基于改进Adaboost-SVM的风机叶片覆冰检测
2023-06-07冉浦东张子凡庞成鑫黄墀志
冉浦东 范 磊 张 军 张子凡 庞成鑫* 黄墀志
1(上海电力大学电子与信息工程学院 上海 201306) 2(国电南瑞南京控制系统有限公司 江苏 南京 210000)
0 引 言
风电作为可再生的清洁能源越来越受到国家和社会的重视,我国的北方和沿海地区是风电场分布最密集的地区,在秋冬寒冷季节极易发生叶片覆冰现象[2]。风电机组在运行时出现叶片覆冰现象会使风机的发电量降低甚至停机而且叶片覆冰会缩短风机的使用寿命甚至导致叶片折断或者风机倒塌[2]。风力发电机的故障检测研究可以提高其运行可靠性,降低运维成本,这对于目前风电设备由于故障频发所带来的高昂的运维成本来说极具经济价值[3]。本文提出的算法是一种以SVM模型作为基分类器的自适应提升算法(Adaptive Boosting,Adaboost),能够有效地提升风力发电机叶片覆冰故障检测准确率和模型的泛化能力。
1 算法原理
1.1 支持向量机
支持向量机(SVM)是一种以统计学和结构风险最小化为理论基础的机器学习经典方法[4],其核技巧是把低维样本空间中线性不可分的问题使用核函数映射到高维空间,使其在高维空间中线性可分并寻求距离两类样本的最优分类超平面[5]。SVM对于非线性的分类问题有着非常好的分类效果,非常适合应用于风机叶片覆冰的检测。在实际应用中效果也很好,对风机叶片覆冰检测的准确率也很高,但是在对结冰数据的查全率方面还有提升的空间。
1.2 Adaboost原理
Adaboost算法是一种迭代算法,首先初始化样本权重,使每一个样本权重相同,使用样本集训练第一个基分类器模型,根据分类结果调整样本的权重,被分类错误的样本权值会增加,分类正确的样本权值会降低,通过这样的方式来聚焦于那些难分的样本,使这些样本在下一轮分类中更容易被分类正确[6-7]。经过多次迭代训练生成多个差异化的基分类器,最终的学习结果取决于多个基分类器分类结果的策略组合,其目的是通过提升的方式使算法变得更精确[8]。正是由于这种机制使得Adaboost算法对于样本中少数的离群点很敏感[9]。
1.3 Adaboost-SVM模型设计
风机叶片覆冰问题是典型的数据不平衡问题,常规的Adaboost-SVM算法在处理不平衡数据问题时可能会出现集成效率低、分类准确率下降等问题。出现上述问题的原因是:(1) 以基分类器的分类准确率作为该分类器的权值,会使得该模型的分类结果偏向于多数类,对少数类不利[10]。正确分类少数类样本的分类规则及其特殊,其覆盖率低,在训练过程中可能会被忽略。(2) Adaboost算法对离群点敏感,而不平衡数据中少数类样本的离群点对Adaboost算法影响更加严重,为了能正确分类离群点数据,会通过迭代生成多个准确率极低的分类器,影响Adaboost-SVM模型的集成效率,甚至降低算法的分类准确率。
Adaboost与SVM算法的结合与具体的模型训练过程和公式参考文献[11-14]。针对上述问题和风机叶片覆冰样本数据的特点对常规Adaboost-SVM算法做出以下两点改进:
(1) 首先使用线性核的SVM模型将部分未结冰数据和极少数结冰数据的离群点分类出来,再使用Adaboost-SVM算法对剩下部分数据进行进一步分类和提升。这样不仅可以减少该算法的计算量,降低剩余数据的不平衡程度,也消除了部分离群数据对算法的影响。
(2) 常规Adaboost-SVM算法最后的结果是对各个SVM分类器的分类结果进行加权求和,权值就是各个分类器的分类准确率,现改为各个SVM分类器的分类结果,结冰数据乘以结冰数据的权值,未接冰数据乘以未接冰数据的权值。而这两类权值的取值就是SVM分类器输出的两类数据的准确率。
算法流程如图1所示。样本数据经过数据预处理和特征选择后先经过线性SVM模型进行初步筛选,线性SVM分类为未接冰类型的数据准确率高,可以直接作为最后的分类结果,而准确率低的结冰类型数据会再经过Adaboost-SVM模型进行更精确的分类。

图1 算法流程
首先初始化结冰类型样本的权重,将每个样本初始权重设置为W1,所以样本的权重之和为1。再将带有权值W1的样本进行训练第1个SVM模型,通过网格搜索的方法对SVM模型的惩罚系数C和核变量σ进行优化,得到第一个SVM模型,计算样本在第1个SVM模型的整体错误率e1,和整体准确率a1和结冰类型的准确率B1,未接冰数据准确率C1。根据分类器准确率a1更新样本权重为W2。不断循环上述步骤直道达到设置的迭代次数m。将各个SVM分类器的分类结果进行加权求和得出最后的分类结果。
(1)
式中:F(Xi)为第j个样本的最终分类结果;Gi(Xi)为第j个样本在第i个SVM模型中的分类结果,当Gi(Xi)为结冰时Ki=Bi,当Gi(Xi)为未结冰时Ki=Ci。
2 实验设计
2.1 数据预处理
本文数据来源于2017年工业大数据创新竞赛中的15号风机2个月时长和21号风机1个月时长的SCADA数据以及结冰时间段和未结冰时间段。对数据进行预处理:
(1) 去除其中无效数据、异常数据和重复数据。
(2) 根据结冰时间段和未结冰时间段将15号风机和21号风机所有数据分类并贴标签,把结冰数据标为1,未结冰数据标为-1。
(3) 对结冰和未结冰数据按时间序列分别进行移动滑窗处理。
(4) 对所有特征都进行归一化处理,降低不同量纲对分类结果的影响。
经过数据预处理过后,15号风机未结冰数据44 371组,结冰数据3 215组,21号风机未结冰数据22 711组,结冰数据1 432组。在15号风机数据的结冰数据中随机抽取2 000个样本在未结冰数据中随机抽取2 000个样本作为训练集。15号风机其余数据作为测试集。21号风机数据作为测试集。
2.2 特征选择
由于本文中每组数据都有27个特征量,部分特征与结冰结果关系不明显,不少特征含有很多重复信息或者无效信息。为了减少这些信息对模型最终分类结果的影响,降低模型的计算开销,本文使用递归消除(Recursive Feature Elimination)加交叉验证的方法对训练集数据的特征进行选择,采用5折交叉验证,将数据平均分成5份,其中4份作为训练集,1份作为验证集,轮换5次最终的特征数量与结冰与否的相关性得分取5次结果的平均值。
如图2所示,特征数量为11个时,特征集与结冰与否的相关性达到最高,图中的阴影部分表示在交叉验证中出现的波动范围。所以本文选择在SVM模型中表现最好的11个特征来对模型进行训练。特征重要性排名如图3所示。
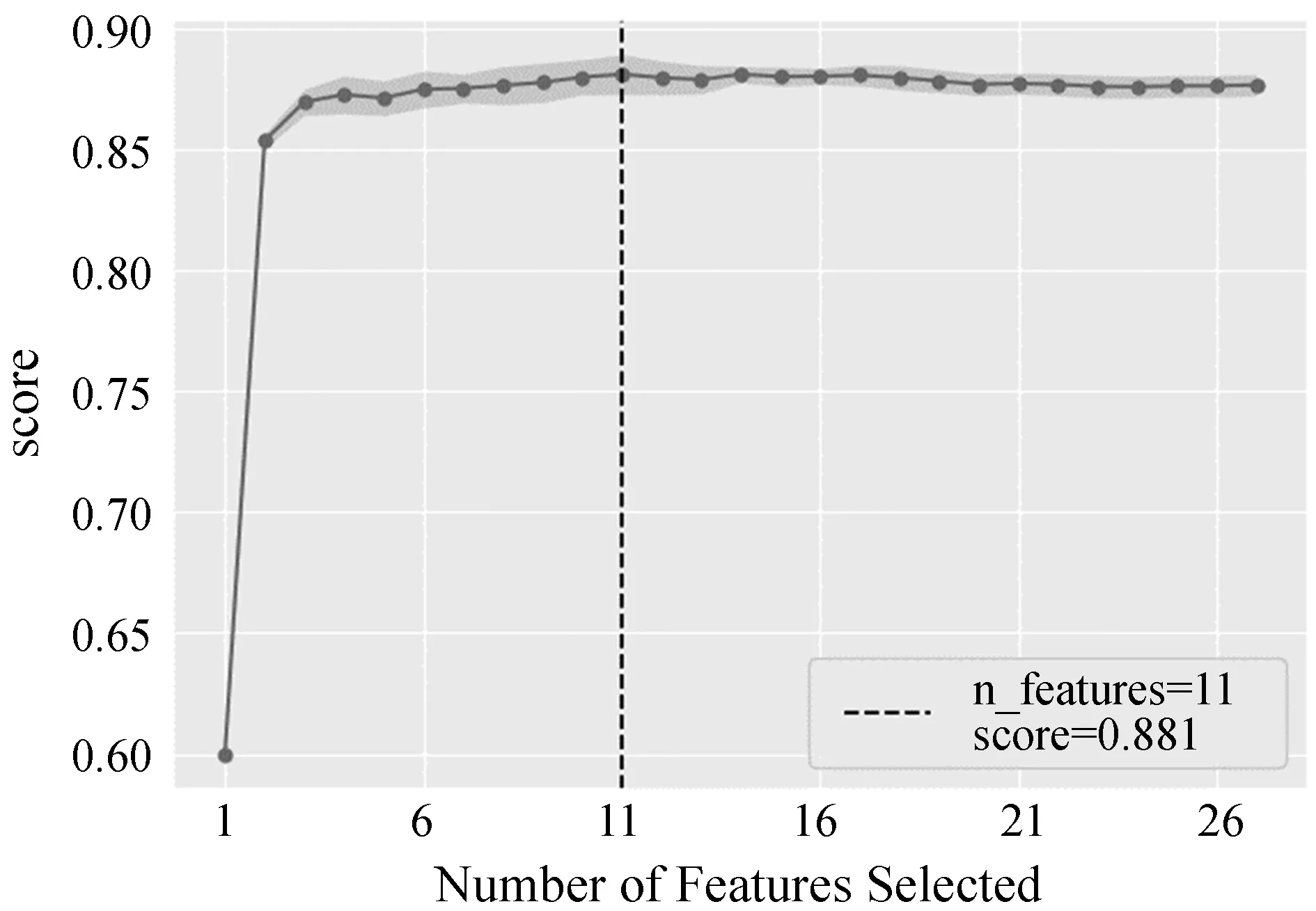
图2 RFE最佳特征数
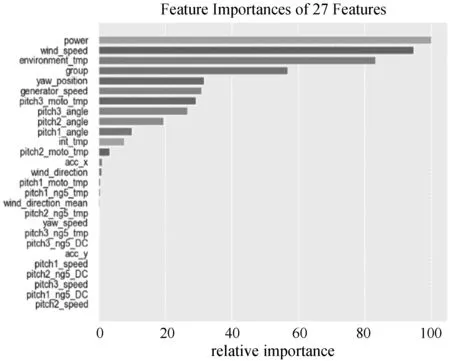
图3 特征重要性排序
2.3 模型训练
线性SVM模型用于初步筛选出样本数据中的部分未结冰数据和极少数结冰数据的离群点,要保证被线性SVM模型分为未结冰类型的数据分类准确率高,且数据量尽可能大。使用训练集数据对线性SVM模型进行训练,模型的权值系数clss-weight={-1:1=1:X},表示模型中未接冰数据的权值是1,而结冰数据的权值是X,通过调节X的大小来调节模型的分类效果。使用验证集数据对X取不同值的线性SVM模型的分类效果进行验证,并选取最优的X取值。X的取值与被结冰类型数据的准确率和数据量的关系如图4所示。
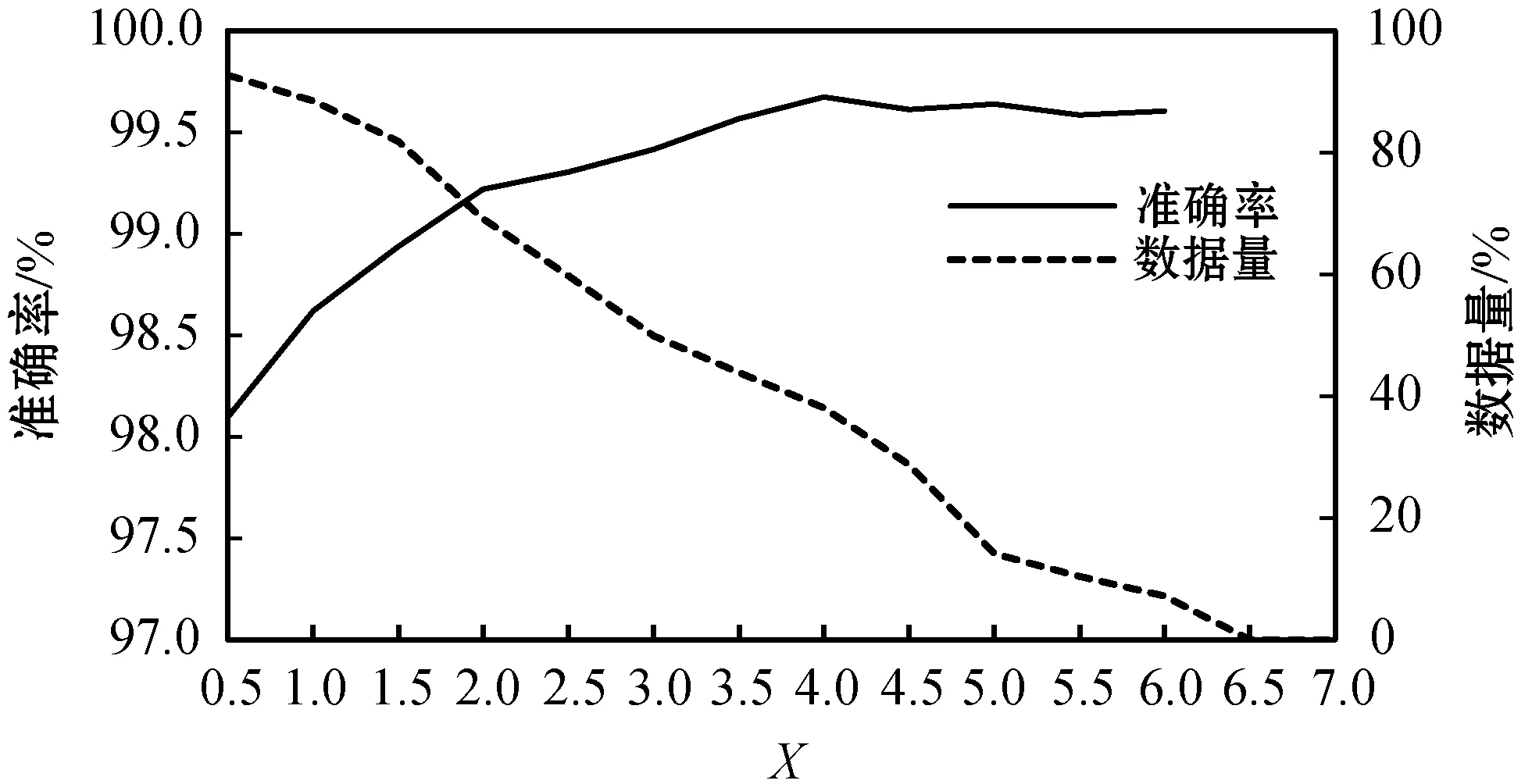
图4 未结冰类型数据准确率和数据量
数据量随着X的增大而减小,当X>6.5过后所有数据全被分模型分为结冰数据。分类准确率在X=4时达到最大。最终选择X为4的模型作为初步筛选的线性SVM模型,X=4时未接冰数据准确率为99.672%,数据量为38.028%。
将训练集中被线性SVM模型分类为结冰数据类型的样本作为新的训练集,训练改进的Adaboost-SVM模型。利用验证集数据对本文算法与常规Adaboost-SVM算法在不同迭代次数下模型整体分类准确率进行比较。如图5所示,本文算法在集成效率和准确率方面优于常规的Adaboost-SVM算法。确定本文算法迭代次数m=55,常规Adaboost-SVM算法m=80。
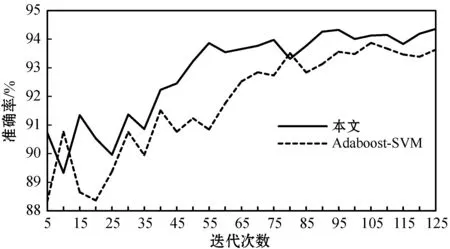
图5 迭代次数与准确率关系图
3 结果分析
在实际运行中风力发电机叶片结冰时长远小于不结冰时长。这就要求我们在判断模型预测和检测有效标准时不能仅仅以整体的精确度作为唯一标准,要从精确度、查全率、查准率与F1等多方面进行评价。
使用测试集数据对本文算法,常规Adaboost-SVM算法和SVM算法进行测试比较,其结果如表1所示。表1中的算法在测试集都表现出了相当不错的精确度,但是在查准率方面都普遍较低,这也符合不平衡数据的特征。
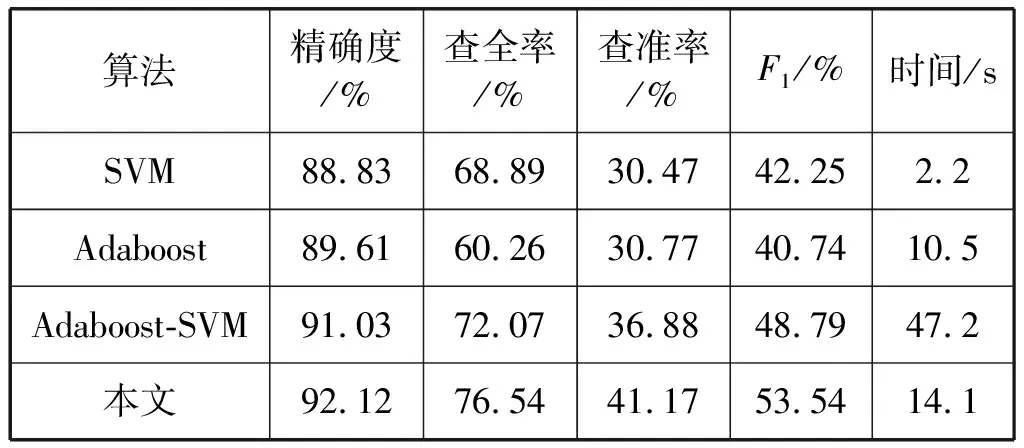
表1 4种分类算法的检测结果对比
从检测速度方面来看,本文算法由于要对数据进行前期筛选和部分数据的多次迭代,所以检测时间大于SVM算法和Adaboost算法。但是相比于将所有数据都进行多次迭代的Adaboost-SVM算法来说,本文算法的运算速度有较大的优势。而本文算法在精确度、查全率、查准率和F1度量方面相比于其他三种算法都有明显的提升。尤其是结冰数据的查全率方面,在实际的风机叶片覆冰的故障检测中,故障的查全率非常重要,因为一旦发生故障就会面临严重的经济损失和安全问题。
为了比较不同算法模型在风机叶片覆冰检测中的效果,引入2017工业大数据竞赛评分标准:
(2)
式中:S为模型检测得分;α为结冰数据在总数据中所占的比例;β为未结冰数据在总数据中所占的比例;TP为真正例;TN为真反例;FP为假正例;FN为假反例。模型检测得分S权衡了数据的不平衡性,能够科学地评价各个算法模型对测试集的综合检测能力。本文模型和文献[15-16]中的各种神经网络算法模型得分对比如表2所示。

表2 算法模型评分对比
可以看出本文算法的模型检测得分相比于文献[15-16]中的各种神经网络算法模型有明显优势的。
4 结 语
(1) 本文算法能够有效地对风力发电机叶片覆冰故障进行检测,相比SVM、Adaboost和Adaboost-SVM算法整体精确度,结冰故障的查全率和查准率更高。相比于CNN、LSTM等神经网络算法有更高的综合检测能力,更加适应不平衡数据的分类问题。
(2) 本文提出的集成权值的变化有利于提升Adaboost算法在处理不平衡数据时的集成效率和准确率。
(3) 本文算法也存在一些不足,算法的检测时间较SVM和Adaboost算法略长,算法在结冰数据的查准率方面仍有很大的提升空间,这将是我在接下来的研究中要解决的问题。
综合来看本文方法对于风机叶片覆冰检测问题具有较高的实用价值。
