基于改进的条件生成对抗网络的可见光红外图像转换算法
2023-06-16马得草鲜勇苏娟李少朋李冰
马得草,鲜勇,苏娟,李少朋,李冰
(1 火箭军工程大学 作战保障学院, 西安 710025)
(2 火箭军工程大学 核工程学院, 西安 710025)
0 引言
利用可见光图像得到对应红外图像的方法,能够有效解决红外图像在红外制导、红外对抗和红外目标识别任务中数据缺乏的问题。目前,采用红外特性建模得到红外仿真图的方法,能够有效仿真得到目标的红外辐射特性。但是,该方法的仿真过程需要进行目标材质分类、分割等繁琐的操作,并且仿真得到的红外图像缺乏纹理信息。因此,需要探索一种高效准确的将可见光图像转换为对应红外图像的新范式。
基于生成对抗网络(Generative Adversarial Nets, GAN)[1]的图像生成技术为红外图像的生成提供了新的思路。特别地,Pix2Pix[2]和CycleGAN[3]为可见光图像转换为红外图像提供了通用网络框架,在文献[4-8]中均采用条件生成对抗网络的方式生成了红外图像。其中,ThermalGAN[4]和LayerGAN[5]通过多模态数据生成红外图像。ThermalGAN 分两步生成红外图像,首先用可见光图像和温度矢量生成目标的平均温度红外图像,然后用目标的平均温度红外图像和可见光图像生成更加精细的红外图像。LayerGAN 包括两种方式生成红外图像:一种方法是使用温度矢量、语义分割图像和热分割图像生成红外图像;另一种方法是使用可见光图像、语义分割图像和热分割图像生成红外图像。这两种方法对数据要求高,需要多种模态的数据,对于基于红外图像的行人重识别任务有着重要意义。文献[6-8]算法仅将可见图像作为输入,输出等效的红外图像。I-GANs[6]和Pix2pix-MRFFF[7]通过改进生成网络来改善红外生成图像的质量,而InfraGAN[8]基于UNetGAN[9]的思路是通过改进对抗网络来提高红外生成图像的质量。
本文针对现有方法生成的红外图像在不同程度上存在纹理不清晰、结构缺失的问题,将可见图像作为输入,输出等效的红外图像,通过改善生成网络和对抗网络来提高红外生成图像的质量,基于ConvNext[10]设计生成网络有效利用提取的可见光图像的深层特征和浅层特征,对抗网络通过对红外生成图像进行特征统计,对红外生成图像的灰度和结构信息加以引导,减弱对生成网络的约束,从而释放生成网络更大的潜能。
1 网络结构
本文提出的网络是基于条件生成对抗网络[11](Conditional Generative Adversarial Nets, CGAN)改进而来的,由基于ConvNext 编码解码结构的生成网络和特征统计对抗网络组成。其结构如图1 所示,生成网络的解码部分通过对编码部分深层特征和底层特征的利用改善了红外生成图像的质量,对抗网络通过对图像特征的一阶特征统计量和二阶特征统计量进行损失计算得到GAN 损失,与L1 损失结合作为总的损失,最终生成了更为清晰的红外图像。

图1 算法结构Fig.1 Algorithm structure
1.1 生成网络
生成网络以256×256 大小的可见光图像作为输入,将其转换为对应的红外图像,结构如图2 所示。具体来讲,生成网络在编码部分通过步长为4 和2 的卷积对可见光图像进行下采样,通过卷积模块提取可见光图像的特征,如图2(b)所示,最终使用在ImageNet 数据集上训练好的ConvNext_tiny 作为网络的编码器。在解码部分,通过跳跃连接和残差连接分别加强了对编码部分提取的图像底层特征和深层特征的利用。在上采样过程中,通过上采样模块,如图2(c)和(d)所示,重建出256×256 大小的红外图像。生成网络结构参数如表1 所示。

表1 生成网络结构参数Table 1 Generative networks structure parameter

图2 生成网络Fig.2 Generative Networks
该生成网络在编码部分主要采用的卷积是7×7 的大卷积核,步长为1,填充为3,每个Stages 的卷积通道数借鉴Tranformer 的经验,如ConvNext_tiny 的通道数分别设为96、192、384 和768,且每个Stages 中堆叠的卷积模块之比为3∶3∶9∶3。在解码部分,主要采用具有相同结构的上采用模块,包括两个1×1 卷积核的卷积和一个3×3 卷积核的反卷积。其中卷积主要用于对反卷积结果进行微调,反卷积主要用于扩充图像的尺寸,两个残差连接分别加强了编码部分提取的特征和反卷积后结果的利用。
图2(b)所示的卷积模块采用了ConvNext 中的卷积模块设计,文献[10]证明了这种模块的设计方法在分类、检测和分割方面的优异表现。此外,文献[12]表明ConvNext 可以像当前最先进的Transformer 一样鲁棒和可靠,甚至更加可靠。UNet 网络及其变体主要关注于编码部分和解码部分之间的跳跃连接,注重对图像底层特征的利用而缺少对图像深层特征的关注。图2(c)所示的上采样模块通过残差连接加强了对编码部分图像深层特征的利用。具体过程如式(1)所示。此外,上采样模块融合了卷积模块中一些有益的设计,如采用更少的归一化层,层归一化(Layer Normalization, LN)替代批量归一化(Batch Normalization,BN)等技巧。
式中,U(⋅)表示上采样模块操作,C(⋅)表示卷积模块操作,D(⋅)表示采用转置卷积进行上采样,Fdeep表示深层特征。最终上采样的结果与编码部分的底层特征进行拼接,进行下一步的上采样。生成网络一共进行了5 次上采样,最后一次上采样采用图2(d)所示的上采样模块,逐渐降低卷积的通道数,平滑地生成图像。
1.2 对抗网络
提出的对抗网络称为特征统计网络(Statistical Feature Discriminator, SPatchGAN)是将一些常见的对抗网络如PatchGAN[13]专注于图像感受野特征的研究转化为对图像特征统计信息的研究,减小对生成网络的约束,从而释放生成网络更大的潜能。统计特征网络由特征提取层、特征计算部分和线性层组成,最后将图像的特征统计量作为损失进行监督。结构如图3 所示。表2 中展示了对抗网络的结构参数。具体地,对抗网络通过平均池化对图像进行降采样,在图像的三个不同尺度上通过相同结构的卷积层进行特征提取(表2 中Conv1~Conv5),然后进行统计特征计算,最后通过线性层得出的损失相加得到总的损失。文献[8]表明,L1 损失和基于结构相似性(Structural Similarity Index Measure, SSIM)的损失结合可以有效地提高红外生成图像的质量,其中评价指标SSIM 由均值、标准差和协方差组成,即通过图像一阶信息和二阶信息的结合构建的。因此,选取图像特征的一阶统计量(均值)和二阶统计量(标准差)作为损失监督。

表2 对抗网络结构参数Table 2 Adversarial networks structure parameter
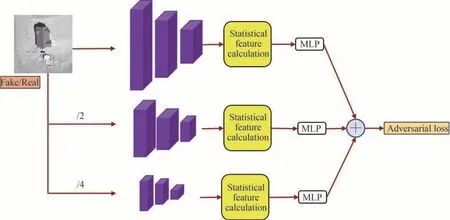
图3 对抗网络Fig.3 Adversarial networks
1.3 损失函数
仅使用L1 损失和GAN 损失用于生成高质量的红外图像,本文算法的损失函数表示为
式中,G∗表示总的损失,ℓCGAN表示条件生成对抗网络的损失,ℓL1表示L1 损失;E( ⋅)表示期望值,下标x∼Pdata表示x取自可见光图像的数据,下标x,y∼Pdata表示x取自可见光图像及y取自x对应的真实红外图像的数据;λ表示L1 损失的权重,y表示标签信息(真实红外图像),D(x,y)表示判别器判断真实数据是否真实的概率;G(x,z)表示生成器根据源域图像x(可见光图像)生成的目标域图像z(红外图像),D(x,G(x,z))表示判别器判断生成数据G(x,z)是否真实的概率。
2 实验验证
2.1 数据集
实验涉及3 个不同的数据集(VEDAI Dataset[14]、OSU Color-Thermal Dataset[15]和KAIST Dataset[16]),均由配准好的可见光图像和红外图像对组成。VEDAI 数据集采集的是2012年美国犹他州AGRC 卫星的春季图像,包含1 024×1 024(其中每个像素代表了12.5 cm×12.5 cm 的区域)和512×512(其中每个像素代表了25 cm×25 cm 的区域)两种尺寸的图像,红外图像为近红外图像。将VEDAI 数据集中512×512 尺寸的图像裁剪为包含目标的256×256 尺寸的图像以适应网络输入。其中,1 046 对用于训练,200 对用于测试。OSU 数据集常用于可见光图像和红外图像的融合,其中红外相机采用Raytheon PalmIR 250D,25 mm 的镜头,光学相机采用Sony TRV87 Handycam,采样频率为30 Hz,得到的图像分辨率为320×240,最终拍摄得到的图像采用单应性矩阵和人工选点的方式进行配准。OSU 数据集的拍摄场景是美国俄亥俄州立大学校园内繁忙的道路交叉口。OSU 数据集图像被裁剪并放大为256×256 尺寸以适应网络输入。因为该数据集得到的图像场景单一,对该数据进行了抽样处理。最终,683 对图像用于训练,170 对图像用于测试。KAIST 数据集包含学校、街道和乡村的各种日常交通场景,一般用于行人检测,其中彩色相机是PointGrey Flea3,彩色图像尺寸为640×480,红外相机是FLIR-A35,红外图像尺寸为320×256,经过相机标定,最终得到640×512 尺寸的图像对。实验中选择KAIST 数据集中白天拍摄的图像,并被缩放为256×256 尺寸以适应网络输入。经过抽样处理,减少大量重复的图像对,最终,5 008 对用于训练,1 239 对用于测试。
2.2 评价指标
6 个客观评价指标用于评估生成图像质量,包括峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)[17]、结构相似性(SSIM)、多尺度结构相似性(Multi-scale Structural Similarity Index Measure, MS-SSIM)[18],学习感知图像块相似度 (Learned Perceptual Image Patch Similarity, LPIPS)[19]、 Fréhet Inception 距离(Fréchet Inception Distance, FID)[20]和灰度相似性。PSNR 和SSIM 通常一起用于评估图像质量。多尺度结构相似性弥补了结构相似性在图像多尺度评价上的不足。LPIPS 测量两个图像特征向量之间的欧几里得距离。为了计算指标,比较特征是从在ImageNet 上预训练的基于卷积神经网络(Convolutional Neural Network,CNN)的主干中获得的(实验中使用了AlexNet 网络模型)。FID 是两个图像数据集之间相似性的度量,在本文被用于评估生成红外图像集和真实红外图像集的相似性,它被证明与人类对视觉质量的判断有很好的相关性,并且常用于评估生成对抗网络样本的质量。灰度相关性是采用灰度相关匹配中常用的归一化积相关算法中归一化相关性(Normalized Cross Correlation,NCC)作为评价指标。文献[21]中证明了红外图像的灰度特征与温度分布有着密切的关系,因而灰度相关性评价指标可以在一定程度上表示温度分布相关性。
2.3 训练细节
所有实验均在Intel (R)Core (TM)i9-10980XE CPU 3GHz 和一块NVIDIA RTX 3090 GPU 上运行,采用的深度学习框架是Pytorch。提出的基于改进的条件生成对抗网络的红外生成算法,使用了Adam 优化器,其中β1和β2分别设置为0.5 和0.999。网络训练共包含200 轮训练,以确保模型收敛。其中,生成网络前100 轮训练的学习率固定在0.000 2,然后在剩余的100 轮训练中线性下降到0,对抗网络前100 轮训练的学习率固定在0.000 002,然后在剩余的100 轮训练中线性下降到0。
在本文算法中,L1 损失和GAN 损失对于网络的训练起着重要作用,设置λ 作为L1 损失的权重系数用于协调L1 损失和GAN 损失。L1 损失设置过大将导致对抗网络不能有效工作,从而导致生成图像缺乏纹理信息,不添加L1 损失或者L1 损失设置过小将导致网络难以训练。图4 表明当λ取100 时,SSIM、MSSSIM、PSNR、LPIPS、FID 和NCC 评价指标均取得了最好值,因而将λ 设置为100。
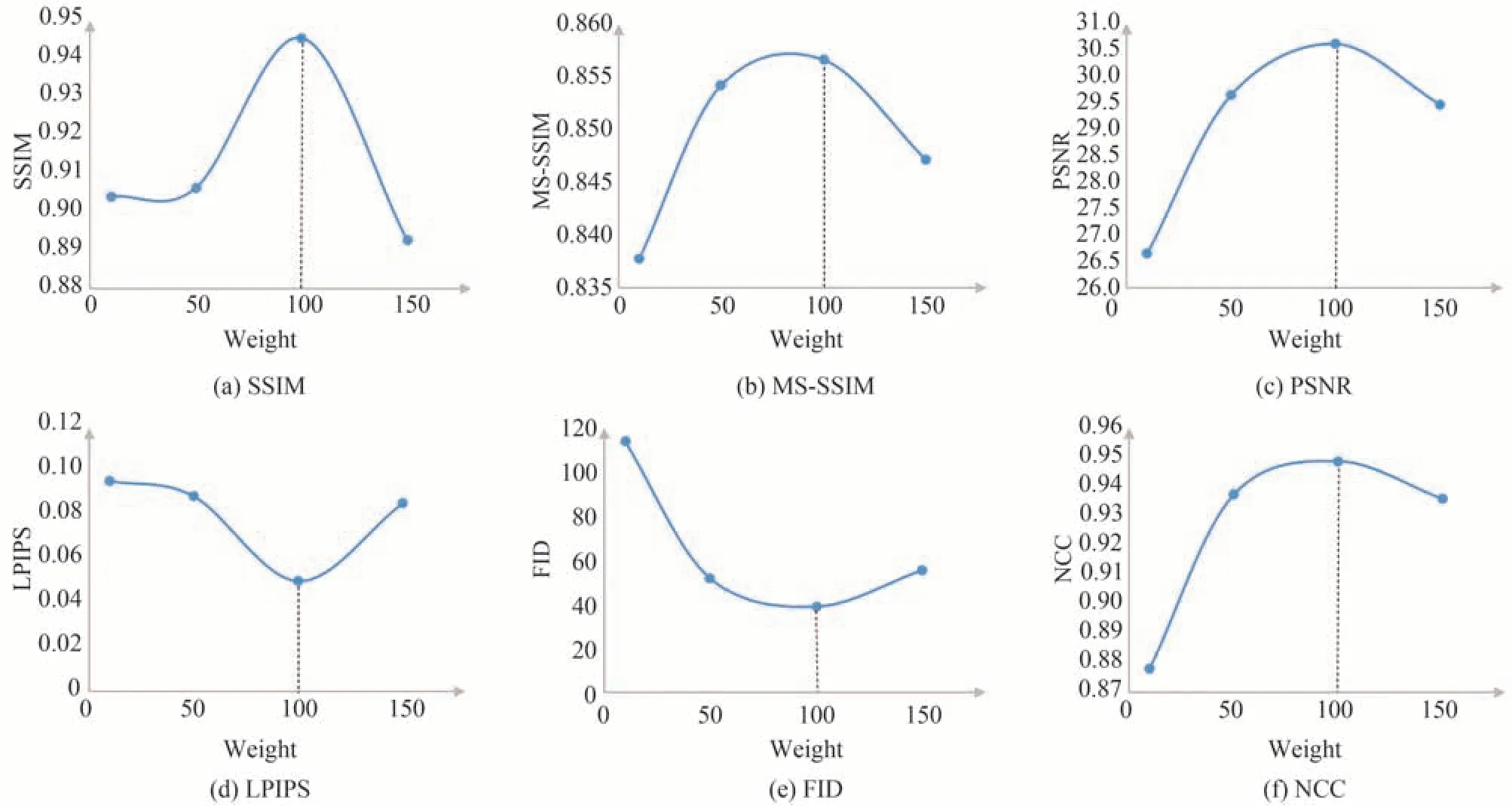
图4 评价指标随权重系数λ 的变化Fig.4 Change of evaluation metrics with the weight coefficient λ
2.4 消融实验
为了验证本文方法的有效性,在VEDAI 数据集上进行了消融实验,Pix2Pix 作为基线模型分别验证了改进的生成网络和对抗网络的效果,为了公平起见消融实验中生成网络的编码部分没有加载预训练参数,将特征统计对抗网络(SPatchGAN)、无两种残差连接的上采样模块(Upsampling1)、仅有第2 种残差连接的上采样模块(Upsampling2)、仅有第1 种残差连接的上采样模块(Upsampling3)、有两种残差连接的上采样模块(Upsampling4)和Pix2Pix 模型生成结果进行对比。主观评价结果如图5 所示,客观评价结果如表3 所示。

表3 消融实验客观对比结果Table 3 The objective comparison results of ablation experiment

图5 消融实验主观对比结果Fig.5 The subjective comparison results of ablation experiment
观察图5 的生成结果可以发现,采用本文提出的统计特征对抗网络生成的红外图像在图像的灰度信息上保持较好(图5(d)红色框所示),原因在于本文对抗网络中采用均值和标准差作为统计量,均值有助于引导图像生成过程中灰度信息的保持,标准差有助于图像生成过程中结构的保持。这在文献[22]中也得到了证明。图5(e)~(h)中红色框结果显示了本文提出的上采样模块对于红外图像生成过程中的灰度真实性有较大的改善。
从表3 中的数据对比可以发现,SPatchGAN 对MS-SSIM 的提升较大,这主要在于其相比PatchGAN 提取了生成图像的多尺度特征,从不同尺度的角度分别约束了图像的生成。从表3 中的第4 行至第7 行数据观察可以发现,提出的几种上采样模块对5 种指标的提升均有帮助,从4 种上采样模块的对比中可以看出上采样模块中第一种残差连接的效果更加显著(Upsampling3 的结果相比Upsampling2 的结果指标提升更明显),第一种残差连接主要将编码部分的深层特征传入解码部分,说明加强对生成网络编码部分提取图像深层特征的利用有助于改善生成图像的质量。
2.5 对比实验
为了验证本文方法的优越性,在3 个数据集上进行了实验验证,将本文方法与基于条件生成对抗网络的红外图像生成算法Pix2Pix、ThermalGAN、I-GANs、InfraGAN 进行对比实验。ThermalGAN 使用了可见光图像和温度矢量作为输入,为了对比的公平,实验中的ThermalGAN 仅使用了可见光图像作为输入。InfraGAN 的输入是512×512 大小的图像,对InfraGAN 进行了修改以适应256×256 大小图像的输入。图6展示了实验的主观对比结果,表4 展示了客观评价结果。

表4 不同算法的客观实验结果对比Table 4 The objective experiment results comparison of different algorithms

图6 不同算法的主观实验结果对比Fig.6 The subjective experiment results comparison of different algorithms
图6 中3 个数据集典型红外图像的生成结果表示5 种模型在VEDAI 数据集上的生成效果均较好,5 种模型在VEDAI 数据集上的生成结果主要体现在图像的灰度信息差别上,从最终结果可以看出本文算法生成的红外图像灰度信息更加准确。OSU 数据集场景较为单一,本文算法在OSU 数据集上对于微小物体有着更好的生成效果,细节更加分明。本文方法在KAIST 数据集上相比其他4 个模型,红外生成图像中的物体纹理更清晰,细节信息更丰富。
表4 数据表明本文方法在3 个不同数据集上有着最好的表现,尤其在高分辨率的VEDAI 数据集上。从对比结果来看,随着图像分辨率的增加,算法的性能出现了下降,这将在下一步研究中进行解决。综合主观和客观对比结果,本文算法的红外生成图像质量优于其他算法的生成结果。
表5 中展示了5 种算法的不同结构,本文算法仅使用L1 损失和GAN 损失对生成网络进行指导,便取得了较好的红外图像生成效果。算法设计时没有考虑网络规模和训练耗时的因素,下一步将在网络轻量化和减少网络训练耗时方面进行改善。
3 匹配应用实验
为了验证本文算法在可见光图像与红外图像异源匹配方面的应用价值,采用3 种经典的传统匹配算法和3 种较为先进的基于深度学习的匹配算法进行实验验证。传统匹配算法分别是尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)算法、SURF(Speeded Up Robust Features)算法和ORB(Oriented FAST and Rotated BRIEF)算法,基于深度学习的匹配算法分别是D2-Net 算法[23]、SuperGlue 算法[24]和LoFTR 算法[25]。匹配实验结果采用匹配终点误差(Matching end Point Error,EPE)进行评价,表示为
式中,n代表匹配成功的点数,(xi,yi)代表特征点在目标图像上的位置,代表相应特征点经过真实单应性矩阵转换后的位置。所使用的数据集均是配准好的图像对,因此单应性矩阵实际上是一个单位矩阵。
3.1 传统匹配算法
SIFT 算法是通过求一幅图中的特征点及其有关尺度和方向的描述子得到特征,并进行图像特征点匹配。SIFT 所查找到的关键点是一些十分突出,不会因光照、仿射变换和噪音等因素而变化的点。SURF 算法是一种稳健的局部特征点检测和描述算法。SURF 的出现很大程度是对SIFT 算法的改进,用一种更为高效的方式改进了特征的提取和描述方式。ORB 算法是一种快速特征点提取和描述的算法,其特征检测是将FAST 特征点的检测方法与BRIEF 特征描述子结合起来,并在它们原来的基础上做了改进与优化。采用不同的传统匹配算法(SIFT 算法、SURF 算法和ORB 算法)进行图像特征提取,之后用K 近邻算法匹配特征点,并用随机采样一致性算法剔除错误的匹配点得到最终的匹配结果。特别地,由于算法限制,其中部分图像无法匹配,因此在评价生成红外图像的传统匹配算法结果时,只计算了成功匹配图像对的匹配终点误差。
3.2 基于深度学习的匹配算法
D2-Net[23]直接从特征描述子进行关键特征检测,将检测放在处理的后期阶段,从而获得更稳定的关键点,解决了在困难的成像条件下找到可靠像素级匹配的问题。SuperGlue[24]提出了一种基于图卷积神经网络的特征匹配算法,采用SuperPoint 提取特征点及描述符,通过求解可微分最优化转移问题实现特征匹配。LoFTR[25]是一种不依赖关键点检测的端到端特征匹配方法,利用卷积神经网络初步提取特征,再利用Transformer 的全局注意力加强特征,可以较好地对低纹理图片和相似区域进行匹配。使用这3 种匹配算法时,均采用它们提供的预训练权重进行匹配实验。
3.3 匹配实验验证
为了验证本文算法在可见光图像和红外图像异源匹配任务中的应用价值,在3 个数据集上对生成的结果进行了匹配实验,分别对比了Pix2Pix、ThermalGAN、I-GANs、InfraGAN 和本文算法生成的红外图像与真实红外图像之间的匹配结果。此外,还添加了可见光图像和红外图像的匹配实验作为对照。图7 展示了6 种匹配方法在可见光图像与红外图像之间的匹配结果,图8 展示了6 种匹配方法在相同红外图像之间的匹配结果。表6 展示了6 种匹配方法的匹配终点误差。
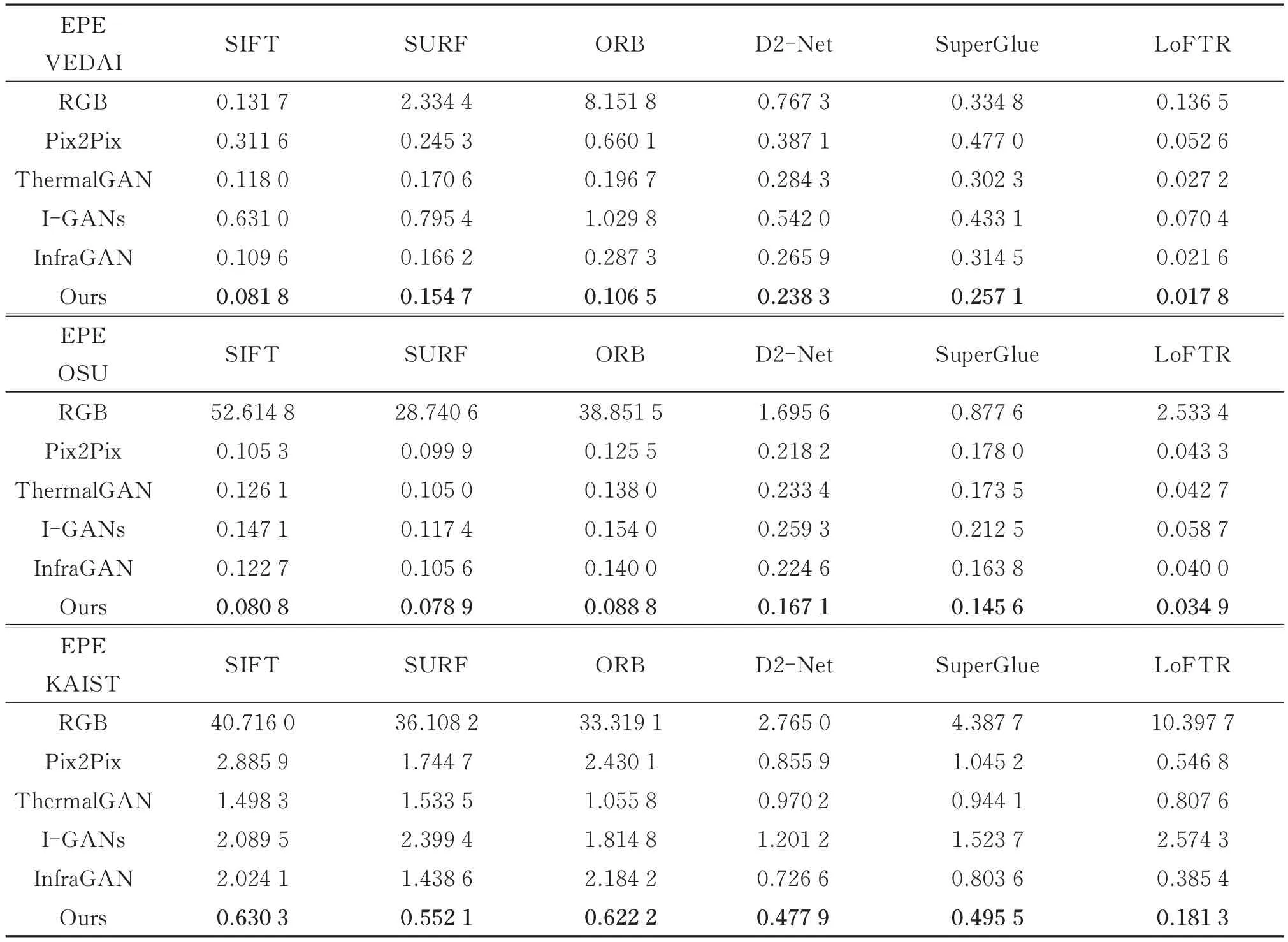
表6 6 种匹配算法的匹配终点误差Table 6 EPE of six matching algorithms

图7 6 种匹配算法在异源匹配中的表现Fig.7 Performance of six matching algorithms in heterogeneous matching

图8 6 种匹配算法在红外图像匹配上的表现Fig.8 Performance of six matching algorithms in infrared image matching
图7 和图8 每组匹配图像对中左侧图像为真实红外图像作为基准图像,右侧为待匹配图像。对比发现,6 种算法在同源图像的匹配上相比异源图像提取的特征点更多且错误匹配的情况更少。从图7 可以发现基于深度学习的匹配算法相比传统匹配算法在异源图像的匹配上提取的特征点更多且误匹配现象更少。特别地,传统图像匹配算法在异源图像匹配过程中可能会出现失败的现象,如图7(c)KAIST 数据集上的结果所示。
从表6 的结果可以发现,LoFTR 匹配算法在3 个数据集上表现最好。相比采用可见光图像进行匹配,利用图像转换算法将可见光图像转换的对应红外图像进行匹配,可以有效降低匹配终点误差。对比表4 和表6的数据可以发现,匹配终点误差和6 种客观评价指标并不成严格的正比关系,但是具有正相关关系,即一般客观评价指标表现越好,相应的匹配终点误差也越小。从表4 和表6 的结果中可以发现,本文算法不仅主客观上表现较好,而且在匹配任务中也有着较好的表现。
4 结论
本文提出了一种基于改进的条件生成对抗网络的可见光红外图像转换算法,用于解决当前典型红外生成算法中生成图像纹理细节信息差和结构信息差的问题。该算法提出的生成网络不仅注重对图像底层特征的利用,而且加强了对图像深层特征的利用。对抗网络通过图像特征的一阶统计量(均值)来引导红外图像在生成过程中产生更加真实的灰度信息,通过图像特征的二阶统计量(标准差)来引导红外图像在生成过程中保持结构信息。实验结果表明,所提算法生成了纹理细腻、结构清晰的红外图像,并且生成的红外图像在可见光图像与红外图像匹配方面有较好的应用价值,适用于室外温度相对固定情况下的可见光图像和对应红外图像的转换。
