基于服务功能链的网络功能资源调度机制设计与实现*
2023-06-27陶思言陈光建
陶思言,陈光建
(1.四川轻化工大学物理与电子工程学院,四川 自贡 643000;2.四川轻化工大学计算机科学与工程学院,四川 自贡 643000)
0 引言
传统的硬件中间件设备往往高度定制化,其容量固定且有限,只能够处理固定量的网络负载。然而,在现实部署中,入口流量需求会随着波峰、波谷时间以及特殊网络时间产生大规模的波动。传统硬件设备不支持动态启动新的硬件设备以应对突发增长的流量需求。
网络功能虚拟化(network function virtualization,NFV)技术的核心优势之一是支持灵活资源调度,根据在线实时变化的流量负载按需分配底层资源,在保障系统性能的同时实现底层资源利用率最大化。对于每个网络功能,NFV 通过弹性扩展网络功能实例实现底层资源的动态调度。目前已经有大量的资源调度机制被提出,主要分为两类:基于流量速率的资源调度机制以及基于网络功能状态的资源调度机制。然而,上述机制均将每个网络功能视为独立个体,忽略了邻居网络功能节点对资源调度的影响。
本文提出了一种基于服务功能链的网络功能资源调度机制(graph-based scaling detection mechanism,GSDM),将邻居节点的状态信息加入到控制策略中,通过刻画网络功能连接关系有效地提高资源调度性能。本文的创新性工作主要有以下4 个方面:
1)将流量速率信息以及网络功能实时运行信息结合在一起实现资源调度。流量速率信息难以直接对网络功能运行状态信息进行刻画,并且容易受到流量多样性的影响,包括数据包大小以及类型等。网络功能实时运行状态信息则包含许多不可避免的噪音信息,干扰资源调度结果。流量速率信息以及网络功能实时运行信息可以互补结合在一起,有效提高资源调度机制的性能。
2)将综合特征序列信息作为资源调度策略的输入信息。相比于单一时间点的特征信息,特征序列有利于准确过滤噪音信息,以及实现扩展行为的提前预测。通常情况下,网络功能实例启动需要若干秒,基于序列的提前预测能够有效缓解实例启动过程中的性能下降。GSDM 基于长短时记忆网络(long short-term memory,LSTM)模型进行设计。LSTM能够有效捕捉序列信息之间的关系。
3)考虑到网络功能连接关系对资源调度策略的影响,将邻居网络功能的特征序列加入到控制策略中。将邻居节点信息也加入到控制策略中,有效刻画网络功能连接信息,提高资源调度及时性。
4)考虑到不同邻居节点对最终检测结果的不同影响,设计了网络功能级的注意力机制,为不同邻居节点设置不同的权重。注意力机制能够使得关键邻居节点对最终结果有更大的影响力,并且忽略不重要的邻居节点。
1 关键技术
GSDM 基于时间序列信息进行扩展动作预测。目前,人工智能领域已经有大量的模型用于刻画时间序列信息,例如:RNN,LSTM 等。注意力机制在人工智能领域也得到了广泛应用,能够对序列信息进行处理,抓取其中的关键信息并赋予更高的权重。本章将对时间序列神经网络模型以及注意力机制进行具体介绍。
1.1 时间序列神经网络模型
LSTM 是一种特殊的RNN 网络模型,通过引入输入门、遗忘门以及输出门,能够解决RNN 模型存在的长期依赖问题并对长序列信息进行处理。目前,LSTM 模型已经成功应用到各类人工智能问题中,并取得了显著的效果,例如:计算机视觉[1]、人类活动行为分析[2-3]以及自然语言处理[4]等。
图1 展示了LSTM 神经网络模型状态转换过程,其具体计算过程如下公式所示。
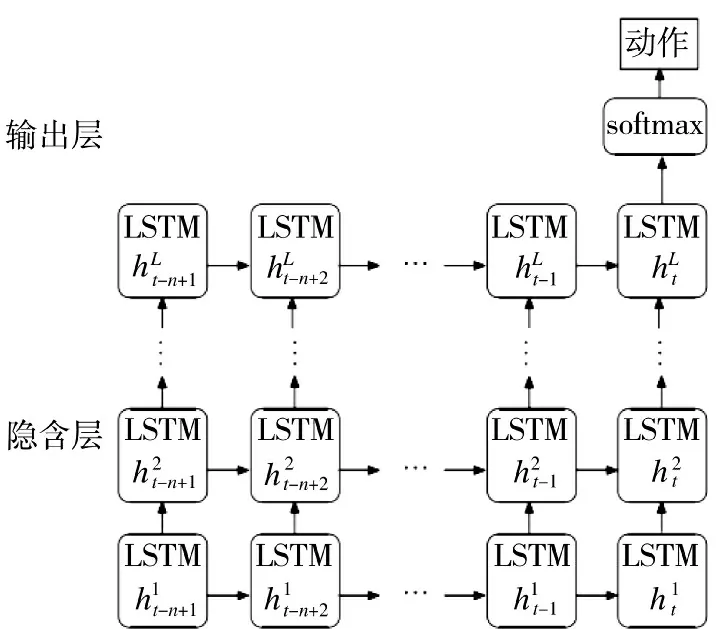
图1 LSTM 神经网络模型Fig.1 LSTM neural network model

1.2 注意力机制
在GSDM 模型设计中,将邻居节点的特征序列信息作为输入信息加入到控制策略中,有效提高资源调度的及时性。然而,观察到不同的网络功能对于最终的扩展动作影响力是不同的。因此,采用注意力机制为不同的邻居节点设置不同的权重,更加有效地扩大重要邻居节点的影响力以及避免不重要邻居节点的干扰,有效提高模型性能。
目前,注意力机制已经大量应用到分类任务中,并取得了显著的性能提升效果[5-8]。注意力机制首先计算各个输入向量与输出向量的匹配程度,匹配程度高的节点得到高权重,反之,匹配程度低的节点得到低权重。具体来讲,基于输入序列的隐含层表示向量,注意力机制聚合输出一个序列向量s。在最终向量s 中,每个节点的内部状态信息ht被赋予不同的权重。注意力机制的计算过程如下所示:1)根据ht得到注意力层的隐含状态向量ut;2)每个节点的影响力表示向量at根据ut与uw之间的相似度利用softmax 计算得到,其中,uw作为整个序列信息的上下文查询表示向量,起初被随机设定,并在训练过程中不断得到更新;3)最终输出向量s 根据H 向量矩阵的加权平均获得。具体计算过程如下公式所示:
2 GSDM 设计
为了实现资源调度,GSDM 包括两个部分:1)特征采集模块:在数据层实时采集所有网络功能的综合状态信息;2)GSDM 模型:根据采集得到的状态信息,在控制层利用神经网络模型计算每个网络功能对应的扩展动作。下文将分别对这两方面内容进行具体介绍。
2.1 特征采集模块
特征采集模块安装在数据层,用于全面测试所有网络功能的运行特征数据。本文采用综合特征作为输入,包括以下3 个方面的特征:流量速率特征,硬件层特征和应用层特征。以下部分将对3 种类型特征的采集方式进行具体描述。
1)流量速率特征:包括入口流量速率和出口流量速率。目前,大部分的NFV 系统(例如:Open-NetVM),提供了成熟的接口用于准确获取入口以及出口的流量速率。在原型系统实现中,利用NFV 系统提供的接口对流量速率信息进行采集。
2)硬件层特征:GSDM 包含CPU 利用率和内存利用率两个特征。现有的NFV 系统在虚拟机或者容器中对网络功能进行实现。虚拟机或者容器技术使得每个网络功能占用单独的CPU 以及内存区域,不会被其他的系统进程所调用。因此,在原型系统实现中,特征采集模块以privileged 模式运行可以准确地获取这些硬件层资源利用率信息。
3)应用层特征:将数据包处理时延作为代表有效地反映当前网络功能的运行状态。设计了一种轻量级的时延测量方法。特征采集模块自动生成样本流量并发送到各个网络功能进行时延测量。对于网络功能而言,它们负责接收样本数据包,并执行与其他数据包一样的处理操作,最后默认转发到特征采集模块。网络功能的时延由发送时间和接收时间之间的时间差值计算得到。样本流量的速率可以由用户自主地进行控制,并只占所有处理数据包的很小部分,并不会影响整体系统运行。在设计的原型系统中,样本数据包采用具有特殊端口的UDP 数据包。对于IPv4 数据包而言,8 bit 的ToS 字段用于存储被测量的网络功能的“Service ID”,从而方便地对每个网络功能的时延进行计算。在时间计算精度方面,采用CPU 硬件时间戳的方法进行测量。在原型系统实现中,采用的CPU 时钟频率是1 200 MHz。因此,计算的时延精度在纳秒级别。
2.2 GSDM 模型
GSDM 模型的整体结构主要由4 层组成:特征表示层、LSTM 层、邻居网络功能节点层以及输出层。以下部分将对每一层进行具体介绍。
2.2.1 特征表示层
对于每一个网络功能,将其连续n 个时间点特征组成的特征序列S 作为输入信息。每一个特征向量xt由五维特征组成:入口流量速率、出口流量速率、CPU 利用率、内存利用率以及数据包处理时延。特征序列信息能够有效地展示网络功能状态信息随时间的变化,帮助更好地预测扩展动作以及过滤噪音信息。
2.2.2 LSTM 层
利用LSTM 模型对每个网络功能的特征序列S进行计算,并得到每个网络功能的表示向量。LSTM 模型可以有效地捕捉序列信息之间的关系,并将其映射到低维向量空间。假设采用了L 层进行训练,将经过L 层LSTM 模型计算输出的隐含状态信息为赋值给,从而得到网络功能表示向量。LSTM 模型具体计算过程已经在1.1 节进行了具体介绍。最后,LSTM 层将所有网络功能的表示向量反馈到邻居网络功能节点层作进一步处理。
2.2.3 邻居网络功能节点层
考虑到邻居网络功能节点状态信息对资源调度结果的影响,加入了邻居网络功能节点层。将邻居网络功能节点集分为两个部分,分别是上流网络功能节点集F 以及下流网络功能节点集B。对于每一个在F 或者B 中的邻居网络功能节点,通过上述LSTM 层获取到其网络功能级别的表示或者。考虑到多种不同邻居节点对资源调度结果的不同影响,采用了网络功能级注意力机制来刻画影响力大小。最终,上流网络功能节点集表示sF和下流网络功能节点集表示sB通过以下的公式计算得到。其中,以及全部是注意力机制的参数。
2.2.4 输出层
最终输出层通过以下两个步骤共同完成:
1)向量聚合:将上流网络功能节点集表示sF,下流网络功能节点集表示sB以及当前网络功能节点表示sR集合得到了最终的表示向量m。
2)扩展动作概率计算:m 向量被反馈到softmax层得到所有扩展动作的可能性分布。这个过程通过下面公式计算得到。其中,是指所有可能扩展动作的概率分布,C 表示扩展动作空间大小,以及分别是权重矩阵以及偏差矩阵。在本文中,设置C=3,用于表示所有可能扩展动作的数目,包括扩容、缩容、保持不变3 种类型。
2.3 GSDM 训练方法

3 原型系统实现
本章对GSDM 模型训练过程以及原型系统实现进行了具体介绍,并对其他对比资源调度方案进行了具体说明。
3.1 GSDM 模型训练
采用深度学习框架TensorFlow 对GSDM 模型进行训练。为了实现模型训练,构建了一个数据集,并按照以下结果对超参数进行了设置。
1)数据集:为了实现模型训练,生成了多种不同类型的流量并将其应用到NFV 系统中,获取了大量的网络功能运行状态信息。对于每一个网络功能,标注了35 000 组数据,其中,80%用作训练集,20%用作测试集。对于每一个标注的数据,为其标注了对应的扩展动作“-1”“0”或者“1”,分别表示“扩容”“保持不变”以及“缩容”。
2)超参数设置:GSDM 模型的超参数设置如下所示:输入特征序列长度n=20,LSTM 层数L=2,隐含层维度大小d=200,最大上流网络功能集大小,最大下流网络功能集大小,学习率,正则项系数以及dropout 率0.5。
3.2 系统实现
在OpenNetVM 18.05 版本以及dpdk 17.08 版本的基础上实现了GSDM 原型系统。该原型系统搭建在若干服务器上,每一个服务器配备有两个CPU(Intel(R)Xeon(R)E5-2620 V3)以及两块10 G 网卡,运行在Linux 操作系统,其内核版本为3.10.0。在数据层,实现了特征采集模块,周期性地对所有网络功能的特征信息进行采集,周期为1 s。在控制层,将训练完成的GSDM 模型进行部署,并将采集得到的特征序列信息输入到训练完成的GSDM 模型计算对应的扩展动作,周期为1 s。
3.2.1 流量生成
采用开源流量生成器MoonGen[9],自动生成多种类型流量进行性能验证。MoonGen 安装在一个单独的服务器上,并且与安装原型系统的服务器进行直接连接。发包服务器发送以及接收数据包,并在时延和吞吐量两方面对GSDM 系统性能进行测量。总结了真实网络中常见的需要扩展动作的流量类型,包括缓慢增长型、快速短时型以及快速长时型3种。图2(a)~图2(c)分别对以上3 种类型流量进行了展示。
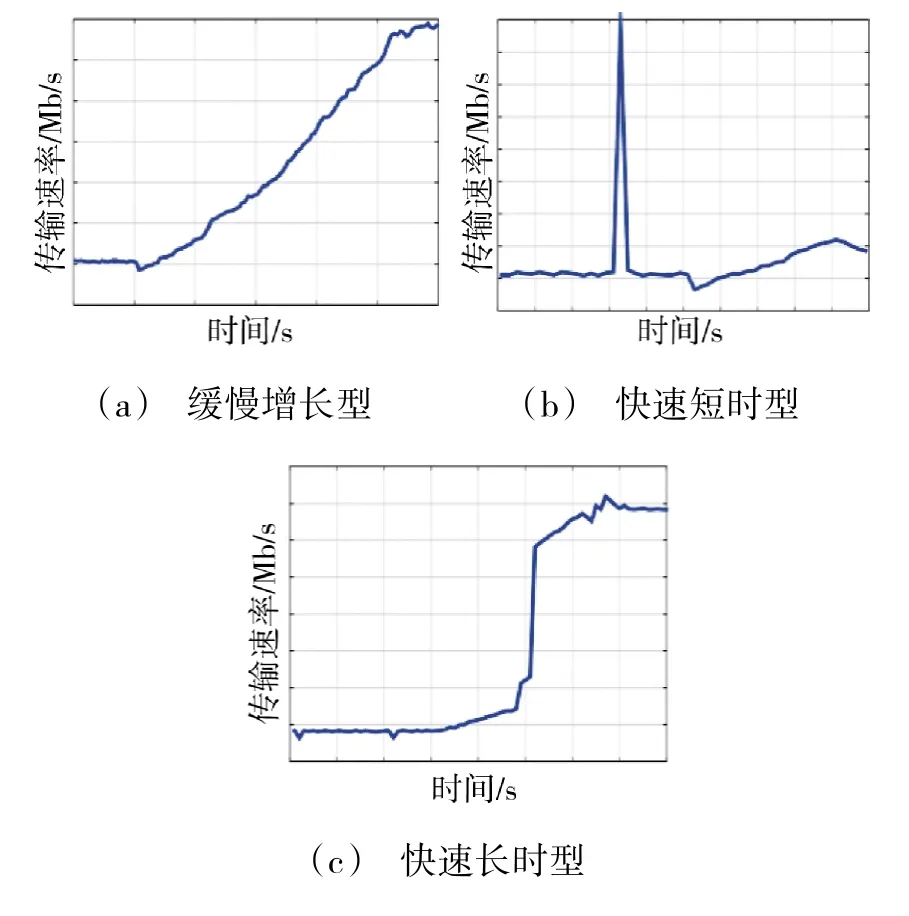
图2 3 种不同的流量类型Fig.2 Three different traffic types
3.2.2 流量生成
为了进行性能验证,对以下3 种网络功能进行了实现,包括虚拟专用网络,深度包检测以及网络监控器。这些网络功能按照顺序连接在一起组成服务功能链。
1)虚拟专用网络:利用IPsec 的AH 模式,实现了一个虚拟专用网络隧道。具体而言,利用AES算法对数据包进行加密,并将其封装到AH 中进行转发。
2)入侵检测系统:该网络功能基于SnortIDS 进行设计,通过数据包特征匹配识别网络攻击行为。
3)网络监控器:以数据包的五元组为哈希值,将数据包划分为不同的数据流。此网络功能为每条流计算对应的数据包数量。
3.2.3 对比资源调度方案
现有的资源调度机制根据入口流量速率或者网络功能实时状态信息进行资源调度。为了进行性能对比,对以下3 种类型的扩展机制进行了实现。
1)基于速率模式:对网络功能的单独实例进行处理能力测量,并假定网络功能处理能力与实例数目呈线性关系。一旦发现输入流量速率超过网络功能处理能力则触发扩展动作,增加一个实例保障系统性能。
2)基于状态模式:测量每个网络功能发生拥塞时的时延,并设置其为状态阈值。一旦监控得到的数据时延超过了阈值,则采取扩展动作。
3)基于MLP 模式:此方案将流量速率以及网络功能实时状态信息均作为输入信息,也即五维特征(包括入口流量速率,出口流量速率,CPU 利用率,内存利用率,时延),并利用多层感知器(multi-layer perceptron,MLP)构建一个全连接神经网络,建立五维综合特征与扩展动作之间的对应关系。
4 验证与评价
本章对GSDM 系统进行了性能验证并与其他资源调度方案进行了对比分析。性能验证包括3 个方面:
1)离线模型性能:基于生成的数据集在精准率、召回率、F1 值3 个评价指标上进行性能测量;
2)在线系统性能:基于实现的原型系统上在系统总开销、时延、吞吐量3 个评价指标上进行性能评价对比;
3)模型时间分析:对模型的离线训练时间以及在线运行时间进行分析,并进一步分析该扩展检测机制对NFV 系统性能的影响。
4.1 离线模型性能
将实现的GSDM 模型与其他3 种资源调度方案在3 个性能参数上进行了性能对比,包括精准率(precision)、召回率(recall)、F1 值(F1 value)。对于每种算法而言,将其结果标注为TP(true positives)、TN(true negatives)、FP(false positives)以及FN(false negativess)4 种类型。TP 是指样本以及预测结果均为+1 的数据;TN 表示样本与预测结果均为0 的数据;FP 是指样本为0 然而预测结果为+1 的数据,FN 表示样本为+1,预测结果为0 的数据。根据上述标注数据,采用以下公式所展示的方法对精准率、召回率以及F1 值进行计算。
精准率是指预测为正例的数据中预测正确的数据个数,能够有效地表示资源调度机制对噪音信息的过滤程度。高精准率能够避免错误扩展动作导致的不必要运维开销。召回率指真正为正例的数据中预测正确的数据个数,能够有效地表示资源调度机制的及时性。高召回率机制能够避免延迟的扩展动作造成的系统性能下降。通常情况下,精准率以及召回率此消彼长。F1 值根据精准率以及召回率综合计算获得,能够对机制性能作出综合测评。
图3 展示了具体的性能对比结果,发现GSDM同时实现了最高的精准率和召回率,也即同时实现系统性能提升以及底层资源利用率提升。将其他3种资源调度机制进行对比,发现最佳方案是基于MLP 模式方案。这也证明了综合特征相比于单一特征,能够实现不同的特征之间的性能互助,提升检测性能。与最佳的基于MLP 模式方案相比较,GSDM 模型在召回率方面提升了2.75%,在精准率方面提升了1.2%,在F1 值方面提升了2.17%。
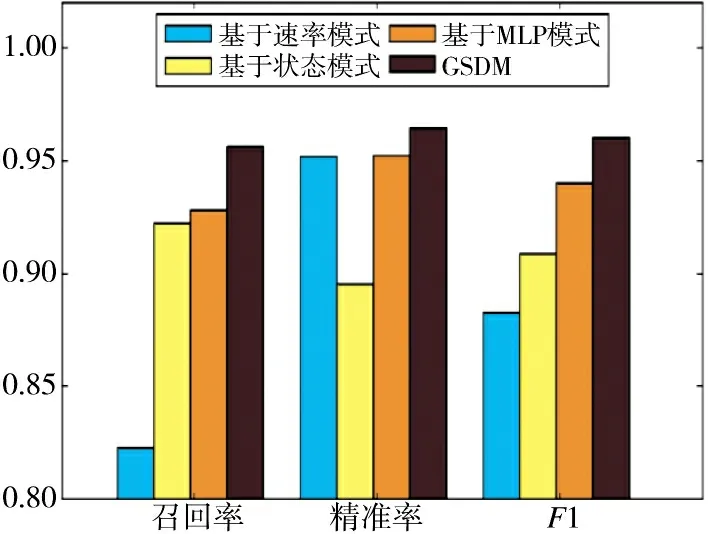
图3 离线系统总开销对比Fig.3 Comparison of total overhead of offline system
4.2 在线系统性能
4.2.1 性能指标
资源调度策略的评价指标必须能够综合考量资源调度的时间是否准确,包括过早检测造成的高运维开销以及过晚检测造成的系统性能下降两方面。通常情况下,运维开销以及系统性能两方面的目标是此消彼长的关系。如式(22)所示,将两者相加得到整体的系统开销,综合判断资源调度策略的性能。

图4 展示了在3 种流量场景下,GSDM 与其他资源调度机制的系统总开销对比结果。结果显示:在所有场景下,GSDM 系统均超过了其他机制,实现了系统总开销的最小化。以下部分将对每种流量场景下的具体信息进行分析说明。
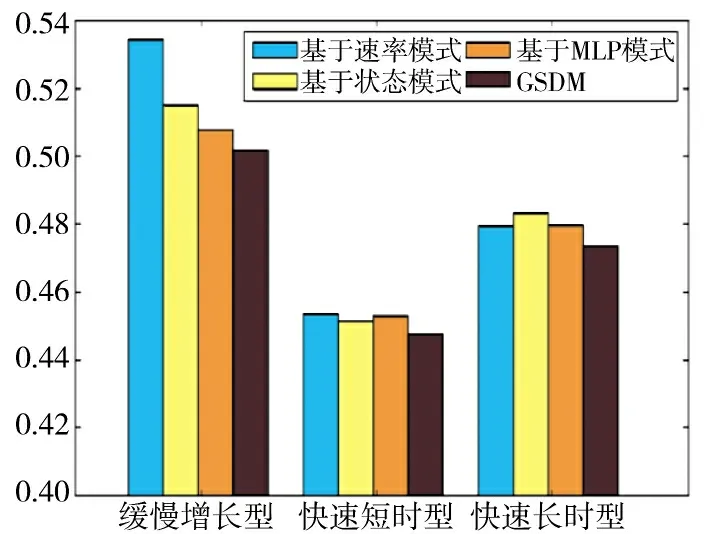
图4 在线系统总开销对比Fig.4 Comparison of total overhead of online system
4.2.2 缓慢增长型流量场景
图5 和下页图6 展示了缓慢增长型流量场景下的时延以及吞吐量变化过程。以纳秒的精度对时延进行了测量。为了更好地展示时延变化过程,对时延进行取10 的对数处理。面对变化的数据包大小以及类型,基于速率模式机制不能够应对流量多样性,导致延迟的扩展动作、数据包丢失惩罚以及系统性能的下降。

图5 缓慢增长型流量场景下的时延对比Fig.5 Delay comparison in slow increase traffic scenarios
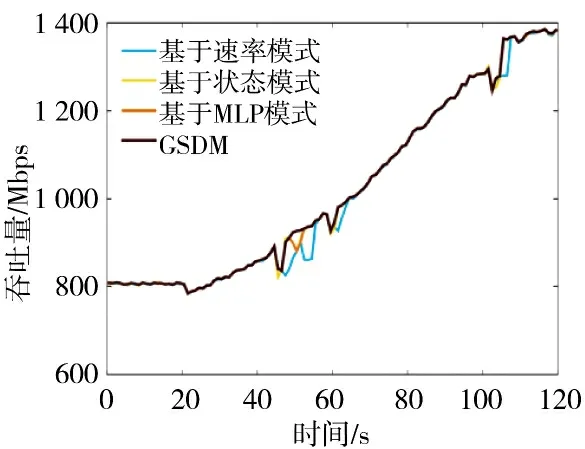
图6 缓慢增长型流量场景下的吞吐量对比Fig.6 Throughput comparison in slow increase traffic scenarios
相比于基于速率模式机制,基于状态模式机制依据网络功能的实时状态进行资源调度,可以有效忽略流量类型的多样性,提高调度的及时性。然而,在系统刚启动的阶段,系统的不稳定性容易造成噪音信息输入,导致资源调度策略的不准确性。错误的检测结果使得网络功能实例频繁增加以及删减,对底层资源造成了极大的浪费以及不必要高昂运维开销。
基于MLP 模式机制将综合特征信息作为输入,使得两类特征互补,有效地适应流量的多样性以及实现噪音过滤。基于MLP 模式机制证明了综合特征信息相比于单一特征信息的有效性。
与上述机制相比,GSDM 机制以高维特征序列作为输入信息,能够更好地提前预测扩展动作以及过滤噪音信息。除此之外,GSDM 能够根据上流或者下流节点的状态信息,帮助判断自身节点是否有扩展需求。特征序列信息以及邻居节点信息的引入,使得GSDM 有效地提高了准确性和及时性。
4.2.3 快速短时型流量场景
图7 和图8 展示了快速短时型流量场景下的时延以及吞吐量变化过程图。在这种类型的流量场景下,基于速率模式、基于状态模式以及基于MLP模式方法均立即采取了扩展操作保证系统性能。然而,实例的增加往往需要几分钟或者几秒用于实例启动。因此,新增加的实例并没有服务于短时增长的流量,反而造成了系统频繁的实例增加或者删减。与之相比,GSDM 以连续时间的特征序列为输入替代单一时间节点特征,能够有效地对流量类型进行识别,避免执行不必要的扩展动作。最终,GSDM机制在系统性能几乎一致的情况下,避免实例的频繁增加和删减,有效地提高了资源利用率以及降低了系统总开销。
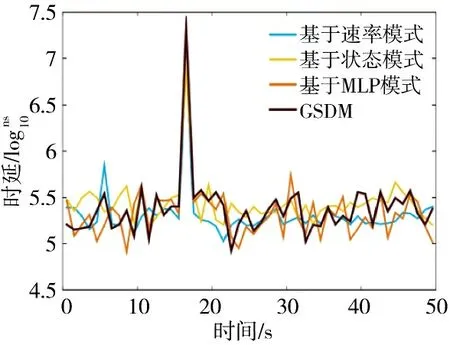
图7 快速短时型流量场景下的时延对比Fig.7 Delay comparison in fast short-term traffic scenarios
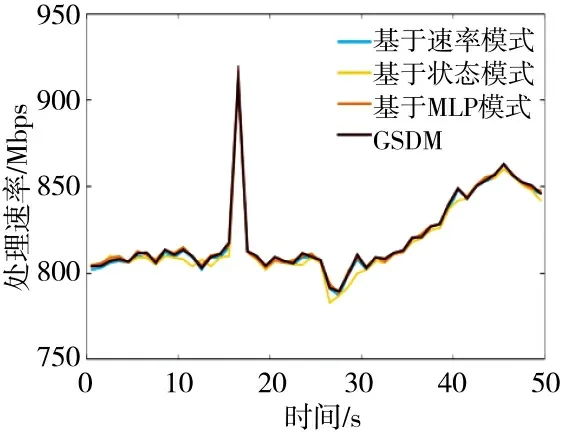
图8 快速短时型流量场景下的吞吐量对比Fig.8 Throughput comparison in fast short-term traffic scenarios
4.2.4 快速长时型流量场景
图9 和图10 展示了快速长时型流量场景下的时延以及吞吐量的变化过程图。对于基于状态模式方案,在系统刚启动的阶段作出了错误的扩展判断导致了资源的浪费。除此之外,基于状态模式、基于速率模式以及基于MLP 模式表现基本一致。三者的缺陷在于必须等待上流节点完成弹性扩展,下流节点才能感应到扩展需求。与之相比,GSDM 面对网络突发事情造成的大幅流量增长时,利用邻居网络功能的状态信息,能够对多个网络功能同时启动扩展操作。对于系统整体性能而言,GSDM 有效地提高了资源调度的及时性,并进一步在时延和吞吐量两方面提高了系统性能。
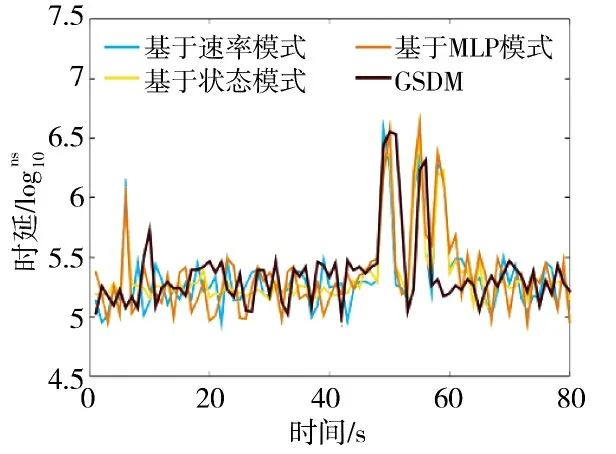
图9 快速长时型流量场景下的时延对比Fig.9 Delay comparison in fast long-term traffic scenarios
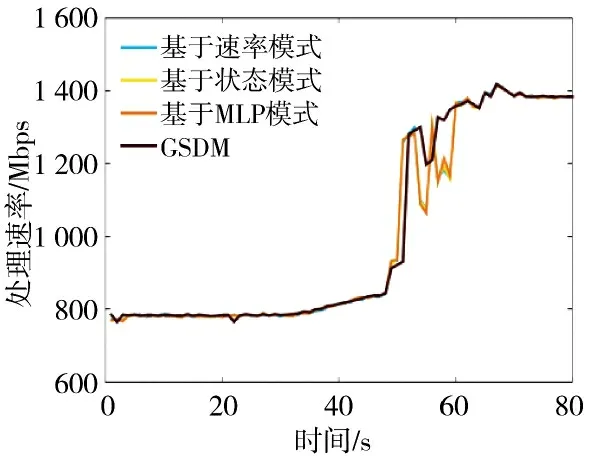
图10 快速长时型流量场景下的吞吐量对比Fig.10 Throughput comparison in fast long-term traffic scenarios
4.3 模型分析
本节对神经网络模型的性能进行具体分析,包括时间开销以及内存开销两方面,从而有效说明神经网络模型运行对NFV 系统整体性能的影响。
4.3.1 离线训练时间
针对于离线训练,训练一个单独的网络功能需要大概250 个迭代,每一个迭代大概花费500 ms。总体而言,GSDM 可以迅速地收敛。传统方案需要几个月甚至几周的时间进行设计。与之相比,GSDM 模型可以有效地降低方案设计时间。
4.3.2 在线运行时间
对训练好的GSDM 模型在线运行时间进行了测量,运行时间大约在0.12 s~0.14 s 之间。与其他后续的资源调度策略相比(例如:实例启动以及实例迁移需要几十秒甚至几分钟),GSDM 在线运行时间几乎可以忽略不计,对系统整体资源调度策略影响非常小。
4.3.3 内存开销分析
本文提出的神经网络模型较为简单,仅需要对多个网络功能的特征序列进行处理。在实际应用中,相较于在数据中心运行的大型NFV 系统,训练完成的神经网络模型在线运行带来的内存开销非常微小,几乎可以忽略不计。
5 结论
本文提出了一种基于服务功能链的资源调度的机制——GSDM,将邻居节点信息加入到输入信息中,有效地刻画网络功能连接关系对资源调度机制的影响。考虑到高维输入信息难以采用传统数学建模方法进行有效刻画,GSDM 利用神经网络模型构建了高维特征序列(自身以及邻居节点特征序列)与扩展动作之间的对应关系。除此之外,GSDM设计了网络功能级的注意力机制,有效地区分不同的邻居节点并设立不同的权重,从而捕捉对最终结果影响力更大的邻居节点。实现了GSDM 的原型系统,并将其与现有的各类资源调度机制进行了对比分析。实验结果表明,GSDM 机制能够快速准确地发现系统运行中的瓶颈网络功能节点,并为其分配更多的资源保障性能,在多种网络流量场景下均超过其他机制,表现出最好的性能。
