负激励对联邦学习激励机制的影响
——基于演化博弈的角度
2023-06-02刘家凤刘佳萍河北工程大学管理工程与商学院烟台南山学院纺织科学与工程学院
郭 洋 刘家凤 刘佳萍 .河北工程大学管理工程与商学院 .烟台南山学院纺织科学与工程学院
一、引言
随着人工智能和大数据技术快速发展,数据的安全性和隐私性得到越来越多的关注[1]。作为机器学习的新兴范式,联邦学习可在保证参与者数据隐私安全的前提下充分挖掘数据中潜在价值。近年来,联邦学习在医学成像[2]、智能终端[3]以及计算机视觉等领域得到了广泛应用。
但审核机制与监督机制的缺失给参与者提供了破坏联邦学习的机会,提高了联邦学习项目管理难度,给联邦学习项目带来了极大的不稳定性。而负激励可以有效约束参与者的行为,将参与者带给联邦学习项目的不稳定性降到最低,丰富联邦学习项目管理的方法。因此,引入负激励到联邦学习项目管理中,对联邦学习的可持续发展和实际应用具有重要的理论意义和实际价值[4]。然而,参与联邦学习时,参与者不仅需提供设备资源,还会消耗自身的计算资源。若负激励幅度过大,会大幅度降低参与者的积极性,导致项目无法进行。相反则对参与者的约束能力下降,无法维护项目的稳定性,给联邦学习项目管理带来极大的不稳定性。为解决以上问题,利用演化博弈模型动态演化负激励对联邦学习项目稳定性的影响问题,为激励机制的设计提供行之有效的参考意见,丰富负激励理论的发展领域。
二、文献综述
目前针对联邦学习激励机制方面已有一些研究工作。Deng 等[5]发现聚合恶意参与者低质量模型会恶化全局模型质量,提出质量意识激励机制。王鑫等[6]构建以贡献度分配奖励的奖励机制并评估参与者的可靠性,并降低评估结果较差的参与者奖励。Gao 等[7]依据贡献指标和声誉分配奖励,对贡献度较低的恶意行为进行惩罚。考虑以上激励机制在联邦学习中的应用,本文着重分析负激励对激励机制稳定性的影响,为制定激励效果更加稳定的激励机制提供参考意见。
利用演化博弈探究因素的影响已有一定的研究。姚至臻等[8]利用演化博弈探究参与者参与行为转化的影响因素。王道平等[9]构建了不同级别参与者知识交互行为的演化博弈模型,并认为研究对象不同行为策略选择关注的重点因素不同。由于联邦学习项目的复杂性,联邦学习项目组织者和参与者的行为意愿时刻变化,给联邦学习项目带来的影响有利有弊。据此,考虑参与双方有限理性和重复博弈的特点,构建演化博弈模型对负激励对联邦学习激励机制的影响进行动态演化。
三、联邦学习负激励机制演化博弈模型
(一)问题描述和基本假设
考虑联邦学习项目参与双方都是有限理性的,很难通过一次决策就达到最优策略,特别是机器学习领域,由于投资额巨大、数据隐私性强、利益相关者众多等特点,使得其比一般实体项目更加复杂,因此,在参加联邦学习项目期间,组织者和参与者需要通过不断调整参与项目策略直至达到演化稳定的状态。为便于研究的进行,做出以下假设:
假设1:组织者有两种策略选择,其一选择引入负激励(简称“负激励”),指组织者会在项目的实行过程中对提供错误信息的恶意参与者进行直接罚款和降低声誉等级等惩罚性操作。组织者选择“负激励”行为策略的概率为;其二为只实行正激励机制(简称“正激励”),指组织者对参与者的表现只采用正向激励机制,仅根据参与者表现结果给予参与者相应的工资报酬等,组织者选择“正激励”行为策略的概率为。
假设2:参与者有两种选择,其一为积极参与联邦学习项目(简称“积极参与”),即参与者在参与项目时,不隐瞒自身数据,保证投入数据正确,完全诚实的参与联邦学习项目,参与者选择“积极参与”行为策略的概率为;其二为采取恶意行为破坏联邦学习项目(简称“恶意行为”),即参与者选择进行诸如利用较少或错误数据进行本地模型训练,造成本地模型训练提前中止等恶意行为,参与者选择“恶意行为”行为策略的概率为。
假设3:如果组织者选择实行激励机制,并检测到参与者未发生任务失败、中途下车、输入错误信息等恶意行为,会提高参与者声誉等级并对其进行奖励,这会增加参与者声誉收益。
假设4:本文的组织者主要是指组织构建联邦学习模型的领头团体或者公司,并且其对参与者是否实行负激励机制仅取决于负激励机制对项目收益的提升效果和成本负担。参与者主要指拥有联邦学习项目所需数据的个人或团体,其是否实行恶意行为不仅取决于恶意行为带来的额外收益,还需要考虑实行恶意行为的成本。参与者需要一定的声誉才能继续进行项目,这表示参与者不会导致声誉归零,否则带来的成本会剧增。根据现有联邦学习项目的基本设置,本文具体参数及含义如表1 所示。

表1 模型参数和代表含义Table 1 Model parameters and their representation
(二)联邦学习激励机制演化博弈模型构建
根据博弈双方的利益诉求,计算参与者在{恶意行为,积极参与}、组织者在{正激励,负激励}策略集合下,双方主体演化博弈收益并组成演化博弈收益矩阵,如表2所示。
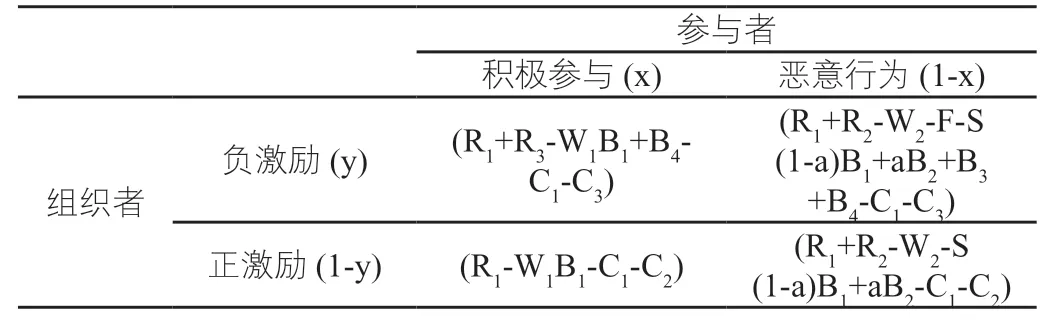
表2 博弈收益矩阵Table 2 Game income matrix

表3 仿真参数数值Table 3 Numerical values of simulation parameters
根据演化博弈利益矩阵,计算博弈双方的复制动态方程,步骤如下:首先,根据利益矩阵计算参与者主体不同策略的期望收益Ex1和Ex2;其次根据期望收益计算参与者主体的平均收益;最后,再根据Malthusian 动态方程构建参与者主体的复制动态方程。参与者主体选择“积极参与”的期望收益为Ex1:
参与者主体选择“恶意行为”行为策略的期望收益为Ex2:
参与者主体根据两种决策行为的期望收益计算平均收益Ex:
根据式(1)—(3),计算可得参与者主体的复制动态方程为:
类比得出组织者主体的复制动态方程为:
(三)策略稳定性分析
根据式(4)和式(5)可组成演化博弈模型的二维动力系统(6)。由组织者和参与者的二维动力系统表示,当F(x)=0和F(y)=0,即选择策略变化率不变时,组织者和参与者选择策略的状态是稳定不变的。由此可得演化博弈模型的五个均衡点,P1(0,0),P2(0,1),P3(1,0),P4(1,1),P5(x*,y*)。
四、模型仿真分析
在本节中,本文在Matlab2018a 环境下对激励机制演化博弈模型进行数值仿真,验证负激励机制的稳定性。为分析参与者和联邦学习组织者不同初始策略和负激励主要参数罚款对系统演化趋势的影响,结合现有的联邦学习激励机制和审核机制设定的成本和利益,工资等初始参数的设定,依据本文参数的具体定义和约束条件给出参数的初始值,在表 3 进行展示。
(一)初始状态对行为演化趋势的影响
演化博弈双方策略的初始状态对于博弈结果会有直观的影响,随着演化进程可以达到稳定演化均衡状态,在不同的初始比例条件下系统演化的波动性和双方收敛到稳定状态的时间都不相同。对均衡点为P4(1,1)的情形进行仿真,此时各参数需满足F+R3+W2+S-W1-R2>0,W2<W1,B4+C2-C3>0,C2<C3。由图1 可知双方主体选择策略的初始比例对系统收敛速度有所影响,当选择策略的初始比例越接近均衡点该系统收敛速度越快。这说明初始策略比例对参与双方是否向(积极参与,奖惩激励)模式出发至关重要。当x=0.1 时,演化达到稳定点的所需时间较长,但组织者较快达到稳定性,这表明组织者急切需要激励机制来解决参与者参与意愿并不强烈或实行恶意行为的问题。与之相对的是x=0.9 的情形下,稳定所需时间较短,表明越早建立激励机制,模型训练过程稳定得也越快。初始比例变换给演化稳定时间的影响,表明负激励机制具备强有力的约束力来监管和激励参与者,从未导致参与者更快更迅速的调整自己的策略。

图1 初始状态对演化结果影响Figure 1 The influence of initial state on evolution results
(二)罚款F 对演化结果的影响
组织者罚款力度F 对参与者行为的影响趋势,如图2所示。随着F 的增加,对参与者策略稳定性有不同程度的影响。
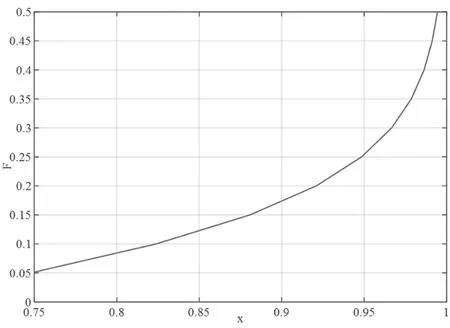
图2 罚款对演化结果影响Figure 2 The influence of penalty on the evolution results
当值减少至0 时,参与者选择“积极参与”策略的概率为0.652 5。表明在没有罚款的情况下,声誉机制对参与者的激励程度为65.25%,即在所有的参与者中,仅有65.25%的参与者会选择激励参与联邦学习项目,其余参与者会选择放弃或实行恶意行为。当时,罚款对参与者策略稳定性的影响较为均匀。随着F 增加F≤0.1,参与者“积极参与”的概率缓慢提高,但增加的幅度较小,极限值为0.823 9。表明罚款与参与者实行恶意行为或不参与项目的隐形收益持平时,最多可保留82.39%的参与者。当0.1≤F≤0.5 时,参与者积极参与联邦学习项目的概率成指数型增加,这表明罚款的增加已经严重影响到参与者不参与联邦学习项目的利益,导致参与者生成巨大的利益落差,进而主动选择积极参与联邦学习项目。但是这种增长是有限度的,当罚款超过0.5 之后,参与人数稳定在99.44%。结合现有的联邦学习项目激励机制经验分析可得,F 的增加提高了组织者实行激励机制的收益,大大降低了组织者的投资风险。但罚款会提高客户的退出或实行恶意行为的成本,能较好地维持训练环境的健康和稳定。同时罚款的稳定也代表着负激励的应用趋向于稳定。
五、结语
本文运用演化博弈理论,构建了激励机制下联邦学习组织者和参与者双方主体的联邦学习演化博弈模型,并结合系统动力学理论,对联邦学习组织者和参与者之间的利益诉求、演化行为、影响因素进行详细分析。研究结果表明:当直接惩罚的罚款增加与参与者的额外收益持平时,可保证82.39%的参与者会积极参与联邦学习程序的训练过程,但过度的惩罚并不会持续增加参与者的激励性,罚款增加对参与者的激励效果在递减。
为促进联邦学习项目各利益主体的协同,本文提出以下建议:(1)作为引导者,联邦学习项目组织者应重视领域声誉带来的收益,勇担责任,积极建设有利于项目进行的奖惩制度机制。负激励机制的建立,不仅实际增加联邦学习模型的利益,而且对自身的声誉和行业认可度的提升也卓有成效。构建和完善对与参与者的监督评判机制,结合声誉机制和惩罚机制,降低奖惩激励机制的建设和运行成本是组织者目前急需进行的工作。(2)参与者应积极提供数据参与联邦学习项目的训练过程。参与者因在联邦学习模型构建过程中处于被动地位,导致自身参与意识不强,搭便车行为和恶意参与行为显著。组织者应加强罚款和声誉损失的管理力度,积极引导参与者参与联邦学习模型训练。参与者应明确自身是联邦学习项目的受益者,对组织者不履行职责的行为进行反馈,充分发挥主动权,积极提供优质数据,促进联邦学习模型的良性循环。囿于自身研究水平和客观条件,本文对联邦学习参与者问题的研究不够全面,只是做了初步探讨,在今后的研究中将基于现有研究做进一步的研究和探讨。具体的研究方向可从构建更加完善的声誉机制和加强对参与者的预先筛选等方面。■
