XGBoost融合模型在银行客户流失预测中的应用研究
2023-06-25陈光镁孙雪莲
陈光镁 孙雪莲
摘要:针对银行行业的客户流失问题,构建基于地域、收入、信用卡、银行存款等属性的银行客户指标体系,研究中采用K-Means对数据进行聚类分析,细分客户类型,将细分结果作为XGBoost、ANN预测模型的输入,从而融合XGBoost与K-Means模型,经过分析发现单一模型acc(准确率)在85%左右,融合模型的acc在87%以上,根据K-Means-XGBoost融合模型与K-Means-ANN融合模型的预测结果,利用流失概率公式构建XGBoost-ANN组合模型,通过调节两个模型占比来确定最优模型,根据组合模型计算acc。实验显示,组合模型的acc、F1-Score等均高于单一算法模型与融合模型。
关键词:客户流失;XGBoost;ANN神经网络;聚类算法;融合模型;组合模型
中图分类号:TP301 文献标识码:A
文章编号:1009-3044(2023)13-0055-03
开放科学(资源服务)标识码(OSID)
0 引言
目前银行在客户竞争方面面临着严峻挑战,面对激烈的市场竞争,如何尽可能留住老客户,减少客户流失是目前银行应重点关注的问题[1]。研究表明,对银行业而言,客户流失会给利润带来巨大的影响[2],当客户流失率减少5%,企业的利润增长是30%到85%,发展新客户的成本是挽留老客户成本的5~7倍[3]。所以银行必须在深入发现客户需求的基础上,对客户赋予优质的、非同质化的服务[4],从而满足不同客户的要求,从而提升客户对银行项目和服务的满意程度,提高客户对银行的忠诚度,这样才能实现银行盈利的持续增加。
客户希望银行可以根据他们的需求和资产情况推出需要的投资理财相关的产品或服务,而这就要求银行要积极建立完整的客户需求体系、主动维护良好的客户关系,并及时关注客户意向的转变,定制并提供具有个性化的产品及服务[5]。因此,有效预测客户流失可能性,制定相应的挽回措施,防止客户的流失,是银行提升核心竞争力的关键。基于银行客户数据建立RFM模型同时使用K-Means进行聚类分析,将客户类型进行细分。对XGBoost模型和ANN神经网络模型实验得到两个的预测值和准确度,将两者的流失概率组合成新模型,通过新模型不断地调整两个模型的比重,直到模型的准确度和拟合度最高[5]。
1 预测模型
1.1 K-Means融合模型
选择预测效果、轮廓系数均最优的类簇进行聚类[6],将K-Means聚类结果(3类)进行处理,生成三个新的数据集,将三个数据集作为XGBoost、ANN预测模型的输入(每个数据集单独预测),构建K-Means与XGBoost、ANN的融合模型,进行融合模型的训练测试,得出结果,搭建步骤如下:
1) 使用K-Means进行两次聚类,选择预测效果和SH系数均佳簇个数([k1=2]、[k2=2]) ,将客户类型细分为3类得到3组数据,在手肘法的基础之上进行轮廓系数的比较[6],最终使用SH系数进行评价。
2) 对K-Means细分客户[6]的三个数据集进行处理,数据没有缺失、异常等问题,将K-Means输出分别存储到不同的文件中,为模型融合做准备。
3) 将细分客户类型分别代入ANN、XGBoost模型中进行训练,训练完毕后,两个模型在测试集上进行测试,得出准确率。
4) K-Means[7]与ANN、XGBoost融合得出预测结果,最终得到准确率、精确率等。
1.2 组合模型
对于XGBoost模型和ANN神经网络模型[8],两者都能在客户流失管理中对潜在的流失客户进行预测,通过实验可以分别得到两个模型的预测值和准确率[8]。本文将两者组合起来建立组合建模,并进行分析。设XGBoost流失预测模型的预测结果为[X],预测准确率为[α];ANN神经网络流失预测模型的预测结果为[Y],预测准确率为[β]。其中,[X]和[Y]的取值为0或者1,0-未流失,1-流失。[α]和[β]的取值范围为[0,1]。设[Tw]为组合模型的流失概率,则[Tw]的计算如公式(1) 所示。
[Tw=k1αX+k2βY] (1)
初始时设置[k1],[k2]为0.1、0.9,然后不断调整两个模型的占比,直至找出最佳的[Tw]值。对于组合模型来说,若XGBoost模型和ANN神经网络模型都预测为未流失[9],即[X], [Y]都取值为0,则[Tw]也为0,组合模型预测结果为流失;若两个模型都预测为未流失,即[X],[Y]都取值為1,若[Tw]大于等于70%,则组合模型预测结果为流失,反之组合模型预测结果为未流失;若两个模型中,一个模型预测为流失,一个为未流失,则依据组合模型的流失概率来判断,则[Tw]大于35%,表明组合模型预测结果为流失,反之组合模型预测结果为未流失。后续不断地调整XGBoost模型和ANN神经网络模型的占比[9],调整时从两个模型分别占比10%、90%,一直调整到两个模型分别占比90%、10%。直至模型的准确度和拟合度最高[9]。
2 客户类型分析结果
2.1 特征重要性排序
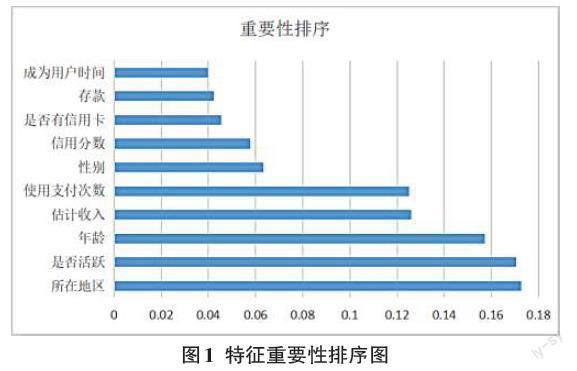
文中选用随机森林进行特征重要性的排序,选取前十行为[x]的取值,最后一列为[y]的取值,算法实现后特征重要性排序如图1所示。当[n_estimators=10000]时,Geography特征的重要性系数为0.166 258(最高),其次是IsActiveMember、Age分别为0.163 906、0.153 392,最低的是Tenure,重要性系数仅为0.039 8,估计收入情况、使用信用卡支付次数、性别、信用分数等重要程度在0.126 007到0.057 710之间。
2.2 K-Means客户类型细分
第一次聚类k=2时轮廓系数为0.467 4,类型0数据占总数据的超60%,而类型1的数据大约占总数据的38%,类型0单独进行预测准确率偏低,单独将类型0再进行一次聚类分析。第二次聚类k=2时轮廓系数为0.495 8,且类型0(第二次)占据占比50%,类型1(第二次)占据了接近50%。
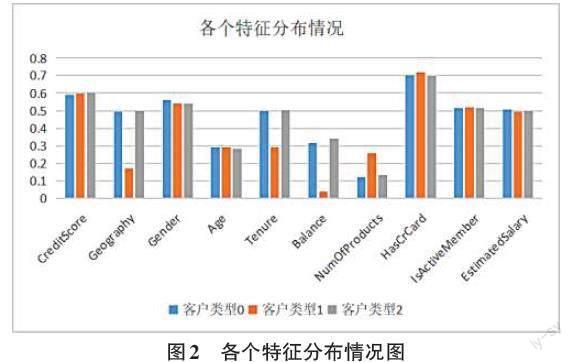
文中定义了3种客户类型,利用RFM的分类原理,结合随机森林特征重要性排序,选Salary、Balance、CreditScore三种属性作为指标,两次K-means得到的聚类特征分布情况如图2所示。据分析,第一簇人群:3 799人,客户Balance、EstimatedSalary、CreditScore三个指标数据均值高,将类型0定义为低流失风险客户;第二簇人群:3 135人,类型1客户EstimatedSalary偏高,Balance、CreditScore都是偏低的,将其定义为高流失风险客户;第三簇人群:3 057人,类型2的三个指标均值较高,定义为中流失风险客户。
3 实证研究
3.1 融合模型预测
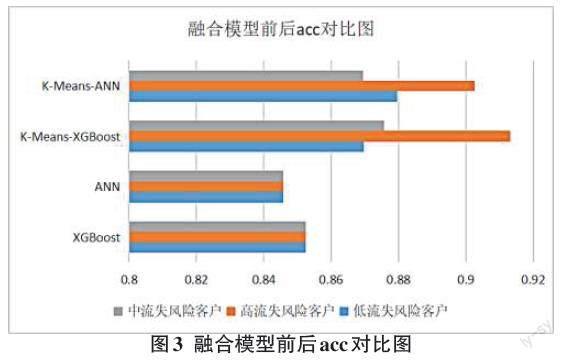
低流失风险客户实验中test_size=0.1,XGBoost的max_depth=2,ANN中训练1 500次alpha=0.000 1结果对比图如图3所示,从图中可知对于该类型客户而言,XGBoost融合模型的准确率提高了0.017 2,ANN融合模型的准确率提高了0.032 0。高流失风险客户实验中test_size=0.1,XGBoost的max_depth=2,ANN中训练1 000次alpha=0.000 1结果对比图如图3所示,XGBoost融合模型的预测准确率提高了0.060 7,ANN融合模型预测准确率提高了0.055 1。中流失风险客户实验中test_size=0.1,XGBoost的max_depth=2,ANN中训练1 500次alpha=0.000 1结果对比图如图3所示,XGBoost融合模型的准确率提高了0.023 3,ANN融合模型的准确率提高了0.021 9。
3.2 ANN-XGBoost组合模型预测
低流失风险客户组合模型为[Tw2=0.5αX+0.5βY]时模型最优,组合模型准确率比融合模型提高了0.0424,比单一模型分别提高了0.069 6、0.064 6;高流失风险客户组合模型为[Tw2=0.6αX+0.4βY]时预测效果最好(最优模型),组合模型准确率比融合模型准确率平均提高了0.05,比最初的单一模型分别提高了0.105 4、0.110 4;中流失风险客户组合模型为[Tw2=0.4αX+0.6βY]时模型最优,中流失风险客户K-Means-XGBoos融合模型的准确率提高了0.023 3,K-Means-ANN的准确率提高了0.021 9,XGBoost-ANN组合模型比融合模型准确率平均提高了0.0287,比单一模型平均提高了0.051 3,各评价指标对比图如图4所示。相较于前两个阶段而言,组合模型很大程度上提高了预测的准确率,在K-Means聚类的基础上XGBoost与ANN组合对预测模型的改进是有效的。
4 结束语
通过对多种机器学习算法的应用,进行特征的重要程度排序,进一步确定流失预测所需要的重要指标,避免了特征的浪费也避免的特征过度带来的麻烦,结合特征工程、RFM模型理论等手段,建立K-Means聚类模型实现更为科学化的客户细分体系,分析影响客户类型的各项指标,更为准确地进行客户的类型。将K-Means与XGBoost、ANN融合对客户流失进行预测,再將融合后的XGBoost与ANN结合,更好的反映客户所处在的状态以及在当前状态下结合该客户的类型能够提出更贴合实际的策略。但是对于银行客户的价值体系,需要不断完善和更改,适当的收紧评估体系,同时在对客户进行聚类分析的时候采用的是单一K-Means算法,应考虑更新且改进后的算法,如KNN或者加权值的K-Means算法。
参考文献:
[1] 张芸.基于复合CatBoost的银行客户流失预测模型[D].兰州:兰州大学,2021.
[2] 陈静,余建波,李艳冰.基于随机森林的用户流失预警研究[J].精密制造与自动化,2021(2):21-24,51.
[3] Becker J U,Spann M,Schulze T.Implications of minimum contract durations on customer retention[J].Marketing Letters,2015,26(4):579-592.
[4] 李波,谢玖祚.生成对抗网络的银行不平衡客户流失预测研究[J].重庆理工大学学报(自然科学版),2021,35(8):136-143.
[5] 程勇,梁吉祥.基于数据挖掘的掌银客户流失预测建模方法研究[J].中国金融电脑,2019(8):10.
[6] 闫春,张馨予.基于改进的K-means和BP-Adaboost的寿险客户流失预测算法研究[J].山东科技大学学报(自然科学版),2022,41(1):54-65.
[7] 刘玥.基于改进的K-means算法的银行客户聚类研究[D].长春:吉林大学,2016.
[8] 张安琳,张启坤,黄道颖,等.基于CNN与BiGRU融合神经网络的入侵检测模型[J].郑州大学学报(工学版),2022,43(3):37-43.
[9] 刘海航.基于XGBoost和BP神经网络的会员流失预测及内容推荐方法的研究[D].呼和浩特:内蒙古大学, 2019.
【通联编辑:王力】