基于图像检索构建现代化博物馆可视化应用
2023-06-03郑雯锴田子禾
郑雯锴 田子禾

关键词:文物识别;知识图谱;可视化;画作;前端
中图分类号:TP183 文献标识码:A
文章编号:1009-3044(2023)10-0040-04
0 引言
目前,以数字化博物馆为主体的App通常是对实体物品进行拍照、扫描、建模等方式,将其转化为数字化的电子媒介,并且通过图像、文字、声音及影像等形式进行展示。在这些App进行数据检索大致分为两种方式。第一种是用户自主查询的方式。这种类型的检索方式优点在于,给用户足够多的自主性,可根据自己的意愿去搜索。但是其缺点也很明显,若用户不知道文物的名称或者只知道文物的模糊信息,就无法检索出想要的文物信息。这类检索方式查出来的信息相互之间也没有关系。总体来说,这类检索方式不具备针对性并且效率极低,给用户带来的体验感也不好。该类型App缺少成体系的结构化知识,导致其内容检索更偏向于对文物知识有一定基础的人群。第二种是基于GPS的馆内电子导游型,例如中国国家博物馆的App,这种类型的App有详细的解说,以及较为系统的知识体系,通过声音的方式传递信息给用户,不会妨碍用户正常地观赏文物。通过使用其App,游客可将自己的可移动设备当作讲解器,在需要的地方通过扫码来触发语音讲解功能,甚至通过AR 参与馆内互动。这类App更注重游客在馆内浏览文物时对实体文物的知识介绍,没有将各种实体之间的知识联系起来。而且,这种方式仅限于在博物馆内使用,并对用户移动设备的信号强度以及电池的续航能力要求高。随着人们对知识文化需求的提高,如何以更便捷的方式为用户提供文物知识检索,并在检索的同时为用户提供更多相关联知识,是未来智慧博物馆需要解决的问题。
图像检索和知识图谱技术可以作为解决上述问题有效的技术途径。本文提出一种基于图像检索和知识图谱的现代化博物馆系统设计方案。
1 相关技术
1.1 图像检索
图像检索被广泛用于图像识别等应用领域,其主要实现的步骤如下:首先,对图片特征进行提取;第二,对图片特征信息进行编码;第三,运用匹配算法进行比对。其关键在于图像的编码和匹配算法的设计。本项目采用的是为图片生成一个特定的64位整数,然后将得到的数字和数据库中的数据进行比对,如果不同的位数越少,说明两张图片的相似度越高。在比对的过程中,还会设置一个临界值,笔者设置的临界值为:两个64位整数所相差的位数为10,当超过这个临界值,就说明两张图片的相似度较低,判定为两张不同的图片。
1.2 知识图谱的技术介绍
知识图谱则是把一组数据转换成实体,实体是有属性的,在不同实体之间会存在各种联系。比如西瓜,知道它的属性是水果,那么与它相关联的就有如葡萄、橙子等其他水果,它又是季節性水果,也可以想到与它同季节的水果有哪些,同时西瓜视频还是中国的IT公司,属于视频娱乐性产品,又可以想到如腾讯视频、爱奇艺、优酷等视频娱乐影音类产品,这些关系用传统手段是无法展示出来的,而知识图谱可视化工具可以将它们的联系清晰地展示出来,如同一张网一样,将所能联想到的信息都关联起来,这些数据之间的关系也就简单明了地呈现在眼前。现在知识图谱技术已经很成熟了,最早的知识图谱技术主要应用于搜索引擎。
2 基于图像检索和知识图谱的现代化博物馆系统设计
2.1 系统整体设计思路
本系统的核心目的是根据用户上传的图片进行图像检索,并将文物的信息以及横向信息全部返回给用户。大致流程如图2所示,首先,用户进入界面首页会看到搜索框,在该处可进行文本和图像搜索方式的选择。若进行文本的搜索,可支持文物的作者和文物的名字的搜索;若选择图像的搜索,会从用户本地获取一张图片上传。因为不同用户拍摄的水平不同,拍摄出图片的质量也不同,所以第一步先进行图像处理。其中包括灰度化、二值化、去噪、归一化等一系列操作;第二步进行图像的识别,采用图像感知哈希算法,它会为每一张图片生成其自己特定一个称之为“指纹”的64位整数,然后通过计算汉明距离来检索图像(就是比较不同图片的指纹)。相差的位数越少,就说明图片越相似。将用户上传的图片与图片库进行比较,当结果值非常接近时,即可判定识别成功。并将识别的结果返回。然后根据查询到的结果,到知识图谱中进行查找其关联的信息。最后将知识图谱查询到的内容一并返回给用户。
2.2 知识图谱的构建
2.2.1 概要
本图谱主要基于名画和作者中的关系抽取,数据源于http://www.youhuadaquan.org/和https://www.dpm.org.cn/Home.html本图谱基于LSTM长短期记忆模型,如图3所示,对画家和画作的描述文本进行分类,抽取出画家画作实体和关系,存入neo4j数据库后,通过业务规则描述新的关系。
2.2.2 数据标注
数据的预测类别有7种:
主语开头:B-SUBJECT
主语非开头:I-SUBJECT
谓语开头:B-PREDICATE
谓语非开头:I-PREDICATE
宾语开头:B-OBJECT
宾语非开头:I-OBJECT
其他:O
举例:
凡·高来到法国小镇阿尔,创作了《阿尔的吊桥》,被标注为:
B-SUBJECT I-SUBJECT O O O O O O O O BPREDICATE I-PREDICATE O
B-OBJECT I-OBJECT I-OBJECT I-OBJECT IOBJECT
2.2.3数据预处理
1)词典映射实现包括低频词过滤、字与ID的映射(word2id)、预测类别与ID的映射(lable2id),实现ID-词-类别的映射绑定。
2)从训练文件中获取句子和标签并转化为ID 实现将文件中存储的标签训练集加载到词典中来,通过词典将句子和标注转换为ID,实现句子和标签的离散化,同时,为了保证数据的维度一致,在行向量中进行句子填充。
2.2.4 构建模型
利用PyTorch中RNN的LSTM类,传入数据量,词嵌入和标签的行向量,标签大小等超参数后,利用model等Sequential()函数进行序列化,在CRF层,利用tag参数进行loss函数的构建。最后,将数据集导入模型中训练40个epoch[1]。
2.2.5 图谱存储
利用爬虫[2]引擎scrapy和元素解析引擎jsoup进行数据挖掘,将数据源网站上的文本进行持久化,导入MySQL中,按batch进入模型进行识别,输出形式化结果,利用正则表达式筛选合并后存入CSV文件中,利用neo4j图数据库提供的import工具进行导入和存储。存储的实体类型和属性包括:作品(作品名、作者名、创作时间、类型、图片URL、博物馆名称)、作者(姓名、国籍、出生年份、死亡年份、头像图片URL、描述),关系类型和属性包括:相同时期(SAME_ERA)、相同博物馆(SAME_MUSEUM)、被创作(MADE_BY)、同作者(SAME_MAKER)[1]。如图5、图6所示。
2.3 图像检索方法的设计
2.3.1 感知哈希算法(Perceptual Hash Algorithm)
其主要的功能是给每一张图片生成一个特定的字符串,可以称之为“指纹”。不同的图片会生成不同的特定字符串,就可以用已有的特定字符串,和数据库中图片的特定字符串进行比较,如果比对的值越相似,就会判定两张图片就越相似。具体的实现步骤如下所示:首先,将图片进行缩小,比如将图片缩小为8×8,一共为64个像素。这么做的目的在于,去除具体的细节,只要大概的结构信息(例如明暗信息等),同时也可以排除一些非必要因素对算法的影响,例如用不同大小的图片或者比例相差很大的图片所带来的差异;其次,将其颜色简化,将第一步所得到的图片进行灰度转化,让其所有的像素点只有64种颜色;然后,对这64个像素的灰度平均值进行计算,并将计算得到的结果和每一个像素的灰度值进行比对。假设“1”表示平均值小于等于每个像素的灰度值,“0”表示平均值大于等于每个像素的灰度值;最后,直接计算哈希值,这一步将之前得到的结果和刚才计算的结果进行组合,得到了一张图片的指纹(是一个具有64位的整数)。在组合时,并不用考虑其组合的先后顺序,主要考虑所有的图片是否都是用一种顺序组合的。
根据以上步骤,会为每一张图片生成一个特定的64位整数,当进行图像检索时,只需要为用户上传的图片生成一个特定的64位的整数,用生成的整数来和数据库中的所有64位整数对比,重点关注有多少位置是不一样的。其实质是在计算汉明距离[3]——如果发现两张图片所具有的64位整数不同的位数相差超过10位,就判定为不同的图片;如果这两个整数相差的位数小于等于5,那就说明两张图片相似。
本算法的优点在于能够快速检索出图片,同样也不会受到图片尺寸的影响。当然也有一定缺点,如果对图片内容进行修改,会导致64位的整数和数据库中的数字相差很多的位数,最后导致检索失败。所以,本算法适用于给出缩略图找原图[4]。
3 原型系统实现
3.1 系统框架图
3.1.1 系统架构
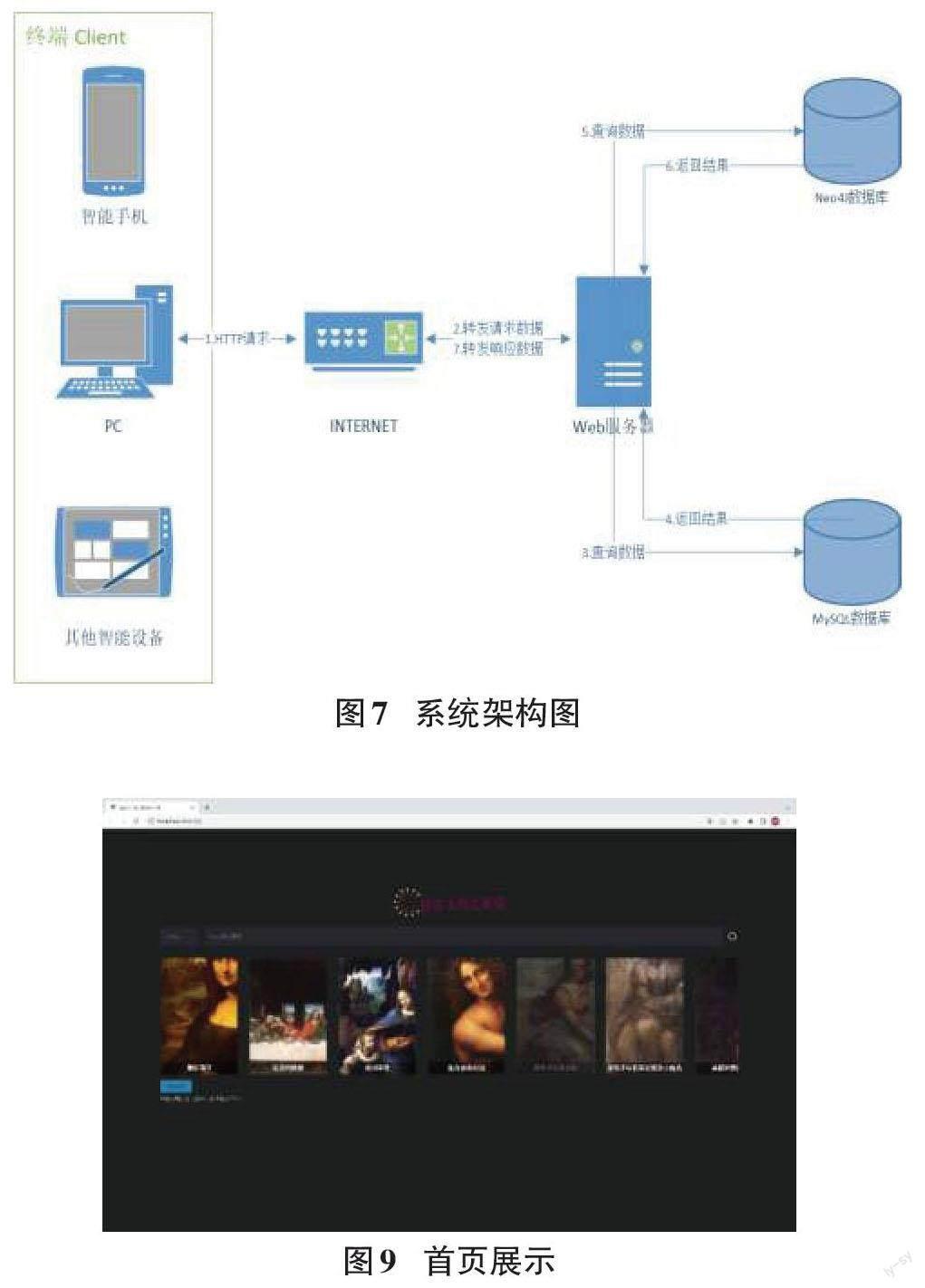
本系统采用B/S架构(Browser/Server)[5],在此架构下,用户通过使用瀏览器浏览,基于HTTP协议提供的服务。Server通过提供api接口的方式响应请求、传递数据,前端通过AJAX发送GET、POST、PUT等请求调用这些API接口,Server接收请求并响应后,前端将数据展示给用户。基于HTTP协议,也可以将Server提供的API接口方便提供给其他平台使用,最终实现跨平台[1]。模式结构如图7所示:
3.1.2 系统环境
1)硬件环境
CPU: 1.4 GHz Inter Core i5 处理器;内存: 8 GB2133 MHz LPDDR3 主板集成内存;图形处理器: IntelIris Plus Graphics 645 图形处理器;外置存储设备:512 GB SSD;操作系统: MacOS Catalina。
2)软件环境
NodeJS 12.18.2、Webpack、Vue 2.6.6、ElementUI2.4.5、Echart 4.8.0、Vue-Axios 2.1.5、Vue-Router 3.4.3、Vue-Cookie 1.1.4。
3.2 原型系统展示
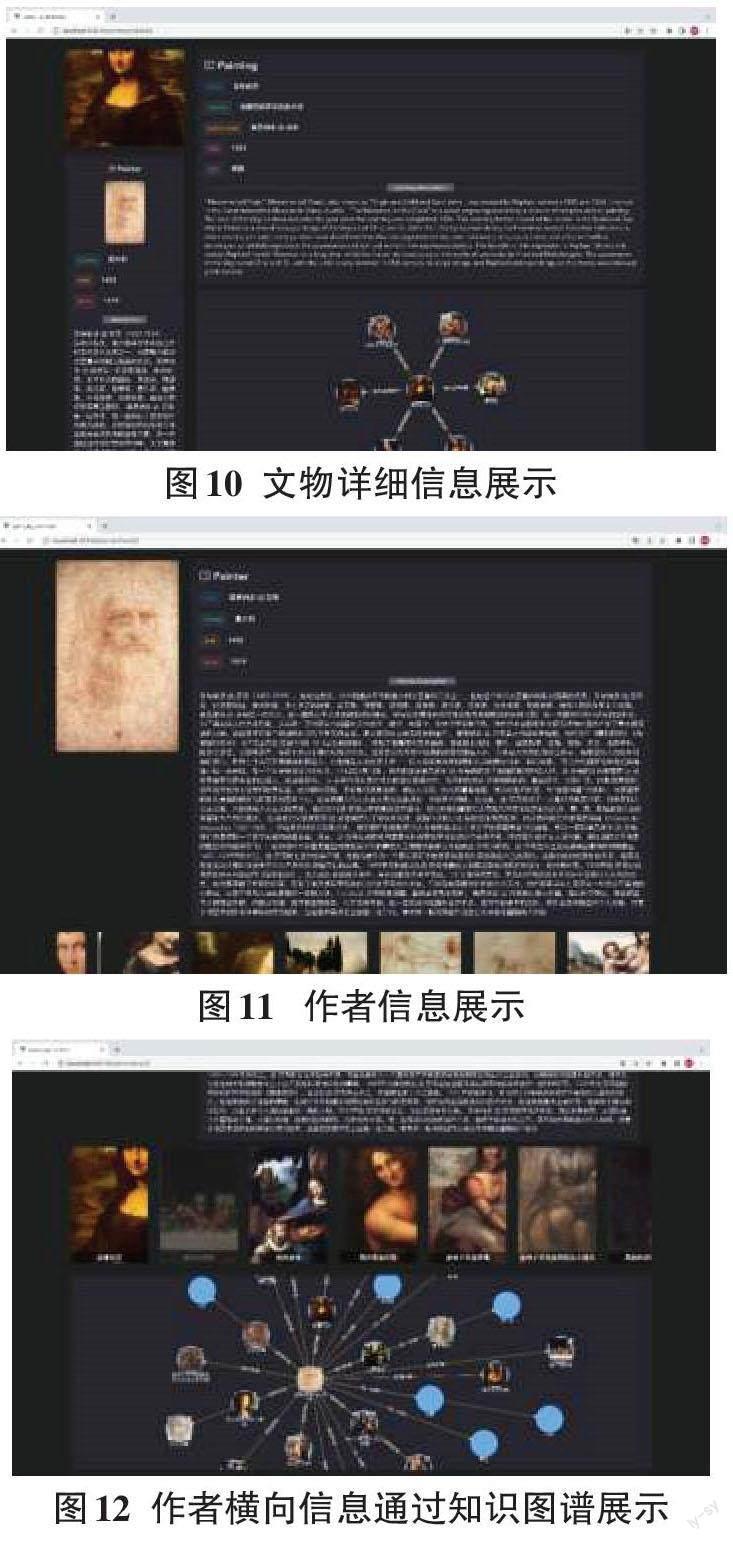
以查询蒙娜丽莎为例,如图9所示,进入首页后,会有点击上传的按钮,点击上传后。跳转到文物信息界面(图10):在这个界面能看到左上角是文物的图片展示;左下方是文物作者信息的介绍;右上方是文物重点信息的介绍以及文物详细信息介绍;右下方是文物的知识图谱展示。如果查询文物的作者,会看到图11、图12的界面。
4 结束语
本文提出了一种基于图像检索和知识图谱的现代化博物馆系统设计方案,并通过原型系统验证了方案的可行性。通过本文的文物识别检索方式,可以通过上传文物图片的方式轻松检索出系统化的知识体系。相比于传统的检索方式以及单一知识的方式,图像识别更便于用户检索,知识图谱关系表达能力更强,并且它能像人一样分析数据。本文只是对该方案进行了初步尝试,目前知识规模较小,后期需要扩展并更深入地分析和发掘文物知识的文化内涵。
