典型汽车碰撞事故场景中行人运动轨迹预测方法 *
2023-06-25林旭洁黄红武蔡鸿瑜罗金镕李燕婷
韩 勇,林旭洁,黄红武,蔡鸿瑜,罗金镕,李燕婷
(1. 厦门理工学院机械与汽车工程学院,厦门 361024; 2. 福建省新能源汽车与安全技术研究院,厦门 361024)
前言
据WHO 的报告显示,全球每年有135 万人死于交通事故[1]。现代智能交通安全辅助驾驶系统(safety driving assist system, SDAS)采用计算机视觉原理对感知范围内的行人进行检测和分析,有效提高行车安全[2]。在行人检测方面,基于机器学习的方法有Dalal 等[3]提出的HOG+SVM 算法,但该算法计算速度较慢,Zhu 等[4]使用AdaBoost 算法,提高行人检测速度和计算速度。考虑到交通监控摄像头以及视频质量不高导致的局部特征不明显问题,崔华等[5]通过改进AdaBoost,更准确地检测出行人。孙炜等[6]提出了基于支持向量机的行人检测跟踪方法,可以在遮挡变化的情况下自动识别和跟踪目标。基于深度学习的YOLO 系列模型[7]的比较结果如表1所示。由于YOLOv5在灵活性和速度上占有优势,并可较快地进行模型部署[8],本文中选用YOLOv5作为检测模型。

表1 YOLO系列模型比较[9]
在传统的跟踪算法方面,主要有最近邻算法[10]、多假设跟踪[11]和联合数据关联[12-13]。由于场景中目标较多,传统算法存在跟踪不可持续的缺陷,因此Wojke 等[14]基于前人开发的SORT 算法[15]设计了Deep-Sort 算法,可减少数据冗余,达到跟踪可持续的目的。同时,Qiu 等[16]提出了一种基于YOLOv5 和Deep-Sort 的行人计数方法,可对行人进行实时检测和跟踪,具有较高的精度和鲁棒性。
在预测算法方面,有社会力(Social-Force)模型[17]、卡尔曼滤波器模型[18]、动态贝叶斯网络[19]等。但这些方法很难适用于行人运动的不确定性,因此Alahi 等[20]提出了社会长短时记忆神经网络(sociallong short-term memory, Social-LSTM),解决了多个行人之间信息交互,提高了预测精度。Yagi 等[21]提出了第一视角的行人流轨迹预测方法,将行人行走姿势应用于其未来位置的预测中。国内有基于卡尔曼滤波[22]、行人姿态[23]、多融合的行人意图[24]、基于社会注意力机制的GAN 模型[25]的行人轨迹预测方法。李克强等[26]根据弱势道路使用者的运动特征,提出面向弱势道路使用者的多目标运动轨迹预测方法。
综上,国内外学者针对行人轨迹预测已进行大量研究,提出了多种预测算法,但建立的行人运动轨迹预测模型大多基于图像像素坐标系,较难应用于车辆避撞策略的开发。针对上述问题,本文构建了一种新型的轨迹预测模型,该模型通过YOLOv5-Deep-Sort 对行人历史轨迹进行检测跟踪,采用Social-LSTM 对其未来运动轨迹进行预测,得到轨迹坐标,选择较为典型的行人横穿斑马线的事故场景对预测模型进行验证,进一步预测出人车碰撞点位置。本研究可为汽车避撞行人的决策和主动安全技术的开发提供参考。
1 方法
图1 所示为研究技术路线图。首先通过YOLOv5算法对COCO 数据集[27]进行训练和验证,利用精度和召回率等指标评估行人检测效果。COCO数据集是微软构建的一个数据集,可以用于图像检测、语义分割等。结合Deep-Sort算法对检测到的行人进行跟踪,并实时记录行人坐标信息;其次,以记录的坐标信息为输入条件,采用Social-LSTM 算法对行人未来运动轨迹进行预测,并基于ETH/UCY 数据集[28]评估预测模型的有效性。该数据集源于Computer Vision Laboratory,且均为鸟瞰视角,符合本文中的典型交通事故监控视角。最后,采用透视变换与直接线性变换理论将行人预测轨迹像素坐标转换为与之相对应的世界坐标。

图1 行人轨迹预测技术路线图
1.1 检测跟踪模型
图2 为用于行人检测的YOLOv5 算法模型结构图。主要由输入端、骨干网络层、颈部网格层和输出端4 部分组成。输入层选用Mosaic 数据增强方法,自适应锚定框计算和自适应图片缩放;骨干网络层包括Focus结构和CSP(跨阶段局部网络)结构;颈部网络层利用FPN+PAN结构以实现高维度与低维度之间的双向语义信息传递;最终的输出端通过GIOULoss计算检测框的损失。损失由边界框回归损失、目标置信度预测损失和类别预测损失3部分构成[29]。

图2 YOLOv5算法模型结构
图3 为Deep-Sort 目标跟踪算法模型结构,主要包括卡尔曼滤波先验预测和卡尔曼滤波后验预测。卡尔曼滤波器对轨迹进行预测,在先验预测中通过匈牙利算法进行预测轨迹数据和真实轨迹数据的级联匹配和IOU 匹配;后验预测对滤波器的参数进行更新。可视化结果如结构图中的事故图片所示[30]。
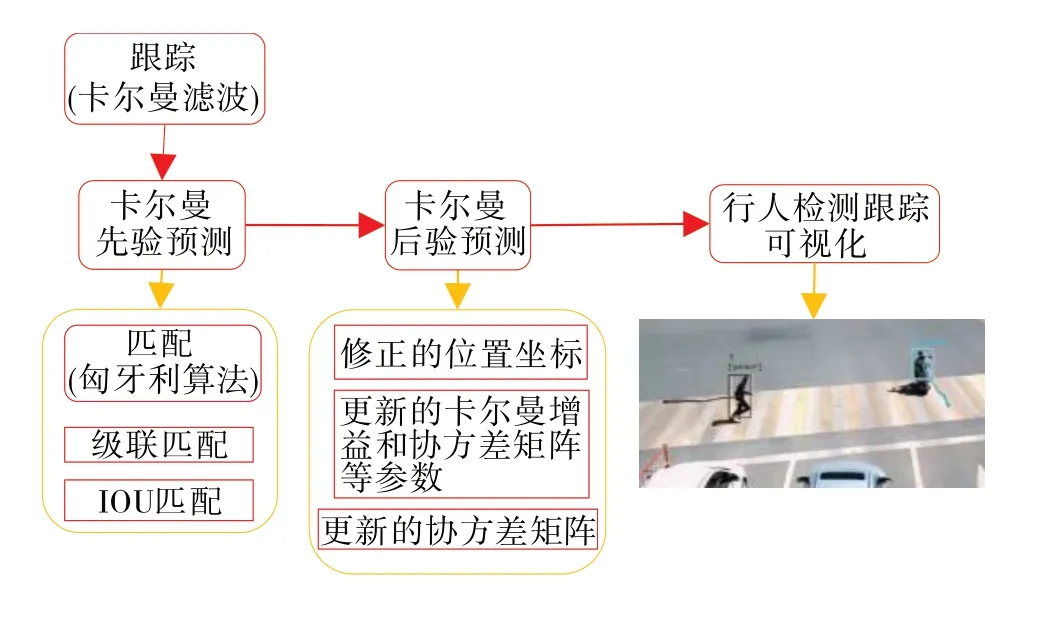
图3 Deep-Sort算法模型结构
1.2 轨迹预测模型
为有效解决循环神经网络(recurrent neural network, RNN)因递度消失而长期依赖不足及长短期记忆网络(long short-term memory, LSTM)无法获取同一场景中不同行人之间的交互信息等问题,采用Social-LSTM 对行人未来轨迹进行实时预测。该算法通过为每一个相邻空间上的LSTM 增加Pooling池化层,实现视频场景中不同行人之间的信息共享[31],结构如图4所示。
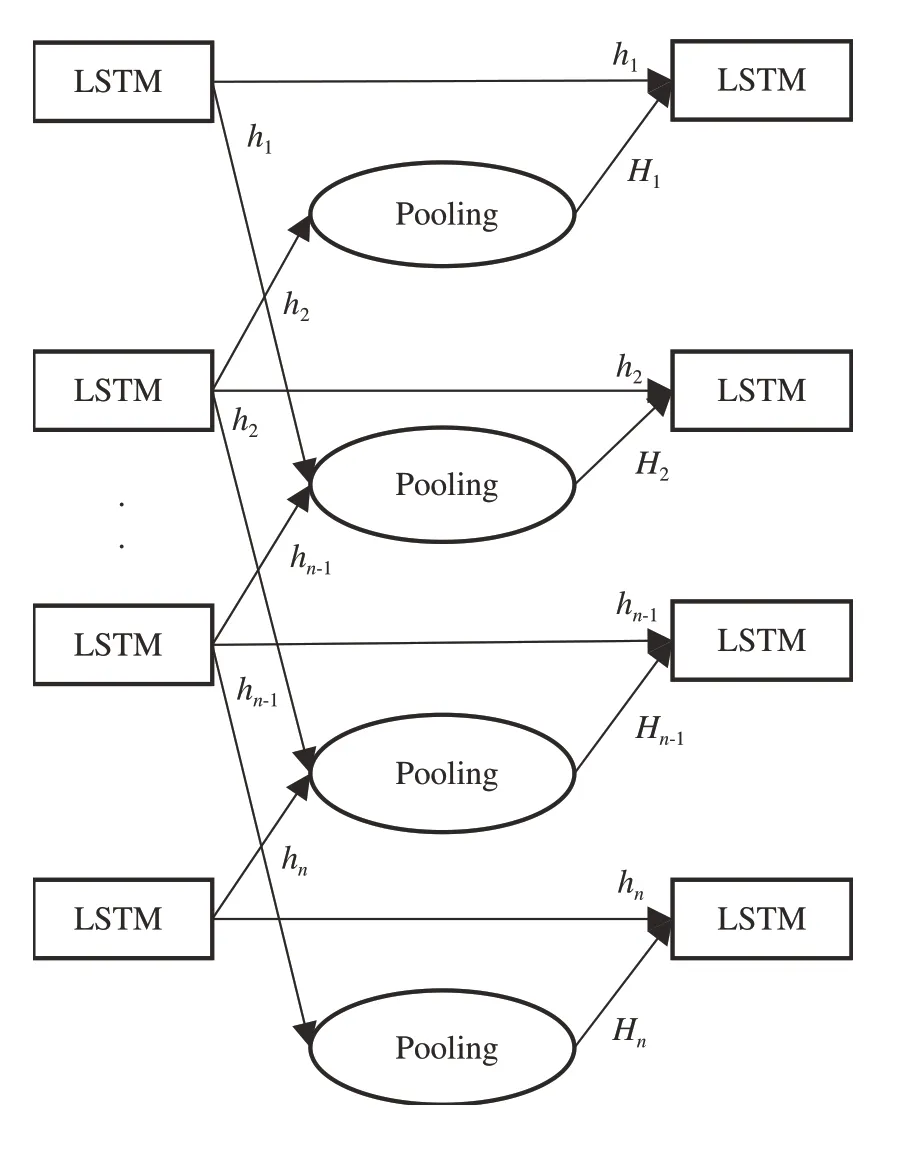
图4 Social-LSTM 结构[31]
LSTM 有3 种类型的门构成,分别是遗忘门ft、输入门it、输出门ot。对应的表达式为
式中:w表示权重;ht-1是上一时刻的输入值;xt是当前时刻的输入值;b表示偏差项。
Pooling层的主要任务是通过空间信息收集邻近目标的隐藏状态信息,表达式为
1.3 映射模型
为实现行人未来位置信息与车辆避撞系统中感知位置信息实时匹配,须将其映射到与之相对应的世界坐标系中,映射过程主要包括透视变换和直接线性变换两部分,透视变换主要利用透视中心、像点、目标点3 点共线的条件,将图片由一个平面透视到另一个新的平面[32]。直接线性变换是建立像点坐标和相应点物方空间坐标之间直接线性关系的算法[33-34]。映射模型如图5所示。

图5 坐标映射模型流程
行人轨迹预测的图像多通过道路监控摄像头采集所得,由于监控摄像头的高度与角度问题,拍摄的场景存在较大畸变。如距离摄像头较近位置的斑马线在视觉上会比距离摄像头较远位置的斑马线更宽、更长。为解决监控摄像头视角下的图像畸变问题,须通过透视变换将其转换成俯视图视角。
透视变换模型由如下透视变换矩阵A构成:
式中:u、v是原始图像的像素坐标;x'、y'是透视变换后的像素坐标。
得到俯视图视角下行人未来运动轨迹预测像素坐标后,采用直接线性变换理论实现像素坐标与世界坐标之间的转换。首先分析像素坐标系与世界坐标系之间的关系,根据式(9)线性变换表达式和选取的控制点坐标得到变换矩阵,通过变换矩阵完成从像素坐标到世界坐标系的转换。
U、V是像素坐标,对应世界坐标(X,Y),L为变换矩阵,式(11)为像素坐标与世界坐标之间的直接线性变换模型:
其中变换矩阵L为
结合式(9)与式(10)可得以下方程:
2 结果分析
2.1 检测跟踪算法验证
图6 为基于COCO 数据集训练并验证的YOLOv5 算法结果。其中图6(a)和图6(b)分别为训练损失和验证损失随训练步长(次数)的增加而变化的趋势。经过300次的步长训练,损失总体呈下降趋势,最终的边界框回归损失为0.026,目标置信度预测损失为0.031,类别预测损失为0.004,训练集和验证集的损失指标保持较低的状态且逐渐趋于平稳。
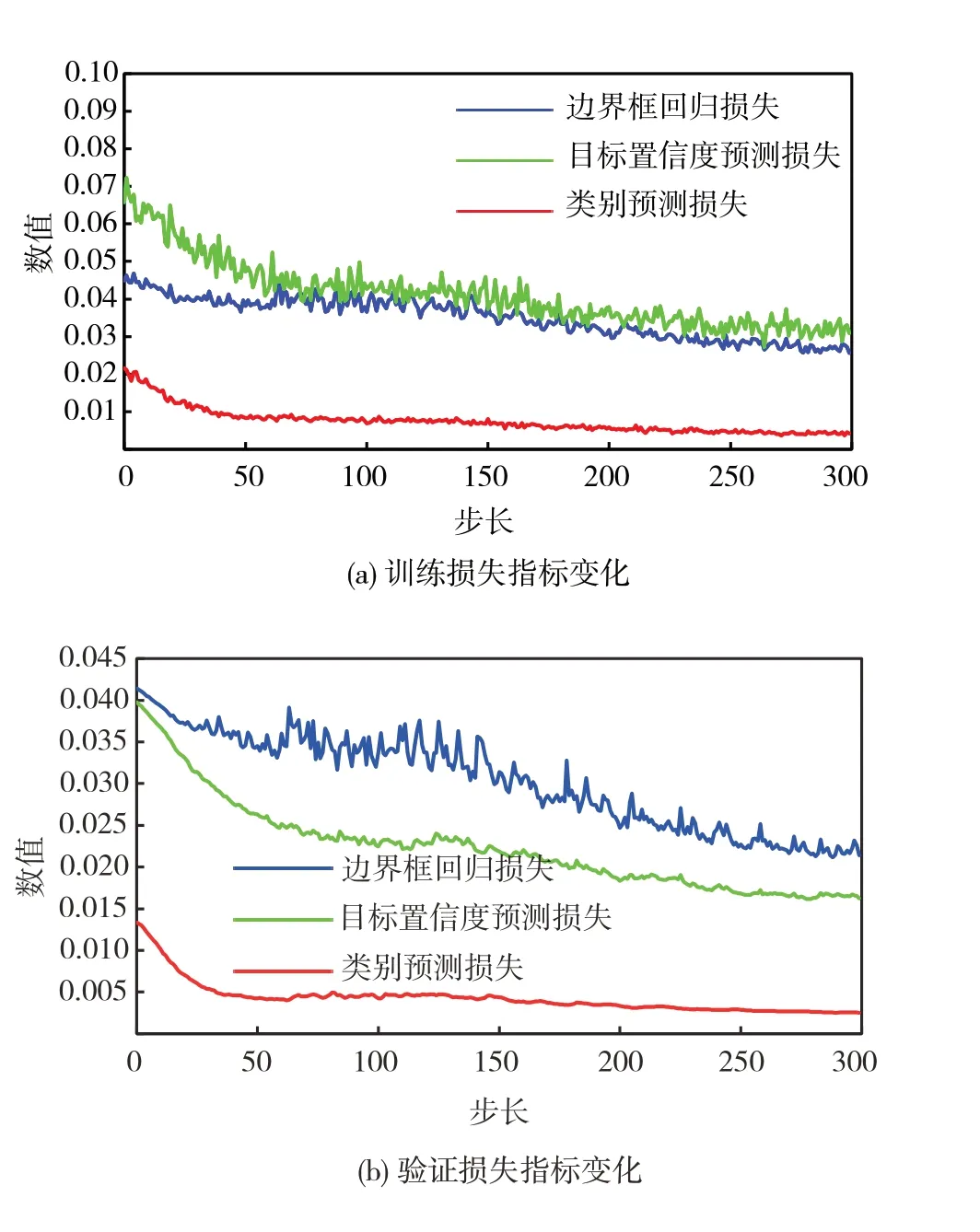
图6 YOLOv5损失指标变化
图7 所示为不同精确指标随学习步长的增加而变化的趋势。在模型训练过程中,整体指标呈递增趋势,模型整体准确率、召回率、平均精度值分别为93.889%、 91.858%、 96.753%。表明该模型检测效果较好。
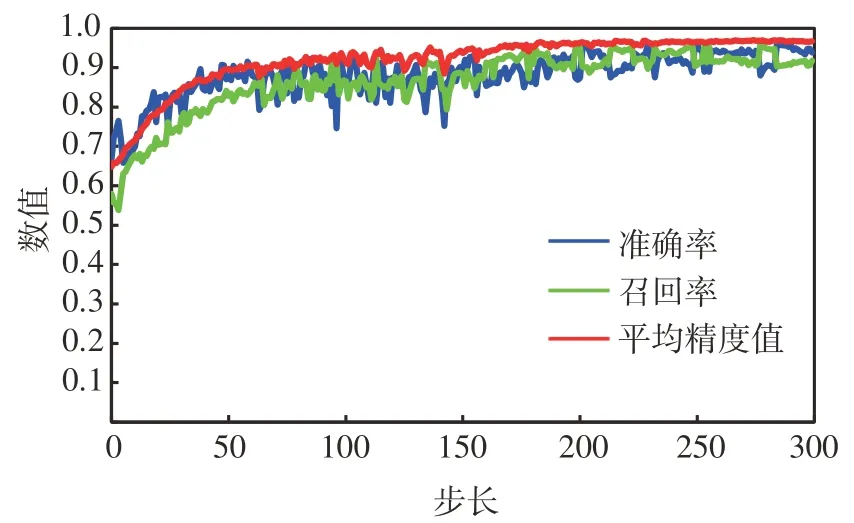
图7 精确指标变化
进一步采用YOLOv5-Deep-Sort 模型对VRUTRAVI(VRU-Traffic accident videos)[35]中两起典型事故的过街行人进行检测跟踪(见图8(a))。事故1中,身着黑色衣服的行人奔跑在斑马线上,由于白色的SUV 挡住了事故车的左侧视线,导致事故车驾驶员未及时发现行人,并未明显减速,导致撞倒行人后停车。事故2 中,身着粉红色连衣裙的行人走在人行横道上。当行人过马路时,没有看到左边开过来的黑色SUV,黑色SUV 的驾驶员也没有看到行人。驾驶员直到撞倒行人后才减速或制动停车。

图8 检测跟踪事故视频对标
图8(b)为临撞前行人检测及运动轨迹实时跟踪结果。通过与原视频进行对标可知,整个碰撞前的过程中,均可实现行人实时检测及跟踪,跟踪的轨迹与行人的真实轨迹基本一致,表明YOLOv5-Deep-Sort模型对事故视频中行人检测跟踪效果良好。
2.2 轨迹预测算法验证
采用ETH/UCY 行人轨迹数据集[31],涵盖了具有挑战性的运动模式,如一起行走和避免碰撞。这两个数据集中总共有5 个子集,包含数百个注释的行人轨迹。这些子集是eth、ucy、hotel、zara1 和zara2,Social-LSTM 轨迹预测算法有效性验证结果如图9所示。经过20 次步长的训练,整体损失呈下降趋势且趋于收敛,其中eth 的损失下降到0.008,ucy 为0.011,hotel 为0.001,zara1 为0.007,zara2 为0.008。训练集和验证集的损失逐渐趋于平稳。
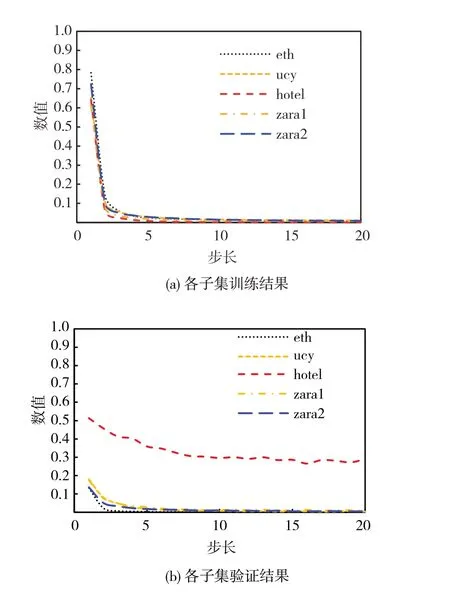
图9 数据集训练验证结果
如表2 所示,通过评价指标平均位移误差和最终位移误差对预测模型进行评估,可得平均位移误差为0.087,最终位移误差为0.092,均低于原始预测模型,其中平均位移误差降低了18.3%,最终位移误差降低了51.9%。因此采用YOLOv5和Deep-Sort对行人进行检测跟踪,结合行人历史轨迹,可以降低预测模型的误差。
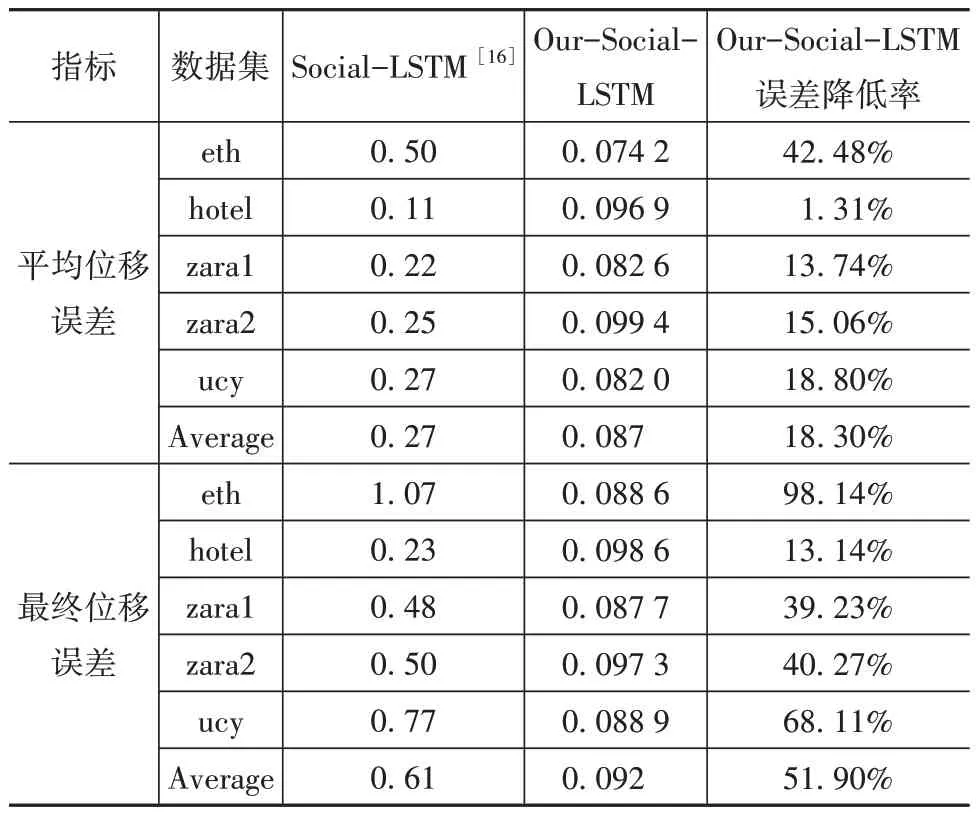
表2 预测模型评估指标对比
基于Social-LSTM 对两起事故视频中的行人碰撞前轨迹进行预测,结果如表3 和图10 所示。表3为事故1 与事故2 的行人碰撞前5 帧的预测坐标与实际坐标对比,随着跟踪时长的增加,预测也随之准确,整体的预测坐标误差在(±0.1,±0.1)。可视化结果如图10 所示。其中黄色为行人的真实轨迹,蓝色为行人的预测轨迹,黄线与蓝线的轨迹基本一致,表明该预测模型能较好预测行人未来轨迹。

图10 碰撞前预测轨迹

表3 行人碰撞前预测坐标
2.3 行人预测轨迹坐标映射
利用不同监控视角,随机采集2 例厦门某路段斑马线上的行人过街视频,分别对其位置进行透视变换,得到如图11 所示的效果。经过变换后,斑马线的畸形程度均降低,且逐渐接近摄像第一俯视角度,验证了透视变换的有效性,便于后续对其建立二维世界坐标系。

图11 不同监控视角的透视变换对比
图12 (a)和图12(b)分别为真实行人事故中碰撞前图像透视变换前后行人轨迹预测对比结果。由图12(b)可知,视频图像透视变换后的斑马线整体长度和宽度畸变程度明显降低,表明透视变换效果较好,采用透视变换后的行人预测轨迹像素坐标可直接与世界坐标转换。

图12 透视变换结果对比
进一步基于透视变换的结果建立二维世界坐标系,依次选取A、B、C、D 4 个点为控制点,如图13 所示。根据《城市道路交通标志和标线设置规范》[36],设 A点世界坐标为(0,0),可得出B、C、D 3个点对应世界坐标依次为(3.15,0)、(3.15,6)、(0,6)。
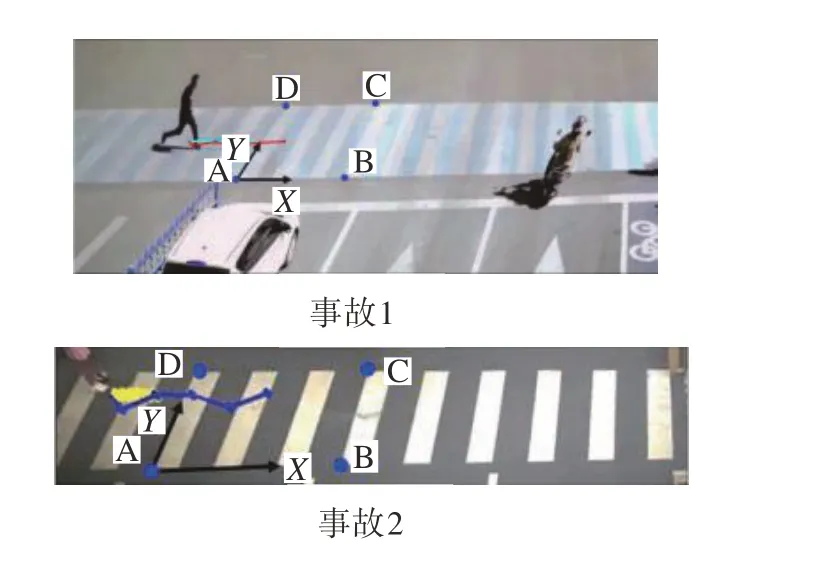
图13 坐标系参照
分别读取事故1 中A、B、C、D 4 个控制点的像素坐标,依次为(412,355)、(686,350)、(766,165)和(540,170),事故2 中4 个控制点的像素坐标为(91,116)、(133,26)、(298,25)和(273,112),根据直接线性变化方程,可得像素坐标与世界坐标间的变换矩阵L1与L2为
进一步读取已预测的未来10 帧行人轨迹像素坐标,通过式(9)变换矩阵和式(11),可得到行人未来轨迹世界坐标。表4 所示分别为事故1 与事故2的行人拟合世界坐标与实际坐标的对比。从表中可以看出,拟合结果与实际值基本一致,误差平均不超过±0.2。图14 为世界坐标系下行人预测轨迹与车辆运动轨迹拟合结果。由图14 可知,基于直接线性变换可实现行人预测轨迹像素坐标与世界坐标之间的转换。基于世界坐标系下的行人轨迹及车辆轨迹可进一步对车辆-行人碰撞点进行预测,并与实际车辆碰撞行人的事故对比可得,预测得到的行人和车辆运动轨迹及碰撞点与真实事故发生的碰撞点位置一致。表明行人预测轨迹坐标映射模型有效。
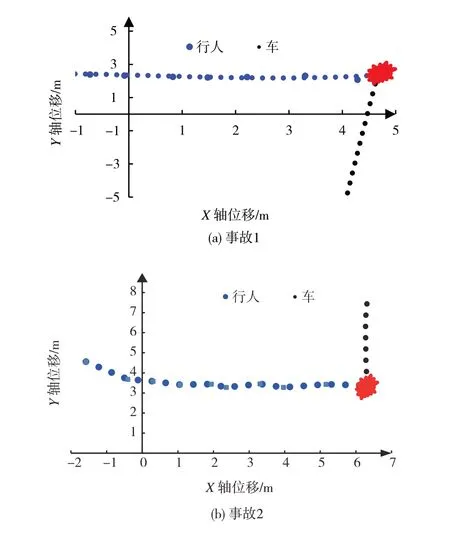
图14 行人与车辆轨迹拟合图

表4 行人碰撞前世界坐标
3 总结与展望
基于真实汽车碰撞行人事故案例视频,采用YOLOv5 和Deep-Sort 算法对行人实时检测与跟踪,同时基于Social-LSTM 算法对行人未来轨迹像素坐标进行预测。通过透视变换与直接线性变换将行人预测轨迹像素坐标转换为世界坐标,主要结论如下。
(1)基于YOLOv5、Deep-Sort 和Social-LSTM 的深度学习算法可实现对事故视频中的行人进行实时检测、跟踪以及轨迹预测,目标检测精度高达93.889%,且预测误差比现有Social-LSTM 有明显降低,其中平均位移误差降低了18.30%,最终位移误差降低了51.90%,与真实事故视频中行人轨迹一致。
(2)基于透视变换与直接线性变换理论可减小视频畸变对行人预测轨迹的影响,实现行人预测轨迹像素坐标与世界坐标之间的转换,将行人与车辆的世界坐标进行拟合,可精确预测车辆碰撞行人碰撞点位置,便于车辆避撞策略的开发,为智能车辆避撞感知和决策融合提供参考依据。
本文研究目前局限于行人横穿道路的线性运动,后续将结合行人的不规则随机运动轨迹进行预测;在坐标映射模型的量化分析中,将进一步增加典型事故案例样品数量。
