基于改进深度学习的风机油污识别
2023-06-02李家源曹雪虹焦良葆张智坚
李家源,曹雪虹,焦良葆,2,张智坚,陈 烨
(1.南京工程学院 人工智能产业技术研究院,南京 211167;2.江苏省智能感知技术与装备工程研究中心,南京 211167)
0 引言
随着新能源的发展,风力发电得到广泛应用。只有保证风机机组处于健康状态,才能确保发出稳定持续的电能。油液作为风机设备运转的必备部分,常因地域温差太大、设备结构设计不合理、油封材料质量差等原因造成油污现象的发生,继而对设备运行环境造成影响[1]。油液渗漏过多会影响风机中主轴、偏航轴承、偏航减速器、液压站等设备的正常运行。要保证风机的稳定运行,务必减小油污对风机运行的影响[2],因此对风机进行油污检测具有十分重要的意义。当前风机油污大多靠维护人员定期检测,但人工巡检的质量往往受到巡检经验等因素影响,难以做到有效避免。如能借助目标检测方法实时检测油污,那么油污所产生的负面影响会大大下降。
近年来,随着卷积神经网络的出现,目标检测算法上升到了一个新的高度[3]。基于深度学习的目标检测网络主要有两种,一种是双阶段检测框架如R-CNN(Region based Convolutional Neural Network)、Fast-RCNN(Fast Region based Convolutional Neural Network)。双阶段网络首先产生区域候选框并提取特征,然后产生位置框并预测类别[4]。另一种是单阶段检测框架如SSD (Single Shot MultiBox Detector)与YOLO系列等。单阶段网络流程简单直接产生物体类别率及位置情况,单次检测即可完成,检测速度较快[5]。在单阶段网络检测油污中,武建华等人使用Mobilenet-SSD深度网络模型检测识别变电站设备油液渗漏并经过部署证明了模型的实用性[6]。李跃华等人基于Yolov3模型识别油液渗漏现象,在边缘设备使用模型进行实时检测,取得了较好的效果[7]。
基于深度学习的目标检测算法对检测图片样本要求较高,一旦检测目标重叠复杂或检测环境差,检测效果便不太理想。因此针对检测出现的问题,只有将检测算法进一步改进,才能满足实际的应用[8]。针对检测目标重叠漏检问题,杨喻涵将Soft-NMS与 Faster R-CNN算法相结合,降低了目标的漏检误检率,进一步提高了检测精度[9]。根据特征融合不充分问题,陈一潇等人引入CA注意力机制,在考虑通道关系的同时兼顾长距离位置关系,增强了模型对目标的捕捉定位能力,进一步提高了精度[10]。李阳等人提出CA与YOLOv4相结合检测肺结核数据,增强了数据特征提取与数据融合,网络检测精度得到了提升[11]。对于目标检测中边界框检测精度较低等问题,陈兆凡等提出了改进边框损失函数的方法,加入惩罚项对IoU损失函数进行修正,提升了模型的回归精度[12]。
为了有效解决油污因目标混乱、油液浓度低、光线不足等引起的检测效果下滑的问题,本文通过构建风机液压站,偏航齿圈,偏航轴承集油槽油液渗漏数据库,在YOLOv5n算法的基础上,对网络骨干部分及后处理部分进行改进,通过多组对比消融实验,根据模型评价指标验证改进后模型的有效性,以便更好地运用模型检测风机油污。
1 YOLOv5n网络结构
YOLOv5家族包括5个成员,分别是YOLO5s、YOL-Ov5m、YOLOv5l、YOLOv5x、YOLOv5n。每种网络的深度宽度都不相同。其中,YOLOv5n的模型总参数最小,更具轻量化。随着YOLOv5版本的不断迭代,YOLOv5-6.0版本在5.0的基础上集成了新特性,微调了网络结构,减少了总参数,提高了运行速度。
YOLOv5n网络结构由输入端、骨干、颈部、头部组成,其网络结构图如图1所示。首先,使用Mosaic方法对输入数据进行数据增强,使用自适应缩放操作根据输入图像尺寸大小的不同进行自适应填充,提升了推理速度。骨干部分主要包括Focus、CBS (Conv (Convolution)+ BN (Batch Normalization)+ SiLU (Sigmoid Weighted Liner Unit))、C3和SPPF (Spatial Pyramid Pooling Fast)等模块。Focus模块是YOLOv5旧版本中的一个模块,核心部分是对图片进行切片操作,减小图片的高度和宽度,并通过Concat将其整合,其次对整合后的图像通过大小为 3,步长为 2 的 Conv 卷积模块进行特征提取,此模块加强了图片特征提取的质量。6.0版本使用了尺寸大小为6×6,步长为2,padding为2的卷积核代替了5.0版本的Focus模块,便于模型的导出,而且效率高。与之前的BottleneckCSP(Bottleneck Cross Stage Partial)模块不同,YOLOv5-6.0中使用了C3模块(图1用CSP1表示),包含着3个标准卷积层以及多个残差模块,C3模块去掉了残差模块所在支路输出后的Conv模块。在骨干最后,SPPF(Spatial Pyramid Pooling-Fast)结构将输入串行通过多个MaxPool层,替代SPP(Spatial Pyramid Pooling)模块中将输入并行通过多个不同大小的MaxPool层,进一步提高了效率。颈部采用 CSP2 模块减少模型参数量,CSP2与Backbone中CSP1的区别是将残差模块变为CBS模块。Neck层使用FPN(Feature Pyramid Network)与PANet(Path Aggregation Network)相结合的结构,使用 CSP2_X,相当于CBS将主干网络输出分为两个分支然后再连接,增强了网络的特征融合能力。头部包含3个检测层,对颈部3种不同尺度特征图,通过卷积操作,最终得到3个大小不同的特征图。特征图上生成类别概率,置信度得分和包围框的输出向量。
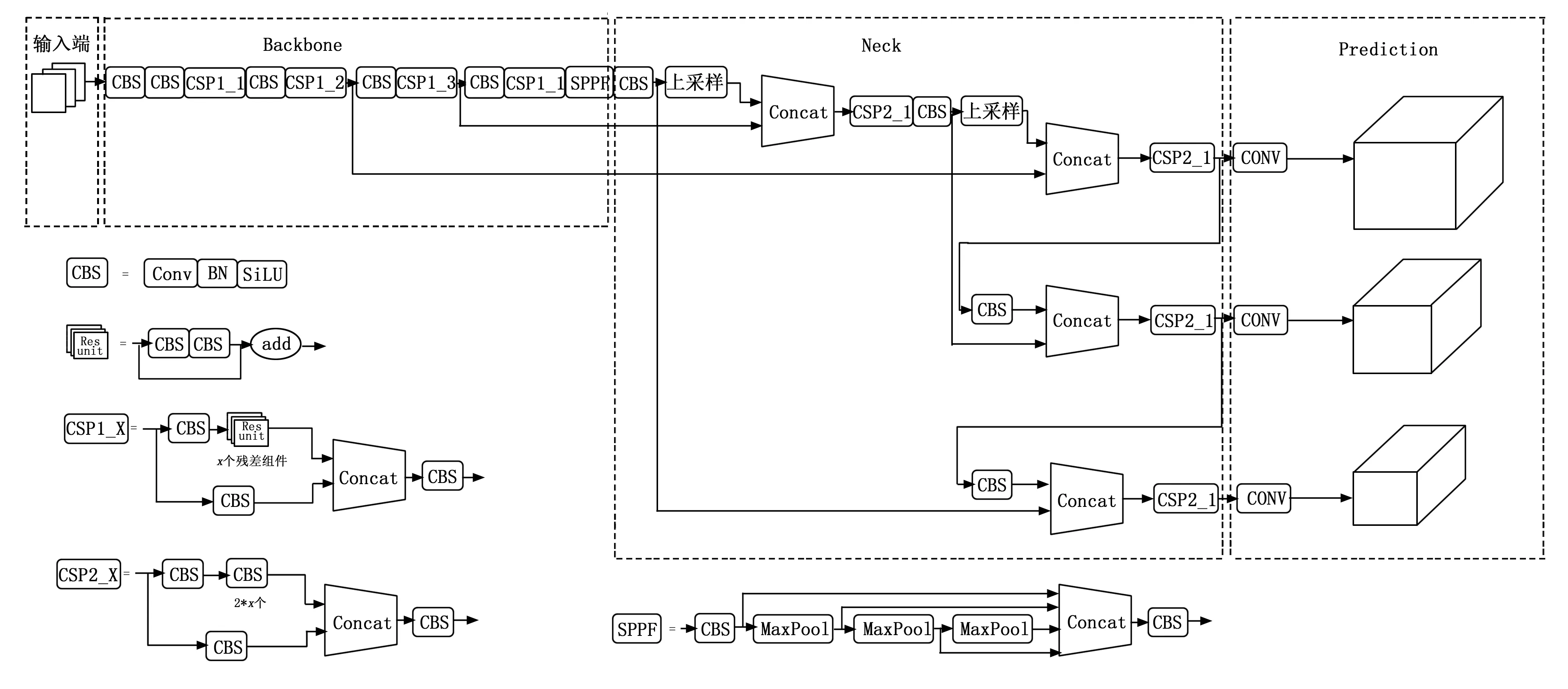
图1 YOLOv5n网络结构图
2 YOLOv5n改进策略
2.1 改进NMS为Soft-NMS
针对YOLOv5n算法遇到重叠或者距离较近的油污目标时存在漏检而影响检测效果的问题,使用Soft-NMS算法对YOLOv5n进行改进[13]。作为目标检测重要的后处理部分,NMS的目的是将目标的重复预测边界框合并或者选取最好的框。YOLOv5n默认使用NMS算法通过IoU选出候选框,IoU又名交并比,用来判断真实框与预测框的重合度。IoU如公式(1)所示,式中A、B分别代表真实框与预测框,IoU计算值越高,A、B框重合程度就越高,预测越准确,模型精度也相应越高,反之亦然。
(1)
NMS算法是一个寻找局部最大值的过程,第一步从所有候选框中选取了某一个置信度最高的预测边界框作为基本框,然后删除了周边与基本框的IoU超过预定阈值的边界框,接下来迭代与第一次相同,直到找到目标区域为止。NMS原理表达式如公式(2)所示。
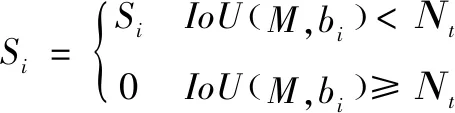
(2)
其中:Si代表了每个边框的得分,M为当前得分最高的框,bi为剩余框中的某一个框,Nt为设定的阈值,IoU(M,bi)为最高分框M与剩余框bi的交并比值。当所得值小于阈值时保留分数,反之,删除bi框并将其分数归0。NMS的实现原理使得整个检测过程具有以下缺点:删除与基本框交并比值超过阈值的边界框使得出现在重复区域的目标检测物检测失败,总的检测成功率会下降。此外,阈值的选定对检测的准确率具有很大的影响。
针对NMS呈现出的问题,采用Soft-NMS进行改进,Soft-NMS算法[14]对与基本框交并值大于阈值的候选框不直接删除,而对原分数进行函数运算,用较低的分数代替原来的高分数。Soft-NMS有线性和高斯两种表达式,线性表达式如公式(3)所示。
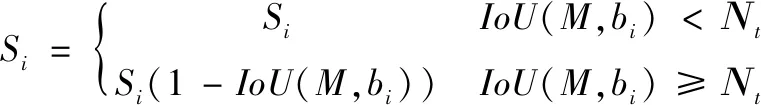
(3)
由于线性不连续,所以高斯较为常用,高斯表达式如公式(4)所示。
Si=Sie-IoU(M,bi)2/σ,∀bi∉D
(4)
式(4)中D代表最终存放结果框,σ代表加权系数,取0.3。使用Soft-NMS算法后能有效解决重叠目标的漏检问题,有效提升网络的检测精度。
2.2 添加注意力机制CA
Hou Q[15]等提出了一个轻量型的注意力模块,将其称为“Coordinate Attention”(简称CA)。CA注意力机制将横纵方向的位置信息编码到通道信息,能够在考虑通道间关系的同时考虑到长距离的位置信息。因此CA注意力机制的加入能使得网络在不增加大量计算量的同时能够关注大范围的位置信息,以此增强模型的目标定位能力。
CA模块可视作增强移动网络特征表达能力的计算单元,它可以对网络中的任意中间特征张量作为输入然后输出大小相同的增强特征[16]。CA注意力机制具体结构如图2所示。
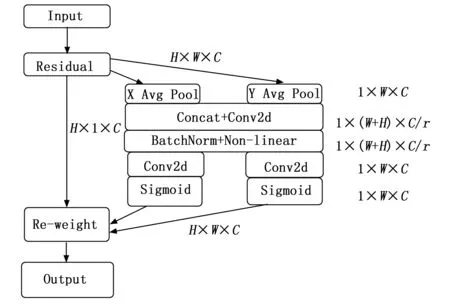
图2 CA注意力模块结构图
CA模块首先使用池化核(H,1)、(1,W)将输入信息沿水平垂直两个方向对每个通道分别编码,将坐标信息嵌入对应图中X AvgPool与Y AvgPool两部分。该过程允许注意力块在捕捉单方向上的长距离关系的同时保留另一个方向上的空间信息,增强网络定位目标的准确性。接着将一对方向可知的特征图拼接在一起,使用1×1卷积模块将其维度降低为原来的C/r,然后使用BN批量化归一处理,再送入Sigmoid 激活函数得到包含横纵空间信息且维度为1×(W+H)×C/r的中间特征。该过程将两个方向特征连接在一起进行特征转化主要为了统一的BN操作,未将两个方向的特征进行强烈的融合。接着将中间特征分为两个方向独立特征,经过两个1×1卷积和Sigmoid激活函数进行特征转化,分别得到特征图在两个方向的注意力权重,并使其维度与输入保持一致,最后将特征权重乘法加权在输出特征上。
相比与忽视位置信息单考虑通道信息的SE (Squeeze-and-Excitation)模块以及缺乏长距离信息提取能力的CBAM (Convolutional Block Attention Module)模块,CA模块不仅获取了通道间信息,还考虑了方向相关的位置信息[17]。此外足够灵活和轻量的特征使其能够简单地插入移动网络的核心结构中。本文将CA模块加入YOLOv5n网络中Backbone部分的SPPF层前面。通过实验发现,CA模块的加入可有效提高模型的检测精度。
2.3 将损失函数修改为α-IoU
目标检测网络对特征图上的每个网格进行预测,并对比预测信息与真实信息,以便为下一步的收敛方向做指导。损失函数用来判断以上两种信息的差距,若预测信息越接近真实信息,则损失函数值越小。YOLOv5使用CIoU(Complete Intersection over Union)[18]计算边界框损失,CIoU损失函数没有考虑真实框与预测框方向不匹配的问题导致推理速度较慢,效率较低。CIoU的损失计算公式如式(5)。
(5)
式中,b表示预测中心坐标,bgt表示真实框中心坐标,ρ代表b、bgt之间的欧式距离,α是平衡比例的参数,它的表达式如式(6)。
(6)
v用来衡量预测框与真实框的高和宽之间的比例的一致性,表达式如式(7)。
(7)
式中,wgt、hgt分别代表真实框的宽度、高度,w、h分别代表预测框的宽度、高度。
针对CIoU损失函数出现的问题,J He[19]等人提出一种新的power IoU损失函数,称为α-IoU。该损失函数将基于IoU的现有损失统一幂化,并通过加上额外的power正则化项推广到更一般的形式,从而得到一个新的power IoU损失函数以获得更准确的边界框回归和目标检测。power参数α可作为调节α-IoU损失的超参数以满足不同水平的回归精度,此次实验将α值设为3。在α-IoU损失函数公式中只列举α-IoU、α-CIoU损失函数如公式(8)~(9)所示。
Lα-IoU=1-IoUα
(8)
(9)
式中,α、β代表权重参数,c表示最小闭包对角线的长度,其余物理量与式(5)相同。
α-IoU损失可以很容易地用于改进检测器的效果[20],对小数据集和噪声的鲁棒性更强,统一幂化可以增大梯度加速收敛,网络的推理速度得到进一步缩短。
3 实验结果与分析
3.1 模型的训练
本次模型训练平台搭建在GPU运算服务器上,硬件配置如表1所示。
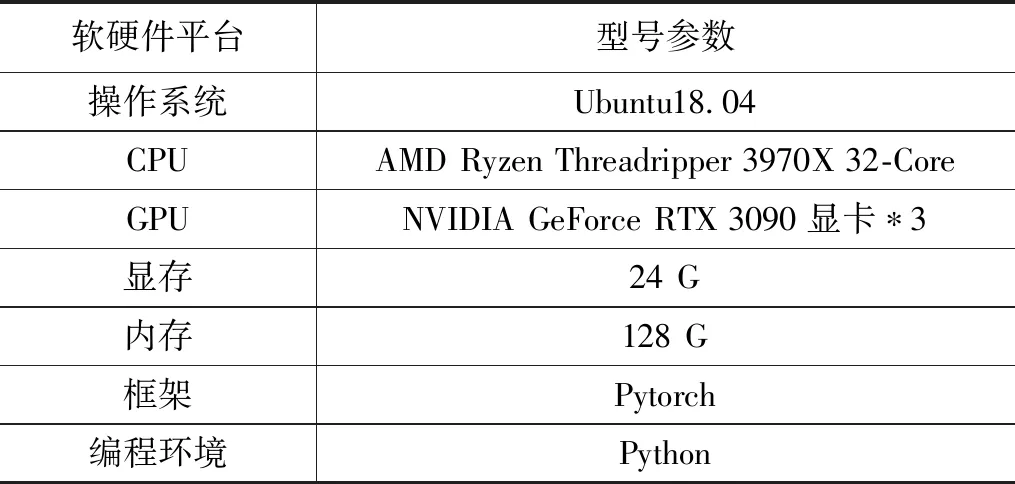
表1 硬件参数配置
为了保证实验的对比性,本次实验均在此台GPU运算服务器上进行,所有训练参数都保证一致,训练参数如下:不加预训练权重,统一输入图片尺寸Img-Size为640×640,迭代次数epochs设置为300,batch-size设置为16,调用3个GPU,iou阈值为0.5。
3.2 数据集的构建
数据集的准备过程在基于深度学习的目标检测算法中极为重要。为了保证训练后模型具有较好的泛化能力,在风机中分别收集不同光照强度、油液浓度下的易漏油设备如液压站,偏航齿圈,偏航减速器的油液渗漏图像共计1 073张,其中数据集原图如图3所示。

图3 风机设备油污数据图
本文将待检测油污设备分三类,分别为液压站,偏航齿圈,偏轴轴承,按照对应标签进行标注,液压站为oil,偏航齿圈为circle,主轴轴承为axle,采用软件LabelImg对所得到的数据图进行人工标记,标注完的信息以xml的格式保存在相同路径下。在数据集中随机选取580张作为训练集,200张作为验证集,293张作为测试集。各类数据具体分配如表2。
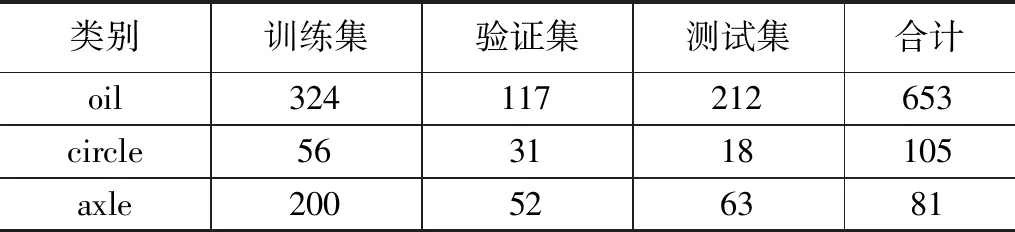
表2 数据集准备
3.3 模型评价指标介绍
对训练模型结果进行评估时,具有衡量模型泛化能力的评价指标与科学的实验估计方法具有同等的重要性。此次实验的评价指标有模型参数量、训练所得权重文件大小、模型训练速度、推理时间,查全率R、查准率P和平均精度均值(mAP,mean average precision)。
训练速度可根据整个训练消耗时间除以迭代完成轮数计算,推理时间表示模型对每张图的推理时间。查全率R也称召回率表示在全部真实正样本中,预测真正目标的概率,用来评估目标检测模型找的是否完整。查准率P也称精确率表示在全部预测正样本中,预测真正目标的概率,用来评估目标检测模型找的是否精确。mAP表示各类检测器分别用R和P作为横纵轴作图后围成的面积总占比的平均值。mAP@.5表示阈值大于0.5的mAP。
实验观察R、P的波动情况,两者是一对矛盾的概念,在保证不下降的前提下,观察mAP值来判断模型的精度。mAP指标越高,说明模型的检测性能越强。
3.4 实验结果
3.4.1 不同网络模型实验
通过与其他目标检测算法的对比,可以凸显出YOLOv5n网络的优越性,用于对比实验的目标检测算法有YOLOv3、YOLOv3-tiny(表中用YOLOv3t表示)、YOLOv5x,YOLOv5s。使用相同的数据集,相同的实验平台,相同的训练参数,只改变网络模型。最终根据模型评价指标综合评价各个模型,对比结果如表3。由表3可知,YOLOv3、YOLOv5x模型参数量大,训练速度、推理时间耗时长。YOLOv3-tiny在YOLOv3的基础上轻量化,训练速度与推理时间最短,但其网络模型精度最低,mAP值低于75。YOLOv5s的查准率与精度值最高但由于参数量较高,推理时间相较于Yolov5n来说较长。YOLOv5n的参数量及权重文件大小最少,参数量是其他对比模型的20.2%~28.6%,精度与YOLOv5s相比,差别甚小,具有较快的训练速度与推理速度。对比可知,从速度与精确度方面考虑,改进YOLOv5n网络是最好的选择。
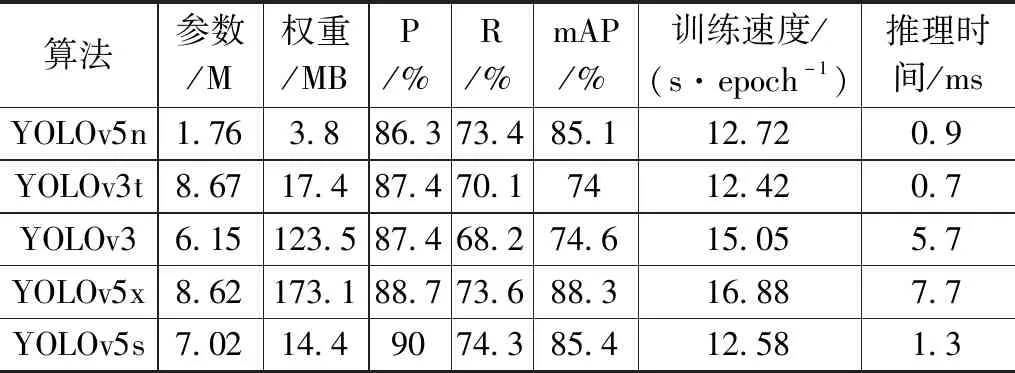
表3 不同网络对比实验
3.4.2 注意力机制实验
本文尝试将注意力机制加入YOLOv5n模型中的Backbone部分,本次实验分别对比加入CBAM、(ECA,efficient channel attention)、CA注意力机制后根据评价指标评价各个模型,加入注意力机制对比实验如表4所示。由表4可见,加入CA注意力机制后网络精度提升最高、推理时间最短。在四组模型中,只有加入CA后,查准率与查全率均达到了80%以上。可见,CA可以作为添加注意力机制改进网络模型的最优选择。
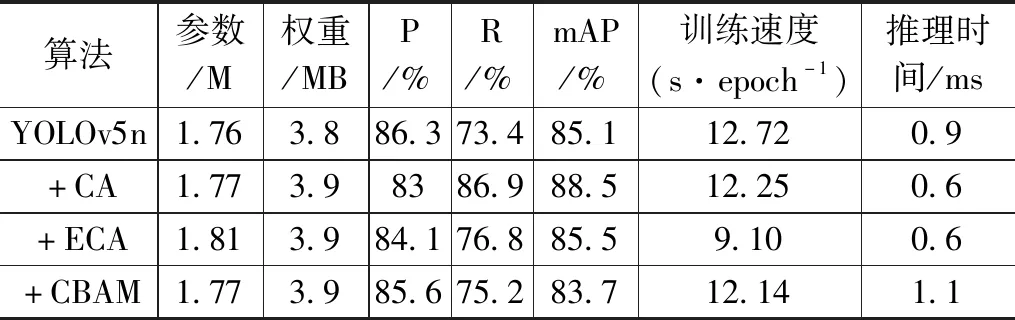
表4 加入注意力机制对比实验
3.4.3 损失函数实验
本文尝试改进YOLOv5n模型中的损失函数,原YOLOv5n损失函数为CIoU,此次实验通过对比(EIoU,efficient intersection over union)、(SIoU,scylla intersection over union)、α-IoU,根据评价指标对比更换各损失函数后模型的效果,改进损失函数对比实验表如表5所示。由表5可知,在参数量与权重文件大小维持不变的情况下,EIoU的推理时间与训练速度最快,但精度值下降了1.6个百分点。对比CIoU、SIoU,损失函数改为α-IoU,虽推理时间略有下降,但查准率、查全率、精度大幅提升,对比原CIoU损失函数分别提升了2.78%、15.3%、5.7%。综上,将损失函数改为α-IoU效果对网络精度的提升最明显。
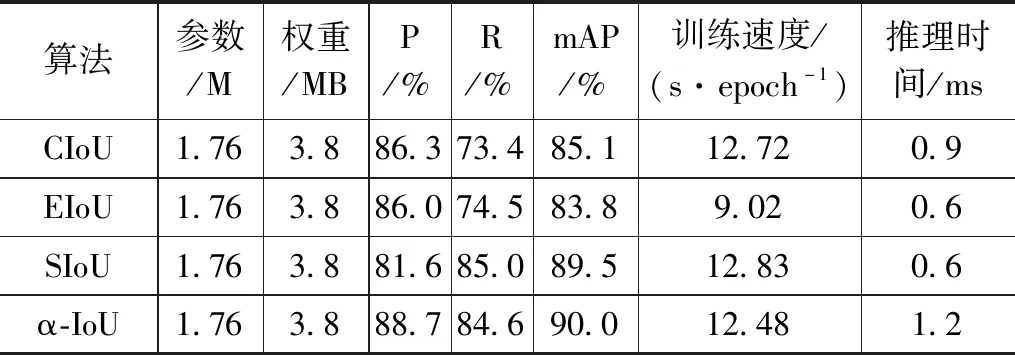
表5 改进损失函数对比实验
3.4.4 消融实验
此实验基于原网络通过加入注意力机制CA、改进输出端NMS为Soft-NMS,改进损失函数为α-IoU,分别单独加入特定模块、组合加入模块,做消融实验。消融实验表如表6所示。由表6可知,对比原YOLOv5n网络,加入CA可以将网络精度提高4%,改进Soft-NMS可以提高5.29%,同时加入CA并改进Soft-NMS将mAP值提高了5.34%,在此基础上,将损失函数更换为α-loss,网络精度提高到92%,相比原始模型提高了8.1个百分点,此外网络查全率提高到87.4%,网络的推理速度提高了28.6%。综上,原网络在三者同时改进的情况下,网络的检测效果提升最大。

表6 消融实验
为了凸显网络改进效果的直观性,列举改进前后网络的检测效果图,检测效果图如图4所示,左图(a)代表原网络检测效果图、右图(b)代表改进后网络检测效果图。由图4(a)可见,原网络在检测过程中油污漏检问题较为严重,油污目标混乱复杂检测难度较高,部分油污难以完整识别。将模型进行改进后,由图4(b)可见,模型对油污的识别能力明显增强,检测到的油污较为完整,同时置信度明显增加,检测精度显著提高。

图4 改进前后网络检测效果对比图
4 结束语
针对现有风机油污目标混乱、检测环境复杂等引起的油污检测效果下降的问题,本文提出了一种基于改进YOLOv5n的油污检测算法。本文的主要工作如下:
1)改进YOLOv5n的NMS结构为Soft-NMS,有效解决重叠目标的漏检问题;添加CA注意力机制,在保证精度的基础上增强网络对目标的识别定位能力;更换损失函数为α-IoU损失函数,统一幂化增大梯度加速收敛,加快网络的推理速度;
2)实验结果表明,本文改进的模型精度达到92%,推理速度达到0.7 ms,在不增加参数量的同时,模型的精度速度都得到了提升。后续工作可将改进后的轻量化模型部署在边缘计算设备上,搭建于风机机舱实际应用场景,进一步优化检测环节,全方面提升模型对风机油污的检测效果。
