面向GPU 集群的动态资源调度方法
2023-06-07傅懋钟胡海洋李忠金
傅懋钟 胡海洋 李忠金,2
1 (杭州电子科技大学计算机学院 杭州 310018)
2 (浙江省北大信息技术高等研究院智能软件技术与应用研究中心 杭州 311215)
深度学习(deep learning,DL)技术已被广泛应用于众多业务场景,研发人员根据业务场景的目标特征构建深度神经网络(deep neural network,DNN)模型,并在特定数据集上反复训练,直至模型精度维持在一个预期的水平,从而达到在业务场景中对目标行为进行预测的目的.随着业务场景的复杂程度提高,需要结构更加复杂且层数更多的DNN 模型来获得更高的精度.同时,数据集的规模也在不断地增长,导致训练一个DNN 模型需要很长时间.因此,通过构建分布式深度学习(distributed deep learning,DDL)任务,在GPU 集群上对DNN 模型进行训练,从而加快训练的过程[1],受到了工业界和学术界的广泛关注.主流的机器学习框架,如PyTorch[2],TensorFlow[3],都对DDL 提供了完整的技术支持.
不同于大型公司或企业所部署的高性能计算中心[4-5]这类高度专业化的平台,考虑到GPU 设备的成本和组建难度,众多中小型企业、研究所和高校通常会采购GPU 服务器组建一个小规模的GPU 集群来处理多个用户的DDL 任务,如图1 所示.GPU 集群的计算资源有限,且各GPU 服务器的算力、内部通信方式等处于异构性质,如何对其进行高效的资源调度具有重要意义.
Fig.1 Application scenarios of GPU cluster图1 GPU 集群的应用场景
现有的集群调度器,例如Yarn[6],Mesos[7],Kubernetes[8],在对DDL 任务调度时表现出资源分配不当、运行效率不高的问题,从而无法满足用户需求.例如,在某实验室使用Yarn 进行资源管理的GPU 集群[9]中,同一机架和跨机架分别采用InfiniBand 和以太网对GPU 设备之间进行互联,由于GPU 设备间的带宽差异,不同资源布局方式会导致DNN 模型的训练效率不同,该集群上的历史调度日志表明该集群的平均资源利用率仅有50%.此外,对于集群用户而言,任务截止时间是衡量用户满意度的关键指标,根据文献[10]中的研究得知,在大多数情况下,用户可以接受在截止时间之前完成的任务,而当任务结束时间超过截止时间时,用户对于集群的性能满意度会大幅度下降.
基于以上分析,本文提出一种面向GPU 集群的动态资源调度(dynamic resource scheduling,DRS)方法,以解决异构GPU 集群环境下具有截止时间需求的多DNN 调度问题.DRS 考虑了带宽差异和资源布局对任务训练时间的影响,并结合截止时间需求指导资源方案的生成,其目标在于优化截止时间保证率和集群节点的资源利用率.
本文的主要贡献包括4 个方面:
1)基于Ring-AllReduce 通信架构下的DNN 模型迭代特征和GPU 设备间的带宽差异,构建了资源-时间模型,以计算不同资源方案下的任务运行时间.该模型能够较为充分地体现分布式DNN 训练的特征以及异构带宽所带来的影响.
2)根据资源数量、任务运行时间和任务截止时间构建了资源-性能模型,利用该模型筛选多个满足截止时间需求的资源方案并得到最优方案,以提高资源利用效率.
3)结合资源-时间模型、资源-性能模型以及资源布局,设计了DRS 算法,进行DDL 任务的资源方案决策.再基于最近截止时间原则选择调度任务,进行实际资源分配,以最大化截止时间保证率并提高集群节点的资源利用率.此外,还引入了迁移机制减少动态调度过程中出现的资源碎片.
4)在一个包含4 个节点,每个节点有4 个NVIDIA GeForce RTX 2080 Ti 的GPU 集群上,使用到达时间服从泊松分布的DDL 任务队列,并对DRS 进行了对比实验.结果表明,相较于对比算法, DRS 的截止时间保证率提升了39.53%,资源利用率达到了91.27%.
1 相关工作
随着DL 技术的发展和大规模应用,许多专家和学者对GPU 集群资源调度上的优化指标进行了研究,现有相关工作主要从减少任务完成时间和提升集群性能指标这2 方面进行研究.
为减少任务的完成时间,文献[11]提出了基于GPU 集群的任务调度算法Optimus,该算法通过预测训练过程中的模型收敛性,建立性能模型来估计模型的训练速度,并利用贪心策略分配计算资源,最小化任务完成时间.然而,该工作仅考虑任务自身的完成时间,无法保证用户需求的截止时间.文献[12]构建了一个任务性能模型,以量化分布式训练中不同并行方式下的模型分区形式和对系统可伸缩性的影响,确定任务的最优资源方案,使得任务的完成时间最小化.然而,该工作采用静态配置的方式完成资源分配,不能根据集群负载和任务运行情况动态地调整资源分配方案.文献[13]提出了基于强化学习技术的任务调度器Chic,通过集群调度日志不断优化学习模型和决策任务的最优资源方案.然而,当集群规模扩展时需要收集新的日志并耗费额外时间重新训练,导致该方法不能很好地扩展.文献[11-13]的工作均以参数服务器(parameter server,PS)[14]方式作为分布式训练的通信架构,本文则基于Ring-AllReduce[15]通信架构进行研究,它能够减少GPU 之间的通信开销.
文献[16]提出了集群调度框架Gandiva,借助透明迁移和分时作业,使多个DDL 任务在不同时刻复用GPU 设备,从而提高资源利用率.然而,该工作以提升资源利用率作为优化目标,而不是最大化截止时间保证率.文献[17]提出了基于云PS 架构的资源配置框架Cynthia,通过资源消耗的性能分析模型预测任务的完成时间,从而提供最优成本收益下的资源分配方案.然而,该工作关注的是资源成本需求,而不是截止时间需求.文献[18]则设计了面向服务质量感知的动态调度框架GENIE,它借助负载预测估计任务的完成时间,得到预期运行时间内的最优资源方案,最大化集群服务质量.然而,该工作限制资源分配为对称形式并遵循整合约束[19]来获得PS架构的最优训练效率[11],导致集群中存在空闲的GPU设备无法立即使用,造成任务排队延迟和资源利用率不足[20].
现有相关工作能够较为有效地解决GPU 集群的资源调度问题,但其中尝试结合资源分配、资源布局和截止时间需求的研究工作较少,对于异构环境下最大化截止时间保证率仍存在一定的局限性.本文提出的DRS 方法,基于Ring-AllReduce 通信架构,将资源配置、资源布局和截止时间需求相结合,能够最大化截止时间保证率并提高集群节点的资源利用率.
2 系统模型
本节主要介绍异构GPU 集群场景下的动态资源调度模型、基础模型、资源-时间模型、截止时间模型以及资源-性能模型,以及对目标函数进行了描述.
2.1 动态资源调度模型
本文提出的DRS 框架如图2 所示.用户提交含有截止时间需求的DDL 任务到达GPU 集群时,会被放置到一个等待队列中.调度器在感知等待队列有新的任务加入或者集群上有任务运行结束时,便执行调度算法,选择DDL 任务至GPU 集群运行.在此过程中,首先利用时间模型获取任务在不同资源方案下的运行时间;其次利用性能模型指导DDL 任务的最优资源方案生成;然后基于最近截止时间原则选择调度任务;最后进行资源分配确定资源方案的物理资源位置,生成含有节点序号和GPU 数量的运行方案.借助机器学习框架API 在GPU 集群服务器上启动任务运行脚本,完成资源调度过程.并引入迁移机制减少调度过程中出现的资源碎片.
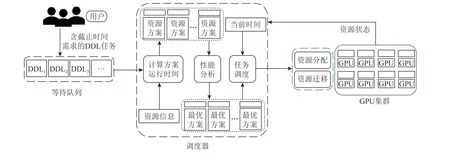
Fig.2 DRS framwork图2 DRS 框架
2.2 基础模型
对于一个GPU 集群而言,需要提供自身所包含的节点数量和每个节点上的空闲GPU 数量等信息,以供调度算法进行决策.本文使用R={Nodei(s,cfree)|1 ≤i≤Nnode}来表示集群的资源列表,其中,Nnode是集群的节点总数,Nodei(s,cfree)表示节点对象,s和cfree分别表示节点对象的序号以及空闲GPU 数量.
当任务被提交到集群时,任务本身应包含DNN模型训练的所有必需信息.本文将一个任务对象表示为t=〈Pmodel,Pdataset〉,其中Pmodel和Pdataset分别表示任务对象所携带的模型和数据集属性.具体来说,Pmodel包含了模型名称、模型结构和模型参数量Nparam等信息;Pdataset包含了数据集名称、数据集大小Sdataset、批次大小Sbatch和迭代回合Nepoch等信息.
DDL 任务的一个资源配置方案则使用Rt={Nodei(s,cused)|1 ≤i≤Nnode}来表示,其中,cused表示任务在序号为s的 节点上所使用的GPU 数量.
2.3 资源-时间模型
在分布式深度学习场景下,模型训练通常采用分布式数据并行[21]的方式来完成,如图3 所示.分布式数据并行首先通过在多个GPU 设备上装载完整的DNN 模型副本;然后将数据集均分为多个子数据集并分配到各个GPU 设备上,并保证每个GPU 设备上所持有的数据集各不相同;最后每个GPU 设备独立地对DNN 模型副本进行迭代训练,并在每次更新自身DNN 模型参数之前与其他设备借助网络通信交换梯度参数,使用平均后的梯度参数对自身DNN模型权重进行更新.由于增加了DNN 模型对于数据集的吞吐率,因而实现了DNN 模型训练加速的目的.Ring-AllReduce 通信架构能够有效减少参数同步阶段所需要的通信时间,目前已成为主流机器学习框架中分布式训练模块的默认选择.该架构将参与训练的所有GPU 在逻辑上以环形的方式相互连接,每个设备在环上都有各自相邻的其他设备,参数同步时将自身参数发送给右邻居设备,同时接收从左邻居设备发送过来的参数,如图4 所示.同一节点上的GPU设备借助PCIe(peripheral component interconnect express)和QPI(quick path interconnect)进行通信,节点和节点之间则借助InfiniBand 进行通信,其中虚线部分便是Ring-AllReduc 通信架构在逻辑上所组织的环形结构.后续的时间、性能模型和对比实验中的DNN 模型训练过程都将基于Ring-AllReduce 架构进行.
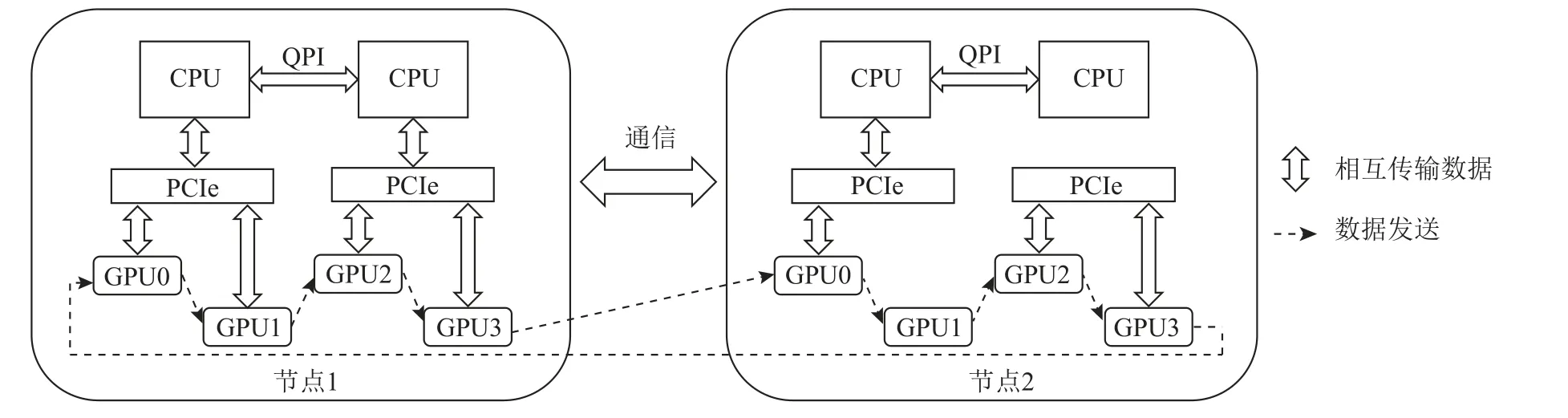
Fig.4 Ring-AllReduce communication architecture图4 Ring-AllReduce 通信架构
采用分布式数据并行进行模型训练的DDL 任务的实际运行时间主要由2 部分构成:第1 部分是在单个GPU 设备上的计算时间;第2 部分是参数同步阶段所花费的通信时间.本文将DDL 任务在某个资源方案下的实际运行时间Trun表示为:
其中Tstep是模型训练一个批次大小的数据集所花费的时间,Nstep是模型在一个迭代回合中可输入的一个批次大小的数据集个数.随着任务在集群上的运行时间的增加,Nepoch会逐渐减少,直至为0,此时DNN模型训练结束.
Tstep由单个GPU 设备上的计算时间Tcal和设备间的通信时间Tcomm所组成,其计算公式为:
Nstep会随着资源方案所包含的GPU 总数不同而发生变化,数量越多,则Nstep会相应地减少.Nstep,Sdataset,Sbatch和GPU 总数NGPU在分布式数据并行训练过程中的关系为:
其中NGPU由资源方案上每个节点的cused累加得到,由于Sdataset和Sbatch保持不变,因此NGPU的增加会使得Nstep减少.
计算时间Tcal和模型计算量以及GPU 设备的物理环境有关,通过在真实环境下对模型进行少量迭代来获得真实的Tcal值.通过将模型放置在单个GPU设备上进行若干批次的迭代,并记录对应的运行时间,由于不涉及多设备通信,因此该运行时间仅包含Tcal.将单个GPU 设备上的计算时间Tcal表示为:
其中是若干次迭代的运行时间,是相应的迭代次数.在计算任务实际运行时间Trun时,对于深度学习这类长时间运行的任务来说,若干次迭代的时间可以被忽略不计.
如果不存在通信时间,那么任务的运行时间Trun和资源方案所包含的GPU 总数NGPU将为反比关系,即随着NGPU上升,Trun将会成比例下降.而存在通信时间时,则会导致运行效率的下降.由于GPU 设备可能被部署在集群的多个节点上,因而设备间可能涉及跨节点通信.在本文中,根据文献[15]中的理论,将Ring-AllReduce 通信架构下的通信时间Tcomm表示为:
其中B是设备之间的带宽速度,如果资源方案所包含的GPU 设备都处于同一个节点上,则B就是节点内GPU 设备之间的带宽,如果包含的GPU 设备跨多个节点,则B就是节点间的网络带宽.
2.4 截止时间模型
本文设用户对于任务的截止时间需求由任务到达时间、任务优先级以及任务最大运行时间所组成,其中最大运行时间是任务仅在单个GPU 设备上的运行时间.由于任务结束时间和任务到达集群后的排队时间、集群空闲资源情况以及所使用的资源调度算法有关,对于GPU 集群的用户而言,在提交DDL任务时,通过指定任务优先级来表示任务的紧急程度比预估一个合理的截止时间要来得容易.为了简化该问题,本文根据文献[22]中的研究,定义若干任务优先级,将优先级转换为任务的期望运行时间Texp,其计算公式表示为:
其中 α对应任务优先级,α值越小说明优先级越高,而则是任务在单个GPU 设备上的运行时间.
设任务的到达时间和运行开始时间分别为Tarr和Tstart,则任务的截止时间Tdl和运行结束时间Tend可分别表示为式(7)和式(8):
当任务的截止时间Tdl和运行结束时间Tend满足式(9)时,说明任务运行结束时满足用户的截止时间需求.
2.5 资源-性能模型
在分布式深度学习过程中,存在着带宽敏感性[20],即2 个NGPU相同的资源方案,会由于GPU 设备的布局方式不同而造成任务运行时间上的不同,这是由于设备间的带宽差异所造成的.当资源方案所持有的GPU 设备都位于同一节点上时,其带宽速度为GPU设备之间的直连带宽;而当资源方案所持有的GPU设备位于不同节点上时,其带宽速度则为节点和节点之间的网络带宽.由式(5)可知,在NGPU和Nparam不变的情况下,Tcomm随着B的减少而增加,而当设备间的带宽性能不足以支撑分布式训练时,就会出现多机分布式训练的运行时间比单机训练的运行时间要来得长的情况.将式(2)(3)带入到式(1)中,并要求多机训练的运行时间比单机训练的运行时间要来得短,则可以得到不等式:
其中不等式号左边部分和右边部分分别表示模型在多机和单机上训练一个迭代回合的时间,化简式(10)可得
故当模型在进行多机分布式训练时,Tcomm,NGPU,Tcal只有符合式(11)才能达到模型训练加速的目的.
为了更好地展示不同资源方案以及带宽差异对任务性能的影响.在包含4 个节点,其中每个节点包含4 个NVIDIA GeForce RTX 2 080 Ti 的异构带宽GPU集群上测量了多个DNN 模型在不同GPU 数量下的迭代回合时间.节点内设备借助PCIe 和QPI 进行互连,其平均带宽速度为10 GBps;节点间设备借助InfiniBand进行互连,其带宽速度为6 GBps.参与测量的模型信息如表1 所示,模型所采用的数据集为CIFAR-100[29],批次大小统一为16,测量结果如图5 所示.

Table 1 Deep Neural Network Model Information表1 深度神经网络模型信息
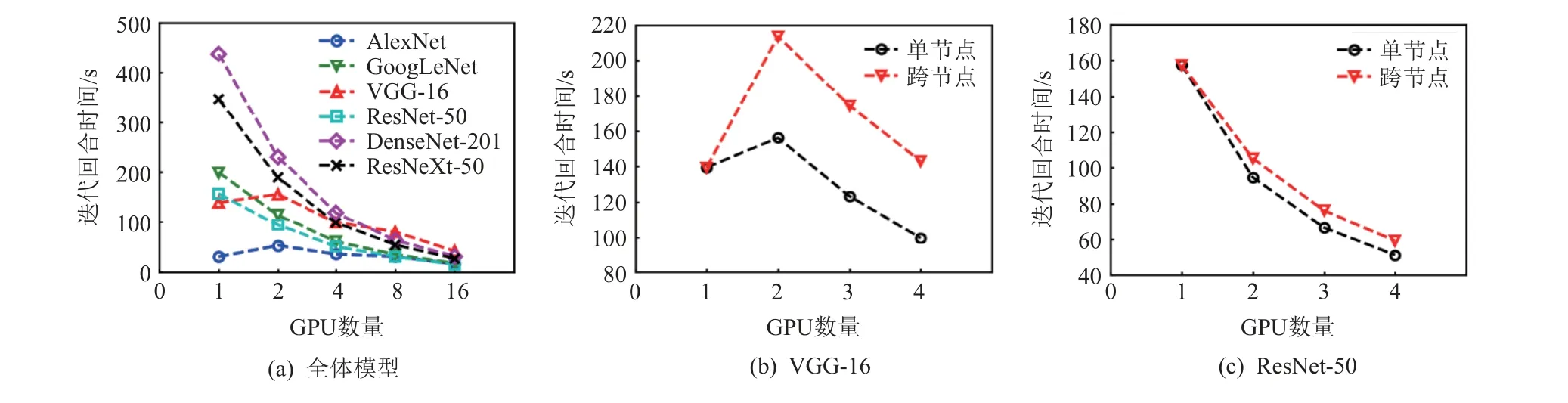
Fig.5 Epoch time of the DNN model under different GPU numbers图5 DNN 模型在不同GPU 数量下的迭代回合时间
如图5(a)所示,在异构GPU 集群环境下,DNN模型的迭代回合时间总体上是随着GPU 数量的增加而减少.其中,VGG-16 在GPU 数量为2 以及AlexNet在GPU 数量为2 和4 时,其迭代回合时间反而比GPU数量为1 时的迭代回合时间还要长.主要原因是DNN模型属于参数量较多的一类模型,其通信时间比起参数量较少的模型要长,在迭代一个批次的数据时,大部分时间都花费在参数同步阶段.故当带宽性能存在瓶颈时,对于DNN 模型而言,增加少量GPU 设备所带来的吞吐率上升并不足以抵消参数同步阶段的通信开销,从而导致多机训练无法达到训练加速的目的.由于可能出现此类资源方案的运行时间仍能满足截止时间需求的情况,本文方法将采用式(11)对可用资源方案进行筛选,保留可进行有效分布式训练的资源方案,减少出现资源浪费的现象.
图5(b)(c)分别展示了在上述环境下,VGG-16和ResNet-50 在单节点设备和跨节点设备上的迭代回合时间.可以看出VGG-16 这类参数量多的模型对于带宽的敏感性较强,在单节点上可以得到训练加速的效果,而在相同GPU 数量的跨节点方案上由于没有完全抵消通信开销而无法得到训练加速的效果.而ResNet-50 这类模型无论在单节点还是跨节点场景下都可以得到训练加速的效果,只是在跨节点时由于带宽性能较低,因而导致迭代回合时间略慢于单节点.故在异构带宽GPU 集群中,调度算法在进行资源分配时应考虑不同模型在单节点和跨节点资源布局方式上的带宽差异,过于追求减少当前任务的完成时间而选择单节点资源方案时,可能会造成后续到达任务在需要单节点资源方案时的排队延迟和资源利用率的下降.
基于上述分析,为了衡量任务在不同资源方案下的性能,并在满足截止时间需求的多个资源方案中选择运行效率最高的资源方案,充分发挥资源性能.本文将资源方案的性能公式定义为:
式(12)表明,如果一个资源方案使用的资源数目越少且能得到的任务运行结束时间越短,则发挥的资源性能越高.
2.6 目标函数
本文方法的目标是在一个资源有限且带宽异构的GPU 集群上,对于一个到达时间服从泊松分布的DDL 任务队列trace={t1,t2,…,tM},在集群资源限制和任务截止时间需求上进行权衡,确定每一个DDL任务的执行顺序以及最优资源方案,最大化截止时间保证率.本文将保证率Rtrace定义为:
其中Nsati和M分别表示任务队列中满足截止时间需求的任务数量和队列中的任务总数.
故将本文方法的目标函数表示为:
3 本文方法
本节介绍了资源方案决策、实际资源分配、资源迁移机制以及DRS 算法.DRS 算法将遍历等待队列并执行资源方案决策得到每个任务的最优资源方案,再基于最近截止时间原则选择调度任务,并执行实际资源分配.在集群运行过程中,引入资源迁移机制减少动态调度过程中资源碎片所带来的影响.本节将分别对资源方案决策、实际资源分配和资源迁移机制进行介绍,并展示DRS 算法的伪代码和复杂度分析.
3.1 资源方案决策
在资源方案决策部分,首先会为等待队列中的每个任务基于集群空闲资源和资源布局生成可用资源方案列表,然后根据2.5 节中的性能模型并结合集群节点负载情况,确定每个任务的最优资源方案.资源方案决策的步骤有4 个:
1)获取资源列表R,并设cfree>0的资源节点数量为n,资源节点cfree的最大值为max(cfree)及其累加和为sum(cfree),最后初始化一个单节点资源方案列表ls和一个跨节点资源方案列表lm.
2)生成cused从1~max(cfree)的资源方案Rt添加到ls中,如果n>1,则再生成cused从1~sum(cfree)的资源方案Rt添加到lm中.根据式(1)和式(8)计算ls和lm中Rt的Trun和Tend,并根据式(11)过滤部分资源方案Rt.
3)根据式(12)得到ls中PRt≥0且PRt最大时的资源方案Rt,设为单节点预期方案;以及ls中Tend>Tdl且Tend最小的资源方案Rt,设为单节点非预期方案.按照相同的思路从lm中得到跨节点预期方案和跨节点非预期方案.注意其中和可能不存在.
4)如果存在且集群存在0 <cfree<NGPU的资源节点,说明当前任务存在跨节点资源方案可以利用局部资源并在Tdl内结束运行,此时设最优资源方案=.如果条件不成立但存在,则设=;如果仍不存在,说明集群当前空闲资源无法令当前任务在Tdl内结束运行,则先后对和以相同的思路选择其一作为当前任务的.
3.2 实际资源分配
1)获取资源列表R并按照节点的cfree升序排序.
3.3 资源迁移机制
由于无法预知将来提交到集群的任务情况,动态调度方法在根据当前资源做出资源方案抉择时就可能出现仅有的跨节点资源被当前任务所使用,在一段时间后和其他任务运行结束后释放的资源形成资源碎片的场景.结合2.5 节可知,资源碎片会造成单个资源节点的高性能无法被单个模型充分利用.
DDL 任务的特性允许中途停止模型训练过程并在之后任意时间点重启,比如利用PyTorch 框架可以通过参数设置设定模型权重文件的保存时机,该权重文件会保留目前已经训练好的参数信息和迭代次数,之后可以基于该权重文件在先前已经训练的基础上继续后续的训练过程.基于DDL 任务的这项特性,本文通过引入资源迁移机制来减少资源碎片所带来的影响,尽可能发挥单个节点的性能优势.资源迁移的过程如图6(a)(b)所示,其中阴影部分表示GPU 设备正处于运行状态,空白部分则处于空闲状态,虚线框部分为某个运行任务的实际资源配置.

Fig.6 Resource migration图6 资源迁移
在每次执行任务调度之前,DRS 算法将分析已运行任务情况,决定是否进行资源迁移过程.将资源列表中处于运行状态但运行设备数量不超过自身总设备数量一半的节点定义为可迁移节点Nodem(s,cfree),当Nodem(s,cfree)数量超过Nnode的一半时,暂停全体运行任务并执行资源迁移过程.其步骤有2 个:
1)初始化任务列表ls和lm.遍历运行任务队列Qrun,将原处于单节点运行的任务t添加到ls中,将原处于跨节点运行的任务t添加到lm中.
2)将ls和lm中的任务t根据的NGPU降序排序.首先遍历ls,对其中的任务t执行3.2 节中的实际资源分配过程,然后遍历lm,对其中的任务t同样执行3.2 节中的实际资源分配过程.
3.4 调度算法流程
每当有新任务到达且GPU 集群存在空闲资源或有任务运行结束时,调度器会根据调度算法选择新的任务运行.算法接收等待任务队列Qwait、资源列表R和当前时间Tcurr作为输入参数,其中Tcurr以单位时间增加,当DDL 任务的到达时间Tarr=Tcurr时,将任务添加到队列Qwait中,此时会根据式(7)预先计算任务的截止时间Tdl.本文将DRS 算法的具体步骤定义为:1)根据集群资源的负载情况,尝试执行3.3 节的资源迁移过程.2)遍历等待队列Qwait,对任务t执行3.1 节的资源方案决策得到t的最优资源方案.3)初始化预期任务队列Qexp和非预期任务队列,如果任务的运行结束时间Tend和截止时间Tdl满足式(9),则将任务t添加到队列Qexp中,反之则添加到队列中.将队列Qexp中的任务t根据Tdl-Tend的值升序排序,此时排在队头的任务t在资源方案下的Tend越接近Tdl.将队列中的任务t根据Tend的值升序排序,排在队头的任务t在资源方案下的Tend越接近Tdl.注意队列Qexp可能为空.4)如果队列Qexp不为空,则选择排头任务t作为调度任务t*,否则选择队列中的排头任务t作为调度任务t*,并对t*执行3.2 节的实际资源分配过程.
本文将DRS 算法的伪代码表示为:
3.5 复杂度分析
在本文所提出的DRS 算法伪代码流程中,资源方案决策部分的最坏时间复杂度为O(Nnode×Gnode),即所有节点皆处于空闲状态时,最多可以得到Gnode个单节点资源方案和Nnode×Gnode个跨节点资源方案.而实际资源分配部分的最坏时间复杂度为O(Nnode),即所有节点皆处于非满载状态时,可以对Nnode个资源节点进行资源分配过程.资源迁移机制部分的最坏时间复杂度为O(|Qrun|×Nnode),即对|Qrun|个运行任务进行Nnode个资源节点的分配过程.在任务决策部分,其最坏时间复杂度为O(|Qwait|×Nnode×Gnode),即对|Qwait|个等待任务最多执行Nnode×Gnode个跨节点资源方案下的最优资源方案选择过程.
执行包含资源迁移过程的DRS 算法时间复杂度为O(nN)+O(mNG)=O(N(n+mG)),其中n,m,N,G分别表示运行任务数量、等待任务数量、节点数量和节点上的最大可用GPU 设备数量.
在随机生成到达时间Tarr符合泊松分布的任务队列时,本文设定集群默认的任务接收时间范围为0~24 h.默认的任务抵达率λ=4,即平均每小时有4个任务到达集群.将任务队列的任务优先级0.5,1,1.5 的默认比例分别设置为10%,30%,60%.
除DRS 外,本文还引入了常见的调度策略和具有代表性的GPU 集群资源调度算法进行对比.
1)EDF(earliest deadline first)[36].从等待队列中选择截止时间最小的任务并使用整体GPU 资源进行资源分配.
2)FIFO(first in first out).从等待任务队列中选择到达时间最小的任务并使用整体GPU 资源进行资源分配.
3)Themis[37].将GPU 资源根据完成时间公平性分配给多个等待任务并将任务一次性调度至集群运行,尽可能保证任务之间具有相近的完成时间.
4)NoRM(no resource migration).为了验证DRS引入迁移机制的有效性,将DRS 中的迁移机制部分移除之后,再与DRS 比较各种性能指标.
本文方法的目标在于最大化截止时间保证率Rtrace,因此将Rtrace作为主要性能指标.除此之外,任务平均等待时间Twait和任务平均完成时间Tcomp同样是重要的性能指标[38].后续实验将从Rtrace,Twait,Tcomp这3 个指标对各个调度算法进行分析比较,Rtrace依据式(13)进行计算,Twait和Tcomp则各自根据Twait=(Tstart-Tarr)/M和Tcomp=(Tend-Tarr)/M计算得到,其中M是任务队列中的任务总数.
4 对比实验
本节首先在异构带宽GPU 集群上对DRS 和多种调度算法进行对比;研究了任务抵达率、节点数量、紧急任务数量、任务接收时间和带宽性能对于各个调度算法的性能影响;使用截止时间保证率、平均等待时间和平均完成时间作为性能指标.然后还对比了各个算法在运行过程中集群总体节点的资源利用率.最后分别介绍实验准备和各个对比实验,并对实验结果进行分析.
4.1 实验准备
本文的GPU 集群包含4 个节点,每个节点有4 个NVIDIA GeForce RTX 2 080 Ti,节点内的GPU 通过PCIe和QPI 进行互连,其平均带宽速度为10 GBps;节点间设备借助InfiniBand 进行互连,其带宽速度为6 GBps,因此GPU 之间的通信具有异构性质.GPU 服务器运行Ubuntu 18.04 操作系统和PyTorch 1.7.1 框架,其分布式训练API 默认采用分布式数据并行的方式进行模型训练,并采用NCCL(NVIDIA collective communication library)通信库[30]实现Ring-AllReduce 通信架构.
为了提升DDL 任务的多样性,在DNN 模型方面除了采用表1 当中的图像分类模型,还引入了用于动作识别场景下的TSN[31], R(2+1)D[32], TSM[33], Slow-Only[34]等模型,图像分类模型依旧采用CIFAR-100数据集,而动作识别模型则采用UCF-101[35]数据集.DDL 任务可携带的工作负载的具体信息如表2 所示,其中计算时间是模型在上述集群单个GPU 设备上训练一个迭代回合的时间.
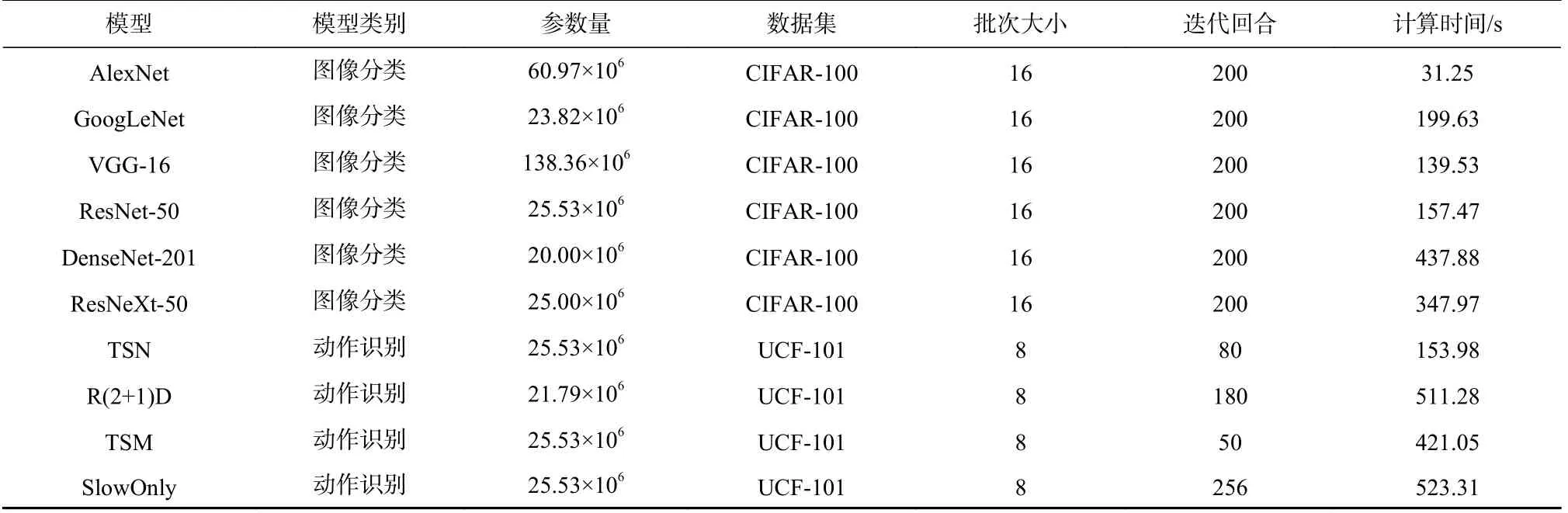
Table 2 Workloads表2 工作负载
4.2 任务抵达率
本节研究了任务抵达率 λ对于各个调度算法性能的影响.在保持任务队列其他参数不变和控制 λ=2,4,6,8,10 变化的基础上,进行了对比实验,实验结果如图7 所示.

Fig.7 Algorithm performance at different arrival rates图7 在不同抵达率下的算法性能
由图7(a)可知,由于资源有限,所有算法的Rtrace随着 λ的增大而减少,其中DRS 和NoRM 的表现要优于其他算法.EDF 由于只关心任务的截止时间需求,没有考虑实际资源配置对于任务运行时间的影响,会导致在任务数量较多时,运行时间超过截止时间的等待任务比未超过截止时间的任务优先得到了调度.FIFO 仅考虑了任务的次序而忽视了截止时间需求,当任务队列中预先到达的都是一些长时间任务时,则后续到达的任务在短时间内都无法得到资源,导致超过截止时间的任务都无法运行.Themis 仅考虑了资源配置对任务完成时间公平性的影响,导致在调度过程中,资源优先倾向后续到达的任务,先前到达的任务则无法得到足够的资源在截止时间内结束运行.本文所设计的DRS 算法考虑了任务的截止时间需求和资源方案性能,实现了截止时间保证率和资源利用之间的权衡,在不同 λ下的Rtrace相较于EDF,FIFO,Themis,NoRM 能够分别提升39.53%,41.41%,45.49%,3.11%的性能.DRS 通过引入迁移机制减少了动态调度过程中资源碎片带来的影响,性能上要略优于NoRM,证明了引入资源迁移机制的有效性.
由图7(b),图7(c)可知,任务的Twait和Tcomp普遍随着 λ的增大而增大,由于资源的有限性和任务的随机性,因此在部分 λ值之间,Twait和Tcomp会有下降的趋势,其中DRS 的性能表现最好.DRS 基于资源方案性能为任务分配合适的设备数量,减少资源浪费,将其余资源保留给后续到达的任务,使得后续任务能够被及时响应,同时也为任务基于现有资源确定了运行效率最高的资源方案,故在Twait和Tcomp指标表现上能够优于其他算法.
4.3 节点数量
本节研究了节点数量Nnode对于各个调度算法性能的影响.在保持任务队列其他参数不变和控制Nnode=2,3,4 变化的基础上,进行了对比实验,实验结果如图8 所示.

Fig.8 Algorithm performance under different numbers of node图8 在不同节点数量下的算法性能
由图8 可知,随着Nnode的增加,各个算法在Rtrace,Twait,Tcomp指标上都得到了优化,原因在于节点数量的增加使得各个算法可以为更多的任务执行资源调度.EDF,FIFO,Themis 在不同集群规模下依旧基于任务自身指标确定任务执行顺序,而DRS 能够在不同集群规模下基于集群资源情况和整体任务截止时间需求动态调整等待任务的执行顺序,以最大化Rtrace为前提选择被调度任务,故其性能表现最佳.另外,图8(a)中,DRS 和NoRM 的性能几乎一致,原因在于资源数量对于λ=4的任务队列来说远远不够,且队列中的任务运行时间皆较长,故在集群运行过程中,资源节点几乎都处于满载状态,资源碎片出现的频率较低,减少了DRS 执行资源迁移的次数.
4.4 紧急任务数量比例
本节研究了紧急任务数量比例对于各个调度算法性能的影响.在保持任务队列其他参数不变和控制任务优先级α=0.5时,进行了对比实验,实验结果如图9 所示.

Fig.9 Algorithm performance under different numbers of urgent task图9 在不同紧急任务数量下的算法性能
由图9(a)可知,随着α=0.5的任务数量比例增加,DRS 和NoRM 在Rtrace指标上都有所下降,原因在于部分任务的截止时间缩短,需要更多的资源来满足这部分任务的截止时间需求,但是受到集群资源的限制,无法满足所有任务的截止时间需求,对比其他算法DRS表现依旧出色.由图9(b)(c)可知,FIFO 和Themis 在不同优先级比例下的Twait和Tcomp完全不变,原因在于二者并没有考虑任务的截止时间需求,因此紧急任务比例的变化没有影响到算法的调度决策.而EDF虽基于截止时间需求决策调度顺序,但是没有结合资源配置进行考虑,依旧使用全体资源作为任务的资源配置,因此在Twait和Tcomp指标上仅有细微的变化.
4.5 任务接收时间
本节研究了任务接收时间对于各个调度算法性能的影响.在保持任务队列其他参数不变和控制任务接收时间上限在12,24,48,72 h 变化的基础上,进行了对比实验,实验结果如图10 所示.
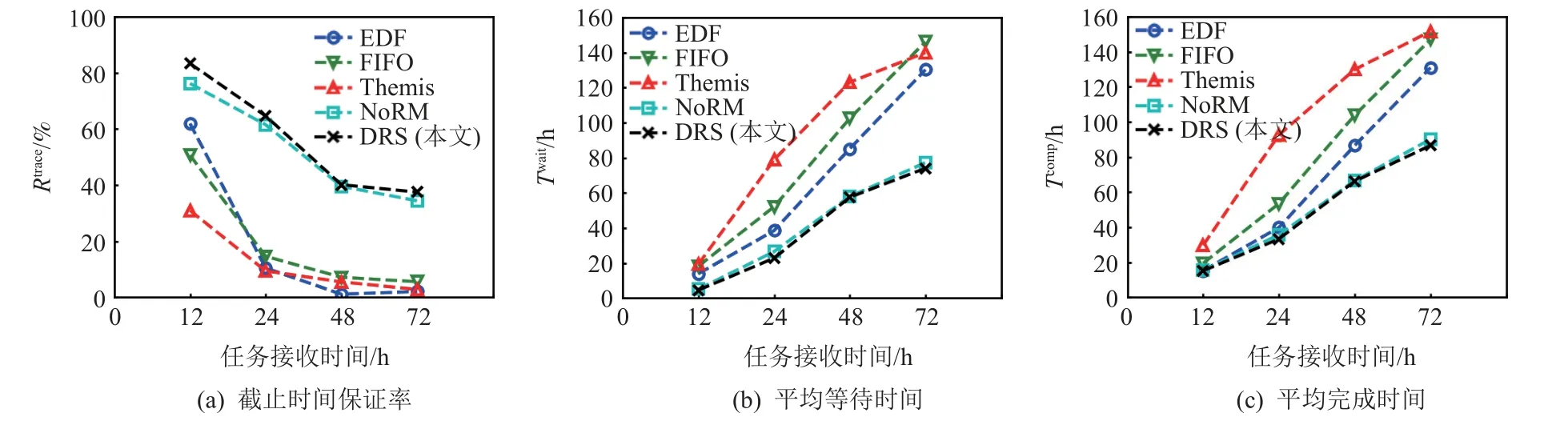
Fig.10 Algorithm performance at different reception time图10 在不同接收时间下的算法性能
由图10 可知,随着任务接收时间的增加,各个算法在Rtrace,Twait,Tcomp指标上性能逐渐下降,这是因为对于本文集群而言,长时间接收深度学习这类运行时间普遍较长的任务,由于资源的有限性,会导致等待队列中出现任务堆积的现象而导致性能下降.可以注意到当任务接收时间范围在[0,12]时,EDF 和FIFO 在Rtrace指标上都有不错的性能表现,原因在于此时的资源数量对于任务队列来说,足够完成大多数任务的调度安排,并且使用整体资源能够获得最短的运行时间,故在Tcomp指标上二者性能和DRS 相近,但是随着等待任务的堆积,没有合理进行资源配置的EDF 和FIFO 的总体性能不如DRS,DRS 在长时间任务接收中会根据等待任务情况和集群负载动态调整任务的执行顺序,故DRS 对集群长时间接收任务的场景适应性最好.
4.6 带宽性能
本节研究带宽性能对于各个调度算法性能的影响.保持任务队列其他参数不变,并控制工作负载中为AlexNet,VGG-16 这类模型占比由表2 的1/5 提升为1/3 生成限定任务队列.将限定任务队列和随机任务队列进行了对比实验,实验结果如图11 所示.

Fig.11 Algorithm performance under different task queues图11 在不同任务队列下的算法性能
由图11(a)可知,EDF 和FIFO 在限定任务队列上性能表现不如随机任务队列.通过2.5 节可以了解到对于AlexNet,VGG-16 这类参数量大但计算时间少的模型来说,在此时的集群环境下,GPU 数量的大幅提升对于这类模型的训练效率来说没有其他模型来得明显.EDF 考虑了截止时间,对于限定任务队列来说,1/3 比例任务的截止时间都较小,故EDF 提前了这部分任务的执行顺序,但也导致了其他任务的延后训练.FIFO 没有改变任务的执行顺序,但由于任务性能提升不明显,故这部分任务在到达集群后没有及时得到调度,即使分配了全体资源也无法在截止时间内结束训练.Themis,NoRM,DRS 在限定任务队列的性能表现上都比随机任务队列要好,其原因在于限定任务属于短时间任务,分配适当数量的资源并不会延长过多的运行时间,因此能尽快释放资源到其他任务以满足截止时间需求.由图11(b)(c)可知,Themis,NoRM,DRS 在限定任务队列上的性能都比随机任务队列优化明显,也是由于同样的原因.
DRS 在资源方案选择上会过滤无效的资源方案,并考虑单节点和跨节点之间的带宽差异,优先选择能够利用局部资源运行的跨节点资源方案,为后续需要单节点完整性能的任务提供条件,特别是AlexNet和VGG-16 这类工作负载,因此DRS 在限定任务队列上的综合表现最好.
4.7 资源利用率
本节对比了在各个调度算法的决策下集群总体节点的资源利用率,即单位时间内处于运行状态的设备数量和总数量的比值.节点的资源利用率越高,表明动态调度过程中出现的资源碎片越少,节点性能发挥越充分.实验结果如图12 所示,本文记录了FIFO,Themis,NoRM,DRS 在默认任务队列下的性能表现.
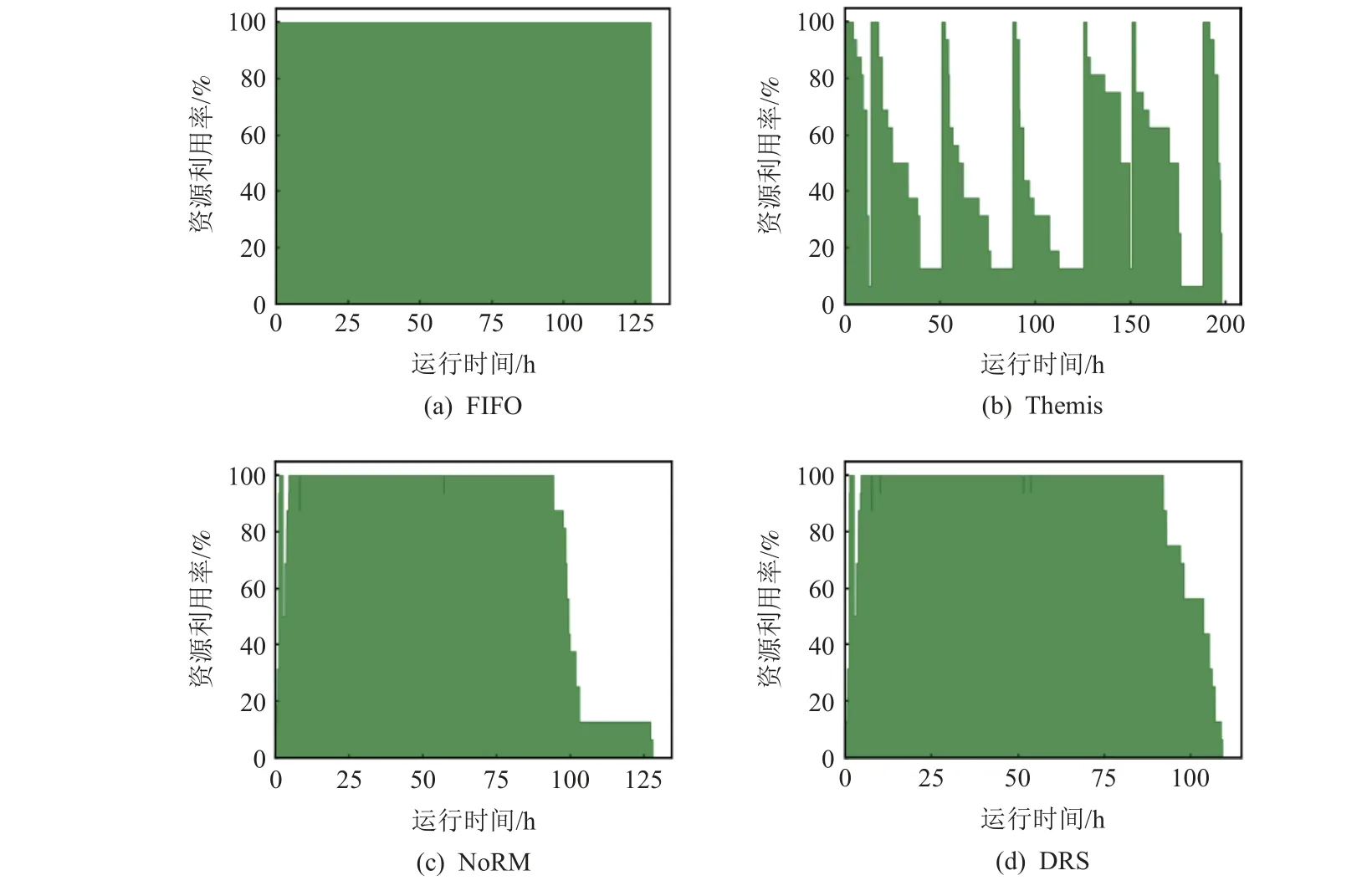
Fig.12 Resource utilization rates in cluster nodes图12 集群节点的资源利用率
由图12(a)可知,FIFO 几乎全程保持了最高的资源利用率,原因在于FIFO 每次调度时都为任务分配全体资源,并且任务数量能够保证每次调度时都存在等待任务,此结果和原因对于EDF 也同样适用.由图12(b)可知,Themis 出现了间歇性的最高资源利用率,原因在于资源配置对于不同工作负载的性能影响不会完全相同,当一次性调度多个作业时,即使追求完成时间公平性,仍会出现部分任务的运行时间要远大于其他任务的时间,导致较早结束运行的任务所释放的资源出现了空闲现象.而由图12(c)(d)可知,NoRM 和DRS 仅在集群运行过程的后半段出现了资源利用率逐渐下降的情况,这是因为后续到达集群的任务较少时,仍选择性能最高的资源方案,没有完全利用剩余的空闲资源,而DRS 因为额外引入了资源迁移机制,因此在集群运行的后半段过程中下降趋势相比NoRM 更加平缓,二者在默认任务队列上的总体节点资源利用率分别达到了79.13%和91.27%.
5 结束语
本文针对异构带宽GPU 集群上对于具有截止时间需求的DDL 任务的资源调度问题,提出了一种面向GPU 集群的动态资源调度方法DRS.通过资源-时间模型得到不同资源方案下的任务运行时间,然后通过资源-性能模型对资源方案进行性能分析并选择最优的资源方案,将资源分配、资源布局和截止时间需求相结合,最大化集群的截止时间保证率.另外,还引入了迁移机制来减少动态调度过程中产生的资源碎片.在实际的GPU 集群上进行的对比实验证明DRS 具有可行性和有效性.在未来工作中,我们将对DRS 进一步优化,考虑集群设备的能耗问题以及设备故障后的容错问题,尝试结合集群调度日志研究资源伸缩的可能性.
作者贡献声明:傅懋钟实施实验方案和论文撰写;胡海洋负责论文的修改;李忠金负责论文方案的提出和论文修改.
