基于改进YOLOv5的电厂人员吸烟检测
2023-06-02王彦生曹雪虹焦良葆孙宏伟
王彦生,曹雪虹,焦良葆,2,孙宏伟,高 阳
(1.南京工程学院 人工智能产业技术研究院,南京 211167;2.江苏省智能感知技术与装备工程研究中心,南京 211167)
0 引言
如今,随着用电负荷的不断增加,为了保证供电的可靠性,发电厂的安全运行至关重要[1]。大多数发电厂内的设备仪器日常养护需要使用各种润滑油,这些润滑油遇到明火极易引起火灾,从而引发重大安全事故。因此需要规范约束工作人员的日常吸烟行为,对违规吸烟行为进行监测警告。在日常生活中,我们通常依靠烟雾报警器来监测吸烟行为,该方法依靠传感器技术对空气进行实时采样,尽管其检测精度较高,但该方法无法准确判断是人为原因还是其他原因导致报警,满足不了实时控烟的要求[2]。因此,为了及时发现电厂中有无人员违规吸烟,方便管理者对电厂内人员进行高效的管理,有必要采用有效的目标检测方法,通过视频监控电厂工作环境下的违规吸烟行为,防止发生火灾火险。
近年来,深度学习在目标检测领域的应用愈发广泛[3]。目前基于深度学习的目标检测方法主要分为两类,一类是以R-CNN(region-based convolutional neural network)、Fast R-CNN(Fast Region-based Convolutional Network)、Faster R-CNN(Faster Region-based Convolutional Network)等为典型代表的双阶段目标检测算法[4],这种检测方法的主要思路是先预设一个可能包含待检测物体的预选框,再通过卷积神经网络进行样本分类计算;另一类则是以YOLO(You Only Look Once)系列、SSD[5](Single shot multi-box detector)等为典型代表的单阶段目标检测算法[6],与双阶段目标检测算法不同的是,这种方法不用生成预选框,而是直接在网络中提取特征值来分类目标和定位,因此这种算法检测速度快,检测精度也很高[7]。目前对于吸烟行为检测的目标检测方法主要以Faster R-CNN和YOLO系列为基础,文献[8]通过检测人脸,在人脸检测的基础上再利用Faster R-CNN算法检测烟支,从而提高检测速度并降低误检率。文献[9]通过改进YOLOv3中的损失函数实现检测速度和精度的提升,但该算法模型复杂度较高,缺乏应用价值。文献[10]通过YOLOv4检测算法和人体关键点结合进行吸烟检测以提高检测精度,尽管其在近距离条件下效果较好,但是当人距离监控较远时误测严重。
针对吸烟行为检测精度较低的问题,本文以YOLOv5 6.0版本中的YOLOv5s算法为基础,通过修改网络结构和添加相关模块,在保持网络轻量化的同时,有效提升吸烟行为检测精度,具有较高的实用价值。
1 YOLOv5网络介绍
整个YOLOv5网络可以分为4个部分,分别是输入端、骨干网络Backbone、强特征提取网络Neck以及预测网络Prediction[11]。YOLOv5 6.0版本的具体结构如图1所示。
YOLOv5 6.0版本的输入端与之前的5.0版本一样,采用Mosaic数据增强、自适应锚框计算和自适应图片缩放。
6.0版本在主干网络Backbone中与5.0版本有所不同,6.0版本使用一个卷积(Convolution,Conv)替换了5.0版本Backbone中的Focus层,其目的是为了方便模型导出。此外还使用了CSP结构,简称C3模块,在YOLOv5中有两种CSP结构,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中,CSP1_X将输入分为两个分支,一个分支先通过CBS(Conv+BN(Batch Normalization)+SiLU(Sigmoid Weighted Liner Unit)),再经过多个残差结构(Bottleneck×N),另一个分支则只进行CBS,然后两个分支进行Concat,最后再进行一个CBS。CSP2_X与CSP1_X唯一的不同是CSP2_X用CBS替换了CSP1_X中的残差结构。对比普通的CBS,CSP结构分为两个支路,有支路就意味着特征的融合,而Concat就可以更好的把不同支路的特征信息保留下来,因此CSP的设计可以提取到更为丰富的特征信息。在Backbone的最后采用SPPF(Spatial Pyramid Pooling Fast)的结构,即空间金字塔池化,SPPF结构将输入串行通过多个MaxPool层,从而融合不同感受野的特征图,丰富特征图的表达能力,进一步提高运行速度。
在网络的Neck部分,沿用了FPN(Feature Pyramid Network)+PAN(Path Aggregation Network)的结构,FPN结构以自顶向下的方式构建出高级语义特征图,PAN又加入了自底向上的路线,弥补并加强了定位信息[12]。此外,使用CBS结构来进一步加强网络特征融合。
预测网络Prediction的工作就是对特征点进行判断,判断特征点是否有物体与其对应。
2 改进策略
2.1 多头注意力机制
UC Berkeley和Google基于Transformers结构设计了一种结构简单、功能强大的Backbone,名为BoTNet[13],其改变是将ResNet(Residual Network)中的3×3卷积替换为多头注意力层(Multi-Head Self-Attention,MHSA),其具体结构如图2(a)(b)所示,具体的MHSA层如图3所示。
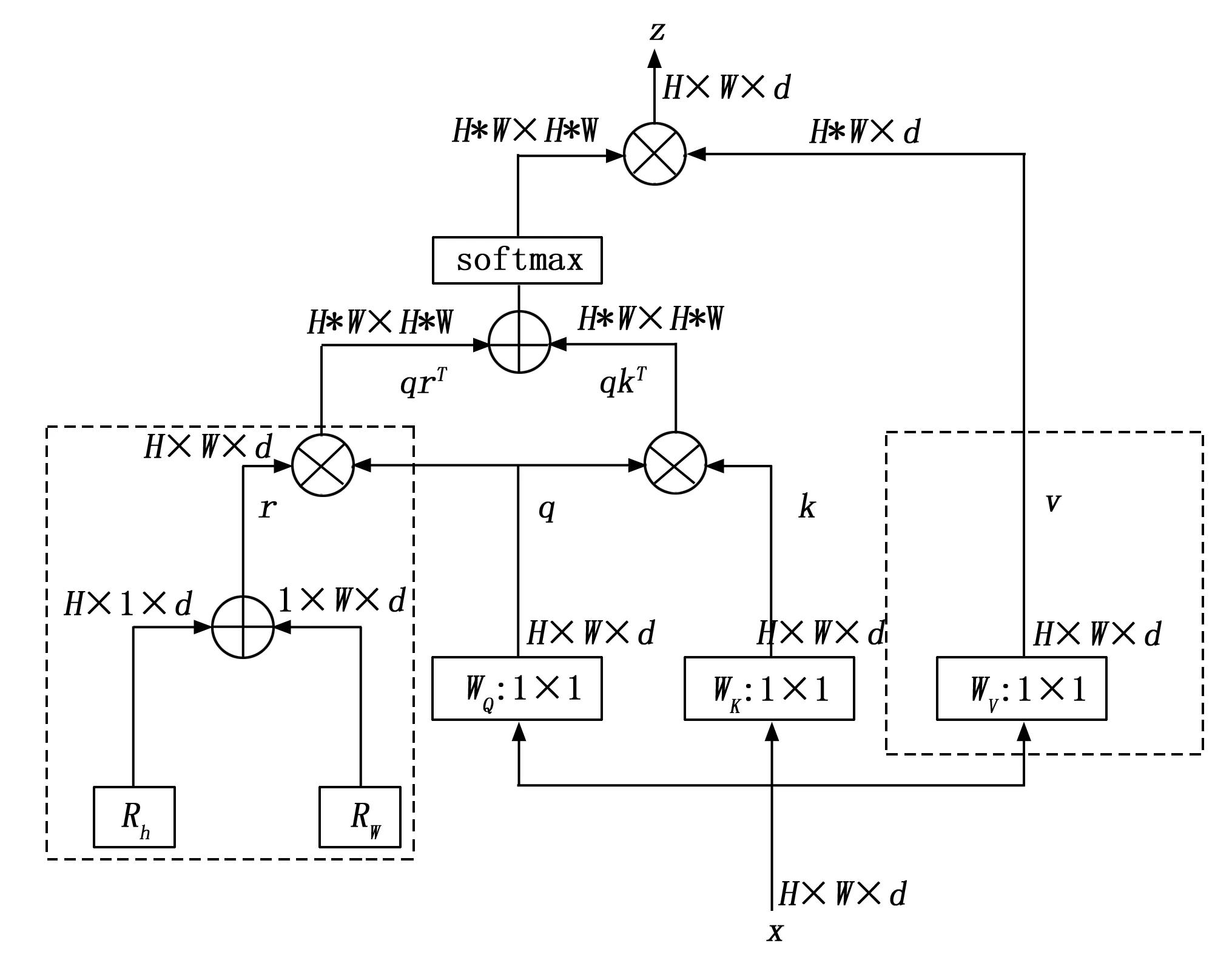
图3 MHSA层网络结构
由上图3可知,MHSA的输入尺寸为H×W×d,分别表示输入特征矩阵的高宽以及单个token的维度,token的数量即为H×W。首先是初始化两个可学习的参数向量Rh、Rw,分别表示高度和宽度不同位置的位置编码,然后将它们通过广播机制加起来,即位置的编码为Rhi+Rwj的两个d维向量相加,这样做将H×W×d个编码简化为(H+W)×d。此外,位置编码也不是直接加到输入上,而是与query矩阵进行矩阵乘法得到Attention的一部分,从而可以从多个维度提炼特征信息,最后将其与query和key算出来的加和后经过 softmax得到最终的Attention。
卷积神经网络YOLOv5通过堆叠卷积层来放大感受野,进而增强网络性能,但是卷积神经网络只关注图像局部,无法兼顾图像全局。为此本文将YOLOv5s网络Backbone和Neck中C3模块的3×3卷积替换为MHSA,使YOLOv5s网络可以关注图像全局,并且能够基于相同的注意力机制学习到不同的行为,提高算法的学习能力,进而提高检测精度[14]。由于Backbone和Neck中C3模块Bottleneck结构不一样,因此图4分别展示了两个部分具体的替换过程,将替换后的结构命名为BottleneckTransformer,最终替换后的结构如图4(d)和(h)所示,替换后的结构与原网络C3模块相比,唯一不同的就是将Bottleneck模块替换成了BottleneckTransformer。
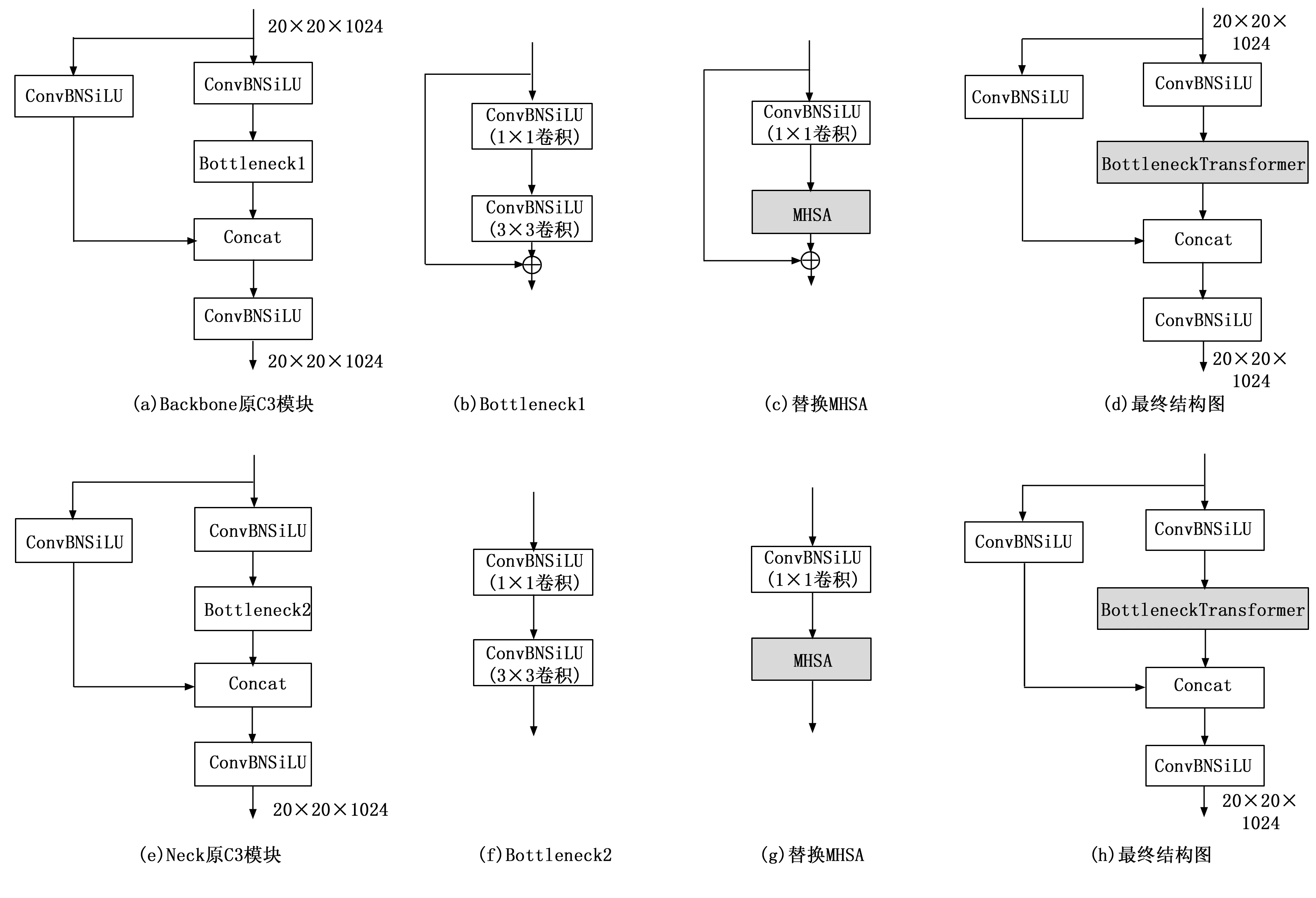
图4 MHSA的替换过程
2.2 添加注意力机制ECA
传统的注意力机制有很多,例如SE(Squeeze-and-Excitation)、CA(CoordAttention)以及CBAM(Convolutional Block Attention Module),加入注意力机制的目的就是为了从众多信息中选择出当前任务更关注的信息。2020年天津大学Wang Qilong[15]等人提出了一种高效的通道注意力机制(ECA),具体结构如图5所示,作者通过对注意力机制SE的研究发现,SE注意力机制首先会对输入特征图进行了通道压缩,而这样的压缩降维对于学习通道之间的依赖关系有不利影响,基于这个缺点,提出了一种无需降维的局部跨通道交互策略,该策略可以通过1D卷积有效地实现,并且可以自适应选择一维卷积核的大小[16]。
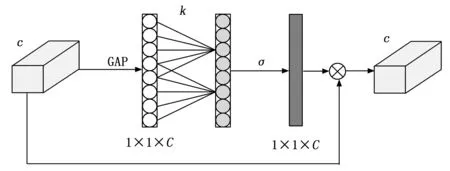
图5 ECA结构图
ECA模块的实现主要分为三步,第一步是将输入特征图进行全局平均池化(Global average pooling,GAP)操作,从而获得未降维的所有特征;第二步则进行卷积核大小为k的1维卷积操作,以此来捕获局部跨通道交互信息,接着经过 Sigmoid 激活函数得到各个通道的权重,如公式(1)所示;最后将权重与原始输入特征图对应元素相乘,得到最终输出特征图[17]。
ω=σ(C1Dk(y))
(1)
式中,C1D代表一维卷积;k为卷积核大小;y代表输入特征图;σ代表Sigmoid 激活函数。
有时由于距离远,从视频监控中监测到的吸烟人员相对较小,使用原始的YOLOv5s算法无法检测到吸烟行为。为此本文引入ECA注意力模块,通过将此模块添加在YOLOv5s网络Backbone部分中80×80×256的CSPLayer层输出位置,以此来增强算法的特征学习能力,让算法关注更有用的信息,最终提高YOLOv5s算法对吸烟行为的检测效果。
2.3 修改损失函数
传统的目标检测损失函数(例如GIoU(Generalized Intersection over Union)、CIoU(Complete Intersection over Union)、ICIoU(Improved CIoU)等)依赖于边界框回归度量的聚合,如预测框和地面真值框的距离、重叠面积和长宽比。但是,这种方法有一个明显的缺点,那就是没有考虑真实框与预测检测框之间方向不匹配的问题,使得目标检测算法在模型训练的过程中出现预测框“四处游荡”的情况,导致收敛速度较慢且效率较低,最终产生更差的模型[18]。针对上述缺点,Zhora Gevorgyan[19]提出了一种新的损失函数SIoU,SIoU充分考虑了所需回归之间的向量角度,并且重新定义了惩罚指标,从而有效提高模型训练的速度和推理的准确性。
SIoU 损失函数由4个成本函数组成,分别是角度成本、距离成本、形状成本以及IoU(Intersection over Union)成本。在目标检测一开始的训练中,大多数的预测框与真实框是不相交的,为了快速的收敛两框之间的距离,添加角度感知LF组件,定义如公式(2)所示,进而可以最大限度地减少与距离相关的变量数量。
(2)
式中,α为预测框与真实框之间的水平夹角。
但是直接使用角度损失是不合理,因此还需要考虑距离。定义距离成本时考虑了公式(2)定义的角度成本。
Δ=∑t=x,y(1-e-γρt)
(3)
式中,γ为2减去角度成本,当t为x时,ρt表示真实框和预测框宽的差值比上真实框和预测框最小外接矩形宽的平方值;当t为y时,ρt表示真实框和预测框高的差值比上真实框和预测框最小外接矩形高的平方值。
形状成本定义为:
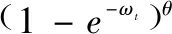
(4)
式中,当t为w时,ωt表示预测框和真实框的宽的插值的绝对值比上两宽中的最大值;当t为h时,ωt表示预测框和真实框的高的插值的绝对值比上两高中的最大值。θ值定义形状成本,其值对于每个数据集都是唯一的,若θ=1,则代表立刻优化形状,从而影响形状的自由运动。
IoU表示预测框与真实框相交的面积比上相并的面积。最后SIoU损失函数定义如公式(5)所示:
(5)
原YOLOv5s网络中的损失函数为CIoU将边界框的纵横比作为惩罚项加入到边界框损失函数中,一定程度上可以加快预测框的回归收敛过程,但是一旦收敛到预测框和真实框的宽和高呈现线性比例时,就会导致预测框回归时的宽和高不能同时增大或者减少。而用SIoU替换CIoU就可以轻而易举的解决这个问题,从而有效提高模型训练的速度和推理的准确性。
2.4 特征金字塔改进
原本的YOLOv5s网络采用FPN+ PAN的金字塔结构,FPN自顶向下将高层的强语义特征传递下来,对整个金字塔进行增强,不过只增强了语义信息,对定位信息没有传递,而PAN就是针对这一点,在FPN的后面添加一个自底向上的金字塔,对FPN补充,将低层的强定位特征传递上去,结构如图6(a)(b)所示。

图6 不同特征融合结构示意图
尽管这种结构有效加强了网络的特征融合能力,但是却存在一个问题,那就是PAN没有接收到原始的信息,只接收到FPN的输出信息,这就导致模型训练时目标检测算法学习出现偏差,进而导致检测精度低的问题,此外,带来很大的计算量。针对这个问题,谷歌提出一种新的双向特征网络BiFPN,BiFPN允许特征既能够自下而上也能够自上而下地反复流动,从而可以重复多次以得到更多高层特征融合,具体结构如图7(c)所示[20],与FPN+PAN结构相比,BiFPN去掉了只有一条输入边和输出边的结点,并且如果输入和输出结点是同一层的,就额外添加一条边,如图7(c)中的P4、P5和P6层。因此,用BiFPN网络替换FPN+ PAN的金字塔结构,可以有效增强不同网络层之间特征信息的传递,明显提升YOLOv5s算法检测精度,并且具有不错的检测性能。

图7 LabelImg软件操作界面
3 实验与分析
3.1 数据集采集及制作
本文实验的数据集采用两种方式进行采集,第一种采集方式是先录制模拟电厂厂区内不同人员吸烟的视频,然后按照一定的帧率间隔截取视频获得图片,另一种采集方式是从网络上搜集不同场景下的吸烟图片,通过上述采集方法共采集图片1 395张,其中,视频截取图片873张,网络搜集图片522张。对于准备好的数据集,采用LabelImg软件进行标注。操作界面如图7所示,按照标签为cigarette进行标注,标注完的信息以xml的格式保存在相同路径下,然后通过代码脚本将xml文件转换为YOLOv5模型需要的txt文件。最后将数据集按6∶2∶2的比例划分为三部分,分别为训练集、验证集和测试集。
3.2 实验环境与模型训练
本次实验的实验平台操作系统为Ubuntu18.04,实验以Pytorch为软件框架,编程环境为Python,CPU为Intel(R)Xeon(R)Glod5118CPU@2.3 GHz,GPU为GeForce RTX2080Ti,显存24 G,内存128 G。
实验参数的设置根据自己电脑的性能而定,由于本文实验使用有四张独显的实验室服务器,其性能远优于普通电脑,故其参数的设置相对较高。本文实验均是在不加载预训练权重的情况下进行,其他相关参数设置如表1所示。
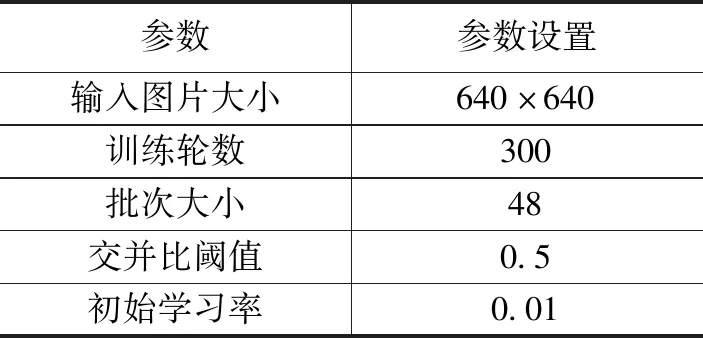
表1 相关参数设置
划分完数据集后,搭建YOLOv5网络环境,修改数据配置文件和模型配置文件,然后根据自己的电脑配置设置好相关的参数进行训练。训练结果如图8所示,从图中可以看出,box_loss和obj_loss曲线逐渐下降,最后趋于稳定,这两条曲线趋近的值越小,表明方框越准,目标检测越准;cls_loss曲线指推测为分类loss均值,越小分类越准;Precision曲线、Recall曲线以及mAP曲线随着训练轮数的增加,逐渐趋于0.9,表明训练效果较好,训练精度较高。
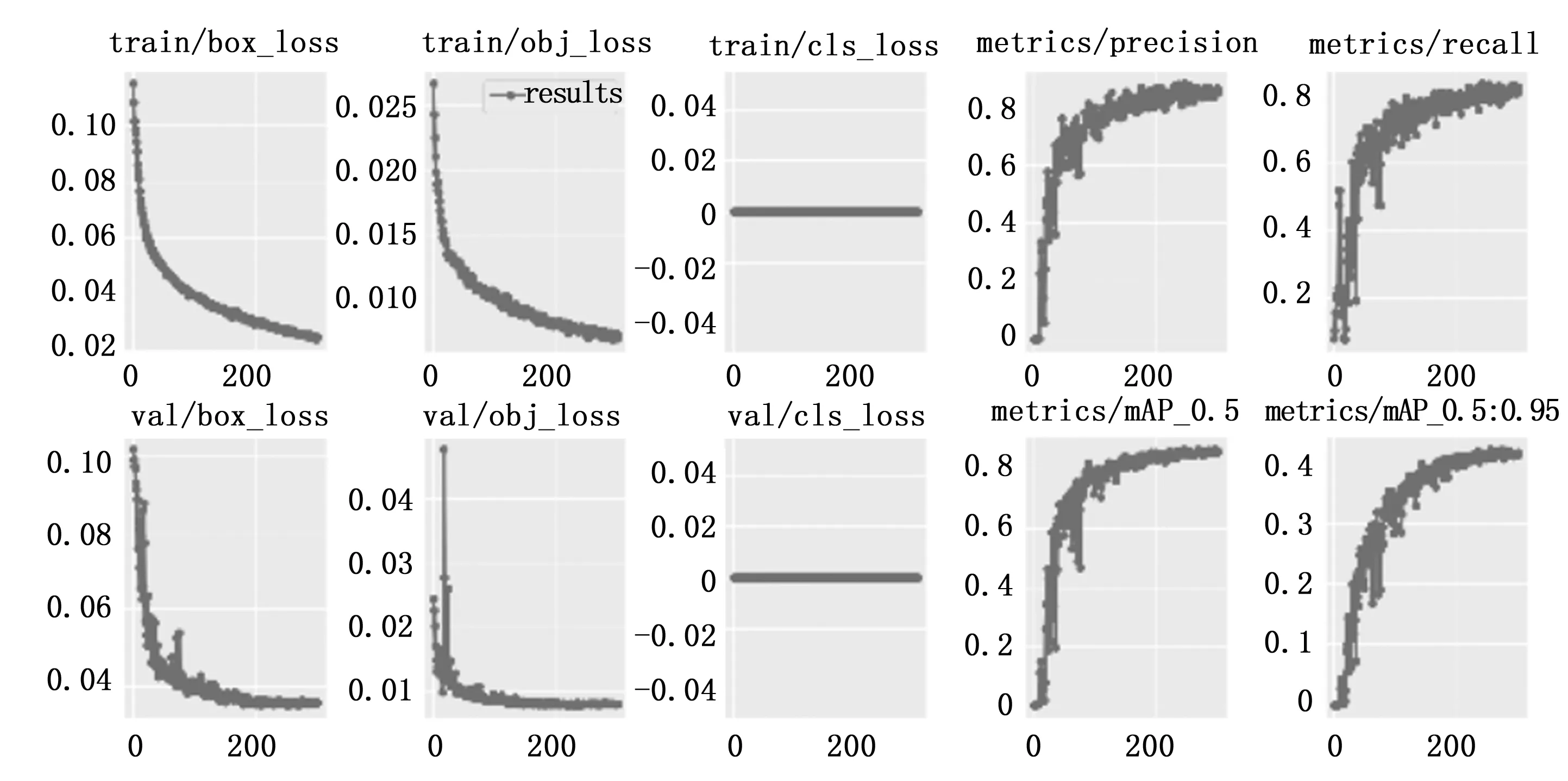
图8 训练参数变化图
训练结束后会生成相应的权重文件,将测试代码中的权重路径修改为生成的best权重文件,其余相关参数设置同训练设置一样,然后运行代码就会生成测试结果。改进前后的网络对吸烟行为的检测如图9所示,图(a)表示原YOLOv5s的检测效果,图(b)表示改进后YOLOv5s算法的检测效果,可以看出,使用原YOLOv5s检测时存在一定的误报和漏报,而使用改进后的算法进行检测时,误报和漏报情况明显改善,并且对于视频监控下远距离的人员吸烟行为检测置信度达79%,属于较易检测出的对象,检测效果较好。

图9 算法改进前后的检测效果对比图
3.3 模型评价指标
目标检测实验评价中将模型参数量(万)、模型权重文件大小(MB)、查全率(Recall,R)、查准率(Precision,P)、平均精度均值(mAP)、每秒检测帧数(Frames Per Second,FPS)这几项性能指标评判算法的性能。其中P、R和mAP分别为[21]:
(6)
(7)
(8)
其中:TP(True Positives)表示被正确检测出的目标数,FP(False Positives)表示检测错误的目标数,FN(False Negatives)表示未被检测出来的目标数,∑r=1,∑Pri表示PR曲线上时对应P的数值,num_classes为类别数。
3.4 实验评估与分析
3.4.1 替换多头注意力机制的实验分析
为了确定替换多头注意力机制的位置,本文通过将不同位置的C3模块Bottleneck中的3×3卷积替换成多头自注意力层,在不加载预训练权重的情况下在A、B、C、D四种替换方案下进行实验,替换位置如图10所示,替换方案如表2所示,实验结果如表3所示。通过实验最终确定将Backbone和Neck中两个C3模块Bottleneck的3×3卷积替换为多头自注意力层时,检测精度提高2.3%,检测效果最好。

表2 具体替换方案
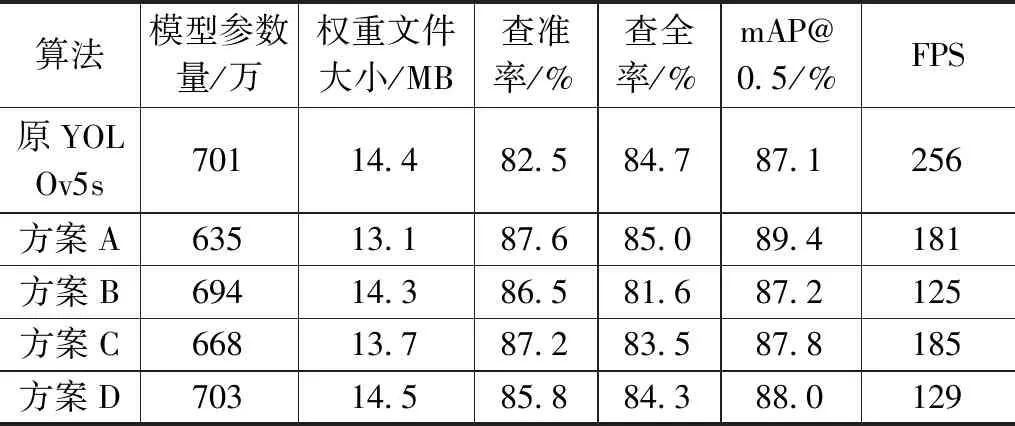
表3 替换多头自注意力层验证实验

图10 替换位置
3.4.2 注意力模块实验
为了验证加入注意力模块后算法的检测能力以及探究应该将注意力模块加到算法的具体哪个位置,本文通过在同一位置分别加入ECA、CBAM、CA三种注意力机制实验,实验结果如表4所示,实验结果表明,加入ECA注意力机制的效果最好。然后再变换ECA加入的位置,具体替换位置如图10所示,具体实验结果如表5所示。通过实验得出,将ECA加到Backbone部分中80×80×256的CSPLayer层输出位置的效果最好,精度提升3.9%。
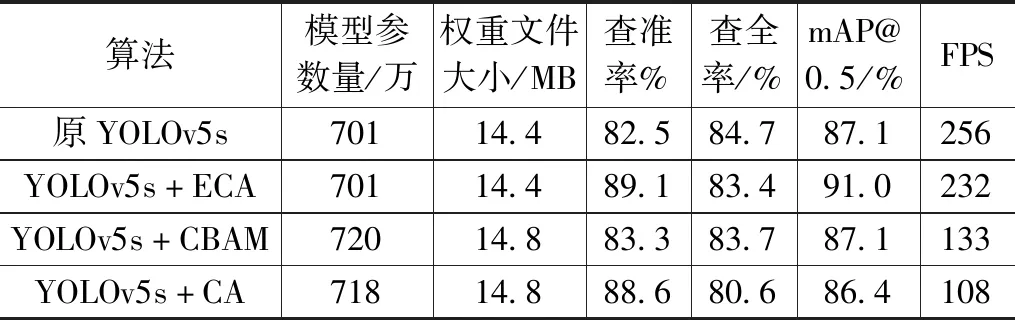
表4 融合不同注意力模块对比实验
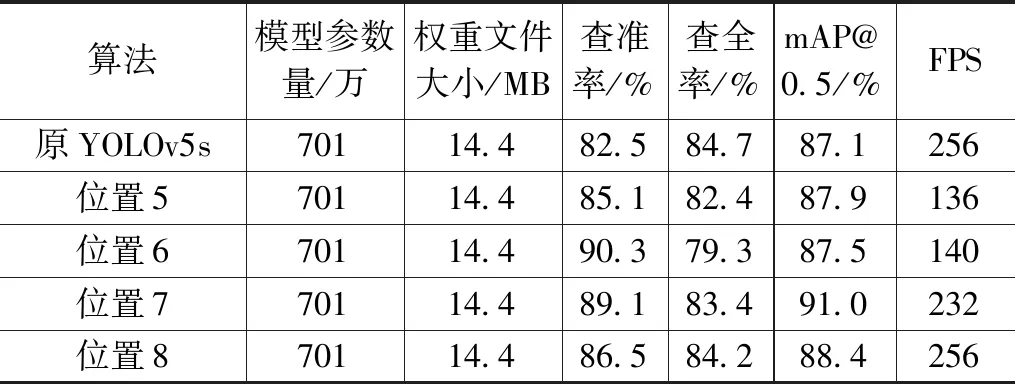
表5 融合注意力模块验证实验
3.4.3 损失函数实验
为了验证SIoU损失函数的有效性,本文以YOLOv5s 为基础,通过替换原始网络损失函数为本文引入的SIoU以及EIoU和Alpha-IoU两种常用损失函数,其他部分均不变,在同一数据集上进行实验,实验结果如表6所示。通过实验可以看出,相较于其他两个损失函数,原始网络替换完SIoU的效果最好,精度提升了3.6%。

表6 改进损失函数SIoU验证实验
3.4.4 金字塔实验
为了验证改进BiFPN的有效性,本文将原始YOLOv5s算法和将FPN+PAN结构改为本文提出的BiFPN 结构进行实验,实验结果如表7所示[22]。通过实验结果可以看出,替换完BiFPN 以后,目标检测算法的检测精度提高了0.9%。
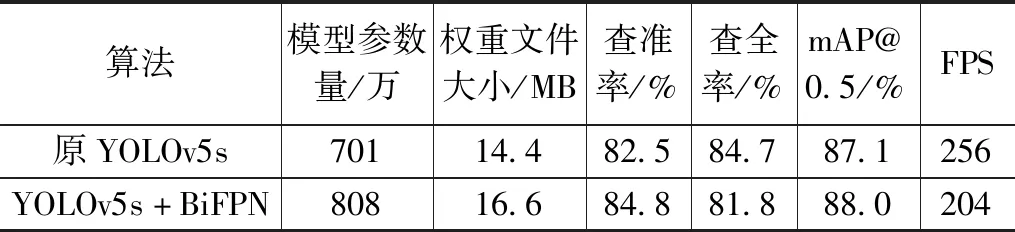
表7 替换BiFPN验证实验
3.4.5 消融实验
本文提出的4种改进方法分别为MHSA、ECA、SIoU、BiFPN。为了验证这4种不同改进方法的有效性,本文在原始YOLOv5s网络的基础上,分别只改进一种方法,然后再将4个改进点一同加入进行实验,实验结果如表8所示。实验结果表明,每种改进方法都显著提高了模型的检测精度,其中加入ECA注意力机制的精度提升最高,提高了3.9%。此外,将4个改进点一同加入,精度提升也十分明显,相交原始YOLOv5s网络提高2.2%。通过消融实验,再次证明了本文提出的改进点有效提高了目标检测算法的检测精度。
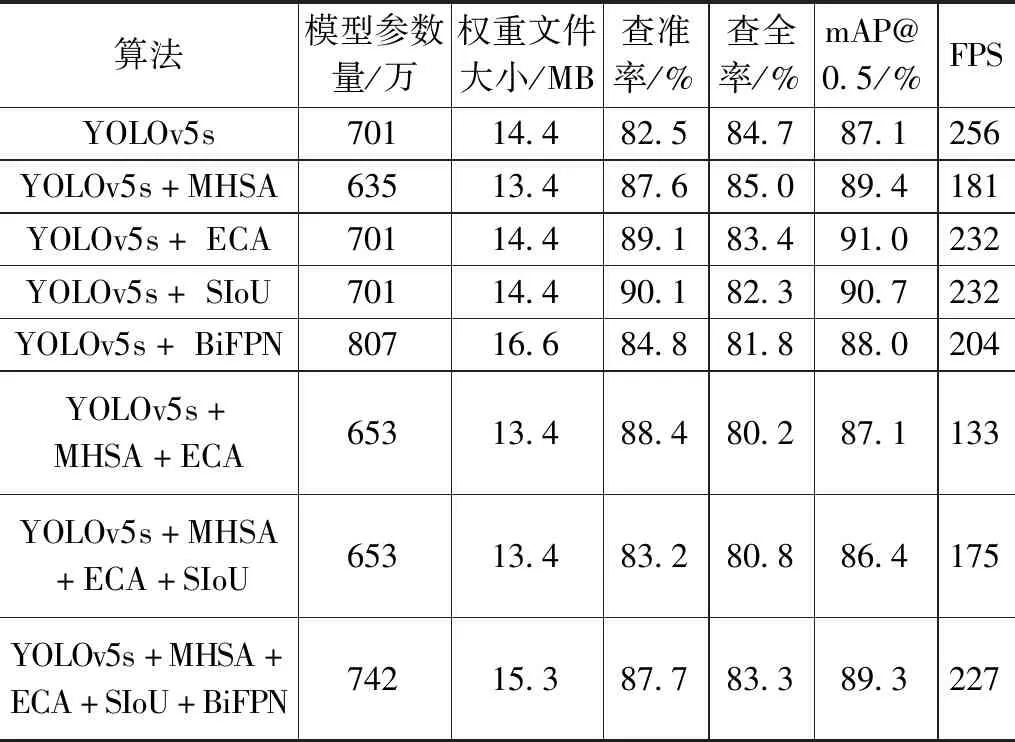
表8 消融实验结果
3.4.6 对比实验
为了进一步证明本文改进算法的优越性和有效性,有必要将其与其他目标检测算法进行对比,因此将本文算法与传统的YOLOv3、YOLOv3-tiny、YOLOv5l、YOLOv5m、YOLOv5x、YOLOv5s以及YOLOv5n进行对比,实验结果如表9所示。
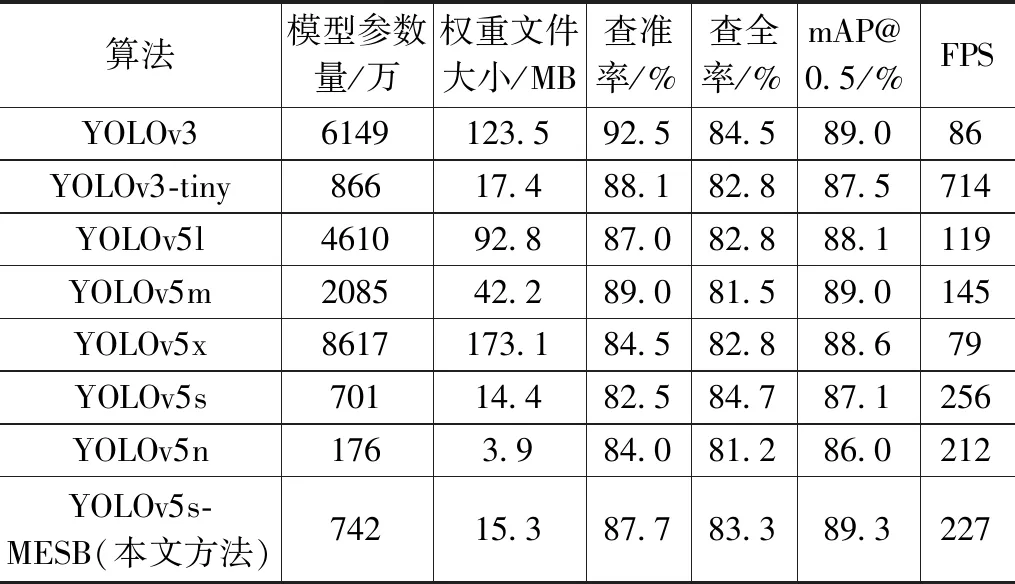
表9 不同的算法模型性能对比
从实验结果可以看出,相较于其他几种目标检测算法,本文提出的算法检测精度最高。其中,YOLOv3、YOLOv5m以及YOLOv5x的检测精度与本文提出的算法检测精度较为相近,但本文所提算法权重文件大小只有YOLOv3的12.3%,只有YOLOv5m的36.2%,只有YOLOv5x的8.8%,体量优势明显;相较于检测速度较为相近的YOLOv5n算法以及 YOLOv5l算法,本文所提算法的检测精度优势明显,比YOLOv5n高3.3%,比YOLOv5l高1.2%,此外,虽然YOLOv5n有最小的权重文件,仅有3.9 MB,但是检测精度却较低,只有86%,无法精确的识别有无人员吸烟,相较于权重文件大小相近的YOLOv5s、YOLOv3-tiny,本文提出算法的检测精度分别提高了2.2%、1.8%。综上所述,本文提出的YOLOv5s-MESB算法在保持轻量化的同时,有着最高的检测精度,并且保持着较好的实时性,整体表现较为突出,证明了本文所提算法的优越性。
4 结束语
由于距离远,从视频监控中捕捉到的吸烟人员相对较小,图像相对模糊,用原始的YOLOv5s网络检测吸烟人员精度较差,并且误检漏检严重,为此本文通过对多头自注意力层、ECA注意力模块、损失函数SIoU、BiFPN等方法的研究,将其统一改进到YOLOv5s网络中,进一步优化YOLOv5s算法。实验结果证明,改进后的算法对于吸烟行为的检测精度提高了2.2%,检测速度达到了227FPS,在保持算法速度和轻量化的同时获得了更高的检测精度,相比其他目标检测算法,更加适用于对吸烟行为的检测。但是,对于人员密集或是在阴暗的场合,本文改进的算法会存在一些误检,影响检测效果,因此本文算法还有很大的改进空间,后续工作可以针对提高密集人群和阴暗场景下吸烟检测精度进行研究,来进一步提升吸烟行为的检测效果。
