基于局域社交网络的舆情溯源算法研究
2023-06-21张欣王丽娟沐雅琪
张欣 王丽娟 沐雅琪

摘 要:随着互联网技术的日益普及,加快了信息在网络中传播速度及影响。信息体量增加的同时,许多虚假舆情信息也应运而生,舆情信息的广泛传播会对国家、社会以及个人利益造成难以控制的负面影响。因此,需采用技术手段对网络中的舆情信息进行溯源研究,从而保证网络安全。文章提出了一种舆情溯源算法,并通过实验结果表明:该算法具有准确率较高、错误距离较小的优点,适合在局域社交网络中应用,对网络安全具有重要现实意义。
关键词:社交网络;信息溯源;传播中心性;网络安全
中图分类号:TP312 文献标识码:A 文章编号:2096-4706(2023)09-0177-04
Abstract: With the increasing popularity of Internet technology, the speed and influence of information dissemination in the network have been accelerated. With the increase of information volume, much false public opinion information also emerges as the times require. The wide spread of public opinion information will cause uncontrollable negative impact on the interests of the country, society and individuals. Therefore, it is necessary to use technical means to trace the source of public opinion information in the network to ensure network security. This paper proposes a public opinion traceability algorithm, and the experimental results show that the algorithm has the advantages of high accuracy and small error distance, which is suitable for application in local social network and has important practical significance for network security.
Keywords: social network; information tracing; communication centrality; network security
0 引 言
随着互联网的日益普及与飞速发展,人们的生活也发生了巨大变化,越来越方便的在线交流功能极大地降低了人们生活的时间成本与社交成本,导致人们对于社交网络的依赖性逐渐增加[1]。社交网络最初只是获取信息与资源的平台,现已成为生活和情感的延续。因此,许多网民在运用社交网络的时候,已经不仅仅是单纯地通过社交网络获取信息与资源,而是会更加主动地去创造并传播信息。与此同时,随着网络中信息传播量的增多,有些为了达到某个负面影响的虚假舆情信息也随之出现,但由于社交网络的发展及使用速度过快,用户发布信息的门槛较低,编辑和传播的方式也越来越简单,加之民众对于网络的依赖性愈加严重,致使监管人员无法及时地对社交网络中全部的信息进行有效监管,因此社交网络也变成了网络舆情信息滋生的温床。如果任由一则虚假的舆情信息在网络中肆意传播且不加以控制,将会造成民众的恐慌并引发后续的公共信任危机事件,造成恶劣的社会影响[2,3]。
社交网络中传播的信息可以分为正面导向信息和负面导向信息[2]。特别是未经验证的负面导向信息,在经过刻意的夸大修饰后,更能激发人们的兴趣,并且总是能伴随一定规模、一定热度的传播。例如,在2022年广为流传的“腾讯云数据库泄露”“死亡的鸟类可以传播猴痘病毒”“0蔗糖就是无糖”等虚假舆情信息,这些舆情信息在人群中进行快速传播,造成了混乱影响。尽管后期有关部门及相关机构对上述舆情信息进行辟谣处理,但仍然对网络造成了不良影响,如不及时控制,甚至会影响社会公序良俗和经济的发展。
在现实世界中,当一个用户接收到一则虚假的舆情信息,该用户可以选择相信或者不相信。如果该用户不相信会直接丢弃这条信息,但如果该用户相信了这条信息,那么就有一定概率会向该用户的亲朋好友继续传播,因此社交网络中的传播方向具有多向性和随机性的特征[4]。我们可将每个人所处的社交网络提取成为规模较小的局域社交网络,用户抽象成为局域社交网络中的节点,某个用户的亲朋好友即为局域社交网络中的邻居节点,从而得到以每个用户本身作为根节点扩展得到的局域社交网络结构。针对一条舆情信息,我们假设一个节点有“相信”“不相信”两个状态,并且在节点之间无指定的传播方向,即舆情信息是在无向网络中进行传播,并采用SI模型来模拟舆情信息的扩散,以此来验证舆情溯源算法的有效性。
1 基于局域网络中的信息溯源方法研究
1.1 构建局域网络
生物代谢网、食物链(网)等,都是自古时候起已经存在的网络。对人类社会而言,只要是有人群的时间与空间,就会有网络。进一步地,随着人与人之间的沟通、互动、往来等,引发了众多学者对于社交网络的深入研究。
伴随着互联网和计算机技术的发展,使得网络中产生的现象具有可计算性,因此众多学者聚焦于人群的行为与网络之间互動的可预测性。为了更好地探究社交网络领域,结合图论的相关内容来进行分析研究。
图是事物与联系的集合体。图可以用于表现网络中各种事物的关系,是网络结构信息的抽象体现。在现实世界中,人与人之间存在社交关系,所以采用图论的观点进行分析,可以将用户和用户之间的关系用图来表示。
首先,具有共同兴趣爱好,或共处于某一局域网络的用户,可以将其抽象为一个局域社交网络。其次,在这个局域社交网络中,用户可以抽象为不同的节点,用户之间存在互动关系即代表着两个节点之间存在连边关系。当有一则舆情信息在局域社交网络中进行传播,使用溯源算法可以快速定位到源节点,将舆论信息对于网络的负面影响最小化。因此,在进行溯源计算时,需要根据局域社交网络的结构与受感染节点集合构建出感染网络。在感染网络中运用溯源算法,快速准确定位源节点[5]。
在局域社交网络中,每条边将两个节点连接起来,可以用式(1)进行表示:
式中,E代表的是网络中的连边集合,V代表的是网络中的节点集合,i,j分别代表网络中的不同节点。由式(1)得到的局域社交网络连边关系可以构成邻接矩阵,从而进行计算。
将局域社交网络结构转换为邻接矩阵可以表示为式(2)。在式(2)中,若a12=1代表在网络环境中节点1和节点2存在连边关系,那么映射到现实世界则代表着两个用户之间存在联系,可能互为好友、同学等。
1.2 传播路径分析
以经典的传染病传播模型—SI模型为例,S代表易感者,是容易被疾病感染的用户;I代表感染者,指的是已经被感染的用户,并且处于I态的患者还存在一定概率去感染其他处于S态的用户。在信息传播领域,通常采用传染病模型来类比信息传播过程[6]。在一个局域的社交网络中,对于一则信息,节点会处于“相信”和“不相信”两种状态的其中之一,“相信”即为该节点已经被感染,对应SI模型中的I态;“不相信”即代表着这个节点未被感染,处于易感态,对应SI模型中的S态。当有一则舆论信息在局域社交网络传播后,处于感染态的节点会向自己周边的节点进行传播感染,在经过一定的时间步长后形成局域感染网络。因此最初时刻处于感染态的节点是感染网络的核心节点,感染网络中其他节点都是被这一节点感染所导致的,所以这一核心节点在网络中的节点重要性程度要高于其他感染节点。由于信息传播在网络中存在随机性的特征,因此以一个包含10个节点的原生网络为例,来模拟传播的过程,如图1所示。
图1(a)代表的是某一时刻的原生网络,其中2号节点代表该节点处于感染态,其他节点但处于易感态。当舆情信息开始由2号节点传播后,第一个感染轮次t1内,首先感染了6、8、10号节点;第二个轮次t2在t1轮次已经感染的节点的基础上,继续感染了1、4号节点;第三个轮次t3在上述两个感染轮次之后,继续感染了7号节点。因此图1(a)所示的网络在经过了三个感染轮次之后,依次感染了网络中6、10、1、8、4、7号节点,最终得到结果为图1(b)的感染网络。根据SI传播模型的特点,在图1所示的网络中,如果一个节点被感染,那么该节点将一直处于感染态,不会被再次感染。
由图1可知在局域社交网络中信息传播的过程,为了简述舆情算法计算流程,可列出舆情溯源步骤如下所述:
1)初始化处理阶段:获取数据集,对数据进行预处理,构建局域社交网络G。此时网络G即为原生网络,所有节点都处于易感染状态,存在一定概率被感染。
2)信息传播阶段:在一定的传播轮次之内,构建被感染节点的集合。如果节点被感染,则加入感染节点集合SI中。当信息传播停止后,根据感染节点集合与邻接矩阵,得到所有的受感染节点与感染子图GI。
3)计算阶段:根据感染子图GI中的结果,采用溯源算法进行计算,得到最终信息溯源结果。
1.3 溯源算法建立
舆情溯源算法(KRC)的计算思想如下:根据原生网络G中诱导出的感染子图GI,在GI的基础上构建以节点v为根节点的广度优先搜索树Tbfs(v),之后进行溯源运算。KRC算法计算流程如图2所示。
图2的计算流程实现了基于SI信息传播模型的溯源算法,通过溯源计算可以快速定位到舆情传播的源节点,进一步地可以对网络中的源节点进行处理,净化用户上网环境,为网络中的信息安全提供了有力保障。
2 实验结果与分析
2.1 数据集介绍
为了验证溯源算法的有效性,本文设计了仿真对比实验来进行验证。对比方法采用目前溯源领域中具有代表性的方法,分别是距离中心性算法(DC)、Jordan中心性算法(JC)、传播中心性算法(RC)[7]。在实验过程中,采用SI模型来模拟信息传播,代表着网络中的节点只可能处于感染态(I态)和易感态(S态)。在此模型下,被感染的节点会一直处于感染态并且会以一定的概率持续感染它的相邻节点。与此同时,选用三个具有代表性的网络进行模擬实验,分别是人工网络SCALE-FREE、真实网络HARM及POWER-GRID。三个网络的详细信息如表1所示。
本文选用了三个具有代表性的网络,其节点数量与连边数量符合局域网络的特征,使实验结果更具有说服力。
2.2 实验指标选取
想要评价一个溯源算法的效果,一般采用溯源检测率 (Detection Rate)和错误距离(Error Hops)来衡量。其中,溯源检测率的计算方式如式(3)所示:
在上述公式中,M代表溯源计算的总次数,MT代表监测到真实源节点的次数。因此,如果检测率的值越大,则说明溯源方法的准确率越高。
错误距离的计算方式采用式(4)可以表示为:
在上述公式中,v1代表通过溯源算法计算得到的源节点,v2代表网络中的真实源节点。错误距离代表的是两者之间的差值。因此,如果错误距离的值越小,则说明通过溯源方法计算得到的源节点距离网络中真实源节点距离越小,溯源结果的准确率越高。
2.3 实验结果
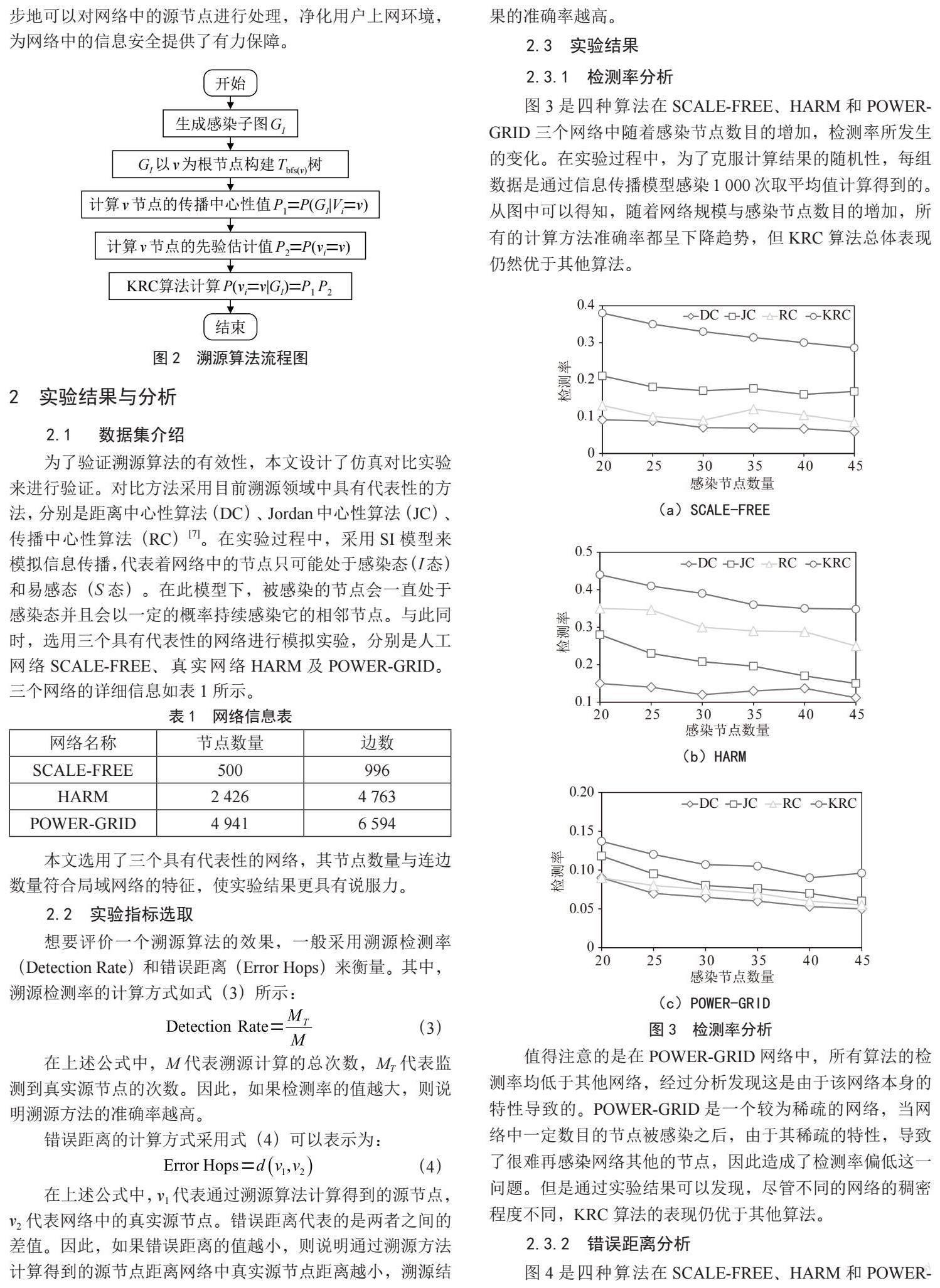
2.3.1 检测率分析
图3是四种算法在SCALE-FREE、HARM和POWER-GRID三个网络中随着感染节点数目的增加,检测率所发生的变化。在实验过程中,为了克服计算结果的随机性,每组数据是通过信息传播模型感染1 000次取平均值计算得到的。从图中可以得知,随着网络规模与感染节点数目的增加,所有的计算方法准确率都呈下降趋势,但KRC算法总体表现仍然优于其他算法。
值得注意的是在POWER-GRID网络中,所有算法的检测率均低于其他网络,经过分析发现这是由于该网络本身的特性导致的。POWER-GRID是一个较为稀疏的网络,当网络中一定数目的节点被感染之后,由于其稀疏的特性,导致了很难再感染网络其他的节点,因此造成了检测率偏低这一问题。但是通过实验结果可以发现,尽管不同的网络的稠密程度不同,KRC算法的表现仍优于其他算法。
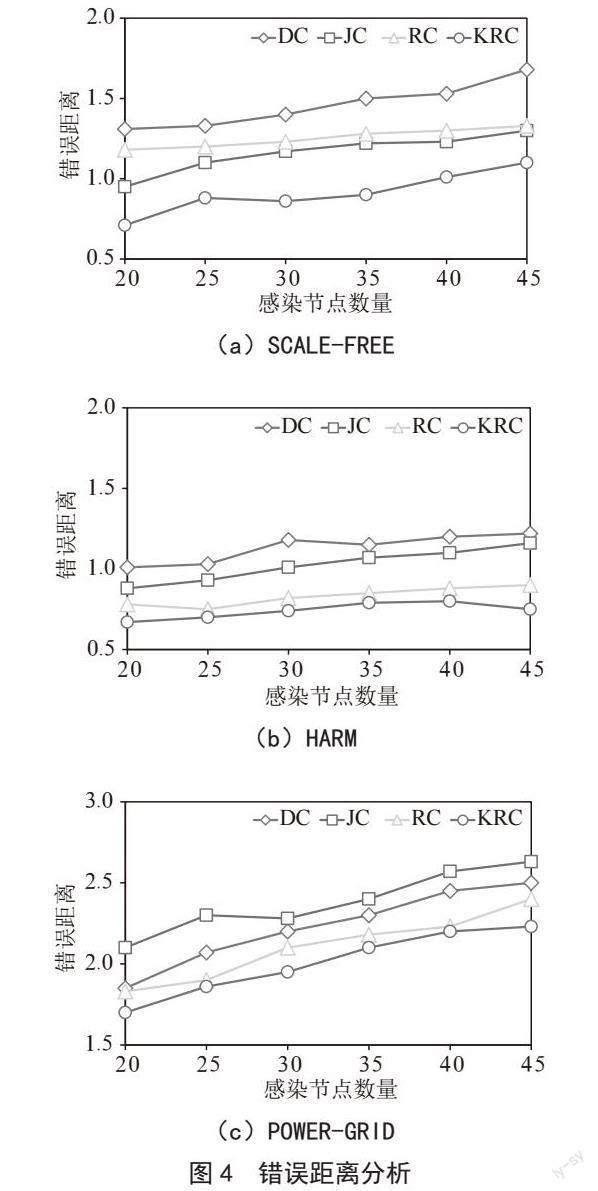
2.3.2 錯误距离分析
图4是四种算法在SCALE-FREE、HARM和POWER-GRID三个网络中随着感染节点数目的增加,错误距离所发生的变化。算法通过计算所得到的错误距离越小,代表着其与真实源节点的距离越小,说明算法溯源性越强。同样地,为了克服计算结果的随机性,每组数据是通过信息传播模型感染1 000次取平均值计算得到的。从实验结果中我们可以发现,随着网络规模与感染节点数目的增加,所有算法的错误距离都有所增加,但KRC算法总体表现仍然优于其他算法且增长较为平稳。
同样地,在POWER-GRID网络中,所有算法的错误距离均高于其他网络,原因在检测率分析处已经进行详解,因此此处不再进行赘述。
结合溯源检测率和错误距离的实验结果表明,在局域网络中,本文所提出的溯源算法KRC具有准确率高、错误距离较小的优点。
3 结 论
随着计算机技术的飞速发展,社交网络的应用已经逐渐成熟。但与此同时随着用户数目的增加,网络关系变得愈发复杂,信息传播的方式也愈发多样化。此时网络中所产生的信息质量将无法保证,有些不实消息进而演变成舆情信息,如果纵容舆情信息在网络中持续发酵,将对社会产生危害。由此可见,对舆情信息进行溯源是十分必要的[8-10]。
本文聚焦于局域社交网络,针对现有算法对于网络结构特性分析不足,从而导致了溯源结果准确率不高的现状,对局域网络的结构特征和节点自身特性进行分析,提出了一种融合先验估计与后验估计的信息溯源算法,弥补了当前溯源算法存在的缺陷。当一则信息在网络中传播一定时间步长后,根据感染网络快照中已感染节点其节点重要性值进行排序并处理,以此作为溯源算法的先验估计;随后,采用传播中心性算法作为后验估计,得到融合先验估计和后验估计的信息溯源算法。并且经过多维度的对比试验,验证了本文所设计的算法在检测率和错误距离两个方面均优于其他算法。
因此可以考虑将本文所设计的融合先验估计与后验估计的舆情溯源算法应用于真实的局域社交网络中,可以精准锁定局域社交网络中传播舆情信息的源点,并对其加以管理,从而净化网络环境,维护网络安全。
参考文献:
[1] 陈齐瑞,徐家宁,张维,等.基于AARRR模型的电力微信公众号信息溯源方法研究 [J].微型电脑应用,2021,37(7):97-99.
[2] 查蕴初.论复杂网络在公安情报网络中的应用 [J].网络安全技术与应用,2022(6):113-115.
[3] 范诗雨.突发事件下网络谣言传播结果影响因素研究 [D].太原:山西财经大学,2021.
[4] 黄春林,刘兴武,邓明华,等.复杂网络上疾病传播溯源算法综述 [J].计算机学报,2018,41(6):1156-1179.
[5] VEGA-OLIVEROS D A,COSTA L D F,RODRIGUES F A. Influence maximization by rumor spreading on correlated networks through community identification [J].Communications in Nonlinear Science and Numerical Simulation,2020,37 (4):83-98.
[6] 赵文,水铭伟.大数据背景下个人信息安全保护措施研究 [J].电脑编程技巧与维护,2018(7):86-87+93.
[7] 于欢. 社交网络中信息溯源算法研究 [D].徐州:中国矿业大学,2021.
[8] 边娜.大数据信息安全典型风险及保障机制研究 [J].大众标准化,2022(19):110-112.
[9] 张欣.基于节点重要性的溯源算法研究 [D].徐州:中国矿业大学,2021.
[10] 陈业华,白静,李兴源.基于网络媒体信息的传染病传播模型及其仿真研究 [J].数学的实践与认识,2017,47(13):176-185.
作者简介:张欣(1997.05—),女,汉族,辽宁营口人,助教,硕士研究生,研究方向:社交网络;王丽娟(1981.11—),女,汉族,江苏赣榆人,副教授,硕士研究生,研究方向:机器学习、聚类分析;沐雅琪(1996.10—)女,汉族,江苏兴化人,助教,硕士研究生,研究方向:动态规划算法。
