智能语音技术与门诊多系统深度融合建设实践
2023-06-05郝文睿徐金建
郝文睿,张 沛,孙 震,徐金建,计 虹
(北京大学第三医院信息管理与大数据中心,北京 100191)
0 引言
随着医疗信息化的发展,门诊医生诊疗过程已实现从接诊到完成病历的全流程电子化,门诊系统功能的丰富性以及通过电子病历模板录入的便捷性大幅提高了医生的工作效率。但是医生在高门诊量的工作中频繁依靠键盘和鼠标进行录入和功能操作,存在打字烦琐、不易查找功能、看屏疲劳等问题。因此系统操作和文本录入的便捷性成为影响医生看诊效率的重要因素,医生在人机交互上花费的精力会间接影响患者看病的就医体验[1]。
国家卫生健康委员会在2019 年的例行新闻发布会上曾提到“在诊疗过程中使用语音输入病历,极大提升了服务效率”[2]。将智能语音技术应用到门诊医生诊疗过程中,不仅能够使医生本身获益,也间接促使医生把更多时间和精力放在患者服务上。
目前,国内已有医疗机构将语音录入应用在口腔科、超声科、病房等专科场景[3-12],由于综合医院门诊科室和出诊医生特点的差异性和多样性,鲜有在多科室门诊医生使用的多系统中深度应用智能语音的案例。本文旨在论述智能语音技术与门诊多系统深度融合的实践情况,以为提升医生诊疗效率提供参考。
1 需求分析
我院每日门诊量已超过1.5 万人次[13],在高强度出诊工作中,门诊业务系统操作效率对于医生十分重要。传统的人机交互方式中,医生的精力和时间过多地用于系统操作和录入电子病历,不仅使医生容易产生倦怠,也影响患者的就医体验。我院门诊医生使用的系统包括门诊电子病历系统、集成了门诊电子病历系统的门诊医生工作站以及产科专科信息系统,在以上系统中采用智能语音代替键盘鼠标可重点解决以下问题。
1.1 功能操作点击频繁
门诊医生使用的3 个系统功能较多,从呼叫候诊患者鼠标点击叫号功能开始,医生频繁在各种界面点击功能操作,例如在看诊期间需要点击查看检查结果、院外医嘱、电子签名等功能,而很多功能配置在二级菜单中,操作较为烦琐,并且较多功能操作在看诊每名患者时都会进行重复操作。用户界面(user interface,UI)设计的易用性优化已不能满足医生高效看诊的需要。为了快速完成功能选择操作,可通过实现口述语音指令代替键盘和鼠标操作。
1.2 病历录入存在难度
模板化的电子病历虽然在一定程度上方便了医生录入,但有些医生在使用习惯上会对模板进行个性化删减、内容粘贴或在模板元素外录入,这种方式降低了病历录入的效率;专业医学词汇也存在一定录入难度,常见的专业医学词汇有中英文与符号混合词语,例如Hoffmann 征(+),以及计量单位,例如mmol/L。为了更加便捷、准确地完成电子病历的录入,可通过口述语音的人机交互方式完成。
2 关键技术
2.1 语音识别
语音识别的核心是识别引擎的构建,识别引擎构建的过程包括训练和识别2 个部分。训练时对预先收集的海量语音及数据进行信号处理和数据挖掘,以构建所需要的声学模型和语言模型。识别过程的前端部分主要进行端点检测、降噪和特征提取,后端部分利用训练好的声学模型和语言模型对语音的特征向量进行解码,得到其包含的文字信息。语音识别技术路线如图1 所示。
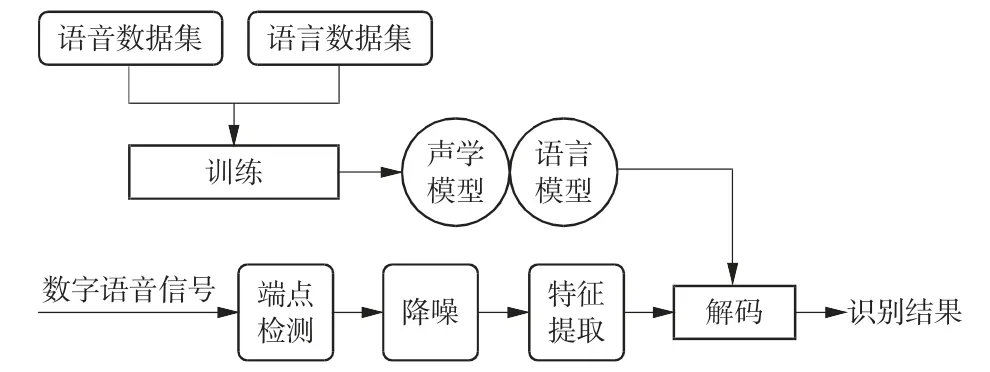
图1 语音识别技术路线图
2.1.1 声学建模
通过深度神经网络(deep neural network,DNN)训练海量医疗场景下的语音数据集,建立语音信号特征与音素之间的映射关系,收集的语音数据包含各种年龄、噪声、环境、内容等,并通过求解既定语言文本下产生对应语音波形概率的最大值建立声学模型。训练及测试集综合考虑多场景应用,以保证通过声学模型测试语音的准确率。
2.1.2 语言建模
收集医疗语言数据集,并依据n-gram 统计模型训练,从而构建语言模型,考虑到n≥3 时存在n-gram 统计模型的稀疏性[14],而且n 值较大会降低计算速度,因此使用较小的n 值训练医疗语言数据集,即基于1-gram 和2-gram 统计模型来预测正确字词产生的最大概率。收集的语言数据集经过充分叠加以覆盖各科室的医学用语、中英文词句、计量单位、数字等,用来保证通过语言模型测试识别的准确率,满足医学专有名词、医学常用计量单位、医学专有特殊符号、医学专用中英文混合单词、医学专有英文简称、罗马数字、希腊字母等的识别,以及全院各专科语音录入特点。采用自然语言处理分词技术建立特定语言模型,自动过滤与医学内容无关的语气助词等内容。
2.1.3 解码
根据上述已经训练好的声学模型和语言模型构建出识别网络后,基于Viterbi 搜索算法在该网络中寻找能够以最大概率输出该语音信号的词串,得到最终识别结果。
2.1.4 口述病历内容识别结果流式显示
识别结果的呈现方式包括流式呈现和非流式呈现2 种,其中流式呈现具有更好的使用体验,由于n-gram 统计模型中第n 个词的概率仅与其前n-1个词的概率有关,因此,这种语言模型默认支持流式呈现。通过n-gram 统计模型得到的识别结果由当前焦点所在的窗口经过Windows 消息通道直接显示。
2.2 多路监听方式集成指令和关键词
语音识别结果可作为语音指令和关键词,通过统一标准的SDK 接口和应用程序进行交互。SDK 接口采用回调函数处理方法监听回调音频数据与错误信息,从而使应用程序与语音录入客户端之间建立注册和注销机制。应用程序启动时通过SDK 接口注册回调函数,当语音口述门诊医生工作站、门诊电子病历系统和门诊产科专科信息系统中的相应功能指令后,语音录入客户端会将事先定义好的这些指令词加载到内存中,并在识别结果中检索这些指令词,当指令词匹配时,语音录入客户端则会将指令词回调发送给门诊医生工作站、门诊电子病历系统或门诊产科专科信息系统并执行相应操作。其中门诊电子病历系统中匹配的关键词则自动定位到相应位置。对于不同程序的相同功能操作,将相同的名称改为同义名称后,语音指令即可按照名称一致性设计原则加以区分,例如门诊医生工作站中口述“预约”,而在门诊产科专科信息系统中则口述“约号”。通过多路监听方式进行系统集成的时序图如图2 所示。
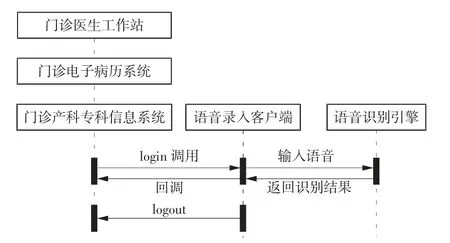
图2 多路监听方式系统集成时序图
3 关键问题
3.1 硬件设备选型
语音识别的关键硬件设备为语音麦克风,本研究采用抗菌材料设计四麦阵列鹅颈式麦克风,通过USB 接口实现供电和数据传输,保证门诊医生使用时的稳定性,同时提供多方位拾音采样,方便后级处理。为避免主说话人以外的人员说话干扰,通过算法实现一定夹角内的定向拾音。
3.2 效果优化
通过提高语音识别准确率优化语音识别效果时,识别准确率受到识别环境场景和识别引擎等因素的影响。识别环境场景因素主要包括环境噪声和无关人员的语音,通过麦克风阵列技术可以减弱这种影响。麦克风阵列技术的核心是由多个麦克风信号产生相位差异,这样就可以通过计算声源方位并对来自医生方向一定夹角的目标声音信号进行增强,进而对其他方位的噪声和无关人员的语音干扰进行抑制。由于不同医疗场景下的专科词汇存在发音相似性,为了充分覆盖各种医疗场景下的语音识别和提高识别准确率,构建识别引擎的语言模型时除了采用通用的医疗训练集以外,还额外对口腔科、中医科、超声科等专科的数据集进行训练,建立专科语言模型,将智能语音应用在上述专科时配置专科识别引擎,以确保识别准确率。
4 功能实现
4.1 语音指令和关键词识别
在使用多个系统时,通过口述指令即可在对应系统中进行功能操作,并且在基于数据元素的结构化电子病历中录入内容时,关键词自动定位到电子病历对应位置,方便替代键盘、鼠标操作。本研究共集成了34 个常用语音指令,覆盖了出诊医生在门诊医生工作站、门诊电子病历系统和门诊产科专科信息系统中高频使用的基本操作,例如界面功能名称为“检验申请”,则语音口述“检验申请”即可实现开具检验申请功能。常用语音指令包括签名、叫号、处方录入等。其中门诊电子病历系统集成了全院通用模板和各科病历模板中常用的11 个关键词,通过口述关键词,病历内容自动定位到关键词位置,并插入口述病历内容;覆盖了不同科室和医生的录入需求,常用的关键词包括主诉、现病史、既往史等。
4.2 语音指令扩展
实现多种口述表达方式可以完成同一指令。通过配置事先定义好的规则映射将差异表达词句转义为特定词句,当语音录入客户端接收到引擎识别的结果匹配所配置的差异表达词句时,语音录入客户端转义为特定词句并执行相应语音指令。例如功能模块为“电子病历”,而有些医生习惯用“写病历”来描述这一操作,这2 种口述方式均可实现打开电子病历这一操作。其中14 个常用语音指令在实际应用中会涉及多种口述方法,因此配置了由其扩展出的60 种不同语料,医生通过多种口述说法均能实现同一功能,满足了指令表达的差异化需求和不同医生的习惯。
4.3 语音医学文本识别
语音口述即可实时在门诊电子病历系统显示医学文本内容,包括词句、计量单位、医学专用中英文混合单词、数字等。其中血压、脉搏等数字串可自动规整,例如口述“心率六十五次每分”,则病历自动写入“心率65 次/分”。
5 应用效果和讨论
2022 年1—3 月将智能语音技术应用于门诊医生工作站、门诊电子病历系统和门诊产科专科信息系统中,期间我院门诊诊室共部署了342 台语音录入客户端,累计274 个诊室的医生使用了智能语音录入,智能语音使用率达80%。使用过智能语音录入的医生人群覆盖了所有门诊的科室,且这些医生普遍在出诊时首选语音进行人机交互。高使用率得益于智能语音的高识别率,通过对比原始音频和识别词句,语音识别准确率达到95%。本研究从语音指令使用、语音病历使用和效率分析3 个方面对智能语音技术的应用效果进行论述。
5.1 语音指令使用情况
34 个语音操控指令中“签名”“打印”“完成”和“叫号”的使用频率最高,累计使用1 614 次。这是由于这4 个指令是诊疗的最后一步,而且每次诊疗都需要重复操作,医生通过一次开启语音,即可在语音录入病历后完成这4 个重复操作,使得医生看诊每位患者时最少省去了4 次鼠标点击。以每位医生平均每个出诊单元(医务人员一次出诊时所在的半个工作日)接诊20 位患者计算,可至少省去80 次鼠标屏幕定位和点击。医生进行业务系统操作时解放了双手,通过口述即可完成相应操作,大大提高了医生进行系统操作的效率。各种指令使用频次占比如图3所示。
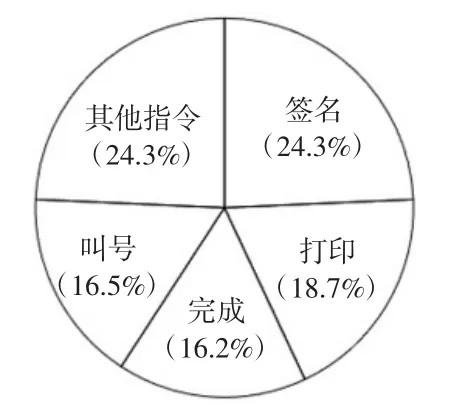
图3 语音指令使用频次占比
5.2 语音病历使用情况
医生通过传统键盘录入初诊患者病历平均需4~5 min,录入复诊患者病历平均需2~3 min,年长的医生花费的时间更多。采用语音录入病历后,即使是年长的医生,平均1 min 即可完成病历的录入,而医生实际出诊的总时长并没有变化,间接反映出通过采用语音录入后,医生将更多的时间和精力留给了患者,提升了医生问诊的质量和患者的就医体验。
选取同年龄段医生20 人,随机分为2 组,每组10 人,一组采用键盘录入病历,另一组采用语音录入病历,分别统计2 组的录入速度,结果如图4 所示。医生习惯和熟练度不同使得录入速度存在较大差异,所以统计录入速度的中位数。相比较键盘录入的26 字/min,语音录入可达172 字/min,语音录入速度是键盘录入速度的6.6 倍。
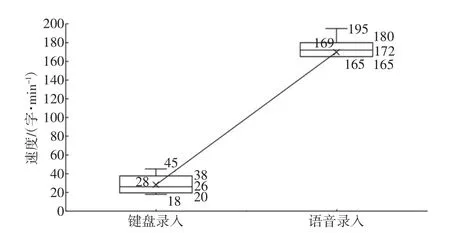
图4 2 种录入方式速度对比
医生普遍反馈进行专业名词、中英混合词汇或复杂计量单位等录入时,无需在传统键盘输入法中查找,大大提高了电子病历的录入速度。
5.3 语音使用效率分析
语音使用效率采用2 种操作方式对比进行分析。随机选取10 名使用语音录入的年龄较大的外科医生,这些医生反馈因键盘操作慢和不够熟练而花费更多精力录入病历,或者其录入操作依靠助手完成。另外随机选取10 名因固有习惯而继续选择使用键盘的年龄较小的同科室医生,这些医生普遍熟练使用键盘打字。监测、统计以上2 类医生在一个出诊单元中分别录入病历的平均数量、平均每份病历录入字符数量以及平均每份病历退改次数(见表1),其中退改次数指删除1 个以上字符的次数。数据表明,在录入病历情况接近的情况下,使用键盘的年轻医生和使用语音的年长医生在病历录入中退改次数比较接近,但后者录入字符数多于前者。这表示年龄较大的医生语音录入病历的效率可以达到熟练使用键盘的年轻医生水平,甚至可以录入更多的内容。

表1 2 种病历录入方式指标对比
5.4 存在问题及解决方法
医生使用智能语音过程中存在语音指令冲突和识别结果偏差的问题,分别通过以下方式解决。
5.4.1 指令区分
门诊医生工作站和门诊电子病历系统存在个别语音识别结果冲突,例如语音录入病历的内容涉及“病理”词汇时,会触发门诊医生工作站中的“病理”指令而启动病理模块。对于此类问题,可通过对语音识别触发词加以区分解决,例如将门诊医生工作站中启动病理模块指令配置为“开具病理”。
5.4.2 词汇替换
由于医生使用习惯差异、专科简称和医学词汇的复杂性,存在个别词汇识别结果不符合实际口述的情况。例如,有些骨科医生习惯使用英文疾病名称表达“Hoffmann 征”而不是“霍夫曼征”;产科医生习惯用“羊穿”表达“羊水穿刺”;有些口腔科医生使用公司产品名称录入“士卓曼”种植体。对于此类特殊使用方式且当前语音引擎未覆盖的情况,一方面积累词汇定期训练、调整语言模型以覆盖更多识别结果;另一方面在客户端增加词汇替换功能配置,通过将识别有误的词汇替换为正确词汇,以便更快捷处理此类问题。
6 结语
通过将智能语音创新性地深度集成到门诊医生工作站、门诊电子病历系统和门诊产科专科信息系统,将新的人机交互模式应用到医生门诊工作中,实现了通过语音指令操控系统、语音定位和语音识别快速录入病历,并且经过推广后在门诊全科室进行了普及,医生反馈良好,有效提高了门诊医生的工作效率,尤其降低了年长的医生操作业务系统时的难度。在实践使用过程中发现由于个别使用人的发音特点,一些语音识别结果与实际表达存在差异,例如识别指令“叫号”和录入的病历内容“较好”识别混淆。这是由于现有的语言模型和声学模型是基于概率进行统计建模,虽然测试训练集能够覆盖绝大部分现有使用的医疗场景,但难以100%覆盖全体人群。下一步拟加入自适应技术解决说话人差异特点导致的不匹配问题,尤其是解决在线状态说话人自适应建模时数据较短、语音表征稳定性差、模型需重新训练等问题[15]。另一方面,当前训练集基于标准普通话模型,未来拟根据医生实际需求划分地区模型,针对特殊口音医生群体需要,按区域语音数据集训练对应模型,构建特殊方言识别引擎。未来将针对智能语音的应用难点不断优化和改进,进一步提升医生诊疗效率。
