基于CNN-LSTM的工控协议同源攻击检测方法
2023-06-07竹瑞博任晓刚王建华
禹 宁 竹瑞博 狄 婷 任晓刚 王建华
1(国网山西省电力公司信息通信分公司 山西 太原 030021) 2(山西联拓科技有限公司 山西 太原 030021) 3(太原理工大学信息与计算机学院 山西 太原 030024)
0 引 言
工业控制系统(ICS)是国家关键基础设施的重要组成部分,在国家安全、社会民生、经济发展和政府事务中的基础性作用不断凸显,逐步成为保障社会稳定和持续运转的重要支撑。随着国家智能制造、物联网、“互联网+”等各种战略规划不断发展和深入,工业控制系统逐步实现了信息数字化、网络化和共享化。然而,网络环境所带来的不安全因素对关键基础设施的安全构成极大威胁。从2010年众所周知的“震网病毒”事件,2011年“Duqu病毒”和2012年的“火焰病毒”到2015年波兰航空公司黑客攻击事件,每年都有几百起针对ICS的攻击事件,给相关国家造成了不可估量的损失,这充分显示了国家基础关键设施安全问题的现实迫切性,保障工控系统安全也成为新的网络形势下的关键问题。
对恶意攻击溯源可以有效对工控系统做出主动的防护,传统的攻击者溯源方式为IP溯源技术。这种技术为单一溯源,通过设置并更改专门的物理设备,使用概率包标记法[1]、日志信息溯源法[2]等进行IP溯源。然而,由于攻击者使用代理的普遍性,导致传统的IP溯源技术效率和精度都不高。除此之外,在工控系统中,有组织的大型攻击行为往往都不是一个攻击者来进行攻击,这就使得对恶意攻击者的溯源无法满足当前的需要。例如,Shodan[3]作为一个公开的设备搜索引擎,可以识别具有可路由IP地址的设备,包括计算机、打印机、网络摄像头和工业控制设备等。Shodan7×24小时都在运行多个序列式的扫描代码,从而每月收集大约5亿台联网设备和服务的信息。攻击者通过Shodan可以发现暴露在互联网上的工业控制设备以及与该设备相关的IP地址、开放的服务和存在的漏洞等信息,进而发动攻击,对工控系统造成严重破坏。除Shodan外还有许多私密、私有的扫描引擎或攻击组织,意在非法地探测ICS系统设备的信息,试图对ICS安全造成威胁。因此,我们把具有相同或相似攻击行为的恶意IP定义为同一组织,同源攻击检测就是为了找到互联网中存在的恶意攻击组织,以此来提高工控系统安全性。
为此,本文提出基于CNN-LSTM的工控协议同源攻击检测方法,实现攻击者溯源。主要是通过长时间部署工控协议蜜罐,来收集互联网上的一些针对工控协议的攻击事件,使用深度学习的CNN和LSTM神经网络分析攻击者各项特征,找到具有相同或相似攻击特征的攻击源或攻击组织,以达到检测同源攻击的目的。
本文的主要贡献有两点:
1) 基于蜜罐数据流,提出基于卷积神经网络(Convolutional Neural Network,CNN)-长短期记忆(Long Short-Term Memory,LSTM)的工控协议同源攻击检测方法,相比较于传统方法[4-5]和基于无监督的聚类方法[6]等,本文方法具有更好的性能表现。
2) 通过基于注意力机制(Attention Mechanism)的模型优化方法,对模型进行无监督训练和有监督调整,使模型分类的准确率大幅提高,并找到了除Shodan外的多个攻击组织。
1 相关工作
概率包标记法和日志溯源法是传统的IP溯源方法,Luo等[7]提出了一种单一封包溯源的方法,在包的报头中使用32位空间来记录攻击者的攻击路径,并使用生存时间字段来减少溯源的误报率。Snoeren等[8]提出了一种基于报文摘要(Hash)的IP追踪溯源方法,相比较于传统的日志溯源法,该方法节约日志空间。设备的修改以及日志格式的不统一使得这种传统的IP溯源技术成本开销高、误报率高、实际可操作性不强,需要对网络基础设备进行一些修改、改变,使得这种方法开销很大。在工业控制系统领域,这种传统的方法在PLC等工业控制系统设备上进行应用更是不安全且难以实现。因此,在近些年的研究中,ICS安全的研究人员通常使用较为成熟的蜜罐法来确定针对ICS设备的恶意IP攻击源。Li等[6]部署了分布式蜜罐系统来收集威胁数据库,并根据三种不同的工控协议蜜罐数据,对攻击方法、攻击模式和攻击源分析,并提出一种聚类算法,进行对攻击组织追溯。Xiao等[9]通过对S7comm协议中的功能码特征和攻击数据中的各项参数,构建了一个名为ICSTrance的恶意IP溯源模型,使用短序列概率方法将攻击行为特征转换为向量,并对该向量进行Partial Seeded K-Means算法模式聚类,追溯攻击组织。然而,他们并没有用任何标识数据进行验证,无法解释结果的好坏。
如今,深度学习在广泛的应用中取得了巨大的成功,包括在自然语言处理、计算机视觉等领域[10]。卷积神经网络(CNN)是一种前馈神经网络,对于大型图像处理有出色表现,近些年也成功地应用于网络安全领域[11]。Kang等[12]已有研究表明,在入侵检测领域,通过引入深度学习模型来训练分类器,可以提高入侵或攻击检测方法的准确性和效率。而长短期记忆网络是一种神经循环网络,对于处理时间序列中的一些数据流或事件具有一定的优势。CNN是一种具有特征提取功能的深度神经网络[13],利用多个过滤器对输入数据进行逐层卷积、池化操作,自动提取数据流中的数据特征。然而,CNN不能学习序列的相关性[14]。Zhang等[15]提出字符级卷积神经网络,将字符的序列转换成大小固定的向量序列。我们依据这些灵感,将预处理后原始数据流使用CNN进行特征提取。
长短期记忆(LSTM)网络是一种特殊的循环神经网络(Recurrent Neural Network,RNN),而RNN是一种时间递归网络,具体来说是同一个神经网络结构在时间轴上循环多次得到的结果。相比于其他神经网络,RNN更加擅长处理序列数据。而LSTM作为一种特殊的RNN,其增加了输入门、遗忘门、输出门等门控机制,控制记忆过程,解决了长序列训练中的梯度消失与梯度爆炸问题,因此,在长序列中有比普通RNN更好的表现。王红等[16]发现LSTM模型能够充分利用整个文本序列的信息,包括词之间的相互关系信息,并将该种信息用于对每个词的处理。由于当前社会的网络攻击行为通常都是具有多个复杂步骤和多条攻击序列的攻击行为[17],我们充分依据现实情况,考虑攻击数据流之间的上下文关系,使用LSTM来处理序列标注问题。因此,本文加入LSTM对序列化的攻击流进行分析和分类,以此进行工控同源攻击检测。
2 相关知识
2.1 工控Modbus协议
Modbus协议由Modicon公司于1979年为其生产的PLC设计的一种通信协议,该协议广泛应用于电力、水利、能源等领域的监控系统中,由于其开放性和透明性,成为了业界的主流通信协议[18]。由于TCP/IP协议在数据链路层已经保障了数据传递的正确性,因此Modbus TCP相对于Modbus协议来说,减少了LRC校验域。Modbus TCP的报文格式如图1所示。

图1 Modbus TCP协议报文格式
2.2 蜜罐技术
蜜罐作为一种新兴的攻击诱骗技术,经过近些年的发展,已经在互联网安全威胁监测方向上得到了较为广泛的应用[19]。Glastopf项目在github上发布了第一个开源工控蜜罐框架Conpot[20],该系统是工业控制系统服务器端的低交互的蜜罐技术,该框架实现了协议栈上的请求-应答交互,整体框架设计易于配置、部署、修改和扩展。使用者可以通过内置提供的各种通用工控协议,模拟构建基础设施,构建所需的虚拟系统。
通常情况下,攻击者利用漏洞的速度要比供应商创建和推出补丁的速度快得多,如果仅仅依靠传统的防御方式,例如入侵检测系统和动态防火墙,并不能对检测出新的和正在出现的攻击模式提供全面的覆盖[21]。蜜罐是诱饵计算机资源,其价值在于被探测、攻击或危害[22],蜜罐技术不是一种解决方法,相反它是一个工具,如何使用这个工具依赖于你期望它能取得何种结果。因此,我们提出应用工控蜜罐技术对工控攻击者行为进行分析。
3 方法设计
3.1 数据流特征提取
网络流量中包含许多冗余和与溯源无关的属性,这些属性会降低模型准确率,而且会增加基于CNN-LSTM模型的计算负载和计算复杂度。依据Moore等[23]提出的248个流量统计特征,本文依据工控协议Modbus TCP特有的数据报文特点,来进行基于流量统计特征的特征选择,最终选择了15种工控流量特征。选取特征及特征描述如表1所示,前6个为Modbus TCP特有特征,其余为流量传统特征。

表1 流量层特征描述
3.2 基于CNN-LSTM的模型构建
根据2.1节介绍的Modbus TCP数据报文格式,依据数据流中的关键字段,转化为可供CNN进行特征学习使用的多维向量。然后对设置的CNN卷积神经网络进行卷积和最大值池化操作,随后将CNN网络输出的特征向量作为LSTM网络的输入层,并加入注意力机制计算权值,使用反向传播算法(Back Propagation algorithm,BP)对权值进行迭代寻优,以此找到最优特征向量,最后进行数据流分类和模型评估。
具体方法是:
1) 由于数据包的二进制形式,若关键字段长为m/8字节,将数据嵌入一个m维空间中,数据总量为n,则生成一个m×n的位矩阵。
2) 根据数据特性,我们使用一维卷积层进行卷积计算。其中,卷积核个数为k=3,过滤器大小为m×q,若步幅为2,那么该层输出矩阵大小为3×(n/2)。
3) 在池化层,我们使用的最大值池化法(Max Pooling)来降低特征值的维度,并生成对应的特征图。若窗口值为2,那么输出特征图大小为3×(n/4)。
4) 将CNN特征图结果输入至构建好的LSTM网络中,此时输入为5维特征向量c0。
5) 通过在LSTM网络中进行无监督学习训练和有监督的微调,得到数据特征l0,再使用基于注意力机制的模型优化方法,对全连接层特征向量使用BP算法进行权值迭代优化。
6) 通过Softmax激活函数对数据流特征向量实现进行归一化,计算概率进行分类并使用交叉熵损失函数来进行模型评估。图2显示了本文方法的总体结构和流程。
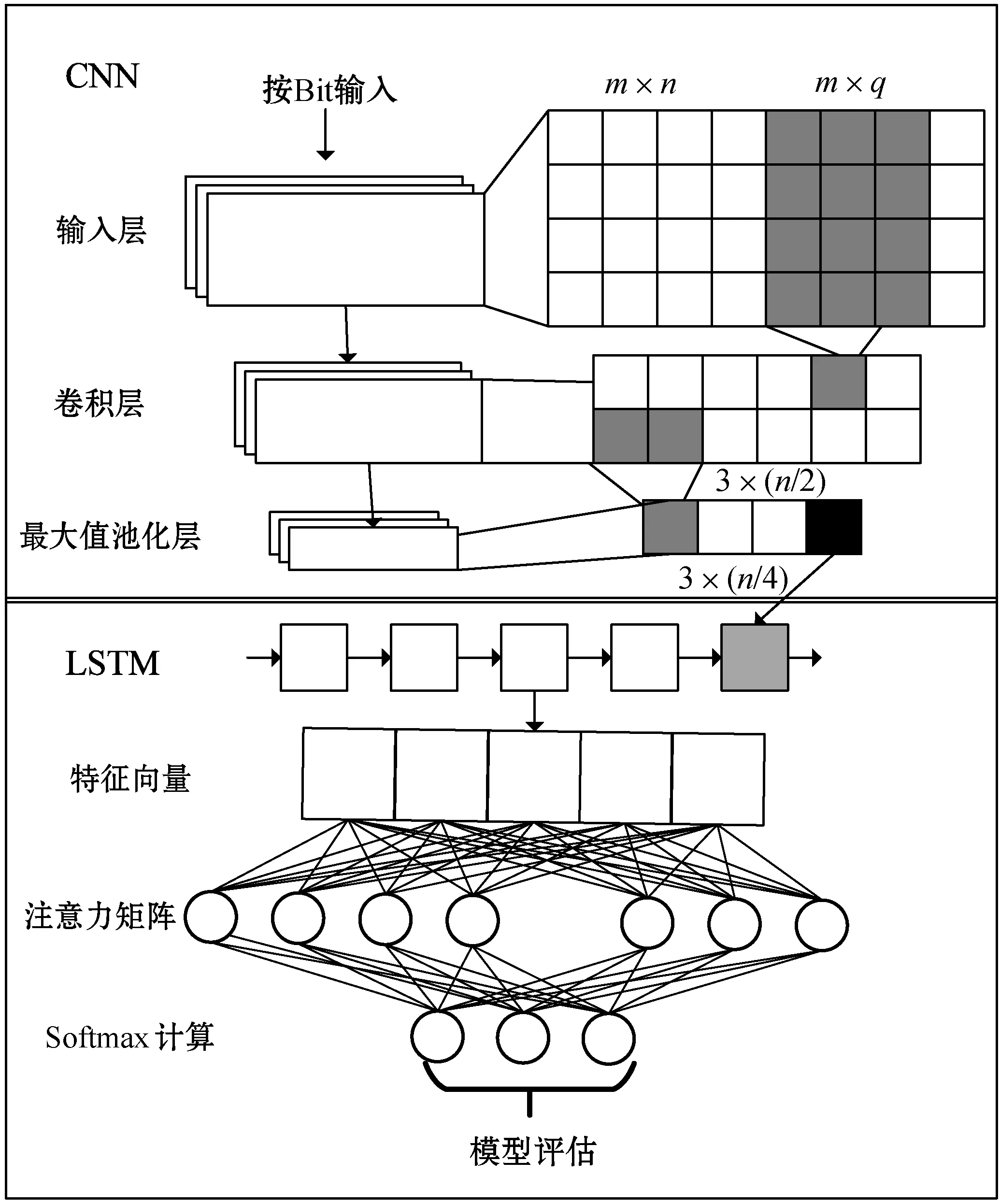
图2 总体结构和流程
3.3 基于注意力机制的模型优化方法
注意力机制(Attention Mechanism)是将有限的注意力资源聚集到具有大量数据包中部分关键的信息维度上,从而避免将资源平均到各个信息维度上所造成的资源浪费和精度降低。从本质上看,注意力机制就是对输入内容的加权并求和。计算公式如式(1)所示。
Z=tanh(WtY+bt)
α=softmax(wTZ)
R=YαT
(1)
式中:Wt代表t时刻的权值矩阵;Y代表数据特征l0所组成的矩阵;bt则为有监督微调下的偏差值;α为注意力向量;w代表迭代寻优的权值矩阵;R代表基于注意力机制的数据流表达。在注意力机制基础下,我们选择BP算法来对权值矩阵进行迭代寻优,使模型特征向量的偏差值达到最小。BP算法包含激励传播和权值更新两个阶段,第一个阶段通过将训练输入网络来获得激励,再通过反向输入对应的目标来得到隐层和输出层的误差。第二个阶段通过式(2)来进行权值更新。
wn=w0-δ(l0w0-bn)
w=(w1,w2,…,wn)T
(2)
式中:w0表示初始权重;δ为梯度的修正比例;bn为第n个偏置项。
根据我们提出的基于CNN-LSTM神经网络模型通过一系列训练学习调整得到了特征向量值等,为了解决流量分类的问题,我们通过Softmax激活函数来计算概率,计算公式如式(3)所示。
(3)
由于模型参数以及向量预测高度复杂等多重因素的影响,LSTM神经网络无法做到准确的预测。我们计算了真实值与估计值的偏差,并以交叉熵损失来评估模型的输出,交叉熵的值越小,实际与期望差距越小。交叉熵的计算公式如式(4)所示。
(4)
式中:概率分布p(xi)为期望输出;q(xi)为实际输出。我们通过迭代注意力向量和注意力矩阵来降低交叉熵损失。
4 实 验
为了测试模型的性能,通常的方法是将一个标准的标记数据集分成两部分,一部分训练网络模型,另一部分用于测试其准确性。据我们所知,很少有公共工控蜜罐数据集来对攻击组织、攻击事件进行标定,例如Shodan组织对某水处理厂设备的扫描序列、攻击组织对某电厂基础设备的攻击事件等。因此,我们花费超过十二个月的时间来进行工控蜜罐数据收集,以此来进行对模型的实验评估和同源攻击分析。
4.1 数据收集
我们通过部署分布式工控蜜罐,并在不同国家的虚拟专用服务器(Virtual Private Servers,VPS)上部署了16个分布式的蜜罐节点,VPS部署国家包括中国、以色列、巴西、美国、英国、南非、德国和加拿大等,收集了专有的工控蜜罐数据集,蜜罐以Conpot[20]框架为基础进行开发,它们可以在预先定义好的响应机制下进行响应请求,并设置了蜜罐数据捕捉模块,捕获与攻击者的所有交互数据流。为了使蜜罐更具欺骗性,我们根据反蜜罐识别的一些措施,更改了Conpot蜜罐框架的一些自定义属性和字段,改变硬编码特征,以达到欺骗攻击者的目的。此外,每个蜜罐集成了开源认证发布-订阅协议(Hpfeeds),将捕获的数据传输到数据中心Mongodb数据库中。工控蜜罐构造和部署如图3所示。
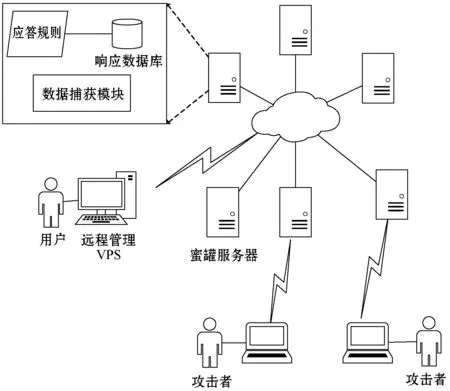
图3 蜜罐构造和部署
基于CNN-LSTM的工控协议同源攻击分析主要是依靠网络数据流进行分析,因此,本文方法对于所有的工控协议具有一定的通用性。蜜罐数据总量达17 315条Modbus TCP数据包,每月收集数量如图4所示。

图4 蜜罐Modbus TCP收集数据量
4.2 实验设置
蜜罐环境中,通常认为所有的流量均为攻击者的恶意流量。由于一些国家法律等原因,具有资质的物联网设备服务商、设备扫描引擎等企业会公开所拥有的设备扫描IP节点,这就使得我们可以对其中一部分数据进行标记。具体地,我们通过反查DNS的方式,对所有蜜罐攻击源中的Shodan、Censys[24]和Plcscan[25]节点进行统计,得到一系列有标识的数据用于调整模型。以Modbus根据反查DNS的结果,Shodan、Censys,Plcscan等组织的ip数量分别为:27、16、18。而数据流中,这三个组织的攻击事件数量分别为3 579、1 854和2 325。
无监督的学习和有监督的微调[26]消除了学习时人为标记的瓶颈,增加了原始数据的计算能力和可用性。因此,我们首先使用数据流特征以及基于CNN-LSTM的模型进行无监督的学习和训练。其次,根据模型优化策略,我们使用BP算法,根据最优交叉熵值的变化进行注意力权值迭代,以此来达到对模型有监督的微调。最后,由于蜜罐数据集的特殊性,并没有完全的标识数据可供训练和验证,相比于完全的无监督学习,本文方法可以最大程度地保障基于CNN-LSTM的分类模型的性能。
在实验分类结果验证方面,有标签数据进行十折交叉验证;无法反查DNS信息的攻击源通过比对公开的恶意IP库-IBM X-Force Exchange[27]进行攻击组织对比验证。IBM X-Force Exchange作为公开的情报分析库可以找到在近5年内,某一IP的活动情况,包括其何时被识别为扫描IP、何时自动运行木马、是否运行恶意软件。这样的验证方式不能全面地考察所有恶意IP的攻击组织情况,但是这是现有数据下最好的验证方式。
4.3 实验结果
通过对预处理的数据流字段嵌入基于CNN-LSTM的模型中进行一系列处理,我们基于Softmax激活函数计算概率进行流量分类,相比较于基于无参的贝叶斯模型聚类[6]、基于TTL存活时间特征的攻击组织检测[4]、基于位置信息的传统分析方法[5]和基于Partial Seeded的K-Means聚类方法[9],本文方法具有更高的精度和F值(F1 Score)。实验结果对比如图5所示。此时,本文的准确率为93.7%,召回率为90.5%;而基于TTL特性方法的准确率为75.4%,召回率为61.3%;基于无参贝叶斯模型方法准确率为82.9%,召回率为87.1%;基于Partial Seeded的K-Means模型准确率为91%,召回率为79.3%,这一模型是除本文方法外最好的;基于物理信息的准确率为75%,召回率为64.7%。综上显示,基于CNN-LSTM的工控协议同源攻击检测方法对于工控蜜罐数据集,具有最好的性能表现。

图5 各模型实验结果对比
对本文模型来说,更多的迭代次数意味着时间消耗的增加,图6显示了迭代次数和交叉熵趋势、模型F值之间的关系,可以看出迭代次数越高,模型性能越好。然而在迭代42次之后,两条曲线变化趋势放缓,我们认为这一迭代次数是综合时间复杂度和模型性能来看最适合的。
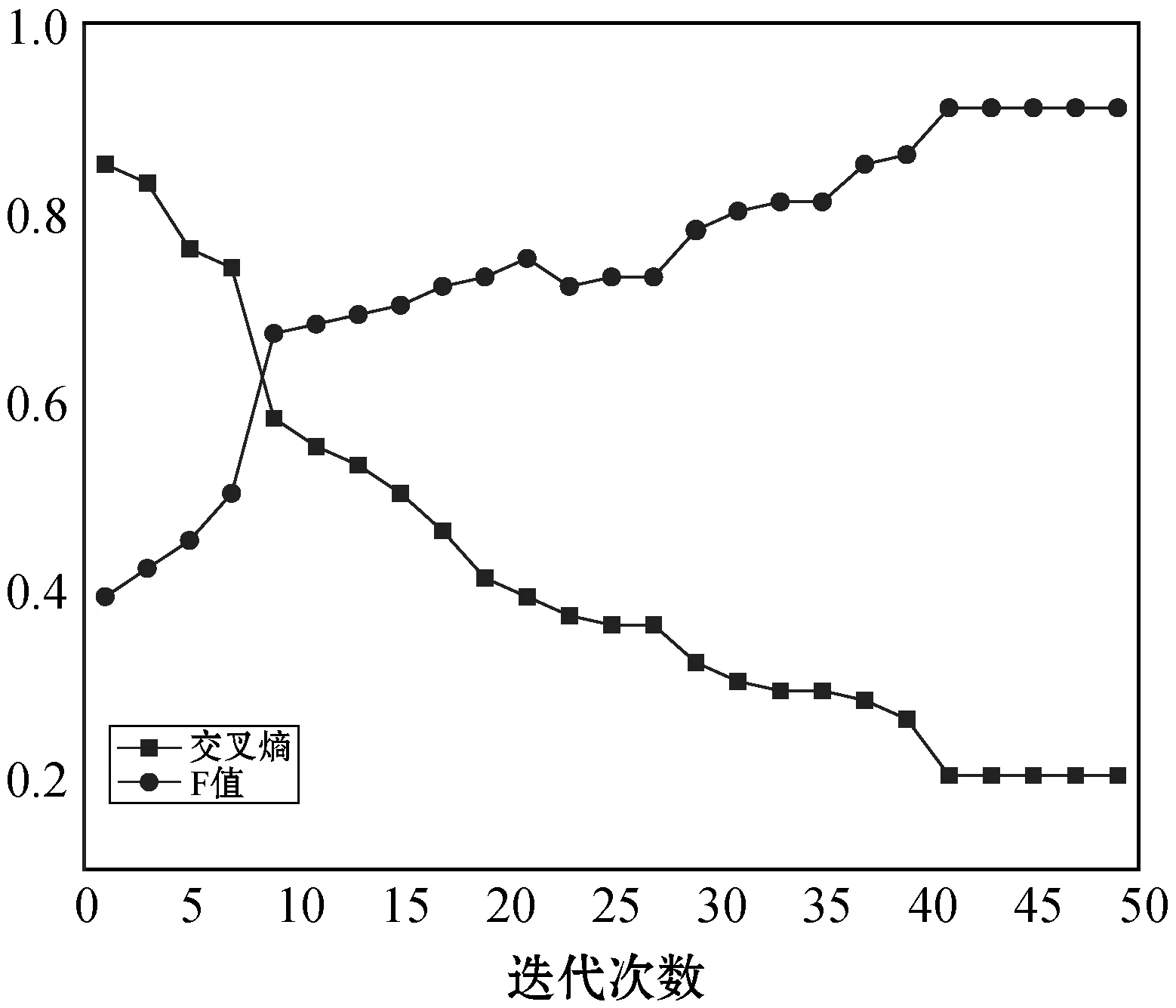
图6 迭代次数与交叉熵趋势和F值的关系
根据模型的迭代推优,我们基于CNN-LSTM的工控协议同源攻击检测方法发现了包括Shodan、Censys、Plcscan,东北大学和密歇根州立大学等在内的10个攻击(包括设备扫描)组织,一共涉及的IP数量超过200个。
5 结 语
本文提出一种基于CNN-LSTM的工控协议同源攻击检测方法。通过提取数据流中的序列和字段特征,经过CNN进行数据流特征卷积、池化运算,将生成的特征向量输入LSTM进行序列学习。加入注意力矩阵,使用BP算法进行权值寻优和更新,而后基于Softmax激活函数得到分类概率值的同时使用交叉熵函数进行模型评估。在处理离线蜜罐数据时,模型随着长时间的迭代,相比其他模型具有最优的准确率和召回率,有最好的F值效果。我们通过基于CNN-LSTM的工控协议同源检测方法发现了10个攻击组织,涉及IP超过200个。
