作为GPT的GPT
2023-06-26陈永伟
[摘 要:在经济发展过程中,通用目的技术(GPT)的作用是至关重要的。作为一种新出现的技术,生成式AI具有GPT所要求的普遍适用性、进步性和创新孕育性等特征,因而很可能会成为全新的GPT。生成式AI领域最具代表性的模型就是OpenAI的GPT系列等,这里的GPT全称是“生成式预测训练”(Generative Pre?Training)模型。无论是出于高质量发展的需要,还是出于加强我国国际竞争力的考量,发展生成式AI都是当务之急。从目前看,我国在发展生成式AI方面还存在着很多障碍,这就要求政府用好产业政策,为其发展扫清障碍。与此同时,作为GPT,生成式AI的发展一定会伴随着“创造性毁灭”过程,由此带来技术性失业、收入分配恶化,以及垄断和不正当竞争等问题。对于这些问题,应当用好相关政策加以应对,尽可能趋利避害,让生成式AI更好地为经济发展服务。
关键词:生成式AI;GPT;ChatGPT
中图分类号:F49文献标识码:A文章编号:1000?176X(2023)06?0041?18 ]
最近,由美国人工智能研究公司OpenAI开发的大型语言模型ChatGPT引发了各界热议。相比于过去的AI产品,ChatGPT不仅可以更为顺畅地与用户交流,而且可以十分高效地按照要求完成包括文本写作、资料整理,甚至程序编写等在内的多种任务,因而广受用户青睐。自2022年11月30日正式上线以来,ChatGPT的用户数量就保持了高速增长。仅仅5天时间,其用户量就突破了100万;不到两个月,用户量就超过了1亿。2023年3月14日,OpenAI又发布了多模态的AI应用GPT-4。这一新模型不仅可以和ChatGPT一样识别文本,还可以进行图像识别,而且其问题解答、人机交互能力都有了质的提升。
从分类上看,ChatGPT和GPT-4都属于“生成式AI”(Generative AI)的范畴。随着ChatGPT的爆火,这种类型的AI逐步被人们关注。过去市场上的AI产品主要是所谓的“分析式AI”(Analytical AI),这类AI的主要功能是对数据进行学习和分析,以此来预测、辅助用户进行判断。与这类AI不同,生成式AI的主要功能是通过学习来生成与训练数据不同的新数据。例如,ChatGPT会生成不同于其学习材料的文本,Dall?E2、Stable Diffusion等图片生成AI则会生成不同于其学习材料的图形。得益于这种创造能力,生成式AI可以比分析式AI应用于更多不同的场景、完成更为多样化的任务,因而生成式AI正在成为一种“通用人工智能”(Artificial General Intelligence)[1]。
既然生成式AI的表现已经如此之好,那么一个直接的问题就是,它是否可能成为经济学意义上的“通用目的技术”(General Purpose Technology,GPT)?1如果这个答案是肯定的,那么这种技术将会对经济发展产生怎样的影响?又应该用怎样的政策去促进这种技术的发展?本文将对以上所有问题展开讨论。
一、GPT及其影响
(一)GPT的定义和特征
“通用目的技术”是现代经济增长理论中经常被提及的一个概念。与仅用于某些具体用途的专用目的技术(Specific Purpose Technology,SPT)不同,GPT的应用范围通常十分广泛,对经济的影响是整体性的。例如,蒸汽机、电气化等技术就是最常被提及的GPT。在文献当中,这些技术通常被称为“经济增长的引擎”。Bresnahan和Trajtenberg[2]最早对GPT进行了研究。根据他们的定义,GPT应该具有如下三个基本特征:
普遍适用性(Pervasiveness)。GPT可以作为投入品,被广泛地应用到各个部门。例如,作为GPT的新能源在不同的行业都能够使用,而作为GPT的计算机也可以为各個行业赋能。
进步性(Improvement)。通过持续的创新和学习,GPT的表现会随着时间的推移而不断改进。这种改进是多维度的:可能表现为与GPT相关产品、系统及组件的成本降低,也可能表现为质量改善。随着GPT表现的优化,使用它们将会变得越来越有利可图,而这也会有助于它们的进一步扩散。
创新孕育性(Innovation Spawning)。GPT的创新会促进相关应用技术的创新,进而提高应用部门的研发生产率,而应用部门的技术进步又会反过来促进GPT自身的进步。显然,创新孕育性的存在会让GPT创新和应用部门创新的回报率同时得到提升。
后来的经济学家对Bresnahan和Trajtenberg[2]的上述标准提出了一些修正。例如,Carlaw和Lipsey[3]认为,GPT的特征应该包括:最初只用于一些特殊用途;随着在经济中的扩散,它会演化成更为复杂的形式,其效率会不断提升;它会被用于帮助众多领域的生产;它会产生更多新产品,演化出新的生产流程。后来,Bekar等[4]进一步总结出GPT的六个特征:与定义和支撑它的一组技术互补;与由它赋能的技术具有互补性;与一系列在社会、政治和经济上具有变革性的技术具有互补性;没有相近的替代方案;具有广泛的应用;开始时比较粗糙,但会演化得越来越复杂。不过,尽管有了这些论述,Bresnahan和Trajtenberg[2]的标准依然被认为是判断GPT的最重要标准。按照上述标准衡量,尽管人类历史上技术发明众多,但能称之为GPT的却很少。Lipsey等[5]曾对历史上的GPT进行过专门研究。在他们看来,从公元前9 000年至今,只有24种技术可以称为GPT。按照出现的顺序,它们分别为:植物驯化、动物驯养、矿石冶炼、轮子、写作、青铜、钢铁、水车、三桅帆船、印刷术、蒸汽机、工厂体系、铁路、铁轮船、内燃机、电力、汽车、飞机、大规模生产、计算机、精益生产、互联网、生物技术、纳米技术。
按照不同的标准,可以对GPT进行不同的分类。例如,在Lipsey等[5]就给出了两种分类方法:一种是按照技术呈现的形态进行分类,可以将GPT分为产品型技术、流程型技术和组织型技术;另一种则是根据技术的最终用途进行分类,可以将GPT分为材料技术、能源技术、交通技术、组织技术、信息和通讯技术。(二)GPT与生产率的关系
与SPT不同,GPT的发明并不能立即带来生产率的显著变化。具体来说,GPT作用的发挥在很大程度上依赖于基础设施,以及与其相关的具体应用的数量和普及程度。一般来说,在一项GPT被发明出来后会经历两个阶段:在第一阶段,与GPT相关的各项基础设施没有普及,各项相关应用也没有被开发出来。此时GPT并不会马上对生产率产生提升效果。甚至由于在这个阶段需要对基础设施和应用发明进行大量的投资,产生大量的成本,因而从总体上看整个经济的生产率甚至会是下降的。在第二阶段,随着基础设施的建成、具体应用的开发,GPT对生产率的作用就会逐渐体现出来。在Helpman和Trajtenberg[6]的研究中,以上两个阶段分别被称为“播种阶段”(Time to Sow)“收获阶段”(Time to Reap)。以美国经济为例,在电气化技术被发明出来之初,其对经济的影响微乎其微,但到了19世纪90年代,以尼亚加拉水电站为代表的一批重要电力设施建立起来后,电气化对美国经济的提升作用就开始体现。1915年之后,电力网络在美国逐步普及,独立辅助发电器开始广泛应用,电气化对生产率的影响才随之变得明显。同样,在IT技术发展的早期,其对生产率的影响也并不显著,由此还诞生了著名的“索洛悖论”。但是,随着计算机普及,互联网、云计算等基础设施的建立,IT技术在提升生产率方面的作用终于得到体现。欧洲央行在一份报告中指出,“从历史视角来看,索洛悖论并不是什么悖论”,其原因正在于此[7]。
需要指出的是,GPT对生产率的影响在很大程度上取决于其扩散的程度。例如,Jovanovic和Rousseau[8]曾经对电气化和IT技术这两种GPT对生产率的影响进行过比较。结果发现,截至其研究发表时,IT技术对生产率的影响要远小于电气化的影响。Jovanovic和Rousseau[8]认为,这是由于电气化技术可以更为平稳地与更多资本存量结合,从而迅速融入更多部门当中,相比之下,IT技术在其发展初期只能应用于较少部门,其传播和扩散速度较为缓慢。不过,他们也发现,与电气化相比,IT技术的动态性更强,与其相关的技术发明速度和专利申请量都要胜过电气化,同时其相关产品的成本下降趋势也更为明显。因此,他们预期IT技术对生产率的影响将会在未来逐步显露出来。
(三)GPT的社会影响
GPT的扩散通常表现为一个“创造性毁灭”(Creative Destruction)的过程。它可能在促进生产力提升的同时,颠覆既有的经济秩序。在这个过程中,可能会造成一系列复杂的经济、社会和组织影响。限于篇幅,本文集中讨论其中的三种影响。
1.GPT对竞争的影响
从理论上讲,GPT的扩散可能会重新配置企业之间的竞争优势,从而可能让固守旧技术的在位大企业没落,而率先采用新技术的中小企业则可能趁势兴起,但现实却并非如此[9]。1一些实证研究证实了这一点,如Jovanovic和Rousseau[8]曾考察过1988—2001年间不同规模的资本回报状况。他们发现,从长期看,小企业的年资本增值率要比大企业高出7.5%。但是,在电气化和IT技术这两种GPT的主要扩散时期,大小企业在资本增值率方面的相对差异并没有明显变化。也就是说,“创造性毁灭”的作用效果并不明显。
对于这种现象有很多解释。其中的一个解释来自Schumpeter[10]。他认为,当技术引发的“创造性毁灭”到来时,在位企业不愿意就此退出市场,因而会采用各种不正当的竞争手段来阻碍新兴企业超越自己。另一种解释则来自Aghion等[11]。他们认为,大企业也可能率先成为新技术的推动者。在这种情况下,它们相对小企业的竞争优势将会进一步凸显,而这可能会反过来打击小企业的创新动力,甚至让它们放弃竞争。无论根据上面哪种解释,都意味着在GPT迅速扩散的同时,也可能會发生比较严重的垄断和不正当竞争问题。事实上,历史也在一定程度上印证了这一理论。以美国为例,电气化扩散的同时,也恰好是美国大型托拉斯兴起的时期;在IT技术扩散的同时,一大批平台巨头也迅速崛起,并由此引发了平台垄断问题。
2.GPT的就业效应
从历史上看,很多GPT的发明和扩散都会对既有的工作方式产生重大冲击,并带来明显的就业影响。一方面,新技术的扩散会让很多采用旧技术的人失去工作,从而产生“技术性失业效应”;另一方面,新技术的扩散又会催生很多新的就业,从而产生“补偿效应”[12]。例如,蒸汽机和工厂体系的出现抢走了很多手工业者饭碗的同时,却创造出工人这个新职业;汽车的出现抢走了马车夫生意的同时,却创造出司机这个新就业岗位。尽管从长期看,后一种效应通常会胜过前一种效应,从而使新增的就业数量超过消失的就业数量,但从短期看,前一种效应通常会更占优势,因而技术性失业就成为了新技术,尤其是GPT扩散过程中经常出现的一种现象。
3.GPT对收入分配的影响
GPT的扩散会从多个机制对收入分配产生影响。技术的影响是有偏向性的,如果某种技术是资本偏向性的,就可能减少对劳动力的需求,这会让劳动力的工资下降,从而导致劳动力收入在总收入中所占的份额也随之减少[13]。例如,经济史学家Allen[14]曾经对18世纪早期至20世纪初的工资状况进行过研究,结果发现在这个曾出现众多GPT的时间段内,企业的利润率出现了大幅增长,但与此同时,真实工资水平却一直维持不变。在经济史上,这一现象被称为“恩格斯停滞”(EngelsPause)。1从技术偏向性的角度看,“恩格斯停滞”产生的主要原因是这个时期主要GPT几乎都是替代劳动力的。例如,蒸汽机、火车、汽车等的出现,都大幅降低了市场对劳动力的需求,这就导致了工资的停滞不前。此外,GPT的扩散可能还有助于“巨星”企业的发展,使其在行业内的份额变得更高。由于这类企业通常都有高资本密集度的特点,因而“巨星”企业的发展就会加剧劳动力份额在总收入中占比减少的趋势[15]。
二、生成式AI:原理和发展
(一)生成式AI的技术原理简介
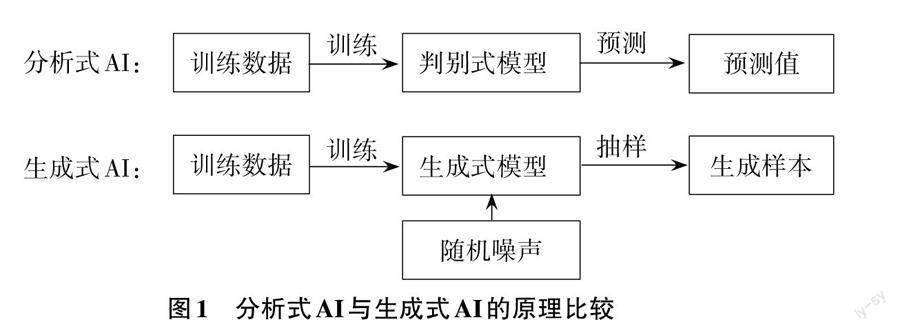
生成式AI和分析式AI的根本区别是:后者采用的是“判别式建模”(Discriminative Modelling),其目的是通过训练样本数据来提升模型的判断能力,从而能够帮助人们实现对训练外样本性质的判断;而生成式AI采用的则是“生成式建模”(Generative Modelling),它学习的目的是创造出和训练样本中数据类似的新数据(如图1所示)。举例来说,一个分析式AI通过学习大量梵高的作品,就可以在遇到一幅新作品时判断出它是否为梵高所画;而一个生成式AI在进行了类似的学习后,就可以创造出类似梵高风格的新作品。
虽然从表面上看生成式AI非常神奇,但从本质上看,生成式AI就是一个概率模型。通过对样本数据的学习,生成式AI可以形成一个关于数据的分布模型,所谓“生成”新数据的过程就是从这个分布模型中进行重新抽样的过程。目前,人们已经提出了很多不同的生成模型,它们之间在分布模型的构建,以及样本的抽取上都存在着很大差别,各方面表现也不尽相同。在这些分布模型中,最有代表性的有五类:自回归模型、生成式对抗网络模型(GAN模型)、变分自编码模型(VAE模型)、流模型和扩散模型。
第一,自回归模型[16]。自回归模型是文本生成模型中经常用到的一种模型,ChatGPT在训练中就采用了这一模型。这种模型的原理非常直观,即根据之前出现的语句来对后续可能出现语句的概率分布进行建模,并挑选概率最高的那个语句作为生成内容。例如,当AI学习了大量文本后发现,如果在一段文字中出现了“生成式”这三个字,后面出现“AI”的可能性是最高的,那么它在遇到“生成式”之后就会生成“AI”。
第二,生成式对抗网络模型[17]。GAN模型的基本思想来自博弈论中的零和博弈。具体来说,它构造两个相互对抗的网络,分别作为生成器和判别器。其中,生成器通过训练样本进行学习,并根据学习结果生成数据,其目的是让判别器相信所生成的数据是真实的;而判别器则根据训练样本的学习结果对训练外的数据进行判别,其目标是正确判断这些数据是否是生成的。通过这种对抗,生成器和判别器的性能就可以同时得到提升,由该模型生成的数据也就越来越接近真实。不过,GAN模型的缺陷也很明显。由于它不直接对训练样本进行建模,因而其可解释性非常差,并且也难以保证生成数据和训练数据来自同一分布。
第三,变分自编码模型[18]。和GAN模型不同,VAE模型会直接对训练样本进行概率建模。包含两个部分:编码器和解码器。其中,编码器负责对训练样本中各潜变量(Latent Variable)的均值和方差信息进行建模,解码器则利用这些信息生成新的数据。VAE模型会不断将生成的数据和训练数据进行对比,以此对潜变量的均值和方差信息进行重复校正。这样,生成内容的信息质量就能得到持续改进。由于VAE模型对训练样本直接进行概率建模,因而具有很强的可解释性,并且可以有效保证生成数据和训练数据来自同一分布。
第四,流模型[19]。流模型会直接计算决定数据表征的潜变量的分布和数据表征分布之间的转移函数,并由此直接反推出潜变量的分布状况,完整地还原出训练数据的概率模型。显然,流模型具有很强的可解释性,并且可以保证生成数据和训练数据来自相同分布。不过,其对计算的要求很高,因而需要较强的算力支持。
第五,扩散模型[20]。扩散模型由前向扩散过程和反向生成过程构成。在前向扩散过程中,模型会根据事先学习的一些参数,通过一个马尔可夫过程对原数据逐步加入噪声,直到将数据变为近似纯噪声的水平为止。在反向生成过程中,模型则对之前处理的数据进行逐步减噪,由此生成新的数据。通过不断将新生成数据与原数据进行对比,就可以不断校正参数,让模型的质量更高。
2.重要训练架构
除了训练方法之外,训练架构也是生成式AI的重要支柱。在对神经网络进行训练时,人们开发了很多训练架构模型,如卷积神经网络(Convolutional Neural Networks,CNN)模型、循环神经网络(Recurrent Neural Network,RNN)模型等。这些模型在生成式AI的训练中依然被广泛使用。但是,与这些经典模型相比,对生成式AI发展推动更大的模型则是Transformer模型。
Transformer模型最早的应用场景是自然语言处理(Natural Language Processing,NLP)。在处理这类问题时,模型需要对之前处理过的信息有所记忆,但CNN、RNN等经典模型要么难以处理记忆问题,要么不能处理并行计算,运作效率很低。Transformer通过创造性地引入了一种被称为“自注意”(Self?Attention)机制成功地解决了这些问题[21]。这种机制可以根据某个词语所处的位置来确定与这个位置关联最大的词语的概率分布,从而不仅可以处理记忆问题,还可以支持并行计算。借助Transformer模型,NLP的处理效率得到了突飞猛进的发展,ChatGPT等明星级产品最终得以出现。当然,目前Transformer模型的应用已经不再局限于NLP,而是被广泛应用到了图形、语音处理等各个领域,从而成为了生成式AI,是整个深度学习的一种通用训练架构。
正是在上述这些训练模型和训练架构的支撑之下,生成式AI才在当前实现了高速發展。
(二)生成式AI发展简史
生成式AI的历史原型可以追溯到20世纪60年代的聊天机器人Eliza,但直到2014年GAN模型被提出,它才开始了实质性发展。最早引起人们关注的生成式AI用例是“深度伪造”(Deepfake)。所谓“深度伪造”是指借助GAN模型,将人的形象、表情、声音进行拼接,并合成音频和视频的技术。2018年,互联网上出现了很多利用“深度伪造”合成的虚假视频,并引发了争议,但客观上,它也首次让人们认识到生成式AI的力量。此后,随着VAE、扩散模型等新训练方法的提出和应用,生成式AI迎来了高速发展。尤其是在2022年,诸如Dall?E2、Stable Diffusion、MidJourney、Flamingo等产品相继面世,生成式AI市场开始进入繁荣时期。
当然,生成式AI领域最大的突破还是来自“大型语言模型”(Large Language Models,LLM)。2017年,Transformer模型架构被提出,NLP模型的发展取得了突破。从此,很多企业都开始构建自己的LLM。其中,最有代表性的模型就是OpenAI的GPT系列和谷歌的BERT系列。GPT的全称是“生成式预训练”(Generative Pre?Training)模型,其采用的训练方法是自回归算法,通过前面出现过的文字来推断下文。人们现在所熟知的ChatGPT、GPT-4等都是这个系列的产物。BERT模型(Bidirectional Encoder Representations from Transformers,BERT)则采用了自编码技术,根据前后文来生成内容,其逻辑类似于完形填空。尽管现在BERT模型的知名度并不如GPT系列产品,但它在很多方面的性能甚至比GPT系列更优。谷歌正在研发中的很多大模型就是基于BERT模型开发的。
最近一段时间,生成式AI迎来了大爆发。在ChatGPT的爆火引发了人们对生成式AI的关注后,国内外各大企业都将生成式AI作为重点发展方向,大量的生成式AI在短期内纷纷涌现。与此同时,生成式AI的普及也十分迅速,目前已经有很多企业将生成式AI应用于自己的业务,并构造出了对应的商业模式。从各方面看,生成式AI已經从孕育期转入了爆发期。
三、生成式AI的GPT属性
关于AI是否是一项GPT,已经有不少文献进行过讨论。一些观点认为,AI已经被广泛应用于多个领域,并且发展十分迅速,因而具有了GPT属性;另一些观点则认为,虽然广义上的AI被应用于很多领域,但AI本身的含义过宽,在不同领域应用的AI模型在原理上存在着很大的差别,并不能被称为是一类技术。例如,知识图谱和机器学习虽然都归于AI的范畴,但其实是两种差异化的技术。从这个角度看,它们不应该被认为是GPT。
本文不对广义上的AI模型是否应该属于GPT进行讨论,本文关注的焦点是生成式AI。如前所述,生成式AI模型从本质上都属于深度学习模型的分支,在训练方法、模型架构上也都有很强的共性,因而大致上可以属于一种单独的技术类别。那么,这种技术是否可以被归入GPT的范畴呢?为了回答这个问题,需要检验它是否具有普遍适用性、进步性和创新孕育性。
(一)关于普遍适用性的检验
检验一种技术是否属于GPT的首要标准是它是否可以普遍使用。具体到生成式AI,需要检验它是否可以在垂直领域内得到大规模的应用。这个问题的答案是肯定的。无论是在消费端,还是在产业端,生成式AI都有广泛的应用前景。在很多领域,使用者只需要用提示词(Prompt)对预训练模型进行引导就可以得到符合专业需要的版本。相比于过去的分析式AI,生成式AI在各用途之间的转换成本非常低。
1.消费端的应用
在消费端,生成式AI可以为互联网生态提供大量的内容产品,从而丰富互联网的多样性,提升用户的使用体验。众所周知,在Web1.0时代,互联网的内容产品主要来自“专业生产内容”(Professional Generated Content,PGC),其内容数量很小,难以满足用户需要;在Web2.0和Web3.0时代,“用户生产内容”(User Generated Content,UGC)开始大幅增加,这在很大程度上丰富了互联网的生态[22]。不过,受创作者水平、激励措施等因素的制约,UGC产品的质量良莠不齐,其供给量也很难满足用户需求[23]。随着生成式AI的面世,一种全新的内容生产方式——“AI生产内容”(AI Generated Content,AIGC)随之诞生。相比于PGC和UGC,AIGC在内容制作成本和内容数量、质量的稳定性等方面都更有保证。这些特点决定了它可以被应用到相当多的领域。目前,生成式AI在消费端的很多领域得到了应用。限于篇幅,这里只对其中的五个领域进行介绍:
第一,日常办公。生成式AI可以在用户的指导下生成对应的内容,因而日常办公中相对重复、创造性较低的任务都可以由生成式AI辅助完成。最近,不少企业已经将生成式AI植入到办公软件当中。例如,2023年3月16日,微软发布了Office 365 Copilot,这款新的应用不仅可以根据用户的提示直接生成Word、PPT和Excel等,还可以帮助用户完成整理会议摘要、处理邮件等多种任务。也就是说,人们日常办公中的大部分任务都可以由Office 365 Copilot辅助完成。
第二,搜索。在搜索领域,目前微软已经将GPT-4模型应用到搜索引擎中,形成了“新必应”(New Bing)。新必应可以根据用户的需要实时从网上获取相关信息,并将信息整理成文本进行输出。和之前的ChatGPT不同,新必应在对用户的要求作答时,会给出确切的参考信息来源,这样就可以在很大程度上保证输出信息的可靠性。很多评论都认为,这种“AI+搜索”模式可以大幅提升人们从海量信息中检索出自己所需要信息的效率,因而可能会成为新一代的搜索方式。
第三,教育。生成式AI可以帮助用户创造独特的学习环境和学习内容,并根据其学习的反馈自动进行调整。通过这种方式,用户的学习体验和学习质量就可以得到十分有效的提升。目前,已经有不少平台将生成式AI应用于教育的实践。例如,著名的在线语言学习平台Duolingo就将GPT-3应用于语法修改,这一举措显著提升了学习者的外语写作能力。又如,一项来自教育机构Knewton的研究表明,通过引入GPT-3为高校学生提供个性化教学,可以有效提升教学质量;另一项来自教学机构Querium的研究则显示,GPT-3可以很好地帮助数学和自然科学的教学,让学生更为直观地理解教学内容。
第四,金融服务。生成式AI在经过进一步训练之后,可以充当个人的金融顾问,为个人提供投资理财、风险管理等各方面的建议。例如,在一项研究中,人们对ChatGPT的金融知识进行了测试。结果显示,其得分已经达到了充当金融顾问的水平。并且,由于相比于人类顾问,ChatGPT作为顾问会被人们认为更加客观,因而在实践中更加容易被人们所接受[24]。
第五,医疗。以ChatGPT为代表的生成式AI不仅可以辅助用户诊断病情,针对病情给出特定的就医和用药建议,还可以根据患者的描述和医生的诊断自动生成病例记录,从而大幅提升患者就诊和医生诊断的效率。需要指出的是,GPT-4目前已经可以支持图形识别,这为计算机根据图形诊断病情提供了基础,从而可以大幅提升诊断的准确率。
2.产业端的应用
在产业端,生成式AI的应用同样非常广阔。根据著名咨询机构Gartner的研究,其中最有代表性的应用场景包括工业设计、药物研发和材料科学。
第一,工业设计。当前的工业设计通常采用线性化的流程,不仅步骤繁多,耗费巨大,而且在每一步都可能产生错误,导致设计原型报废,从而产生严重浪费。如果采用生成式AI辅助设计,上述问题就可以得到较好的解决。AI不仅可以根据设计人员的思路迅速提出多套方案,还可以直接对各套方案进行比较评估,供设计人员选择,这样就可以有效节省设计成本、缩短设计时间,还可以有效减少浪费[25]。以芯片设计为例,在设计过程中,设计人员需要在微小的晶片上尝试各种组件的排列方案。实践中,可供选择的排列方案非常多,甚至可能达到数十亿种。如果依靠人力对这些方案一一尝试,就会产生巨大的成本,研发周期也会非常久。针对以上问题,很多企业已经开始将生成式AI应用到芯片的设计当中。例如,谷歌正在利用生成式AI輔助设计TPU1芯片,英伟达也在其GPU芯片的设计当中使用了生成式AI。
第二,药物研发。在药物研发的过程中,研究人员需要在海量的化合物当中不断试错,探索可供入药的成分。这使得药物的研发成为了一项周期长、成本高的工作。研究数据显示,美国研究一款新药的平均时间为12年,平均成本则高达26亿美元[26]。如果引入生成式AI来辅助研究人员识别化合物的分子结构,并根据需要对分子结构进行重构和修改,那么研发时间就可以大幅度缩短,研发成本也可以大幅度降低[27]。以DeepMind的AlphaFold对蛋白质结构的预测为例:在AlphaFold投入应用之前,人们用实验方法了解的蛋白质折叠结构大约为几万种。而AlphaFold则用很短时间就破解了现在已知的一百多万个物种的2.14亿种蛋白质结构[28]。在被破解的结构中,35%已经达到了和实验方法破解相当的精度,80%的结果有很高的可靠性,可以被用于后续的分析研究。
此外,生成式AI在直接的药物研发上也已经有了不少的应用。例如,英矽智能(Insilico Medicine)曾利用生成式AI开发治疗纤维化的新型DDR1激酶抑制剂,整个开发过程仅仅用了21天[29]。这个速度要远远高于传统的开发方式。
第三,材料科学。生成式AI既可以帮助研究人员更好地了解各种材料的结构及化学性质,还可以根据需要对材料进行“反演设计”(Inverse Design),因而在材料科学领域大有用武之地[30]。几年前人们已经开始将GAN、VAE等生成技术应用于新材料的研发。例如,德国马克斯·普朗克科学促进会下属的钢铁研究所不久前提出了一种基于机器学习的高熵合金设计方案,从而大幅提升了设计效率。应用这个方法,该研究团队已经成功设计出了多种高熵因瓦合金[31]。又如,沙特阿卜杜拉国王大学的研究团队也借助生成式AI对光学纳米材料进行反演设计,其设计效果也得到了很大的改进[32]。
综合以上分析不难看到:生成式AI在各个领域都有巨大的应用潜力。事实上,在以ChatGPT为代表的生成式AI爆火之后,已有大量的企业和个人开始使用ChatGPT。例如,不久前美国的《财富》杂志进行了一次调查,结果显示在被访的一千多家企业中,有50%的企业已经开始使用ChatGPT,另有30%的企业计划使用[33]。由此可见,生成式AI确实具有GPT所要求的普遍适用性。
(二)关于进步性的检验
作为一种技术,生成式AI的进步是十分迅速的,主要表现为如下四个方面:
1.模型规模的膨胀
以GPT系列的发展为例:2018年6月,GPT-1面世时,其参数仅为1.1亿,预训练数据量也仅有5GB;到2019年2月GPT-2推出时,参数达到了15亿,预训练数据量也增加到了40GB;而到2020年5月GPT-3推出时,参数已经猛增到1 750亿,预训练数据量也猛涨到45TB。此后,OpenAI又在GPT-3的基础上增加了参数量和训练数据量,将其升级为GPT-3.5,并用GPT-3.5训练ChatGPT。尽管ChatGPT并没有对外公布其确切的参数量和预训练数据量,显然这些数字都要高于GPT-3。在GPT-4推出之前,曾有传闻说,其参数量将达到100万亿,与人类大脑神经元数量相当。尽管该消息最终被确认为不实消息,但可以肯定的是,GPT-4模型的体量应该比GPT-3.5有很大的增加。
2.模型性能的提升
由于AI模型的性能很大程度上取决于其参数和训练数据的量,因而随着这两者的飞速增长,生成式AI模型的表现也出现了突飞猛进的发展。仍以GPT系列为例,在GPT-3之前,由于模型的参数量和训练数据量都很少,其表现并不突出,而GPT-3和ChatGPT在大幅增加参数量和训练数据量之后,无论是语义识别能力、逻辑推理能力,还是问题解决能力都有了质的飞跃。到了GPT-4,这种提升就更加明显。根据OpenAI官方公布的技术报告,如果让ChatGPT参加总分400分的美国律师资格考试,其得分为213分,大约只能胜过10%的人类考生;而如果让GPT-4参加这一考试,则可以得到298分,可以胜过90%的人类考生[34]。
3.模型使用成本的下降
以ChatGPT的使用成本为例:在OpenAI开放ChatGPT的API接口之前,对外开放的一直是instructGPT版本。这个模型的性能比ChatGPT稍差,其收费大约为每千个令牌(Token)0.02美元。按此计算,进行一轮对话的成本大约与目前推送一次搜索广告的成本相当。2023年3月1日,OpenAI开放了ChatGPT的API,其收费下降到了每千个令牌0.002美元,仅为原来的1/10。这样一来,ChatGPT相对搜索广告的成本优势就十分明显了,这为其未来的商业应用创造了无限的想象空间。
4.从单模态到多模态的跨越
在生成式AI发展的早期,模型大多是单模态的。例如,从GPT-1到GPT-3,以及ChatGPT都是文本输入、文本输出,而最近,多模态模型成为更为流行的选择,Dall-E2、Midjourney等模型都可以根据输入的文字信息输出图形,GPT-4可以从图形中读取信息并生成文字,也能根据文字生成图形,而微软的Kosmos-1模型则可以同时处理文字、图形、音频和视频。
总而言之,生成式AI的进步十分迅速。不久前,OpenAI的创始人Altman在自己的社交媒体上提出了一个“智能摩尔定律”:“宇宙中的智能数量每18个月翻一番。”尽管有不少评论人士批评该“定律”语焉不详,甚至有炒作之嫌,但在某种程度上,它其实是对过去一段时间内生成式AI发展的很好概括。由此可见,对于GPT所要求的进步性,生成式AI也可以很好的满足。
(三)关于创新孕育性的检验
生成式AI对创新的孕育表现在如下三个层面:
1.对人工智能创新的推进
近十多年来,人工智能的发展主要来自机器学习领域,而这个领域的发展对数据有非常高的依赖性。在具体的实践当中,数据的搜集和整理不仅成本高、质量难控制,还可能衍生出侵犯个人隐私、威胁数据安全等问题,这些都制约机器学习的发展。为了应对这些问题,一些学者建议可以使用合成数据作为真实数据的补充,供机器学习使用。与真实数据相比,合成数据至少具有以下三点优势:
第一,从训练效果上看,用合成数据进行训练的效果并不比真实数据差,在一些场合,它们的表现甚至更优异。在真实数据的形成过程中,可能混入很多不必要的噪声信息,这就可能对其质量造成影响,而合成数据则没有这样的问题。麻省理工学院、波士顿大学和IBM曾联合做过一项研究,用真实数据和合成数据分别训练模型识别人类行为,结果是采用合成数据进行训练的模型表现要比采用真实数据进行训练的模型更优[35]。
第二,从成本上看,合成数据要远远低于真实数据。例如,合成数据服务提供商AI.Reverie曾提供过一组数据:用人工方式标注一张图片,平均成本需要6美元,而如果用AI合成一张图片则只需要6美分,其成本仅为前者的1%[36]。由于在机器学习过程中用到的数据通常是海量的,因而用合成数据代替真实数据将会产生巨大的成本节约。
第三,从法律上看,合成数据可以规避很多风险。合成数据都是由AI生成的,而非向个人采集的,因而就可以避免漏露隐私、数据安全等众多问题。对于企业而言,用这样的数据来训练模型就更加没有后顾之忧。
综合以上原因,用生成式AI合成数据将有助于突破阻碍机器学习发展的数据瓶颈,这对于促进机器学习的进步将会起到十分重要的作用。
2.对其他科研领域创新的促进
著名哲学家怀特海在回顾科技进步的历史时曾经说过:“19世纪最大的发明是找到了发明的方法。”由此可见,找到新的“发明方法”或“发现方法”对于推进创新是十分关键的。从某种意义上讲,生成式AI的出现其实就是发现了一种新的发明或发现的方法。
从本质上讲,发明创新是一种对各种要素的组合。传统上,人们基于既有知识对要素的组合进行探索,因而具有很强的路径依赖性。正是因为这个原因,在早期的内生增长文献中,都习惯于将创新(也就是知识的增长)视为既有知识的函数。在应用了生成式AI这个新工具后,人们可以以更低廉的成本去探索更多组合的可能,这就让创新可以在更大程度上突破既有知识的藩篱,有了更大的可能性。正如前文中已经指出的,生成式AI已经在生物、化学、制药等需要大量试错的领域得到了广泛应用,并对这些领域的知识和要素重组起到了很大的促进作用。显然,这种“组合式创新”将会大幅提升这些领域的技术进步速度[37]。
3.技术进步的回振作用
生成式AI在促进各垂直领域技术进步的同时,这些垂直领域的技术进步也会反过来促进生成式AI本身的进步。一个典型的例子就是生成式AI和机器人学的互动。不久前,谷歌的机器人团队和谷歌创新团队联合研发了一款生成式语言模型PaLM?E[38]。这款模型可以根据不同类型的数据,如图像、声音、文本等对机器人进行控制,让它们完成各种任务。应用PaLM?E,研究者可以更容易地完成对机器人性能的各種测试,从而促进机器人技术的进步。反过来,机器人技术的进步也要求更好的控制技术,从而对PaLM-E的性能提出更多要求,促进其进步。通过这种互动关系,生成式AI和机器人学就可以同时获得进步。
综合以上分析可以看到,生成式AI确实具有GPT所要求的创新孕育性。至此,Bresnahan和Trajtenberg[2]提出的关于GPT的三条标准已经全部检验完毕。因此,笔者得出的结论是生成式AI应当可以被认为是GPT。
四、对GPT的生成式AI提出的挑战
由GPT的一般理论可知,生成式AI的发展和普及过程会遭遇很多问题和挑战[39]。无论是对政策制定者还是研究者,这些问题和挑战十分值得重视。
(一)制约生成式AI发展的障碍
1.基础设施的缺乏
在GPT的研发和扩散过程中,基础设施的作用是十分突出的。例如,如果没有电力网络,那么电力这种GPT的力量就无法发挥作用;而如果没有网络基础设施,那么计算机和互联网等GPT的作用也会受到很大的限制。同样的道理,对于生成式AI来说,如果没有对应的基础设施,其发展速度也会大打折扣。
具体到生成式AI,其发展需要的“硬性”基础设施和“软性”基础设施在我国现阶段都是比较缺乏的。
第一,“硬性”基础设施。所谓“硬性”基础设施,即支撑生成式AI发展所需要的硬件设施。限于篇幅,本文仅聚焦其中的两样:算力和存储。
首先,算力。虽然生成式AI的产生主要得益于算法层面的改进,但其能够迅速成熟、迅速扩散则主要依赖于算力的助推。相关研究已经表明,在深度学习中,即使算法本身没有进步,当训练数据大幅增加时,“涌现”效应就会出现,模型的性能就会出现质的变化。当然,大规模数据训练并不是没有成本的,需要巨大的算力投入。例如,在训练GPT-3时,OpenAI建立了专门的数据中心,动用了上万块英伟达A100 GPU芯片。正是这种庞大的算力投入,才保证了后来GPT-3和ChatGPT模型的出色性能。随着大模型的普及,生成式AI对算力的依赖性正变得越来越强[40]。总体上看,提升算力水平的途径有如下三条:一是通过采用高性能芯片,提升单位计算单元的算力水平;二是通过建设数据中心、智算中心,通过集中大量运算单元来提升算力水平;三是通过对量子计算等新型方式的开发和应用,从根本上改变计算方式。从目前看,这三条路径都会遭遇不少障碍:一是客观上讲,我国的芯片研发和生产能力还和西方存在着差距,在短期内难以生产满足生成式AI大模型训练所需要的芯片,加之西方对我国的封锁和禁运,要购买高性能芯片也很困难,这就决定了我国很难通过采用高性能芯片来提升算力;二是虽然我国已经建立了大量的数据中心,但这些数据中心安装的要么是CPU,要么是相对低端的GPU,很难支撑生成式AI大模型的训练;三是虽然我国在量子计算的理论和实践上已经有很大的突破,但受量子计算特性的影响,很难直接用量子计算解决大模型所需要的算力。综合以上三点,至少在未来的几年内,算力依然可能是制约我国生成式AI发展的一大瓶颈。
其次,存储设施。在生成式AI模型的训练过程中会产生大量的数据存储需求,而在这些需要存储的数据中,非结构化数据将会占据很大部分。为了能够对这些非结构化数据进行更好的整理、检索和存储,人们提出了向量数据库的解决方案。向量数据库专门用于存储、索引和查询嵌入向量,这些向量都是通过机器学习模型传递非结构化数据而生成的。对于构建专有大型语言模型的组织而言,向量数据库至关重要,但至今为止,我国向量数据库的建设依然是落后的。
显然,如果要在未来一段时间内大力发展生成式AI,就必须首先在算力、存储等基础设施上进行大量投入。
第二,“软性”基础设施。影响技术发展的“软性”基础设施有很多,包括法律制度环境、研发环境等。限于篇幅,本文仅强调影响生成式AI的“软性”基础设施之一,即开源环境。
随着IT技术的发展,开源平台和开源社区在软硬件研发当中的重要性正在日益凸显。在开源平台上,来自不同国家、不同企业的研究人员可以相互交流思想,交换各自的发明发现,很多重要的技术革新都首先出现在开源平台上。以生成式AI为例,无论是重要的训练算法,还是训练架构的核心思想,都最先在开源平台上出现,然后在开源社区经过讨论、打磨后逐步完善。由此可见,对于未来生成式AI的发展来说,开源平台和开源社区是必不可少的。
现在,世界上已经有很多著名的开源平台和开源社区,我国很多企业也都深度参与其中,但总体来说,我国企业在这些开源平台和开源社区的影响力和话语权都不够大。更为重要的是,当前国际形势风云变幻,这些开源平台和开源社区对我国企业的态度很容易受到国际形势变化的影响。如果它们对我国企业进行了封锁,那么我国企业在生成式AI的研发过程中就会失去重要的交流环境。显然,这会对相关研发进程产生非常负面的影响。
2.技术扩散过程中的协调问题
GPT要发挥作用,就必须扩散到各个具体领域当中,产生出各种具体的用途。在这个过程中,就会产生协调问题。具体来说,GPT的研发和推广会涉及很多不同的子系统,而各子系统的发展速度、行业标准通常会不一致[41]。如果这种不一致得不到很好的解决,那么GPT的扩散就会受到影响。例如,随着生成式AI的火热,国内很多企业都开始研发相关产品,但与此同时,国内生成式AI的应用生态相比于国外还存在着很大的差距。如果不解决好应用生态相对技术研发滞后的问题,那么即使相关的产品研发得到突破,也很难从中获得对应的经济回报,其长期可持续发展也会因此受到阻碍。
(二)生成式AI带来的“创造性毁灭”
和所有的GPT一样,生成式AI的发展也会带来“创造性毁灭”,由此会引发技术性失业、收入分配恶化,以及垄断和不正当竞争等问题。
1.技术性失业问题
从凯恩斯开始,经济学家们就开始对技术进步引发的失业问题表示关切。从“深度学习革命”后,人工智能就一直被视为可能引发新一轮技术性失业的重要源头。早在2013年,牛津大学的学者Frey和Osborne[42]就曾对人工智能可能产生的就业冲击进行过分析。他们的研究表明,在二十年内,美国的702个职业岗位中的47%都可能会受到人工智能的冲击,由此可能造成上千万人失业。需要指出的是,根据他们的研究,在人工智能时代,一个职业所受冲击的大小与其所要求的教育水平,以及其所提供的薪酬都是负相关的。总体来说,一个职业要求的教育水平越高,从业者的薪酬越高,那么这个职业可能受人工智能的冲击就越小。
与分析式AI一样,生成式AI的发展也可能引发大规模的技术性失业。最近,OpenAI的几位研究员Eloundou等[34]发表了一篇论文指出,大约 80% 的美国劳动者可能至少有 10% 的工作任务会受到 GPT等生成式AI大模型的影响,其中大约 19% 的劳动者至少有 50% 的工作任務会受到影响。
需要指出的是,不同于Frey和Osborne[42]的研究,他们认为,对教育水平要求更高、对从业者支付薪酬更高的岗位会受生成式AI大模型的冲击。例如,根据Frey和Osborne[42]的估计,程序员、律师等岗位都是受人工智能影响较小的工作,但根据OpenAI的估计,这些都可能是生成式AI冲击之下的“高危”职业。
2.收入分配恶化问题
生成式AI的发展可能会带来收入分配格局的重大变化:
一方面,作为带有技术偏向性的技术,生成式AI可能会引发不同职业劳动者薪酬的变动[43]。对于那些可能被生成式AI替代的职业,如程序员、设计师等,其薪酬水平可能会因此而大幅下降;而对于那些和生成式AI互补性较强的职业,如提示工程师(Prompt Engineer)、AI工程师等,其薪酬水平则可能出现大幅上涨。由于技术带来的职业冲击需要一定的时间消化,至少在短期内,受到生成式AI负面影响的人应该会比受到其正面影响的人更多,这就会导致整个劳动力群体获得的总收入下降。另一方面,由于生成式AI带有十分明显的资本密集型特征,因而随着这一技术的发展,资本的收益率将会大幅提升。尤其是主导该技术的头部“巨星企业”[44],更可能在这一轮技术革命中获益丰厚。
综合以上两个方面,如果不加干预,生成式AI的发展很可能导致资本回报在国民收入中的比例大幅上升,而劳动力回报在国民收入中的比例则大幅下降。
3.垄断和不正当竞争问题
同每一次GPT的引入一样,生成式AI的发展和扩散可能会对市场竞争格局产生重大的影响,与此同时,也会带来很多新的竞争问题。
第一,由持股关系导致的合谋。现在很多生成式AI模型的研发都是由巨头企业和其所投资的新创企业合作开发的。例如,ChatGPT虽然是OpenAI推出的,但其背后离不开微软的巨大支持,并且微软还持有大量的OpenAI股份。这种合作形式可以给研发活动带来很多的便利:由于像微软这样的上市企业受严格的财务制度制约,因而很难长时间、大投入、无回报地支持某种技术的研发;而OpenAI这样的初创企业虽然没有这样的制度约束,但其自身通常没有足够的资金从事研发活动。因此,通过类似的投资和持股关系,就可以很好地避免制度约束,让更有创新力的新创企业获得足够的资金从事颠覆性技术研发。不过,这种合作关系也客观上造成两者之间的合谋。在OpenAI通过高密度研发,推出了ChatGPT、Dall?E2等先进的AI模型后,OpenAI就选择了微软作为其唯一的合作对象,而微软也迅速将这些AI模型结合到自己的各种产品中。容易看到,面对微软和OpenAI的这种合作,它们的对手将很难与之开展竞争。
第二,滥用市场支配地位。由于类似ChatGPT这样的大型生成式模型的研发都需要大量的资金和技术投入,因而只有少数力量雄厚的巨头企业,或者由巨头支持的初创企业有能力进行研发。这样一来,一个大模型一旦面世,也就自然地获得了一定的市场力量。为了排挤潜在的对手,拥有大模型的企业可能会对其市场力量进行滥用。例如,此前OpenAI大幅下调了ChatGPT的API接入价格,这固然有模型运营成本降低的因素,但一些猜想也认为,这更有可能是微软和OpenAI用低价限制潜在对手进入的一种手段。如果这些猜想属实,那么微软和OpenAI就涉及掠夺性定价问题。又如,ChatGPT在市场上获得成功后,微软立即将其集成到自己的各种产品当中,这一行为很可能会涉及搭售问题。再如,不久前微软对一些采用必应搜索数据进行AI助手研发的企业提出警告,要求它们停止类似活动。考虑到搜索引擎检索到的数据本身为公开信息,而重新在网络层面建立索引数据库的成本非常高,因而它在某种程度上可能构成开发AI应用的必需设施。如果是这样,那么微软的这一行为就可能涉及拒绝交易问题。
第三,并购控制问题。如前所述,现在很多科技巨头为了在生成式AI领域取得优势,都对优秀的AI初创企业进行了大量的投资。例如,微软对OpenAI的投资总计已经达到了数百亿美元。在现实中,接受投资的初创公司和进行投资的巨头之间通常会一致行动,从而对市场竞争格局造成显著影响,但到目前为止,反垄断监管机构很少对这种合作关系进行关注。
所有上述现象都可能给正常的竞争秩序带来干扰,并影响生成式AI技术的进步和普及。因此,监管者应该对这些问题给予足够的重视。
五、关于促进生成式AI发展的政策思考
通过前面的分析可知,作为GPT,生成式AI在未来的发展中将扮演至关重要的角色。目前生成式AI的发展还存在着很多障碍,并且在其发展过程中,还会引发很多问题。在这种情况下,要促进生成式AI的健康、平稳、高速发展,并尽可能减少其发展过程中伴生的各种负面影响,就必须用相关的政策加以引导,本文将主要讨论以下三类政策:
(一)产业政策
根据Lipsey等[45]的观点,在支持GPT的发展方面,一直有两种不同的观点:新古典观点和结构—演化观点(Structure?Evolution Lenses,简称S?E观点)。其中,新古典观点假设政府具有完全信息和完备知识,可以识别出最优的均衡状态,因而政府可以通过直接指令、补贴或税收来诱导均衡的实现;而S-E观点则认为,GPT的扩散是通过演化实现的,政府并不能事先识别出最优的均衡。因此,政府应该做的就是建设支撑GPT研发和扩散的基础设施,同時作为协调者,解决GPT扩散当中遭遇的协调问题。在实践中,新古典观点对应的是“挑选赢家”的产业支持政策,S?E观点对应的则是现代的以塑造发展环境为主的产业政策。新近的研究表明,后一种产业政策通常是更有效的[46-47]。因此,在促进生成式AI方面,政府也应该采用这种观点,并以此来指导产业政策的制定。具体来说:
1.在扶持目标的选择上,不宜以特定的产品或技术目标为对象,应该更加重视塑造竞争环境,让不同的产品、技术路径可以彼此竞争
在ChatGPT获得成功之后,有不少地方政府都表示要支持企业研发对标ChatGPT的产品,这种政策是值得商榷的。从目前看,生成式AI无论是在训练方法、训练框架,还是在产品构思方面,都存在着很多彼此竞争的路径。例如,在NLP领域,就有GPT和BERT这两种重要的竞争路径,虽然前者由于ChatGPT的流行而暂时获得了优势,但这并不意味着从长期看BERT路径一定不如GPT路径。类似地,在文字生成图片领域,GAN、流模型及扩散模型的竞争仍然十分激烈。在这种情况下,如果政府过度强调对标某一产品或技术路径,就会对其他可能的技术发展方向造成抑制,从而不利于生成式AI整个领域的长期发展。相比之下,对所有产品、技术路径都一视同仁,在政府采购、招标时只提性能、质量要求,不对工艺技术进行强行规定,则是一种更为可取的思路。这样的做法可以激励各种技术路径展开竞争,倒逼技术进步,最终促进生成式AI的健康发展。
2.应当集中力量突破高性能芯片等“卡脖子”技术,保障生成式AI“硬性”基础设施的供给
对于生成式AI的发展来说,高性能芯片等技术的作用十分关键,单个企业很难突破这些关键技术。在这种情况下,政府应该集中全国的科研力量,做好这些技术的攻关工作。具体来说,在进行技术攻关的过程中,可以参考美国的经验,组建一个类似“国防部高级研究计划局”(Defense Advanced Research Projects Agency,DARPA)的机构来协调分散在各机构和企业中的科研力量[48]。这个机构可以采用相对松散的组织机构,根据项目从不同的企业抽调所需的技术人员。一旦相关研发取得突破,该机构还可以通过项目发包的方式提供资金支持,让这些技术更快地实现产业化。借助这种模式,就可以比较好地整合各种研究资源,从而促进生成式AI的研发,以及研发成果顺利转化。
3.应当强化相关“软性”基础设施的供给,尤其是应该引导国内开源生态的形成
在促进技术发展方面,“软性”基础设施的作用不容忽视,政府应当予以高度重视。具体到生成式AI的发展,政府应当关注相关法律、法规,以及行业标准的建设,做好这些“软性”基础设施的供给者。尤其需要指出的是,目前我国在开源生态方面的建设还很落后,这会在很大程度上制约生成式AI的发展。针对这一问题,政府应当投入专项资金支持开源平台的建设,并鼓励企业积极参与建设开源生态。通过这些举措,就可以有效激活生成式AI研发的交流生态,对这一技术的发展产生显著的推进作用。
4.应当扮演好“协调者”角色,引导不同角色之间的相互配合,促进生成式AI的扩散
作为GPT,生成式AI对生产率的促进作用很大程度上取决于其扩散程度,因而政府需要积极促进生成式AI在各部门之间的扩散。在现实中,制约技术扩散的因素有很多。例如,不同行业所使用的技术标准不一,技术的发展程度、接受程度不同,以及一些具有市场力量的企业拒绝与其他企业互联互通等,都有可能减缓技术扩散的速度。针对这些问题,政府应当积极制定相关的通用标准,引导不同企业之间的互联互通和技术合作。通过这些举措,就可以有效加强不同企业之间的协调,从而促进生成式AI在不同领域、不同部门之间的迅速扩散。
(二)就业和社会保障政策
随着生成式AI的发展和普及,大量岗位都可能受到剧烈冲击。至少在短期内,失业和收入分配恶化的问题可能会非常突出。针对这一情况,政府必须积极出台相关的就业和社会保障措施来加以应对。
1.应当积极鼓励服务业的发展
由于生成式AI具有较强的创造能力,对技术性的、以物为工作对象的就业岗位替代性非常强。相比之下,服务业尤其是那些以人为工作对象的、以为人提供情绪价值为主要目标的就业岗位则相对难以被AI替代。政府应当积极鼓励服务业的发展,创造更多就业岗位。
2.应当积极鼓励和引导零工经济、共享经济等新就业形态的发展
随着生成式AI的普及,工作的性质会发生很多改变:一方面,由于很多任务都可以由AI代为完成,大量就业岗位将不再需要全职劳动者;另一方面,随着生成式AI的扩散,不断会有新的就业岗位被替代,因而失业的人们会经常需要暂时的工作机会。在这种情况下,社会上对更灵活、更具弹性的工作形态的需求就会增加。显然,零工经济、共享经济等就业形态非常符合上述要求,不仅可以有效利用碎片化时间,还可以很好地充当“就业蓄水池”的作用,在技术性失业压力增大时提供大量就业机会。因此,政府应当对弹性工作的发展多加鼓励和支持。
3.应当建立终身培训体系,帮助因AI冲击而失业的人实现再就业[49]
当人们因AI的冲击失业后,会因缺乏相关技术而难以再就业。为了帮助这部分人实现再就业,政府有必要建立培训体系,提供有针对性的培训服务。需要指出的是,即使是政府也未必掌握完整的市场信息,因而其提供的培训也可能不符合市场需求。为了解决这个问题,需要用相关机制来加强政府、用人企业及劳动者之间的协调。具体来说,可以设计一种“就业抵押贷款”机制:用人单位可以先和劳动者签订就业合同,并对其提出相关的技能要求。劳动者根据要求,以其未来的收入作为抵押,去相关培训机构进行培训,学成相关技能后再上岗。政府可以根据用人单位提供的信息为劳动者提供相应的补贴,作为其参与技能培训的费用。利用这种方式,就可以有效减少因搜索和协调问题产生的成本,促进整个劳动力市场更高效的运作。
4.应当做好社保的托底工作
无论政府如何引导,在生成式AI的冲击面前,总有一部分劳动者会因此而长期失业。对于这部分群体,政府应该做好托底,满足其基本生活需求。在未来机会合适时,还可以考虑探索“全民基本收入”(Unconditional Basic Income,UBI)制度,为全体公民按月提供一笔基本收入。至于托底性收入及未来的UBI资金来源,可以考虑向AI提供商及大规模使用AI的企业收税来获得。借助这种制度设计,就可以有效缓和因生成式AI普及而带来的收入分配恶化问题,引导生成式AI创造的财富更好地为共同富裕事业服务。
(三)竞争政策
在生成式AI的发展过程中,容易引发很多新型的垄断和不正当竞争问题。为了维护市场秩序正常运作,监管机构必须重视这些问题。
1.对科技巨头与新创企业之间的合作关系应当予以重点关注
一方面,对那些巨头企业通过投资获得初创企业控股权或决策权的情形,应当进行并购审查;另一方面,对那些表面上不涉及控股问题的投资合作,应当评估合作双方的各种一致行动是否会带来反竞争效果,是否构成合谋。如果在审查和评估中发现问题,当立即予以纠正。
2.对于生成式AI所涉及的相关市场界定,以及市场力量的决定等基本问题,应当主动开展研究
作为一个新事物,生成式AI的应用潜力还没有完全开发出来,生成式AI究竟可以替代哪些产品,和哪些产品形成竞争,涉及的相关市场究竟有哪些进入壁垒,这些问题都不是非常清楚。出于监管的需要,应当立即对这些基础问题进行研究,摸清相关情况。
3.对于生成式AI的应用合规问题,应当出台相关指南和细则
为了规范企业在生成式AI市场中的竞争行为,防止垄断企业滥用市场支配地位,应当在加强调查研究的基础上,尽快出台相关的行为指南和细则,有利于企业在竞争中有法可依,规范竞争。
六、结 语
在经济发展过程中,GPT是一类非常重要的技术,其发展和传播不仅会为经济发展注入新的动力,还会对整个经济的结构进行重塑。作为一种新出现的技术,生成式AI具有GPT所要求的普遍适用性、进步性和创新孕育性等特征,因而很可能会成为全新的GPT,对经济的贡献潜力巨大。因此,无论是出于高质量发展的需要,还是出于加强我国国际竞争力的考量,都需要大力支持生成式AI的发展,用好产业政策,对其进行支持。
与此同时,作为GPT,生成式AI的发展一定会伴随着“创造性毁灭”过程。这会带来技术性失业、收入分配恶化,以及垄断和不正当竞争等问题。对于这些问题绝不能放任不管,必須用好相应的政策来加以应对。
总而言之,生成式AI的出现是一个巨大的发展机会。只要能够用好政策加以妥善引导,就可以扬长避短,让生成式AI的力量得到更好发挥,让这种新技术更好地造福人民。
参考文献:
[1] HACKER P,ENGEL A,MAUER M. Regulating ChatGPT and other large generative AI Models[R].ArXiv Preprint,2023.
[2] BRESNAHAN T,TRAJTENBERG M. General purpose technologies: ‘engines of growth?[J].Journal of econometrics,1996,65(1): 83-108.
[3] CARLAW K,LIPSEY R. Externalities,technological complementarities and sustained economic growth[J].Research policy,2002,31(8-9): 1305-1315.
[4] BEKAR C,CARLAW K,LIPSEY R. General purpose technologies in theory,application and controversy: a review[R]. Simon Fraser University Department of Economics Working Papers,2016.
[5] LIPSEY R,CARLAW K,BEKAR C. Economic transformations: general purpose technologies and long?term economic growth[M].Oxford: Oxford University Press,2005:132.
[6] HELPMAN E, TRAJTENBERG M. A time to sow and a time to reap: growth based on general purpose technologies [R]. NBER Working Paper,1994.
[7] ANDERTON R. Virtually everywhere? Digitalisation and the euro area and EU economies[R].European Central Bank,2020.
[8] JOVANOVIC B, ROUSSEAU P. General purpose technologies [C]// AGHION P,DURLAUF S. Handbook of economic growth( Volume 1B). Amsterdam: North Holland,2006: 1181-1225.
[9] CHRISTENSEN C. The innovators dilemma[M].Boston,MA: Harvard Business School Press,1997:257-261.
[10] SCHUMPETER J. The theory of economic development[M]. New York: Oxford University Press,1911:99-133.
[11] AGHION P,ANTONIN C,BUNEL S. The power of creative destruction: economic upheaval and the wealth of nations[M]. Cambridge: Belknap Press,2021:55-74.
[12] PETIT P. Employment and technological change [C]// STONEMAN P. Handbook of the economics of innovation and technological change. Amsterdam: North Holland,1995:366-408.
[13] ACEMOGLU D. Technical change,inequality,and the labor market[J].Journal of economic literature,2002,40(1):7-72.
[14] ALLEN R. Engels pause: technical change,capital accumulation,and inequality in the British industrial revolution[J].Explorations in economic history,2009,46(4): 418-435.
[15] AUTOR D,DORN D,KATZ L F,et al. The fall of the labor share and the rise of superstar firms[J].Quarterly journal of economics,2017,135(2): 645-709.
[16] BENGIO Y,DUCHARME R, VINCENT P. A neural probabilistic language model [J].Journal of machine learning research,2000,3(6):932-938.
[17] GOODFELLOW I ,POUGET?ABADIE J ,MIRZA M,et al. Generative adversarial nets [R]. Advances in Neural Information Processing Systems,2014.
[18] KINGMA D,WELLING M. Auto?encoding variational Bayes[R].ArXiv Preprint,2014.
[19] DINH L,KRUEGER D,BENGIO Y. NICE: Non?linear independent components estimation[R].ArXiv Preprint ,2014.
[20] HO J,JAIN A,ABBEEL P. Denoising diffusion probabilistic models[R]. Advances in Neural Information Processing Systems,2020.
[21] VASWANI A,SHAZEER N,PARMAR N,et al. Attention is all you need[R]. Advances in Neural Information Processing Systems,2017.
[22] 陳永伟,程华.元宇宙经济:与现实经济的比较[J].财经问题研究,2022(5):3-16.
[23] 陈永伟.Web 3.0:变革与应对[J].东北财经大学学报,2022(6):27-39.
[24] NISZCZOTA P,ABBAS S. GPT as a financial advisor[R].SSRN Working Paper,2023.
[25] YOO S ,LEE S ,KIM S ,et al. Integrating deep learning into CAD/CAE system: generative design and evaluation of 3D conceptual wheel[J].Structural and multidisciplinary optimization,2021,64(4):2725-2747.
[26] BIAN Y,XIE X. Generative chemistry: drug discovery with deep learning generative models[J].Journal of molecular modeling,2021,27(3):1-18.
[27] WALTERS P,MURCKO M. Assessing the impact of generative AI on medicinal chemistry[J].Nature biotechnology,2020,38(2):143-145.
[28] CALLAWAY E. The entire protein universe: AI predicts shape of nearly every known protein[J].Nature,2022,608(7921):15-16.
[29] TANG B,EWALT J,NG H. Generative AI models for drug discovery[M]. Cham: Springer International Publishing,2021:221-243.
[30] LU S,ZHOU Q,CHEN X,et al. Inverse design with deep generative models: next step in materials discovery[J].National science review,2022,9(8):8.
[31] SANCHEZ?LENGELING B,ASPURU?GUZIK A. Inverse molecular design using machine learning: generative models for matter engineering[J].Science,2018,361(6400):360-365.
[32] LIU Z,ZHU D,RODRIGUES S P,et al. Generative model for the inverse design of metasurfaces[J].Nano letters,2018,18(10): 6570-6576.
[33] WILLIAMS T. Some companies are already replacing workers with ChatGPT,despite warnings it shouldnt be relied on for ‘anything important [EB/OL].(2023-02-25)[2023-03-03].https://fortune.com/2023/02/25/companies?replacing?workers?chatgpt?ai/.
[34] ELOUNDOU T,MANNING S,MISHKIN P,et al. GPTs are GPTs: an early look at the labor market impact potential of large language models[R]. ArXiv Preprint, 2023.
[35] ZEWE A. In Machine learning,synthetic data can offer real performance improvements [EB/OL].(2022-10-03)[2023-03-03].https://news.mit.edu/2022/synthetic?data?ai?improvements?1103.
[36] ANDREWS G. Hat is synthetic data? [EB/OL].(2021-06-08)[2023-03-03].https://blogs.nvidia.com/blog/2021/06/08/what?is?synthetic?data/.
[37] AGRAWAL A,MCHALE J,OETTL A. Finding needles in haystacks: artificial intelligence and recombinant growth[M].Chicago: University of Chicago Press,2018: 149-174.
[38] DRIESS D,XIA F,SAJJADI M,et al. PaLM?E: An embodied multimodal language model[R]. ArXiv Preprint,2023.
[39] 陈永伟.超越ChatGPT:生成式AI的机遇、风险与挑战[J].山东大学学报(哲学社会科学版),2023(3).
[40] SEVILLA J ,HEIM L ,HO A ,et al. Compute trends across three eras of machine learning[R]. International Joint Conference on Neural Networks ,2022.
[41] LIPSEY R,CARLAW K,BEKAR C. Economic transformations: general purpose technologies and long?term economic growth[M]. Oxford: Oxford University Press,2005:37-42.
[42] FREY B,OSBORNE M. The future of employment[R]. Oxford Martin School Working Paper,2013.
[43] ACEMOGLU D. Technical change,inequality,and the labor market[J].Journal of economic literature,2002,40(1):7-72.
[44] AUTOR D ,DORN D ,KATZ L F ,et al. The Fall of the labor share and the rise of superstar firms[J].Quarterly journal of economics,2020,135(2): 645-709.
[45] LIPSEY R,CARLAW K,BEKAR C. Economic transformations: general purpose technologies and long?term economic growth[M]. Oxford: Oxford University Press,2005:499-515.
[46] RODRIK D. Industrial policy for the Twenty?first Century[R]. SSRN Working Paper,2004.
[47] AGHION P,JING C,DEWATRIPONT M,et al. Industrial policy and competition[J].American economic journal: macroeconomics,2015,7(4):1-32.
[48] 郝君超,王海燕,李哲.DARPA科研项目组织模式及其对中国的启示[J].科技进步与对策,2015(9):6-9.
[49] 陈永伟.人工智能与经济学:近期文献的一个综述[J].东北财经大学学报,2018(3):6-21.GPT as GPT:Opportunities and Challenges of the New Generation of Artificial Intelligence
CHEN Yong?wei
(Research Department, Journal of Comparative Studies, Beijing 100871, China)
Summary:This paper provides an overview of opportunities and challenges of the new generation of artificial intelligence (AI) from the perspective of general purpose technology (GPT). It also introduces recent development in generative AI, such as ChatGPT and GPT-4.
This paper first discusses whether AI can be considered a GPT. The first criterion for determining whether a technology is a GPT is its universality. In terms of generative AI, it needs to be examined whether it can be widely used in vertical fields. The answer to this question is yes. Generative AI has broad application prospects in both consumer and industrial sectors. In many fields, users only need to guide pre?trained models with prompts to obtain results that meet professional needs at low conversion costs compared with traditional analytical AI. Generative AI can provide a large number of content products for the internet ecosystem on the consumer side, enriching internet diversity and improving user experience. On the industrial side, generative AI can help researchers better understand protein folding structures or design materials through inverse design methods based on their structure and chemical properties. The second criterion for determining whether a technology is a GPT is its progressiveness. Generative AI has made significant progress in recent years, especially with the development of deep learning models and training methods. The third criterion for determining whether a technology is a GPT is its innovation. Generative AI has the potential to create new business models and industries, as well as new products and services.
However, there are still many obstacles to the development of generative AI. One of the biggest challenges is the need for high computing power during model training. Another challenge is the need for large?scale facilities for data storage, especially for non?structured data. In addition to technical challenges, generative AI causes social challenges such as technological unemployment and income inequality. Governments need to adopt appropriate policies to address these issues while promoting the development of generative AI.
To promote the development of generative AI, governments should focus on following key areas. (1) R&D investment. Governments should invest in R&D of generative AI technologies to improve the performance and reduce costs. (2) Infrastructure construction. Governments should build high?performance computing facilities and large?scale data storage facilities to support the development of generative AI. (3) Promoting collaboration. Governments should encourage collaboration between academia, industry and government agencies to promote innovation in generative AI. (4) Talent training. Governments should invest in education and training programs to develop talent with expertise in generative AI technologies. (5) Addressing social challenges. Governments should adopt appropriate policies to address social challenges such as technological unemployment and income inequality that may arise from the development of generative AI.
Key words:generated AI; GPT; ChatGPT
(責任编辑:邓 菁)
