基于宽度学习和协同过滤的在线信息推荐算法
2023-06-07周正茜
景 楠 周正茜 袁 戟
1(上海大学悉尼工商学院 上海 201899) 2(万物云空间科技服务股份有限公司 广东 深圳 518000)
0 引 言
随着社交媒体的兴起,口碑营销已从线下推荐转变为以线上推荐为主,线上线下相结合的多渠道推荐。目前的推荐系统中,用户在网络上的评价和推荐能够显著影响产品的销售状况[1]。因此,从企业角度考虑,用户口碑对产品设计和营销策略起着决定性的作用。基于此,建立基于用户个性特征的产品推荐系统,不仅能够提高用户体验和满意度,而且能够增强用户购买产品和服务的意愿。为了适应以上需求,在线电影评论网站中现已建立了基于评论和评分等数据的个性化推荐系统,其应用成果加速推动了推荐算法的落地和发展。
在推荐系统中,被推荐的产品被称为项目(item),通常具有较高的社交相关性,主要是指电影[2-4]、音乐[5-6]、电视节目[7-8]以及旅游规划[9]等产品和服务。推荐系统中的用户(user)是指有意向购买或使用项目的特定用户,他们通过在线评论网站对项目进行评分或发表评论来评价项目。在线评论网站和社交媒体通过提取项目和用户评价的内在属性,使相关信息进一步转化为可量化的数据,便于推荐算法建模。
协同过滤方法(Collaborative Filtering, CF)[10]是目前在推荐系统中最常用的推荐方法。它的基本原理是通过计算用户之间的相似度,找出目标用户的相似用户(邻居),并根据相似用户的浏览、观看、点击和评价等历史行为数据估计目标用户对项目的偏好,从而得出推荐的结果。
但在大数据背景下,推荐系统正面临着诸多挑战。当前的网络环境对信息推荐系统的快速反应能力提出了更高的要求。其中信息过载问题很大程度上影响了信息推荐系统的推荐效率。而当大量新项目或新用户进入到推荐系统时,历史行为数据缺失将导致冷启动问题和数据稀疏性问题,进而影响推荐结果的准确性。
迄今,研究者主要通过采用矩阵分解法[11]、深度学习模型[12]来实现推荐算法准确性的提升。但由于深度学习模型中隐含层结构复杂,训练参数数量大,快速增量的用户和项目数据使得模型的训练时间过长,进而引起推荐系统模型训练的效率大幅度降低。此外,深度学习模型易引起过拟合问题,导致模型的泛化能力较弱,进而降低了推荐系统的准确性。与此同时,宽度学习系统(Broad Learning System, BLS)[13]省略了深度学习模型中的隐含层结构,通过在输入层中增加增强节点,既保障了模型的准确率,又大幅度提高了模型的训练效率,已经被广泛地应用于图像识别、时间序列预测等领域。
为在保证推荐准确率的前提下,提高推荐系统的在线计算效率,本文基于协同过滤和宽度学习构建信息推荐系统,以适应快速增量的用户和项目数据。本文将宽度学习模型与深度学习模型和集成学习模型进行对比实验,对宽度学习模型的准确性和训练效率进行评估。
1 研究现状
本节对目前的推荐系统中的主要方法和应用场景进行回顾,并对宽度学习及其相关研究进行介绍。本文所提的宽度学习是指由Chen等[13]提出的宽度学习系统(Broad Learning System, BLS),与基于多种用户数据资源的宽泛学习方法(Broad Learning, BL)[14-16]相区别。
1.1 推荐系统
推荐系统主要由用户信息、项目信息和推荐方法三个部分组成。用户信息主要包括用户行为和内在属性两方面。用户行为是用户模型构建的基础,包括用户的点击、收藏、评分[2]、评论[7]和根据评论内容提取得到的情绪特征[5]。此外,用户的内在属性,如性别、年龄和受教育程度也可作为寻找相似用户的重要依据。项目信息取决于项目的具体类别,以电影为例,其内在属性包括名称、标签、流派和发行年份等。此外,项目信息也包括了用户对项目的行为数据。
目前,推荐方法主要有基于内容推荐[17-18]和协同过滤推荐[19]两种。基于内容推荐方法侧重于挖掘项目和用户信息的内涵,基于用户和项目的内在属性为目标用户找到最匹配的项目。与此同时,协同过滤推荐则通过分析用户与用户、项目与项目之间的关系,在系统中为目标用户查找相似用户,并根据相似用户的历史行为数据来进行推荐。这些相似用户在协同过滤推荐中也被称为“邻居”。根据算法的面向对象,协同过滤推荐可以进一步分为基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。实践中为了提高推荐系统的准确性,学者们通常融合多种推荐算法。例如,Shin等[7]基于关键词分类方法和用户相似度预测构建数字电视推荐系统。Su等[17]基于聚类算法对用户行为和音乐内容进行分析构建音乐推荐系统。Rosa等[5]对音乐评论的情绪进行分析,基于用户的社交网络和推荐系统中的行为数据为用户提供精准推荐。Deng等[20]结合离线数据的挖掘与在线推荐系统进行了推荐系统的仿真。
然而,随着用户和项目数据的快速增加,数据稀疏性问题和冷启动问题将会大幅降低推荐系统的准确性和效率。以电影推荐为例,由于用户无法对所有电影进行评分,最终的评分矩阵会因为评分缺失而过于稀疏,影响推荐结果的质量。而对于没有历史数据的新用户和项目,推荐系统无法找到其相似用户和项目(邻居),因此无法利用邻居的历史行为数据为目标用户进行推荐,导致冷启动问题。由于当前推荐系统的应用场景大多为在线环境,需要高质量的推荐精度以及在线计算能力。因此,解决数据稀疏性问题和冷启动问题对提升推荐系统效率尤为重要。
针对数据稀疏性问题和冷启动问题,通常学者们采用基于模型的协同过滤方法对快速增量的数据进行处理,主要包括矩阵分解法[2,21-22]、神经网络[12]、关联分析和聚类分析等算法。其中,矩阵分解法由于其运算速度快等优点,被广泛应用于各种推荐系统。如Ma[2]通过矩阵分解法来评估显式和隐式信息对推荐系统的影响。由于数据改变时矩阵分解法需要对数据进行重新计算,因此不适用于数据快速增长的在线推荐系统。随着机器学习方法的广泛应用,在推荐系统中使用深度学习等算法成为新的趋势。Yang等[23]在2013年提出了一种基于贝叶斯概率模型的推荐方法。Zhou等[10]在2016年基于LDA算法和贝叶斯概率模型进行电影推荐。Fu等[12]在2018年使用深度学习方法对电影推荐系统中协同过滤方法进行了改进,通过前馈型神经网络模型挖掘用户与项目之间的关系,预测目标用户对项目的评分。以上机器学习模型能够在数据不断增长的情况下进行增量训练,且具有较高的推荐准确率。但由于模型结构复杂,参数量大,训练时间长,导致推荐系统效率降低。
因此,为了克服现有机器学习模型训练过程复杂,训练耗时的缺点,本文将宽度学习和协同过滤相结合,构建在线信息推荐系统,在保持较高推荐准确率的同时,提高推荐系统的训练效率。
1.2 宽度学习
宽度学习是一种基于随机向量功能链接神经网络(Random Vector Functional-link Neural Network, RVFLNN)[24]和增量学习算法的机器学习模型。2018年Chen等[13]提出的宽度学习是一种不需要隐含层结构的新兴机器学习模型。实验结果表明,该方法无需长时间的训练,就能达到较高的预测准确率[13,24]。如图1所示,为了保证较高的准确率,宽度学习不是通过增加神经网络中隐含层的层数和每层神经元的个数,而是在输入层中引入增强节点,从而提高模型拟合的效果。2018年Jin等[25]进一步建立了正则化的宽度学习模型以处理不确定数据。目前,宽度学习已经在分类问题[26-28]、特征提取[29]、时间序列预测[30-31]、函数逼近[32]、图像识别[33-35]和故障诊断[11]等领域得到了广泛的应用。近期研究中,Liu等[26]基于宽度学习对MINIST数据集进行分类模型的构建,取得良好的实验效果。Zou等[27]采用了宽度学习来构建图像分类模型。Liu等[29]将宽度学习应用于图像识别领域中的特征提取问题,并与K-means聚类算法相结合,提高了图像特征提取的效果。Xu等[30]改进了宽度学习系统,基于递归宽度学习系统进行空气质量的时序预测,实验结果验证了该模型的有效性。Chen等[32]将宽度学习应用于函数逼近、时序预测和人脸识别方面等领域,并将其在不同领域的性能进行比较。Shi等[35]使用宽度学习识别学生的肢体动作。Jin等[33]提出了一种基于正则化的宽度学习系统用于图像识别领域。Jiang等[11]学者基于宽度学习和矩阵分解方法对感应电机的故障诊断进行分析。
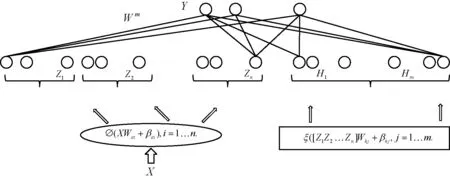
图1 宽度学习模型结构[24]
此外,一些学者还通过优化算法来提高宽度学习的准确率。2018年,Li等[34]基于BP反向传播算法对宽度学习进行改进,对特征节点和增强节点的权重和阈值进行反向传播调整。与最初的宽度学习系统相比,基于BP反向传播算法的宽度学习系统能够实现更高的预测准确率。从上述研究中可以看出,宽度学习可与聚类、关联等方法相互融合来提升模型的性能,其可扩展性和鲁棒性较高。
2 信息推荐系统
本文首先基于协同过滤和统计分析构建推荐系统的输入特征,进一步基于宽度学习系统预测用户偏好,得到用户对项目的预期评价,并将预期评价与用户历史真实评价进行比较,得到最终的推荐结果。
如图2所示,本文提出的信息推荐系统中包含用户和项目两类对象。用户是推荐系统的目标客户,项目是要推荐给用户的产品。为了对推荐结果进行评价,用户是只包含少量历史记录的冷启动用户,原始数据包括用户属性、项目属性和用户行为三类。其中,用户属性和项目属性是用户和项目的固有属性,用户行为数据是用户对项目的评分,此外也可基于用户的评论或购买记录数据进行分析。基于项目属性和用户属性,通过特征提取和相似度计算得到用户的邻居信息和项目的邻居信息,并结合用户自身行为信息的统计特征和用户内在的属性特征,构造推荐输入特征。然后,将推荐输入特征输入到基于宽度学习系统的用户偏好预测模型中,对用户的评分进行预测,完成项目的推荐。完成评分预测后,将最终的推荐结果返回给目标用户,并根据用户的真实行为数据来评价推荐结果的质量。推荐结果将作为用户偏好信息存储在数据库中,作为推荐的基础。
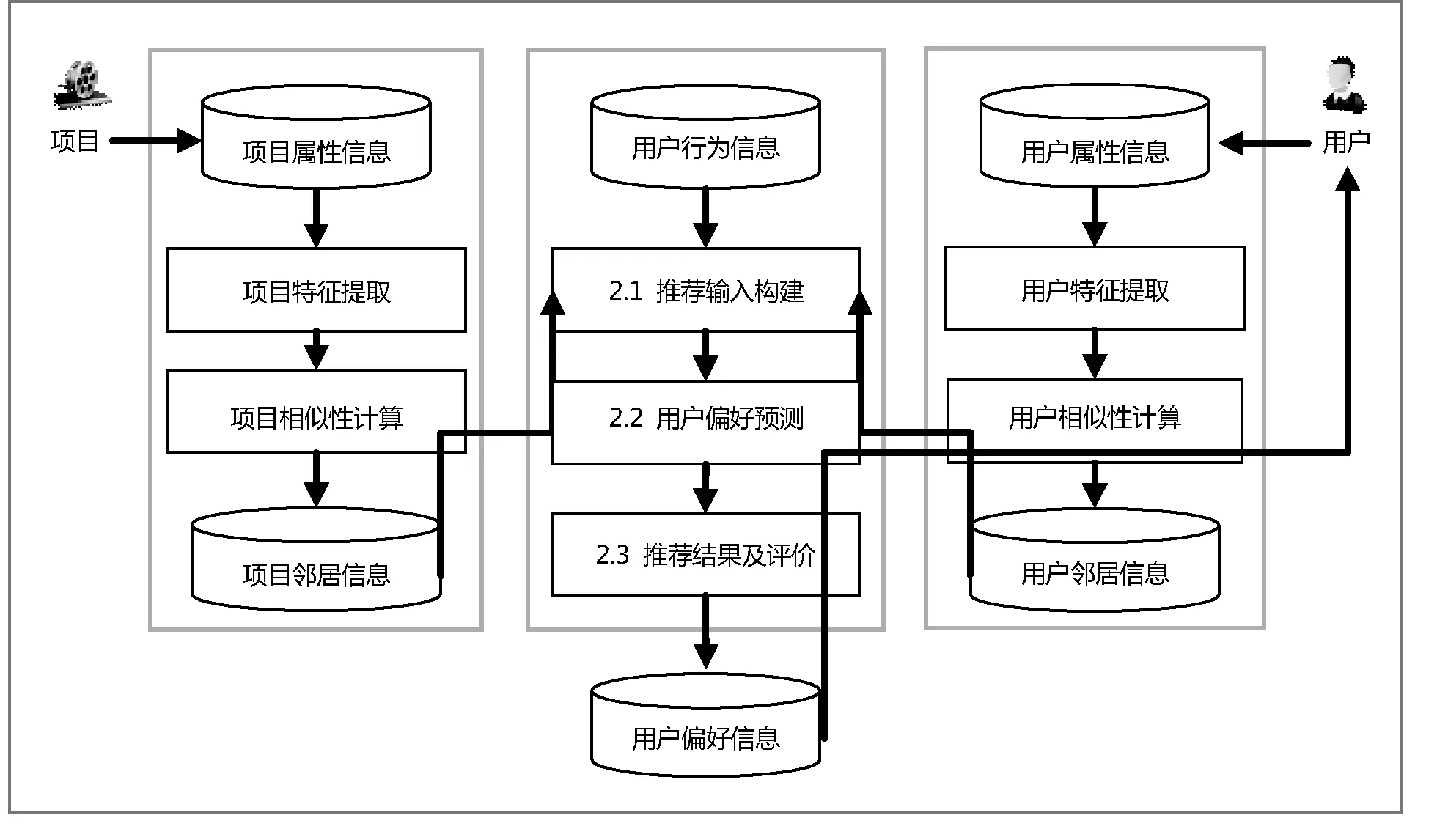
图2 信息推荐系统框架
2.1 特征工程
(1) 特征提取。由于特征提取的质量会很大程度上影响用户和项目的相似度计算的有效性,而相似度计算的优劣又决定了最终找到的邻居质量,进而影响推荐输入特征对用户偏好的预测效果。基于用户和项目信息提取推荐输入特征,包括类别变量和数值变量两种。对于目标用户,本文根据其内在属性和行为数据生成用户特征,如年龄、性别、职业和评分等。对于目标项目,根据其内在属性和行为数据生成特征,如发行时间、流派、评分和评论等。当项目和用户存在内在属性数据时,通过其内在属性数据来计算相似度,避免提前使用与推荐结果相关的行为数据。无法获取内在属性数据时,引入评分记录等用户行为数据来寻找邻居。用户对项目的评分记录等行为数据能够表示用户对项目的偏好,且很容易从在线评论网站的数据库中生成。但也存在一些不足,即提前使用用户行为数据会影响推荐结果,不能客观地评价信息推荐系统的效果。
(2) 相似度计算。相似度计算是协同过滤方法的基础。为了对目标用户进行推荐,计算目标用户与其他用户之间的相似度,并根据设定邻居用户的数量对用户进行筛选和匹配。本文选用余弦相似算法、Pearson相关系数算法和Jaccard算法根据不同的数据类型来计算相似度。
对于数值型的非用户行为特征(年龄等),由于不需要考虑用户偏好的影响,通过Pearson相关系数算法计算用户相似度,描述用户存在均值差异的特征属性。
(1)

对于数值型的用户行为特征(评分等),由于用户行为偏好不同(如打分的高低),为了减少其对相似度计算的影响,本文采用调整的余弦相似算法来计算其相似度,其计算方法如式(2)所示,这也是文本相似度计算的主流方法。
(2)
对于类别型的属性特征(如项目的流派),本文采用Jaccard系数来计算相似度,其计算方法如式(3)所示。
(3)
式中:以项目i和j的内在属性相似度计算为例,Jaccard_simij表示其相似度,其大小在0到1之间;Gik和Gjk为项目i和j的第k个内在属性特征值,共n个内在属性特征。
完成对用户和项目的相似度计算后,基于相似度计算结果找到每个目标用户和项目的相似度前1%数目(按相似性大小排序)的邻居用户和邻居项目。在进行推荐时,本文根据邻居用户和邻居项目的历史行为数据来为目标用户构建推荐输入特征,并基于协同过滤获得质量较高的推荐输入特征。
(3) 特征构建。完成对相似度和邻居信息的提取后,基于协同过滤的推荐来构造推荐输入特征。如表1所示,本文通过协同过滤和特征提取方法得到六类推荐输入特征。推荐输入特征可根据对象分为用户推荐特征和项目推荐特征。本文在其基础上进一步再细分为属性特征、行为特征和邻居特征。
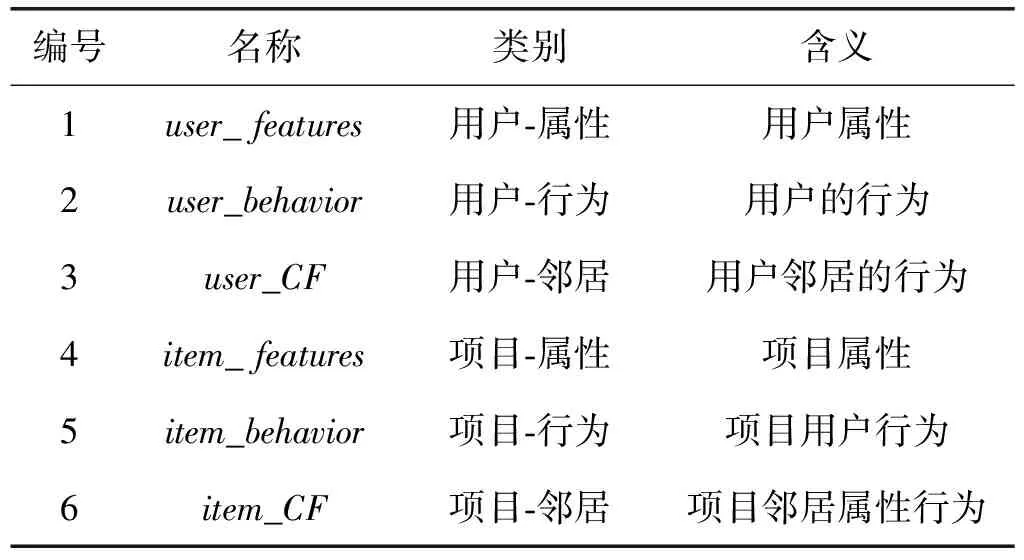
表1 推荐输入特征
用户推荐特征中,user_features是用户的属性特征(年龄、性别、职业等),user_behavior是用户行为特征(评分、标签、评论量和购买量等数值统计结果)。user_CF是用户的相似邻居行为特征,与用户的行为特征相似,通过基于用户的协同过滤算法进行构建。
项目推荐特征中,item_features是项目的属性特征(上市年份、价格、类别等),item_behavior是项目的用户行为特征(购买量、评分数、评论数等数值统计结果)。item_CF是项目的相似邻居的用户行为特征,通过基于项目的协同过滤方法来构建。
2.2 用户偏好预测模型
基于2.1节中生成的推荐输入特征,采用宽度学习系统(Broad Learning System, BLS)对用户的偏好进行预测。为了比较宽度学习模型与其他机器学习模型,还使用深度学习中的深度神经网络模型(Deep Neural Networks, DNN)[38]、集成学习中的轻量化梯度促进机(Light Gradient Boosting Machine, LGBM)[39-40]进行模型的训练和测试。本文通过对比实验宽度学习模型、深度神经网络模型和轻量化梯度提升模型,对基于宽度学习的信息推荐系统进行有效性验证。
本文将通过协同过滤得到的推荐输入特征作为用户偏好预测模型的输入。分别基于以上三种模型进行用户偏好预测,以对比分析宽度学习模型的准确性和效率。输出预测分数后,将预测评分与用户真实平均评分进行对比,以确定是否进行推荐,并将推荐结果存储到系统中。最终,提出的信息推荐系统将推荐的项目返回给目标用户。本文主要将深度学习、集成学习和宽度学习在准确率和效率两个方面进行比较。
(1) 基于深度学习的预测模型。本文使用深度神经网络模型作为宽度学习模型的对比模型。如图3所示,深度神经网络模型中包括输入层、隐含层和输出层三个部分。用户偏好预测模型基于2.1节中生成的推荐输入特征Xa,通过激活函数得到激活后的输入特征Φ(XWei+βei)。预测模型将计算输入层节点和隐藏层节点的权值和阈值,并通过正向学习算法得到预测结果Ya。当预测精度要求较高时,深度神经网络模型将增加隐含层的层数和各隐含层神经元的节点数来提高模型的拟合能力。但模型训练的复杂度和训练时间将大幅度上升,模型的泛化性能也受到一定的影响。以上问题将导致在线信息推荐系统中推荐响应速率大幅度降低。因此,本研究引入基于宽度学习结构的预测模型,在保障模型准确率的基础上提高模型训练的效率。
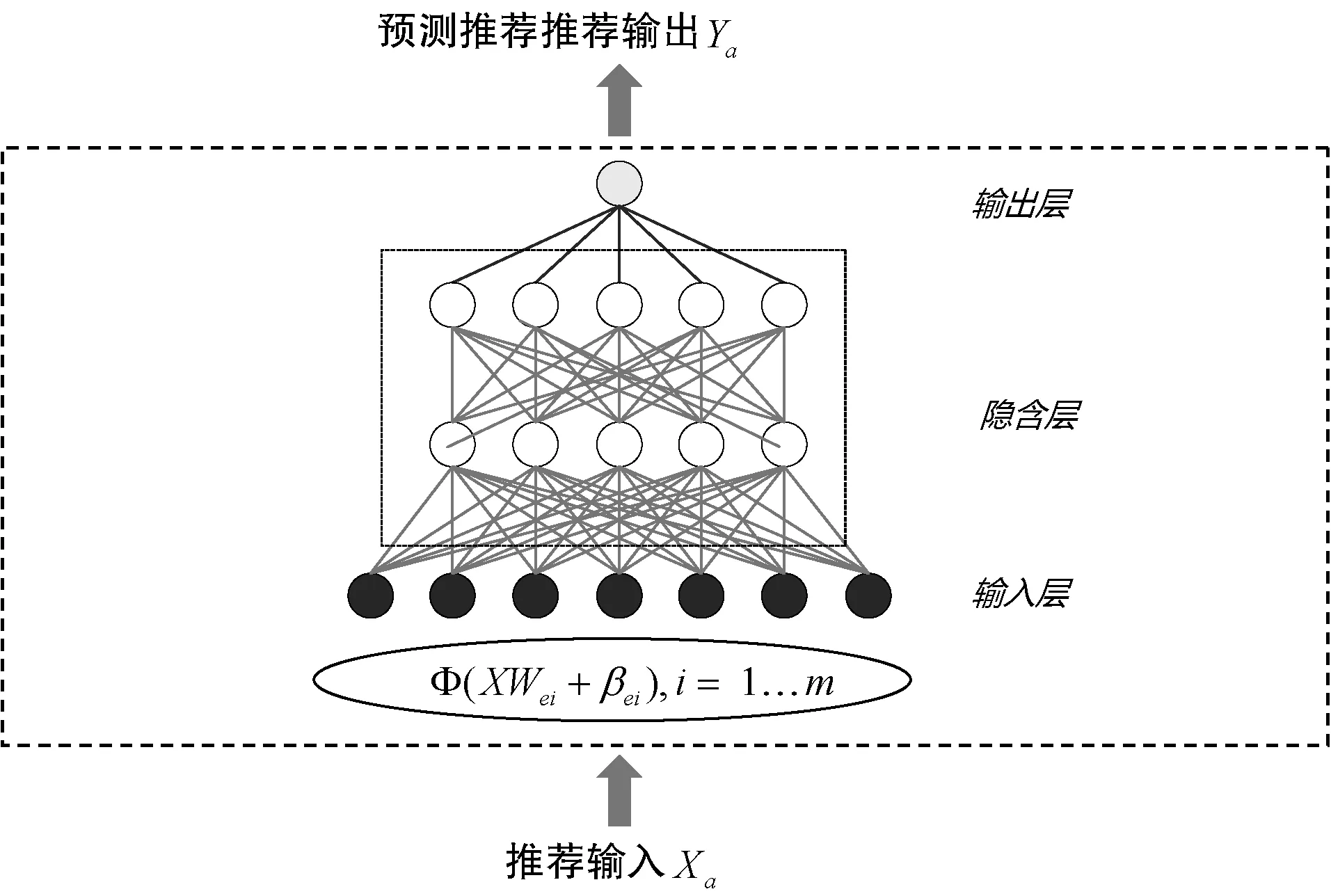
图3 基于深度学习结构的预测模型
(2) 基于宽度学习的预测模型。基于宽度学习结构的预测模型同样使用推荐输入特征来对用户偏好进行预测。如图4所示,基于宽度学习的预测模型包括输入层和输出层两层结构。相比于深度学习模型,宽度学习模型将隐含层结构转变为输入层中的增强节点。宽度学习模型中的输入数据为2.1节生成的推荐输入特征Xa,其输出结果为Ya。在模型构建过程中,首先对推荐输入特征Xa进行特征映射,得到输入层的特征节点Z=Φ(XWei+βei),并进一步对特征节点进行激活,得到输入层中的增强节点H=ξ([Z1Z2…Zm]Whj+Bhj)。由于模型训练时已知输入特征Xa和输出结果Ya,本文可直接通过对公式Y=A×W求矩阵伪逆的方式得到特征节点Z和增强节点H的权重集合W,降低了模型训练过程中参数计算的时间和模型的复杂度。在进行模型测试时,由于预测输出可直接通过输入层节点与权重集合W相乘来得到,模型的测试效率大幅度提升。此外,当输入特征数据增加时,由于不需要对模型进行重复运算,可直接通过矩阵运算得到输出结果。
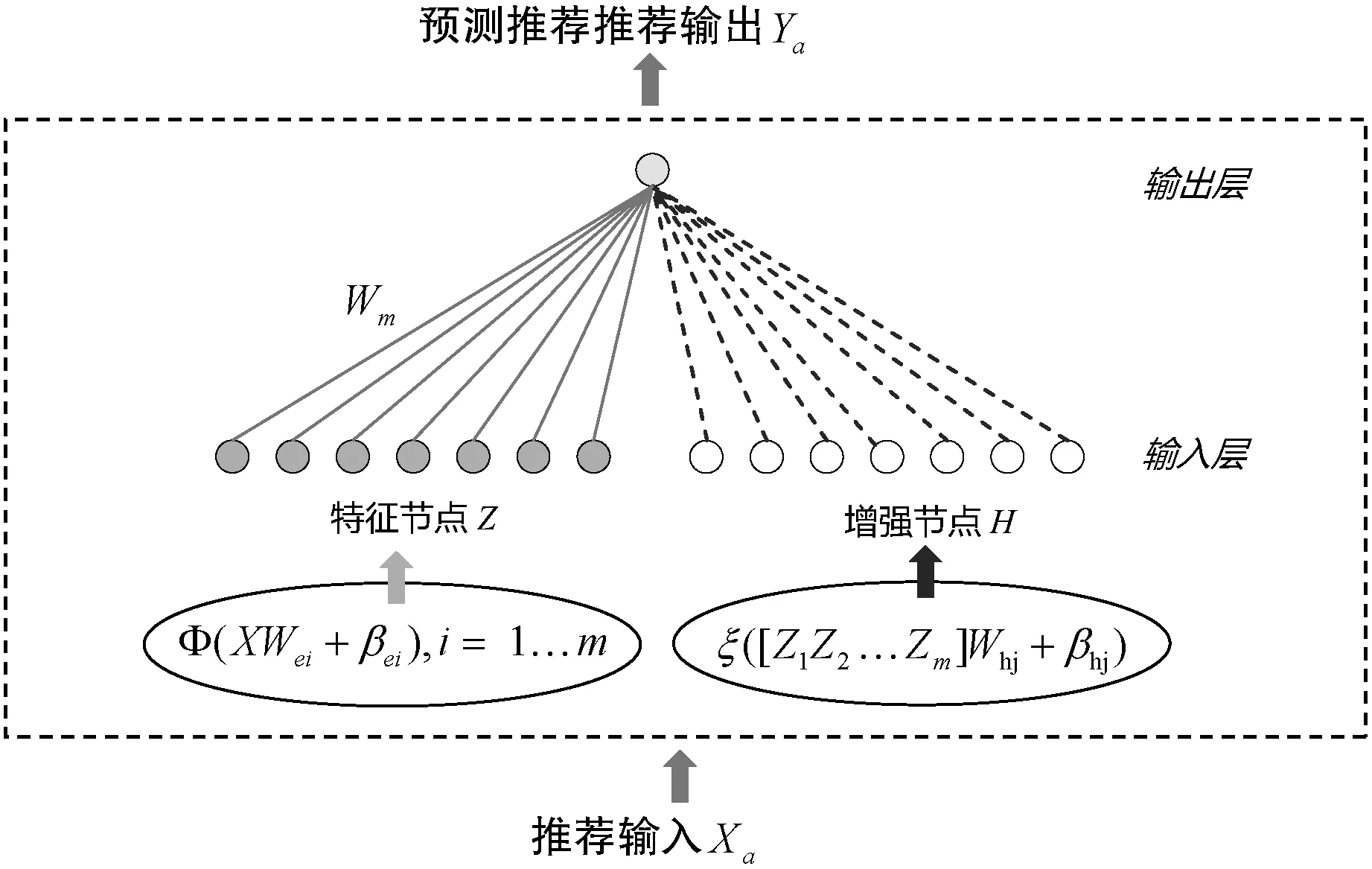
图4 基于宽度学习结构的预测模型
(3) 推荐结果评价。本文采用均方根误差(Root Mean Square Error,RMSE)评价预测结果的准确性。如式(4)所示,RMSE用于评价预测输出与真实输出之间的误差大小。
(4)
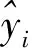

(5)
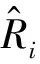
(6)
3 实验与分析
本文使用公共电影数据集MovieLens进行实验,构建基于宽度学习和协同过滤的信息推荐系统。实验的第一阶段,本文通过协同过滤方法构建推荐输入特征,用于预测用户的偏好。实验的第二阶段,本文基于宽度学习模型和其他对比模型对用户偏好进行预测,完成对目标用户的推荐。实验的第三阶段,本文对得到的推荐结果进行分析,并对各个模型的准确率和效率进行总结和评价。
3.1 实验环境
本文实验环境基于个人笔记本电脑,中央处理器为Intel(R) Core(TM) i7-6700HQ CPU @ 2.60 GHz (8 CPUs)~2.6 GHz,内存为8.00 GB,硬盘为500 GB。本文使用Windows 10的64位操作系统,开发语言为Python 3.6.5,集成开发环境(Integrated Development Environment, IDE)为Jupyter notebook。
3.2 实验过程
如图5所示,本文的实验过程包括以下三个步骤:第一步根据用户和项目信息构建协同过滤模型,首先对项目和用户特征进行提取,并通过对相似度的计算,找到相似的项目和用户来帮助推荐。第二步利用相似用户和相似项目的信息,建立推荐系统的推荐输入特征,主要包括六类,在2.1节特征工程的特征构建中已进行阐述。第三步基于多种机器学习方法和交叉验证法进行对比实验,包括宽度学习系统(Broad Learning System, BLS)、深度神经网络模型(DNN)、基准模型协同过滤方法(Collaborative Filtering, CF)和轻量化梯度提升模型(Light Gradient Boosting Machine, LGBM),对用户偏好进行预测和分析。
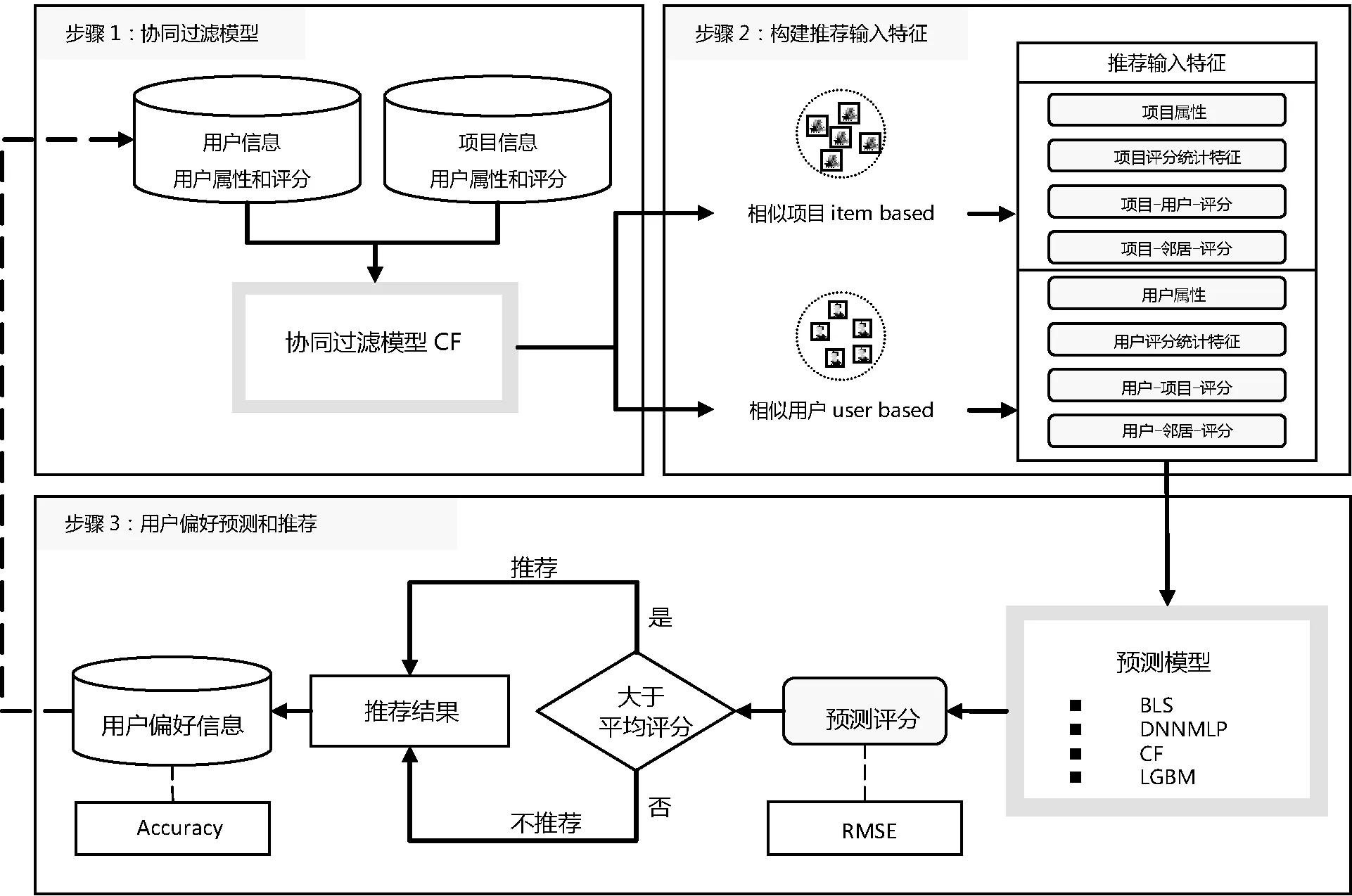
图5 实验过程
在完成模型的训练和预测后,本文通过比较各模型的预测评分和用户平均评分,计算出模型的测试误差和准确率,从而对各个模型的有效性进行评价。本文将最终的推荐结果存储在用户偏好信息中作为未来推荐的基础,以适应在线推荐系统中快速增量的用户行为数据。
3.3 数据描述
本文基于广泛应用于电影推荐系统的公共数据集MovieLens[41]构建用户信息推荐系统。本文采用的数据集为百万评分数据集ml-1m,包括电影评分数据、电影属性数据和用户属性数据三个部分。
如表2所示,评分数据中包含来自6 040个用户对3 706部电影的1 000 209条评分记录。最早评分记录的时间为2000/04/26 10:19,最新评分记录的时间为2003/03/01 01:49。评分记录的值从1到5不等,表示用户对某一部电影的喜爱程度。
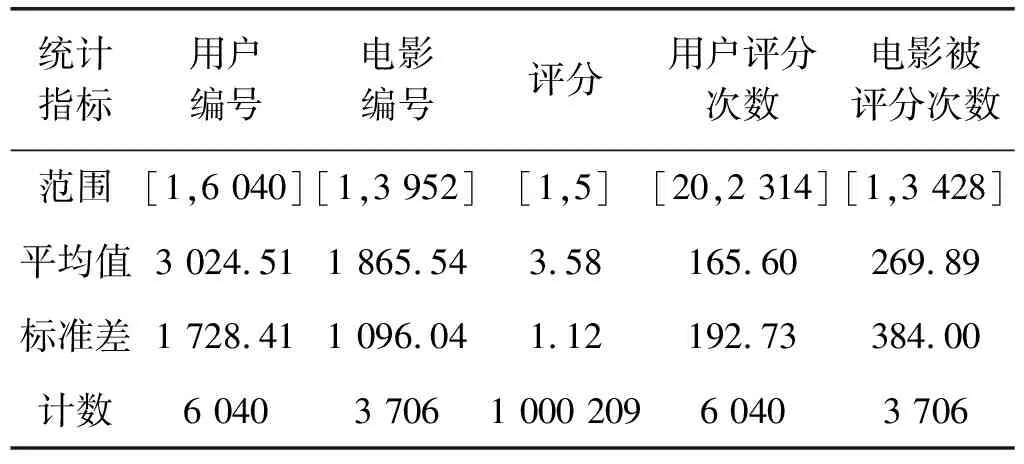
表2 评分数据集描述
本文根据用户的评分记录计算用户和电影的评分次数,数据中的用户至少对20部电影进行了评分,最多对2 314电影进行了评分。数据集中电影最少被1个用户评分,最多被3 428个用户评分。因此,本文中用户均存在历史评分记录,不存在冷启动问题,能够对推荐效果进行评价。
在模型的构建过程中,为了对比宽度学习模型、深度神经网络模型和轻量化梯度提升模型的表现,本文基于十折交叉验证法,将数据集随机分成10个子集,使用其中9份数据对模型进行训练,并使用剩下的1份数据对模型进行测试,共完成10次训练和测试。协同过滤方法将作为基准模型使用所有数据集进行测试,以评估其他机器学习模型的有效性。
3.4 实验结果
本文采用十折交叉验证法,对预测模型进行训练和测试。从表3可看出,相比于基准模型基于用户的协同过滤(User based CF)和基于项目的协同过滤(Item based CF),宽度学习系统(BLS)、深度神经网络模型(DNN)和轻量化梯度提升模型(LGBM)均实现了较高的推荐准确率和较低的评分预测误差。
推荐准确率(Accuracy)方面,宽度学习系统在十个交叉验证测试集上的平均推荐准确率为65.63%,相比于基于用户的协同过滤51.70%和基于项目的协同过滤50.14%有显著提升。与此同时,相比于深度神经网络模型的推荐准确率宽度学习系统有所提高。相比轻量化梯度提升模型67.22%的推荐准确率存在约2%的差距,但仍能保障较高的推荐准确率。
与此同时,如表4所示,在评分预测误差(RMSE)方面,宽度学习系统的评分预测误差平均值为0.914 0,相比于基于用户的协同过滤的2.355 0和基于项目的协同过滤的1.834 9有着明显的降低。且相比于深度神经网络模型的误差均值宽度学习系统的平均误差有所降低。相比于轻量化梯度提升模型,宽度学习系统的评分预测误差高出0.035 7。但总的来说,宽度学习系统能够实现较低的推荐评分预测误差和较高的推荐准确率,实现较好的推荐效果。
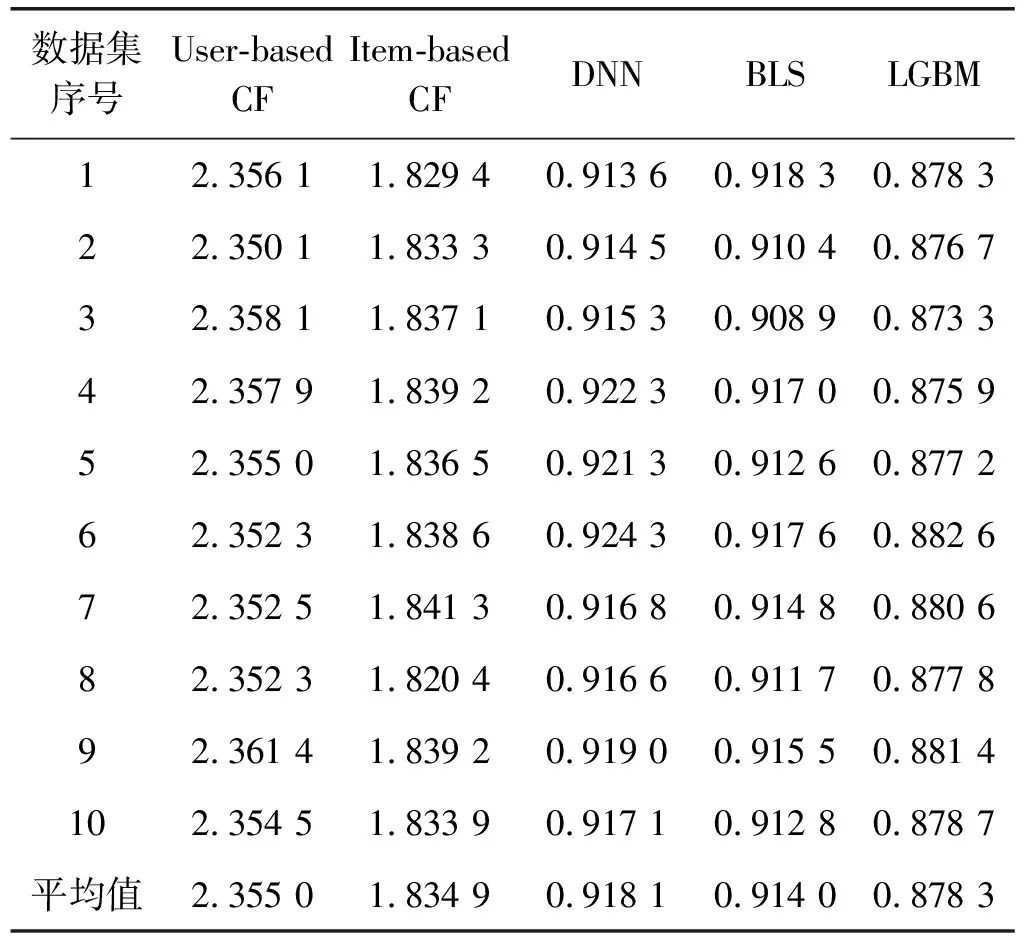
表4 模型测试集预测评分误差
通过实验进一步对模型的训练效率进行评价。由于协同过滤模型无需单独的测试和训练,本文忽略其模型训练的效率问题。如表5所示,深度神经网络模型(DNN)的平均训练时间为373.63 s,轻量化梯度提升模型(LGBM)的平均训练时间为77.19 s,而宽度学习系统(BLS)的训练时间仅为14.52 s,相比于深度神经网络模型训练效率提升近25倍,相比于轻量化梯度提升模型训练效率提升近5倍。主要原因在于宽度学习系统中的宽度学习结构不需要对参数进行复杂重复的训练,可直接通过矩阵相乘和伪逆计算完成模型的训练和测试。总的来说,宽度学习系统能够在保障准确率的前提下,大幅度提高预测和推荐的效率,实现精准高效的用户在线信息推荐。
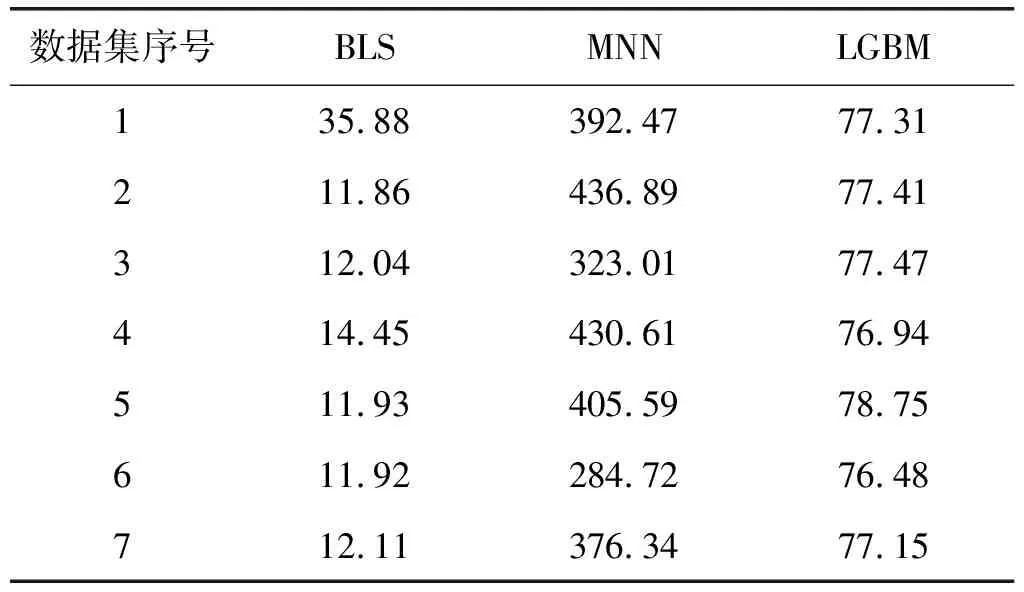
表5 模型训练时间 单位:s
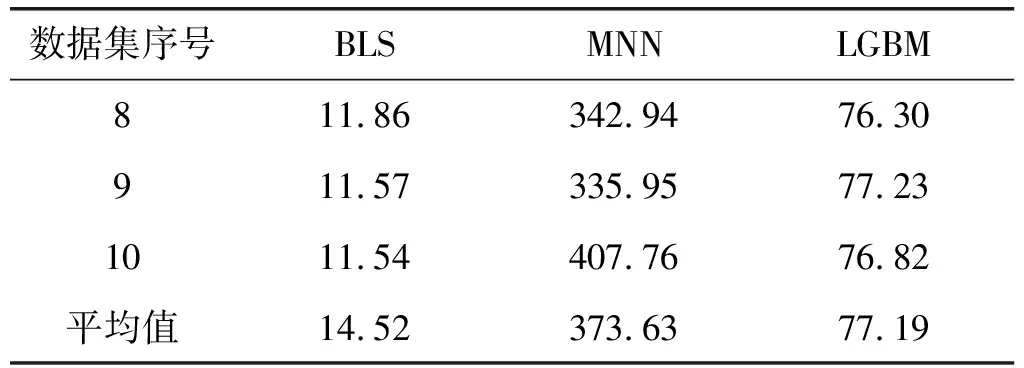
续表5
4 结 语
本文针对当前推荐系统中由于信息超载导致的响应效率低以及由于缺失大量历史数据导致冷启动等问题,对协同过滤方法进行改进,与宽度学习系统相结合,在保障计算准确率的基础上提高模型训练的效率。通过在公共数据集MovieLens上的测试效果显示,该模型在精度上优于协同过滤模型和深度神经网络模型(DNN),接近轻量化梯度提升模型(LGBM);而实际运算效率分别是上述两个模型的近25倍和近5倍。因此,本文中的模型非常适用于在线推荐计算,同时对大型推荐系统的集成开发也有一定的借鉴和参考意义。下一步将通过去噪、内插、平滑等数据预处理方式提高信息推荐系统中输入特征的质量,使用更多的机器学习模型进行算法的集成,提升模型的推荐效果。
