基于改进双向注意力映射的单板图像修复
2023-06-13娄蕴祎张冬妍葛奕麟崔明迪张泽冰
娄蕴祎 张冬妍 葛奕麟 崔明迪 张泽冰


摘要:木材生长加工过程中产生的缺陷会影响产品质量并且浪费大量木材资源,为提高木材利用率与缺陷修复效果,提出一种基于可学习的双向注意力映射(Learnable Bidirectional Attention Maps,LBAM)网络模型的轻量化Lightweight LBAM网络(LL-Net)。该网络使用级联与并行方式的膨胀卷积扩大感受野,修改掩膜更新的激活函数提高修复效果,减少网络深度,在保证效果前提下降低参数量。结果表明,LL-Net与全局与局部判别器(Global and Local Discriminator,GL)方法相比,峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构相似性 (Structural Similarity,SSIM)最高分别提升48.6%和14.2%;与上下文注意力(Contextual Attention,CA)方法相比,PSNR和SSIM最高分别提升23.0%和7.9%;与LBAM方法相比,PSNR和SSIM最高分别提升1.5%和0.6%。并且LL-Net网络参数量为63.58 m,相较于LBAM方法降低了75%。该方法可取得纹理更清晰、语义一致性更好的修复效果,为单板缺陷修复提供指导性意见。
关键词:图像修复;深度学习;单板;双向注意力映射
中图分类号:S781.5; TP391.4文献标识码:A文章编号:1006-8023(2023)02-0132-07
Image Inpainting of Veneer with Improved Learnable
Bidirectional Attention Maps
LOU Yunyi, ZHANG Dongyan*, GE Yilin, CUI Mingdi, ZHANG Zebing
(College of Mechanical and Electrical Engineering, Northeast Forestry University, Harbin 150040, China)
Abstract:Defects in the growth and processing of wood will affect product quality and waste a significant amount of wood. To improve the use rate of wood and defect repair effect, this study proposes a Lightweight LBAM Network (LL-Net) for veneer based on learnable bidirectional attention maps (LBAM). In this network, cascade and parallel dilated convolution were utilized to increase the receptive field, and activation function of mask update was modified to improve the repair effect, reduce the network depth, and reduce the number of parameters on the premise of ensuring the effect. The results showed that compared with Global and Local Discriminator (GL) method, the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity (SSIM) were increased by 48.6% and 14.2%, respectively. Compared with Contextual Attention (CA), the PSNR and SSIM were increased by 23.0% and 7.9%, respectively. Compared with LBAM, the PSNR and SSIM were increased by 1.5% and 0.6%, respectively. The number of LL-Net network parameters was 63.58 m, which was 75% lower than that of LBAM method. This method can achieve clearer texture and better semantic consistency, and provide guidance for veneer defect repair.
Keywords:Image inpainting; deep learning; veneer; learnable bidirectional attention maps
收稿日期:2022-07-14
基金項目:林业公益性行业科研专项(201504307)
第一作者简介:娄蕴祎,硕士研究生。研究方向为林业工程自动化。Email: 2313348732@qq.com
*通信作者:张冬妍,副教授,硕士生导师。研究方向为林业工程。Email: nefuzdhzdy@nefu.edu.cn
引文格式:娄蕴祎,张冬妍,葛奕麟,等. 基于改进双向注意力映射的单板图像修复[J].森林工程,2023,39(2):132-138.
LOU Y Y, ZHANG D Y, GE Y L, et al. Image inpainting of veneer with improved learnable bidirectional attention maps[J]. Forest Engineering,2023,39(2):132-138.
0引言
单板产品由多层单板组成,木材生长与加工过程产生的木节、裂纹、腐烂和虫蛀等缺陷分散在整个单板上[1]。这些缺陷既影响产品的力学性能又影响产品的外观,降低木材利用率,导致大量木材资源被浪费[2]。为提高单板的等级及木材利用率,在单板加工时提倡以挖代拼的挖补工艺[3]。目前缺陷处理的方式如Raute公司的Patchman系统[4],使用机器视觉进行缺陷检测与定位,之后挖去缺陷并用不同纹理的补片掩盖或嵌入缺陷进行修补。国家《普通胶合板外观等技术条件》将单板分3级,其中优等品指外观基本看不出加工缺陷与天然缺陷,若符合优等品的标准可以很好地满足工业上的应用需求[5]。然而,Patchman虽然可以达到一定程度的修补效果,但无法构建自然且美观的单板纹理,且加工后缺陷处明显,单板品质较低。因此,本研究使用图像修复技术以提高单板缺陷修复效果,以期提高单板整张率,提供美观装饰材料,并起到保护天然珍贵树种资源的效果。
基于深度学习的图像修复技术旨在通过计算机自动修复图像中的缺损内容[6],生成图像中原本不存在的事物。Pathak等[7]提出编码-解码结构的上下文编码器(Context Encoder, CE) 模型,利用对抗损失修复图像并打开了将深度学习与图像修复结合的大门,但修复后图像模糊且存在明显的人工痕迹。针对这一问题Iizuka等[8]提出全局与局部判别器(Global and Local Discriminator, GL),全局判别器根据完整图像确保整体一致性,局部判别器根据修复区域确保局部一致性,然而由于模型空间问题对于像素较大的图像无法产生合理结果。针对这些问题,Song等[9]将图像修复过程分解为推理、匹配和翻译3个阶段,使用U-Net网络还原出修复图像,修复速度更快并且修复效果更好。不同于上述分阶段的修复方法,Yan等[10]提出Shift-Net修复网络,通过U-Net将图像特征传送到上采样中进而提升修复效果。之后,Yu等[11]将注意力机制加入到网络中,提出了上下文注意力(Contextual Attention, CA)修复模型,解决修复过程中无法从较远距离获得信息的问题,然而忽略特征之间的连续性导致修复后图像不连贯。针对这一问题,Liu等[12]提出连贯语义注意力机制,有效地解决修复后图像断层的现象。上述方法采用标准卷积对有效像素与损失区域进行无差别处理,受限于处理规则损失,有着一定的局限性。但是单板缺陷是不规则的,因此李月龙等[13]提出部分卷积进行图像修复,将掩膜更新并用于下一卷积层,解决不规则掩膜修复效果差的问题。然而由于部分卷积使用硬掩膜方式,掩膜更新过程是不可学习的,导致修复效果无法满足视觉要求。为了解决这一问题Xie等[14]提出了可学习的双向注意力映射(Learnable Bidirectional Attention Maps, LBAM)模型,在上采样过程中引入反向掩膜,使用U-Net [15]的跳跃链接将下采样中图像与掩膜信息分别与上采样中图像与掩膜信息拼接,使得修复后图像更清晰。尽管LBAM可以初步满足修复需求,但是仍然存在训练速度慢,修复效果不合理等问题。
因此本研究针对LBAM网络参数量大、训练速度慢及修复后纹理间断等问题,提出一种图像修复方法Lightweight LBAM Network(LL-Net)。网络中使用并行与级联的膨胀卷积进行特征融合,解决修复图像內部数据结构损失的问题,并修改掩膜更新的激活函数,提高图像修复效果。在单板图像数据集上与其他3种方法进行比较,本研究方法可以得到纹理更清晰、视觉更可信的修复效果,为单板缺陷修复提供可信度高的模板,能够提高单板产品质量与木材利用率。
1实验与方法
1.1实验数据及环境
研究中使用采集单板图像设备如图1所示,该设备配备了OscarF810CIRF工业相机,相机分辨率为2 048×2 048,传动带的速度约为2 m/s。在拍照过程中,使用具有均匀光的LED灯板照亮单板表面,减少阴影与过度曝光等因素的影响。拍摄得到带有横纹、斜纹、不规则纹理的单板纹理图像10 000张,带有孔洞、裂纹等缺陷的图像100张,将其像素大小裁剪为256×256。先随机选择7 000张图像用作训练集,其余3 000张用作测试集,然后分别通过4种数据扩增方法将训练集扩增至40 000张,测试集扩增至10 000张。扩增方法如图2所示。图2(a)为原始图像;图2(b)以Y轴作为对称轴,对图像进行翻转操作;图2(c)使图像进行旋转;图2(d)对图像进行加噪处理;图2(e)对图像进行随机亮度变换。
1.2研究方法
1.2.1LL-Net
研究方法的图像修复网络LL-Net整体框架如图3所示,分为编码器、特征融合和解码器3个部分。Iin是带有掩膜的木板图像,Iout是修复后木板图像,Min与1-Min是掩膜输入图像。编码器部分,使用VGG[16]网络下采样。中间特征融合部分使用级联与并行的膨胀卷积,用来扩大感受野的同时避免使用过多池化导致图像内部数据结构丢失等问题。解码器部分,由于在上采样过程中会丢失部分语义特征,所以使用U-Net的跳跃链接,将下采样中图像和掩膜的信息与上采样的图像和掩膜分别拼接。在掩膜前向传播的过程中,掩膜随着更新变得越来越小,网络越来越注重修复损失区域,而在反向传播的过程中,非掩膜区域变得越来越小,网络越来越注重提升已修复区域的质量。
1.2.2掩膜激活函数
部分卷积[13]使用的卷积掩膜为
Mc=Mk1/9 。(1)
式中:M为0-1硬掩膜;为卷积算子;k1/9为每个元素为1/9的3×3卷积滤波器。
由于M是硬掩膜,不可自动修改,影响掩膜在网络中的效果,因此本研究先用可学习的卷积滤波器km替换k1/9,然后将掩膜的激活函数修改为
f(Mc)=(ReLU(Mc)) 。(2)
式中,参数设置为0.7。将此激活函数应用于更新掩膜中,提升网络的修复效果。
1.2.3膨胀卷积
标准卷积膨胀率为1,如图4(a)所示,此时这个卷积核的感受野大小为3×3。Yu 等[17]提出膨胀卷积,设置膨胀率提高卷积的感受野,如图4(b)和图4(c)所示,膨胀率分别为2和4,整个卷积核的感受野为7×7和15×15。
本研究在特征融合部分使用级联与并行方式的膨胀卷积,在进行消融实验确定使用如图5所示形式的方案。图5中膨胀系数分别为1、2、4,从上至下的感受野分别为15、7、3、1,最后将4条路线的结果相加得到融合的特征。
1.2.4损失
为了更好地修复图像,本研究使用像素重构损失、感知损失[18]、风格损失[19]和对抗损失[20]训练本网络。
1)像素重构损失
使用Iin表示有掩膜的输入图像,Min表示掩膜区域,Igt表示真实图像,LL-Net输出可以定义为Iout=φ(Iin,Min;θ),θ是需要学习的模型参数,使用l1范数误差作为像素重构损失。
Ll1=‖Iout-Igt‖1。(3)
2)感知损失
为了解决l1损失仅捕捉高级语义,与人类对图像修复质量的感知不一致,引入了感知损失(Lperc)。
Lperc=1N∑Ni=1‖Pi(Igt)-Pi(Iout)‖2。(4)
其中Pi(I)是第i个池化层的特征映射,在本研究方法中使用预训练的VGG-16的1、2、3层。
3)风格损失
为使修复效果的纹理细节更好,本研究采用从VGG-16的池化层中定义的特征图上的风格损失,从每一层特征图构造一个矩阵。假设特征图Pi(I)的大小为Hi×Wi×Ci,风格损失(Lstyle)可以定义为
Lstyle=1N∑Ni=11Ci×CiPi(Igt)(Pi(Igt))T
-Pi(Iout)(Pi(Iout))T2。
(5)
4)对抗损失
对抗损失在图像修复领域被广泛应用,在低水平视觉中用来提升图像修复的视觉质量。为了提高GAN的训练稳定性,Arjovsky等[21]使用wasserstein距離测量生成图像与真实图像的分布差异,Gulrajani等[22]在此基础上引入梯度惩罚在判别器上加强Lipschitz约束。在参考文献[22]基础上本研究将对抗损失表示为
Ladv=minΘmaxDEIgt~Pdata(Igt)D(Igt)-
EIout~Pdata(Iout)D(Iout)+λEI^~PI^[(||I^D(I^)||)2-1]2。(6)
式中:D(·)代表鉴别器;I^是通过线性插值从Igt和Iout中随机抽取的样本;λ在实验中设置为10。
5)总损失
考虑上述所有损失函数,总损失函数设置为
L=λ1Ll1+λ2Ladv+λ3Lperc+λ4Lstyle 。 (7)
式中,λ1,λ2,λ3,λ4为权重参数。根据部分卷积[13]及LBAM [14],将参数设置为λ1=1,λ2=0.1,λ3=0.05,λ4=120,并取得有效结果。
2结果与分析
在数据集上,将提出的LL-Net方法与GL [8]、CA [11]、LBAM [14] 3种方法作对比,验证和评估了LL-Net的图像修复能力。
2.1定性评价
在定性评价中,使用规则掩膜与不规则掩膜分别进行对比,并在具有缺陷的单板图像上验证了对纹理的重建效果。图6(a)是原图像,图6(b)是带有中心掩膜的输入图像,图6(c)—图6(e)是对比方法的修复结果,图6(f)为本方法的修复结果。
由图6可知,本研究比较了不同方法对于中心规则掩膜与不规则掩膜修复的效果。GL修复后图像存在明显阴影;CA修复后会产生图像色差问题并存在纹理间断现象;LBAM修复效果较好但仍然会出现纹理扭曲等现象,有时无法产生合理的结果。然而,本研究方法无论是规则掩膜与不规则掩膜,在色差、纹理连续性和语义一致性等方面均得到合理的结果,同时修复效果最接近于真实图像。研究推测,在降低网络深度情况下,使用膨胀卷积扩大感受野提高特征提取范围可以有效提升效果,并利用空间通道注意力降低干扰特征的影响。这些推测在消融实验中得到证实。
为了验证对单板缺陷图片的重建效果,挑选不同纹理的缺陷图像,修复结果如图7所示,图7(a)为原始图像;图7(b)为遮掩缺陷后的图像;图7(c)为本研究方法得到的修复结果。从图像中可以看到,本研究方法去除缺陷并生成纹理清晰,结构完整,结果合理的图像。这可以证明,本研究方法可以有效地修复单板缺陷图像,为单板缺陷提供真实并客观的修复图像模板并给予指导性意见。
2.2定量评价
根据峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)与结构相似性(Structural Similarity,SSIM)指标评价LL-Net、GL [8]、CA [11]和LBAM [14]4种方法对图像的修复效果。
PSNR基于对应像素间的误差,是使用最广泛的一种客观图像评价指标。给定一个m×n大小的图像I和修复图像K,像素值由B表示,其均方误差MSE(公式中用MSE表示)和PSNR(公式中有PSNR表示)公式如下所示。
MSE=1mn∑m-1i=0∑n-1j=0I(i,j)-K(i,j)2。 (8)
PSNR=10log10((2B-1)2MSE) 。(9)
SSIM是从亮度、对比度和结构3方面评判图像相似性。公式如下所示,其中μx为x的均值;μy为y的均值;σ2x为x的方差;σ2y为y的方差;σxy为x和y的协方差;c1=(k1L)2;c2=(k2L)2;c3=c2/2;k1=0.01;k2=0.03。
l(x,y)=2μxμy+c1μ2x+μ2y+c1c(x,y)=
2σxσy+c2σx2+σy2+c2s(x,y)=σxy+c3σxσy+c3。(10)
在试验中,使用相同的测试集进行测试,掩膜使用占原图像像素10%~20%、20%~30%、30%~40%和40%~50%大小的规则掩膜。对于不同大小掩膜,将4种方法最后5个训练模型分别测试得到的PSNR和SSIM值分别相加取平均数。结果见表2,其中参数值越高代表效果越好。从表2中可以看出LL-Net的PSNR、SSIM值在不同大小掩膜下均高于其他方法,这证明了本研究方法的有效性。
2.3消融实验
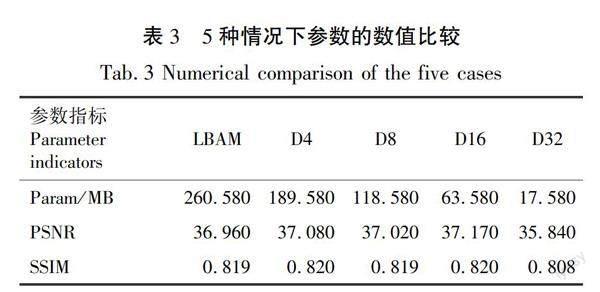
加入膨胀卷积与降低网络深度的效果。使用膨胀卷积替换网络中的普通卷积时,膨胀卷积的感受野要求小于图像的特征尺寸。当膨胀率分别为1、2、4、8时膨胀卷积感受野分别为3、7、15、31。由图8可知,在本研究中,使用这4种情况来替换网络中五角星1,2,3,4的位置。将4种情况分为4组,分别命名为D4、D8、D16、D32。每组都取最后的5个模型分别进行测试,得到对应的PSNR、SSIM值与其网络参数量。将5组PSNR与SSIM值相加取平均数,原方法与这4种情况结果见表3。
通过表3可以发现,D16方法的PSNR、SSIM值最高,同时参数量仅有63.58 m,相对于LBAM参数量减少75.6%。这是由于膨胀卷积增加网络提取特征的范围,使得网络提取更多有效像素,可以提升修复效果。实木单板特征相对并不复杂,因此本研究使用膨胀卷积精简网络使PSNR值与SSIM值相较于原网络有所提升,并且由于降低网络深度导致参数量明显下降。但是D32的网络深度过浅,导致细节特征提取较差,因此参数值相较于原网络明显下降。
3结论
本研究提出一种基于LBAM的单板图像修复方法LL-Net,首先修改激活函数,提升掩膜在网络中的作用并改善修复效果,然后使用级联与并行方式的膨胀卷积扩大特征提取范圍;同时,减少网络深度降低网络参数量,可以更快地训练网络。实验结果表明,在单板图像数据集上,本研究所提出的LL-Net与GL、CA、LABM方法相比可以获得纹理更清晰,更接近于真实的修复结果,为单板缺陷修复提供真实且客观的修复图像模板并为其提供依据。
【参考文献】
[1]WONG R. Green possibilities in a green industrial sector: the lumber industry[J]. Physical Sciences Reviews, 2020, 5(9):1-14.
[2]牟洪波,王世伟,戚大伟,等.基于灰度共生矩阵和模糊BP神经网络的木材缺陷识别[J].森林工程,2017,33(4):40-43,54.
MU H B, WANG S W, QI D W, et al. Wood defects recognition based on gray-level co-occurrence matrix and fuzzy BP neural network[J]. Forest Engineering, 2017, 33(4): 40-43, 54.
[3]王阿川,侯畅,宋宏光,等.基于图像分解的单板节子缺陷图像修补方法研究[J].林业机械与木工设备,2013,41(8):50-54.
WANG A C, HOU C, SONG H G, et al. Study on method for repairing veneer knot defect images based on image decomposition[J]. Forestry Machinery & Woodworking Equipment, 2013, 41(8): 50-54.
[4]王阿川.基于变分PDE的单板缺陷图像检测及修补关键技术研究[D].哈尔滨:东北林业大学,2011.
WANG A C. Research on the key technology of veneer defect image detection and patching based on variational PDE[D]. Harbin: Northeast Forestry University, 2011.
[5]苍圣.基于PDE的旋切单板表面缺陷图像修补方法研究[D].哈尔滨:东北林业大学,2011.
CANG S. Based on PDE sub-section defect image veneer repair[D]. Harbin: Northeast Forestry University, 2011.
[6]李月龙,高云,闫家良,等.基于深度神经网络的图像缺损修复方法综述[J].计算机学报,2021,44(11):2295-2316.
LI Y L, GAO Y, YAN J L, et al. A review of image defect repair methods based on deep neural network [J]. Chinese Journal of Computers, 2021, 44(11): 2295-2316.
[7]PATHAK D, KRAHENBUHL P, DONAHUE J, et al. Context encoders: feature learning by inpainting[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). June 27-30, 2016, Las Vegas, NV, USA. IEEE, 2016: 2536-2544.
[8]IIZUKA S, SIMO-SERRA E, ISHIKAWA H. Globally and locally consistent image completion[J]. ACM Transactions on Graphics, 2017, 36(4): 1-14.
[9]SONG Y H, YANG C, LIN Z, et al. Contextual-based image inpainting: infer, match, and translate[M]//Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 3-18.
[10]YAN Z Y, LI X M, LI M, et al. Shift-net: image inpainting via deep feature rearrangement[M]//Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 3-19.
[11]YU J H, LIN Z, YANG J M, et al. Generative image inpainting with contextual attention[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. June 18-23, 2018, Salt Lake City, UT, USA. IEEE, 2018: 5505-5514.
[12]LIU H Y, JIANG B, XIAO Y, et al. Coherent semantic attention for image inpainting[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). October 27-November 2, 2019, Seoul, Korea (South). IEEE, 2020: 4169-4178.
[13]李月龍, 高云, 闫家良, 等. 基于深度神经网络的图像缺损修复方法综述 [J]. 计算机学报, 2021, 44(11): 2295-2316.
LI Y L, GAO Y, YAN J L, et al. A review of image defect repair methods based on deep neural network [J]. Chinese Journal of Computers, 2021, 44(11): 2295-2316.
[14]XIE C H, LIU S H, LI C, et al. Image inpainting with learnable bidirectional attention maps[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). October 27-November 2, 2019, Seoul, Korea (South). IEEE, 2020: 8857-8866.
[15]RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[M]//Lecture Notes in Computer Science. Cham: Springer International Publishing, 2015: 234-241.
[16]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. 2014: arXiv: 1409.1556. https://arxiv.org/abs/1409.1556
[17]YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[EB/OL]. 2015: arXiv: 1511.07122. https://arxiv.org/abs/1511.07122
[18]JOHNSON J, ALAHI A, LI F F. Perceptual losses for real-time style transfer and super-resolution[M]//Computer Vision-ECCV 2016. Cham: Springer International Publishing, 2016: 694-711.
[19]GATYS L A, ECKER A S, BETHGE M. Image style transfer using convolutional neural networks[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). June 27-30, 2016, Las Vegas, NV, USA. IEEE, 2016: 2414-2423.
[20]CRESWELL A, WHITE T, DUMOULIN V, et al. Generative adversarial networks: an overview[J]. IEEE Signal Processing Magazine, 2018, 35(1): 53-65.
[21]ARJOVSKY M, CHINTALA S, BOTTOU L. Wasserstein generative adversarial networks[C]//Proceedings of the 34th International Conference on Machine Learning-Volume 70. August 6-11, 2017, Sydney, NSW, Australia. New York: ACM, 2017: 214-223.
[22]GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of Wasserstein GANs[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. December 4-9, 2017, Long Beach, California, USA. New York: ACM, 2017: 5769-5779.
