基于轮胎特征点的并行大型车辆朝向角计算 *
2023-06-25赵嘉豪齐志权齐智峰
赵嘉豪,齐志权,齐智峰,王 皓,何 磊
(1. 北京理工大学机械与车辆学院,北京 100081; 2. 毫末智行科技有限公司,北京 100192)
前言
近些年,自动驾驶技术已经成为汽车工业的重要研究领域。智能汽车环境感知技术是自动驾驶技术中不可缺少的一部分,为自动驾驶汽车的规划和控制提供环境信息。
计算机视觉技术的快速发展和视觉传感器具有的信息丰富、成本低廉的优势使得视觉环境感知广泛应用于自动驾驶环境感知。
早期,视觉环境感知大多利用几何先验知识作为感知引导。Stein 等[1]提出基于图像中2D 位置,使用透视关系进行自动驾驶中前方车辆测距,用于进行车辆自适应巡航控制。Chen等[2]基于地平面假设提出了用于自动驾驶的单目3D 目标检测模型。后续使用几何先验的方法中,Chabot 等[3]建立目标CAD 模板库用于车辆识别;Chen 等[4]引入PnP 投影进行目标定位;Chen 等[5]引入目标相对位置优化检测效果。
基于几何先验的模型通常存在模型结构复杂、部署困难的问题,因此,Zhou 等[6]参考2D 目标检测模型提出基于key-point 且不引入几何先验的3D 目标检测模型CenterNet。基于CenterNet 的思想,文献[7]~文献[9]中提出在2D 图像中回归3D 投影中心点,用于计算目标3D 位置;Wang等[10]提出使用二维高斯分布定义中心度,提高3D 投影中心点定位精度。
同时,激光雷达在自动驾驶中的应用促进了基于图像深度估计的单目3D 目标检测模型的发展。Wang 等[11]提出基于Pseudo-lidar(伪激光点云)单目3D 目标检测方法;Reading 等[12]提出点云深度离散化及BEV空间3D目标检测方法;Park等[13]提出基于Pseudo-lidar的one-stage单目3D目标检测模型。
实际应用中,智能车辆通常在车身两侧安装侧视相机用于车身两侧环境感知。当目标车辆与自车横向距离在5 m 以内,纵向距离在8 m 以内,且目标车辆车身长度不小于10 m 时(并行大型车辆),目标车辆在侧视相机图像中同时受到目标截断和图像边缘畸变影响,导致朝向角检测稳定性差。
由于目标朝向角是预测目标速度和轨迹的重要因素,进一步影响到自车的规划和控制,因此并行大型车辆朝向角检测不稳定对于智能车辆行驶安全性和舒适性造成极大影响。
国内外专门针对此问题开展的研究工作较少,因此针对以上问题,本文在3D 目标检测朝向角处理中引入几何先验,做出如下工作:
(1) 提出一种使用相机逆投影方法计算大型车辆轮胎特征点位置,进而计算大型车辆朝向角的方法;
(2) 基于已有3D 目标检测卷积神经网络模型,在不影响原有模型基础上增加轮胎特征点检测分支;
(3) 建立并行大型车辆朝向角验证数据集,对算法进行验证。
1 基于轮胎特征点的朝向角计算
1.1 目标截断与图像畸变具体影响分析
由实车侧视相机道路拍摄如图1 所示,目标车辆由绿色方框包围。目标车辆车身较长,与自车并行,横向距离较小,导致相机视野中不能包括完整车身,即目标截断。

图1 实车采集图像说明
图像畸变指的是图像中原本应该是直线的地方发生不自然的变形或扭曲,如图中两条红色直线为目标车辆货箱下边缘在图像中不同位置的切线,可以看到在图像边缘位置,畸变现象十分严重。
视觉感知实际应用中,目标截断和图像畸变的主要问题如下:
(1) 目标截断导致图像中目标信息缺失,相较于非截断目标,特征提取难度增大;
(2) 图像畸变在大规模数据自动标注中导致激光点云与图像目标无法对齐,影响标注精度,进一步影响3D目标检测效果。
由于同时受到以上两个问题的影响,3D 目标检测模型对于并行大型车辆朝向角的预测效果较差。同时仅从3D 目标检测模型本身出发上述两个问题很难得到有效解决,因此本文引入几何先验知识,提出基于轮胎特征点位置并行大型车辆朝向角计算方法。
1.2 朝向角和轮胎特征点定义
本文通过Prescan 搭建模拟场景对朝向角进行描述。如图2 所示,图中轿车代表自车,厢式货车代表目标车辆,θ即为所求目标车辆朝向角,将其定义为目标车辆车身与自车车辆坐标系X轴之间的夹角。

图2 朝向角示意图
对于一个大型车辆轮胎,本文定义了轮胎接地点、轮胎中心点、轮胎上顶点3 个特征点,如图3 所示。
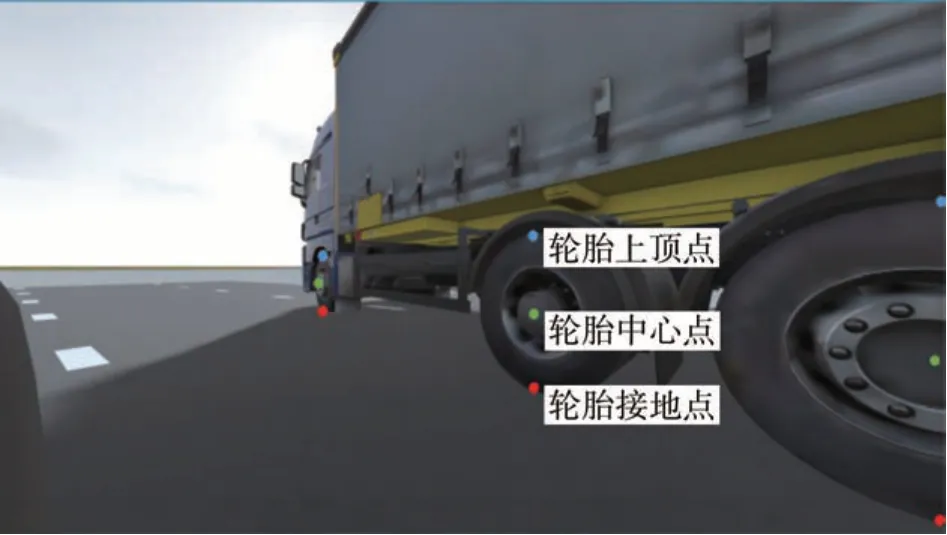
图3 大型车辆轮胎特征点定义
1.3 相机逆投影模型与坐标系
1.3.1 相机逆投影模型
图4为针孔相机成像模型。
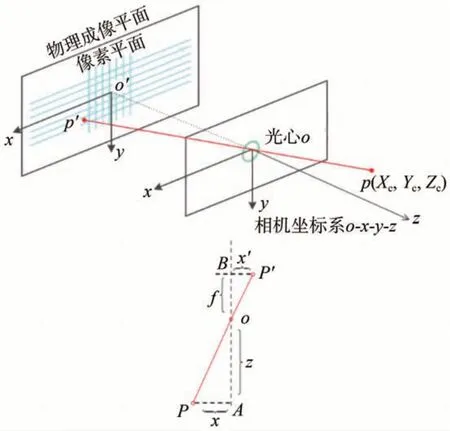
图4 针孔相机成像模型 [14]
基于此模型提出的相机逆投影模型如式(1)所示:
式中 :(Xc,Yc,Zc) 为P点在相机坐标系下位置;(u,v)为P点投影至图像中像素坐标系的坐标;fx和fy为相机X和Y方向上的焦距; (cx,cy)为像素坐标系中光轴对应的坐标;K为相机内参矩阵,通常由相机标定得到。
由于针孔相机模型仅能代表理想视觉传感器,在实际成像中图像会发生畸变, 因此本文使用多项式畸变模型进行图像坐标修正。
1.3.2 车辆坐标系与相机坐标系描述
车辆坐标系如图5 白色坐标系所示,坐标系原点Ov建立在汽车后轴中心点,X轴指向车辆前进方向,Y轴水平指向车辆左侧,Z轴垂直于水平面向上。自动驾驶车辆中通常使用左前、右前、左后、右后4个侧视相机进行车身周围环境感知,图5 中蓝色坐标系为典型自动驾驶左前相机的相机坐标系,Oc为相机坐标系原点,为相机镜头光心位置,相机光轴与Z轴重合指向车辆左前方,X轴指向相机右侧,Y轴指向相机下方。
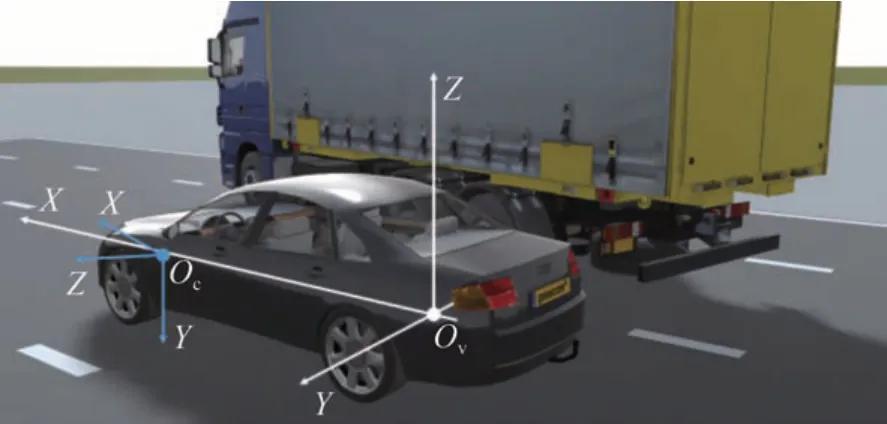
图5 车辆坐标系与左前相机坐标系
1.4 逆投影朝向角计算
1.4.1 特征点位置计算朝向角
如图6 所示,目标车辆不同轮胎同一类别特征点在自车车辆坐标系下的坐标可以用于估计目标车辆朝向角。以图中目标车辆最前方轮胎和最后方轮胎的轮胎接地点为例计算目标车辆朝向角。
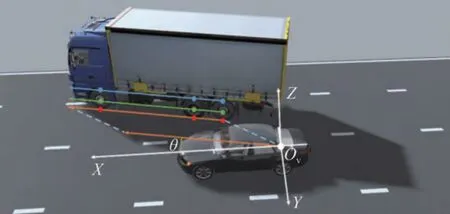
图6 特征点位置计算朝向角示例
式中:P1、P2代表选择的两个特征点在自车的车辆坐标系下的位置;θ代表根据目标车辆轮胎特征点计算得到的朝向角。
1.4.2 轮胎接地点逆投影朝向角计算
基于相机逆投影模型可以得到式(3),用于根据像素坐标系中特征点像素坐标计算车辆坐标系下特征点3D坐标。
式中:(u,v)为接地点特征点在像素坐标系下的坐标;Rvc、Tvc为由相机坐标系到车辆坐标系的旋转矩阵和平移向量;K为相机内参矩阵;(Xv,Yv,Zv)为特征点在车辆坐标系下的3D 坐标;Zc为特征点在相机坐标系下的Z坐标。
由于式中Zc为非固定值,无法通过标定获取,因此对于特征点中的接地点,本文中提出基于地平面假设[1]进行信息补全,进一步计算出接地点在自车车辆坐标系下的位置。
地平面假设将自车周围一定范围内的路面作为平面处理,则该范围内所有车辆接地点在自车车辆坐标系下的Z坐标为定值,代入式(3)有:
式中Zground为自车后轴距地面高度的相反数。
式(4)为可解的线性方程,可以计算出轮胎接地点在自车车辆坐标系下准确的3D 位置,任取目标车辆两个轮胎接地点代入式(2)可以求出目标车辆朝向角。
车辆转向时,由于车辆轴距远远大于前轮特征点移动距离,并且在车辆并行行驶时,一般转向角较小,因此前轮转角对车辆朝向角估计计算结果的影响较小。
1.4.3 轮胎非接地点特征点逆投影计算朝向角
在车辆实际行驶过程中,存在由于车道较窄相邻车辆间距过近导致相机视野中无邻近车辆接地点的情况,如图7 所示。

图7 无接地点并行大型车辆案例
在上述案例中,由于接地点信息丢失,无法使用基于地平面假设的朝向角计算方法,且不同车型轮胎大小不一致,无法获取确定的特征点距地面高度,地平面假设无法使用,因此本文中提出了基于相对位置的非接地特征点大型车辆朝向角的计算方法。
在相机光心处定义中间坐标系Om,其原点与相机坐标系重合,坐标系XYZ轴与车辆坐标系方向一致。
定义Tvc:
式中Tx、Ty、Tz分别为由相机坐标系到车辆坐标系的X、Y、Z轴坐标的平移量。
对于空间一点P在车辆坐标系下坐标为(Xv,Yv,Zv),其在中间坐标系的坐标(Xm,Ym,Zm)为
将式(6)代入式(2)得
式中: (Xm1,Ym1)、(Xm2,Ym2)表示用于计算朝向角的特征点在中间坐标系的位置;θ为目标车辆朝向角。
式(7)证明通过特征点在中间坐标系坐标同样可以计算目标车辆朝向角,但是对于非接地特征点,其在中间坐标系的坐标依旧无法求取,因此本文利用大型车辆前后轮特征点高度一致的特征计算朝向角。
首先,本文对于前后轮特征点高度进行假设,设其在车辆坐标系下的真实高度为Zt,则在中间坐标系中其真实高度Zmt=Zt-Tz,得到特征点在中间坐标系的坐标计算式:
式中:(u,v)为特征点在图像像素坐标系下的坐标;Rvc为相机坐标系到车辆坐标系转换的旋转矩阵;K为相机内参矩阵;(X'mt,Y'mt,1)为假设Zc为1 时计算得到的特征点在相机坐标系下的坐标;(Xm,Ym,Zm)为计算得到的像素点在中间坐标系的坐标。
然后,将式(9)代入式(7),得
式中:Zc1、Zc2分别是选中的两个特征点在相机坐标系下的深度;(X'mt1,Y'mt1,1)、(X'mt2,Y'mt2,1)为选中的两个特征点在假设Zc为1时的中间坐标系坐标。
根据式(9)和式(10),因为前后轮特征点在自车车辆坐标系下Zt相等,所以Zc1=Zc2,则式(11)可以进一步简化为
其中:
式中:(u1,v1)、(u2,v2)代表选中的特征点在像素坐标系下的坐标;Rvc为相机坐标系到车辆坐标系的旋转矩阵;K为相机内参矩阵;θ为根据目标车辆轮胎特征点计算得到的朝向角。
2 大型车辆轮胎特征点检测模型
2.1 轮胎特征点检测模型结构设计
本文在原有3D 目标检测模型基础上增加轻量化分支用于轮胎特征点检测。3D 目标检测模型用于周围环境3D 目标检测,根据目标3D 位置和类别筛选出并行大型车辆,在此基础上,应用本文提出的算法进行并行大型车辆的朝向角估计计算。
在分支结构设计上,本文中使用检测精度和检测速度均表现良好且在工业界有较多应用的yoloV3神经网络算法的模型结构[15]。yoloV3为全卷积onestage 模型,其检测速度优于two-stage 方法。同时,yoloV3 的FPN 结构可以提取不同尺寸的特征图,在多个特征图中进行检测,相较于在单个尺寸特征图进行检测能够有更好的召回率。
模型网络结构如图8 所示,分为两个分支:主分支用于单目3D 目标检测,根据输入图像进行车辆两侧环境感知;子分支用于大型车辆轮胎特征点检测。子分支模型结构与主分支完全一致,不同之处在于为了降低子分支的算力消耗,backbone 采用移除全连接层后的ResNet18,而不是与主分支相同的移除全连接层后的ResNet34[16]。

图8 轮胎特征点检测模型网络结构图
图片经过前处理后输入到主分支backbone 中,主分支backbone 对输入图片进行处理后输出4 个不同大小的特征层,其中后3 个高级特征层用于主分支进行3D 目标检测。第一个低级特征层为144×256,通道数为64,作为轮胎特征点检测分支的输入。特征点检测分支backbone 输出3 个不同尺度的特征层用于轮胎特征点检测。
模型两个分支均使用了FPN对不同尺度的特征进行融合,其具体结构如图9 所示。backbone 输出的特征层由低级到高级为特征层1 到特征层3。特征层输入到FPN 中,进行逐级的特征融合后输出。图中DBL 表示由Conv、BN、Leaky relu 顺序连接组成的模块。
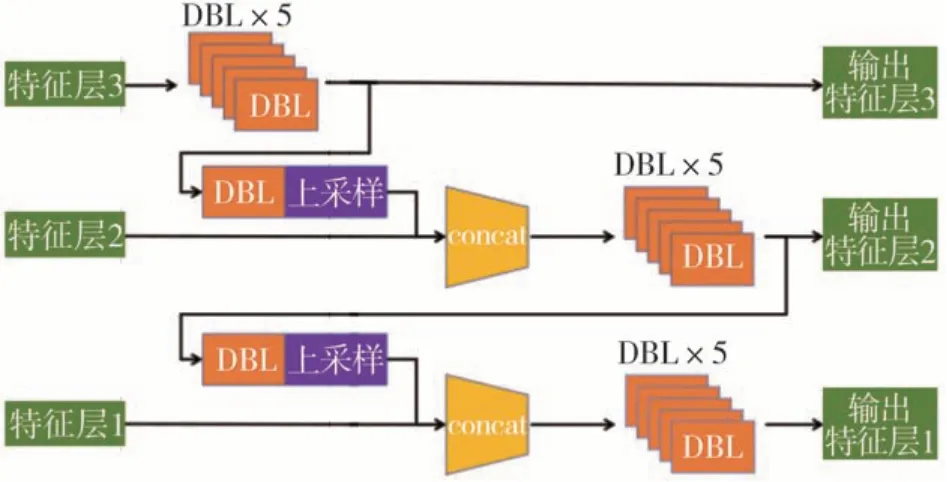
图9 FPN结构
检测头结构采用yoloV3的检测头结构。每一个尺度的特征层由FPN 结构输出后经过一个DBL 模块处理,再经过一次卷积为最终输出。轮胎特征点检测模型的3 个尺度分别将图片分割为9×16、18×32、36×64 的网格,其中每个网格内设置3 个anchor用于进行特征点检测。
2.2 模型训练及结果
轮胎特征点检测方案采用了基于yoloV3 的anchor based 检测方法。图10 所示为轮胎特征点标注示例,将特征点标注为以特征点为中心的2D边界框,同时将轮胎整体进行标注。在训练时将3 类特征点与轮胎整体作为4个不同的类别进行处理。

图10 特征点标注示例
本文标注并行大型车辆数据共7998张图片,其中随机选取7593 张图片作为网络训练数据,剩余405张数据作为验证集用于模型训练验证。
由于主分支训练数据集达到10 万量级,子分支训练数据集仅有7593 张,训练数据量极度不平衡,且需要优先保证主分支的模型性能,因此本文在训练时,首先对主分支进行训练。主分支训练完毕后,将主分支所有参数冻结,在此基础上进行子分支的训练,保证子分支训练不影响主分支模型性能。
训练数据原始图片为1920×1080,前处理中图片尺寸调整为1024×576 作为模型输入。在子分支训练中,本文基于不同的数据增强方式进行了两次实验,验证不同数据增强方式下模型训练结果。两次实验中仅数据增强方式不同,训练集和验证集保持一致,训练次数均设置为140,实时记录每次训练的损失值,在训练结束后在验证集中进行模型验证。
图11 为两次实验中的损失函数变化图。实验1为数据增强中配置了mossaic和mixup两种数据增强方式,实验2 中仅配置了mixup 一种数据增强方式。两次实验中loss函数在20次训练时均基本达到收敛状态。图12 为实验2 模型对白天和夜晚的轮胎特征点检测结果。
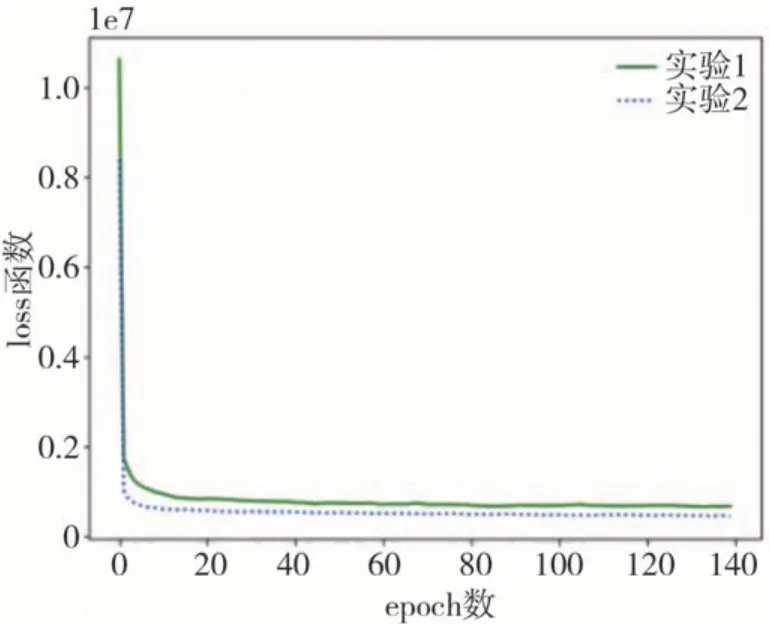
图11 模型训练损失函数

图12 模型检测结果
3 算法实现
本文基于python语言实现提出的朝向角计算方法。图13 为算法实现主体逻辑。
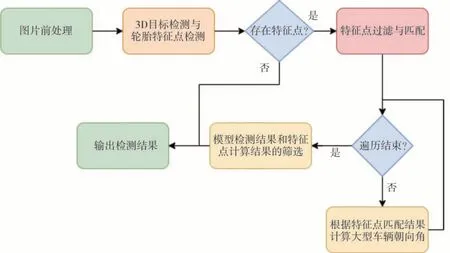
图13 朝向角处理逻辑
(1) 各相机拍摄的图像首先经过网络进行3D目标检测和特征点检测,输出图像内各个目标的3D位置及其2D 边界框和图像内特征点位置。若图像中不存在特征点,则直接返回3D目标检测结果。
(2) 如果图像内检测到特征点,则进行特征点匹配。在模型输出的3D 目标中筛选出并行大型车辆及其2D 边界框,通过2D 边界框包含关系进行特征点和目标车辆的匹配。随后对所有匹配到特征点的并行大型车辆进行朝向角计算。
(3) 根据本文算法进行朝向角计算。
(4) 对于3D 目标检测结果中朝向角和特征点计算得到的朝向角进行筛选处理。
(5) 输出并行大型车辆朝向角最终检测结果。
具体匹配结果计算大型车辆朝向角流程如图14 所示。输入为并行大型车辆及该车辆匹配到的特征点。
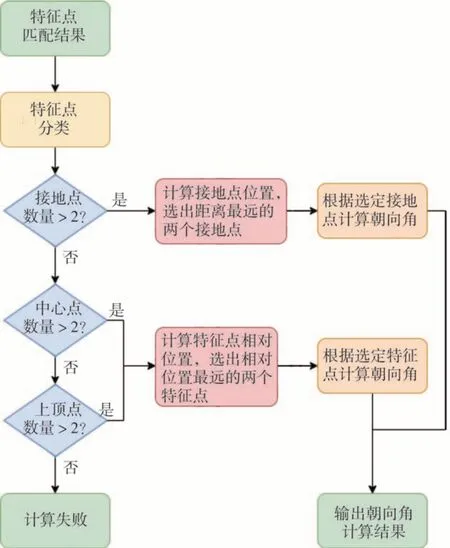
图14 朝向角计算流程
(1) 若目标车辆匹配到两个及以上接地特征点,则优先使用接地点进行朝向角计算。基于地平面假设计算所有接地点位置,选择距离最远的两个接地点进行朝向角计算。
(2) 若接地点特征点数量不足两个,则使用中心点或上顶点根据相对位置计算朝向角。将同类别的特征点均假设Zc为1 后进行位置计算。选择相对位置最远的两个特征点,根据相对位置计算目标车辆朝向角。
(3) 若3个类别特征点的数量均不足两个,则无法进行朝向角计算,输出3D 目标检测结果中的朝向角。
4 实验结果与分析
本文主要针对并行大型车辆的朝向角检测进行研究,用于验证本文朝向角计算算法有效性的实验数据均来自实验车道路采集,包含大客车、货车、板车等大型车辆。
图15 为大型车辆朝向角计算可视化结果,左上、右上、左下、右下顺序4 张图片分别代表实验车采集的左前方、右前方、左后方、右后方视角的同一时刻的相机数据。右侧网格图为根据检测结果进行鸟瞰图视角下可视化的结果,每个网格代表实际空间中5 m 范围。目标大型车辆在鸟瞰图可视化结果中用红色方框表示。

图15 大型车辆朝向角可视化
图中绿色方框代表模型检出的2D 边界框,其中up、mid、down、wheel标注分别对应于轮胎上顶点、轮胎中心点、轮胎接地点、轮胎整体(图中区域有限仅显示单词前3 个字母),为特征点检测子分支检测出的轮胎特征点以及轮胎。
本文从路测数据中并行大型车辆情景中筛选出不同时刻共计158 张图片以及对应时刻各传感器数据,作为最终并行大型车辆朝向角计算结果实验评测集。根据激光雷达点云进行标定,作为评测集中目标朝向角真值。
表1 为单目3D 检测模型和特征点检测算法在评测集中统计数据对比。评测集中存在一部分目标,其在相机视野中的轮胎数量少于两个,特征点朝向角计算方法无法处理,因此特征点朝向角计算方法统计数量少于模型3D目标检测。
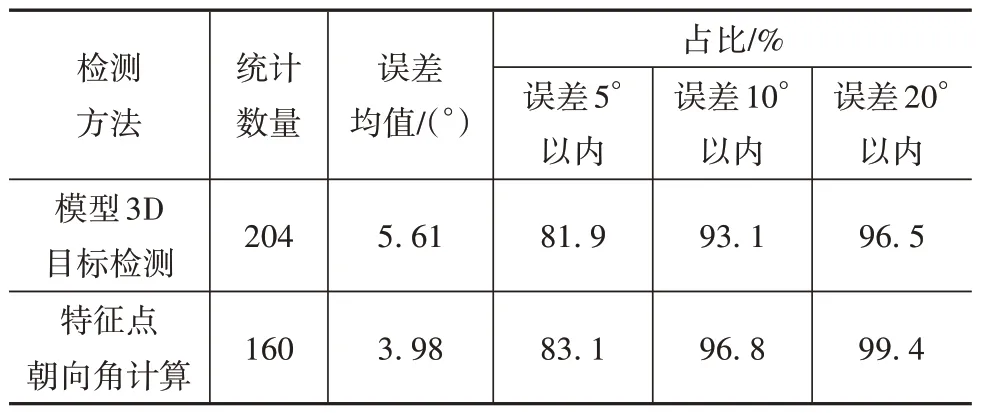
表1 朝向角检测结果对比
特征点朝向角计算方法误差均值相较于模型3D 目标检测方法降低1.63°,误差范围在5°、10°、20°以内占比分别提高1.2、3.7、2.9 个百分点,朝向角计算稳定性有明显提高。
为保证模型实时性要求,本文对模型增加特征点检测分支前后进行检测速度和参数量对比,对比结果如表2 所示。模型基于mmdetection 代码平台实现,其中pytorch 版本为1.6.0,mmcv 版本为1.3.14,GPU 采用V100 显卡,CUDA 版本为11.0。增加轮胎分支后,模型参数量增加64%,由25.77×106增加至42.30×106,fps 降低39%,由103.4 降至62.8,满足大于30 fps的实际使用需求。

表2 模型检测速度及参数量对比
本文采用实验2 模型作为最终特征点检测模型,其验证结果如表3 所示,模型准确率约为98%。召回率最小值为轮胎中心点的召回率81.0%,最大值为接地点的召回率87.2%。
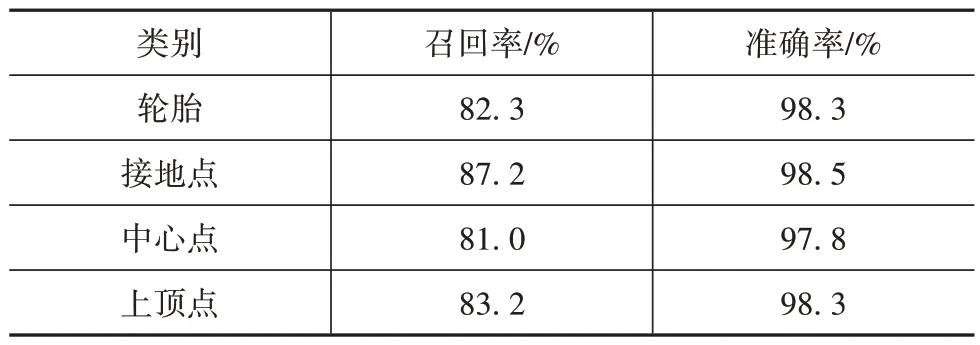
表3 特征点检测准确率与召回率
表4 为特征点定位精度统计结果,分别统计了不同特征点的平均定位误差。分析统计结果可以发现特征点X方向定位误差略大于Y方向定位误差,约为5 像素,Y方向平均定位误差约为3 像素。两个方向上定位精度均满足车辆朝向角计算需求。
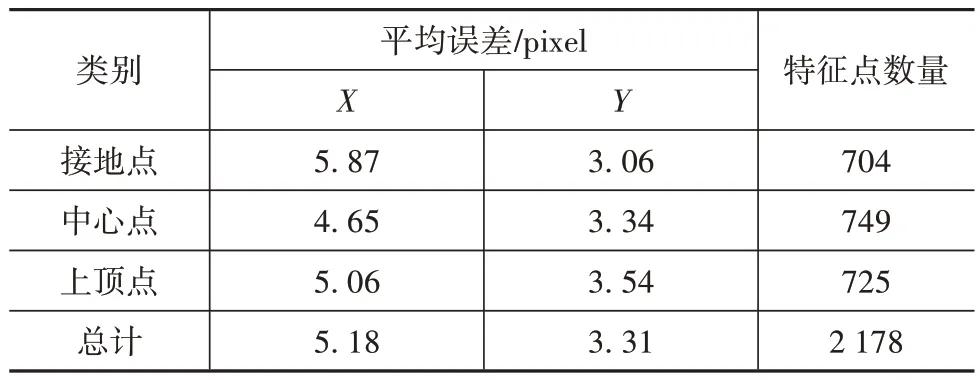
表4 特征点定位精度统计
5 结论
针对单目3D 目标检测在自动驾驶实际应用中并行大型车辆朝向角预测稳定差的问题,本文引入几何先验知识,基于相机逆投影模型提出利用轮胎特征点计算并行车辆朝向角的方法,基于已有3D 目标检测卷积神经网络模型,在不影响原有模型基础上增加轮胎特征点检测分支,建立并行大型车辆朝向角验证集验证所设计算法,结果表明:
(1) 本文提出的利用轮胎特征点计算并行车辆朝向角的方法,能够提高单目3D目标检测模型针对并行大型车辆的朝向角检测稳定性;
(2) 增加轮胎特征点检测分支后,3D 目标检测模型计算速度仍能够满足实时性需求;
(3) 轮胎特征点检测子分支具有较高的准确率和定位精度,能够保证算法稳定性。
