融入对抗训练的中文电子病历命名实体识别
2023-06-22李曼玉于瓅
李曼玉 于瓅

摘 要:为提高中文电子病历中命名实体识别模型鲁棒性和准确性,为此提出一种基于BERT模型融入对抗网络的中文电子命名实体识别模型,该方法使用BERT预训练模型动态生成字向量,通过对抗训练生成扰动,将字向量与扰动相加生成对抗样本,再通过膨胀卷积网络(IDCNN)捕捉句子单词间的依赖,最后通过条件随机场(CRF)得到最终预测结果。在CCKS 2019数据集上的实验表明,模型的F1值达到83.19%,证明该模型的有效性。
关键词:命名实体识别;中文电子病历;BERT;对抗训练;
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2023)02-0090-04
Named Entity Recognition of Chinese Electronic Medical Record Integrated
with Confrontation Training
LI Manyu, YU Li
(School of Computer Science and Engineering, Anhui University of Science and Technology, Huainan 232001, China)
Abstract: In order to improve the robustness and accuracy of the named entity recognition model in Chinese electronic medical records, a Chinese electronic named entity recognition model based on the BERT model and the confrontation network is proposed. The method uses the BERT pre-training model to dynamically generate the word vector, generates the disturbance through the confrontation training, adds the word vector and the disturbance to generate the confrontation sample, and then captures the dependency between the words in the sentence through the Iterated Dilated Con-volutional Neural Network(IDCNN). Finally, the final prediction result is obtained by Conditional Random Field (CRF). The experiment on CCKS 2019 dataset shows that the F1 value of the model reaches 83.19%, which proves the effectiveness of the model.
Keywords: named entity recognition; Chinese electronic medical record; BERT; confrontation training
0 引 言
近年來,人工智能的快速发展,现已深入与不同领域结合,如医疗领域,其中电子病历作为疾病诊断治疗的记录,为医生诊断,疾病预防提供决策和医疗保险报销提供支持。目前电子病历大部分以半结构化形式存储,命名实体识别作为快速提取半结构化文本中信息的技术,如何准确的提取出信息是命名实体识别技术的关键。
命名实体识别作为自然语言处理基础,文本预处理的下游任务之一,命名识别是关系抽取、知识图谱构建的基础,其准确率高低直接影响下游任务。通用领域中命名实体识别主要识别出新闻文本中的人名、地名、组织名等。目前,命名识别任务也广泛应用于不同的领域,如裁判文书、医疗中电子病历等。其作为典型序列标注任务,需根据具体任务先预定义实体类别对文本进行标注,在医疗文本中实体类别可以定义为疾病、诊断、检查、药物、手术部位等。
Wu等[1]为丰富训练数据从现有的标记数据自动生成伪标记样本,采用CNN-LSTM-CRF神经架构来捕获局部和远程上下文,为了增强模型识别实体边界的能力,联合训练识别模型和分词模型。陈茹[2]使用CNN获取字的字符向量、部首向量结合词向量,送入局部注意力捕捉局部特征,使用IDCNN替代BILSTM,再通过全局注意力提取上下文关联信息,但是存在外部资源对数据集的干扰。赵萍[3]在使用多特征降低未登录词的干扰,在注意力机制中引入动态缩放因子,减小了无关词对模型的干扰。谭岩杰[4]使用提出门控空洞卷积与级联网络,将编码信息分别输入至CRF层和Softmax层中进行解码作为级联结构,将中文命名实体识别任务改为多任务学习,降低在CRF层中分类计算的复杂度,提高精度取得的较高F1。
上述模型在开放领域效果较好,在特定的专业领域,领域文本存在大量技术术语和习惯表达,在医学信息领域命名实体识别任务从文档中提取疾病等相关实体,并将其分为预定的类别。其中,杨红梅[5]构建医学专用词典基于结巴分词进行语义分割,使用双向LSTM网络结合CRF训练模型,但是由于分词错误影响识别准确率。巩敦卫[6]词嵌入层融合字符、单词、字形丰富特征,使用BILSTM模型,加入注意力机制,最后通过CRF得到最终标签,在自建糖尿病数据集上取得较高F1值。梁文桐[7]提出了一个基于BERT的医疗电子病历命名实体识别模型,结合膨胀卷积和多头注意力,分别捕捉局部特征和全局特征,在CCKS 2019数据集上F1值达到82.43%。孔令巍[8]在BERT-BILSTM-CRF中加入对抗训练在CCKS 2021数据集上F1值达到了93.92%。
针对医疗NER任务中分词错误或者歧义会影响到实体边界的确认从而影响实体识别,选择BERT预训练字向量,又由于神经网络模型易受未登录词等外界信息影响,造成模型稳定性不高,为提高模型准确性和鲁棒性,给出了基于对抗训练的医疗文本命名实体识别模型,将BERT与IDCNN结合增加对抗训练运用在医疗文本中。该方法的贡献在于:
(1)将字向量通过BERT模型预训练,避免分词错误对实体识别效果的影响,使模型更好的学习上下文语义生成字向量。
(2)通过IDCNN膨胀卷积提取局部距离上下文语义,丰富特征信息同时提高模型运行的并行性,减少模型训练的运行时间。
(3)加入对抗训练提高模型的鲁棒性和准确性,避免微小扰动对模型的准确性产生较大影响。
1 神经网络结构
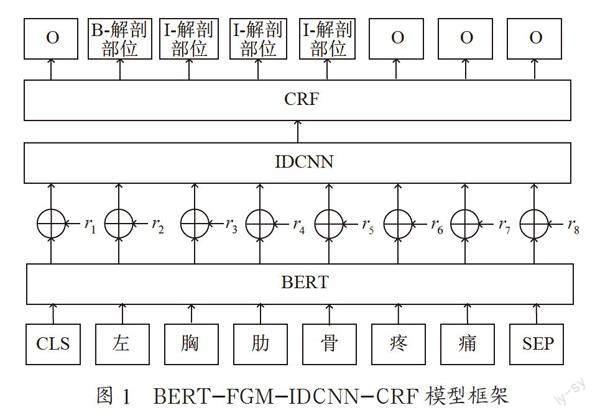
模型框架如图1所示,由词嵌入层,IDCNN层和CRF解码层三层组成。BERT层输入层的作用将原始文本序列转化为模型可接受的矩阵,以“左胸肋骨疼痛”为例,其中,BERT模型将每个字被处理为对应的字向量,通过对抗网络加入扰动值r,将字向量与扰动值r相加得到新特征向量,通过全连接层实现维度变换,再送入IDCNN捕捉长文本的局部特征,最后通过CRF进行解码得到最终的预测序列标签。
1.1 词嵌入层
词嵌入层主要由BERT模型和对抗训练组成。Bert是由12层的双向Transformer编码器构成,使用两项任务进行训练分别是MLM和NSP,MLM任务是将句子中字作为token进行掩盖(mask),随机掩盖15%的单词,在这15%中80%的单词替换成[mask],10%替换成任何单词包括自身,10%保持不变,通过上下文预测被掩盖位置原本的单词。NSP任务预测任意两句之间的关系,判定是否連续为上下文。不同于静态词嵌入如word2vec、glove无法处理不同语境下的语义问题,BERT根据语境变化动态生成词向量更好地解决一词多义的问题。
BERT的输入为词向量(Token Embedding),片段向量(Segment Embedding),位置向量(Position Embedding)三者加和,在中文任务中Token Embedding为对应字向量,其中[CLS] [SEP]符号分别用来表示句子的开始位置与结束位置,Segment Embedding区分不同句子用来预测两句之间的关系,Position Embedding标记字的位置信息:以“直肠癌伴有穿孔”“感染性休克”为例,如图2所示。
BERT经过12层的双向Transformer训练,会产生12个输出向量,对于BERT模型到底学到了什么,Ganesh Jawahar[9]通过一系列的实验证明BERT学习到了一些结构化的语言信息,比如BERT的低层网络学习到了短语级别的信息表征,BERT的中层网络学习到了丰富的语言学特征,而BERT的高层网络则学习到了丰富的语义信息特征,且在高层中会遗忘低层学习到的浅表信息。为了充分利用语义特征,对BERT模型后4层输出求平均作为字向量输出。
对抗训练常用在计算机视觉领域,在自然语言处理领域常用FGM[10]、PDG[11]算法来实现对抗训练,模型使用FGM算法,输入当前BERT模型生成样本的字向量的损失值和当前梯度值,计算生成扰动量r,字向量与扰动量相加即为对抗样本,将生成的对抗样本再次送进IDCNN层。
1.2 IDCNN层
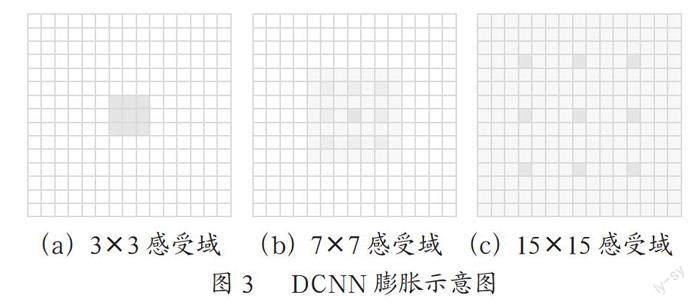
Strubell等[12]提出了迭代卷积神经网络(IDCNN)以此来改善NER任务的并行性。IDCNN是指卷积核中存在空洞的CNN又称为空洞卷积、膨胀卷积,其通过卷积核增加空洞来扩大感受域,在滤波器本身的大小并没有发生变化的情况下扩大感受域,来获得更多细节减少信息损失。如图3所示,卷积核大小为3,图(a)中(膨胀宽度)dilation=1,感受域为3×3;图3(b)中dilation=2,感受域为7×7;图3(c)中dilation=4,感受域为15×15。
膨胀卷积网络和一般的卷积网络一样通过在输入矩阵滑动获得进行卷积运算,膨胀卷积每层的参数相互独立且数量相同,使用膨胀宽度分别为1,1,2的膨胀卷积核,迭代四次,通过IDCNN模型增加感受域,从而获得较远距离的字符间的语义关系,提取局部特征信息,来进一步丰富模型的特征信息。
1.3 条件随机场
因命名实体标签之间存在依赖关系,如“B-手术”标签后可能接“I-手术”或者“O”标签,不应该接“I-疾病和诊断”标签,而条件随机场(CRF)可以有效地约束标签之间的关系,因此使用CRF作为输出层得到全局最优解。
记句子序列作为输入变量X={x1, x2, x3,…, xn},预测标签作为输出变量y={y1, y2, y3,…, yn},且X,y均为线性序列,P( y|X )满足(1)式马尔科夫性时(i=1/n时只考虑单边),则称P( y|X )为线性链随机条件场。
P(yi|X, y1, y2,…, yn)=P(y|yi-1, yi+1) (1)
IDCNN层获得字符xi对应的标签向量后,标签向量yi作为发射分数传入CRF计算转移分数,其中转移分数表示一个标签向另一个标签转移的分数,转移分数越大则转移概率越大,预测一个序列y的概率表示为S(X,y)如式(2)所示,,yi+1表示从yi到yi+1的转移分数,Oi,yi表示xi被预测为yi的分数, 表示真实标签序列。
(2)
句子X的产生标签序列y的概率P( y|X )如式(3)所示,Y表示所有可能序列集合。
(3)
通过最大条件对数似然函数进行参数估计,预测中使用维特比算法获得最高分数标签序列y*作为最优路径,如式(4)所示:
(4)
2 实验数据及评价指标
2.1 实验数据集
数据集采用的是2019年全国知识图谱与语义大会(CCKS 2019)发布的数据,实体预定义类别包括疾病和诊断、解剖部位、药物、影像检查、实验检验、手术,其中训练集600份,验证集400,测试集379。数据集文本较长,据统计在Train、Dev、Test数据集中文本字符长度分别最高达到1 436、1 664、664,文本字符长度最短分别低至174、172、198,对应数据集中实体字符长度分别最高达到55、125、84。
使用BIO方式对电子病历文本进行标注,“B-”代表实体的开始位置字符,“I-”代表实体的其他位置字符,“O”代表非实体部分,共计13种标签,实体类别在Train,Dev,Test数据集中的实体个数统计如表1所示。
由表1可知,疾病和诊断、解剖部位、药物、影像检查、实验检验、手术在Train、Dev、Test数据分布较为平均。其中疾病和诊断、解剖部位实体多于药物、影像检查、实验检验、手术。解剖部位实体数量的最高共计11 520,手术最少共计1 191,其余从高到低依存是疾病和诊断共计5 535,药物共计2 307,实验室检验共计1 785,影像检查共计1 317,存在标签数量不平衡问题。
2.2 实验环境、参数设置以及评价标准
实验环境如下:操作系统为Ubuntu 18.04,CPU为Intel(R)Xeon(R) CPUE5-2678 v3@2.50 GHz,GPU为NVIDIA Tesla K80,显存12 GB,Python版本3.7,Pytorch版本1.8.1。
其中模型的參数值包括,学习率1.5e-5,迭代次数100,优化器Adam,文本最大长度设置为500,批大小为8。BERT选用12层的bert-base-chinese版本,隐藏维度为768,IDCNN层膨胀卷积核为3个,膨胀宽度依次为1,1,2,迭代4次,隐藏滤波器个数为64,使用RELU作为激活函数。
为了检测模型的性能,采用准确率P,召回率R和F1作为评价指标,具体公式为:
(5)
(6)
(7)
模型识别实体边界与标注的真实边界一致认定为识别成功,TP为正确识别医疗实体的个数;FP为识别到不相关医疗实体的个数;FN为未识别到相关医疗实体的个数;TP+FP为识别出的所有实体数量,TP+FN为实际标注实体总数。
2.3 实验结果与分析
实验一共有三组,模型BERT-FGM-IDCNN-CRF与BERT-CRF、BERT-IDCNN-CRF作对比模型。测试集上实验结果如表2所示。
(1)BERT-CRF模型。基于BERT模型的特征抽取,是NER任务中基于预训练任务的经典模型,训练时采用动态生成字向量。
(2)BERT-IDCNN-CRF模型。将BERT-CRF与IDCNN结合,BERT-CRF基础上更好的捕捉局部特征的能力,可以进一步提高实体识别能力。
(3)BERT-FGM-IDCNN-CRF模型。在BERT-IDCNN-CRF模型的基础上加入对抗网络,生成对抗样本,提高模型鲁棒性的情况下进一步提高实体识别能力。
根据表中的实验数据,相对于基线模型BERT-CRF,结合IDCNN的BERT-IDCNN-CRF与加入对抗网络FGM的BERT-FGM-IDCNN-CRF在数据集上的实体识别效果有不同程度上得提升,对比基线模型BERT-CRF、BERT-IDCNN-CRF的模型F1、P、R值提升了1.17%、1.61%、0.8%,证明加入IDCNN层有效的丰富文本特征,提高了模型的实体识别效果,证明加入对抗网络也可以有效提高模型识别的准确度。本模型对比基线模型BERT-CRF F1、P、R值提升了1.5%、1.25%、1.77%,对比BERT-IDCNN-CRF模型本模型虽然P值略有下降,但F1、R值提升了0.33%、0.97%。本模型的F1值和R值取得83.19%和84.74%成绩,充分证明本模型的有效性。
3 结 论
近年来基于深度中文命名实体识别的快速发展,给出加入对抗训练的BERT-FGM-IDCNN-CRF模型,该模型将BERT后加入IDCNN层,对比普通的BERT-CRF,有效捕捉局部特征,通过增加对抗网络在提高模型鲁棒性的基础上进一步提高了模型的识别效果。基于对抗网络的BERT-FGM-IDCNN-CRF医疗文本的命名实体效果有所提升,但是中文电子病历的命名实体识别任务,仍有较大改善空间。由于电子病历为长文本且实体长度较大,模型对于长文本的识别的理解较为困难,效果普遍低于短文本,加入IDCNN丰富文本特征的同时训练时间相较于基线模型的训练时间也会随之增加,加入对抗网络增加扰动信息使得模型训练时间进一步加长,未来将考虑来进一步研究在保证医疗领域的实体识别效率的同时更高效的模型。
参考文献:
[1] WU F Z,LIU J X,WU C H,et al.Neural Chinese Named Entity Recognition via CNN-LSTM-CRF and Joint Training with Word Segmentation [J].The World Wide Web Conference,2019:3342-3348.
[2] 陈茹,卢先领.融合空洞卷积神经网络与层次注意力机制的中文命名实体识别 [J].中文信息学报,2020,34(8):70-77.
[3] 赵萍,窦全胜,唐焕玲,等.融合词信息嵌入的注意力自适应命名实体识别 [J/OL].计算机工程与应用,2022:1-9[2022-08-13].http://kns.cnki.net/kcms/detail/11.2127.tp.20220524.1001.005.html.
[4] 谭岩杰,陈玮,尹钟.门控空洞卷积与级联网络中文命名实体识别 [J/OL].小型微型计算机系统,2022:1-10[2022-08-13].http://kns.cnki.net/kcms/detail/21.1106.tp.20220418.1445.032.html.
[5] 杨红梅,李琳,杨日东,等.基于双向LSTM神经网络电子病历命名实体的识别模型 [J].中国组织工程研究,2018,22(20):3237-3242.
[6] 巩敦卫,张永凯,郭一楠,等.融合多特征嵌入与注意力机制的中文电子病历命名实体识别 [J].工程科学学报,2021,43(9):1190-1196.
[7] 梁文桐,朱艳辉,詹飞,等.基于BERT的医疗电子病历命名实体识别 [J].湖南工业大学学报,2020,34(4):54-62.
[8] 孔令巍,朱艳辉,张旭,等.基于对抗训练的中文电子病历命名实体识别 [J].湖南工业大学学报,2022,36(3):36-43.
[9] JAWAHAR G,SAGOT B,SEDDAH D.What Does BERT Learn about the Structure of Language [C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics.Florence:ACL,2019:3651-3657.
[10] MIYATO T,DAI A M,GOODFELLOW I.Adversarial Training Methods for Semi-Supervised Text Classification [J/OL].arXiv:1605.07725 [stat.ML].[2022-08-09].https://arxiv.org/abs/1605.07725.
[11] MADRY A,MAKELOV A,SCHMIDT L,et al.Towards Deep Learning Models Resistant to Adversarial Attacks [J/OL].arXiv:1706.06083 [stat.ML].[2022-08-11].https://arxiv.org/abs/1706.06083.
[12] STRUBELL E,VERGA P,BELANGER D,et al.Fast and Accurate Entity Recognition with Iterated Dilated Convolutions [J/OL].arXiv:1702.02098 [cs.CL].[2022-08-16].https://arxiv.org/abs/1702.02098v3.
作者簡介:李曼玉(1997—),女,汉族,安徽蚌埠人,硕士研究生在读,研究方向:自然语言处理;通讯作者:于瓅(1973—),女,汉族,安徽宿州人,教授,博士,研究方向:区块链、图像处理。
收稿日期:2022-09-01
基金项目:2021安徽省重点研究与开发计划项目(202104d07020010)
