
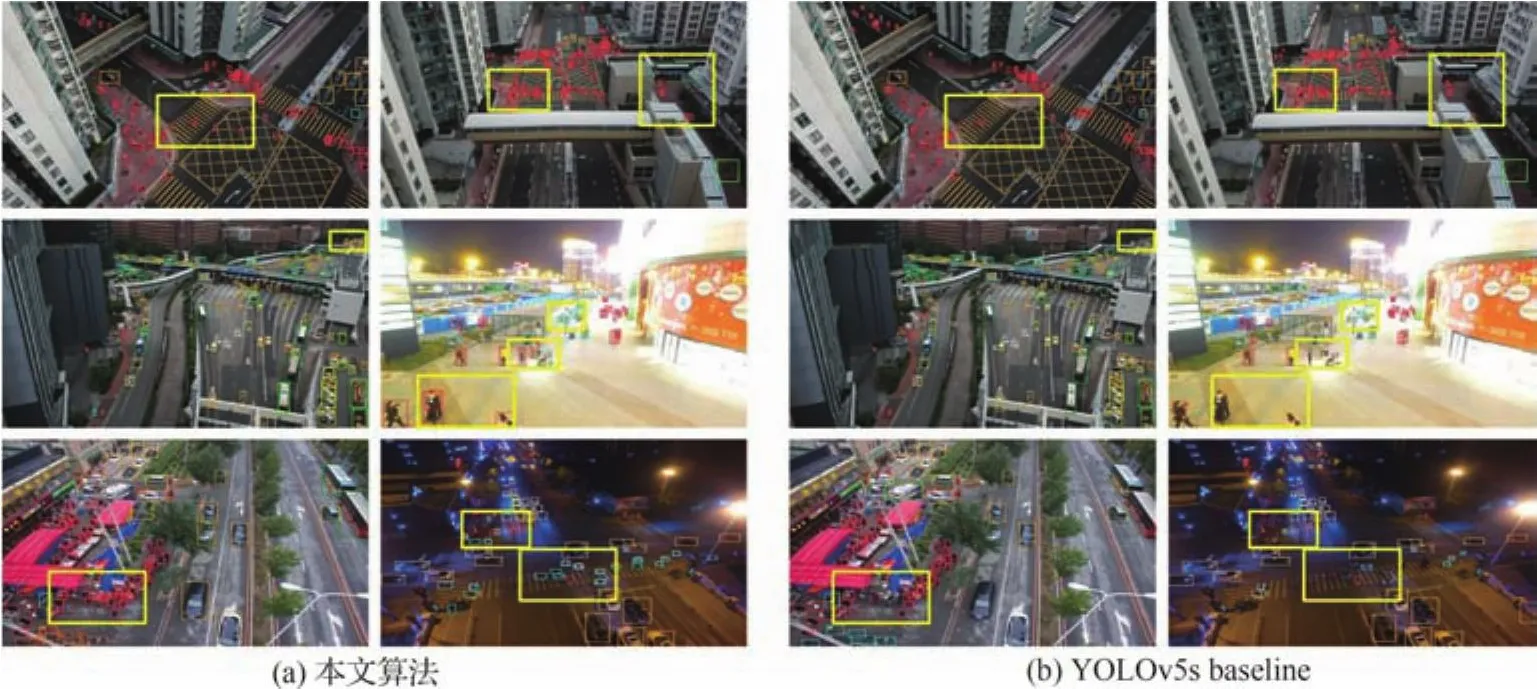
图14 检测效果对比Fig.14 Comparison of object detection results
3 结论
本文提出一种基于改进YOLOv5的目标检测算法,意在提高其在密集小目标场景下的检测性能,用于实时的无人机航拍目标检测任务。
1) 在不损失过多精度的情况下,大量降低参数量和计算量。另外,使模块更侧重于捕获空间维度的特征信息,减少了注意力过度聚集导致的特征丢失问题。模型可以根据注意力权重大小分布,将更多计算资源聚焦到密集小目标区域,减少复杂背景的噪声干扰,提高小目标特征提取能力。经实验,该模块计算开销不大,效果明显,可以在主干网络和特征融合网络中多次使用。本文进一步提高了特征融合效率,特别是小目标区域特征。并提高了输入图像的全局特征提取能力,弱化背景噪声的干扰。
2) 进一步提高了主干网络对密集小目标区域的特征提取能力,并加速收敛。在Vis-Drone2021数据集中的实验结果表明,与其他目标检测算法相比,本文提出改进算法在大幅提高检测精度的同时保证了基本的实时性,可以应用在实际无人机实时目标检测任务中。
3) 本文算法在引入Transformer Encoder结构后,参数量、计算量大大增加,且实时性大幅降低,因此可以进一步研究如何融合Self-Attention与CNN来实现更加轻量化且高效的模型。另外,对于如何利用无人机有限的机载计算资源,实现高性能的目标检测任务这一问题,可以继续展开对改进后的YOLOv5网络模型轻量化的研究。
