基于改进YOLOv5s的无人机火灾图像检测算法
2023-06-02苏小东胡建兴陈霖周廷高宏建
苏小东,胡建兴,2,陈霖周廷,高宏建
(1.贵州理工学院 航空航天工程学院,贵阳 550003;2.中航贵州飞机有限责任公司,贵州 安顺 561000)
0 引言
火灾是世界性的自然灾害之一,也是日常生活中主要灾害,其发生发展不仅对自然环境有着严重影响,还威胁着人们的生命与财产安全,因此及时准确地发现火灾并预警具有十分重要的研究和现实意义。近年来由于自然和人为原因引发的火灾已造成极大的人员伤亡和生态破坏。2020年四川凉山发生森林火灾,过火面积超过30 m2,火灾造成19人死亡[1]。在2014年,拥有300多年历史的贵州报京侗寨失火,烧毁房屋100余栋[2]。
传统的火灾检测算法通过温度、烟雾传感器采集相关数据进行火灾预测,但是检测准确性和实时性得不到保证。随着计算机技术和人工智能技术的不断发展,深度学习技术已经在图像识别和检测方面展示了良好性能,被广泛应用到火灾检测和预警。基于深度学习的目标检测算法,如:R-CNN[3]、Fast R-CNN[4]、Faster R-CNN[5]、YOLO[6-9]、SSD[10]、RetinaNet[11]、EfficientDet[12]等。这些算法根据原理不同被分为:单阶段目标检测算法和双阶段目标检测算法。YOLO从2016年被提出就受到广泛关注,作为基于回归的单阶段目标检测算法,其在COCO数据集上均表现出良好性能,但对于无人机航拍图像,其在检测速度上仍然达不到实时要求,模型比较大,对设备硬件要求比较高,不能够很好的部署在无人机平台[13-15]。
在火灾检测领域,晋耀[16]采用 Anchor-Free 网络结构,在MobileNetV2 网络后引入特征金字塔结构,模型AP50达到90%,单张火灾图片检测时间为40.1 ms。张坚鑫[17]提出一种改进的Faster R-CNN检测火灾区域的目标检测框架,将主干网络替换为ResNet101,并加入注意力机制,模型mAP为0.851。任嘉锋[18]利用FPN思想,将更低层次特征与高层次特征进行融合提高模型检测小目标能力,模型Map为0.87,相比YOLOV3原模型提高8个百分点。栗俊杰[19]等针对无人机火灾检测问题,提出一种改进yolov2-tiny无人机火灾检测方法,并将模型部署至K210开发板,算法检出率为96.6%,检测速度为每秒14帧,为无人机火灾检测提供新思路,但其训练数据集为常规火灾数据集,飞机试验飞行高度为3米,与无人机实际工作环境有一定差异。杨文涛[20]针对小目标检测问题,通过增加小目标检测层和特征融合的方法,提升模型对小目标检测准确度,为无人机图像目标检测提供借鉴。
针对以上问题,笔者利用自主航拍火灾视频、互联网公开无人机航拍视频和北亚利桑那大学[21]公开FLAME航拍森林火灾图像自建无人机航拍火灾图像数据集,以YOLOv5s为基础模型,修改网络结构并引入注意力模块(CBAM,convolution block attention module),提出一种改进YOLOv5s的无人机航拍火灾图像检测方法。并通过仿真实验验证算法可行性,为部署无人机平台奠定技术基础。
1 材料与方法
1.1 航拍火灾图像采集
数据集来源于无人机航拍火灾视频和北亚利桑那大学公开FLAME航拍森林火灾图像。无人机航拍火灾视频拍摄于贵州理工学院蔡家关校区足球场,采用大疆MATRICE 300 RTK无人机搭载高清摄像头与2020年10月20日对模拟火灾场景进行拍摄,通过调整无人机飞行高度获取不同高度的航拍火灾视频。如图1所示。

图1 航拍火灾图像
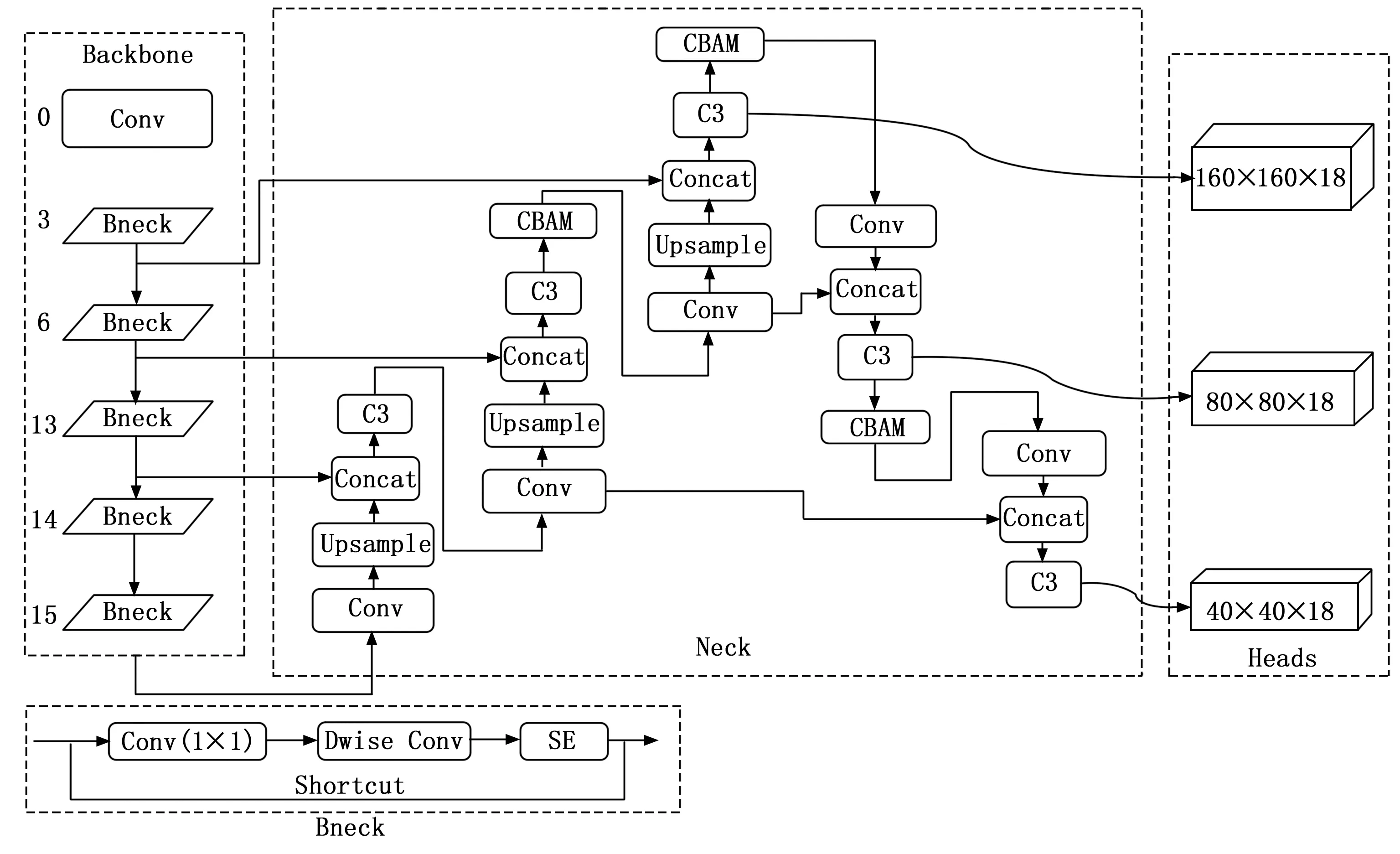
图2 改进YOLOv5s网络结构
1.2 数据集构建
本文按照VOC格式自主构建数据集,由火灾视频、火灾干扰视频(类似火灾)和FLAME数据集构成。视频利用DVDVideoSoft Free Studio软件对视频每10帧截取图像,共获得841张图像火灾图像和1 161张干扰火灾图像,在FLAME中筛选1 492张无人机火灾图像,自建3 494张无人机火灾图像数据集。
利用标注软件labelImg对无人机火灾图像标注,文件包括图片的位置、名称、宽度、高度和维度,以及标注框对应的坐标信息。
1.3 研究方法
相比于其他目标检测算法,YOLO 算法的特点是兼具精度和速度,这使得工程部署成为可能。YOLOv5是YOLO系列中比较容易部署的,其模型最小为1.9 M。本研究使用YOLOv5s为基础模型,算法结构如图3所示,其由主干网络(Backbone)、颈部(Neck)和检测层(Detect)3个部分组成。主干网络由卷积模块(Conv)、C3模块、SPPF模块。颈部为特征融合网络,主要包含卷积(Conv)、C3模块、上采(Upsample)、特征融合(Concat)等操作[22]。检测层进行3个尺度的预测。
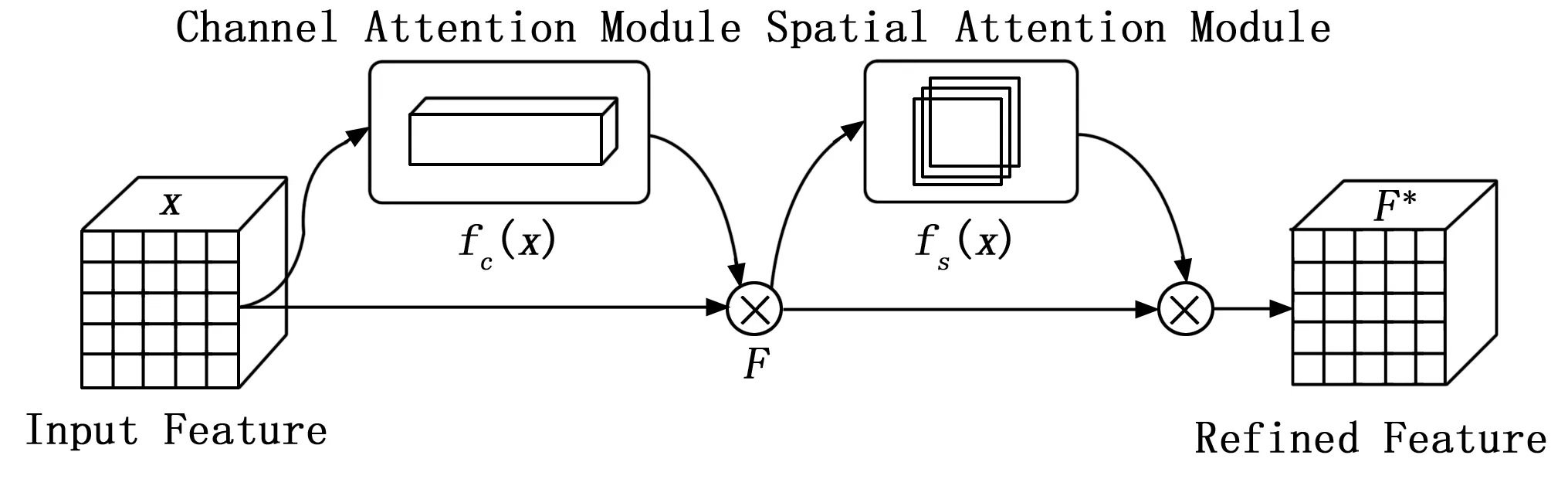
图3 CBAM模块
2 改进YOLOv5s算法
本研究引入CBAM注意力模块,修改主干网络和输出结构,在减少模型参数的同时进一步加强高层次特征和低层次特征融合,改进后的YOLOv5s结构如图2所示。
2.1 注意力机制CBAM
Sanghyun Woo(2018年)提出了一种轻量的注意力模块(CBAM,convolutional block attention module),如图3所示。CBAM包含2个独立的子模块,通过通道注意力模块(CAM,channel attention module)和空间注意力模块(SAM,spartial attention module)获得通道与空间上的信息并融合[23]。相比于SENet,CBAM不仅关注特征的位置信息,还关注目标的语义特征,分别在空间和通道两个维度。网络更加关注感兴趣的目标区域,可以增强有效特征,抑制无效特征或噪声,尤其是对于小目标区域,能获取更多的小目标的细节信息,避免小目标特征不明显被当成背景信息[24-25]。
CBAM中,输入特征图x,通过通道注意力和空间注意力模块的串行计算,得到输出特征F*,即:
F=fc(x)⊗x
(1)
F*=fs(F)⊗F
(2)
式中,fc(x),fs(F)分别表示通道注意力和空间注意力,F为通道注意力输出,F*为空间注意力输出,x为输入特征图。
将输入特征经最大池化和平均池化后,输入MLP多层感知器,然后逐元素加和操作后经过激活函数生成通道注意力模块输出,输出与输入特征图逐元素作乘法操作后作为空间注意力模块的输入。利用通道注意力模块输出的特征图作为空间注意力模块的输入,通过通道注意模块的最大池化和平均池化得到两个H×W×1的特征图,通过Concat方式拼接为H×W×2,随后通过卷积操作(7×7)降维,最后通过激活函数操作得到空间注意力模块输出,输出与空间注意力模块输入逐元素相乘得到最终特征
fc(x)=σ(MLP(AvgPool(x))+MLP(MaxPool(x)))
(3)
fs(x)=σ(Conv7×7(Concat(AvgPool(F);MaxPool(F)))
(4)
式中,σ(x)为激活函数,MLP为多层感知器,AvgPool为平均池化操作,MaxPool为最大池化操作,Conv7×7为卷积核大小为7的卷积运算,Concat为拼接方式。
2.2 检测层改进
YOLOv5s中有3个尺度的检测层,分别为20×20、40×40、80×80(输入为640×640),可以检测大中小目标,对图像具有很强的适应能力。本研究中自建数据集图像为航拍火灾图像,目标多为小目标,大尺度检测层的作用不明显,为了在不降低检测性能的前提下尽可能减少参数,删除大目标检测层20×20。在小目标检测中,具有丰富位置信息的浅层特征比具有丰富语义信息的深层特征更重要[26]。为了弥补高层次特征分辨率降低造成的空间信息丢失,提高YOLOv5s模型对小目标的检测能力,将第3层与第 27层融合、第 6与第 22 层的融合,第 13与第 18层的融合,检测尺度变为40×40、80×80、160×160。
2.3 骨干网络修改
为了更好将模型部署在无人机嵌入式平台,使用MobileNetV3[27]代替YOLOv5s骨干网络,通过轻量型网络对模型进行优化,减少参数量和运算量,提升检测实时性。
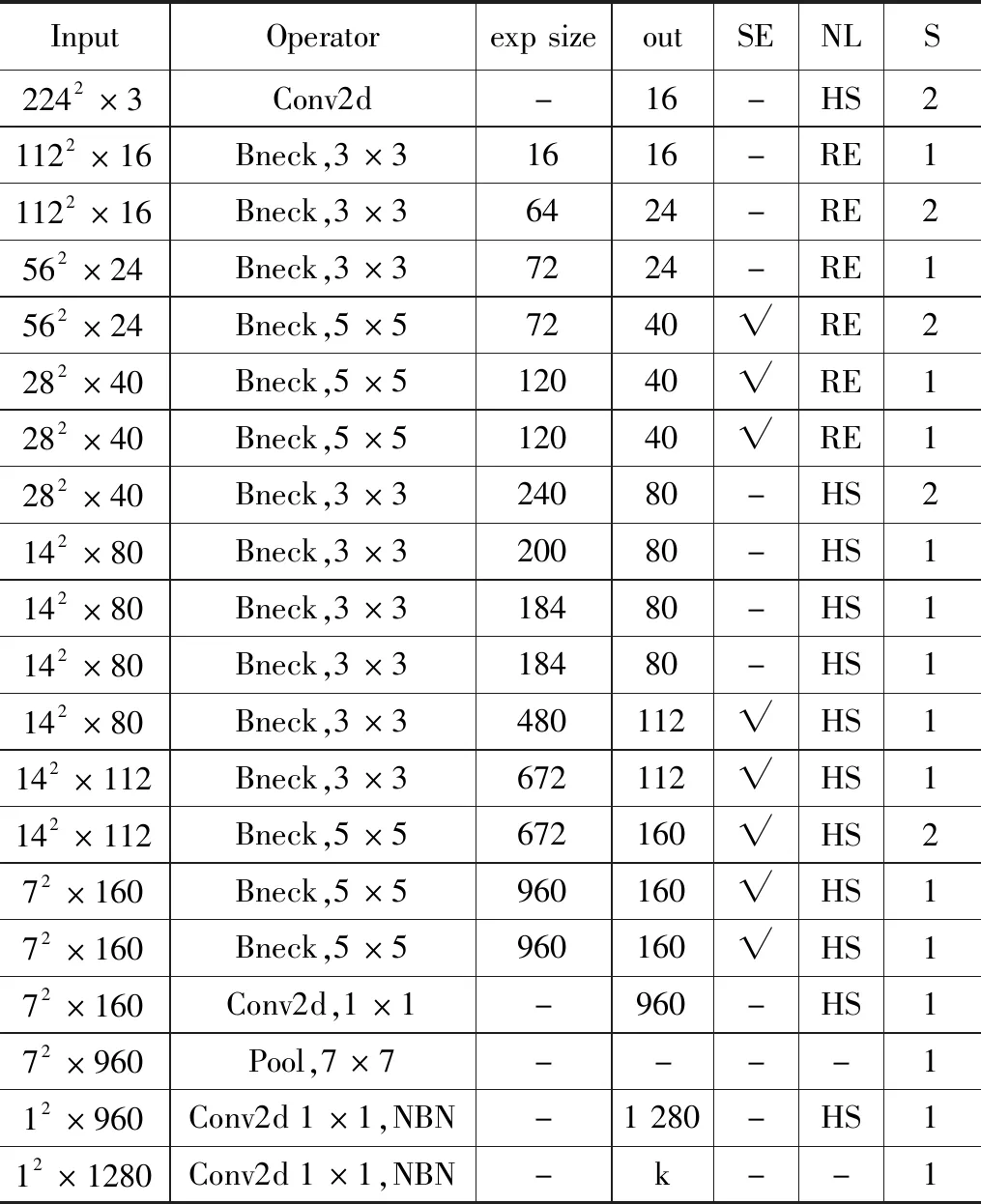
表1 MobileNetV3-Large网络结构
MobileNetV3主要针对嵌入式设备和移动端设备开发,是一种轻量化网络结构,它继承V1[28]的深度可分离卷积,降低网络的计算量,引入V2[29]的具有线性瓶颈的残差结构并引入轻量化SE注意力模块,使网络关注更有用的信息来调整每个通道的权重,同时该网络在结构中使用了 h-swish 激活函数,代替 swish 函数,减少运算量,提高性能。其中深度可分离卷积是MobileNet系列的主要特点,也是其发挥轻量级作用的主要因素,MobileNetV3相比MobileNetV2可以在COCO数据集达到相同精度,但速度提高了四分之一,如图4所示。
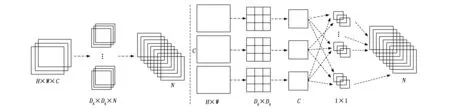
图4 标准卷积与深度可分离卷积
与标准卷积相比,深度可分离卷积将其拆分为逐通道卷积和点向卷积两个阶段。在逐通道卷积阶段,输入特征图中的每个通道仅和与之对应的单通道卷积核进行卷积操作,各输入通道之间相互独立,取消了通道之间特征融合,保持了卷积后输出特征图通道数量。点向卷积使用标准卷积方式,采用 1×1 大小卷积核对所有通道的输出特征图进行整合处理,进而改变输出特征图的通道数,深度可分离卷积参数量与标准卷积参数量的比值Q与计算量比值R为[29]:
(5)
式中,N输出特征图数量,DK为输出特征图尺寸。
因此深度可分离卷积能降低卷积操作的参数量与计算量,使网络更加轻量化,提高模型检测效率。
3 试验环境与参数设置
3.1 训练环境
本实验选用开源的PyTorch框架,PyTorch是一个开源的Python机器学习库,该框架具有强大GPU加速的张量计算,包含自动求导系统的深度神经网络,PyTorch版本为1.7.0,编程语言选用Python3.8.10,硬件设备配置为Interi7-9700,内存为8 G,GPU为GeForce RTX 2060 Super,显存为8 G,操作环境为Ubuntu20.04。
3.2 训练参数设置
模型训练参数设置BitchSize为6,epoch为100。初始学习率lr0为0.001,动量因子为0.937,优化器选用Adamw,超参数flipud =0.5,mixup =0.5,mosaic=1,copy_paste=1,训练方式采用多尺度训练。
3.3 评价指标
目标检测的效果由预测框的分类精度和定位精度共同决定,因此目标检测问题既是分类问题,又是回归问题[26]。目标检测模型的评价指标有精度(Precision,P,%)、召回率(Recall,R,%)、平均精度(Average Precision,PAP,%)、均值平均精度(Mean Average Precision,mAP,%)等。PAP用来衡量数据集中某一类的平均分类精确率,平均精确率均值(Mean Average Precision,mAP),用来衡量分类器对所有类别的分类精度,也是目标检测算法最重要的指标。本文中只有一个类别,PAP与mAP相同。
为了综合评价模型,本文使用平均精确度PAP、模型参数量、模型大小和处理图像速度FPS(帧/s)、浮点运算数FLOPs作为模型的主要评价指标。其中均值平均精度计算公式如下:
(6)
(7)
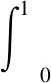
(8)
式中,XTP为正样本被检测为正样本的数量;XFP为负样本被检测为正样本的数量;XFN为正样本被检测为负样本的数量。
4 试验与分析
为了验证小目标检测层、CBAM注意力机制和轻量化骨架MobileNet在无人机火灾检测任务重的有效性,本文在自建数据集上进行了一系列消融试验,以YOLOv5s为基线算法,mAP、P、模型大小、参数量、浮点运算次数为评价指标。
4.1 检测尺度改进试验
为了验证测试小目标检测尺度对模型的影响,在基础模型的基础上增加一个160×160的小目标检测尺度,构成20×20、40×40、80×80、160×160四个检测尺度的YOLOv5s模型。
表2中分析了增减不同检测层,对模型性能的影响,可以看出增加小目标检测层,比基线模型平均精度上升3个百分点,侧面说明小目标检测层可提升特征提取能力,但网络层数增多,参数量和模型大小分别增加329 714和1.1 M;增加小目标检测层,并删除大目标检测层后,平均精度提升5个百分点,小目标检测能力得到明显提升,同时参数下降164 681 6,模型大小减少2.9 M,主要得益于小目标检测层具有下采样的效果,使网络输出特征图数量大幅减少,参数数量下降;删除20×20、40×40大中目标检测层,只保留80×80、160×160小目标检测层后,模型精度比基础模型精度提升3.6个百分点,参数量和模型大小分别减少209 470 6和3.9 M。综合分析后,检测头部网络选择40×40、80×80、160×160三个中小尺度来检测目标。
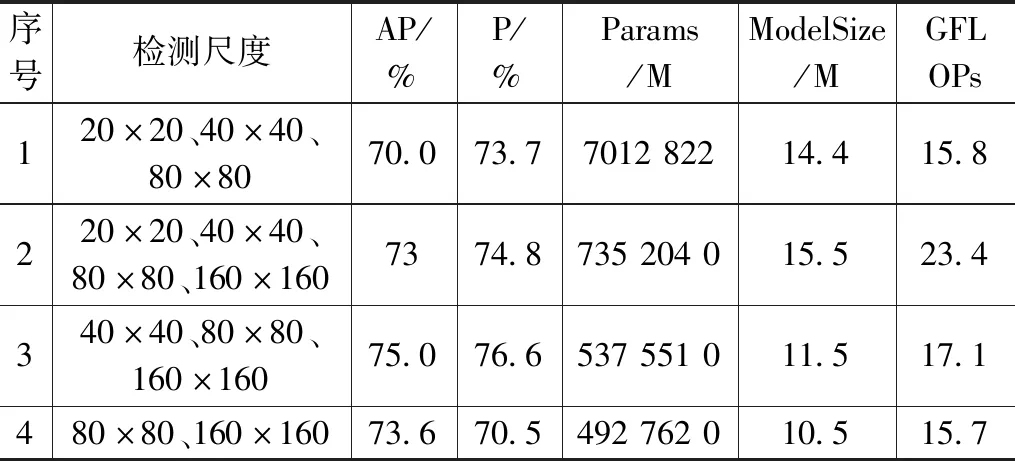
表2 不同检测尺度性能对比
4.2 消融试验
为进一步说明小目标检测层无人机图像检测的有效性和CBAM注意力机制和轻量化骨架MobileNet对模型性能的影响,在自建数据集上进行消融试验。
4.2.1 CBAM对模型的影响
由实验1,2;3,5;4,6;7,8分别对比分析可知,注意力机制CBAM不仅可加强对感兴趣区域的特征提取能力稳定提升模型平均精确度PAP,还可节约参数和计算量。
4.2.2 改进检测层对模型的影响
由实验1,3;2,5;4,7;6,8分别对比分析可知,增加小目标检测层可提升模型对小目标的特征提取能力提升模型平均精确度PAP并减少参数量。
4.2.3 MobileNetV3对模型的影响
由实验1,4;2,6;3,7;5,8分别对比分析可知,MobileNetV3不仅具有强大的特征提取能力,在不降低检测效果的前提下还因深度可分离卷积的作用可大幅度减少参数量和计算量。
由消融实验(表3)可知,YOLOv5s基础模型在自建数据集上PAP为70.0,参数量为702 232 6个,模型大小为14.4 M,计算量为15.8 G,将上述3种改进方法同时加入基线模型时,模型PAP提升6.9个百分点,模型参数减少404 710 0个,同比减少57%,模型大小减少7.7 M,同比减少53.4%,计算量减少6.2 G,同比减少39.2%。,验证了改进方案的可行性,改进后的YOLO5s在不降低精度的前提下,大幅减少模型参数和计算量,可以有效指导无人机进行火灾检测。
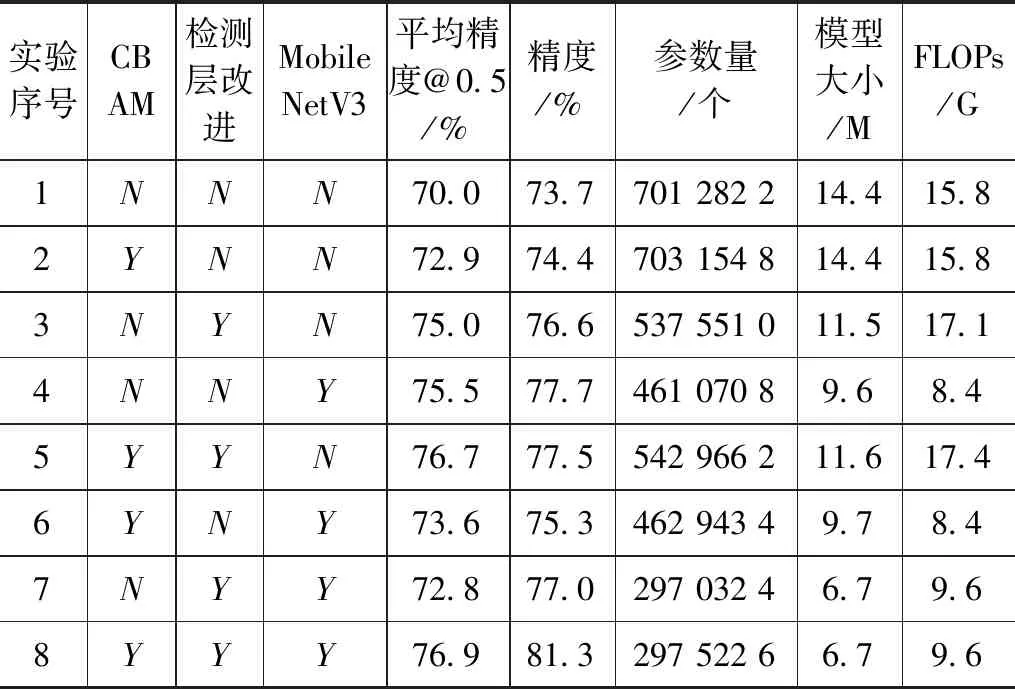
表3 自建数据集消融实验
图5为训练过程中PAP和损失的曲线图,PAP得到显著提升,损失值进一步降低,直观的说明改进方法对模型性能的有效提升。
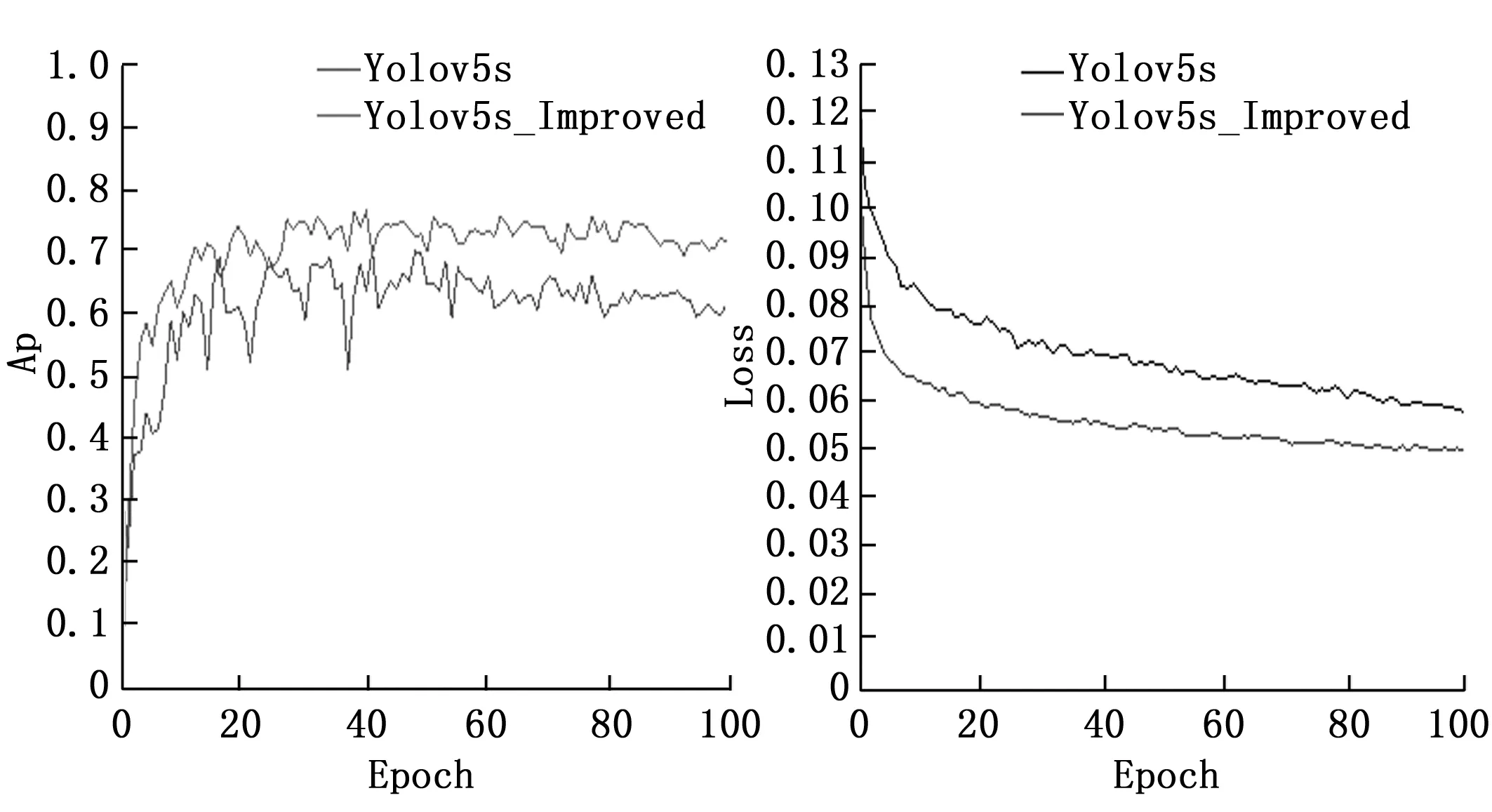
图5 训练过程参数曲线
图6为算法在测试集中火灾检测效果图,图(a,b,c)为改进前的火灾检测效果,图(d,e,f)为改进后的火灾检测效果。检测结果表明本文改进的YOLOv5s算法,可快速准确检测出火灾位置,降低了重复检测以及在干扰图像中误检的情况,提高了检测精度。

图6 算法检测效果
5 讨论
5.1 YOLO系列检测算法在自建数据集上的性能对比
为证明改进后YOLOv5s算法对无人机火灾目标检测的有效性,本文对YOLO系列算法在自建数据集上性能进行对比分析,表4所示为各算法对自建数据集航拍火灾目标的P值、mAP值、模型规模和浮点运算次数FLOPs。从表4中可以看出,改进YOLOv5s算法与其他先进算法相比取得了最优的综合性能,检测性能与YOLOv3比较接近,模型大小仅为YOLOv3的5.4%,浮点运算次数仅为9.6 G,计算量较小。由此可见本文提出改进YOLOv5s算法在处理无人机火灾图像目标检测任务时具有较大优势,其检测精度达到81.3%,效果是十分可观的。

表4 YOLO系列检测算法在自建数据集上性能对比
5.2 主流火灾检测算法性能对比
为证明改进后YOLOv5s算法相比其他主流火灾检测算法的优势,将本文算法与当前主流火灾检测算法进行对比分析,表5所示为各算法对常规火灾数据集上的P值、mAP值、模型规模和FPS。可以看出当前主流火灾检测算法模型评价指标主要以精度为主,未涉及模型大小、参数、计算量等指标,但这些指标均影响着模型的部署难易程度和实时性,其在精度和均值平均精度都达到较高水平,但实时性比较差,尤其是采用两阶段目标检测算法(FasterRCNN),处理1帧火灾图像需要1秒左右时间,单阶段算法YOLO、CenterNet等最快可每秒处理59.6帧火灾图像。本文提出的改进YOLOv5s算法,在保证精度的前提下,优化网络结构,降低网络参数,模型大小为6.7 M,每秒可处理66.6帧640×640火灾图像,容易部署,实时性比较好。
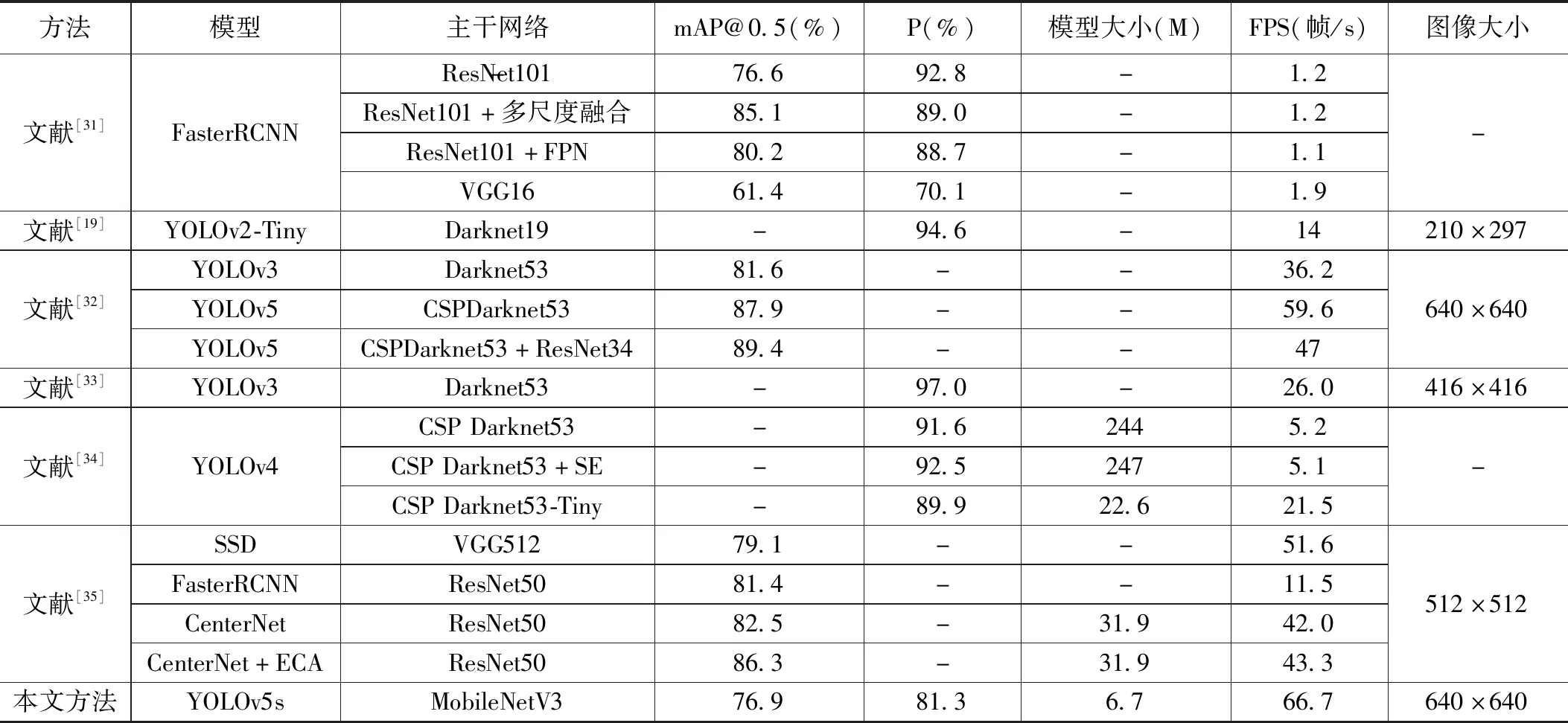
表5 主流火灾检测算法性能对比
6 结束语
针对常见火灾检测算法应用场景受限,模型无法部署在无人机平台的问题,本文提出一种基于YOLOv5s轻量化航拍火灾检测算法。针对模型体量大,在无人机平台部署难度大的问题,以MobileNetV3为特征提取主干网络,减少模型参数和计算量。为了增强模型对感兴趣区域特征提取能力和抑制无效特征和背景信息,引入CBAM注意力机制,加强网络特征提取能力;针对无人机火灾图像主要为小目标的特点,修改网络头部检测层,提高模型小目标检测能力。通过消融实验验证各个模块对模型性能均有不同方面和不同程度的提升,改进后火灾检测平均精度达到76.9%,模型大小仅为6.7 M,满足部署无人机平台的要求,图像处理速度为66.7帧/s,即单帧图像处理时间为15.2 ms,满足实时性要求。通过与主流目标检测算法和主流火灾检测算法对比分析可知,改进后的YOLOv5s,不仅具有良好的特征提取能力,模型体量小,计算量小,实时性强,满足部署无人机进行火灾检测的要求,为无人机火灾检测提供技术基础,具有一定的科学和现实意义。
