“一带一路”国家涉税数据分析架构技术研究与应用
2023-06-22王明贾希强邵徽钦
王明 贾希强 邵徽钦
摘 要:“一带一路”国家在税务信息化的发展过程中,产生了海量的涉税数据,如何从海量数据中分析挖掘纳税主体的风险行为,为税务决策制定提供量化支撑,是“一带一路”国家税务信息化未来研究的重要方向。文章结合目标国家税务信息化建设的需求和数据特征,基于大数据存算分离架构,采用Flink实时计算与离线计算相结合的方法构建多种数据分析模型,实现了以企业发票数据分析为着手点,以企业风险识别为目标的分析预警系统。
关键词:一带一路;涉税数据;Flink;实时计算
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2023)03-0041-04
Research and Application of “The Belt and Road Initiative” National Tax-related Data Analysis Architecture Technology
WANG Ming, JIA Xiqiang, SHAO Huiqin
(Aisino Corporation, Beijing 100195, China)
Abstract: During the development of tax informatization of the “the Belt and Road Initiative” countries, a large amount of tax-related data has been generated. How to analyze and mine the risk behaviors of taxpayers from the huge amount of data and provide quantitative support for tax decision-making is an important direction for the future research of tax informatization of “the Belt and Road Initiative” countries. This paper combines the needs and data characteristics of the target country's tax informatization construction, based on the big data storage and calculation separation architecture, uses the method of combining Flink real-time calculation and offline calculation to build a variety of data analysis models, and realizes the analysis and early warning system with the enterprise invoice data analysis as the starting point and the enterprise risk identification as the goal.
Keywords: the Belt and Road Initiative; tax-related data; Flink; real-time calculation
0 引 言
我国税收征管经历了“经验管税”和“以票管税”两个时期,现如今逐渐进入“以数治税”阶段[1,2],而“一带一路”沿线国家(地区)在经济发展水平、税务管理能力等方面均存在较大差异[3],异常纳税及异常开票等问题在各个国家普遍存在。随着信息化技术的发展,如何应用大数据技术构建数据分析架构,有效识别企业纳税行为风险,促进税务部门征管能力和纳税服务水平,帮助建立并完善区域法治环境[4],是“一带一路”沿线国家税务信息化建设面临的主要问题。
税务数据处理的难点在于,首先税务数据的数据量非常大,以我方税务系统投入运营的某中等国家为例,税务信息化系统上线运营仅两年,月开发票数量已超千万级。其次,数据结构较为复杂,主要体现在数据来源多样、数据结构行业特征化突出,因此存在大量同源异构、异源异构数据。采用传统分析方式直接对原始数据进行处理,效率极低,资源占用严重。
为解决上述问题,文章提出的分析架构,采用大数据存算分离技术、实时计算与离线计算相结合的方式,解决了传统应用架构数据统计时重复计算和资源无效等待等弊端,提高了数据分析的时效性和资源利用效率。税务数据分析预警平台的构建,遵循国内“以票控税、大数据管税”的原则,通过对目标国家纳税主体涉税数据的有效分析和行为预警检测,为税务机关制定决策提供了可量化的数据支撑。
1 总体架构与功能设计
1.1 总体架构
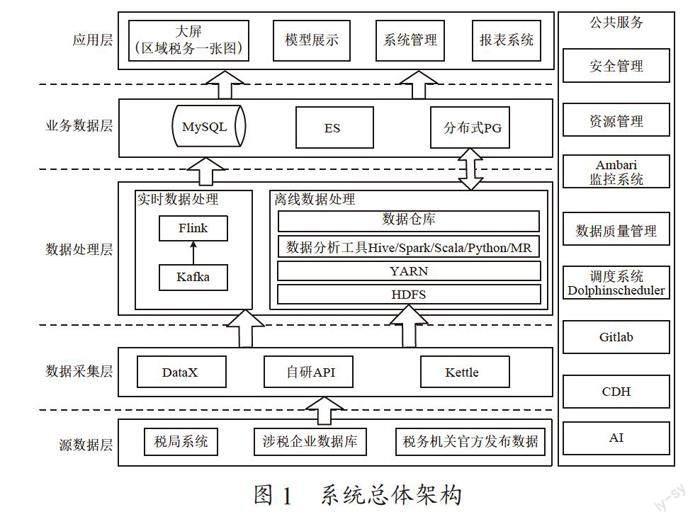
系统总体架构如图1所示。
平台的结构包括源数据层、数据采集层、数据处理层、业务数据层、应用层。总体的构建使用了大数据集群存算分离模式,利用Spark计算引擎进行海量数据的计算和分析,避免了大量计算对系统资源的占用影响上层业务的问题。对于实时需求的业务,采用实时计算与离线计算相结合的方式,保证平台统计分析结果的及时性和可靠性。另外,通过使用可视化调度工具和实时监控工具,确保了平台系统的资源规划和运行状况更加清晰和易维护。其特点主要体现在:
(1)在数据处理层中,采用Kafka與Flink技术相结合的方式实现在线数据实时处理和传输功能。其中,Kafka是Apache软件基金会的一个开源流处理平台,主要由Scala和Java编写,是Hadoop生态系统中的一个重要工具[5]。与传统的消息系统相比Kafka消息队列有着流量削峰、缓冲、系统解耦、异步通信、可恢复性和可扩展性等特点,并且还具有其他消息中间件难以实现的消息顺序性保障和回溯消费等功能。而Apache Flink也是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式数据流引擎,可用于对无界和有界数据流进行有状态计算[6]。它主要包括三个重要特点:事件驱动型、流与批的世界观、分层API。由于Flink能在单独集群中运行、适用于具有不可靠数据源、海量数据处理等场景中的三项重要特点[7],非常契合欠发达地区涉税数据的处理,因此系统选用Flink结合Kafka消息队列为不同类型的数据实时计算和传输提供支撑。
(2)在数据调度环节,有很多成熟的开源工具可以用于解决数据抽取、转换、加载等流程中错综复杂的依赖关系,能使调度系统在数据处理流程中开箱即用[8],如Azkaban、Oozie、DolphinScheduler、Quartz、air-flow、XXL-Job等。文章选用的Apache DolphinScheduler大数据工作流任务调度平台,其去中心化的多Master和多Worker服务对等架构,能够有效地避免单Master压力过大问题,在执行时利用任务缓冲队列来避免过载机制,也提供了高可靠性。它所提供的DAG监控界面所有流程定义都可视化,通过拖拽任务即可完成定制DAG,通过API方式与第三方系统集成,支持一键部署简单易用。目前能够支持Spark、Hive、M/R、Python、Shell等近20种任务类型,紧密贴合大数据生态。另外,其调度器使用分布式调度,调度能力随集群线性增长,依靠Master和Worker支持动态上下线的能力,保证了可扩展性。
1.2 系统功能
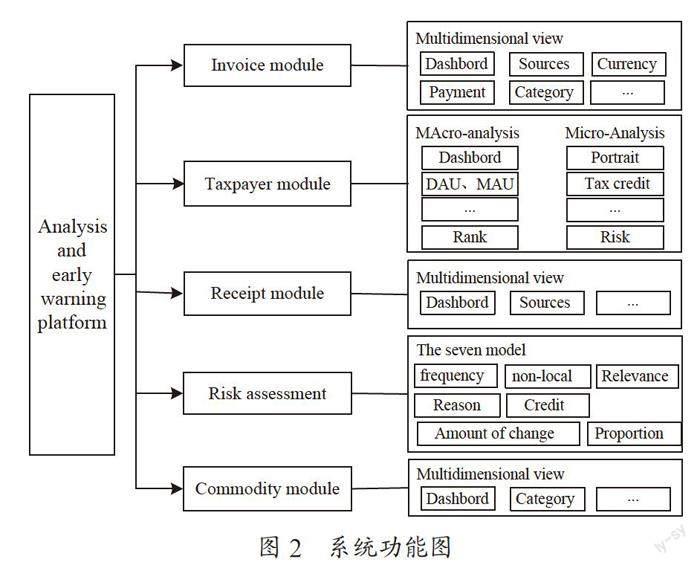
系统功能如图2所示。
系统主要包括五大功能:
Invoice分析:主要实现发票数据的汇总、统计、分析和展示,子项功能均围绕invoice数据进行。
Taxpayer分析:该功能项为纳税主体画像,主要用于对重点关注纳税主体和模型锁定的潜在风险纳税主体进行全面的信息展示。
Receipt分析:主要是纳税主体非税凭证票据的统计分析展示,用以揭示纳税主体的纳税潜力,在一定程度上提供了非税业务可转化纳税业务的一种量化,也可认为是潜在可转化纳税主体情况的展示。
Risk Assessment:系统核心研判功能,在应用标准存算分离技术的情况下,基于各项数据的分析和挖掘,结合税务数据特征维度筛选,构建了七种风险识别模型,通过机器学习综合研判纳税主体是否存有风险,并能够根据政策的改变进行策略调整和学习进化。
Commodity分析:该项功能主要从区域的支柱型产业/商品分析角度出发,对企业交易行为,上下游关系进行深度挖掘和分析,以主营商品的角度去展示企业涉税行为。
2 关键技术应用及效果
2.1 存算分离架构
系统架构选用Kafka消息队列用于传输涉税数据,为数据分析模型提供数据支撑。因其与Flink、Spark等大数据组件能够无缝集成,易于构建数据流的传输通道[9]。同时Kafka通过Hadoop的并行加载机制可以统一线上和离线的消息处理。通过Kafka消息队列的传输能够将原始数据安全可靠的同步到大数据集群中存储和管理,再以消息通知的形式,对已存储的原始数据定期分析和计算,并将计算结果存储至业务数据库(MySQL)中备用。保证上层应用系统可以随时读取业务数据进行展示,有效保证海量税务数据的查询时效性,同时极大地减轻了系统实时运算压力。
采用存算分离架构的好处还在于,在应对由于政策变化、规则更改等因素导致的数据统计方式修改和计算模型更新的情况时,只需要将分析计算的脚本进行更新即可,不会出现传统架构更新时影响系统功能的情况。
2.2 Flink实时计算
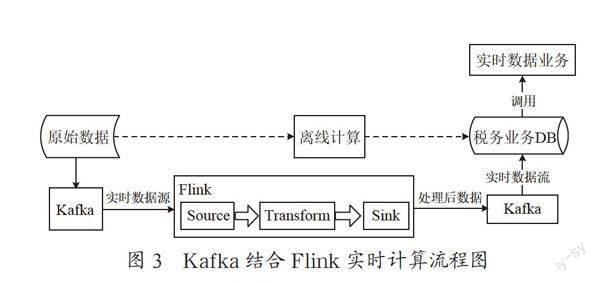
对于实时数据的分析展示,系统采用实时计算与离线计算相结合的实现方式。
如图3所示,对已存储的原始数据,使用大数据集群中离线计算的结果,而数据的实时增量部分采用Kafka消息队列方式进行增量采集,并通过Flink并行实时计算后将计算结果与历史结果信息融合,进而得到符合需求的展示信息。这一处理架构有效地避免了对同一数据的重复计算,减少了计算资源的浪费,同时也保证了功能数据的完整性和准确性。
2.3 分布式任务调度系统
系统应用DolphinScheduler分布式调度平台技术,分别对数据的采集、清洗、运算脚本进行了独立编写、调度和执行,通过定期对海量涉税数据进行包含全量数据计算、增量数据累加计算、机器学习算法模型运算等的分析方式进行数据处理运算。在以上涉税数据特征分析的基础上,构建了企业多维风险识别模型并分别建立独立的Spark计算任务,实现企业税务业务的风险识别。系统中使用的DolphinScheduler核心架构如图4所示。
2.4 应用效果
涉税数据风险预警平台是结合“一带一路”沿线国家对涉税领域管控的需求,借鉴吸收中国先进税收体系理念而提出的综合企业风险管控系统。通过对涉税数据以及相关税法的深入解读,系统从数据的多个维度出发构建了七种算法模型,实现了综合识别和判断纳税主体风险的目的。样本数据分析效果如图5所示,该项功能是构建算法模型中以纳税主体开具发票的时间为主维度的分析执行情况。
依托DolphinScheduler分布式调度平台,模型全部部署为独立调度任务,根据不同模型的具体算法要求,能够分别设定各自的运行周期和算法边界条件。
在实际应用中,目标数据经过系统分析处理后,呈现出如下特征:纳税主体分布情况不均匀,大部分纳税主体归属于少部分税务机关,总体呈泊松分布;纳税主体开票数量和开票金额,与原始数据的分布情况保持一致,呈现18%的企业开具了占比83.23%的发票数据,另23%的企业开了占比16.27%的少量发票,剩余大量的企业仅采集到很少的数据甚至无法采集到有效开票数据。这一特征非常符合项目所在地的税务信息化水平较低,纳税遵从度主要集中在较发达的大城市和大型企业中的现实情况。
3 结 论
经实际数据验证,该系统架构在税务体系仍不完善的地区,能够有效地解决因税制税法变更导致的数据结构频繁修改和来源多变等问题,给目标地区税务信息化的推进和涉税决策提供了量化数据支撑。另外,在进行不同国家的涉税数据的分析过程中,通过对文档、代码复用率(包括UI、算法等)的实证分析,该架构体系对其中跨平台、多类型、多渠道的异构数据的采集、分析和融合处理复用率达到78%。最后,在应对大多数统计方式和计算规则变更时不需要整个系统的重新部署,仅需将独立运行的脚本任务单独更新即可。因此,该架构能够有效地节省项目资源投入,减少海量数据重复处理的资源消耗,在实际效益上具有很高的现实应用价值。
目前此架构经过了两个不同国家样本数据的验证,但对更多涉税数据的有效性仍需进一步观察和研究。因此未来应更加深入的理解“一带一路”国家税法税制用以改进技术架构,同时也需进一步研究整套架构的限制条件和应用边界。
参考文献:
[1] 谢佳音.“以数治税”背景下涉税信息共享机制的转型构建 [J].财会研究,2022(3):15-20.
[2] 王一帆,刘紫斌.“以数治税”背景下税收征管现代化的若干问题研究 [J].财政监督,2022(7):75-81.
[3] 张翠芬,李旭红,许思远.数字化税务管理在“一带一路”沿线国家和地區的应用研究 [J].国际税收,2022(1):74-79.
[4] 漆彤.“一带一路”战略的国际税法思考 [J].税务研究,2015(6):31-35.
[5] 王勇,张跃.Kafka与HBase在健康监测大数据平台中的应用研究 [J].软件导刊,2021,20(4):188-193.
[6] 姜来.基于Flink平台的成都市网约车数据时空分析及系统开发 [D].大连:辽宁师范大学,2021.
[7] 赵润发,娄渊胜,叶枫,等.基于Flink的工业大数据平台研究与应用 [J].计算机工程与设计,2022,43(3):886-894.
[8] 张新兴,杨志刚,庞弘燊,等.科学数据集成体系及最新进展研究 [J].情报理论与实践,2022,45(6):199-206.
[9] 车思阳.基于Kafka的大容量实时预警数据汇集分发技术研究 [D].成都:电子科技大学,2021.
作者简介:王明(1985—),男,满族,河北秦皇岛人,高级工程师,本科,研究方向:税务信息化。
收稿日期:2022-09-26
