多特征尺度融合改进Faster-RCNN视网膜微动脉瘤自动检测算法
2023-06-16高玮玮杨亦乐方宇樊博宋楠
高玮玮,杨亦乐,方宇,樊博,宋楠
(1 上海工程技术大学 机械与汽车工程学院, 上海 201620)
(2 复旦大学附属眼耳鼻喉医院 眼科, 上海 200031)
0 引言
视网膜微动脉瘤(Microaneurysms,MAs)是一种微小血管病变,由血管壁变弱引起的毛细血管肿胀形成[1],因此MAs 可能与不同的眼科和心血管疾病相关[2]。例如,MAs 已被证实是中风的先兆因素[3]。此外,MAs 更是糖尿病视网膜病变(简称“糖网”,Diabetic Retinopathy,DR)[4]的最早期典型症状。糖网是一种由糖尿病引发的视网膜疾病,是目前全球导致中老年人群失明的主要原因[5]。对于糖网,至关重要的是对该疾病的及早发现,以阻止疾病的进展和预防潜在的视力损失。然而,MAs 尺寸较小,相对于眼底图像而言属于微小目标;且由于视觉条件不理想,MAs 可能相对于背景呈现低对比度,或者可能受到图像中不均匀照明的影响;此外,MAs 还可能与图像中的其他结构混淆,例如微出血、色素沉着变化,甚至是眼底照相机中的灰尘颗粒。故针对眼底图像中的MAs 进行自动检测是一项极具挑战性的任务,很多研究人员就此展开了相关研究。
MAs 自动检测算法通常可分为三类:基于物理模型的方法、基于分类器的方法以及基于深度学习的方法。基于物理模型的方法主要根据MAs 的灰度分布特征进行数学建模,如:赖小波等[6]提出了一种基于特征相互关系的视网膜MAs 自动提取算法;郑绍华等[7]提出了一种新的基于Radon 变换的方法对眼底图像中的MAs 进行识别;高玮玮等[8]提出了一种基于数学形态学扩展极小值变换的MAs 自动检测方法; ZHANG Xinpeng 等[9]提出了一种基于特征转移网络和局部背景抑制的MAs 检测方法等。基于分类器的方法一般先获取MAs 候选区,然后再通过所设计分类器对候选区进行分类,如ORLANDO J I 等[10]首先采用中值滤波去除眼底图像中的MAs,再经过形态学膨胀得到糖网背景图像,在此基础上将原图与糖网背景图像相减得到MAs 的候选区,然后对候选区提取传统特征和深度特征用于MAs 分类;WU B 等[11]利用从眼底图像中提取出的多个轮廓和局部特征训练KNN 分类器以实现MAs 的准确分类;YADAV D 等[12]首先通过分析直方图进行MAs 候选区域分割,然后再根据MAs 候选区域的形状、灰度、纹理等特征进行识别等。基于深度学习的MAs 自动检测方法主要为搭建端到端的深度神经网络,如DAI L 等[13]提出了一种临床报告引导的多筛分卷积神经网络,该网络利用临床报告中的少量监督信息,通过特征空间中的图像到文本映射来识别潜在的MAs;ROHAN R A[14]提出了一种基于YOLO(You Only Look Once)的MAs 自动检测算法;赵学功等[15]提出了基于卷积神经网络的MAs 自动检测方法;XU Y 等[16]提出一种基于改进U-Net 网络的MAs 自动分割算法等;郭松等[17]提出一种基于多任务学习的分割模型Red-Seg 来获取眼底图像中的MAs。
由于眼底图像会因为患者、环境、采集设备等因素的不同而出现不同的亮度和对比度,且还会存在类似于MAs 的对象,如小血块、血管结构、背景噪声等,故基于物理模型的方法不仅难以建立广泛适用的算法且容易造成误检。基于分类器的方法通常先采用滤波、形态学、背景估计等传统方法进行候选区提取,而这些方法极易受到参数的制约,同时由于眼底图像内容复杂,故容易使对于微动脉瘤的检测精度不高。基于深度学习的方法相较于上述两种方法所存在的不足,有明显的优势,但针对眼底图像的微小目标——MAs 的自动检测而言,现有深度学习模型仍存在一些问题,如:小目标的特征无法得到充分利用、回归框位置不准确、检测精度不够高等,故提出了多特征尺度融合的改进Faster-RCNN(Improved Faster-RCNN,Faster-RCNN-Pro)用于实现眼底图像中MAs 的精准检测。该方法首先选用检测精度较优的Faster-RCNN 作为基础网络,然后结合眼底图像中的MAs 自动检测,对其进行优化,具体为:首先通过采用多特征尺度融合对特征提取网络与区域候选网络(Region Proposal Network,RPN)结构进行改进以提高网络对于微小目标特征的利用从而提高MAs 的检测精度;然后,通过感兴趣区域齐平池化以消除感兴趣区域池化过程中引入的两次量化误差;最后,对损失函数中的smooth L1 损失函数进行重新设计得到平衡L1 损失函数,以实现通过损失函数优化有效降低大梯度难学样本与小梯度易学样本间的不平衡问题,进而使模型能够得到更好的训练。在完成Faster-RCNN 网络模型优化的基础上,将该网络模型用于眼底图像中MAs 的自动检测,并进行性能分析。
1 实验材料及设备
实验采用Kaggle DR 数据集用以训练和测试所提出的Faster-RCNN-Pro 算法对于眼底图像中MAs 的自动检测性能。Kaggle DR 数据集由EyePACS(视网膜病变筛查免费平台)提供,来源于44 351 位患者(左右眼各一幅),共计有35 126 幅训练图像和53 576 幅测试图像,图像的分辨率在433×289 像素~5 184×3 456 像素之间[18]。眼科医师基于国际标准对每幅眼底图像进行了0~4 的糖网病患病程度的5 级分级,但由于本文研究的是所提出算法对于MAs 病灶的自动检测性能,故需对该数据集进行预处理以满足本研究的需求,具体为:利用文献[8]所述方法并辅以眼科医师的指导对Kaggle DR 数据集进行预处理以获取MAs 图像及注释文件。由于Kaggle DR 数据集的分布不平衡,经过该阶段预处理去除了大量图像(该数据集中几乎90%的图像不包含任何病变),最后只剩下5 519 幅包含MAs 的眼底图像。对于这5 519 幅眼底图像,均生成了注释文件。生成注释文件后,整个数据集(5 519 幅图像)按90/10 的比例进行划分,5 000 幅用于训练,519 幅眼底图像用于测试。此外,为充分验证所提出改进网络的检测性能,对原本包含519 幅眼底图像的测试集予以增加200 幅健康眼底图像进行扩充,即实际测试时测试集包含719 幅眼底图像。
实验采用的操作系统为ubuntu-18.04.5;CPU 为Intel Core i5-10300H;RAM 大小为32 GB;GPU 为RTX2060,显存大小为8 GB。运行软件环境为Pycharm;python 版本为3.7;Pytorch 版本为1.3.0;OpenCV 版本为4.5;此外,安装Cuda10.1 和Cudnn7.51 进行GPU 加速运算。
2 网络设计
Faster-RCNN[19-21]检测算法相较于YOLO[22-24]检测算法,多增设了一个RPN 结构,这不仅使其成为了两阶段的检测算法,而且提高了检测精度,故其检测准确性通常要优于YOLO 算法,具体算法流程如图1。由于MAs 尺寸较小(直径在10~100 µm 之间,具体形态如图1),属于眼底图像中的微小目标,因此利用原始Faster-RCNN 对眼底图像中的MAs 进行检测时会出现一些不足,如检测性能不够好、回归框位置不准确、数据分布不均匀等问题。针对以上问题,对Faster-RCNN 网络提出了3 点改进,分别为:多特征尺度融合、感兴趣区域齐平池化、损失函数优化(具体为对损失函数函数中的smooth L1 损失函数进行重新设计得到平衡L1 损失函数),改进后的算法流程如图2。
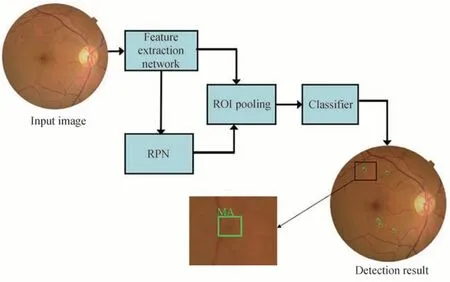
图1 Faster-RCNN 算法结构Fig.1 Faster-RCNN algorithm structure

图2 改进后的算法流程Fig.2 Flow of improved algorithm
2.1 多特征尺度融合
在特征提取网络VGG16 的结构中,特征图的尺寸在卷积的过程中越来越小,与之对应的待检测目标的特征信息也在不断变小。而RPN 网络采用最后一层特征图卷积得到的信息作为特征图并进行后续的操作,这会导致小目标的特征无法得到充分利用,这很明显对于MAs 的自动检测是非常不利的,故采用多特征尺度融合的方法对特征提取网络与RPN 结构进行改进,将该改进结构的Faster-RCNN 称为Faster-RCNN-I。
多特征尺度融合是通过一定的方式整合具有高层语义信息的深层网络特征图的空间特征维度,使其与具有低层语义信息的浅层网络特征图相同后,按照相加的方式进行融合,从而使提取出的特征图能够具有更丰富的语义信息以供后续环节使用[25]。多特征尺度融合后,需要在网络结构、检测和分类层、感兴趣池化层共3 个层上进行改进。
在特征提取主干网络上,将卷积层每次降采样称为一个Stage,如图3 所示,主干网络可分为5 个Stage,分别为C1,C2,C3,C4和C5。对于Ci(i=1,2,3,4,5),通过1×1 的卷积操作与下采样,使得其与Ci-1的尺度相匹配并相加,最后通过3×3 的卷积消除相加后由多维特征不连续产生的混叠效应,从而得到新的特征图Pi(i=1,2,3,4,5)。

图3 多特征尺度融合Fig.3 Multi-feature scale fusion
RPN 网络计算采用的是网络最后一层的特征图,对原图映射至特征图的k个预设大小的Anchor Box 进行分类与回归。这k个Anchor Box 预先设置为固定的长宽比,且在RPN 中使用同一个Stage 的特征图进行计算。为融合多特征尺度,Anchor Box 在保持原有预设大小与比例尺度的情况下,在不同的特征图上匹配与之相应的Anchor Box。考虑到计算效率,将Anchor Box 分别分布在P2、P3、P4这三个特征层上面,每一个特征图上分配的Anchor Box 均有3 种比例尺度,分别为1∶1、1∶2、2∶1。在RPN 检测时,目标在哪个特征图上能够分类出则采用该层的Anchor Box,具体过程如图4。

图4 多特征融合下的RPNFig.4 RPN based on multi feature fusion
在改变RPN 生成的区域建议后,对于特征图的Pooling 方式也需随之变化。原始Faster RCNN 中RoI(Region of Interest)Pooling 是把最后一层特征图作为输入,其中特征图与RPN 产生的映射关系可表示为
式中,P表示特征图的层级,P越大,对应特征图的尺度越小;4 表示输入层级;k是输入图像尺度;w,h分别表示RoI 区域的宽与长。由式(1)可知,RoI Pooling 的输入单一,通过在最后一层特征图上使用RPN 提取出的RoI 区域作为输入,这无法有效利用多特征尺度RPN 获取的RoI 区域,故需对RoI Pooling 进行改进,具体可表示为
式中,输入的特征图为当前层的特征图与深一层的小尺度特征图通过下采样的方式求和后的结果。通过将RPN 在多特征尺度上得到的RoI 区域对应的特征图作为RoI Pooling 的输入,确保了目标特征能够映射到特征图上,从而提高了目标检测精度。
2.2 感兴趣区域齐平池
为进一步提升对MAs 的检测性能,还需对RoIPooling 做出改进。原始RoI Pooling 中,初始像素点与RPN 得出的特征图上RoI 区域像素点对应关系为[20]
式中,(xfeature,yfeature)为特征图上的像素坐标,(x,y)为RoI 区域在原始图像上的坐标,s为下采样倍数,表示为取比括号内值小的最大整数,即向下取整。由于在计算(xfeature,yfeature)时,存在向下取整的计算,故此处引入了一次量化误差。此外,在RoI Pooling 的过程中,需将RoI 的输入直接固定成预设的大小,这带来了第二次量化误差。这两次量化误差使得原始特征区域与映射特征区域产生了偏差,这些偏差对数据集中的小目标——MAs 的检测影响很大,故提出对感兴趣区域进行齐平池化(如图5),图5 中黑色矩形框表示RoI 区域在特征图上的映射位置,具体关系可表示为
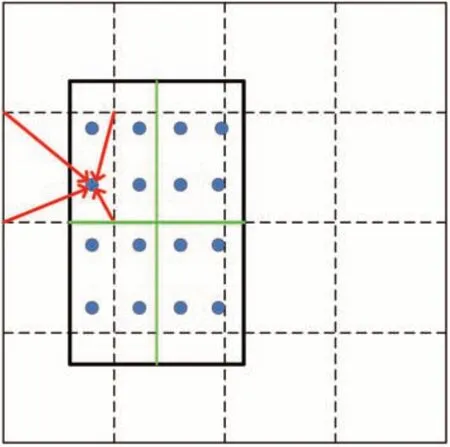
图5 感兴趣区域齐平池化Fig.5 Flush pooling of RoI
图5 中绿色实线表示根据RoI Pooling 的实际需求将区域分割为n个子区域,其中n的大小对应输出特征图尺度。图5 中每一个子区域中设置4 个点,每个点的像素值由特征图上最邻近区域的四个像素点通过双线性插值法获取[26],如红色箭头所示;随后,池化的过程在每个子块中进行,最终得到尺寸齐平的输出。该感兴趣区池化过程与Faster-RCNN 池化即RoI Pooling 过程的对比如图6。将该改进结构的Faster-RCNN 称为Faster-RCNN-II。

图6 感兴趣区池化过程对比Fig.6 Comparison of pooling process in RoI
2.3 损失函数优化
Faster-RCNN 的损失函数包括分类损失和回归损失两部分,可表示为[20]
式中,下标i表示第i个候选区域,i随同批次中真值数量变化;pi为检测网络中离散型概率分布,即判定第i个目标的类别;p*i为第i个框的GT(Ground Truth)标定值,即真实值(当该框中存在该目标物时p*i=1;反之,p*i=0);分类损失Lcls和回归损失Lreg分别由Ncls、Nreg以及权重λ归一化。ti={tx,ty,tw,th}表示目标物位置的预测值;ti*={tx*,ty*,tw*,th*}则是学习样本中人工给定的监督信息。
对于回归损失,由于参数回归时均近似为线性回归,且标注信息噪声较多,梯度回传不稳定[27],为缓解这一情况,回归损失使用梯度平缓的SmoothL1损失函数,可分别表示为
式(6)中的R即为式(7)中的Smooth L1 损失函数。其中,参数σ用于控制平滑区域的范围,以避免过大的梯度对网络参数产生过多的影响。
对式(7)求梯度,即
反向传播中损失较大的定义为困难样本,换言之容易样本损失较小。故由式(8)发现,在smoothL1 函数中,困难样本相较于容易样本来说,提供了更多的梯度信息,这导致了难易样本间学习能力的不平衡。
为解决该问题,设计了balanceL1 损失函数,即由式(8)得到balanceL1 损失的梯度函数,表示为
其中,反向传播时提供梯度高于γ的样本取γ作为梯度,以此平衡小梯度样本的梯度值与难学样本的梯度值。在此基础上,根据式(9)的梯度信息,通过积分求得平衡L1 损失函数为

图7 损失函数梯度Fig.7 Loss function gradient
3 结果与分析
3.1 评价指标
在目标检测任务中,通常使用召回率(Recall,R)和精确率(Precision,P)以及综合考虑召回率与精确率的指标F-score 对网络性能进行评价。因此为评价所提出网络模型对于MAs 的检测性能,基于病灶区域水平定义了上述指标,具体计算表达式分别为[28]
式中,ΤΡ(True Positive)为成功预测的正例,ΤΝ(True Negative)为成功预测的负例,FP(False Positive)为被误判为正例的负例,FN(False Negative)为被错误预测为负例的正例。
3.2 实验结果及分析
利用Kaggle DR 数据集对所提出的Faster-RCNN-Pro 网络模型进行训练时,超参数设置为:输入图像为彩色图像,尺寸经适当裁减去掉背景区域并进行压缩后为1 024×768,批处理大小设置为2,迭代次数共计为31 000 次,基础学习率为0.001 25(当第23 000 次迭代后学习率衰减至0.000 125),优化方法采用带动量因子的小批量随机梯度下降法,特征提取网络部分采用在COCO 数据集上的模型作为预训练模型。
Faster-RCNN-Pro 深度学习检测模型训练的损失函数在20 个轮次的训练周期内,呈现收敛趋势。在训练之初,损失函数快速下降,在迭代到22 000 次后,损失函数收敛放缓,但存在波动;在20 000 次迭代后,学习率下降到十分之一,损失函数也随之下降,波动减少;直至30 000 次迭代,损失函数平稳收敛,识别性能较好,故取第31 000 次迭代后的模型作为最终检测模型。
为验证所提出的3 点改进策略对于Faster-RCNN 算法检测性能的影响,采用消融实验比分析不同改进结构的Faster-RCNN 算法分别在Kaggle DR 数据集上对MAs 的自动检测性能,具体检测结果见表1。由表1 可知,每种网络改进策略均在不同程度上提高了原始Faster-RCNN 的检测性能,具体为:由于MAs 为尺寸微小目标,通过多特征尺度融合可以有效提高对该病灶的检测性能,故Faster-RCNN-I 的F-score 较Baseline(Faster-RCNN)提升了6.82%;通过感兴趣区域齐平池化,先验框中更准确的特征信息优化了模型表现,故Faster-RCNN-II 的F-score 较Baseline(Faster-RCNN)提升了4.68%;采用优化损失函数平衡了难学样本和易学样本对模型提供的梯度,降低了噪声影响,故Faster-RCNN-III 的F-score 较Baseline(Faster-RCNN)提升了2.73%;尤其是3 种改进策略均采用的Faster-RCNN-Pro 的检测性能提升更为明显,其Fscore 较Baseline(Faster-RCNN)提升了9.36%。

表1 不同改进Faster-RCNN 模型在测试集上的性能评估Table 1 Performance evaluation of different improved Faster-RCNN models on the test set
由以上实验结果发现,所提出的对Faster-RCNN 的3 点改进在Kaggle DR 数据集上针对MAs 自动检测,对于网络性能提升是有效的。该网络模型对MAs 的检测效果如图8。由图8 可知,该网络模型可以实现对眼底图像中MAs 的准确检测。
此外,为进一步验证所提出的基于多特征尺度融合的改进Faster-RCNN 对眼底图像中MAs 的自动检测性能,将该方法与文献[8](基于图像处理的方法)、文献[12](基于分类器的方法)、文献[13](采用多筛分卷积神经网络检测MAs)、文献[14](采用YOLO 网络自动检测MAs)、文献[15](利用卷积神经网络检测MAs)、文献[16](采用改进U-Net 网络自动分割MAs)对MAs 的自动检测性能进行了对比,结果如表2。由表2 可知,基于深度学习的方法即文献[13-16]以及所提出的Faster-RCNN-Pro 算法的F-score 均优于基于图像处理方法以及基于分类器的方法。传统算法(基于图像处理的方法以及基于分类器的方法)的F-score低,是因为传统算法易受到参数限制,在眼底图像这样的复杂背景中提取的MAs 病灶候选区易存在较多干扰且无法排除,最终会成为FP,从而导致P值较低进而影响F-score。结合表1、表2 可知,基于深度学习的方法即深度神经网络由于具有更强的拟合性,对于MAs 的自动检测结果更为准确,且两阶段的Faster-RCNN 因为RPN 区域建议网络的存在使得检测性能参数F-score 明显更优,而经过优化后的Faster-RCNN-Pro 的检测精度更是得到了明显提升。但同时也应注意到,深度神经网络也可能存在过拟合现象,从而导致部分MAs 会检测不出,因此文献[13-16]的召回率R会低于传统算法,而Faster-RCNN-Pro 则很好地克服了这个问题。由此可见,所提出的Faster-RCNN-Pro 算法能准确、有效地检测出眼底图像中的MAs,即检测性能更优。

表2 不同算法检测性能对比Table 2 Comparison for detection performance of different algorithms
最后,将所提出的Faster-RCNN-Pro 对于眼底图像中MAs 的自动检测性能与YOLOv5 进行了对比,结果如表3。结合表2、表3 可知,YOLOv5 算法通过使用Focus 与CSPDarknet53 特征提取网络获取多尺度图像特征,相比之前的YOLO 网络进一步消除网格敏感性,优化了小目标特征信息差异,从而提高识别精度[29],但是与Faster-RCNN-Pro 相比,其对于MAs 的检测精度仍逊色不少。因此,就检测精度而言,所提出的Faster-RCNN-Pro 明显更优,能精准检测出眼底图像中的MAs。

表3 与YOLOv5 的检测性能对比Table3 Comparison of detection performance with YOLOv5
4 结论
本文提出了多特征尺度融合的改进Faster-RCNN 算法用以实现眼底图像中MAs 的精准检测。该算法在Faster-RCNN 网络模型的基础上,分别通过采用多特征尺度融合以提高网络对于微小目标特征的利用,感兴趣区域齐平池化以消除池化过程中引入的量化误差,以及优化损失函数有效降低大梯度难学样本与小梯度易学样本间的不平衡问题,从而实现针对眼底图像中MAs 精准检测的Faster-RCNN 网络优化。在以Kaggle DR 数据集为测试对象的基础上,采用消融实验分析验证了所提出的多特征尺度融合的改进Faster-RCNN 算法能够有效提升MAs 的自动检测性能。此外,还将该方法与基于YOLO、基于深度卷积神经网络以及传统方法对MAs 的自动检测性能进行了对比,发现所提出的多特征尺度融合的改进Faster-RCNN 算法在MAs 的自动检测精度方面明显更优。故所提出的多特征尺度融合的改进Faster-RCNN 算法性能较优,能精准检测出眼底图像中的MAs。但改进后的Faster-RCNN-Pro 仍为二阶段目标检测算法,这使其与实时检测之间还存在一定距离,未来可在检测实时性上做进一步深入研究,以期达到更好的检测效果。
