商用4G&5G小基站基带芯片的设计与分析
2023-06-02王俊
王俊
关键词:系统级芯片;5G NR;4G LTE;BB;DSP
1引言
近10年来,4G&5G通信技术的飞速发速极大地提升了通信效率,改变了日常的通信生活方式。5G相比于4G,其空口带宽更大、天线数更多、调制阶数更高,空口速率更是提升到10倍以上,带宽与多天线等通信技术对基站的物理层信号处理能力提出了更高的要求。目前,市场上的5G网侧基带芯片基本被国外芯片厂商垄断,如NXP,Qualcomm,Intel,Xilinx等,国内设备商华为和中兴也有自研的5G基带SoC芯片,但不对其他设备商销售。因此,国内的小站设备商获得4G&5G基带商用SoC芯片的选择范围很小,若要选择纯国产的基带SoC芯片更是不可能。因此,研制一款能部分替代国外小站基带芯片的国产商用SoC芯片便提上了日程。
2项目概况
该基带SoC芯片OC8010是可用于4G&5G小基站或自定义软件无线电(SDR)方案中的基带处理芯片。芯片遵循3GPP[1]Rel-15和Rel-16,并有足够软化资源以支持后续版本的演进,同时兼顾功耗、性能、面积的平衡性。基带处理主要集成了4个高效能的协议与控制处理器ARM A72 CPU、4G和SG双模通信基带处理硬件加速器、4个高性能的专为SG优化过的CEVA XC-12矢量DSP等。另外,芯片上还集成了丰富的前传与中传高速接口、低速外设接口等。在这些加速器和矢量处理器的辅助下,用户可以实现高吞吐率的多种无线通信系统。
芯片设计专门考虑了一些低功耗设计,这些设计有助于其在各种通信场景下获取高性能和低功耗特性。另外,芯片的研发、生产、封装和测试都在国内,是國产自主可控的SDR基带处理芯片。
OC8010是一个异构多核基带SoC,软硬件架构更加复杂,在芯片设计中需应对这几个方面的挑战:更加复杂的数据通信和任务调度:庞大的抽象的系统架构,以实现清晰、高效的硬件与软件设计;协调好SoC上的硬件加速、DSP和CPU等各种异构并行处理资源;提供丰富有效的片上调试功能;在性能、灵活性、功耗、面积等方面折中。
3SoC芯片系统结构设计
OC8010SoC上的基带处理资源主要包括物理层信号处理、物理层控制、前传后中传接口等子系统,BB SoC芯片架构图如图1所示。其中,物理层信号处理子系统主要由芯片上的L1硬件加速器(L1 Accelerator)与矢量DSP(L1 Processor)构成;物理层控制子系统主要由ARMCPU构成;接口子系统包含前传(分布式单元DU与远端单元RU) CPRI或eCPRI接口,与中传(中央单元CU与分布式单元DU)PCIe或ETH接口。
OC8010基带SoC芯片上有丰富的计算资源,有符合3GPP的比特级编译码加速器,以及OFDM波形前端LowPHY处理加速器,片上有多达近万亿MAC运算能力的矢量4个DSP核,可以满足用户差异化的信道估计与均衡算法设计,或者用户自定义的专用通信系统基带信号处理。其可以应用于4G&5G小基站的基带处理,如图2所示,OC8010可以分别完成全部的L1 High-PHY与LowPHY处理,或是只完成High-PHY的处理,需要外接NPU进行L2/L3协议栈处理,外接DFE芯片完成中射频处理等。
该芯片基带处理器中的运算资源灵活可配,可以根据波形基带处理的复杂度,采用1套或2套运算资源完成单模或双模并发波形处理。以单模5GNR为例,可以支持的典型规格为FRl-TDD,BW= 100 MHz.SCS=30 kHz.2小区4T4R,并可以实现DL 4 Gbps,上行2 Gbps的峰值吞吐量。若4G&5G双模并发配置下,则可以同时支持SGNR FRl-TDD,BW=100 MHz.SCS= 30 kHz@ 4T4R 1小区.4G LTE BW= 20 MHz,SCS=15 kHz@ 4T4R 3小区的规格。
4SoC芯片主要功能模块设计
4.1CPU子系统模块设计
Cortex-A72处理器是ARM公司于2015推出,并为高性能,低功耗的处理器实现了ARMv8-A体系结构。其广泛应用于高端智能手机、大屏移动设备、企业网络设备、服务器、无线基台、数字电视等领域。OC8010芯片集成了4个ARM Cortex-A72核,L1和L2缓存子系统等。具体如表1所列。
ARM 72 11存储器系统由独立的指令缓存(I-Cache)与数据缓存(D-Cache)构成[2]。
A72 11指令缓存系统具有以下特点:(1)固定的Cache line为64字节;(2)每16位采用奇偶校验保护;(3)指令缓存按物理索引和物理标记(PIPT)方式工作;(4)采用LRU(Least Recently Used)缓存替换策略;(5)支持内存自检测试MBIST(Memory Built-InSelf Test)。
A72 11数据缓存系统具有以下特点:(1)固定的Cache line为64字节;(2)每32位采用ECC保护;(3)数据缓存按物理索引和物理标记(PIPT)方式工作;(4)支持对正常内存的乱序、推测性、非阻塞性加载请求和对设备内存的非推测性、非屏蔽性加载请求;(5)采用LRU缓存替换策略;(6)硬件预取器,生成针对L1数据缓存和L2数据缓存的预取;(7)支持内存自检测试MBIST(Memory Built-In Self Test)。
在4个Cortex-A72核的共同作用下,CPU子系统可以确保在每个时隙(slot)内完成小基站多小区多用户的处理要求。CPU子系统主要负责物理层处理的控制功能,完成L2与L1之间的FAPI(SCF222:PHYAPI Specification)请求消息参数的解析、FAPI响应消息的准备发送、配置物理信道(如PDSCH,PDCCH,PBCH,PUSCH,PUCCH,PRACH等)的参数、调度L1硬件加速器与L1 DSP矢量处理器完成物理层发送和接收处理等。
4.2DSP子系统模块设计
片上集成了4个高性能矢量CEVA XC12 DSP核。XC12是CEVA的第4代矢量处理器IP,它能够进行客户配置和扩展,应用范围较广,可用于蜂窝网络的5G-NR和4G-LTE,智能手机或其他终端,如Wi-Fi UE和CPE等,提供极低功耗、Gbps级的无线调制解调器功能,以便于客户实现高吞吐率的宽带无线通信系统。
CEVA-XC12 DSP架构突破了以下关键技术。
(1)全新微架構满足超高频率和超低功耗要求——能够在10nm内以1.8 GHz频率运作,与前代产品CEVA-XC4500相比,功耗降低50%。
(2)具有大规模计算能力,以维持高数据速率——配备4矢量处理器引擎,每秒运算次数接近1万亿次(TOP)。
(3)全新独特的高精度算法——支持高达256×256维矩阵高效运算。
(4)用于加速基带信号处理组件的全新专用指令和算法库——为先进的256和1024 QAM解调提供创新支持。
(5)新型核间数据流接口——允许在内核或加速器之间达到超低传输延迟。
为了提升DSP的性能,OC8010对一些关键电路采取了优化方案,如缩短了分频电路的路径延时,并将片上DSP的最高时钟频率提至800 MHz~1GHz。
4.3加速器模块设计
OC8010芯片集成了宽带通信系统常用的硬件加速器。在这些硬件加速器的辅助下,可以实现高吞吐率的4G,SG及用户自定义无线通信信号处理加速,如图3所示为OC8010芯片基带处理软硬件划分,片上的硬件加速器主要包括编译码、均衡、Low-PHY等加速器子系统。
4.3.1编译码加速器子系统
该加速器子系统由LDPC和Polar、卷积、Turbo等加速器构成,LDPC和Polar编码和译码器遵循3GPP38.212 Rel-16规范,主要用于SGNR的编译码处理以及Turbo和卷积编码。译码加速器遵循3GPP 36.212Rel-10规范,主要用于4G LTE的编译码加速处理。
业务信道编码器主要完成TB CRC、CB分割、CBCRC、LDPC/Turbo编码、速率匹配、CB级联等处理;业务信道译码器主要完成CB分割、解速率匹配、HARQ合并、LDPC/Turbo译码、CB CRC、CB级联、TB CRC等处理。表2为典型配置下(LDPC与Turbo译码均为8次迭代)的业务信道编译码器最大吞吐量性能(@ 600 MHz时钟频率)。
4.3.2均衡加速器子系统
均衡加速器子系统支持最小均方误差干扰抑制(MMSE-IRC)算法,因该算法良好的性能与复杂性而被业界广泛应用。MMSE-IRC算法对于基站检测位于相邻小区间环境中的用户来说是必不可少的,与MMSE-MRC算法相比,它能够减少区间干扰和降低高斯噪声的影响,进而提升了接收机的均衡性能。
OC8010的均衡加速器可支持自适应MMSE-IRC和MMSE-MRC算法,可使接收机在不同信道环境下均能获得最好的均衡性能。图4为该加速器的功能示意图。
该均衡加速器可以支持PUSCH均衡处理,在典型配置下的处理能力为:完成每个上行slot全部均衡处理时间小于1个3GPP定义的时隙(slot)。这里的典型配置为2个SGNR FRl-TDD小区,每小区273PRB(BW100MHz,SCS=30 kHz),4接收天线,2Layer等。
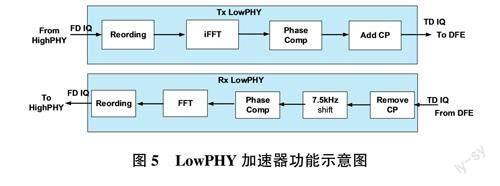
4.3.3时频域转换LowPHY加速器子系统
该加速器主要完成OFDM波形变换:Tx Low-PHY主要完成数据重排、IFFT、加CP、相位补偿(5G)等处理;Rx Low-PHY主要完成去CP、相位补偿(5G)、7.SkShift( LTE)、FFT、数据重排等处理。LowPHY加速器功能示意图如图5所示。
该LowPHY加速器的典型处理能力为2个SGNRFRl-TDD小区,每小区4T4R,BW=100 MHz,SCS=30 kHz。
4.4存储器模块设计
在异构多核系统芯片中,数据的存储、传输与交换需要更加高效的存储架构,从而导致存储与计算之间的矛盾更加突出。基带信号在处理高密集计算类应用时,如何设计高效的片上共享存储器对发挥SoC整体性能有重要作用。
OC8010基带芯片上的处理单元之间需要大量的数据交互,通过仔细分析基带接收与发送信号处理的数据流,得到几种典型场景下的数据流模型(Trafficmode),包括但不限于模块间的数据吞吐量、数据缓存大小、处理单元数据的并发。
OC8010上的共享缓存具有如下系统特性:(1)缓存大小为10 MB字节;(2)分成8个Bank,每个Bank1.25 MB字节;(3)每个Bank均为2端器存储器,支持对同一个Bank不同地址地同时读与写;(4)支持任务队列以及每个端口优先级可配;(5)多个端口访问权重可配,支持带权重的轮询(WRR)访问机制;(6)每个port支持基于“紧急”的防饿死机制等。
4.5总线模块设计
总线结构及互连设计直接影响芯片总体性能的发挥,OC8010片上总线选用ARM的CoreLink NIC系列主流商用总线,将系统中的ARM CPU处理器、CEVA DSP、加速器、PCIe等高速外设、12C等低速外设、存储器(SRAM,ROM,DDR)等所有系统组件连接起来,允许这些组件之间进行互联互通,并且易于软件编程使用。系统分析与评估了片上的通信带宽、吞吐率、QOS、功耗使用、安全性以及成本等因素后,最终通过片上切分为多个总线区域进行互联,参见图1。
4.6高速接口模块设计
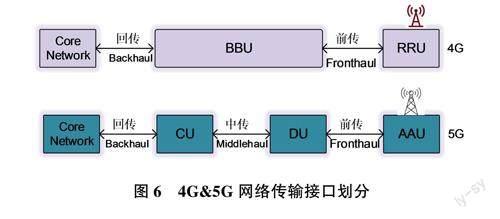
4G只有前传和回传2个部分,在SG网络中则演变为三个部分,AAU连接DU部分称为SG前传(Fronthaul),中传(Middlehaul)指DU(处理L1物理层)连接CU(处理L2/L3协议栈)部分,而回传(Backhaul)是CU和核心网之间的通信承载,如图6所示。基带SoC处于BBU中的DU部分,相关的接口只涉及前传与中/后传。
前传接口:OC8010上的eCPRI用于O-DU High-PHY和O-RU Low-PHY之间通过以太网传输频域IQ数据,接口遵循O-RAN联盟的前传接口规范,同时支持OTIC的相关标准。支持5G物理层功能按Option8(CPRI)和Option7-x(eCPRI)接口切分方式与RU对接,芯片可编程配置处理前传接口的CPRI/eCPRI协议数据和用户自定义数据,CPRI/eCPRI接口均支持发送与接收数据的压缩与解压缩,支持的压缩算法如块浮点(Block Float-Point)、块缩放(Block-scaling)、律(I -law)等,能够满足4G&5G多应用场景下的定制化需求。
中后传接口:DU与CU之间的中传接口采用PCIe Gen4(向下兼容Gen3)或ETH (10GE),该接口主要实现L1与L2的通信。
5SoC芯片的可靠性设计
5.1高可靠的冗余电路设计
对于内存软错误(soft errors),错误修正码(ECC)技术在SRAM电路中得到了广泛的应用,通过对输人数据进行编码并在内存中添加额外的冗余存储位来提高内存的容错性。对于硬错误(hard errors),内置自检(built-in self-test,BIST)技术是内存测试技术的主流,内置自修复(built-in self-repair,BISR)技术应运而生,用于处理硬错误的修复。通过BISR的修复,可极大地提高芯片的优良率以及降低芯片的成本。ECC电路和BISR电路分别用于软误差和硬误差的修复。以上两种冗余电路技术在OC8010芯片上都已被采用,用来提升芯片的可靠性以适应不同的工作环境。
5.2高可靠复位电路设计
为确保芯片系统中电路稳定可靠工作,复位电路是必不可少的一部分。例如,电路在工作中受到干扰后,容易出现CPU程序“跑飞”而盲目运行,甚至出现死机现象,芯片上的复位电路则能够纠正系统错误,以确保系统正常工作。
高可靠复位电路主要应用场景包括如下几个部分。
系统启动:从芯片上电复位开始至CPU加载完Uboot这一阶段,复位电路进行的PLL配置、时钟切换等应用。
子系统初始化:片上子系统由复位释放到正常工作这一阶段,复位电路对应的初始化操作。
子系统重启:子系统在正常工作日寸,可根据需求重新启动。包括CPU、DSP以及各类硬件加速器等子系统重启等。
异常情况处理:应对异常触发的场景,复位电路对应的操作。
5.3多工作模式设计实现低功耗
OC8010芯片从一开始的系统设计阶段就引入了低功耗设计,在系统和架构设计层从性能和功耗方面进行软硬件划分,通过软硬件协同仿真,将最佳性能/功耗比作为确定片上软硬划分的依据,以及将不同的子系统功能单独分割开,方便后续芯片的实现等。
在RTL设计阶段采用的主要方法如下。
(1)门控时钟技术(Clock gating),根据设计将暂时不用的模块的时钟信号通过一个控制信号关断( gating)住,降低该模块的时钟信号翻转率,从而降低芯片功耗。
(2)电源门控(power gating),可通过静态配置的方式,将芯片中某个区域的供电电源关掉。
(3)支持动态频率(Dynamic Frequency Scaling)调节等,如支持每个DSP核可单独配置持降频至1/2和1/4。
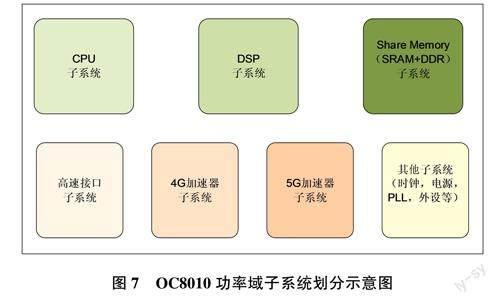
另外,根据系统中各个模块的用途,以及IP自身支持的低功耗方案,将SoC划分为不同的功率域,系统级的功率域如图7所示。
针对不同的功率域子系统,以及每个子系统内部模块都可以进行精细的低功耗设置,如可以对部分CPU/DSP核或者某个加速器进行关断,从而有助于在各种通信场景下获取高性能和低功耗特性。
6结束语
宽带无线通信基帶芯片的设计是一个复杂的系统工程,只有少数几家国外芯片巨头可提供成熟的解决方案。本文介绍了国产OC8010商用小基站基带芯片的设计与实现方案,提出了支持4G&5G双模并发的基带芯片解决方案,设计中解决了基带芯片处理数据量大、算法复杂度高、可靠性要求高、低功耗等问题,满足了商用4G&5G的大容量要求。该芯片方案有助于相关人员了解目前小基站基带芯片的现状,并为类似基带芯片设计提供指导。
