基于改进MC-Bert 的ICD 编码映射方法研究
2023-06-21周浩然郑建立
周浩然, 郑建立
(上海理工大学健康科学与工程学院, 上海 200093)
0 引 言
疾病和相关健康问题的国际统计分类(International Statistical Classification of Diseases and Related Health Problems,ICD)由世界卫生组织创立,用来确定全球卫生趋势和统计数据的一种医疗编码体系国际标准。 该体系由表1 所示的医学编码及对应医学名称组成最小描述单元,涉及到手术、疾病、诊断等医疗环节,对生物医学领域如医学知识实体对齐、医疗标准化、临床路径等研究起着重要作用,同时也作用于医保结算、医疗监督等领域。

表1 ICD 编码示例Tab. 1 Examples of ICD code
当前,国内医疗体系中存在着多种本地化的ICD 编码版本,且大部分基于ICD-9 和ICD-10。 虽然部分机构发布了某版本与另一版本的映射,但不论是从映射版本的数量以及更新速度都不尽如人意。 除此以外,各个医疗机构还存在各自定义的院内码,这更对医疗数据的一致性提出了挑战。
目前,医学编码相关的研究大多集中在病案的命名实体识别和编码领域,如夏等[1]基于深度学习技术实现电子病历的实体识别;厐等[2]基于文本相似度实现了康复量表与 ICF ( International Classification of Functioning,Disability and Health)编码的映射。 此外,专业医生也就各自专业领域ICD编码的合理性进行了讨论,如叶[3]等对ICD-10 在眼挫伤的分类编码讨论;许等[4]对ICD-10 编码在癫痫方面的质量分析。
实现ICD 映射的方式往往需要大量的人工分级、字典映射等传统方式,而基于语义相似度的方法较少。 随着蕴含大量生物医学领域先验知识的预训练模型MC-Bert(Meta-Controller BERT)的出现,中文医学文本可以转化为更加稠密和准确的向量表示,在此基础上本文提出一种基于改进MC-Bert 的ICD 编码映射方法,该方法通过语义相似度在现有的ICD 版本映射库中进行匹配实验,在不同匹配精度下的准确率均达到较高水平。似度,依次进行排序获得Top5,输出用于验证。
1 改进的MC-Bert 模型
改进的MC-Bert 是一种利用白化处理优化MCBert 编码输出的无监督学习模型,其结构图如图1 所示。
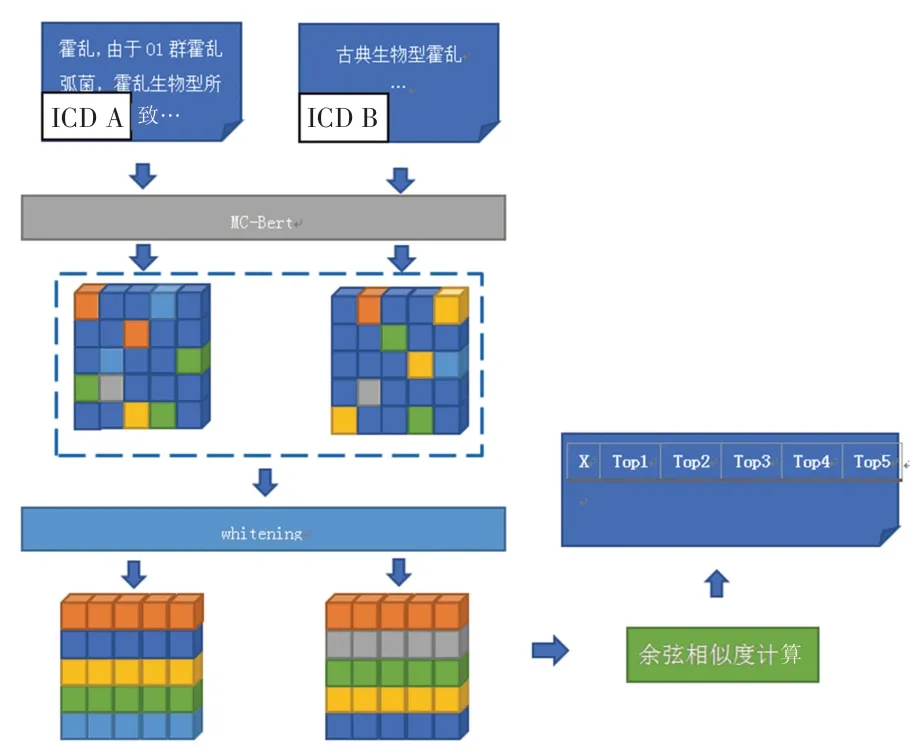
图1 改进的MC-Bert 模型结构图Fig. 1 Model structure diagram of improved MC-Bert
首先,由于ICD 中的名称部分既有较短小的词语如霍乱,也有较长的句子如“遗传性肾病伴有轻微的肾小球异常,不可归类在他处者”,本文将其统一填充为相同长度的句子,输入MC-Bert 进行编码;其次,将两个文档中编码名称的输出矩阵拼接,作为白化处理的输入,计算获得消除各向异性后的句向量;最后,将两文档的句向量两两计算余弦相
1.1 预训练语言模型MC-Bert
MC-Bert 由Zhang 等[5]提出,训练过程如图2所示。 以BERT 作为基础模型,使用大量生物医学领域语料进行训练,包含许多生物医学领域先验知识。 虽然预训练语言模型在各项语言任务中性能均有大幅的提升,但Gao 等[6]发现,其在词向量方面仍存在各向异性,导致模型出现语义表达的退化问题。
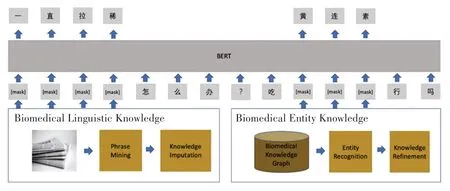
图2 MC-Bert 的训练过程Fig. 2 The training process of MC-Bert
1.2 白化处理
白化处理是一种预处理方法,由Su 等[7]首先引入以解决预训练模型语义表达的退化问题,其具体操作是将文档中N条句子经过预训练模型的编码层输出为向量集合{xi}N i=1,然后将此集合经过如式(1)的线性变换,转变为均值为0 且协方差矩阵为单位矩阵的向量集合。
其中,μ代表平移系数,ω代表缩放系数。
为了实现x~i的均值为0,则μ需要满足式(2):
而{xi}Ni=1的协方差矩阵Σ满足式(3):
转换后的协方差矩阵与Σ的关系为式(4):
由于为单位矩阵,则式(4)等价于式(5):
由此可得到Σ满足式(6):
由于协方差矩阵是正定对称矩阵,因此Σ满足式(7)所示的奇异值分解:
其中,U是ΣΣT的特征向量矩阵,Λ为对角矩阵
由式(6)、式(7)联立,可以得到式(8):
最终可得到ω满足式(9):
1.3 余弦相似度
余弦相似度是一种常用的计算文本相似度的方法,计算公式(10):
其中,x,y代表两条句向量;d代表句向量的长度;xi,yi代表x,y在下标为i处的值。
余弦相似度的值越接近1,两个句子的相似度越高。
2 实验方法和评价指标
2.1 实验数据
本文采用ICD-10 国标2020 版和医保版2.0 对照库以及ICD-9 团标2020 版和医保版2.0 对照库作为实验数据,其实例见表2。

表2 实验数据示例Tab. 2 Examples of experimental data
2.2 实验环境及评价指标
改进的MC -Bert 通过python 3. 9. 7,基于PyTorch 框架实现;硬件环境为Intel Core i7-11700,显卡为RTX 3060,显存12 G,操作系统为window 10。 运用Top-K 准确率(Accuracy)评估方法性能,计算如公式(11)所示:
其中,nk是前k个候选项中包含正确项的个数,N是映射条目的总数。
2.3 实验设计
本文涉及到使用不同版本的ICD 名称进行相似度计算,但不同版本的ICD 之间可能存在大量重复的医学名称,会干扰不同医学名称间的相似度匹配结果,因此设计实验(1);ICD 编码数据蕴含丰富的医学知识,注入这类数据或可提高模型匹配的准确率,因此设计实验(2);为了验证改进MC-Bert 与其他模型在匹配准确率上确有提升,因此设计实验(3)。
(1)重名项对非重名项匹配的干扰评估实验:从ICD-10 国标2020 版中筛选出与医保2.0 版医学名称不重复的1 773 条数据,分别与去除重名项的、包含重名项的医保2.0 版数据进行匹配实验。
(2)医学编码注入与否的对比实验:编码部分包含类目、亚目、细目、附加码,分别代表不同范围的医学知识范畴。 ICD-9 团标版中筛选出非重名项1 289 条,医保2.0 版中非重名项1 255 条,分为编码不注入、整条编码注入、拆分三类编码分别注入3 种数据进行对比实验,3 种实验数据示例见表3。

表3 三组实验数据示例Tab. 3 Three sets of experimental data examples
(3)改进MC-Bert 与其他模型的对比实验:在数据去重和拆分三类编码注入后,在ICD-10 国标2020 版和医保2.0 版对照库以及ICD-9 团标版和医保2.0 版对照库中,就改进MC-Bert 和TF-IDF(Term Frequency-Inverse Document Frequency)、LSI(Latent Semantic Indexing)、MC-Bert、VSM(Vector Space Model)模型的表现进行对比。
3 结果分析和总结
3.1 重名项对非重名项的扰动评估实验
ICD-10 国标2020 版与医保2.0 版重名项对非重名项匹配的干扰结果见表4。 由此实验证明,重名项对非重名项匹配的干扰影响较大,因此需要将不同版本ICD 中的重名项和非重名分开匹配。 同时,也验证了改进MC-Bert 在非重名项之间依旧保有较高的准确率。
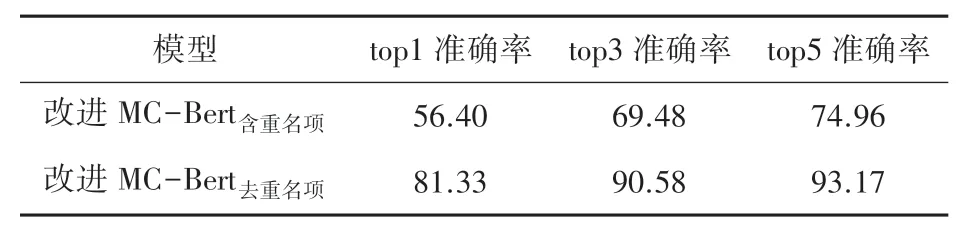
表4 重名项对非重名项匹配的干扰结果Tab. 4 The experimental results of the perturbation evaluation of the duplicated items to the non-duplicated items%
3.2 医学编码注入与否的对比实验
CD-9 团标版中非重名项1 289 条,医保2.0 版中非重名项1 255 条分别对文本中的英文、符号进行预处理后,分为编码不注入、整条编码注入、拆分三类编码注入的性能对比实验结果见表5。 由此实验证明,拆分编码为类目、亚目、细目三级注入医学名称中可显著提升准确率,因而结合医学名称与三级编码是最为合理的语义匹配方案。
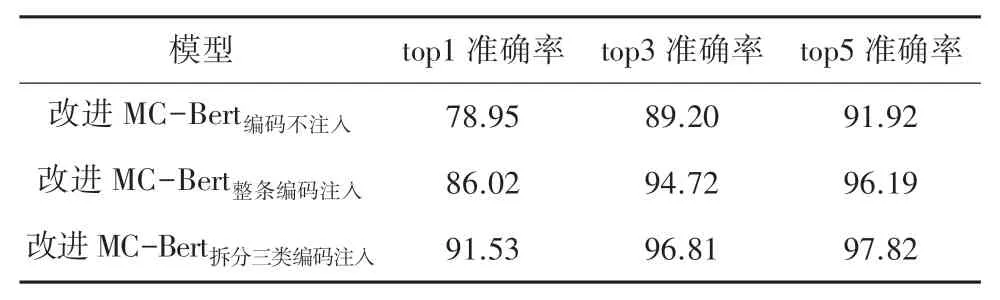
表5 三种实验数据的性能对比结果Tab. 5 Comparison of experimental results of three groups of experimental data%
3.3 改进MC-Bert 与其他模型的对比实验
通过将ICD-9 团标版中非重名的1 289 条向量进行t-SNE 降维,对降维后的向量进行可视化,得到如图3 所示的向量分布对比图,可见改进MCBert 相较MC-Bert 能够有效的将重叠的向量分散开来,拥有更好的语义表达能力,提升语义相似度检索的敏感度。
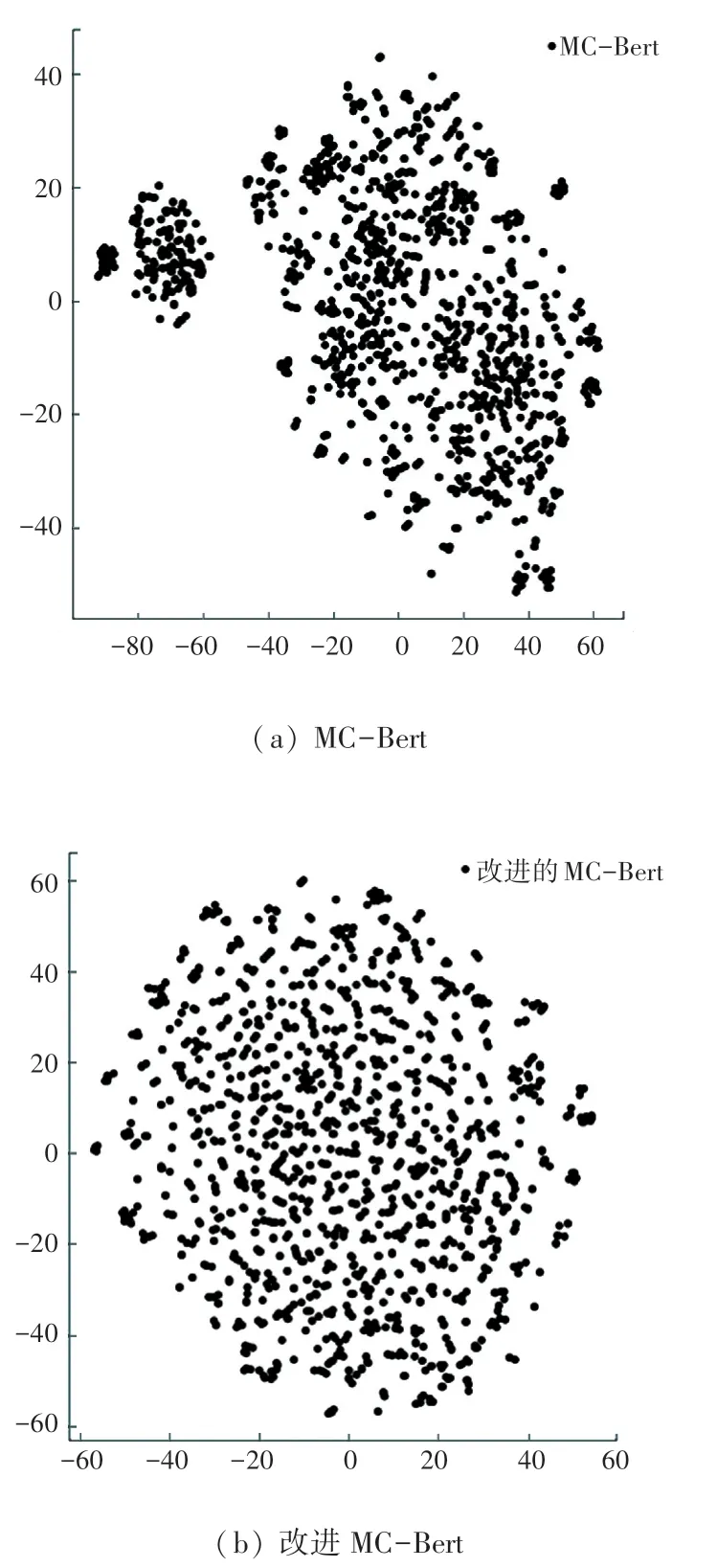
图3 向量分布对比图Fig. 3 Comparison of vector distributions
同时本文也对加进MC-Bert 与其他模型在ICD-10 国标2020 版和医保版2.0 对照库以及ICD-9团标2020 版和医保版2.0 对照库上非重名项的准确率进行比较,结果见表6、表7。
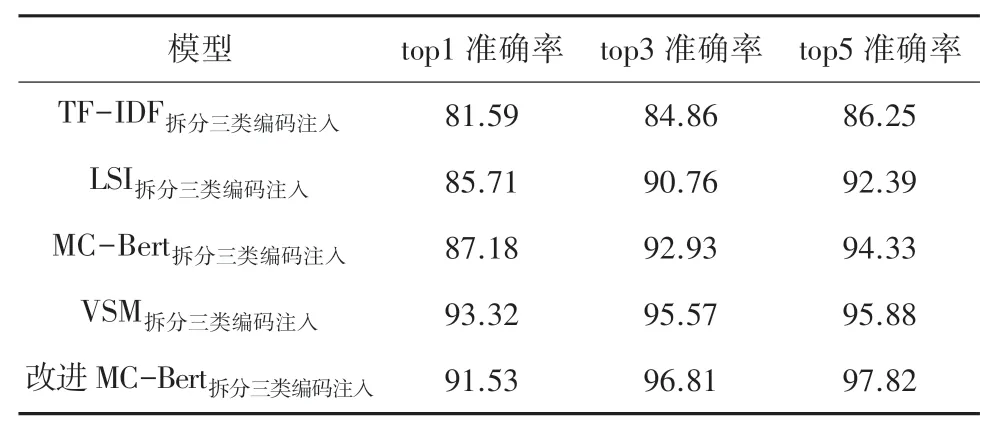
表6 ICD-9 团标2020 版和医保版2.0 映射的对比实验结果Tab. 6 Comparison experiments of ICD-9 group standard 2020 version and medical insurance version 2.0 mapping%
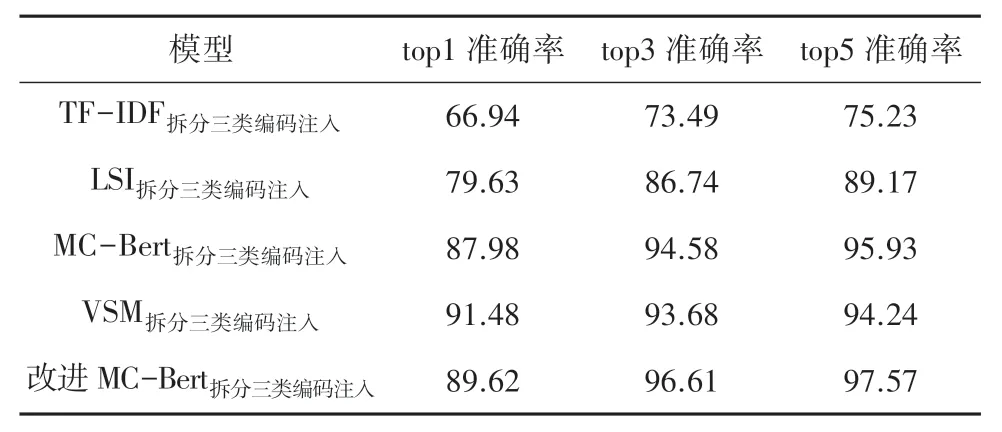
表7 ICD-10 国标2020 版和医保版2.0 映射的对比实验结果Tab. 7 Comparison experiments of ICD-10 national standard 2020 version and medical insurance version 2.0 mapping%
可以看到改进后的MC-Bert 模型与其他模型相比,除了在top1 匹配精度下的准确率方面低于VSM 模型外,其他匹配精度下的准确率较其他模型有较大提升。
4 结束语
本文提出来一种基于改进MC-Bert 的ICD 编码映射方法,通过实验证明了该方法相较其他模型在准确率方面有较大的提升,为医学编码领域的智能化映射提供了一种思路。
