基于外部知识的视觉问答研究
2023-06-25贾少杰王雷
贾少杰 王雷

摘要:视觉问答(Visual Question Answering, VQA) 是当前融合计算机视觉领域和自然语言处理领域的典型多模态问题之一,而基于知识的视觉问题回答任务要求模型具有关联外部知识的能力,文章采用多模态数据集当作外部知识源,相比从文本知识库中提取单模态的文本语义,多模态数据集能够提供视觉问答所需要的多模态知识,能够更好地利用图像中所蕴含的知识,并将其应用到针对图像中问题的回答中。同时,为了能够更轻量级地进行学习,在问题文本中添加并训练了一个前缀prompt,并且冻结了部分的预训练模型参数,通过采用预训练和微调指定未冻结参数的学习策略,逐步积累了基础的多模态知识,用于进行答案的推理。最后,经实验结果证明,文章模型在冻结预训练模型中的大部分参数后,在VQA-V2实验数据集中也具有较好的表现,同时在获取到VQA-V2中的多模态外部知识后,在需要进行推理的数据集OK-VQA数据集上也取得了令人满意的结果,拥有较高的准确率。
关键词:视觉问答;prompt tuning;多模态预训练模型
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2023)13-0015-04
开放科学(资源服务)标识码(OSID)
1 视觉问答研究的相关基础
1.1 视觉问答的概述
多模态视觉问答作为计算机视觉与自然语言处理的一个交叉领域,近年来受到学术界多方关注,主要任务是通过给定一幅图像以及关于该图像的一个开放的用自然语言描述的问题,借助问题和图像中的内容推断出正确的答案,传统的方法是首先将两种模态的数据分别进行嵌入表示,之后通过特征融合的方法对不同模态的数据进行建模,在获取到每个模态单独的特征表示之后进行视觉问答最重要的特征融合工作,目的是将特征空间不同的各模态特征拉入同一个特征空间中,经过融合后的特征向量使用不同的目标函数约束可以得到不同的结果输出,目前的视觉问答为了方便进行精准度的计算,普遍采用分类形式的答案,生成式的答案不利于指标评估。
视觉问答的关键在于不同模态之间的特征融合,特征融合根据阶段的不同可以分为早期融合与晚期融合、混合融合等,早期融合指在各模態提取特征后立刻进行融合,晚期融合指分别训练各模态的模型之后将模型输出进行融合。早期的特征融合常采用基础的向量运算,这种处理方法逻辑简单、计算量较小,但最终并不能在复杂的多模态数据环境下取得很好的融合结果。
目前,常用于特征融合的多模态预训练模型多采用Transformer 机制,通过对大量的无标签多模态数据进行预训练,然后在具体任务中使用少量的标注数据来进行微调,然而使用Transformer 机制计算量与代价都很大,如何能够减少训练参数,实现更轻量级的训练方法也是目前的一大研究热点。
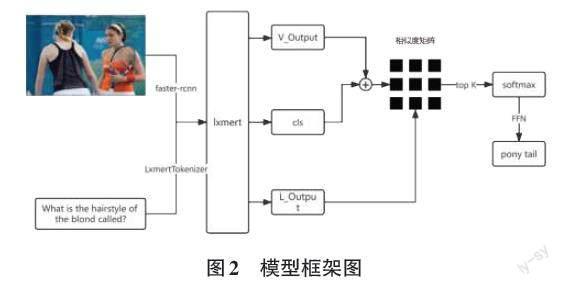
针对需要外部知识的视觉问答,此类问答不只单纯提问图像中的内容,如图1所示,图中左侧的问题提问金发的发型叫什么,只根据图中的信息而不知道发型种类的话是无法推断出是马尾发型的。最近的大多数相关工作都基于知识库检索的方法,此类方法首先从庞大的外部文本知识库中检索相关事实,然后对知识图进行显式推理[1-2]。
受Ding[3]等人提出的Mukea模型的启发,针对需要外部知识进行视觉问答的数据集OK-VQA,通过在知识库中查询的方法没有能够很好地利用多模态的外部数据,而只是利用了知识库中的文本知识,这在多模态问答中略显不足,通过在大规模的视觉问答数据集VQA-V2中对预训练模型以及模型参数进行粗调,能够很好地提取到外部的多模态知识。
1.2 Prompt在视觉问答领域的应用
Prompt中文译作提示,是一种帮助计算机解决视觉问答中关键问题的提示内容,此前在NLP领域中微调prompt取得了不错的成绩,prompt一般分为两种:人工设计的prompt以及连续的prompt, 人工设计prompt的方法通过人工设计的prompt需要额外的知识以及专家的经验来设计,整个设计过程耗时耗力,可能会取得很好的结果但是不具有可迁移性。而连续类的可学习的prompt,需要考虑初始化、向量的长度等设置,这些设置可以在不断的实验过程中根据实验结果进行调整,在NLP领域中的prompt-tuning和prefix-tuning[4]就是典型的连续类prompt的例子。
Prompt在多模态领域的使用主要目的有两个,一是将预训练模型更接近下游任务,二是进行更加轻量级的训练,通过冻结预训练模型的参数来降低训练量,如Frozen模型[5],本文的方法主要侧重prompt在轻量级训练中的应用,在后续的内容中会介绍冻结预训练参数进行训练的训练方法。
2 视觉问答模型研究
问答系统流程的研究,本文将其分为以下几个部分进行介绍(整体流程如图2所示),首先介绍模型的两种模态数据输入处理,然后介绍预训练模型的处理,第三部分介绍答案预测部分,最后介绍粗调和精调的训练思路。
2.1 模型输入
模型的输入是一张图片以及一条涉及图片内容的问句,第一步就是对两种模态数据的特征提取,针对图像可以提取出多个目标区域的位置向量以及语义向量,通过Faster-rcnn[6]获取图片中不同主体的特征表示,每张图片选择36个特征,通过Faster-rcnn后的图片特征表示为一个2 048维的向量fi ∈ Rdf (df = 2 048),位置信息则表示为一个四维向量bi∈Rdb(db = 4)。
针对问题文本的嵌入表示,使用了预训练模型lxmert中的LxmertTokenizer,该tokenizer与bert中的tokenizer用法相同,都是基于WordPiece[7]的嵌入方法,问句经过该嵌入方法后被表示为多个token组成的序列qi。
考虑到多模态预训练模型在多模态信息的融合方面能力强大,采用lxmert预训练模型进行多模态内部以及模态之间的信息建模。将fi、di以及问题文本的嵌入表示qi一同输入经过参数冻结的预训练模型lxmert中,就能得到问题向量Q和视觉向量V以及一个多模态融合向量cls,其中Q和V∈Rdv(dv=768)。
2.2 预训练模型处理
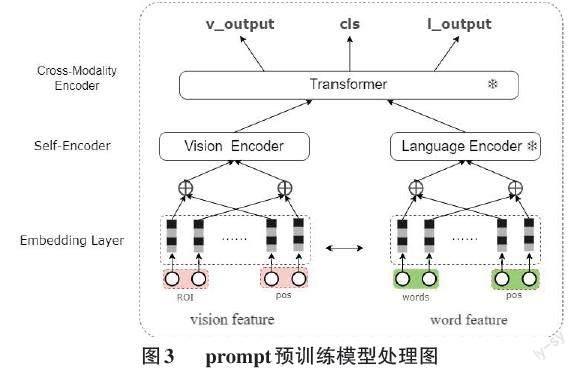
Lxmert模型[8]作为典型的双流预训练模型,首先在单模态内进行自注意力编码,然后设计了跨模态的注意力来学习跨模态信息,以及进行跨模态特征融合,笔者设计的Frozen模型,冻结了预训练模型lxmert中的大部分参数,根据不同的方法冻结不同的参数进行试验,在进行prompt训练的过程中,冻结了预训练模型中除视觉encoder之外的全部参数,整个粗调过程只更新预训练中的视觉encoder以及后续的相似度矩阵和全连接等参数,参数冻结部分如图3所示,图中的雪花标识代表该部分参数已被冻结。
通过只更新视觉encoder来进行训练,这种训练的目的是使用更少的训练参数,避免对数据量较大的预训练模型进行大规模的参数更新。同时,将vision encoder的参数激活的目的是将图片特征的嵌入表示拉到文本的特征空间中,减少不同模态数据表示空间之间的差异。
除此之外,筆者尝试进行了prefix前缀训练方法,在问题文本的嵌入表示向量之前,添加了一段与文本向量维度相同的prefix,在粗调和精调的阶段冻结全部的预训练模型的参数,只训练prefix中的参数以及预训练后的线性层中的参数。
2.3 答案预测
在获取到预训练模型的输出之后,为了能够更好地缩小图片特征与文本特征之间的差距,将图片特征与多模态关系特征进行融合,多模态输出cls起到将视觉特征拉入文本特征空间的作用。同时,为了衡量图片中的对象与问题中的每个词项的相关关系,使用了一个相似度关联矩阵M,图中对象与问题词项相似度越高,则被后续过程选择中的概率越大,然后再与问题词项进行相似度计算,选取相似度最高的融合特征。
[M = (W1Q)T(W2(V+cls))]
选取到与问题最相关的融合特征后,经过一个激活函数softmax以及top k来选取到与问题文本相似度最高的融合特征,选取到的特征经过一个全连接层,输出维度为数据集答案词典维度,通过在查找表中查找出最终答案,在损失函数的选择方面,参考Mukea模型的损失函数选择,受传统知识图领域中的知识嵌入方法TransE的启发,在多模态场景中应用了类似TransE的目标损失函数来作为参数反向传播的依据。
[LTransE = ∑t+∈A+ ∑t?∈A? [γ+d(v+cls, t+)?d(v+cls, t?)]]
其中v+cls代表与多模态关系融合后的图中目标向量,A+代表预测正确的答案,A-代表错误的答案,这个损失函数的目的是使融合后的图中目标向量能够更加接近正确的答案,与正确答案之间的transe距离变小。
2.4 粗调和精调
粗调和精调的整个流程即为上述的步骤,但是不同之处在于粗调是在大规模的多模态视觉问答数据集VQA-V2上进行操作的,好处在于VQA-V2的数据规模相较目标数据集更大,虽然不及外部知识库中的开放领域的文本知识量,但是具备丰富的多模态外部知识,能够解决文本知识模态单一,与图片模态特征空间差距较大的问题。在进行粗调之前,去除VQA-V2中的yes/no类问题以及计数类问题,只保留包含外部知识的开放类问答对,这样操作的目的在于去除掉不包含外部知识的训练数据,减少对预训练模型的干扰。
精调则是在目标数据集上再一次进行微调,经过粗调后的模型已经获得了丰富的外部知识,可以针对某些特定的数据集进行微调,OK-VQA数据集中包含的问答是经过人工筛选的,能够骗过基础模型的复杂问题,只通过图片中的信息无法推断出答案,需要借助一些外部的知识。在针对该数据集进行精调时,该数据集的数据量比起VQA-V2数据集要小很多,所需的计算资源也相对较少,考虑在精调时,放开在粗调时固定的参数,以此取得更好的准确度。其中粗调与精调的两个步骤均包含在下述的实验中,包括完整的实验模型以及针对轻量级学习的prompt和prefix微调的实验。
3 实验结果及分析
为了验证视觉问答模型的可行性,本文利用VAQ-V2以及OK-VQA数据集进行相应的实验,同时针对不同的微调方法进行了相应的对比和测试,证明了该模型的有效性。
3.1 数据集介绍
VQA-V2[9]数据集 全称 Visual Question Answering (v2.0),是一个人工标注的、关于图像的开放式问答数据集。回答这些问题,需要对图像、语言以及常识都具备一定的理解力,在VQA-V2数据集中,针对每一幅图像通常准备了三个问题,针对每个问题有10个正确的答案。
OK-VQA[10]数据集中的图像数据来自COCO数据集,共计约8万张训练图像以及4万张测试图像。经过两轮的人工筛选,剔除掉了直观上可以回答的简单问题,原本86 700个问题最终筛选到34 921个问题。针对s数据集中的偏见问题,作者删除掉了相同答案频率超过五次的问答对,剩余问答对共计14 055道,包括9 009道训练题和5 046道测试题。此外,在OK-VQA数据集上的模型准确率要远低于VQA-V2等直观问答数据集,因为该数据集需要外部知识进行联合推理。
3.2 实验环境及参数设置
本文的实验环境选择采用Windows操作系统和英伟达Tesla P100显卡,深度学习框架采用PyTorch,以此对基于深度学习框架进行实验,并利用Python语言对其进行编程。
参数设置方面:batch size设置为256,优化器选择了adam优化器,学习率为1e-4,训练过程进行200个epoch,得到最终的实验数据。
3.3 結果分析
表1为OK-VQA数据集上不同方法的最终结果,表2为一部分的消融实验以及两种冻结参数的微调方法的最终结果。
如表1所示,完整模型在上述的实验环境与参数设置下的准确度达到了41.01,好于OK-VQA论文中提及的基准方法MUTAN+AN等,虽然VQA-V2的外部知识远没有维基百科和conceptnet中的文本知识丰富,但是模型依然取得了不错的准确度,证明了模型引入多模态外部知识的有效性。
以下是关于表2的分析:
方法2的结果为在VQA-V2进行粗调之后直接在目标数据集上进行准确度验证,并不在目标数据集上进行微调,不包含OK-VQA中知识的模型推导能力较差,也反映了OK-VQA数据集中的问答对难度较高,需要丰富的外部知识。
方法3的结果是在冻结lxmert的全部参数且不添加任何其他结构的情况下,只训练预训练后的网络结构参数。
方法4的结果是直接在目标数据集上进行精调的结果,根据准确度可以得出,通过在外部数据集上进行粗调的方式来引入外部知识是一个有效的途径,直接精调的结果比起完整模型还有一定的差距。
方法6的prompt微调方法和方法5的prefix微调方法在准确度上的差异不大,实验准确度在冻结大部分参数的情况下依然好于未经VQA-V2预训练而直接在OK-VQA上微调的方法4,同时也好于完全冻结预训练模型的方法3。
4 结束语
综上所述,文章对目前主流的视觉问答方法进行了梳理,并提出了一种基于外部知识和多模态预训练模型的视觉问答方法,本方法通过使用预训练模型来进行多模态数据的融合,使用大规模视觉问答数据集VQA-V2来对模型进行一次粗调,之后再利用粗调后的模型数据在目标数据集上进行微调,这样做能够更好地引入多模态的外部知识。
方法的局限性在于多模态问答的训练数据集不够全面,VQA-V2中所包含的外部知识并没有通用知识库中的内容丰富,有很多视觉上相近的材料或物品无法进行有效分辨,prompt和prefix参数的初始化方面还需要继续进行尝试。
参考文献:
[1] Narasimhan M,Lazebnik S,Schwing A G .Out of the box:reasoning with graph convolution nets for factual visual question answering[EB/OL].2018:arXiv:1811.00538.https://arxiv.org/abs/1811.00538.
[2] Wang P,Wu Q,Shen C,et al.FVQA:fact-based visual question answering[EB/OL].2016:arXiv:1606.05433.https://arxiv.org/abs/1606.05433.
[3] Ding Y,Yu J,Liu B,et al.MuKEA:multimodal knowledge extraction and accumulation for knowledge-based visual question answering[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).,New Orleans,LA,USA.IEEE,2022:5079-5088.
[4] Li X L,Liang P.Prefix-tuning:optimizing continuous prompts for generation[EB/OL].2021:arXiv:2101.00190.https://arxiv.org/abs/2101.00190.
[5] Tsimpoukelli M,Menick J,Cabi S,et al.Multimodal few-shot learning with frozen language models[EB/OL].2021:arXiv:2106.13884.https://arxiv.org/abs/2106.13884.
[6] Ren S Q,He K M,Girshick R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[7] Wu Y,Schuster M,Chen Z,et al.Googles neural machine translation system:bridging the gap between human and machine translation[EB/OL].2016:arXiv:1609.08144.https://arxiv.org/abs/1609.08144.
[8] Tan H, Bansal M. LXMERT: Learning Cross-Modality Encoder Representations from Transformers[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019: 5103-5114.
[9] Goyal Y, Khot T, Summers-Stay D, et al. Making the V in VQA Matter: elevating the role of image understanding in visual question answering[C]//Proceedings of the IEEE International Conference on Computer Vision, 2017: 6325-6334.
[10] Marino K,Rastegari M,Farhadi A,et al.OK-VQA:a visual question answering benchmark requiring external knowledge[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).,Long Beach,CA,USA.IEEE,2020:3190-3199.
[11] Ben-younes H,Cadene R,Cord M,et al.MUTAN:multimodal tucker fusion for visual question answering[C]//2017 IEEE International Conference on Computer Vision (ICCV).IEEE,2017:2631-2639.
[12] Zhu Z,Yu J,Wang Y,et al.Mucko:multi-layer cross-modal knowledge reasoning for fact-based visual question answering[EB/OL]2020:arXiv:2006.09073.https://arxiv.org/abs/2006. 09073.
[13] Gardères F,Ziaeefard M,Abeloos B,et al.ConceptBert:concept-aware representation for visual question answering[C]//Findings of the Association for Computational Linguistics:EMNLP 2020.Online.Stroudsburg,PA,USA:Association for Computational Linguistics,2020.
【通聯编辑:唐一东】